2020-12-10 Thu
■ #4245. 頻度と漸近双曲線 (A-curve) [lexical_diffusion][zipfs_law][frequency][statistics][language_change][uniformitarian_principle]
variationist の立場を高度に押し進めた言語(変化)観を提案する,Kretzschmar and Tamasi の論考を読んだ."A-curve", "asymptotic hyperbolic distribution", "power law", "S-curve" などの用語が連発し思わず身構えてしまう論文だが,言わんとしていることは Zipf's Law (cf. zipfs_law) の発展版のように思われる.低頻度の言語項は多く,高頻度の言語項は少ないということだ.
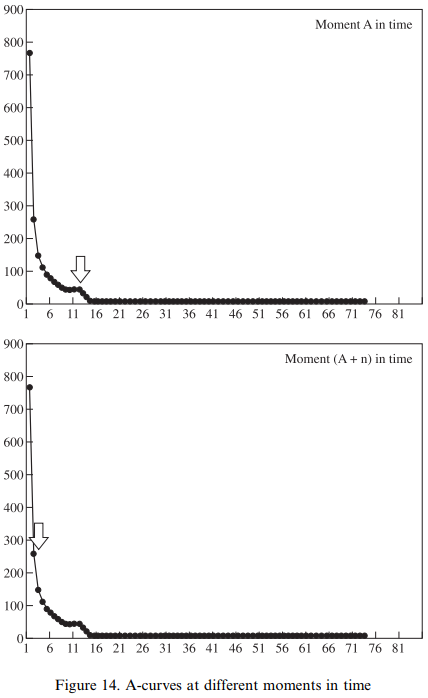
ある英語コーパスにおいて,1度しか現われない語は相当数ある.一方,the, of, have などは超高頻度で現われるが,主として機能語であり種類数でいえば相当に限定される.例えば,1回しか現われない語 ( x = 1 ) は1000個 ( y = 1000 ) あるが,1000回も現われる語 ( x = 1000 ) は the の1語しかない ( y = 1 ) とすると,これを座標上にプロットしてみれば第1象限の左上と右下に点が打たれることになる.この2点を両端として,その間の点を次々と埋めていくと,y = 1/x で表わせるような漸近双曲線 (asymptotic hyperbolic curve) の片割れに近づくだろう.これを Kretzschmar and Tamasi は "A-curve" と呼んでおり,背後にある法則を "power law" (べき乗則)と呼んでいる.後者は "few realizations that occur very frequently and many realizations that occur infrequently" (384) ということである.
Kretzschmar and Tamasi は,アメリカ方言における訛語や調音の variants を調査し,各種の変異形について頻度の分布を取った.結果として,いずれのケースについても "A-curve" が観察されることを示した.
また,Kretzschmar and Tamasi は,語彙拡散 (lexical_diffusion) との関連でしばしば言及される "S-curve" と,彼らの "A-curve" との関係についても議論している.同一の言語変化を異なる軸に着目してプロットすると "S-curve" にも "A-curve" にもなり,両者は矛盾しないどころか,親和性が高いという.
私の拙い言葉使いでは上手く解説することができないのだが,言語体系や言語変化を徹底的に variationist に眺めようとすると,このような言語観あるいは言語理論になるのかと感心した.Kretzschmar and Tamasi (394) より,とりわけ重要と思われる箇所を引用する.
Our second observation, about the distribution of variants according to Zipf's Law, has the strongest set of implications for historical study of language. If we take the A-curve as the model for the frequency distribution of variants for any linguistic feature of interest to us at any moment in time, then we should expect that any particular variant of interest to us will have a particular rank along the A-curve. Therefore, one of the things that we should try to do for any given moment in time is to determine the place of our variant of interest on the curve; we need to know whether it is the most frequent variant in the set of possible realizations (at the top of the curve), or an infrequent variant (in the tail of the curve). Then, for any subsequent moment in time, we can again try to determine the location of our variant of interest along the curve, and so try to make a statement about whether the location of the variant has changed in the intervening time (see Figure 14). Since we hypothesize that an A-curve will exist for every feature at any moment in time (i.e., that language will not suddenly become invariant), we can define the notion "linguistic change" itself as the change in the location of the target variant at different heights along the curve. If a particular variant occurs at a higher place on the curve than it did before, it has become more frequent and so we can say that the direction of change for that variant is positive; if a variant occurs at a lower place on the curve than it did before, it has become less frequent and the direction of change is negative.
・ Kretzschmar, Jr.,William A and Susan Tamasi. "Distributional Foundations for a Theory of Language Change." World Englishes 22 (2003): 377--401.
2020-08-31 Mon
■ #4144. 20世紀の語彙爆発 [oed][pde][lexicology][statistics][renaissance]
「#4133. OED による英語史概説」 ([2020-08-20-1]) で紹介した OED が運営しているブログに,Twentieth century English --- an overview と題する記事がある.20世紀の英語のすぐれた評論となっており,ぜひ読んでいただきたい.
そのなかの1節 "Lexis: dreadnought and PEP talk" で,20世紀の英語の語彙爆発の様子が具体的な数字とともに記述されている.
The Oxford English Dictionary records about 185,000 new words, and new meanings of old words, that came into the English language between 1900 and 1999. That leaves out of account the so-called lexical 'dark matter', words not common enough to catch the lexicographers' attention or, if they did, to compel inclusion, words perhaps that were never even committed to paper (or any other recording medium). Even so, those 185,000 on their own represent a 25 per cent growth in English vocabulary over the century --- making it the period of most vigorous expansion since that of the late-sixteenth and seventeenth centuries.
20世紀中(厳密には1900--1999年)に,OED に採用されたものだけに限っても18万5千もの新語(義)が加わったというのは,想像を絶する爆発ぶりである.引用の後半で触れられている通り,それ以前の時代でいえば,最大級の語彙爆発は1600年前後の英国ルネサンス期にみられた.「#114. 初期近代英語の借用語の起源と割合」 ([2009-08-19-1]),「#1226. 近代英語期における語彙増加の年代別分布」 ([2012-09-04-1]) で見たとおり,Görlach (136) は "The EModE period (especially 1530--1660) exhibits the fastest growth of the vocabulary in the history of the English language, in absolute figures as well as in proportion to the total." と述べている.
20世紀と17世紀では社会の状況も変化速度も大きく異なるので,単純に数字だけでは比較できないが,20世紀は(そしてまだ駆け出しといってよい21世紀もおそらく)英語の語彙爆発の記録を塗り替えた,あるいは塗り替えつつある時代といってよいだろう.
・ Görlach, Manfred. Introduction to Early Modern English. Cambridge: CUP, 1991.
2020-08-27 Thu
■ #4140. 英語に借用された日本語の「いつ」と「どのくらい」 [oed][japanese][borrowing][loan_word][lexicology][statistics]
「#3872. 英語に借用された主な日本語の借用年代」 ([2019-12-03-1]),「#142. 英語に借用された日本語の分布」 ([2009-09-16-1]) などの記事で見てきたように,英語には意外と多くの日本語単語が入り込んでいる.両言語の接触は16世紀以降のことであり (cf. 「#4131. イギリスの世界帝国化の歴史を視覚化した "The OED in two minutes"」 ([2020-08-18-1])),日本語単語の借用は英語史の観点からすると比較的新しい現象とはいえるが,そこそこの存在感を示しているといってよい.このことは「#45. 英語語彙にまつわる数値」 ([2009-06-12-1]),「#126. 7言語による英語への影響の比較」 ([2009-08-31-1]),「#2165. 20世紀後半の借用語ソース」 ([2015-04-01-1]) などでも触れてきた.
OED Online には,様々なパラメータにより,どの時代にどのくらいの単語が英語語彙に加わったかを視覚化してくれる "Timelines" という便利な機能がある.たとえば「日本語が語源である単語」を指定すると,日本語からの借用語が「いつ」「どのくらい」英語に流入したのかを即座にグラフ化してくれる.その結果は以下の通り.
