2021-01-03 Sun
■ #4269. なぜ digital transformation を略すと DX となるのですか? --- hellog ラジオ版 [hellog-radio][sobokunagimon][abbreviation][grammatology][prefix][word_game][x][information_theory][preposition][latin]
本年も引き続き,大学や企業など多くの組織で多かれ少なかれ「オンライン」が推奨されることになるかと思います.コロナ禍に1年ほど先立つ2018年12月に,すでに経済産業省が「デジタルトランスフォーメーションを推進するためのガイドライン(DX推進ガイドライン)」 (PDF) を発表しており,この DX 路線が昨今の状況によりますます押し進められていくものと予想されます.
ですが,digital transformation の略が,なぜ *DT ではなく DX なのか,疑問に思いませんか? DX のほうが明らかに近未来的で格好よい見映えですが,この X はいったいどこから来ているのでしょうか.
実は,これは一種の言葉遊びであり文字遊びなのです.音声解説をお聴きください
trans- というのはラテン語の接頭辞で,英語における through や across に相当します.across に翻訳できるというところがポイントです.trans- → across → cross → 十字架 → X という,語源と字形に引っかけた一種の言葉遊びにより,接頭辞 trans- が X で表記されるようになったのです.実は DX = digital transformation というのはまだ生やさしいほうで,XMIT, X-ing, XREF, Xmas, Xian, XTAL などの略記もあります.それぞれ何の略記か分かるでしょうか.
このような X に関する言葉遊び,文字遊びの話題に関心をもった方は,ぜひ##4219,4189,4220の記事セットをご参照ください.X は実におもしろい文字です.
2020-11-14 Sat
■ #4219. なぜ DX が digital transformation の略記となるのか? [sobokunagimon][abbreviation][grammatology][prefix][word_game][x][information_theory][latin]
本日11月14日の朝日新聞朝刊のコラム「ことばサプリ」に,標題に関連する話題が掲載されています.この問題について事前に取材を受け調査した経緯がありますので,せっかくですし,このタイミングでその詳細を以下に記しておきたいと思います. *
日本でも日常生活のなかで「デジタルトランスフォーメーション」 (= digital transformation = DX ) という言葉を耳にしたり,目にしたりする機会が増えてきた.デジタルによる変革の推奨である.経済産業省が2018年12月に「デジタルトランスフォーメーションを推進するためのガイドライン(DX推進ガイドライン)」 (PDF) を発表しており,DX という略称も表記もすでに国のお墨付きを得ていることになる.だが,そもそもなぜ digital transformation の略記が DX なのだろうか.確かに DT よりカッコよく見えるかもしれないが・・・.
transformation (変形,変質)は,trans- (= across, through, over, beyond) + formation という語形成で,中英語期にフランス語を経由して入ってきたラテン語由来の単語である.ラテン語の接頭辞 trans- は,上記の通り英語でいうところの across や through に相当し,実に後者 through とは印欧祖語のレベルで同根である.このように trans- 自体に「?を超えて(突き抜けて)」という含みがあるために,「変化,変形,変革,変換,変異」などと意味的に相性がよい.transcend, transfer, transfigure, transit, translate, transmit, transport, transpose 等の単語が思い浮かぶ.漢字でいえば「変」のもつ字義に近接する接頭辞といってよいだろう.変革の時代にはもてはやされるはずだ.
さて,上記のように trans- はラテン語由来の接頭辞だが,英語に翻訳するとおよそ across に相当する.この across は「#4189. across は a + cross」 ([2020-10-15-1]) で見たとおり,接頭辞 a- に「十字(架)」を意味する cross を付加した語である.ここで,十字(架)をかたどった文字としての X の出番となる.文字 X といえば英語の名詞・動詞 cross, cross といえば英語の前置詞 across,across といえばラテン語の接頭辞 trans- という理屈で,いつの間にか trans- が X で表記される慣習となってしまった.England を Engl& と記したり,See you later. を CUL8R としたりするのと同じ一種の文字遊び (rebus) の類いといってよい.日本語の戯書にも通じる(cf. 「#2789. 現代英語の Engl&,中英語の 7honge」 ([2016-12-15-1]),「#2790. Engl&, 7honge と訓仮名」 ([2016-12-16-1]).
X の文字は以上の経緯によりラテン語接頭辞 trans- と結びつけられたが,他にも (a)cross に結びつけられたり,Christ (英語の <ch> はギリシア語の <Χ> に対応することから)を表象したり,発音の類似から cryst- の略記としても用いられることがある.XMIT (= transmit), X-ing (= crossing), XREF (= cross-reference), Xmas (= Christmas), Xian (= Christian), XTAL (= crystal) の如くである.また,X はもっとストレートに ex- の略記でもある (ex. XL (= extra large), XOR (= exclusive-or)) .<x> の多機能性,恐るべし!
英語において,x は「#3654. x で始まる英単語が少ないのはなぜですか?」 ([2019-04-29-1]) で論じたように,語頭で用いられることが少ない.したがって,たまに語頭に現われると,他の文字よりも「情報価値」が高い.否,語頭ならずとも x は目を引く.注目を集めるための宣伝文句やキャッチフレーズに最適なのである.しかも,未知を表わす x という用法もある(cf. 「#2918. 「未知のもの」を表わす x」 ([2017-04-23-1])).変革の時代には,未知への挑戦という意味でポジティヴに評価されるのも頷ける.
日本語における DX という略称・表記は,上記のような背景をもちつつ,近年とみに持ち上げられるようになってきた.だが,英語においても同じように流行語的な位置づけにある略称・表記であるかどうかは疑問である.現代英語コーパスに当たってみると確かに使用例は認められ,そこそこ流行っている表現・概念であるとは言えるかもしれないが,英語圏において日本で盛り上がっているほどの特別な存在かどうかは怪しい.もう少し調査が必要である.
2018-08-11 Sat
■ #3393. コミュニケーションとは? [terminology][communication][information_theory]
コミュニケーション (communication) は,言語学でもよく使われる用語だが,一方で日常的に広く使われる用語でもある.実際,言語学でもかなり緩く用いられている.定義を確かめておこうと思い,Crystal の言語学辞典を引いてみた.それによると,communication とは次の通りである (89--90) .
communication (n.) A fundamental notion in the study of behaviour, which acts as a frame of reference for linguistic and phonetic studies. Communication refers to the transmission and reception of information (as 'message') between a source and a receiver using a signalling system: in linguistic contexts, source and receiver are interpreted in human terms, the system involved is a language, and the notion of response to (or acknowledgement of) the message becomes of crucial importance. In theory, communication is said to have taken place if the information received is the same as that sent: in practice, one has to allow for all kinds of interfering factors, or 'noise', which reduce the efficiency of the transmission (e.g. unintelligibility of articulation, idiosyncratic associations of words). One has also to allow for different levels of control in the transmission of the message: speakers' purposive selection of signals will be accompanied by signals which communicate 'despite themselves', as when voice quality signals the fact that a person has a cold, is tired/old/male, etc. The scientific study of all aspects of communication is sometimes called communication science: the domain includes linguistics and phonetics, their various branches, and relevant applications of associated subjects (e.g. acoustics, anatomy).
Human communication may take place using any of the available sensory modes (hearing, sight, etc.), and the differential study of these modes, as used in communicative activity, is carried on by semiotics. A contrast which is often made, especially by psychologists, is between verbal and non-verbal communication (NVC) to refer to the linguistic v. the non-linguistic features of communication (the latter including facial expressions, gestures, etc., both in humans and animals). However, the ambiguity of the term 'verbal' here, implying that language is basically a matter of 'words', makes this term of limited value to linguistics, and it is not usually used by them in this way.
