2012-10-27 Sat
■ #1279. BNC の強みと弱み [bnc][corpus][representativeness]
10月8--11日の4日間にわたり,立教大学英語教育研究所による主催で,Lancaster 大学名誉教授 Geoffrey Leech の公開講演会が開かれた.私は,2日目の "The British National Corpus: Both a Triumph and a Failure" と題する講演のみの参加だったが,聴きに行った.BNC 編者じきじきの作成秘話など,おもしろい話しが何点かあった.
題名にある "triumph" と "failure" について,Leech はそれぞれ次のような項目を列挙していた.
A triumph:
・ It has been claimed that the BNC is the most widely used corpus in the world.
・ It was the first text corpus of its size to be made widely available.
・ It is available from a wide range of different sources.
・ It is widely regarded as a 'standard reference corpus' for the English language.
・ It has been licensed to over 1300 institutions throughout the world, over 1800 users have signed on for access to it through the BNCweb online interface, etc.
A failure:
・ It never reached 100 million words! (98,300,000)
・ The design criteria were never totally achieved.
・ It hardly ever contains complete texts.
・ The spoken materials are poorly transcribed.
・ The metadata are incomplete and can be erroneous.
・ The part-of-speech tagging contains many errors.
・ It is out of date! (dating from the late 20th century)
Leech の言葉の端々には,triumph の各点に示されているように,実績に裏付けされた自信がみなぎっていた.一方,自らのコーパス編集について,こうすればよかった,ああすればよかったという類の後悔ともいえる反省点を多く挙げていたのが印象的である.BNC のタグ付けに用いられたプログラム CLAWS4 の精度が97%ほどある(Hoffmann et al. 43 によると,98--99%)というのは,私は驚くべきことだと思っていたが,コーパス規模が大きいので数パーセントのエラーとはいっても約300万件にのぼるという事実は見落としていた.話しことばコーパスについては,コーパス全体の1割ほどしか含められなかったこと,音声データの transcription の質が悪かったこと,当初採用したデータフォーマット TEI が,話しことばのタグ付けには必ずしも適切でなかったこと,などを挙げていた.
なかでも,企画段階から現在に至るまで一貫してこだわり続けている代表性 (representativeness) について,BNC では完全に目的を果たせなかったことに,後悔をにじませていた.企画段階から,設定する Text Domain のバランスやサイズに関する議論が重ねられてきたことはよく知られている.1ユーザーとしては,限られたリソースのなかで,あれだけの代表性を確保したことは偉業だと評価しているが,Leech にとっては,できる限りのことはやったという自負の反面として,理想が果たせなかったという思いも強いようだ.同時に,穏やかな口調ではあったが,BNC と比較される他のすべての大規模コーパスが,代表性をさほど重視していない点を批判していた.ただし,彼自身が述べているように,コーパスの代表性について独自の理論はもっているが,最終的には "impressionistic" な判断の問題だと考えているようであり,この問題の難しさをにじませていた.いずれにせよ,Leech の代表性への執念の強さに,高度なプロフェッショナリズムを感じた.
なお,[2012-07-05-1]の記事「#1165. 英国でコーパス研究が盛んになった背景」で触れた通り,残念ながらBNCの続編はないだろうということを,Leech は明言していた.
扱う時代は大きく異なるが,初期中英語コーパス The LAEME Corpus の代表性の問題について,[2012-10-10-1], [2012-10-11-1]の記事で考察したので,ご参照を.
・ Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee, and Ylva Berglund Prytz. Corpus Linguistics with BNCweb : A Practical Guide. Frankfurt am Main: Peter Lang, 2008.
2012-10-26 Fri
■ #1278. BNC を中心とするコーパス研究関連のリンク集 [corpus][bnc][link][web_service][lltest]
コーパス言語学の勢いが止まらない.分野が分野だけに,関連情報はウェブ上で得られることが多く,便利なようにも思えるが,逆に情報が多すぎて,選択と判断に困る.せめて自分のためだけでも便利なリンク集をまとめておこうと思うのだが,学界のスピードについて行けない.私が最もよく用いる BNC に関連するものを中心に,断片的ではあるが,リンクを張る.リンク集をまとめる労を執るよりは,芋づる式にたどるかキーワード検索のほうが効率的という状況になりつつある・・・.
1. BNC インターフェース
・ BNCweb (要無料登録)
・ BYU-BNC (要無料登録)
・ BNC ( The British National Corpus )
2. BNC のレファレンス・ガイド
・ Quick Reference for Simple Query Syntax (PDF)
・ Reference Guide for the British National Corpus (XML Edition)
・ 上の Reference Guide の目次
* 6.5 Guidelines to the Wordclass Tagging
* The BNC Basic (C5) Tagset
* 9.8 Simplified Wordclass Tags
* 9.7 Contracted forms and multiwords
* 1 Design of the Corpus
* 9.6 Text and genre classification code
3. コーパス関連の総合サイト
・ David Lee による Bookmarks for Corpus-based Linguists
* Corpora, Collections, Data Archives
* Software, Tools, Frequency Lists, etc.
* References, Papers, Journals
* Conferences & Project
4. hellog 内の記事
・ 「#568. コーパスの定義と英語コーパス入門」: [2010-11-16-1]
・ 「#506. CoRD --- 英語歴史コーパスの情報センター」: [2010-09-15-1]
・ 「#308. 現代英語の最頻英単語リスト」: [2010-03-01-1]
・ コーパス関連記事: corpus
・ BNC 関連記事: bnc
・ COCA 関連記事: coca
5. 計算ツール
・ Corpus Frequency Wizard
・ Paul Rayson's Log-likelihood Calculator
・ VassarStats
・ hellog の「#711. Log-Likelihood Tester CGI, Ver. 2」: [2011-04-08-1]
・ Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee, and Ylva Berglund Prytz. Corpus Linguistics with BNCweb : A Practical Guide. Frankfurt am Main: Peter Lang, 2008.
2012-10-24 Wed
■ #1276. hereby, hereof, thereto, therewith, etc. [compounding][synthesis_to_analysis][adverb][register][corpus][bnc][hc]
標題のような here や there を第1要素とし,前置詞を第2要素とする複合副詞は多数ある.これらは,here を this と,there を it や that と読み替えて,それを前置詞の後ろに回した句と意味的に等しく,標題の語はそれぞれ by this, of this, to that, with that ほどを意味する.現代では非常に形式張った響きがあるが,古英語から初期近代英語にかけてはよく使用され,その種類や頻度はむしろ増えていたほどである.だが,17世紀以降は急激に減ってゆき,現代のような限られた使用域 (register) へと追い込まれた.衰退の理由としては,英語の構造として典型的でないという点,つまり総合から分析への英語の自然な流れに反するという点が指摘されている (Rissanen 127) .文法化した語として,現代まで固定された状態で受け継がれた語は,therefore のみといってよいだろう.
現代英語で確認される使用域の偏りは,すでに中英語にも萌芽が見られる.here-, there- 複合語は,後期中英語ではいまだ普通に使われているが,ジャンルでみると法律文書での使用が際だっている.以下は,Rissanen (127) の Helsinki Corpus による調査結果である(数字は頻度,カッコ内の数字は1万語当たりの頻度を表わす).
| Statutes | Other texts | |
|---|---|---|
| ME4 (1420--1500) | 68 (60) | 621 (31) |
| EModE1 (1500--70) | 77 (65) | 503 (28) |
| EModE2 (1570--1640) | 84 (71) | 461 (26) |
| EModE3 (1640--1710) | 126 (96) | 191 (12) |
初期近代英語のあいだ,一般には問題の複合語の頻度は落ちているが,法律文書においては token 頻度が(そして,Rissanen, p. 128 によれば type 頻度も)増加していることに注意されたい.後の時代でも,法律文書における使用は続き,現代に至る.
現代の分布については,独自に BNCweb で調べてみた.therefore を除く,hereabout, hereabouts, hereafter, hereby, herein, hereinafter, hereof, hereto, heretofore, hereupon, herewith, thereabout, thereabouts, thereafter, thereby, therefrom, therein, thereinafter, thereof, thereon, thereto, theretofore, thereunder, thereupon, therewith の25語について,Written Corpus に絞った上で,CQP syntax にて 「"(hereabout|hereabouts|hereafter|hereby|herein|hereinafter|hereof|hereto|heretofore|hereupon|herewith|thereabout|thereabouts|thereafter|thereby|therefrom|therein|thereinafter|thereof|thereon|thereto|theretofore|thereunder|thereupon|therewith)" %c」と検索した.出現頻度は 68.93 wpm で,散らばり具合は3140テキスト中の1522テキストである.