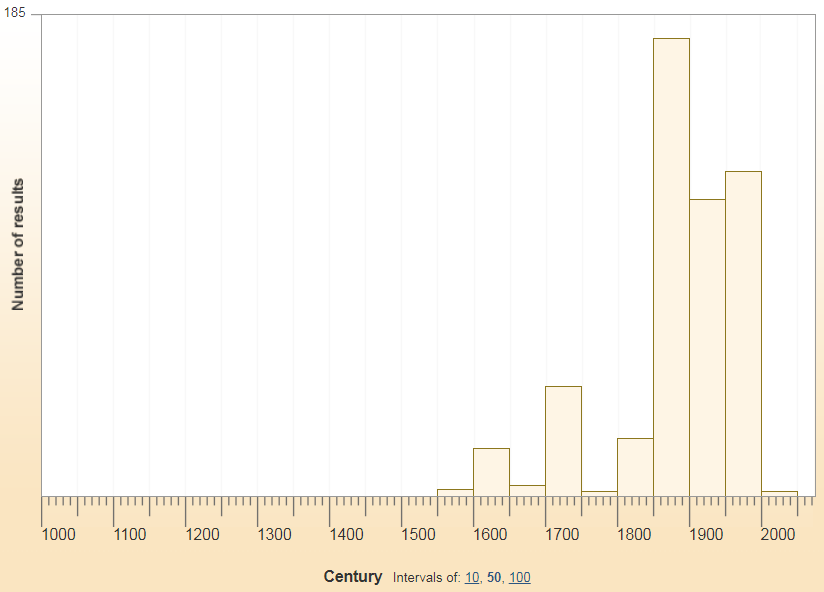
数としては19世紀後半から爆発的に増え始め,現代に至ることがわかる.19世紀後半といえば,もちろん我が国が英米を含む西洋諸国との濃密な接触を開始した幕末・明治維新の時代である.
棒グラフをクリックすると,該当する単語のリストも得られる.ここまで簡単な操作でグラフ化してくれるとは本当に便利な世の中になったなあ.
2020-08-25 Tue
■ #4138. フランス借用語のうち中英語期に借りられたものは4割強で,かつ重要語 [oed][french][latin][loan_word][statistics][lexicology][borrowing]
英語語彙史において,フランス借用語の流入のピークが中英語期にあったことはよく知られている.このことは「#117. フランス借用語の年代別分布」 ([2009-08-22-1]),「#2162. OED によるフランス語・ラテン語からの借用語の推移」 ([2015-03-29-1]),「#2385. OED による,古典語およびロマンス諸語からの借用語彙の統計 (2)」 ([2015-11-07-1]) などのグラフを見れば,容易に理解できるだろう.
OED が提供している Middle English: an overview の "Borrowing from Latin and/or French" を読んでいたところ,この問題と関連して具体的な数字が挙げられていたので紹介しておきたい.
By 1500, over 40 per cent of all of the words that English has borrowed from French had made a first appearance in the language, including a very high proportion of those French words which have come to play a central part in the vocabulary of modern English. By contrast, the greatest peak of borrowing from Latin was still to come, in the early modern period; by 1500, under 20 per cent of the Latin borrowings found in modern English had yet entered the language.
フランス借用語の流入のピークは中英語期であり,ラテン借用語のピークは近代英語期だったという順序についての指摘はその通りだが,ここで目を引くのは,引用の最初に挙げられている40%強という数字である.現代英語語彙におけるフランス借用語のうち40%強が中英語期の借用であり,しかも現在も中核的な語彙として活躍しているという.言い方をかえれば,この時期に借用されたフランス単語は,古株ながらも現在に至るまで有用性を保ち続けているものが多いということである.残存率が高いと言ってもよい.
それに対するラテン借用語の残存率は,残念ながら数字で表わされていないが,フランス語のそれよりもずっと低いと考えられる.新参者でありながら,現在まで残っていない(あるいは少なくとも有用な語として残っていない)ものが多いのである(cf. 「#478. 初期近代英語期に湯水のように借りられては捨てられたラテン語」 ([2010-08-18-1]),「#1409. 生き残ったインク壺語,消えたインク壺語」 ([2013-03-06-1])).英語史において,このフランス語とラテン語の語彙的影響の差異は興味深い.
今回の話題と関連して,「#3180. 徐々に高頻度語の仲間入りを果たしてきたフランス・ラテン借用語」 ([2018-01-10-1]),「#2667. Chaucer の用いた語彙の10--15%がフランス借用語」 ([2016-08-15-1]),「#2283. Shakespeare のラテン語借用語彙の残存率」 ([2015-07-28-1]) なども参照されたい.
2020-08-17 Mon
■ #4130. 英語語彙の多様化と拡大の歴史を視覚化した "The OED in two minutes" [oed][map][lexicology][borrowing][lexicography][philology][statistics][web_service][hel_education]
The OED in two minutes に,中英語の始まる1150年から2010年までの英語(借用)語彙史を地図上で視覚化してダイジェストで示すコンテンツが公表されている.これは凄いコンテンツ.実にみごとに英語語彙の多様化と拡大の歴史が表現されており,しかもいろいろな意味で考えさせられる.こちらからどうぞ.
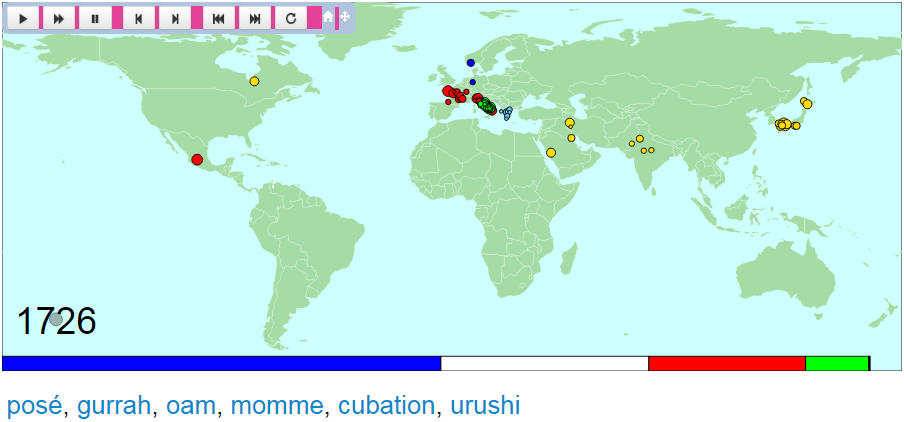
地図の下にある色付きの帯は,現代英語における語種ごとの総トークン頻度を表わしている(背後で利用されているデータベースは Google Ngrams の1970--2008年の部分だという).試しに2010年現在の地図に示される統計をみてみると,総トークン頻度にして,ゲルマン系の語彙(青帯)が49%,英語要素に基づく複合語など(白帯)が26%なので,ここまでで全体の3/4である.ロマンス系の語彙(赤帯)が18%,ラテン語が7%,そしてその他が0.2%だ.英語史では語彙の歴史は借用の歴史であるというのが定番だが,トークン頻度で考える限り,現在でも英語の語彙は圧倒的にアングロサクソン(あるいはゲルマン)的であるといってよいことになる.この事実については「#3400. 英語の中核語彙に借用語がどれだけ入り込んでいるか?」 ([2018-08-18-1]) と,そこに張ったリンク先の記事を参照.
地図左下の年号に重なって描かれている灰色のバブルは,高頻度かつ多数の単語が加わった年ほど大きくなり,低頻度かつ少数の単語が加わったにすぎない年には小さくなる.17世紀を通じて相対的に大きかったバブルが,18世紀にかけてしぼんでいく様子も興味深い (cf. 「#2995. Augustan Age の語彙的保守性」 ([2017-07-09-1]),「#203. 1500--1900年における英語語彙の増加」 ([2009-11-16-1]),「#4070. 18世紀の語彙的低迷のなぞ」 ([2020-06-18-1])) .