いろいろと説明されているが,核心部分を端的に解釈すれば,コミュニケーションとは「2者間における信号体系を用いた情報の精確なやりとり」となろう.言語は,このようなコミュニケーションを達成するための手段の1つということになる.しかし,言語はコミュニケーションのためだけに用いられているわけではない.言語は,しばしば上記のコミュニケーションの定義から逸脱するような用いられ方もする.言語の諸機能 (function_of_language) については,以下の記事を参照されたい.「#523. 言語の機能と言語の変化」 ([2010-10-02-1]),「#1071. Jakobson による言語の6つの機能」 ([2012-04-02-1]),「#1862. Stern による言語の4つの機能」 ([2014-06-02-1]),「#1776. Ogden and Richards による言語の5つの機能」 ([2014-03-08-1]) .
もちろん,コミュニケーションの定義に含まれる「情報」 (information) とは何か,という大きな問題が残っている.これも厄介な問題だが,当面は「#1089. 情報理論と言語の余剰性」 ([2012-04-20-1]),「#1098. 情報理論が言語学に与えてくれる示唆を2点」 ([2012-04-29-1]) を含む information_theory の各記事を参照されたい.
・ Crystal, David, ed. A Dictionary of Linguistics and Phonetics. 6th ed. Malden, MA: Blackwell, 2008. 295--96.
2017-11-23 Thu
■ #3132. 暗号学と言語学 (2) [cryptology][linguistics][statistics][chaos_theory][information_theory]
最近,言語学とカオス理論 (chaos_theory) について少し調べているが,フラクタル図形「マンデルブロー集合」 (Mandelbrot set) で知られる数学者 Benoît Mandelbrot (1924--2010) が,情報理論や言語学に関する論考を著わしていることを知った(「マンデルブロー集合」については「#3123. カオスとフラクタル」 ([2017-11-14-1]) を参照).
Mandelbrot はその論考で,暗号学 (cryptology) と言語学の接点という話題にも触れている.本ブログでも「#2699. 暗号学と言語学」 ([2016-09-16-1]) の記事で,両分野の密接な関係について考えたことがあったので,ここで再び取り上げたい.その記事の第2段落で述べたことと Mandelbrot (552) の次の1節は,よく符合する.
. . . let us grant for the moment that the encoding and decoding machines may be as complicated as the designer may wish, and that the memory of the human links---using the common sense of the word "memory"---is unbounded. Under those ideal circumstances, it is obvious that any improvement of our understanding of the structure of language and of discourse will bring a possibility of improvement of the performance of the cryptographer or stenographer. For example, a knowledge of the rules of grammar will show that a given phrase will never be encountered in grammatically correct discourse; thus, if his employer were to speak only grammatical English, a stenographer would not need any special set of signs to designate the incorrect sentences. Similarly, a knowledge of the statistics of discourse will suggest that the "cliché" be represented by special short signs; in this way, the stenogram will be shortened and---since deciphering is very much helped by cliché---the code will be strengthened. That is, the ideal cryptographer and stenographer should make the utmost use of any available linguistic information.
暗号作成者は,言語の性質を知っていればいるほど,その性質の裏をかいた暗号文を作成できるし,逆に暗号解読者も,言語の性質を知っていればいるほど,そのように裏をかかれる可能性を減らすことができる.この意味で,暗号学は舞台を変えた言語学ともいえるのである.
・ Mandelbrot, Benoît. "Information Theory and Psycholinguistics." Scientific Psychology: Principles and Approaches. Ed. Benjamin B. Wolman and Ernest Nagel. New York: Basic Books, 1965. 550--62.
2016-01-07 Thu
■ #2446. 形態論における「補償の法則」 [morphology][category][functionalism][redundancy][information_theory][markedness][category]
昨日の記事「#2445. ボアズによる言語の無意識性と恣意性」 ([2016-01-06-1]) で引用した,樋口(訳)の Franz Boaz に関する章の最後 (p. 98) に,長らく不思議に思っていた問題への言及があった.
多くの言語が単数形で示しているほど複数形では明確で論理的な区別をしていないのはなぜか,という疑問を,解答困難なものとしてボアズは引用している.しかし,ヴィゴ・ブレンダル (Viggo Bröndal) は,形態論的形成の中の角の複雑さを避けるための手段が一般的に講じられている傾向があることを指摘した.しばしば分類上の一つの範疇に関して複雑である形式は他の範疇に関しては比較的単純である.この「補償の法則」によって,単数形よりも完全に特定されている複数形は,通例は比較的少数の表現形式を持っている.
英語史でいえば,この問題はいくつかの形で現われる.古英語において,名詞や形容詞の性や格による屈折形は,概して複数系列よりも単数系列のほうが多種で複雑である.3人称代名詞でもも,単数では hē (he), hēo (she), hit (it) と性に応じて3種類の異なる語幹が区別されるが,複数では性の区別は中和して hīe (they) のみと簡略化する.動詞の人称語尾も,単数主語では人称により異なる形態を取るのが普通だが,複数主語では人称にかかわらず1つの形態を取ることが多い.つまり,文法範疇の構成員のうち有標なものに関しては,おそらく意味・機能がそれだけ複雑である補償あるいは代償として,対応する形式は比較的単純なものに抑えられる,ということだろう.
しかし,考えてみれば,これは言語が機能的な体系であることを前提とすれば当前のことかもしれない.有標でかつ複雑な体系は,使用者に負担がかかりすぎ,存続するのが難しいはずだからだ.「補償の法則」は,頻度,余剰性,費用といった機能主義的な諸概念とも深く関係するだろう (see 「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1])) .
もっとも,この「補償の法則」は一般的に観察される傾向というべきものであり,通言語的にも反例は少なからずあるだろうし,逆の方向の通時的な変化もないわけではないだろう.
・ 樋口 時弘 『言語学者列伝 ?近代言語学史を飾った天才・異才たちの実像?』 朝日出版社,2010年.
2015-09-07 Mon
■ #2324. n-gram [corpus][information_theory][coca][bnc][google_books][statistics][n-gram][collocation][frequency][link]
情報理論や自然言語処理の分野で用いられる n-gram という分析手法がある.コーパス言語学でもすでにお馴染みの概念であり,共起表現 (collocation) の研究などでは当たり前のように用いられるようになった.種々のコーパスのインターフェースにおいても採用されており,「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) では名前に含まれているほどだし,本ブログでも COCA (Corpus of Contemporary American English) の N-gram データベースを用いて「#956. COCA N-Gram Search」 ([2011-12-09-1]) を実装してきた(その応用は,「#953. 頭韻を踏む2項イディオム」 ([2011-12-06-1]),「#954. 脚韻を踏む2項イディオム」 ([2011-12-07-1]),「#955. 完璧な語呂合わせの2項イディオム」 ([2011-12-08-1]) を参照).BNC では,Explore Words and Phrases from the BNC が利用できる.
コンピュータを用いた分析手法というと難しそうに聞こえるが,n-gram の考え方は至って単純である.文字レベルの 2-gram (bigram) を考えてみよう.最長の英単語といわれる pneumonoultramicroscopicsilicovolcanoconiosis (「#63. 塵肺症は英語で最も重い病気?」 ([2009-06-30-1])) を例にとる.まず,先頭の2文字1組の pn を取り出す.次に,2文字目に進んで同じように ne を取り出す.3文字目に進んで eu を,4文字目に進んで um を得る.同じように,1文字ずつ右にずらしながら,最後の is まで2文字1組を次々と拾っていく.これで44組の2文字を得たことになる.この組のなかで,ic と co という組み合わせは各々3回起こり,os, si, no, on の組み合わせは各々2回現われ,それ以外の組み合わせはいずれも1度きりである.したがって,この単語において最高頻度の2文字1組は ic と co となる.
n-gram の単位は,このように文字である必要はなく,音素でもよいし,より大きな単位である形態素や語でもよく,さらに大きな句などのより大きな単位でもよい.英語コーパス言語学では,語という単位で考えるのが普通だろう.Martin Luther King, Jr. の I Have a Dream の演説のテキストで語単位の 4-gram を取ると,最も多い4語の組み合わせは,予想通り "I have a dream" の8回だが,"will be able to" も同じく8回現われる."Let freedom ring from" も7回とよく現われる,等々の分析が可能となる.ここでは4語という「窓」を設定したので 4-gram と呼ばれるが,隣接するいくつの文字を考慮するかにより 1-gram (unigram), 2-gram (bigram), 3-gram (trigram),そして 5-gram 以上ももちろん考えることができる(1-gram の場合,得られるリストは,事実上各語の生起頻度表である).