次に,法律関係の文書を最も多く含んでいると想定されるジャンルとして「W:ac:polit_law_edu」に絞り,同じ検索式で結果を見ると,231.33 wpm で,186テキスト中の153テキストに出現する.なお,「W:admin」に絞ると,コーパスサイズはずっと小さくなるが,頻度は439.85 wpm となり,最頻出ジャンルであることがわかる.いずれにせよ,この種のジャンルで here-, there- 複合語が今なお頻繁に用いられていることは確かめられた.
・ Rissanen, Matti. "Standardisation and the Language of Early Statutes." The Development of Standard English, 1300--1800. Ed. Laura Wright. Cambridge: CUP, 2000. 117--30.
2012-05-06 Sun
■ #1105. 美女の形容としての grey eyes (2) [romance][adjective][collocation][bnc][corpus]
昨日の記事[2012-05-05-1]に引き続き grey eyes の話題.昨日は,中英語ロマンスの grey eyes について考えたが,この共起表現は現代にも続いている.BNCWeb で,"(grey|gray) {eye/N}" として検索すると,287例がヒットした.grey eyes がさらに別の形容詞に先行されている例をみると,clear, dark, deep, pale が比較的多い.beautiful や bright の例もわずかながらあった.
このような例から判断すると,grey 自体は輝きの有無を表わす意味を担当していないように思われる.もし担当しているとすれば,むしろ pale 寄りの「薄い,輝きのない」という解釈に引き寄せられるだろう.英英辞書で確認する限り,現代英語の grey の一般的な語感は,日本語のそれとよく似て,negative だからだ.老年,陰気,病気,憂鬱,退屈,悪天候のイメージだ.したがって,現代英語の grey eyes は,negative なニュアンスを特に含意しない読みを求めるとするならば,純粋に色としての「灰色」あるいは「青みのいくぶん混じった灰色」を表わすものと考えられる.あるいは,grey eyes は,意味の薄まった共起表現の伝統として用いられているにすぎないという可能性もあるかもしれない.
すると,ますます中英語の美女の典型的な描写としての grey eyes がわからない.もし,MED や Silverstein が述べている通り,中英語の grey が輝きを表わしたのだとすれば,現代英語の輝きのない grey は180度の意味変化を経たことになる.
色は gradation を描くものであり,かつて覆っていた範囲や意味を推定して復元することは,なかなか難しい.英語のみならず日本語においても,色彩語を巡る議論は厄介である.
なお,中世の美女の典型的な描写を示しておこう.Brewer (258) は,Matthew of Vandôme による Helen of Troy の描写が,以下の要約の通り,1つの型であるとしている.
. . . her hair is golden, forehead white as paper, eyebrows black and thin. The space between the eyes (in contrast to the Greek ideal) is white and clear, a 'milky way'; the face is a shining star; the eyes are like stars. She has a little smile, a nose neither too big nor too small. Her face is rosy, her colouring white and red, like rose and snow. Teeth are like ivory, lips are small, slightly swelling, honeyed. Her mouth smells like a rose, her neck is smooth, shoulders radiant, well-spaced (dispatiati), breasts small, and figure incomparable.
こんな女性,いるんでしょうか,ぜひ会ってみたい・・・.
・ Silverstein, Theodore, ed. Sir Gawain and the Green Knight. Chicago: U of Chicago P, 1983.
・ Brewer, D. S. "The Ideal of Feminine Beauty in Medieval Literature, Especially 'Harley Lyrics', Chaucer, and Some Elizabethans." The Modern Language Review 50 (1955): 257--69.
2012-04-19 Thu
■ #1088. lingua franca (3) [elf][model_of_englishes][global_language][bnc]
この2日間の記事[2012-04-17-1], [2012-04-18-1]に引き続き,lingua franca という語の意味と用法についての話題.昨日は主に辞書の定義を参考にしたが,今日はコーパスに現われる用例から lingua franca の現行の意味に迫りたい.
BNCWeb で "lingua franca" を単純検索すると,34例がヒットした.KWIC出力を眺めてみると,英語が主題となっている例文は予想されるほど多くない.ピジン英語などを含めると英語のシェアが相対的に高いことは認めるにせよ,ラテン語,ギリシア語,フランス語,スワヒリ語などの諸言語に関する例文も決して少なくない.昨日は学習者用英英辞書が,lingua franca の例文において英語びいきであることを見たが,現行の lingua franca の使用では,そのような英語へのバイアスは特にないことが,コーパスの例から明らかだろう.また,lingua franca に対して「世界語」という訳をつけることが不適切であることも,改めて理解できるだろう.
コーパス検索からは,次のように比喩的で広義の「意思伝達の役割を果たすもの」の用例も見られた.
・ Mr Tsurumaki was successful at 315 million francs, generally translated into lingua franca dollars at $51.4 million.
・ . . . the user has to resort to good old ASCII, the lingua franca of all computer systems . . . .
このように専門語から一般語への転身も着実に進んでいるようである.語の意味が広く一般的になるということは,それが本来もっていた意味上の区別を失うということである.この種の意味変化は日常茶飯事であり,言語学的には非難の対象とも推奨の対象ともならない.しかし,専門用語としての lingua franca のもつ繊細な含蓄は保つ価値があるように思う.それは,昨日も指摘した,lingua franca の「母語話者のイメージを喚起しない」性質である.ELF (English as a Lingua Franca) に,母語話者は関わってこない.一方で,母語話者の参加の有無にかわかわらず国際的に用いられる共通語としての英語を話題にするには EIL (English as an International Language) という用語がより適切だろうし,これらすべてを超越する用語として (English as a) Global Language という用語も頻繁に聞かれるようになってきた.
厳密さを要しない一般的な文脈で現在の英語の地位に言及する場合には,lingua franca も global language も大差なく使われているように思われるが,上記のように,両者の区別はつけておくのがよいと考える.母語話者の不関与を押し出す lingua franca と,母語話者の関与・不関与を超越する global language ―――この対立には,単なる定義上の区別のみならず,背景にある英語観の違い,英語の役割のどの側面に力点を置くかの違いが反映されているように思われる.
2012-03-30 Fri
■ #1068. choose between war or peace [conjunction][corpus][bnc][preposition]
ある英文を読んでいて,the choice is between rhyme or prose という句に出くわした.between には等位接続詞 and が期待されるところだが,choice の語感に引きずられて or が使用されているものらしい.ジーニアス大辞典では,この用法について以下のように触れられている.
1(3) between 1980 to 1990 や choose between war or peace のように and の代りに to や or を用いるのは((まれ)).to は from A to Bの類推.or はchoose, decide などの動詞と連語するときに多く用いられる.これは choice [decision] A or B の類推と考えられる(→2).
2[区別・選択・分配] …の間に[で];…のどちらかを?choose ? peace and war 平和か戦争かのいずれかを選ぶ《◆and の代りに or を用いることがある; →1 [語法](3)》
OED では,"between" 18 が区別・選択・分配の用法を説明しているが,or を使用する例文は挙げられていない.同じく,MED では bitwene 7 がこの用法に対応するが,やはり or の例文はない."between A or B" の例がいつ現われたのかという問いに答えるには,より詳しく辞書や歴史コーパスを調べる必要がありそうだ.
現代英語について,BNCWeb で動詞句 "{choose/V} between_PRP + or_CJC" として検索し,該当する例文を選り分けたところ,ほんの8例ではあるが用例が得られた.いずれも Written books and periodicals からの例である.比較的わかりやすい4例を挙げよう.
・ . . . in 1627 Emperor Ferdinand ordered all his Bohemian subjects to choose between Catholicism or exile.
・ The main characters are all glorified psychopaths, with little to choose between hero or villain in terms of basic humanity.
・ . . . Mapleton, already out of breath, had to choose between talking or using his energy to keep up.
・ It is for you to choose between clinical or disciplinary action.
同様に,名詞句 "{choice/N} between_PRP + or_CJC" の検索結果も参照されたい.