英語(語彙)史を大づかみするには,このようなダイジェストの視覚コンテンツが威力を発揮する.
2020-05-09 Sat
■ #4030. -ant か -ent か (3) [spelling][suffix][phoneme][statistics]
2日間の記事 ([2020-05-07-1], [2020-05-08-1]) で標題について考えてきた.両接尾辞の分布を説明することは,共時的にも通時的にも完全にはできないようだ.しかし,Upward and Davidson (423) は,関与する754語に基づいた調査を通じ,ある種の傾向を見出した.どちらの接尾辞を取るか,接尾辞の直前の音素によっておよそ予想できるという.あくまで確率論的な指摘だが,実際的に役立ちそうだ.
| Phonemes | /p/ | /b/ | /t/ | /d/ | /k/ | /g/ | /ʧ/ | /ʤ/ | /m/ | /n/ | /l/ | /r/ | /f/ | /v/ | /s/ | /z/ | /ʃ/ | /w/ | /eɪ/ | /aɪ/ | /ɔɪ/ | /aʊ/ | /ɪ/ | /ʊ/ |
| Letters | <p | b | t | d | c | g | ch | g(e) | m | n | l | r | f | v | s/c | s | ti | (q)u | a | i | oy | ow | i | u> |
| <-ant/ce> | 4 | 1 | 62 | 26 | 13 | 9 | 2 | 4 | 6 | 40 | 24 | 62 | 4 | 14 | 10 | 13 | - | - | 2 | 11 | 6 | 1 | 16 | 6 |
| <-ent/ce> | 8 | 5 | 33 | 62 | - | - | - | 42 | 1 | 24 | 48 | 27 | - | 4 | 66 | 4 | 15 | 17 | - | - | - | - | 49 | 13 |
この確率表を実用的に解釈すれば,Upward and Davidson (423) が以下に述べる通りとなる.
Positive cues for <a> spellings are accordingly a stem-final /k, g, ʧ, f/ or any of the diphthongs /eɪ, aɪ, ɔɪ, aʊ/. The only positive cue for <e> spellings is a previous /kw/. Stems ending in <-ul-> tend to have <-ent>: corpulent, flatulent, flocculent, fraudulent, opulent, succulent, truculent, turbulent, virulent. Exceptions are: ambulance, petulant, stimulant.
The spelling is therefore predictable in words such as: significance, elegance, trenchant, infant, abeyance, reliance, annoyance, allowance, eloquent, consequent.
・ Upward, Christopher and George Davidson. The History of English Spelling. Malden, MA: Wiley-Blackwell, 2011.
2019-12-22 Sun
■ #3891. 現代英語の様々な句読記号の使用頻度 [punctuation][alphabet][diacritical_mark][net_speak][brown][corpus][frequency][statistics][exclamation_mark]
英語は同じローマン・アルファベットを用いる文字圏のなかでも,句読法 (punctuation) に関しては比較的単純な部類に入る.現代的な句読記号が出そろったのは500年前くらいであり,その数も多くない (cf. 「#575. 現代的な punctuation の歴史は500年ほど」 ([2010-11-23-1])) .また,文字そのものが26文字しかない上に,フランス語やドイツ語などにみられる,文字の周辺に付す特殊な発音区別符(号) (diacritical mark; cf. 「#870. diacritical mark」 ([2011-09-14-1])) も原則として用いられない.さらに,現代の印刷文化では句読記号が控えめに使われるようになってきているとも言われる.一方,net_speak などでは,新たな句読記号の使用法が生み出されていることも確かであり,句読法の発展が止まってしまったわけではないようだ (cf. 「#808. smileys or emoticons」 ([2011-07-14-1])) .
さて,約100万語のアメリカ英語の書き言葉コーパス Brown Corpus を用いた調査によると,英語の主要な句読記号の使用頻度 (%) は次の通りだという (Cook 92) .
| Commas | 47 |
| Full stops | 45 |
| Dashes | 2 |
| Parentheses | 2 |
| Semi-colons | 2 |
| Question marks | 1 |
| Colons | 1 |
| Exclamation marks | 1 |
用いられている句読記号の9割以上が <,> か <.> であるというのは,英語の読み手・書き手の直感としてうなづける.英語の読み書き学習の観点からいえば,まずはこの2つの句読記号に習熟することに努めればよいことになる.
ローマン・アルファベット文字圏の句読記号の変異について関心のある方は,Character design standards - Punctuation for Latin 1 などを参照されたい.
・ Cook, Vivian. The English Writing System. London: Hodder Education, 2004.
2019-09-11 Wed
■ #3789. 古英語語彙におけるラテン借用語比率は1.75% [latin][loan_word][borrowing][oe][lexicology][statistics]
英語語源学の第一人者 Durkin によれば,古英語期までに英語に借用されたラテン単語の数は,少なくとも600語はあるという.650年辺りを境に,前期に300語ほど,後期に300語ほどという見立てである.この600という数字を古英語語彙全体から眺めてみると,1.75%という割合がはじき出される.しかし,これらのラテン借用語単体ではなく,それに基づいて作られた合成語や派生語までを考慮に入れると,古英語語彙における割合は4.5%に跳ね上がる.Durkin (100) の解説を引用しよう.
If we take an estimate of at least 600 words borrowed (immediately) from Latin, and a total of around 34,000 words in Old English, then, conservatively, around 1.75% of the total are borrowed from Latin. If we include all compounds and derivatives formed on Latin loanwords in Old English, then the total of Latin-derived vocabulary probably comes closer to 4.5% . . . , although this figure may be a little too high, since estimates of the total size of the Old English vocabulary (native and borrowed) probably rather underestimate the numbers of compounds and derivatives.
この数値をどう評価するかは視点の取り方次第である.後の歴史における英語の語彙借用の規模とその影響を考えれば,この段階でのラテン借用語の割合など,取るに足りない数字にみえるだろう.一方,これこそが英語の語彙借用の歴史の第一歩であるとみるならば,いわば0%から出発した借用語の比率が,すでに古英語期中に1.75%(あるいは4.5%)に達しているというのは,ある程度著しい現象であるといえなくもない.さらにいえば,その多くが千数百年を隔てた現代英語にも残っており,日常語として用いられているものも目立つのである(昨日の記事「#3788. 古英語期以前のラテン借用語の意外な日常性」 ([2019-09-10-1]) を参照).
古英語のラテン借用語については英語史研究においてもさほど注目されてきたわけではないが,見方を変えれば十分に魅力的なトピックになりそうだ.
・ Durkin, Philip. Borrowed Words: A History of Loanwords in English. Oxford: OUP, 2014.
2019-09-10 Tue
■ #3788. 古英語期以前のラテン借用語の意外な日常性 [latin][loan_word][oe][lexicology][lexical_stratification][statistics][borrowing]
昨日の記事「#3787. 650年辺りを境とする,その前後のラテン借用語の特質」 ([2019-09-09-1]) で触れたように,古英語期以前,とりわけ650年より前に入ってきた最初期のラテン借用語には,現在でも日常的に用いられているものが多い.「#334. 英語語彙の三層構造」 ([2010-03-27-1]) などで見てきたように,ラテン借用語にはレベルの高い単語が多いのは事実だが,古英語期以前の借用語に関していえば,そのステレオタイプは必ずしも事実を表わしていない.
Durkin (138--39) による興味深い数値がある.Durkin は,「#3400. 英語の中核語彙に借用語がどれだけ入り込んでいるか?」 ([2018-08-18-1]) でも示したとおり,"Leipzig-Jakarta list of basic vocabulary" と呼ばれる通言語的に最も基本的な意味を担う100語を現代英語から取り出し,そのなかにどれほど借用語が含まれているかを調査してみた.結果としては,ラテン借用語についていえば,そこには1語も含まれていなかった.