巨大コーパスから得られた 2-gram や 3-gram の一覧は,それ自体が共起表現の研究などでは基本データとなるため,ウェブ上でもいろいろと公開されている.日本語では「N-gram コーパス - 日本語ウェブコーパス 2010」があるし,現代英語では COCA の n-gram データベース がある.また,Bigram Plus では,歴史英語コーパスを含めた各種英語コーパスから N-Gram Search を行なえる機能を提供している.ほかにも任意のテキストやコーパスを対象に n-gram を取る各種のツールやソフトも,ウェブ上で入手可能だ.
n-gram 分析の言語分野への応用範囲は広い.次に来る語(音,文字)は何か,という予測可能性とも関係が深いため,機械による音声認識,統語分析,言語判定,自動翻訳,スペルチェック,剽窃探知,全文検索用インデックスの作成などに活用される.もちろん,共起表現の研究では,基本にして不可欠の手段となっている.一方,n-gram はもっぱら言語として表面化されたテキストを対象とし,深層にある構造にまったく触れることがないため,生成文法のような言語理論の方面からは批判があるようだ.詳しくは,n-gram in Wikipedia を参照.
n-gram は工夫次第で,まだまだ使い道がありそうだ.歴史英語テキストにも,応用していきたい.
(後記 2015/09/12(Sat): Sketch Engine より N-grams も参照.)
2015-08-21 Fri
■ #2307. 綴字の余剰性 (2) [spelling][redundancy][statistics][information_theory][alphabet][final_e][silent_letter]
「#2249. 綴字の余剰性」 ([2015-06-24-1]) で取り上げた話題.別の観点から英語綴字の余剰性を考えてみよう.
Roman alphabet のような単音文字体系にあっては,1文字と1音素が対応するのが原理的に望ましい.しかし,言語的,歴史的,その他の事情で,この理想はまず実現されないといってよい.現実は理想の1対1から逸脱しているのだが,では,具体的にはどの程度逸脱しているのだろうか.
ここで,「#1159. MRC Psycholinguistic Database Search」 ([2012-06-29-1]) を利用して,文字と音素の対応の度合いをおよそ計測してみることができる.もし理想通りの単音文字体系であれば,単語の綴字を構成する文字数と,その発音を構成する音素数は一致するだろう.英語語彙を構成する各単語について,文字数と音素数の比を求め,その全体の平均値などの統計値を出せば,具体的な指標が得られるはずだ.綴字が余剰的 (redundancy) であるということはこれまでの議論からも予想されるところではあるが,具体的に,文字数対音素数の比は,2:1 程度なのか 3:1 程度なのか,どうなのだろうか.
まずは,MRC Psycholinguistic Database Search を以下のように検索して,単語ごとの,文字数,音素数,両者の比(=余剰性の指標)の一覧を得る(SQL文の where 以下は,雑音を排除するための条件指定).
select WORD, NLET, NPHON, NLET/NPHON as REDUNDANCY, PHON from mrc2 where NPHON != "00" and WORD != "" and PHON != "";
この一覧をもとに,各種の統計値を計算すればよい.文字数と音素数の比の平均値は,1.192025 だった.比を0.2刻みにとった度数分布図を示そう.
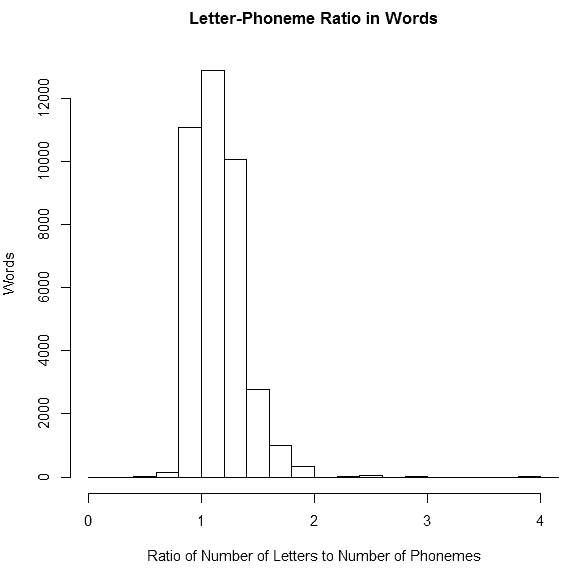
文字数別に比の平均値をとってみると,興味深いことに3文字以下の単語では余剰性は 1.166174 にとどまり,全体の平均値より小さくなる.一方,4文字から7文字までの単語では平均より高い 1.231737 という値を示す.8文字以上になると再び余剰性は小さくなり,1.157689 となる.文字数で数えて中間程度の長さの単語で余剰性が高く,短い単語と長い単語ではむしろ相対的に余剰性が低いようだ.この理由については詳しく分析していないが,「#1160. MRC Psychological Database より各種統計を視覚化」 ([2012-06-30-1]) でみたように,英単語で最も多い構成が8文字,6音素であるということや,final_e をはじめとする黙字 (silent_letter) の分布と何らかの関係があるかもしれない.
さて,全体の平均値 1.192025 で示される余剰性の程度がどれくらいのものなのか,ほかに比較対象がないので評価にしにくいが,主観的にいえば理想の値 1.0 から案外と隔たっていないなという印象である.英単語における文字と音素の関係は,「#2292. 綴字と発音はロープでつながれた2艘のボート」 ([2015-08-06-1]) の比喩でいえば,そこそこよく張られた短めのロープで結ばれた関係ともいえるのではないか.
ただし,今回の数値について注意すべきは,英単語における文字と音素の対応を一つひとつ照らし合わせてはじき出したものではなく,本来はもっと複雑に対応するはずの両者の関係を,それぞれの長さという数値に落とし込んで比を取ったものにすぎないということだ.最終的に求めたい綴字の余剰性そのものではなく,それをある観点から示唆する指標といったほうがよいだろう.それでも,目安となるには違いない.
2015-06-24 Wed
■ #2249. 綴字の余剰性 [spelling][orthography][cgi][web_service][redundancy][information_theory][punctuation][shortening][alphabet][q]
言語の余剰性 (redundancy) や費用の問題について,「#1089. 情報理論と言語の余剰性」 ([2012-04-20-1]),「#1090. 言語の余剰性」 ([2012-04-21-1]),「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]),「#1098. 情報理論が言語学に与えてくれる示唆を2点」 ([2012-04-29-1]),「#1101. Zipf's law」 ([2012-05-02-1]) などで議論してきた.言語体系を全体としてみた場合の余剰性のほかに,例えば英語の綴字という局所的な体系における余剰性を考えることもできる.「#1599. Qantas の発音」 ([2013-09-12-1]) で少しく論じた通り,例えば <q> の後には <u> が現われることが非常に高い確立で期待されるため,<qu> は余剰性の極めて高い文字連鎖ということができる.
英語の綴字体系は全体としてみても余剰性が高い.そのため,英語の語彙,形態,統語,語用などに関する理論上,運用上の知識が豊富であれば,必ずしも正書法通りに綴られていなくとも,十分に文章を読解することができる.個々の単語の綴字の規範からの逸脱はもとより,大文字・小文字の区別をなくしたり,分かち書きその他の句読法を省略しても,可読性は多少落ちるものの,およそ解読することは可能だろう.一般に言語の変化や変異において形式上の短縮 (shortening) が日常茶飯事であることを考えれば,非標準的な書き言葉においても,綴字における短縮が頻繁に生じるだろうことは容易に想像される.情報理論の観点からは,可読性の確保と費用の最小化は常に対立しあう関係にあり,両者の力がいずれかに偏りすぎないような形で,綴字体系もバランスを維持しているものと考えられる.