"between A or B" はあまりに稀な構造だからか,特に規範文法で攻撃されている風でもなさそうだ.先行する語が区別,選択,決定,判定を意味する場合には or の語感は非常によく理解できるし,or の使用によって多義である between の語義が限定されるのだから,このような語法はむしろ推奨されるべきと考える.
2012-02-26 Sun
■ #1035. 列挙された人称代名詞の順序 [personal_pronoun][corpus][bnc][honorific]
昨日の記事「#1034. 英語における敬意を示す言語的手段」 ([2012-02-25-1]) の (4) で,英語では,1人称と他人称が並列される場合に,「倫理的敬意」から1人称が後置されることに触れた.謙譲的な語法といってよいだろう.2人称→3人称→1人称という順序が普通であり,"you and I", "she and I", "you, he, and I" などとなる.このことを初めて学んだとき,これはまさしく尊敬と謙譲の精神の現われであり,日本語に匹敵する敬意と配慮だ,などと感心したものである.Quirk et al. (Section 13.56, Note [a]) には次のようにある.
When one of the conjoins is a personal pronoun, it is considered polite to follow the order of placing 2nd person pronouns first, and (more importantly) 1st person pronouns last: Jill and I (not I and Jill); you and Jill, (not Jill and you), you, Jill, or me (not me, you, or Jill), etc.
同趣旨の記述は,Huddleston and Pullum (1288), Biber et al. (338) にもある.
ところが,英語の人称代名詞の順序を politeness として本当に賛美してよいのかどうか疑わしくなる記述に出くわした.細江 (191) によると,複数では1人称→2人称→3人称の順序が慣例だという.つまり,"we and you", "we and they", "we, you, and they" などとなる.これでは,敬譲にはならないだろう.
ただし,複数主格形について BNCWeb で調べたところ,そもそも用例が少なく,確かめようがないというのが実際のところだ.3つの人称の並列される例などは皆無だった.
・ we and you (0), you and we (0);
・ we and they (11), they and we (7)
・ you and they (11), they and you (6)
・ we, you, and they (0), we, they, and you (0)
・ you, we, and they (0), you, they and we (0)
・ they, we, and you (0), they, you, and we (0)
複数については,例文を豊富に挙げるのを身上とする細江にも例文が挙がっていないことからすると,何らかの規範文法書から取ってきたものなのだろうか.先の3種の大型英文法書にも言及がない.
単数についても,先に示した順序はあくまで慣例であり,場合によってはこの慣例から外れる場合もある.例えば,悪いことをしたときには,1人称を先に出すのがよいとされる (ex. I and Bob were arrested for speeding.) .また,自分の身分のほうが明らかに上の場合には,I and my children や I and my dog も当然ありうる.慣用はあるとしても,最終的にはケースバイケースだろう.
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
・ Huddleston, Rodney and Geoffrey K. Pullum. The Cambridge Grammar of the English Language. Cambridge: CUP, 2002.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
・ 細江 逸記 『英文法汎論』3版 泰文堂,1926年.
2012-01-09 Mon
■ #987. Don't drink more pints of beer than you can help. (1) [negative][comparison][idiom][syntax][corpus][bnc]
cannot help doing は,「?することが避けられない」を原義とし,「?せずにはいられない,?するのは仕方がない」を意味する慣用表現である.cannot but do としても同義.日本人には比較的使いやすい表現だが,標題のように比較の文において than 節のなかで現われる同構文には注意が必要である.
先に類例を挙げておこう.BNCWeb により "(more (_AJ0 | _AV0)? | _AJC) * than * (can|could) (_XX0)? help" で検索すると,関連する例が8件ヒットした.ほぼ同じ表現は削除して,整理した6例を示そう.
・ . . . the Commander struck out for the shore in a strong breaststroke that did not disturb the phosphorescence more than he could help . . . .
・ I'm not putting money in the pocket of the bloody Hamiltons more than I can help.
・ "Don't be more stupid than you can help, Greg!"
・ Resolutely, and determined to think no more than she could help about it . . . .
・ And I won't spend more than I can help.
・ "We'll do our best; we won't get in your way more than we can help."
さて,この構文の問題は,意図されている意味と統語上の論理が食い違っている点にある.例えば,毎日どうしてもビール3杯は飲まずにいられない人に対してこの命令文を発すると「3杯までは許す,だが4杯は飲むな」という趣旨となるだろう(ここでは話しをわかりやすくするために杯数は自然数とする).少なくとも,それが発話者の意図であると考えられる.しかし,論理的に考えると,you can help と肯定であるから,この量は,何とか飲まずにこらえられるぎりぎりの量,4杯を指すはずだ.これより多くは飲むなということだから,「4杯までは許す,だが5杯は飲むな」となってしまう.つまり,発話者の意図と統語上の意味とが食い違ってしまう.あくまで論理的にいうのであれば,*Don't drink more pints of beer than you cannot help. となるはずだが,この種の構文は BNCWeb でも文証されない.
理屈で言えば上記のようになるが,後者の意図で当該の文を発する機会はほとんどないと想像され,語用的に混乱が生じることはないだろう.また,[2011-12-03-1]の記事「#950. Be it never so humble, there's no place like home. (3)」で見たように,肯定でも否定でも意味が変わらないという,にわかには信じられないような統語構造が確かに存在する.とすると,標題の統語構造が許容される語用論的,統語意味論的な余地はあるということになる.
ちなみに,標記の文は今年の私の標語の1つである.ただし,その論理については……できるだけ広く解釈しておきたい.
2011-11-13 Sun
■ #930. a large number of people の数の一致 [agreement][number][syntax][bnc][corpus]
現代英語で「a (large) number of + 複数名詞」が主語に立つとき,動詞は複数に一致するのが原則である.完全にこの理解でいたのだが,先日次のような文に出くわした.
A large number of native speakers is perhaps a pre-requisite for a language of wider communication . . . . (Graddol 12)
そこで,数々の辞書や文法書をひっくり返してみた.ほとんどすべての参考書がこの句を複数扱いとしており,統語分析を与えているものについては,number ではなくこの場合で言えば native speakers を主要部 (head) とみなしている.特に,OALD8, LDOCE5, COBUILD English Usage といった典型的な学習者用英英辞書では,複数形の動詞で一致するよう明示的に注記を与えている.また,規範文法のご意見番 Fowler ("number" の項)によると次の通りで,単数一致については明示的な言及はなかった.
. . . as a noun of multitude in the type 'a number of + pl. noun', normally governs a plural verb both in BrE and AmE.
調べたレファレンスのなかで,単数一致について言及していたのは以下のものである.
・ CGEL: "A (large) number of people have applied for the job. [2]" という例文について,"Use of the singular . . . would be considered pedantic in [2] . . . ." (765) と述べている.
・ CALD3: 単数一致を示す例文を "(slightly formal)" というレーベルを与えつつ挙げていた."A large number of invitations has been sent."
・ 『ジーニアス英和大辞典』: 単数一致を「((正式))」としていた."A ? of passengers were [((正式)) was] injured in the accident."
これで,formal or pedantic という register でまれに使用されるらしいということは分かった.では,BNCWeb で確かめてみようと,"a (very)? (large|great|good|small)? number of ((_AV*)? _AJ*)* _NN2 (_VHZ|_VBZ|was_VBD|_VDZ|_VVZ)" として検索し,該当する例のみを手作業で拾い出してみた.全部で25例あったが,1例を除いてすべてが書き言葉からの文例であり,そのうち12例が Academic prose からのものだった.全体として,この表現が academic or pedantic へ強い傾向を示すことは確かなようだ.
・ Graddol, David. The Future of English? The British Council, 1997. Digital version available at http://www.britishcouncil.org/learning-research-futureofenglish.htm.
・ Burchfield, Robert, ed. Fowler's Modern English Usage. Rev. 3rd ed. Oxford: OUP, 1998.
