2022-04-30 Sat
■ #4751. なぜすべてを大文字書きする人がいるの? [sobokunagimon][punctuation][alphabet][capitalisation][hellog_entry_set]
英語史の授業の履修者から興味深い疑問が寄せられました.
以前より気になっていたことがあり,お聞きします.
これまで,英会話や大学の英語の講義にて,ネイティブの先生で,板書をする際に,アルファベット表記を全て大文字にして書く方がいらっしゃいました.
ネイティブが非ネイティブに教育する際に,そのような習慣があるのでしょうか.
もし何かご存じであれば,ご教示願います.
この疑問に対して,ひとまず次のように回答しました.
確かに黒板などにすべてを大文字書きするシーンというのは,よくありますね.
規範的にいえば,私たちが英語教育で習うように,大文字と小文字の使い分けはしっかり決まっています.しかし,この規範が定まったのも近代以降のことで,比較的新しいものです.
また,今でも必ずしも規範にとらわれないレジスター(使用域)は日常的に多々あります.漫画の台詞は大文字書きが普通ですし,キーワードの強調のための黒板書き大文字もまさにそのようなケースですね.強調のための大文字使用の歴史は千年以上の長きにわたりますので,それが受け継がれていると解釈することもできます.
そもそもなぜ大文字と小文字があるのかを考えてみるとおもしろいと思います.音声解説「なぜ文頭や固有名詞は大文字で始めるの?」および関連する記事セットをどうぞ.
回答後に1つ思い出したことがあります.主に電子テキストにみられる「怒号と敵意の大文字書き」というべき慣習です.すべて大文字書きすることは,話し言葉でいえば大声で(怒号して)発声していることに相当します.これにより,威圧的なメッセージを作り出すことができるわけです.Horobin (129) がおもしろい例を紹介しています.
While exclamation marks, smileys, and emojis offer methods of defusing situations and apologizing, what happens when you want to deliberatively provoke or insult someone? Here traditional punctuation offers little help, since there are no marks that explicitly indicate anger or aggression. In electronic discourse, however, the use of capitals has become an established means of shouting, or expressing hostility towards your addressee. To write an email entirely in upper-case is seen as an act of deliberate aggression; a New Zealand woman was dismissed from her job for sending emails exclusively in capitals, which were deemed to be the cause of disharmony in the office. The US Navy was forced to change its policy of requiring all communications to be in upper-case, since sailors accustomed to reading text messages and emails considered the default use of capitals at the equivalent of being constantly shouted at.
大文字書きの問題1つをとっても,立派な言語学の話題になります.
・ Horobin, Simon. How English Became English: A Short History of a Global Language. Oxford: OUP, 2016.
2021-12-22 Wed
■ #4622. 書き言葉における語境界の表わし方 [writing][distinctiones][word][syntax][grammatology][alphabet][kanji][hiragana][katakana][punctuation]
単語を分かち書き (distinctiones) するか続け書き (scriptura continua) するかは,文字文化ごとに異なっているし,同じ文字文化でも時代や用途によって変わることがあった.英語では分かち書きするのが当然と思われているが,古英語や中英語では単語間にスペースがほとんど見られない文章がザラにあった(cf 「#3798. 古英語の緩い分かち書き」 ([2019-09-20-1])).逆に日本語では続け書きするのが当然と思われているが,幼児や初級学習者用に書かれた平仮名のみの文章では,読みやすくするために意図的に分かち書きされることもある(cf. 「#1112. 分かち書き (1)」 ([2012-05-13-1])).
一般的にいえば,漢字のような表語文字や仮名のような音節(モーラ)文字は続け書きされることが多いのに対し,単音文字(アルファベット)は分かち書きされることが多い.しかし,これはあくまで類型論上の傾向にすぎない.書き言葉において大事なことは,何らかの方法で語と語の境界が示されることである.単語間にスペースをおくというやり方は,それを実現する数々の方法の1つにすぎない.