いずれか一方に力が偏りすぎると体系として機能しなくなるものの,多少の偏りにとどまる限りは,なんとか用を足すものである.主として携帯機器用に提供されている最近の Short Messages Service (SMS) では,使用者は,字数の制約をクリアするために,メッセージを解読可能な範囲内でなるべく圧縮する必要に迫られる.英語のメッセージについていえば,綴字の余剰性を最小にするような文字列処理プログラムにかけることによって,実際に相当の圧縮率を得ることができる.電信文体の現代版といったところか.
実際に,それを体験してみよう.以下の "Text Squeezer" は,母音削除を主たる方針とするメッセージ圧縮プログラムの1つである(Perl モジュール Lingua::EN::Squeeze を使用).入力するテキストにもよるが,10%以上の圧縮率を得られる.出力テキストは,確かに可読性は落ちるが,慣れてくるとそれなりの用を足すことがわかる.適当な量の正書法で書かれた英文を放り込んで,英語正書法がいかに余剰であるかを確かめてもらいたい.
2015-04-14 Tue
■ #2178. 新グライス学派語用論の立場からみる意味の一般化と特殊化 [semantic_change][pragmatics][cooperative_principle][implicature][zipfs_law][information_theory][hyponymy]
Grice の協調の原理 (cooperative_principle) と会話的含意 (implicature) について,「#1122. 協調の原理」 ([2012-05-23-1]),「#1133. 協調の原理の合理性」 ([2012-06-03-1]),「#1134. 協調の原理が破られるとき」 ([2012-06-04-1]),「#1976. 会話的含意とその他の様々な含意」 ([2014-09-24-1]),「#1984. 会話的含意と意味変化」 ([2014-10-02-1]) などの記事で話題にしてきた.Grice の理論は語用論に革命をもたらし,その後の研究の進展にも大きな影響を及ぼしたが,なかでも新グライス学派 (Neo-Gricean) による理論の発展は注目に値する.
新グライス学派を牽引した Laurence R. Horn は,Grice の挙げた4つの公理 (Quality, Quantity, Relation, Manner) を2つの原理へと再編成した.Q[uantity]-principle と R[elation]-principle とである.両原理の定式化は,以下の通りである (Huang 38 より).
Horn's Q- and R-principles
a. The Q-principle
Make your contribution sufficient;
Say as much as you can (given the R-principle)
b. The R-principle
Make your contribution necessary;
Say no more than you must (given the Q-principle)
Q-principle はより多くの情報を提供しようとする原理であり,R-principle はより少ない情報で済ませようとする原理である.この観点からは,会話の語用論とは両原理のせめぎ合いにほかならない.ここには言語使用における "most effective, least effort" の思想が反映されており,言語使用の経済的な原理であるジップの法則(Zipf's Law;cf. 「#1101. Zipf's law」 ([2012-05-02-1]))とも深く関係する.Huang (39--40) 曰く,
Viewing the Q- and R-principles as mere instantiations of Zipfian economy . . ., Horn explicitly identified the Q-principle ('a hearer-oriented economy for the maximization of informational content') with Zipf's Auditor's Economy (the Force of Diversification) and the R-principle ('a speaker-oriented economy for the minimization of linguistic form') with Zipf's Speaker's Economy (the Force of Unification).
さて,意味変化の代表的な種類として,一般化 (generalization) と特殊化 (specialization) がある.それぞれの具体例は,「#473. 意味変化の典型的なパターン」 ([2010-08-13-1]),「#2060. 意味論の用語集にみる意味変化の分類」 ([2014-12-17-1]),「#2102. 英語史における意味の拡大と縮小の例」 ([2015-01-28-1]) で挙げた通りであり,繰り返さない.ここでは,意味の一般化と特殊化が,新グライス学派の語用論の立場から,それぞれ R-principle と Q-principle に対応するものしてとらえることができる点に注目したい.
ある語が意味の一般化を経ると,それが使用される文脈は多くなるが,逆説的にその語の情報量は小さくなる.つまり,意味の一般化とは情報量が小さくなることである.すると,この過程は,必要最小限の情報を与えればよいとする R-principle,すなわち話し手の側の経済によって動機づけられているに違いない.
一方で,ある語が意味の特殊化を経ると,それが使用される文脈は少なくなるが,逆説的にその語の情報量は大きくなる.つまり,意味の特殊化とは情報量が大きくなることである.すると,この過程は,できるだけ多くの情報を与えようとする Q-principle,すなわち聞き手の側の経済によって動機づけられているに違いない (Luján 293--95) .
このようなとらえ方は,意味変化の類型について語用論の立場から議論できる可能性を示している.
・ Huang, Yan. Pragmatics. Oxford: OUP, 2007.
・ Luján, Eugenio R. "Semantic Change." Chapter 16 of Continuum Companion to Historical Linguistics. Ed. Silvia Luraghi and Vit Bubenik. London: Continuum International, 2010. 286--310.
2014-09-18 Thu
■ #1970. 多義性と頻度の相関関係 [polysemy][zipfs_law][information_theory][frequency][statistics]
基本語彙と呼ばれるものの多面的な性質について「#1960. 英語語彙のピラミッド構造」 ([2014-09-08-1]) で触れた.基本語彙とは,日常的で頻度が高く,早期に習得され,変化しにくく,意味・用法が多岐にわたるなどの特徴をもつ.関連する話題は,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]),「#1089. 情報理論と言語の余剰性」 ([2012-04-20-1]),「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]),「#1101. Zipf's law」 ([2012-05-02-1]),「#1874. 高頻度語の語義の保守性」 ([2014-06-14-1]),「#1961. 基本レベル範疇」 ([2014-09-09-1]),「#1965. 普遍的な語彙素」 ([2014-09-13-1]) その他の記事でいろいろと扱ってきた.
今回は,この問題と関連して,高頻度語は多義的であるという命題について考えてみたい.頻度の高い語ほど語義を多くもち,頻度の低い語は語義を多くもたないということは言語使用の事実に照らして実証されるだろうか.また,理論的にいかに説明されるだろうか.Zipf's law で知られる Zipf は,情報理論の立場からこの課題に挑んだ.
Zipf は,E. L. Thorndike の英語最頻20,000語と Thorndike-Century Senior Dictionary に基づき,語の頻度と語義数の相関関係を探った.この辞書は,古語や廃語などの特殊な register をもつ語義は掲載しておらず,一般的に用いられる語義のみを掲載している.丹念に調査した結果,ある頻度域と,そこに属する語が示す平均語義数との間に,明らかな相関関係が見いだされた.以下は,Zipf (253) に示されているグラフを再現したものである.両軸ともに対数軸であり,X軸は頻度順位を,Y軸は頻度域の平均語義数を表わす.
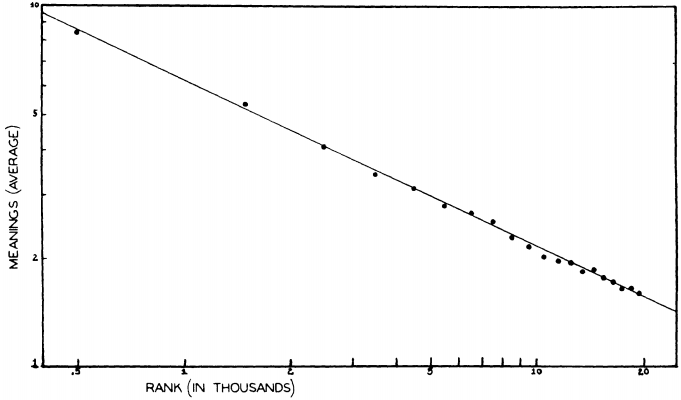
傾きはほぼ0.5に等しく,これは話者の発話と聴者の聴解にかかる費用に関する理論の予測と符合するという.その理論の数学的裏付けは私の理解を超えるので解説できないが,Zipf は結論として語の語義数と頻度(順位)の関係について次のように定式化した (Zipf 255) .
. . . different meanings of a word will tend to be equal to the square root of its relative frequencies (with the possible exception of the few dozen most frequent words)
背景には,多義の定義やある語の語義をいかに区分するかといった意味論の側で問うべき問題もおおいにあるが,示唆に富んだ結論である.関連して,「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]) や zipfs_law の各記事も参照されたい.