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
2011-10-28 Fri
■ #914. BNC による語彙の世代差の調査 [bnc][corpus][statistics][lltest][interjection]
昨日の記事「#913. BNC による語彙の男女差の調査」 ([2011-10-27-1]) で取りあげた Rayson et al. では,話者の性別だけでなく年齢による語彙の変異も調査されている.年齢差といっても,35歳未満か以上かで上下の世代に分けた大雑把な分類だが,結果はいくつかの興味深い示唆を与えてくれる.以下は,χ2 の上位19位までの一覧である (142--43) .
| Rank | Under 35 | Over 35 | ||
| Word | χ2 | Word | χ2 | |
| 1 | mum | 1409.3 | yes | 2365.0 |
| 2 | fucking | 1184.6 | well | 1059.8 |
| 3 | my | 762.4 | mm | 895.2 |
| 4 | mummy | 755.2 | er | 773.8 |
| 5 | like | 745.2 | they | 682.2 |
| 6 | na as in wanna and gonna | 712.8 | said | 538.3 |
| 7 | goes | 606.6 | says | 443.1 |
| 8 | shit | 410.1 | were | 385.8 |
| 9 | dad | 403.7 | the | 352.2 |
| 10 | daddy | 380.1 | of | 314.6 |
| 11 | me | 371.9 | and | 224.7 |
| 12 | what | 357.3 | to | 211.2 |
| 13 | fuck | 330.1 | mean | 155.0 |
| 14 | wan as in wanna | 320.6 | he | 144.0 |
| 15 | really | 277.0 | but | 139.0 |
| 16 | okay | 257.0 | perhaps | 136.0 |
| 17 | cos | 254.4 | that | 131.3 |
| 18 | just | 251.8 | see | 122.1 |
| 19 | why | 240.0 | had | 118.3 |
予想される通り,若い世代に特徴的なキーワードはくだけた語を多く含んでいる.表外の語も含めてだが,yeah, okay, ah, ow, hi, hey, ha, no, ooh, wow, hello などの間投詞,fucking, shit, fuck, crap, arse, bollocks などのタブー語が目立つ.しかし,若い世代のキーワードとして,一見すると予想しがたい語も挙がる.例えば,please, sorry, pardon, excuse などの丁寧語が若い世代に特徴的だという.
ほかには,若い世代に特徴的な形容詞や副詞がいくつか見られる (ex. weird, massive, horrible, sick, funny, disgusting, brilliant, really, alright, basically) .評価を表わす形容詞・副詞が多く,一種の流行とみなすことができる語群だろう.年齢差を "apparent time" の差と考えれば,そこには "real time" の変化が示唆されることになるので,この語群の通時的な頻度の増加を探るのもおもしろそうだ.
・ Rayson, Paul, Geoffrey Leech, and Mary Hodges. "Social Differentiation in the Use of English Vocabulary: Some Analyses of the Conversational Component of the British National Corpus." International Journal of Corpus Linguistics 2 (1997): 133--52.
2011-10-27 Thu
■ #913. BNC による語彙の男女差の調査 [bnc][corpus][statistics][lltest][interjection][gender_difference]
標題の話題を扱った Rayson et al. の論文を読んだ.BNC の中で,人口統計的な基準で分類された,話し言葉を収録したサブコーパス(総語数4,552,555語)を対象として,語彙の男女差,年齢差,社会的地位による差を明らかにしようとした研究である.これらの要因のなかで,語彙的変異が統計的に最も強く現われたのは性による差だったということなので,本記事ではその結果を紹介したい.
まず,以下に挙げる数値の解釈には前提知識が必要なので,それに触れておく.BNC に収録された話し言葉は志願者に2日間の自然な会話を Walkman に吹き込んでもらった上で,それを書き起こしたものであり,その志願者の内訳は男性73名,女性75名である.会話に登場する志願者以外の話者についても,女性のほうが多い.したがって,当該サブコーパスへの参加率でいえば,全体として女性が男性よりも高くなることは不思議ではない.
しかし,その前提を踏まえた上でも,全体として女性のほうがよく話すということを示唆する数値が出た.使用された word token 数でいえば,男性を1.00とすると女性が1.51,会話の占有率では,男性を1.00とすると女性は1.33だった.男女混合の会話では男性のほうが高い会話占有率を示すとする先行研究があるが,BNC のサブコーパスでは女性同士の会話が多かったということが,上記の結果の背景にあるのかもしれない.いずれにせよ,興味深い数値であることは間違いない.
次に,より細かく語彙における男女差を見てみよう.男女差の度合いの高いキーワードを抜き出す手法は,原理としては[2010-03-10-1], [2010-09-27-1], [2011-09-24-1]の記事で紹介したのと同じ手法である.男性コーパスと女性コーパスを区別し,それぞれから作られた語彙頻度表を突き合わせて統計的に処理し,カイ二乗値 (χ2) の高い順に並び替えればよい.以下は,上位25位までの一覧である (136--37) .
| Rank | Characteristically male | Characteristically female | ||
| Word | χ2 | Word | χ2 | |
| 1 | fucking | 1233.1 | she | 3109.7 |
| 2 | er | 945.4 | her | 965.4 |
| 3 | the | 698.0 | said | 872.0 |
| 4 | year | 310.3 | n't | 443.9 |
| 5 | aye | 291.8 | I | 357.9 |
| 6 | right | 276.0 | and | 245.3 |
| 7 | hundred | 251.1 | to | 198.6 |
| 8 | fuck | 239.0 | cos | 194.6 |
| 9 | is | 233.3 | oh | 170.2 |
| 10 | of | 203.6 | Christmas | 163.9 |
| 11 | two | 170.3 | thought | 159.7 |
| 12 | three | 168.2 | lovely | 140.3 |
| 13 | a | 151.6 | nice | 134.4 |
| 14 | four | 145.5 | mm | 133.8 |
| 15 | ah | 143.6 | had | 125.9 |
| 16 | no | 140.8 | did | 109.6 |
| 17 | number | 133.9 | going | 109.0 |
| 18 | quid | 124.2 | because | 105.0 |
| 19 | one | 123.6 | him | 99.2 |
| 20 | mate | 120.8 | really | 97.6 |
| 21 | which | 120.5 | school | 96.3 |
| 22 | okay | 119.9 | he | 90.4 |
| 23 | that | 114.2 | think | 88.8 |
| 24 | guy | 108.6 | home | 84.0 |
| 25 | da | 105.3 | me | 83.5 |
必ずしもこの25位までの表からだけでは読み取れないが,Rayson et al. (138--40) によれば以下の点が注目に値するという.
・ "four-letter words",数詞,特定の間投詞は男性に特徴的である (ex. shit, hell, crap; hundred, one, three, two, four; er, yeah, aye, okay, ah, eh, hmm)
・ 女性人称代名詞,1人称代名詞,特定の間投詞は女性に特徴的である (ex. she, her, hers; I, me, my, mine; yes, mm, really) (男性代名詞の使用には特に男女差はない)
・ the や of の使用は男性に多い(男性に一般名詞を用いた名詞句の使用が多いという別の事実と関連するか?)
・ 固有名詞,代名詞,動詞は女性に多い(男性の事実描写 "report" の傾向に対する女性の関係構築 "rapport" の傾向の現われか?)
・ 固有名詞のなかでも,人名は女性の使用が多く,地名は男性の使用が多い.
他のコーパスによる検証が必要だろうが,この結果と解釈に興味深い含蓄があることは確かである.
キーワードの統計処理と関連して,コーパス言語学でカイ二乗検定の代用として広く使用されるようになってきた Log-Likelihood 検定については,自作の Log-Likelihood Tester, Ver. 1 や Log-Likelihood Tester, Ver. 2 を参照.
・ Rayson, Paul, Geoffrey Leech, and Mary Hodges. "Social Differentiation in the Use of English Vocabulary: Some Analyses of the Conversational Component of the British National Corpus." International Journal of Corpus Linguistics 2 (1997): 133--52.
2011-08-20 Sat
■ #845. 現代英語の語彙の起源と割合 [lexicology][loan_word][statistics][bnc][corpus]
現代英語の語彙における本来語と借用語の比率については,本ブログでも何度か取り上げてきた.いくつかリンクを張っておこう.
・ [2010-12-31-1]: #613. Academic Word List に含まれる本来語の割合
・ [2010-06-30-1]: #429. 現代英語の最頻語彙10000語の起源と割合
・ [2010-05-16-1]: #384. 語彙数とゲルマン語彙比率で古英語と現代英語の語彙を比較する
・ [2010-03-02-1]: #309. 現代英語の基本語彙100語の起源と割合
・ [2009-11-15-1]: #202. 現代英語の基本語彙600語の起源と割合
・ [2009-11-14-1]: #201. 現代英語の借用語の起源と割合 (2)
・ [2009-08-15-1]: #110. 現代英語の借用語の起源と割合
語種の数量的な調査には,数え挙げる際のソースを何にするか,type-count か token-count か,どのくらいの語彙規模を扱うか,語源にまつわる不正確さをどのように処理するか,などの考慮すべき事項が様々あり,研究者によって結果がまちまちとなることがある.しかし,複数の調査を比べれば,およその平均値や全体像が見えてくるのも確かである.