しかし,別途 "the WOLD survey" による1,460個の基本的な意味項目からなる日常語リストで調査してみると,137語ほど(およそ10%)が古英語期以前に借用されたラテン借用語と認定されるものだった.しかも,それらの単語は,24個設けられている意味のカテゴリーのうち,"Kinship", "Quantity", "Miscellaneous function words" を除く21個のカテゴリーにわたって見出されるという.つまり,英語史上,最初期に入ってきたラテン借用語は,広い分野にわたり日常的に用いられる英語の語彙の少なからぬ部分を構成しているというわけだ.古英語の形で具体例をいくつか挙げておこう.
・ butere "butter"
・ ele "oil"
・ cyċene "kitchen"
・ ċȳse, ċēse "cheese"
・ wīn "wine" (and its compounds)
・ sæterndæġ "Saturday"
・ mūl "mule"
・ ancor "anchor"
・ līn "line, continuous length"
・ mylen (and its compounds) "mill"
・ scōl, sċolu (and the compound leornungscōl) "school"
・ weall "wall"
・ pīpe "pipe, tube"
・ pīle "mortar"
・ disċ "plate/platter/bowel/dish"
・ candel "lamp, lantern, candle"
・ torr "tower"
・ prēost and sācerd "priest"
・ port "harbour"
・ munt "mountain or hill"
このようにラテン借用語のなかには意外と多く「基本語彙」もあることを銘記しておきたい.関連して,基本語彙の各記事も参照.
・ Durkin, Philip. Borrowed Words: A History of Loanwords in English. Oxford: OUP, 2014.
2019-08-09 Fri
■ #3756. アイルランド語からの借用語の年代別分布 [loan_word][irish][celtic][statistics][lexicology]
連日ケルト関係の話題を続けているが,「#3740. ケルト諸語からの借用語」 ([2019-07-24-1]),「#3750. ケルト諸語からの借用語 (2)」 ([2019-08-03-1]),「#3749. ケルト諸語からの借用語に関連する語源学の難しさ」 ([2019-08-02-1]),「#3753. 英仏語におけるケルト借用語の比較・対照」 ([2019-08-06-1]) に引き続き借用語の話題.
Durkin の OED3 を用いた調査によれば,英語に少なからぬ語彙的影響を与えた上位25位の言語のなかで,ケルト系諸語としてはアイルランド語のみがランクインするという.そこで,借用元言語としてアイルランド語にターゲットを絞って,借用語数を年代別にプロットしたのが次のグラフである (Durkin 94) .OED3 の A--ALZ, M--RZ の部分のみを対象とした調査である.
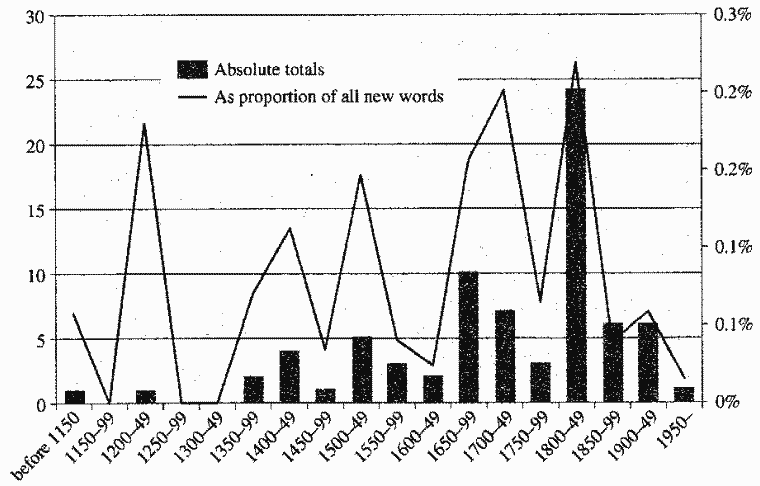
19世紀前半に借用語数のピークが来ているが,同時期の全借用語における割合でみれば0.2%を越える程度であり,著しいわけではない.多少のデコボコはあるにせよ,アイルランド借用語は常に目立たない存在であったことがわかる.考察範囲をケルト諸語全体に広げてみても,事情は変わらないだろう.関連して他の言語からの借用語の分布も比べてもらいたい.
・ 「#114. 初期近代英語の借用語の起源と割合」 ([2009-08-19-1])
・ 「#117. フランス借用語の年代別分布」 ([2009-08-22-1])
・ 「#874. 現代英語の新語におけるソース言語の分布」 ([2011-09-18-1])
・ 「#2162. OED によるフランス語・ラテン語からの借用語の推移」 ([2015-03-29-1])
・ 「#2164. 英語史であまり目立たないドイツ語からの借用」 ([2015-03-31-1])
・ 「#2165. 20世紀後半の借用語ソース」 ([2015-04-01-1])
・ 「#2369. 英語史におけるイタリア語,スペイン語,ポルトガル語からの語彙借用の歴史」 ([2015-10-22-1])
・ 「#2385. OED による,古典語およびロマンス諸語からの借用語彙の統計 (2)」 ([2015-11-07-1])
・ 「#2646. オランダ借用語に関する統計」 ([2016-07-25-1])
・ Durkin, Philip. Borrowed Words: A History of Loanwords in English. Oxford: OUP, 2014.
2018-09-08 Sat
■ #3421. 英語ことわざの文体・語彙的特徴を示す統計値 [proverb][statistics][corpus][stylistics]
「#3419. 英語ことわざのキーワード」 ([2018-09-06-1]) と「#3420. キーワードを含む英語ことわざ」 ([2018-09-07-1]) に引き続き,英語ことわざの話題.安藤邦男(著)『ことわざから探る 英米人の知恵と考え方』の紹介ページより取り出した866件の英語ことわざについて,その文体的・語彙的な特徴を数字で示してみたい.特徴を浮き彫りにするには,英語ことわざコーパスを,より大きな一般的なコーパスと比較する必要があるので,昨日と同様に100万語規模の British English 06 (BE06) を使用した.結果として,次のような基本的な統計値が得られた. * *
| Corpus | Proverbs | BE06 |
|---|---|---|
| tokens (running words) in text | 6,276 | 1,011,020 |
| types (distinct words) | 1,616 | 45,298 |
| type/token ratio (TTR) | 25.75 | 4.48 |
| standardised TTR | 45.25 | 43.90 |
| STTR std.dev. | 46.42 | 54.62 |
| STTR basis | 1,000 | 1,000 |
| mean word length (in characters) | 4.09 | 4.69 |
| word length std.dev. | 1.92 | 2.58 |
| sentences | 869 | 53,466 |
| mean (in words) | 7.22 | 18.91 |
| std.dev. | 2.86 | 14.38 |
| 1-letter words | 292 | 38,775 |
| 2-letter words | 1,020 | 168,273 |
| 3-letter words | 1,345 | 205,211 |
| 4-letter words | 1,370 | 166,961 |
| 5-letter words | 996 | 110,856 |
| 6-letter words | 553 | 88,195 |
| 7-letter words | 359 | 79,174 |
| 8-letter words | 163 | 56,645 |
| 9-letter words | 96 | 39,767 |
| 10-letter words | 53 | 26,170 |
| 11-letter words | 17 | 15,493 |
| 12-letter words | 6 | 8,208 |
| 13-letter words | 4 | 4,557 |
| 14-letter words | 1 | 1,687 |
| 15-letter words | 1 | 623 |
見るべき点として,まず "type/token ratio" を指摘しておこう.この数値が高いほど,コーパス内で異なる語が多く用いられていると解釈できる.純粋に数値を見ると,一般コーパスよりもことわざコーパスのほうが高い値を示しており,語彙が多様であると解釈できそうだが,「#2336. Text Analyser --- 簡易テキスト統計分析器」 ([2015-09-19-1]) で示したように,コーパスサイズが互いに大きく異なるので,この指標単独ではそれほど情報量はない.