・ Zipf, G. K. "The Meaning-Frequency Relationship of Words." Journal of General Psychology 33 (1945): 251--66.
2013-09-12 Thu
■ #1599. Qantas の発音 [acronym][pronunciation][information_theory][redundancy][alphabet][q]
8月後半にオーストラリアに出かけていたが,その往復に初めて Qantas 機を利用した.成田・シドニー路線の機内は非常に広々としており,実に快適なフライトだった.日本語では「カンタス」と呼び習わしているが,機内の放送で [ˈkwɑntəs] の発音を聞いた.Q の文字に対応するだけに,子音は [k] ではなく [kw] なのだ.
Qantas は "Queensland and Northern Territory Aerial Services" の頭字語 (acronym) である.1920年に名前の通りオーストラリアのローカルな航空会社として創設されたが,47年に国営化され,現在では世界有数の国際的な航空会社である.創業してから無事故とされ(事故の定義にもよるが),安全面での評価も高い.
英語本来語あるいは英語に入って歴史の長い語のなかでは,通常 <q> は単独で用いられることはなく,<qu> と必ず直後に <u> を伴う.歴史的には,古英語で <cw> と綴られていたものが,中英語でフランスの写字習慣に習って <qu> と綴られるようになったものだ.<q> の後に原則として <u> が続くということは,情報価値という観点から言い換えれば「<u> の情報量はゼロである」ということになる.<u> が続くことは100%予想できるので,<u> はなくても同じということになるからだ.機能上,<q> の後の <u> は不要ということになるのだが,<qu> の連続に慣れてしまった目には <q> 単独は妙に見える.綴字レベルでも,言語の余剰性 (redundancy) が作用している証だろう.
もっとも,頭字語,アラビア語や中国語からの借用語など,完全に英語に同化したとはみなせない語群では,<q> の後に <u> が続かないことも多い.表題の Qantas は綴字としては <q> 単独で用いられているが,発音としては単独の [k] ではなく [kw] を示している.Qatar [ˈkæːtɑː], qibla(h) [ˈkɪblə], Qing [ʧɪŋ], また <u> が後続するものの [kw] を示さない Quran [kɔːˈrɑːn] も参照.
なお,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]) の末尾で見たように,<q> は英語で <z> に次いで最も使用頻度の低いアルファベットの文字である(<z> については z の各記事を参照).キーボードのQWERTY配列でも,その名が示すとおり,<Q> は左手の小指を差しのばして打たなければならない日陰者である.QWERTY 自体が一種の頭字語であり,<q> の後に <w> が続き,かつ [w] が発音されるまれな例である.
2012-09-05 Wed
■ #1227. 情報理論と意味作用 [information_theory][frequency][sign][semantics]
「#1108. 言語記号の恣意性,有縁性,無縁性」 ([2012-05-09-1]) や「#1110. Guiraud による言語学の構成部門」 ([2012-05-11-1]) で参照した意味論学者の Guiraud は,情報理論 (information_theory) の言語学への応用にも関心が深く,言語体系や言語記号のもつ余剰性,頻度,費用などの問題を考察している.
1954年の論文を読み,多くの示唆的な洞察が得られた.例えば,シニフィアン,シニフィエ,頻度,長さの関係について次のように述べられている (128) .最初はシニフィエがシニフィアンを「選ぶ」,言い換えれば最も短いシニフィアンが最も頻度の高いシニフィエに割り当てられる.それから,シニフィアンが語の用法を「駆動し」,それに「変更を加える」.
このシニフィアンとシニフィエの相互関係が含意するのは,何らかの理由で頻度や意味や形態が変化してゆくと,それまで保たれていた両者の間の均衡が崩れるために,記号体系の調整機能が発動し,均衡を取り戻そうとするということである.別の見方をすれば,言語変化は,情報伝達の効率が最大限に保たれ得る限りにおいて起こるということになる.言語体系も情報体系の1つである以上,情報に関わる一般原理である「効率」に従わざるを得ないという結論になろう.
情報理論では「効率」が論じられ,「意味」は捨象されるのが普通だが,意味論の専門家としての Guiraud は,次のような方法で情報理論の知見を意味作用の問題に活かそうと考えている.客観的に数字で表わされる頻度と長さという指標を利用して,目に見えないシニフィアンとシニフィエの関係を探れるのではないか.
La relation coût/information (ou forme/fréquence) traduit objectivement ces rapports entre le signe et le concept et permet de poser en termes objectifs le problème de la signification. (128)
費用/情報(あるいは形態/頻度)の関係はシニフィアンとシニフィエの間のこれらの関係を客観的に表わすものであり,意味作用の問題を客観的に提示することを可能にしてくれる.
・ Guiraud, P. "Langage et communication. Le substrat informationnel de la sémantisation." Bulletin de la société de linguistique de Paris 50 (1954): 119--33.
2012-05-03 Thu
■ #1102. Zipf's law と語の新陳代謝 [information_theory][frequency][statistics][zipfs_law][shortening][language_change]
昨日の記事[2012-05-02-1]で Zipf's law について概説した.Zipf's law には派生した「法則」が多くあり,その1つに,[2012-04-22-1]の記事「#1091. 言語の余剰性,頻度,費用」でも指摘した「言語要素は,頻度が高ければ音形が短い」というものがある.これを,より動的に,通時的に表現すると「言語要素は,頻度が高くなれば音形が短くなる」となる.ある語の頻度が高くなってゆくと,ある程度の遅延はあるものの,その音形が短くされてゆく傾向のあることは,私たちも経験的によく知っていることである.「#878. Algeo と Bauer の新語ソース調査の比較」([2011-09-22-1]) や「#879. Algeo の新語ソース調査から示唆される通時的傾向」([2011-09-23-1]) で見たとおり,現代英語の新語ソースとして短縮 (shortening) による語形成が増加しており,例には事欠かない.
この Zipf's law の派生法則のもつ共時的意義と通時的意義を合わせて考えると,語の頻度と長さによって,それが老いゆく語 (senescent word) なのか,生まれつつある語 (nascent word) なのかを区別できるという可能性が生じる.Zipf 著 Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology の書評を著わした Chao (399) より,関連箇所を引用しよう.
A very interesting application of the tool analogy is that of senescent and nascent tools in connection with the Principle of Economical Specialization. Reasoning from tool efficiency yields the result that 'whenever we find a tool (or word) whose magnitude is smaller than that of its neighbors in the frequency range, we may conclude that the tool (or word) of below-average size is an older tool (or word) whose usage is on the decrease (hereinafter we shall call this a senescent tool)', and 'whenever we find a tool (or word) whose magnitude is above average for its frequency, we may conclude not only that it is a newer tool (or word), but that its usage may well be directed toward an increase (hereinafter we shall call this a nascent tool)' (72). The application to words is verified to a fair degree for English of various periods (111). By regarding all behavior as work and words as tools, the analogy becomes a case and the qualifier 'or word' can be omitted.
音形の比較的短いある単語 A を考える.Zipf's law によれば,A は比較的頻度の高い語だと予想されるが,実際には同程度の頻度を示す他の多くの語に比べると音形が短すぎたとする.この場合,おそらく A はさかりを過ぎて頻度が徐々に低まってきた senescent word と考えてよいだろう.反対に,音形の比較的長いある単語 B を考える.Zipf's law によれば,B は比較的頻度の低い語だと予想されるが,実際には同程度の頻度を示す他の多くの語に比べると音形が長すぎたとする.この場合,おそらく B はこれから頻度がますます増してゆき,短縮を起こしてゆくと予想される nascent word と考えてよいだろう.これは,Zipf's law に,冒頭に述べた時間的遅延とを掛け合わせた応用法則といってよい.
通常 Zipf's law は静的で共時的な統計的法則ととらえられているが,動的で通時的な観点から,語の新陳代謝の法則として再解釈してみるとおもしろい.