先日参加してきた ICOME7 (The Seventh International Conference on Middle English) で,8月4日,OED3 の主幹語源学者 Philip Durkin 氏が "Some neglected aspects of Middle English lexical borrowing from (Anglo-)French" と題する講演で関連する話題について触れていたので,要点をメモしておく.
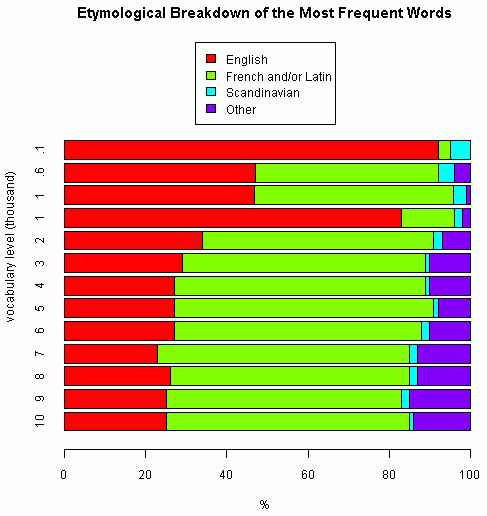
Durkin 氏は BNC から最頻1000語のリストを取り出し,語源分析した.その結果,英語本来語が489語,フランス・ラテン語が489語,ノルド語が32語,それ以外の言語が10語という数値が得られた.大規模コーパスの頻度リスト (see [2010-03-01-1]) を利用した語源調査はいつか自分でやろうと思っていたが,Durkin 氏のおかげでその労力を省くことができた(ありがとうございます!).
これにより,上記のリンクで示した諸調査と合わせて,type-count に基づく最頻100語,600語,1000語,2000語,3000語,4000語,5000語,6000語,7000語,8000語,9000語,10000語という12段階の語彙規模での語種別比率が得られたことになる.母体となる現代英語語彙の情報ソース,数え方,語種区分はそれぞれ異なっているのかもしれないが,一応の目安として以下で全体像を示したい.語種区分は English, French and/or Latin, Scandinavian, Other として4種類に統一した.
|
|
上から3つ目と4つ目の棒グラフは,同じ最頻1000語レベルでの比較だが,3つ目は上述の Durkin の BNC 調査によるもの,4つ目は[2010-06-30-1]の記事で示した Williams のものである.著しい差異が生じたが,これも調査方法が異なるがゆえだろうか.注意して解釈する必要があるが,この点を除けば全体としてなだらかに推移し,最終的には本来語25%,ラテン・フランス語60%,それ以外が15%という数値におよそ落ち着くようだ.
2011-05-24 Tue
■ #757. decline + 蜍募錐隧杣syntax] [gerund][bnc][corpus]
1796年9月19日,アメリカ合衆国の初代大統領 George Washington (1732--99) が大統領職を去るに当たって farewell address 「お別れのスピーチ」を読んだ.渡辺昇一先生の『英文法を知ってますか』 (252--53) によると,その語り出しの部分が英語精読力の試金石になるというので,院生と精読する機会をもった.以下の英文である.
FRIENDS AND FELLOW-CITIZENS. The period for a new election of a citizen, to administer the executive government of the United States, being not far distant, and the time actually arrived, when your thoughts must be employed in designating the person who is to be clothed with that important trust, it appears to me proper, especially as it may conduce to a more distinct expression of the public voice, that I should now apprise you of the resolution I have formed, to decline being considered among the number of those out of whom a choice is to be made.
確かに読み応えのある英文である.注を付すべき英文法のポイントはたくさんあるが,最後のほうに decline に不定詞でなく動名詞が後続する点を指摘してくれた学生がいた.私は見逃していたので余計に関心をもったのだが,decline の用法を学習者用英英辞書で調べると,動名詞が後続する構文は触れられていない.しかし,大きな英和辞書では,一般的ではないとしながらも,動名詞が後続し得ると記述されている.また,OED で調べると decline, v. の語義 13b に挙げられている17世紀末以降からの数例で,動名詞の後続する構文が確認される.したがって,Washington がここで動名詞を使用しているのは歴史的にあり得ない構文ではなかったということになる.
しかし,Washington があえて稀な構文を用いたのはなぜか.style や formality の問題なのか,あるいは decline の取り得る構文の種類の相対頻度が当時から現在までの期間に通時的に変化してきたということなのか.精読を目指すからには,この点が気になった.本格的には通時コーパスなどで調べる必要があるが,まずは BNCweb でどのくらいヒットするか調べてみた.
不定詞が後続する構文を取り出すのに,"{decline/V} (_{ADV})* _TO0" で検索すると,769例がヒット.一方,動名詞が後続する構文は "{decline/V} (_{ADV})* _VVG" で取り出し,ヒットした9例のうち実際には3例のみ該当する例であることが判明した.コンコーダンスラインを示す.
- FTT 821: . . . but with proper delicacy to this subject they decline making application at Present and till it is ascertained how cattle markets may go in June next . . .
- FTT 839: The Presses of this meeting, as being part owner of the Steam Boat, declines allowing the assessment for the Steam Boat to be charged for this year.
- HW8 831: Dosh and Freddie didn't take much persuading but Chase thankfully declined saying that parties didn't like him.
FTT なる典拠(An Islay Notebook という non-academic prose and biography)から2例が例証されるというのは,書き手の癖の問題なのだろうか.Washington の動名詞の使用例については判断を下せないままだが,現在までに古風あるいは格式張った使い方に限定されてきた可能性,通時的に頻度が減ってきた可能性はありそうだ.
・ 渡辺 昇一 『英文法を知ってますか』 文藝春秋〈文春新書〉,2003年.
2011-05-04 Wed
■ #737. 構文の contamination [blend][contamination][syntax][superlative][bnc][corpus]
[2011-01-17-1]で blend 「混成語」を話題にした際に少々触れたが,類似した過程に contamination 「混交」がある.両者は意識的か否かという観点か区別されることがあるが,特に区別せず同様に用いられることもある.通常は語形成上の過程として捉えられるが,[2011-01-17-1]の記事で触れたように構文のレベルででも起こりうる.例えば,前の記事では,"Why did you do that for?" や "different than" を挙げた.
Graddol を講読中に構文の contamination に出会った(赤字は引用者).
English is remarkable for its diversity, its propensity to change and be changed. This has resulted in both a variety of forms of English, but also a diversity of cultural contexts within which English is used in daily life. (5)
ここでは,both . . . and . . . と not only . . . but also . . . の構文が混交している.BNCweb より検索キーワード "both +** but also" で類例を探してみると,6例ほどが見つかった(赤字は引用者).
- Ion Pacepa, Ceausescu's chief intelligence officer who defected in 1978, takes particular pleasure in his memoirs in exposing Stefan Andrei as both corrupt but also as well aware of the absurdity of the Ceausescus' pretensions, especially Elena's academic titles.
- Their economy and population were both suffering, but also they were becoming wary of the Dzhungars' increasing strength.
- In fitting statistical models to study relationships, it is important to take account of such hierarchies, both for technical reasons but also because influential factors can be present at any or all levels of aggregation.
- The changes that have been introduced into South Africa [pause] forced upon the white minority government by both international pressure but also by the magnificent work at the A N C in Cosatu [pause] must be supported as well but we cannot treat South Africa as anything but a pariah [pause] a, a, a national pariah [pause] until we see one person one vote, and a black majority government in South Africa.
- 'Committees' means both actual committees but also individuals or organisers listed as committees.
- I mean that can be both pleasurable, but also make somebody feel uncomfortable.
contamination は,共時的には話者の発話時に生じる2つの関連構文の混交として解釈されるが,これが共同体に広がってある程度の認知度を得ると,新しい構文として独立し定着することがある.そのような場合には,contamination は通時的な観点からアプローチすることができるだろう.以下は現代英語に見られる構文の contamination の例だが,これらがいつ頃に現われ,現在までにどの程度の認知度を得てきたかという問題は,英語史の問題である.