"mean word length" と "word length std.dev." は1語当たりの文字数である.両コーパス間の違いはそれほど大きくないが,示唆的ではある.ことわざコーパスのほうが一般コーパスよりも,より短い綴字の単語を好むと解釈できるが,どんなものだろうか.確かに,いたずらに長い単語は一般コーパスよりも出にくいようには感じられる.
最もなるほどと感じさせられるのは,1文がいくつの単語から成り立っているかを示す "mean (in words)" とその "std.dev." だろう.これらの数値もコーパスサイズに依存するとはいえ,ことわざでは平均して7.22語,一般では18.91語というのは,差が歴然としている.標準偏差も合わせて考えると,ことわざを構成する1文は全体的に短いことが分かる.「短く,語呂がよくてなんぼ」というのが,ある意味ではことわざの形式的な特徴でもあるから,この結果はまったく不思議ではないが,こうして客観的に数値を目の当たりにするとおもしろい.
・ 安藤 邦男 『ことわざから探る 英米人の知恵と考え方』 開拓社,2018年.
[ 固定リンク | 印刷用ページ ]
2018-09-06 Thu
■ #3419. 英語ことわざのキーワード [proverb][keyword][statistics][corpus]
今年6月に開拓社より出版された安藤邦男(著)『ことわざから探る 英米人の知恵と考え方』の紹介ページに,同著で言及された英語ことわざの索引や,その他の関連するリストが公開されている.こちらから英語のことわざ866件を取り出し,簡単にキーワード分析してみた. *
一般的な参照コーパスとして,British English 06 (BE06) を指定した.このコーパスについては「#1730. AmE-BrE 2006 Frequency Comparer」 ([2014-01-21-1]) で紹介しているが,端的にいえば2006年(頃)に出版されたイギリス英語の諸テキストからなる100万語規模のコーパスである.計算の結果,キーワード度数の高かった順に50の単語を挙げよう. *
is, makes, good, man, cannot, a, never, you, love, wise, better, thief, devil, ill, than, fool, horse, no, truth, fortune, sweet, adversity, evil, make, shall, travels, friend, every, don't, beauty, knows, not, money, neighbor, speak, words, will, worth, fair, hath, best, blind, deceives, dog, longest, comes, honor, man's, great, bread
上位語には機能語も多く入っているが,ことわざの文体の雰囲気をよく示しているように思われ,興味深い.cannot, never, you, than, no, shall, every, don't, not, hath などは,いかにもことわざと似合う機能語である.
それに劣らず内容語のラインナップもおもしろい.動詞では make, know, deceive というのがいかにもだし,名詞では man, thief, devil, fool, horse, truth, fortune, adversity, evil, friend, beauty, money, neighbor, words, dog, honor, bread など,思わず首肯してしまうものばかりだ.形容詞や副詞では,good, better, best, ill はもちろんのこと,wise, fair, blind, longest などには納得させられる.善悪,真偽,賢愚の対比や比較により,道徳上・生活上の知恵を授けるという英語ことわざの本質が見えてくるようなキーワードだ.
このような文体に関わるキーワード分析は,極めて客観的でありながら,往々にして直観に適う結果が出る(あるいはそれ以上に発見がある)という点でおもしろい.ほかにも,「いかにもなキーワード」シリーズの記事として,「#317. 拙著で自分マイニング(キーワード編)」 ([2010-03-10-1]),「#518. Singapore English のキーワードを抽出」 ([2010-09-27-1]),「#880. いかにもイギリス英語,いかにもアメリカ英語の単語」 ([2011-09-24-1]),「#2332. EEBO のキーワードを抽出」 ([2015-09-15-1]) を参照.歴史英語の通時的なキーワード分析については,初期中英語コーパス LAEME を利用した Hotta (2013) 論文もある.
・ 安藤 邦男 『ことわざから探る 英米人の知恵と考え方』 開拓社,2018年.
・ Hotta, Ryuichi. "Representativeness, Word Frequency, and Keywords in the LAEME Corpus." Journal of the Faculty of Letters: Language, Literature and Culture 112 (2013): 67--84.
2018-08-18 Sat
■ #3400. 英語の中核語彙に借用語がどれだけ入り込んでいるか? [loan_word][borrowing][lexicology][semantics][oed][htoed][statistics]
英語語彙における借用語の割合が高いことは,本ブログの多くの記事で取り上げてきた.この事実に関してとりわけ注目すべき質的な特徴として,借用語が基本語彙にまで入り込んできているという点が挙げられる(例えば「#2625. 古ノルド語からの借用語の日常性」 ([2016-07-04-1]) を参照).諸言語の比較研究によれば,借用語が基本語彙に入り込むという事例は,非常に稀かといえばそうでもなく,ある程度は観察されるのも事実であり,従来しばしば指摘されてきたように,英語がきわめて特異であると評価することはもはやできない.とはいえ,そのような事例が通言語的には "unusual" (Durkin 391) であるというのも傾向としては確かである.
Durkin は,標記の問いに答えるべく OED と HTOED を用いて実証的な調査を行なった.まず,'Leipzig-Jakarta list of basic vocabulary' と呼ばれる通言語的に有効とされる基本語彙のリストを参照し,そこから100の核心的な意味を取り出す.次に,その各々の意味が,英語語彙史においてどのような単語(群)によって担われてきたかを両辞書によって同定し,その単語の語源情報(借用語か否かなどの詳細)を記録・整理していく.そして,現在,借用語が100の核心的な意味のどれくらいをカバーしているのかを割り出す.その結果は,Durkin (392) によれば次の通り.
To summarize the results of this exercise very briefly . . ., looking in detail at the 100-meaning 'Leipzig-Jakarta list of basic vocabulary' in this way suggests that, while only twenty-two of these meanings appear never to have been realized by a loanword in the data of the OED as summarized in the HTOED, there are only twelve cases where a good case can be made for a loanword being the usual realization of the relevant core meaning in contemporary English:
(from early Scandinavian): root, wing, hit, leg, egg, give, skin, take; (from French): carry, soil, cry, (probably) crush
見方を変えれば,100の核心的な意味のうち78までが,部分的であれ何らかの借用語によって担われているということだ.ここから,借用語が幅広く核心的な意味領域を覆っているということが分かる.しかし,その借用語が,そのような核心的な意味領域を表わす単語群のなかでも典型的・代表的な語であるかどうかは別問題であり,そのような数え方をすると,上記の12語ほどに限定されるということだ.
もっとも,語彙や意味について何をもって「核心」や「基本」とみなすのかは難しい問題であり,それによって結果の数値も変わり得ることはいうまでもない.この問題その他について,以下のような記事で様々に取り上げてきたので参照を.
・ 「#1128. glottochronology」 ([2012-05-29-1])
・ 「#1961. 基本レベル範疇」 ([2014-09-09-1])
・ 「#1965. 普遍的な語彙素」 ([2014-09-13-1])
・ 「#1970. 多義性と頻度の相関関係」 ([2014-09-18-1])
・ 「#2659. glottochronology と lexicostatistics」 ([2016-08-07-1])
・ 「#2660. glottochronology と基本語彙」 ([2016-08-08-1])
・ 「#2661. Swadesh (1952) の選んだ言語年代学用の200語」 ([2016-08-09-1])
・ 「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1])
・ 「#202. 現代英語の基本語彙600語の起源と割合」 ([2009-11-15-1])
・ 「#429. 現代英語の最頻語彙10000語の起源と割合」 ([2010-06-30-1])
・ 「#845. 現代英語の語彙の起源と割合」 ([2011-08-20-1])
・ 「#1202. 現代英語の語彙の起源と割合 (2)」 ([2012-08-11-1])
・ Durkin, Philip. "The OED and HTOED as Tools in Practical Research: A Test Case Examining the Impact of Loanwords in Areas of the Core Lexicon." The Cambridge Handbook of English Historical Linguistics. Ed. Merja Kytö and Päivi Pahta. Cambridge: CUP, 2016. 390--407.