・ Chao, Y. R. "Review of Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology by George Kingsley Zipf." Language 26 (1950): 394--401.
2012-05-02 Wed
■ #1101. Zipf's law [information_theory][frequency][statistics][language_change][zipfs_law][shortening][pragmatics][zipfs_law]
##1089,1090,1091,1098 の記事で,情報理論 (information theory) が言語学に与えてくれる知見について,いくつか見てきた.情報理論からの貢献として,最もよく知られているものの1つに,アメリカの言語学者 George Kingsley Zipf (1902--50) が1949年に Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology において提唱した Zipf's law (ジップの法則)がある.語の頻度についての経験的な法則であり,語の頻度を f とし,その頻度の順位を r とすると,その積 C はほぼ定数となるという.
r × f = C
この法則は,言語,テキストの主題,著者,その他の言語的な変数にかかわらず成り立つとされるが,実際には頻度が最高および最低の語群については誤差の大きいことがわかっており,信頼性は高くないとして批判も多い.また,r (頻度順位)は当然ながら f (頻度)に依存しており,f が増えれば r が減るのは自明であるから,その積が近似値をとるということは驚くべき帰結ではない,一種のトートロジーであるという批判がある.しかし,経験的事実に照らして法則とまではいわずとも傾向をよく表わしているということはでき,これを明示的に指摘した意義は大きい.
Zipf's law の波及効果は多岐にわたる.例えば,この法則によれば,使用頻度の高い語からその使用頻度の累計を求めて行くと比較的少数の語で延べ語数の大部分を占めることから,学習基本語彙の設定に根拠を与えるものとなる.また,この法則に適合しない頻度分布を示す語彙があるとすれば,他の特殊な要因が関与している可能性が疑われるとされる(少数の語の頻度があまりに高すぎれば語彙の貧弱化が生じていると診断されるし,頻度の低いはずの語が高頻度で用いられている場合には爆発的な新造語彙や精神分裂症が原因と想定される等々).
Zipf's law は,人間の行動を司るとされるより大きな原則,the Principle of Least Effort (最小努力の原則)の一部であり,その言語への応用は,上記の最もよく知られた頻度と頻度順の関係の公式化のみならず,他の公式の提案にも及んでいる.例えば,語の頻度と語の長さは反比例の関係にある,というものもある.最頻語は単音節であることが多いという事実(音節数の分布調査については ##348,349,355 を参照)や,頻度が高くなると頭字語などのように短縮・省略されることが多いという事実も,この公式で説明される.ほかには,ある頻度範囲とそれに属する語の数の関係を表わす公式,調音の難しい音素は頻度が低いとする原則など,派生した法則は数多い.語用論の cooperative principle (協調の原則)における量の格律「(その状況において)必要とされている(だけの)情報を与えよ」とも関与するだろう."effort" の定義などの難しい問題が残っており,また最小努力が人間の行動を司る唯一の原則であるとは考えることもできないが,真理の一面をついたものとして重要な学説であることは間違いない.
なお,諸文献では,上記のいずれの原則も Zipf's law として言及されることがあり,また Zipf's laws と複数形でまとめられたり,the Principle of Least Effort と総括されたりすることもあるので注意が必要である.Zipf の著書の書評としては Chao を参照.類似の統計的法則については,Crystal (86--87) を参照.
・ Chao, Y. R. "Review of Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology by George Kingsley Zipf." Language 26 (1950): 394--401.
・ Crystal, David. The Cambridge Encyclopedia of Language. 2nd ed. Cambridge: CUP, 1997.
2012-04-29 Sun
■ #1098. 情報理論が言語学に与えてくれる示唆を2点 [information_theory][redundancy][corpus]
##1089,1090,1091 の記事で,言語学が情報理論 (information theory) から得られる知見について,特に言語の余剰性 (redundancy) に注目しながら紹介した.今回は,Jakobson による "Linguistics and Communication Theory" と題する論文にしたがって,情報理論が言語学に与えてくれるヒントを考えてみたい.
Jakobson は,彼の提示した二進法的な音素の示差的特徴 (distinctive feature) と,情報理論における基本単位である "digit" あるいは "bit" との親和性に気づき,(構造)言語学と情報理論の接点に注目した.Jakobson は両分野の共通点と相違点を洗い出し,言語学が情報言語から学べることは何か,両者の間で同一視してはいけないことは何かということを論じている.その中で特に2点が私の関心に引っかかったので,紹介したい.
(1) 情報理論は,もっぱら物理的な情報伝達の効率や情報体系の仕組み (code) に関心があり,その発信者,受信者,文脈,意味は考慮しない.言語体系も code ではあるが,それは言語行動が必要とする諸側面の1つにすぎず,code のみに注目する態度は避けるべきである.code が1側面にすぎないことは「#1070. Jakobson による言語行動に不可欠な6つの構成要素」 ([2012-04-01-1]) で見たとおりである.
There is a similar danger when interpreting human inter-communication in terms of physical information. Attempts to construct a model of language without any relation either to the speaker or to the hearer and thus to hypostasize a code detached from actual communication threaten to make a scholastic fiction from language. (250)
(2) 言語学が (1) の注意点を意識した上で,情報理論の手法を用いて言語体系の効率を測ろうとするとき,二項対立の体系としての理論的な効率と,言語項目の頻度を考慮した実際上の効率との両方を視野に入れておかなければならない.前者は type 的,langue 的な意味での効率,後者は token 的,parole 的な意味での効率といえばわかりやすいだろうか.Jakobson は,音素の示唆的特徴だけでなく形態カテゴリーも二項対立で記述でき,最終的には統語をも "bit" によって記述できると考えており,それにより言語Aと言語Bの文法情報の効率なども比較できるだろうとしているが,これは抽象化された言語体系としての code の効率のことを指している.一方で,言語使用の実際における情報伝達の効率を測ろうとすれば,言語項目の出現頻度を加味した情報の重みづけという作業が必要である.理論と実際のバランスが肝要ということである.
The amount of grammatical information which is potentially contained in the paradigms of a given language (statistics of the code) must be further confronted with a similar amount in the tokens, in the actual occurrences of the various grammatical forms within a corpus of messages. Any attempt to ignore this duality and to confine linguistic analysis and calculation only to the code or only to the corpus impoverishes the research. The crucial question of relationship between the patterning of the constituents of the verbal code and their relative frequency both in the code and in its use cannot be passed over. (251)
(2) の教訓を現代の言語研究に引きつけて解釈すると,構造言語学とコーパス言語学の連携というような課題につながってくるのではないか.コーパスによって得られた統計値をもとに各言語項目に重みづけを行ない,それを対立の集合として記述された言語体系のパラメータとして含めてやる.そうすることによって,Martinet の主張する言語の経済性の原理 ([2012-03-24-1], [2012-04-21-1]) なども検証可能となるのではないか.
・ Jakobson, Roman. "Linguistics and Communication Theory." Structure of Language and Its Mathematical Aspects. Providence: American Mathematical Society, 1961. 245--52.
2012-04-22 Sun
■ #1091. 言語の余剰性,頻度,費用 [redundancy][information_theory][frequency][shortening][grammaticalisation][idiom][intensifier][language_change]
本ブログでも度々取り上げている André Martinet (1908--99) は,情報理論の知見を言語学に応用し,独自の地平を開いた構造言語学者である.[2012-04-20-1], [2012-04-21-1]の記事で,言語の余剰性 (redundancy) の問題に触れてきたが,Martinet は余剰性と関連させて確率 (probability) ,情報 (information) ,頻度 (frequency) ,費用 (cost) といった概念をも導入し,これらの関係のなかに言語変化の原因を探ろうとした.以下は,これらの用語を導入した後の一節である(拙訳つきで).