(1) these kinds of things: these things と this kind of things の混交.
(2) different than: different from と other than の混交.
(3) different to: different from と opposed to の混交.similar to との類推とも考えられる.
(4) cannot help but do: cannot help doing と cannot but do の混交.
(5) It is no good for us complaining about it.: It is no good for us to complain about it. と It is no good we complaining about it. の混交.
(6) no sooner . . . when: no sooner . . . than と scarcely . . . when の混交.
(7) I am friends with him.: I am friendly with him. と He and I are friends. の混交.
(8) a man whom she thought was a murderer: a man who she thought was a murderer と a man whom she thought to be a murderer の混交.
(9) the cleverest of all the other boys: cleverer than the other boys と the cleverest of all the boys の混交.
調べてみるといろいろとあるようだが,(9) のような例は少なくないようで,石橋 (127) は次のようにコメントしている.研究材料としておもしろそうだ.
Sunday's action was the most brilliant and fruitful of any fought up to that date by the fighters of the Royal Air Force. [the most . . . of (all) + (more . . . than) any]---W. Churchill / This is the greatest error of all the rest. [the greatest . . . of (all) + (a greater . . . than) all the rest]---Sh., Mids. N. D. v. i. 250. 最後の例のように,最上級に修飾される名詞を,意味上はそれを含まないはずの「その他」の中に包括させた混交表現を,とくに包括最上級 (Inclusive superlative) と呼ぶことがある.その例は近代初期の英語にときどき見いだされる.
・ Graddol, David. The Future of English? The British Council, 1997. Digital version available at http://www.britishcouncil.org/learning-research-futureofenglish.htm.
・ 石橋 幸太郎 編 『現代英語学辞典』 成美堂,1973年.
2011-04-08 Fri
■ #711. Log-Likelihood Tester CGI, Ver. 2 [corpus][bnc][statistics][web_service][cgi][lltest]
以下に,汎用の Log-Likelihood Tester, Ver. 2 を公開.(後に説明するように,入力データのフォーマットに不備がある場合や,モードが適切に選択されていない場合にはサーバーでエラーが生じる可能性があるので注意.)
[2011-03-25-1]の記事で,コーパス研究でよく用いられる対数尤度検定 ( Log-Likelihood Test ) の計算機 Log-Likelihood Tester, Ver. 1 を公開した.Ver. 1 は,コーパスサイズを加味しながら2つのコーパスでのキーワード(群)の出現頻度を比べ,コーパス間の差が有意であるかどうかを検定するものだった.
Log-Likelihood Test は上述の目的で用いることが多いと思い,Ver. 1 ではあえて機能を特化させたのだが,より一般的に複数行,複数列の分割表で与えられるデータに対応する対数尤度検定を行ないたい場合もある.例えば,昨日の記事[2011-04-07-1]で,現代英語における though と although の出現傾向について BNC に基づいた調査を紹介したが,Text Domain ごとの頻度比率は,両語の間で統計的にどの程度一致している,あるいは一致していないとみなすことができるのだろうか.昨日のグラフから,although は学術散文に多く,though は創作散文に多いという傾向が一目瞭然だが,この直感的な「一目瞭然」は統計的にはどのように表現されるのだろうか.
このような場合には,次のような頻度表(値は100万語当たりの出現頻度に標準化済み)を準備し,これをコピーして入力ボックスに貼り付ける."lump mode" にチェックを入れ替え,"Go!" する.(デフォルトは "each-line mode" で,これは Ver. 1 と同等のモード.)
| though | although | |
|---|---|---|
| Natural and pure sciences | 56.3 | 80.13 |
| Applied science | 37.36 | 68.31 |
| World affairs | 45.81 | 68.2 |
| Social science | 48.98 | 63.38 |
| Commerce and finance | 46.18 | 57.21 |
| Arts | 74.07 | 52.93 |
| Leisure | 45.85 | 49.46 |
| Belief and thought | 70.78 | 46.75 |
| Imaginative prose | 80.2 | 26.37 |
結果は,1行だけの表として出力される.though と although を表わす2列の数値の並びが,統計的にどのくらい近似しているかを計算している.結論としては,両語の Text Domain ごとの頻度の並びの差は p < 0.0001 という非常に高いレベルで有意であり,両語の出現傾向は Text Domain によってほぼ確実に異なるといえる.
入力ボックスに入れるデータの書式は,タブ区切りの分割表.表頭と表側はいずれも省略可.サンプルのように表頭と表側の両方を含める場合には,左上のセルは空白にしておく必要あり.
"each-line mode" の機能は Ver. 1 と互換なので,入力形式もそちらの説明を参照.今回の Ver. 2 の "each-line mode" では,出力結果をシンプルにおさえてある(逆に,詳しい内部計算値を得たい場合には Ver. 1 のほうが有用).
Log-Likelihood Test の概要については,[2011-03-24-1]の記事を参照.
2011-04-07 Thu
■ #710. though と although の語法の差 (2) [bnc][corpus][lltest][conjunction][statistics]
昨日の記事[2011-04-06-1]で,though と although の語法の差に触れた.今日も同じ話題で.
4000万語超からなる The Longman Spoken and Written English Corpus (the LSWE Corpus) を駆使した現代英語の文法書,Biber et al. (845--46) では次のようにある.
Both of these subordinators [though and although] occur in all four registers [conversation, fiction, news, and academic prose], although the registers show different preferences of use. Conversation and fiction show a slightly greater use of though (concessive clauses are, however, uncommon in conversation generally). News shows no particular preference. In academic prose, although is about three times as frequent as though. Although seems to have a slightly more formal tone to it, fitting the style of academic prose . . . . The greater use of although by writers of academic prose may also result from an attempt to distinguish this subordinator from the common use of though as a linking adverbial in conversation . . . .
また,同書の p. 842 の表からは,相対的に though が fiction で多く,although は academic prose で多いことが確認される.ジャンルによる差が現われているとの結果だ.
このような先行研究を受けて,今回は BNC ( The British National Corpus ) によりこれを確かめてみる.BNCweb で,{although/CONJ}, {though/CONJ} をそれぞれ検索し,Written/Spoken, Text Domain, Sex of Author/Speaker, Perceived Level of Difficulty など様々なパラメータで出現分布を分析した.主立った結果を以下に示そう(数値データはこのページのHTMLソースを参照).
まず,Written/Spoken の差については,予想されるとおり,両語とも Written への偏りが激しい(差異係数は though で 0.66344 ,although で 0.49770 で,明らかに書き言葉に偏る).Log-Likelihood Test では,p < 0.0001 のレベルで書き言葉と話し言葉の有意差が明確に示された.
書き手,話し手の性による差も興味深い.書き言葉と話し言葉の両方で,although は有意差をもって男性の使用に偏っている.though については,性差は although ほど顕著ではない(ただし書き言葉では p < 0.05 で有意差あり).
次に,Text Domain 別に頻度をみる.9種類の Text Domain を区別した ( Natural and pure sciences, Applied science, World affairs, Social science, Commerce and finance, Arts, Leisure, Belief and thought, Imaginative prose ) .100万語当たりの出現回数に標準化した値で,両語の Text Domain 別頻度をグラフ化したのが以下の図だ.
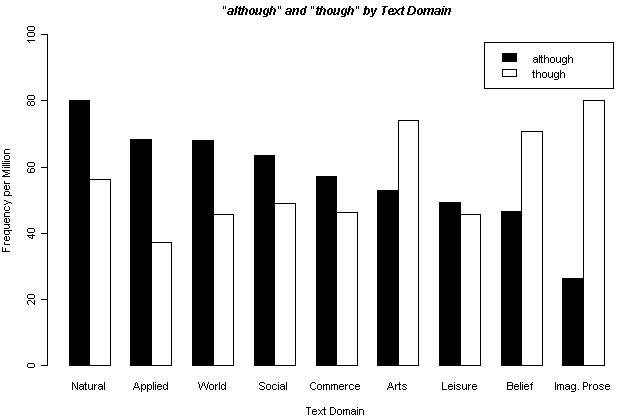
Text Domain によって両語の出現頻度に対照的な傾向が見られることがわかる.相対的に sciences ( = academic prose ) に although が目立ち,Imag(inative) Prose ( = fiction ) に though が多い.Log-Likelihood Test では,Text Domain による出現傾向の差は p < 0.0001 で有意である.