2018-07-21 Sat
■ #3372. 古英語と中英語の資料の制約について数点のメモ [oe][me][philology][manuscript][statistics][representativeness][methodology][evidence]
「#1264. 歴史言語学の限界と,その克服への道」 ([2012-10-12-1]),「#2865. 生き残りやすい言語証拠,消えやすい言語証拠――化石生成学からのヒント」 ([2017-03-01-1]) で取り上げてきたが,歴史言語学には資料の限界という,いかんともしがたい問題がある.質量ともに望むほどのものが残っていてくれないのが現実である.児馬 (29) は,『歴史言語学』のなかの「古英語資料の留意点:量的・質的制約」という節において次のように述べている.
歴史言語学では現存する資料が最重要であることはいうまでもない.現代の言語を研究対象とするのであれば,文字資料・録音資料に加えて,話者の言語直観・内省などの言語心理学的資料も含めて実に豊富な資料を使えるのであるが,歴史言語学ではそうは簡単にならない.古い時代の資料を使うことが多い分野なので,この種の限界は当然のように思えるが,実際は,想像以上に厳しい制約があるのを認識しなければならない.特に扱う資料が古ければ古いほど厳しいものがあり,英語史では,特にOE資料の限界についてはよく認識したうえで,研究を進めていかなくてはならない.
具体的にどれくらいの制約があるのかを垣間見るために,古英語と中英語の資料について児馬が触れている箇所を数点メモしておこう.
・ 古英語期の写本に含まれる語数は約300万語で,文献数は約2000である.部分的にはヴァイキングによる破壊が原因である.この量はノルマン征服以降の約200年間に書かれた中英語の資料よりも少ない.(29)
・ とくに850年以前の資料で残っているものは,4つのテキストと35ほどの法律文書・勅許上などの短い公的文書が大半である.(29)
・ 古英語資料の9割がウェストサクソン方言で書かれた資料である.(31)
・ 自筆資料 (authorial holograph) は非常に珍しく,中英語期でも Ayenbite of Inwit (1340年頃),詩人 Hoccleve (1370?--1450?) の書き物,15世紀ノーフォークの貴族の手による書簡集 Paston Letters やその他の同時期の書簡集ほどである.(34)
英語史における資料の問題は非常に大きい.文献学 (philology) や本文批評 (textual criticism) からのアプローチがこの分野で重要視される所以である.
関連して「#1264. 歴史言語学の限界と,その克服への道」 ([2012-10-12-1]),「#2865. 生き残りやすい言語証拠,消えやすい言語証拠――化石生成学からのヒント」 ([2017-03-01-1]),「#1051. 英語史研究の対象となる資料 (1)」 ([2012-03-13-1]),「#1052. 英語史研究の対象となる資料 (2)」 ([2012-03-14-1]) も参照.
・ 児馬 修 「第2章 英語史概観」服部 義弘・児馬 修(編)『歴史言語学』朝倉日英対照言語学シリーズ[発展編]3 朝倉書店,2018年.22--46頁.
2018-03-30 Fri
■ #3259. 17世紀に作られた動詞派生名詞群の呈する問題 (2) [synonym][loan_word][borrowing][renaissance][inkhorn_term][emode][lexicology][word_formation][suffix][affixation][neologism][derivation][statistics]
昨日の記事 ([2018-03-29-1]) の続編.昨日示した Bauer からの動詞派生名詞のリストでは,-ment や -ure の接尾辞の存在が目立っていた.17世紀の名詞を作る接尾辞にどのような種類のものがあり,それぞれがいくつの名詞を作っていたのだろうか.これについても,Bauer (185) が OED に基づいて統計をとっている.結果は以下の通り.
| Suffix | Number |
| -y | 2 |
| -ery | 8 |
| -ancy | 10 |
| -ency | 10 |
| -ence | 18 |
| -ion | 20 |
| -ance | 49 |
| -al | 56 |
| -ure | 96 |
| -ation | 190 |
| -ment | 258 |
トップ数種類の接尾辞が大半をカバーしていることから,頻度の高い「典型的な」接尾辞があることは確かにわかる.しかし,典型的な接尾辞が少数あるということで,問題が解決することにはならない.これらの典型的な接尾辞を含めた複数種類の接尾辞が,同一の基体に接続し得たということ,そして実際にそのように造語され併用されたという状況こそが,問題だったである.
昨日の記事で触れたように,Bauer はこの問題を新語のニーズに関わる複雑さに帰しているが,それと関連して,生産的な派生に対して非生産的な派生への需要も常に存在するものだという主張を展開している.
. . . there is a constant application of unproductive morphology in order to solve problems provided by productive morphology, so that the language is continually having new words added to it which are not the forms which would be the predicted ones, as well as a number of predicted forms. That is, the processes of history add irregularities (which are available to turn into regularities if enough of them are coined). History, rather than simplifying matters (or rather than merely simplifying matters), reflects a process of building in extra complications.
言語使用者の新語への要求は,必ずしも生産的な派生が与えてくれる手段とその結果だけでは満たされないほどに複雑で精妙なのだろう.そこで,あえて非生産的な派生の手段を用いて,不規則な派生語を作り出すこともあるのかもしれない.現代の歴史言語学者は,過去に生きた言語使用者の,そのような複雑で精妙な造語心理にどこまで迫れるのだろうか.困難ではあるがエキサイティングなテーマである.
・ Bauer, Laurie. "Competition in English Word Formation." Chapter 8 of The Handbook of the History of English. Ed. Ans van Kemenade and Bettelou Los. Malden, MA: Blackwell, 2006. 177--98.
2018-02-15 Thu
■ #3216. ドーキンスと言語変化論 (2) [glottochronology][evolution][biology][language_change][comparative_linguistics][history_of_linguistics][speed_of_change][statistics]
昨日の記事 ([2018-02-14-1]) に引き続き,ドーキンスの『盲目の時計職人』で言語について言及している箇所に注目する.今回は,ドーキンスが,言語の分岐と分類について,生物の場合との異同を指摘しながら論じている部分を取りあげよう (348--49) .
言語は何らかの傾向を示し,分岐し,そして分岐してから何世紀か経つにつれて,だんだんと相互に理解できなくなってしまうので,あきらかに進化すると言える.太平洋に浮かぶ多くの島々は,言語進化の研究のための格好の材料を提供している.異なる島の言語はあきらかに似通っており,島のあいだで違っている単語の数によってそれらがどれだけ違っているかを正確に測ることができよう.この物差しは,〔中略〕分子分類学の物差しとたいへんよく似ている.分岐した単語の数で測られる言語間の違いは,マイル数で測られる島間の距離に対してグラフ上のプロットされうる.グラフ上にプロットされた点はある曲線を描き,その曲線が数学的にどんな形をしているかによって,島から島へ(単語)が拡散していく速度について何ごとかがわかるはずだ.単語はカヌーによって移動し,当の島と島とがどの程度離れているかによってそれに比例した間隔で島に跳び移っていくだろう.一つの島のなかでは,遺伝子がときおり突然変異を起こすのとほとんと同じようにして,単語は一定の速度で変化する.もしある島が完全に隔離されていれば,その島の言語は時間が経つにつれて何らかの進化的な変化を示し,したがって他の島の言語からなにがしか分岐していくだろう.近くにある島どうしは,遠くにある島どうしに比べて,カヌーによる単語の交流速度があきらかに速い.またそれらの島の言語は,遠く離れた島の言語よりも新しい共通の祖先をもっている.こうした現象は,あちこちの島のあいだで観察される類似性のパターンを説明するものであり,もとはと言えばチャールズ・ダーウィンにインスピレーションを与えた,ガラパゴス諸島の異なった島にいるフィンチに関する事実と密接なアナロジーが成り立つ.ちょうど単語がカヌーによって島から島へ跳び移っていくように,遺伝子は鳥の体によって島から島へ跳び移っていく.