語境界を明示するためであれば,何もスペースにこだわる必要はない.世界の文字文化を見渡すと,例えば北セム諸語の碑文においては中点や縦線などで語を区切るという方法が実践されていたし,エジプト象形文字で人名を枠で囲むカルトゥーシュ (cartouche) のような方法もあった(中点については「#3044. 古英語の中点による分かち書き」 ([2017-08-27-1]) も参照).
また,語末が常に(あるいはしばしば)特定の文字や字形で終わるという規則があれば,その文字や字形が語境界を示すことになり,分かち書きなどの他の方法は特に必要とならない.実際,ギリシア語では語末に少数の特定の文字しか現われないため,分かち書きは必須ではなかった.ヘブライ語やアラビア語などでは,同一文字素であっても語末に用いられるか,それ以外に用いられるかにより異なる字形をもつ文字体系もある.
日本語の漢字かな交じり文では,漢字で書かれることの多い自立語と平仮名で書かれることの多い付属語が交互に繰り返されるという特徴をもつ.そのために典型的には平仮名から漢字に切り替わるところが語境界と一致する.部分的にではあれ,語境界の見分け方が確かにあるということだ.
最後に「#1114. 草仮名の連綿と墨継ぎ」 ([2012-05-15-1]) で見たように,書き手が特定の言語単位(例えば語)を書き終えたところでいったん筆を上げるなどの慣習を発達させることがある.すると,その途切れの跡がそのまま語境界を示すことにもなる.
このように古今東西の文字文化を眺めてみると,語境界を表わす方法は多種多様である.英語で見慣れている分かち書きが唯一絶対の方法ではないことを銘記しておきたい.そもそも英語や西洋言語の書記における分かち書きの習慣自体が,歴史的には後の発展なのだから(cf . 「#1903. 分かち書きの歴史」 ([2014-07-13-1])).
・ Daniels, Peter T. "The History of Writing as a History of Linguistics." Chapter 2 of The Oxford Handbook of the History of Linguistics. Ed. Keith Allan. Oxford: OUP, 2013. 53--69.
2021-12-18 Sat
■ #4618. 際立ちのためのイタリック体の起源と発達 [writing][printing][alphabet][grammatology][pragmatics][punctuation][bible][pragmatics]
ローマン・アルファベットを用いる言語では,引用箇所や強調部分など,ある部分を特別に際立たせるためにしばしばイタリック体 (italics) が用いられる.通常のローマン体で書かれた文字列のなかで細身のイタリック体はよく目立つからである.書体の語用論的使用法といってよいだろう(cf. 「#574. punctuation の4つの機能」 ([2010-11-22-1])).
イタリック体は,1501年に当時の写本書体に基づく新書体としてベネチアで現われた.紙が高価だった当時,細身で経済的な書体として生み出されたのである.しかし,イタリック体は当初から際立ちを与えるために用いられたわけではない.際立ちのために使用は,16世紀後半のフランスでの新機軸という.それがイングランドにも伝わり,1611年の欽定訳聖書 (Authorised Version) において挿入文の書体として用いられるに及び,広く受け入れられるに至った.後期近代にはイタリック体の使いすぎに不満を漏らす者も現われたようで,それほどまでに使用が一般化していたということになる.
上記は Daniels (68--69) を読んで初めて知ったことである.欽定訳聖書が英語書記におけるイタリック体使用の慣習確立に一役買っていたいう事実には,特に驚かされた.同聖書の英語史上の意義の大きさを改めて確認した次第である.
・ Daniels, Peter T. "The History of Writing as a History of Linguistics." Chapter 2 of The Oxford Handbook of the History of Linguistics. Ed. Keith Allan. Oxford: OUP, 2013. 53--69.