Ce qu'il convient de retenir de tout ceci pour comprendre la dynamique linguistique se ramène aux constatations suivantes : il existe un rapport constant et inverse entre la fréquence d'une unité et l'information qu'elle apporte, c'est-à-dire, en un certain sens, son efficacité ; il tend à s'établir un rapport constant et inverse entre la fréquence d'une unité et son coût, c'est-à-dire que représente d'énergie consommée chaque utilisation de cette unité. Un corollaire de ces deux constatations est que toute modification de la fréquence d'une unité entraîne une variation de son efficacité et laisse prévoir une modification de sa forme. Cette dernière pourra ne se produire qu'à longe échéance, car les condition réelles du fonctionnement des langues tendent à freiner les évolutions. (189--90)
言語の力学を理解するために,このこと全体について理解すべきことは,次の確認事項である.ある単位の頻度とそれがもつ情報(すなわちある意味ではその効果)のあいだには一定にして反比例の関係がある;それは,ある単位の頻度とその費用(すなわちその単位を使用することで消費されるエネルギー)のあいだの一定にして反比例の関係となる傾向がある.この2つの確認事項の当然の帰結として,ある単位の頻度が変わればその効果も変化するし,その形態の変化も予想されることになる.この後者の変化はあくまで長期間をかけて生じるものである.というのは,言語作用の現実の状況は発達を抑制する傾向があるからだ.
Martinet は,引用した節よりも前の箇所で,余剰性が高いということは予測可能性が高いということであり,それは言語要素の出現確率あるいは頻度とも密接に関連するということを論じている.一般に,言語要素は頻度が高ければ余剰性も高く,情報価値は低い: "plus une unité (mot, monème, phonème) est fréquente, moins elle est informative" (188) .そして,ここに費用という要素を持ち込むことによって,新たな洞察が得られた.話者にとって,頻度が高ければ高いほど,その1回の発音に必要とされるエネルギーの量は少ないほうが都合がよい.多くのエネルギーを要する発音を何度も繰り返すのは不経済だからだ.逆に,頻度の低い表現は,たとえ発音に大きなエネルギーが必要だとしてもあまり困らない.いずれにせよ,発音する機会が稀だからだ.
このように,「費用」を発音にかかるエネルギー量と解釈する場合,厳密には個々の音の発音がどのくらいの費用を要するかを知る必要があるが,その計測は難しい.しかし,仮にすべての単音の発音が同じ程度の費用を要すると仮定すれば,特定の表現に要する費用はその音形の長さに依存するはずである.費用を単純に音形の長さと同値とすれば,次の関係が想定できる:「言語要素は,頻度が高ければ音形が短い」.これを言語変化に当てはめれば「言語要素は,頻度が高くなれば音形が短くなる」となろう.
頻度と費用の反比例の関係は,経験的によく理解できる.よく使われる語句は発音においても表記においても短縮・省略される傾向がある.場合によっては,短縮・省略の究極の結末として,無に帰すことすらある.文法的な慣用表現が短縮した上で固定化する例もよく見られ,これは文法化 (grammaticalisation) として扱われる話題にほかならない.また,[2012-01-14-1]の記事で取り上げた「#992. 強意語と「限界効用逓減の法則」」も,頻度と費用の関係という観点からとらえなおすことができるだろう.
ただし,上の引用の最後にある通り,頻度と費用の関係から言語変化を説明しようとする際には,時間差を考慮する必要がある.ある語の頻度が増してきてからその語形が短縮されるまでには,当然,ある程度の時間が必要だからだ.また,頻度と費用の負の相関関係は,あくまで緩やかなものであることにも注意しておく必要がある.上の一節に先行する標題が "Laxité du rapport entre fréquence et coût" (頻度と費用の関係の緩やかさ)であることを付け加えておこう.
・ Martinet, André. Éléments de linguistique générale. 5th ed. Armand Colin: Paris, 2008.
2012-04-21 Sat
■ #1090. 言語の余剰性 [redundancy][linguistics][entropy][information_theory][paralinguistics]
ヒトの言語の著しい特徴として,以前の記事で「#766. 言語の線状性」 ([2011-06-02-1]) と「#767. 言語の二重分節」 ([2011-06-03-1]) を取り上げてきたが,もう1つの注目すべき特徴としての余剰性 (redundancy) については,明示的に取り上げたことがなかった.今日は,昨日の記事「#1089. 情報理論と言語の余剰性」 ([2012-04-20-1]) を受けて,この特徴について説明したい.
言語による意味の伝達に最小限に必要とされる以上の記号的要素が用いられるとき,そこに余剰性が含まれているといわれる.言語の余剰性は一見すると無駄で非効率に思われるが,昨日の記事で述べたように,言語使用に伴う種々の雑音 (noise) に対する強力な武器を提供している.急ハンドルの危険を防止するハンドルの遊びと言い換えてもよいし,無用の用と考えてもよい.また,言語の余剰性は,言語習得にも欠かせない.言語構造上また言語使用上の余剰性が十分にあれば未知の言語要素でも意味の予測が可能であり,実際に言語習得者はこの機構を利用して,言語内的・外的な文脈からヒントを得ながら,意味の見当をつけてゆくのである.
余剰性という観点から言語を見始めると,それは言語のあらゆる側面に関わってくる要素だということがわかる.まず,昨日の記事で触れたように,音声と音素の情報量の差に基づく余剰性がある.言語の伝達には数十個の分節された音素を区別すれば事足りるが,その実現は音声の連続体という形を取らざるを得ず,そこには必要とされるよりも約千倍も多くの音声信号が否応なしに含まれてしまう.
音韻体系にみられる対立 (opposition) に関係する余剰性もある.英語において,音素 /n/ は有声歯茎鼻音だが,鼻音である以上は有声であることは予測可能であり,/n/ の記述に声の有無という対立を設定する必要はない.これは,余剰規則 (redundancy rule) と呼ばれる.
音素配列にも余剰性がある.語頭の [s] の直後に来る無声破裂音は必ず無気となるので,無気であることをあえて記述する必要はない([2011-02-18-1]の記事「#662. sp-, st-, sk- が無気音になる理由」を参照).予測可能であるにもかかわらず精密に記述することは不経済だからである.しかし,言語使用の現場で,語頭の [s] は何らかの雑音で聞こえなかったが,直後の [t] は無気として聞こえた場合,直前に [s] があったに違いないと判断し,補うことができるかもしれない.このように,余剰性は安全装置として機能する.
音素配列に似た余剰性は,綴字規則にも見られる.例えば,英語では頭字語などの稀な例外を除いて,<q> の文字の後には必ず <u> が来る.<u> はほぼ完全に予測可能であり,情報量はゼロである.
形態論や統語論における余剰性の例として,These books are . . . . というとき,主語が複数であることが3語すべてによって示されている.It rained yesterday. では,過去であることが2度示されている.英語史上の話題である二重複数 (double_plural),二重比較級 (double_comparative),二重否定 ([2010-10-28-1], [2012-01-10-1]) なども,余剰性の問題としてみることができる.
そのほか,類義語を重ねる with might and main, without let or hindrance や,電話などでアルファベットの文字を伝える際の C as in Charley などの表現も余剰的であるし,Yes と言いながら首を縦に振るといった paralinguistic な余剰性もある.
余剰性と予測可能性 (predictability) は相関関係にあり,また予測可能性は構造の存在を前提とする.したがって,言語に余剰性があるということは,言語に構造があるということである.ここから,余剰性を前提とする情報理論と,構造を前提とする構造言語学とが結びつくことになった.構造言語学の大家 Martinet の主張した言語の経済性の原理でも,余剰性の重要性が指摘されている (183--85) .
情報理論と言語の余剰性の関係については,Hockett (76--89) を参照.
・ Martinet, André. Éléments de linguistique générale. 5th ed. Armand Colin: Paris, 2008.
・ Hockett, Charles F. "Review of The Mathematical Theory of Communication by Claude L. Shannon; Warren Weaver." Language 29.1 (1953): 69--93.
2012-04-20 Fri
■ #1089. 情報理論と言語の余剰性 [information_theory][linguistics][redundancy][entropy][history_of_linguistics]
情報理論 (information theory) は戦後に発達した比較的新しい科学研究だが,言語学はその成果を様々な形で享受してきた.情報の送り手と受け手の問題,コード化の問題,予測可能性 (predictability) の問題,そして何よりも言語の顕著な特徴の1つである余剰性 (redundancy) の問題について,言語学が情報理論から学べることは多い.