実際,太平洋の島々の諸言語間の関係を探るのに,統計的な手法を用いる研究は盛んである.太平洋から離れて印欧語族の研究を覗いても,ときに数学的な手法が適用されてきた(「#1129. 印欧祖語の分岐は紀元前5800--7800年?」 ([2012-05-30-1]) を参照).Swadesh による言語年代学も,おおいに批判を受けてきたものの,その洞察の魅力は完全には失われていないように見受けられる(「#1128. glottochronology」 ([2012-05-29-1]) や glottochronology の各記事を参照).近年のコーパス言語学の発展やコンピュータの計算力の向上により,語彙統計学 (lexicostatistics) という分野も育ってきている.生物学の方法論を言語学にも応用するというドーキンスの発想は,素直でもあるし,実際にいくつかの方法で応用されてきてもいるのである.
関連して,もう1箇所,ドーキンスが同著内で言語の分岐を生物の分岐になぞらえている箇所がある.しかしそこでは,言語は分岐するだけではなく混合することもあるという点で,生物と著しく相違すると指摘している (412) .
言語は分岐するだけではなく,混じり合ってしまうこともある.英語は,はるか以前に分岐したゲルマン語とロマンス語の雑種であり,したがってどのような階層的な入れ子の図式にもきっちり収まってくれない.英語を囲む輪はどこかで交差したり,部分的に重複したりすることがわかるだろう.生物学的分類の輪の方は,絶対にそのように交差したりしない.主のレベル以上の生物進化はつねに分岐する一方だからである.
生物には混合はあり得ないという主張だが,生物進化において,もともと原核細胞だったミトコンドリアや葉緑体が共生化して真核細胞が生じたとする共生説が唱えられていることに注意しておきたい.これは諸言語の混合に比較される現象かもしれない.
・ ドーキンス,リチャード(著),中嶋 康裕・遠藤 彰・遠藤 知二・疋田 努(訳),日高 敏隆(監修) 『盲目の時計職人 自然淘汰は偶然か?』 早川書房,2004年.
2018-01-10 Wed
■ #3180. 徐々に高頻度語の仲間入りを果たしてきたフランス・ラテン借用語 [french][latin][loan_word][borrowing][frequency][statistics][lexicology][hc][bnc]
英語史では,中英語から初期近代英語にかけて,フランス語とラテン語から大量の語彙借用がなされた.それらのうち現在常用されるものについては,おそらく借用時点からスタートして時間とともに使用頻度が増してきたものと想像される.というのは,借用された当初から高頻度で用いられたとは考えにくく,徐々に英語に同化し,日常化してきたととらえるのが自然だからだ.
この仮説を実証するのにいくつかの方法がありそうだが,Durkin があるやり方で調査を行なっている.中英語,初期近代英語,現代英語のそれぞれにおいてコーパスに基づく最高頻度語リストを作り,そのなかにフランス・ラテン借用語がどのくらいの割合で含まれているかを調べ,その割合の通時的推移を比較するという手法だ.古い時代のコーパスでは綴字の変異という問題が関わるため,厳密に調査しようとすれば単純にはいかないが,Durkin はとりあえずの便法として,中英語と初期近代英語については Helsinki Corpus の 1150--1500年と1500--1710年のセクションを用いて,現代英語については BNC を用いて異綴字ベースで調査した.それぞれ頻度ランキングにして900--1000位ほどまでの単語(綴字)リストを作り,そのなかでフランス・ラテン語借用語が占める割合をはじき出した.
結果は,中英語セクションでは7%ほどだったものが,初期近代英語セクションでは19%まで上昇し,さらに現代英語セクションでは38%までに至っている.粗い調査であることは認めつつも,フランス・ラテン借用語で現在頻用されているものの多くについては,歴史のなかで徐々に頻度を上げてきた結果として,現在の日常的な性格を示すことがよくわかった.
さらにおもしろいことに,初期近代英語のセクション(1500--1710年)に関する数値について,高頻度語リストに含まれるフランス・ラテン借用語のすべてが1500年より前に借用されたものであり,しかもその2/3ほどは確実にフランス借用語であるという事実が確認される (Durkin 338--39) .
また,中英語と初期近代英語の高頻度語リストに含まれるフランス・ラテン借用語の多くが,現代英語の高頻度語リストにも再現されている事実にも触れておこう.古い2期には現われるが現代期からは漏れている語群を眺めると,なんとも時代の変化を感じさせてくれる.例えば,honour, justice, manner, noble, parliament, pray, prince, realm, religion, supper, treason, usury, virtue である (Durkin 340) .
時代によって最頻語リストやキーワードが異なることは当然といえば当然だが,歴史英語コーパスを用いて様々な時代を比較してみるとおもしろそうだ.例えば,初期近代英語コーパスに基づくキーワード・リストについて「#2332. EEBO のキーワードを抽出」 ([2015-09-15-1]) を参照.また,頻度と歴史の問題については「#1243. 語の頻度を考慮する通時的研究のために」 ([2012-09-21-1]) も参照されたい.
・ Durkin, Philip. Borrowed Words: A History of Loanwords in English. Oxford: OUP, 2014.
2018-01-04 Thu
■ #3174. 高頻度語はスペリングが短い (2) [frequency][spelling][orthography][zipfs_law][statistics][lexicology][corpus]
昨日の記事 ([2018-01-03-1]) と同じ頻度とスペリングの長さに関するデータを,もう少し分析してみた.以下は,頻度ランキングのトップ100語,200語,500語,1000語,2000語,5000語,10000語,20000語,50000語について,それぞれ最低値,第1四分位数,中央値,平均値,第3四分位数,最大値を示した表である.英語の正書法を論じる上での基礎データとしてどうぞ.
| Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. | |
|---|---|---|---|---|---|---|
| Top_100 | 1.0 | 2.0 | 3.0 | 3.1 | 4.0 | 5.0 |
| Top_200 | 1.00 | 3.00 | 4.00 | 3.77 | 4.00 | 10.00 |
| Top_500 | 1.000 | 4.000 | 4.000 | 4.498 | 5.000 | 10.000 |
| Top_1K | 1.000 | 4.000 | 5.000 | 4.968 | 6.000 | 15.000 |
| Top_2K | 1.000 | 4.000 | 5.000 | 5.406 | 7.000 | 15.000 |
| Top_5K | 1.000 | 5.000 | 6.000 | 6.014 | 7.000 | 16.000 |
| Top_10K | 1.000 | 5.000 | 6.000 | 6.488 | 8.000 | 16.000 |
| Top_20K | 1.000 | 5.000 | 7.000 | 6.954 | 8.000 | 17.000 |
| Top_50K | 1.000 | 6.000 | 7.000 | 7.622 | 9.000 | 20.000 |
これをもとに視覚化したのが,以下の箱ひげ図.
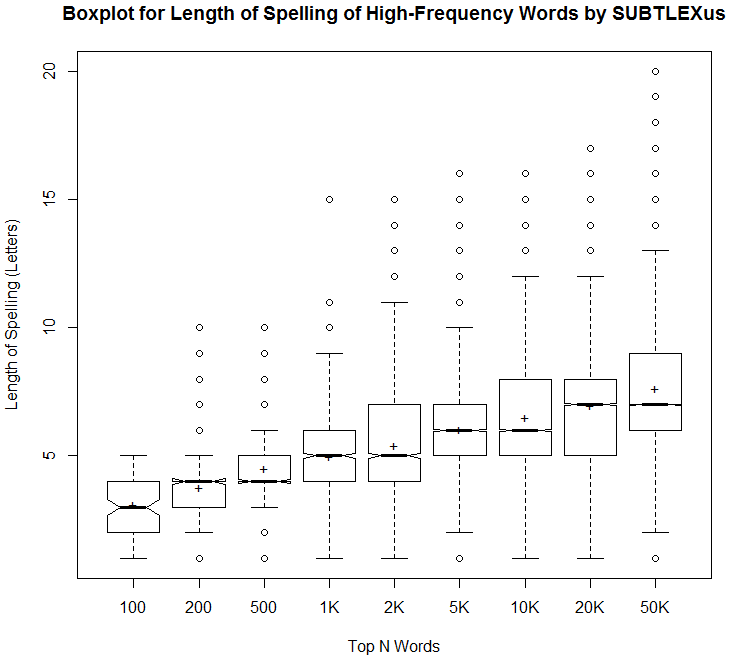
当然予想されたことだが,語数が増えるにしたがってスペリングの平均の長さは徐々に大きくなっていき,バラツキも広がっていく.しかし,トップ数万語でみても平均して7文字程度となっており,さほど長くないのだなという印象を受けた.