直感的にも先行研究の結果からも予想され得たことではあるが,although は男性の書き手により学術散文で顕著に用いられるという図式が現われた.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
2011-04-05 Tue
■ #708. Frequency Sorter CGI [corpus][bnc][statistics][web_service][cgi][lexicology][plural]
何らかの基準で集めた英単語のリストを,一般的な頻度の順に並び替えたいことがある.例えば,[2011-03-22-1]で論じたように,頻度と不規則な振る舞いとの関係を調べたいときに,注目する語(群)の一般的な頻度を知る必要がある.この目的には,[2010-03-01-1]で紹介したような大規模な汎用コーパスに基づく頻度表が有用である.BNC lemma-pos list (122KB) や ANC word-tagset list (7.2MB) などで問題の語を一つひとつ検索し,頻度数や頻度順位を調べてゆけばよいが,語数が多い場合には面倒だ.そこで,上記2つの頻度表から,入力した語(群)の頻度と順位を取り出す CGI を作成した.
改行でもスペースでもカンマでもよいのだが,区切られた単語リストを以下のボックスに入力し,"Frequency Sort Go!" をクリックする.出力結果を頻度順位の高い順にソートする場合には,"sort by rank?" をオンにする(デフォルトでオン.オフにすると,入力順に出力される).例えば,現代標準英語に残る純粋に i-mutation を示す複数形は以下の7語のみである(複合語,二重複数,[2011-04-01-1]で話題にした sister(e)n は除く).これをコピーしてボックスに入力する.
foot, goose, louse, man, mouse, tooth, woman
まず,BNC lemma-pos list による出力だが,この頻度表は約1億語の BNC 全体から,頻度にして800回以上現われる,上位6318位までの見出し語 ( lemma ) を収録している.したがって,それよりも頻度の下回る goose, louse については空欄となっている.頻度と不規則性の相関関係を考える際に参考になるだろう.
次に,ANC word-tagset list による出力が続くが,この頻度表は BNC のものよりも規模が大きく,かつきめ細かい.合計22,164,985語を有する ANC (American National Corpus) から,Penn Treebank Tagset によってクラス付与された単位で語形が列挙されたリストである.タグセットが細かいので読みにくいし,自動タグ付与に起因するエラーも少なからず含まれているが,BNC のものよりも低頻度の語(形)を収録しているので,goose や louse の頻度情報も現われる.こちらの頻度表では WORD FORM ごとの頻度も確認できるため,直接 geese や lice の頻度も確かめられる.
当初 Frequency Sorter の用途として想定していたのは,上記の不規則複数形を示す語群などの頻度と順位の一括調査だったが,他にも用途はあるかもしれない.以下に,思いつきをメモ.
・ 1単語から使えるので,like のような多品詞語を入力して,品詞(あるいはタグ付与されたクラス)ごとの頻度を取り出せる.
・ ヒット数だけを確認したい場合には,いちいちコーパスを立ち上げる必要がない.
・ 論文やプレゼンで,ある目的で集めた数百語の単語リストの中から典型的な例,分かりやすい例を10個ほど示したいときなど,頻度の高い10個を選べばよい.例えば,[2011-03-29-1]で列挙した sur- を接頭辞にもつ単語リストのうち,例示に最もふさわしい10個を選ぶなどの目的に.頻度に基づいた順番のほうが,ランダム順やアルファベット順よりも親切なことが多いだろう(今後,本ブログ執筆に活用する予定).
・ 英米それぞれの代表的なコーパスに基づく頻度表を利用しているので,綴字や形態などの頻度の英米差を確認するのに使える.
・ (実際には lemmatisation が必要だが)適当な英文を放り込んでみて,妙に頻度の低い語が含まれていないかを調べる.頻度のツールなので,その他,教育・学習目的にいろいろと使えるかもしれない.
2011-03-25 Fri
■ #697. Log-Likelihood Tester CGI [corpus][bnc][statistics][web_service][cgi][lltest][sociolinguistics]
昨日の記事[2011-03-24-1]で Log-Likelihood Test を話題にした.計算には Rayson 氏の Log-likelihood calculator を利用すればよいと述べたが,実際の検定の際に作業をもう少し自動化したいと思ったので CGI を自作してみた.細かい不備はあると思うが,とりあえず公開.
上のテキストボックスに入力すべきデータは,タブ区切りの表の形式.1行目(省略可)はコーパス名,2行目以降はキーワードと観察頻度数(ヒット数),最終行は各コーパスのサイズ(語数)."#" で始まる行はコメント行として無視される.1列目のキーワード列は省略可.
以下のテキストが入力サンプル.[2010-09-11-1]の記事で取り上げたテレビ広告で頻用される形容詞(比較級と最上級を含む)トップ20の頻度を,BNCweb の話し言葉サブコーパスから話者の性別に整理した表である.このままコピーして入力ボックスに貼り付けると,出力結果が確認できる.
BNC_Male_Speakers BNC_Female_Speakers new 149 91 good 408 310 free 173 75 fresh 84 118 delicious 12 34 full 210 107 sure 532 328 clean 197 223 wonderful 270 258 special 177 82 crisp 10 16 fine 347 215 big 470 415 great 203 96 real 163 80 easy 326 157 bright 113 110 extra 347 203 safe 182 92 rich 120 45 #-------- corpus_size 4949938 3290569
男女間で有意差の特に大きいのは,対応行が赤で塗りつぶされた fresh, delicious, clean, wonderful, big で,いずれも期待度数に基づいて計算された Diff_Co ( "Difference Coefficient" 「差異係数」 ) がマイナスであることから,女性に特徴的な形容詞ということになる.big は意外な気がしたが,おもしろい結果である.一方,男性に偏って有意差を示すのは黄色で示した easy や rich である.この結果はいろいろと読み込むことができそうだし,より詳細に調べることもできる.広告の形容詞という観点からは,話者ではなく聞き手の性別,年齢,社会階級などを軸に調査してもおもしろそうだ.いろいろと応用できる.
2011-03-24 Thu
■ #696. Log-Likelihood Test [corpus][bnc][statistics][lltest]
[2010-03-04-1]の記事で触れたが,コーパス言語学では各種の統計手法が用いられる.いくつかある手法のなかでも,ある表現のコーパス間の頻度を比較したり,collocation の度合いを測るのに広く用いられているのが Log-Likelihood Test ( LL Test, G Test, G2 Test などとも)呼ばれる検定である.コーパスサイズを考慮に入れた検定なのでサイズの異なるコーパス間での比較が可能であり,同じ目的で以前によく用いられていたカイ2乗検定 ( Chi-Squared Test ) よりもいくつかの点ですぐれた手法と評価されており,最近のコーパス研究では広く用いられている.(例えば,カイ2乗検定は期待頻度が5回より少ないとき,高頻度語を扱うとき,コーパスサイズが大きいものと小さいものを比較するときに信頼性が低くなるが,Log-Likelihood Test はこれらの影響を受けにくい [ Rayson and Garside 2 ] .)
Log-Likelihood Test の基本的な考え方は,コーパスサイズをもとにある表現の期待される出現頻度(期待頻度)を割り出し,その値と実際に出現する頻度(観察頻度)の差が単純な誤差と考えられるほどに近似しているかどうかを判定するというものである.例として,次のようなケース・スタディを試す.BNC ( The British National Corpus ) から話し言葉サブコーパスと書き言葉サブコーパスを区別し,両サブコーパス間で f*ck という four-letter word の頻度を比較する.BNCweb よりこのキーワードを検索すると,次のような結果が得られた.
| Category | No. of words | No. of hits | Dispersion (over files) | Frequency per million words |
|---|---|---|---|---|
| Spoken | 10,409,858 | 579 | 63/908 | 55.62 |
| Written | 87,903,571 | 743 | 172/3,140 | 8.45 |
| total | 98,313,429 | 1,322 | 235/4,048 | 13.45 |
統計処理をほどこすまでもなく最右列 "Frequency per million words" を見れば,f*ck が圧倒的に話し言葉で多く用いられることが分かるが,今回はこれを統計的に裏付ける.まず,帰無仮説として「話し言葉サブコーパスと書き言葉サブコーパスの間での f*ck の頻度差は誤差の範囲内であり,この語に関して両者に意味のある差はない」を設定する.その対立仮説は「話し言葉サブコーパスと書き言葉サブコーパスの間での f*ck の頻度差は誤差の範囲内でなく,この語に関して両者の差は意味がある」となる.帰無仮説が支持されるかどうかを決めるのが,検定の目的である.
| Corpus 1 | Corpus 2 | Total | |
|---|---|---|---|
| Frequency of word | a | b | a+b |
| Frequency of other words | c-a | d-b | c+d-a-b |
| Total | c | d | c+d |
Log-Likelihood Test に用いる Log-Likelihood ratio 「対数尤度比」は,上の表の要領で各サブコーパスの総語数 ( c, d ) と,各サブコーパスでの f*ck の頻度数 ( a, b ) を分割表にまとめた上で,それぞれの期待頻度 E1 と E2 を下の (1) の式で求め,その値を (2) の式に代入して求める.