情報理論と人工頭脳工学 (cybernetics) の基礎理論は Shannon and Weaver の著作によって固まったとされ,これは言語学史においても有意義な位置を占めている(イヴィッチ,pp. 164--71).しかし,この著作は高度に数学的であり,一般の言語学者が読んで,その成果を言語学へ還元するということは至難の業のようだ.このような場合には,言語学者による書評が役に立つ.アメリカの言語学者 Hockett の書いているレビューを読んでみた.
Shannon and Weaver 自体が難解なのだから,その理論のレビューもある程度は難解とならざるをえない.評者の Hockett が情報理論の考え方を言語学へ応用する可能性について論じている部分では,言語学としても非常に高度な内容となっている.書評を完全に理解できたとは言い難いが,言語の余剰性およびエントロピー (entropy) についての議論はよく理解できた.
Hockett はたいへん大まかな試算であるとしながらも,ある発話の音韻的な情報量と音声的な情報量の比は1:1000ほどの開きがあり,仮に音韻論的単位のみを意思疎通に不可欠な単位とみなすのであれば,言語音の余剰性は99.9%にのぼるとしている (85) .情報理論でいうエントロピー (entropy) は,"1 - redundancy" と定義されるので,言語音のエントロピーは0.1%である.言語は,ある言い方をすれば非効率,別の言い方をすれば予測可能性の高い種類の情報体系ということができるだろう.
情報が物理的に伝達される際には,多かれ少なかれ必ず雑音 (noise) が含まれてしまう.したがって,情報伝達が意図された通りに遂行されるためには,雑音による影響に耐えられるだけの安全策が必要となる.言語にとって,余剰性こそがその安全策である.Hockett 曰く,"channel noise is never completely eliminable, and redundancy is the weapon with which it can be combatted" (75) .このように考えると,言語音の余剰性99.9%(あるいはこれに近似する高い値)は,いかに言語が慎重に雑音対策を施された安全設計の情報体系であるかを示す指標といえるだろう.
The high linguistically relevant redundancy of the speech signal can be interpreted not as a sign of low efficiency, but as an indication of tremendous flexibility of the system to accommodate to the widest imaginable variety of noise conditions. (Hockett 85)
情報理論の立場から,特に余剰性という観点から言語を見始めると,それは言語のあらゆる側面に関わってくる要素だということがわかってくる.言語の余剰性について,明日の記事で詳しく見ることにする.
・ ミルカ・イヴィッチ 著,早田 輝洋・井上 史雄 訳 『言語学の流れ』 みすず書房,1974年.
・ Hockett, Charles F. "Review of The Mathematical Theory of Communication by Claude L. Shannon; Warren Weaver." Language 29.1 (1953): 69--93.
・ Shannon, Claude L. and Warren Weaver. The Mathematical Theory of Communication. Urbana: U of Illinois P, 1949.
2011-08-13 Sat
■ #838. 言語体系とエントロピー [entropy][functionalism][information_theory][functional_load]
昨日の記事「言語変化における therapy or pathogeny」 ([2011-08-12-1]) を書きながら,言語における「全快」状態あるいは「罹病」状態とは何かを考えていた.言語学の常識として「個別言語はそれが供する言語共同体の要求をほぼ完全に満たすものであり,その話者にとってはほぼ完璧な記号体系である」という考え方がある.これは,各言語がその話者にとっては常に「全快」に近い状態にあるということを意味する.この考え方でいけば,完全無欠とは言わずとも「罹病」状態にある言語は存在しないということになる.ここでは「その話者にとって」という視点が重要であり,あくまで相対的な基準で「全快」に近いということである (相対的な言語観については,[2011-06-06-1]の記事「Martinet にとって言語とは?」を参照).また,外部の者が複数の言語を絶対的な基準で比べて,A言語のほうがB言語よりも「健全」であるなどと決めることはできないということにもなる.そもそも,言語的にどのような状態であれば「健全」であるかについて客観的な基準を決めることは難しいだろう.
しかし,主観的評価の込もりがちな「健全」や「全快」という表現を避け,絶対的な基準で量化できる項目に着目してその尺度でA言語とB言語を比較評価するということは可能かもしれない.例えば,体系の対称性 (symmetry) ,均衡性 (balancedness) ,経済性 (economy) というものが量化できるのであれば,それらの指標をもって,仮に部分的に言語体系のの「健全性」を論じるということはできるかもしれない.[2010-02-14-1]の記事「言語の難易度は測れるか」の議論とも関係するが,音韻論や形態論など部門別に考えるということであれば,さらに量化はしやすいだろう.[2011-08-11-1]の記事「機能負担量」で説明した functional load の考え方は音韻論から生み出された量的な概念だが,書記素論や形態論など他の部門にも応用することは可能かもしれない(もっとも音韻論のように高度に構造化された部門ではないと実践は難しそうだが).
言語体系の「健全性」を評価する観点として,上で対称性,均衡性,経済性といった特性を挙げてみたが,もう1つの特性として,現代世界のキーワードでもあるエントロピー (entropy) を考えてみるのもおもしろい.エントロピーとは体系としての乱雑さの度合いを指し,値が低いほど体系が秩序だっていることを示す.もともとは熱力学の用語だが,情報理論に広く応用されており,言語理論への応用の道も開かれているといえる.言語体系のエントロピーの測定法を編み出すことは容易ではないだろうが,単純にいって,体系としての規則性が増せばエントロピーが減少し,不規則性が増せばエントロピーが増大すると表現することはできる.
例えば,言語変化には「音声変化は規則的に生じるが形態論に不規則性をもたらし,類推に基づく形態変化は不規則に生じるが形態論の規則性をもたらす」傾向が見られるが,エントロピーの用語を用いれば「形態論において,規則的な音声変化はエントロピーを増大させ,不規則的な類推作用はエントロピーを減少させる」と換言できる(関連して,[2011-03-19-1]の記事「語尾音消失と形態クラス」で取り上げた語尾音の消失と保持の例や,[2010-11-03-1]の記事「2種類の analogy」の議論を参照).
私は詳しくないが,生成文法に基盤を置く音韻論や natural morphology などの分野では,言語変化を記述・説明するのに,その過程の自然さの度合いが考慮される.「自然さ」という特性も,エントロピー,対称性,均衡性,経済性などと同様に,体系の「健全性」を匂わす特性の1つである."natural", "balanced", "economical", "simple", "therapy" などという表現には否応なしに価値観や評価が含まれてしまうが,"entropy" には熱力学の法則とだけあって科学的な響きがあるし,時代のキーワードとはいえ,いまだ手垢がついていないように思える.
熱力学の第2法則によれば,「物質とエネルギーは一つの方向のみに,すなわち使用可能なものから使用不可能なものへ,あるいは利用可能なものから利用不可能なものへ,あるいはまた,秩序化されたものから,無秩序化されたものへと変化する」(リフキン,p. 45).つまり,ある領域でエントロピーが減少しているように見えても,必ず他の領域でそれ以上にエントロピーが増大しており,全体として宇宙のエントロピーは増大の一途をたどるということである.現代物理学が絶対的な真理として認めているのはこの法則だけだと言われるほどの強い法則だ.では,宇宙の体系と言語の体系は類似しているのだろうか.もしそうだと仮定すると,昨日の記事「言語変化における therapy or pathogeny」 ([2011-08-12-1]) で問題になった Schendl (69) の "therapeutic changes in one part of the grammar may create imbalance in another part" の may は must と読みなおさなければならないことになる.だが,幸いなことに,エントロピーの法則は形而下の世界のみに適用されるという.言語変化の議論では may ほどの解釈でよいのかもしれない.
・ ジェレミー・リフキン 著,竹内 均 訳 『改訂新版 エントロピーの法則』 祥伝社,1990年.
・ Schendl, Herbert. Historical Linguistics. Oxford: OUP, 2001.
Powered by WinChalow1.0rc4 based on chalow