[ 固定リンク | 印刷用ページ ]
2018-01-03 Wed
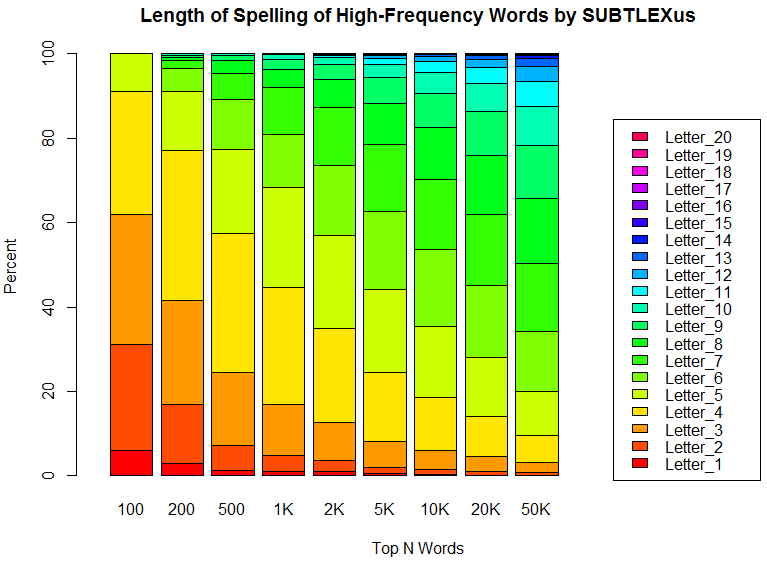
■ #3173. 高頻度語はスペリングが短い (1) [frequency][spelling][orthography][zipfs_law][statistics][lexicology][corpus][three-letter_rule]
標題は特に目新しい指摘ではなく,英語を読み書きする者には直感されていることだと思われる.「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]) や「#1102. Zipf's law と語の新陳代謝」 ([2012-05-03-1]) でも指摘したように,よく読み書きする単語のスペリングは短いほうが効率がよいと考えられるからだ.逆に,滅多に読み書きしない単語であれば少々長くても我慢できる.単語のスペリングに限らず,単語の音形についても同様の原理が作用していると思われる.
また,英語の正書法には内容語は3文字以上で綴られなければならないという「#2235. 3文字規則」 ([2015-06-10-1]) がある.これは機能語という頻度のきわめて高い語類については適用されない.したがって,この規則は上記の効率の問題とも関わる実用的な側面をもつといえる.
高頻度語であればあるほど,そのスペリングが平均的に短いことを示す方法の1つに,頻度ランキングのトップ100語,1000語,10000語などのリストに基づき,文字数別に単語を数え上げるというやり方がある.「#2096. SUBTLEX-US Word Frequency List」 ([2015-01-22-1]) から引き出した頻度ランキングを利用して,トップ100語,200語,500語,1000語,2000語,5000語,10000語,20000語,50000語について調査した.トップ100語のリストについては先の記事でリストを掲載している通りであり,なかには s, ll などコーパスの仕様に由来するとおぼしき怪しい「語」もあるが,結果の大勢には影響を及ぼさないだろう.
以下にグラフで整理した通り,結果は明白である(数値データはソースHTMLを参照).トップ100語の超高頻度語群では62.00%までが3文字以下のスペリングである.3文字以下の割合(下から3つ分のオレンジの帯まで)ということで比べていくと,トップ200語から50000語の調査結果まで,順に41.50%, 24.60%, 17.00%, 12.65%, 8.06%, 6.01%, 4.55%, 3.20%と目減りしていく.
2017-12-31 Sun
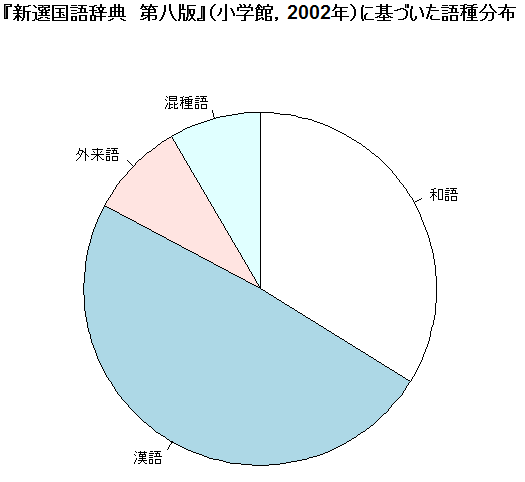
■ #3170. 現代日本語の語種分布 (2) [japanese][lexicology][statistics][etymology][loan_word][lexical_stratification]
「#1645. 現代日本語の語種分布」 ([2013-10-28-1]) の記事で,標題について明治から昭和にかけて出版された国語辞典に基づく数値を示した.今回は平成からの数値を示そう.沖森ほか (71) に掲載されている,『新選国語辞典 第八版』(小学館,2002年)に基づいた語種分布である.
|
|
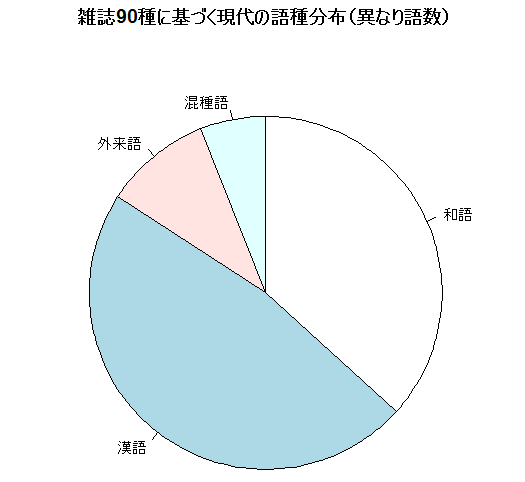
先の記事 ([2013-10-28-1]) で参照した,国立国語研究所『語彙の研究と教育(上)』(大蔵省印刷局,1984年)の雑誌90種に基づく異なり語数と延べ語数の統計も,改めて円グラフにして示そう(こちらも沖森ほか (79) 経由で).
|
|
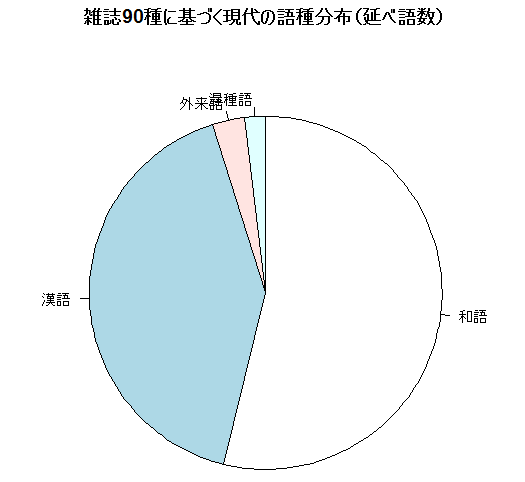
|
|
・ 沖森 卓也,木村 義之,陳 力衛,山本 真吾 『図解日本語』 三省堂,2006年.
[ 固定リンク | 印刷用ページ ]
Powered by WinChalow1.0rc4 based on chalow