(1) E1 = c*(a+b)/(c+d); E2 = d*(a+b)/(c+d)
(2) LL = 2*((a*log(a/E1))+(b*log(b/E2)))
f*ck の数値で計算すると,以下のようになる.
E1 = 10409858*(579+743)/(10409858+87903571) = 139.979170861796
E2 = 87903571*(579+743)/(10409858+87903571) = 1182.0208291382
LL = 2*((579*log(579/139.979170861796))+(743*log(743/1182.0208291382))) = 954.2115
Log-likelihood ratio として 954.2115 という値が算出される.次にこの値を,適切な有意水準(通常は 5%, 1%, 0.1%)に対応するカイ二乗値と比較する.2 * 2 の分割表に対する計算では自由度1のカイ二乗値を用いることになっており,その値は有意水準 5%, 1%, 0.1% の順にそれぞれ 3.84, 6.63, 10.83 である.954.2115 の Log-Likelihood ratio は有意水準 0.1% に対応する 10.83 よりもずっと高いので,0.1% の有意水準で帰無仮説は棄却される.言い換えれば,統計的には帰無仮説が真である確率は 0.1% にも満たず,まず偽と考えてよいということである.このようにして対立仮説「話し言葉サブコーパスと書き言葉サブコーパスの間での f*ck の頻度差は誤差の範囲内でなく,この語に関して両者の差は意味がある」が採択されることになる.
Log-Likelihood Test は以上のように進められるが,この検定を行なうにあたっての前提条件を知っておく必要がある.一般には,計算される期待頻度が 5 を下回るセルが1つでもある場合には,検定の精度は落ちるとされる.これは the Cochran rule と呼ばれているが,よりきめ細かなルールを提起した Rayson, Berridge, and Francis (8) によれば,期待頻度が満たすべき最低値は有意水準 5% で13 回,1% で 11 回,0.1% で 8 回だという.有意水準を 0.01% に設定すれば期待頻度 1 回にも耐える精度を得られるので,Rayson et al. はコーパス言語学で慣習的に用いられている3つの水準に加えて,0.01% の水準(対応するカイ二乗値は 15.13 )までの検定を推奨している.
統計には詳しくないが,ある表現の 2(サブ)コーパス間での頻度比較というシーンで簡単に用いることができる検定として,Log-Likelihood Test の応用範囲は広そうだ.計算自体は Rayson 氏の Log-likelihood calculator などに任せればよい(本記事はこのページの記述とリンク先の論文を参考にした).
BNC を用いた f*ck 関連語の分布の研究は,McEnery et al. (264--86) のケース・スタディに詳しい.
関連して,検定は行なわなかったが,かつて本ブログで扱った gorgeous の調査 ([2010-08-16-1], [2010-08-17-1],[2010-12-25-1]) なども参照.
・ Rayson, P., D. Berridge , and B. Francis. "Extending the Cochran Rule for the Comparison of Word Frequencies between Corpora." Le poids des mots: Proceedings of the 7th International Conference on Statistical Analysis of Textual Data (JADT 2004), Louvain-la-Neuve, Belgium, March 10-12, 2004. Ed. Purnelle G., Fairon C., and Dister A. Louvain: Presses universitaires de Louvain, 2004. 926--36. Available online at http://www.comp.lancs.ac.uk/computing/users/paul/publications/rbf04_jadt.pdf .
・ Rayson, P. and R. Garside. "Comparing Corpora Using Frequency Profiling". Proceedings of the Workshop on Comparing Corpora, Held in Conjunction with the 38th Annual Meeting of the Association for Computational Linguistics (ACL 2000), 1-8 October 2000, Hong Kong. 2000. 1--6. Available online at http://www.comp.lancs.ac.uk/computing/users/paul/phd/phd2003.pdf .
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2011-02-24 Thu
■ #668. Chaucer の knight との脚韻語 [chaucer][bnc][collocation][kyng_alisaunder]
Chaucer の全作品中,knight という語は90回以上,脚韻箇所に現われている.対応する脚韻語を調べ,さらにロンドンの方言で書かれた2つのロマンス Kyng Alisaunder と Arthur and Merlin でも同様に調べてみると,非常におもしろい事実が浮かび上がる.
Chaucer で knight と脚韻を踏む語として5回以上現われるものに,might (32), wight (22), night (9), right (8), bright (5) がある.Kyng Alisaunder では高頻度のものには wiȝth, fiȝth, riȝth / miȝth があり,同じく Arthur and Merlin では ''fiȝt, riȝt, riȝth がある.脚韻語の分布をまとめたのが以下の図である(Burnley, p. 130 の図をもとに作成).
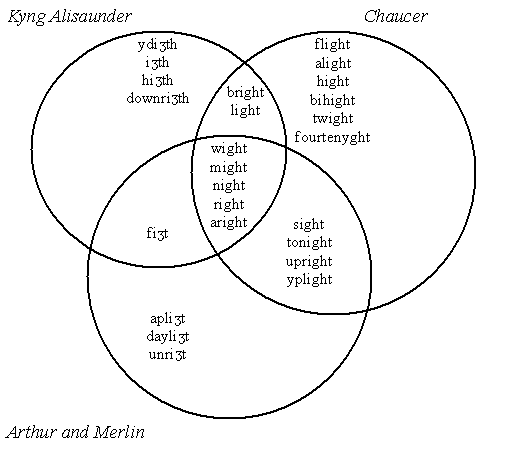
Chaucer の脚韻語は,高頻度のものを中心として大半が他の2つのロマンス作品と重複しており,全体として中英語ロマンスの伝統的な脚韻語を受け継いでいると解釈できる.一方で,Chaucer のみが用いている脚韻語もいくつか確認され,詩人の脚韻語の幅の広さが示唆される.
しかし,比較によってしか得られない非常に興味深い事実がある.他のロマンス2作品,ひいては中英語ロマンス全体として,最も頻度が高い脚韻語とみなしてもよいと思われる fight が,Chaucer には一度も現われないのである.knight と fight は縁語であり,collocation の度合いが高いことは自明であるから,Chaucer における不在は不自然とも思える.Burnley (131) は,脚韻語としての fight の不在は,Chaucer の選択した主題との関連もあるかもしれないが,おそらくは Chaucer が "a hackneyed rhyme" 「使い古された脚韻」とみなして意識的に避けたためだろうという.
Although he [Chaucer] was often content to employ familiar and traditional rhymes, there is also evidence of resourcefulness in seeking unusual rhymes, as well as of avoiding rhymes which might have proved unacceptable to his audience. (Burnley 131)
詩人が用いた脚韻語ではなく,用いなかった脚韻語を指摘することで,その詩人の特徴や詩の言語に対する態度が浮き彫りになりうる好例である.何が不在なのか,何を用いなかったのかを知るには,他と比較しなければならない.対象の本質を知るには,それが置かれている環境を広く見渡す必要がある.文献学の神髄を見せられるような印象的な例である.
ちなみに,knight と fight の collocation は強かったに違いないと述べたが,それは中世での話しである.現代英語における両語の collocation は BNCweb で調べたところそれほど顕著ではない.名詞 knight の前後5語以内に fight が現われる頻度はコーパス中で10回きりである.ただし,[2010-03-23-1]の記事で触れた MI と T-score の値を見ると,それぞれ 3.5415, 2.8907 であり,collocation と認めてよい水準ではある.
・ Burnley, David. The Language of Chaucer. Basingstoke: Macmillan Education, 1983. 13--15.
Powered by WinChalow1.0rc4 based on chalow