2021-08-22 Sun
■ #4500. 文字体系を別の言語から借りるときに起こり得ること6点 [grapheme][graphology][alphabet][writing][diacritical_mark][ligature][digraph][runic][borrowing][y]
自らが文字体系を生み出した言語でない限り,いずれの言語もすでに他言語で使われていた文字を借用することによって文字の運用を始めたはずである.しかし,自言語と借用元の言語は当然ながら多かれ少なかれ異なる言語特徴(とりわけ音韻論)をもっているわけであり,文字の運用にあたっても借用元言語での運用が100%そのまま持ち越されるわけではない.言語間で文字体系が借用されるときには,何らかの変化が生じることは避けられない.これは,6世紀にローマ字が英語に借用されたときも然り,同世紀に漢字が日本語に借用されたときも然りである.
Görlach (35) は,文字体系の借用に際して何が起こりうるか,6点を箇条書きで挙げている.主に表音文字であるアルファベットの借用を念頭に置いての箇条書きと思われるが,以下に引用したい.
Since no two languages have the same phonemic inventory, any transfer of an alphabet creates problems. The following solutions, especially to render 'new' phonemes, appear to be the most common:
1. New uses for unnecessary letters (Greek vowels).
2. Combinations (E. <th>) and fusions (Gk <ω>, OE <æ>, Fr <œ>, Ge <ß>).
3. Mixture of different alphabets (Runic additions in OE; <ȝ>: <g> in ME).
4. Freely invented new symbols (Gk <φ, ψ, χ, ξ>).
5. Modification of existing letters (Lat <G>, OE <ð>, Polish <ł>).
6. Use of diacritics (dieresis in Ge Bär, Fr Noël; tilde in Sp mañana; cedilla in Fr ça; various accents and so on).
なるほど,既存の文字の用法が変わるということもあれば,新しい文字が作り出されるということもあるというように様々なパターンがありそうだ.ただし,これらの多くは確かに言語間での文字体系の借用に際して起こることは多いかもしれないが,そうでなくても自発的に起こり得る項目もあるのではないか.
例えば上記1については,同一言語内であっても通時的に起こることがある.古英語の <y> ≡ /y/ について,中英語にかけて同音素が非円唇化するに伴って,同文字素はある意味で「不要」となったわけだが,中英語期には子音 /j/ を表わすようになったし,語中位置によって /i/ の異綴りという役割も獲得した.ここでは,言語接触は直接的に関わっていないように思われる (cf. 「#3069. 連載第9回「なぜ try が tried となり,die が dying となるのか?」」 ([2017-09-21-1])) .
・ Görlach, Manfred. The Linguistic History of English. Basingstoke: Macmillan, 1997.
2021-07-13 Tue
■ #4460. 古英語の母音字の上につける長音記号は写本にはないので要注意 [manuscript][oe][punctuation][vowel][spelling][palatalisation][alphabet]
昨日の記事「#4459. なぜ drive の過去分詞 driven はドライヴンではなくドリヴンなの?」 ([2021-07-12-1]) をはじめとして,本ブログでは古英語の語句を引用することが多いが,その際に長母音を示すのに母音字の上に macron と呼ばれる横棒(長音記号)を付すことが多い.ā, ē, ī, ō, ū, ȳ 如くである.昨日の例であれば,現代英語の drove に対応する古英語の形態が drāf だったことに触れたが,ここでは長母音であることを示すのに ā の表記を用いている.
注意すべきは,この macron 付き表記は,あくまで現代の古英語学習者の便宜のために現代の編者が付した教育用の符号にすぎず,実際の古英語の写本にはまったくなかったということである.macron に限らず,現代の古英語読本などに印刷されている種々の句読点 (punctuation) は,古英語初学者のために編者が現代英語ぽく補ってくれているものであることが多く,実際の写本に立ち戻ってみると,そのような符号はない,ということが少なくない.つまり,ありたがいような,おせっかいのような話しなのである.このことは明示的に述べておかないと,多くの古英語学習者が誤解してしまう.
一般的にいえば,古英語は現代英語に比べて,綴字と発音の関係がストレートである.現代英語の knight, through, climb を /naɪt/, /θruː/, /claɪm/ を読むことは学習しない限り難しいが,対応する古英語の cniht, þurh, climban を /kniçt/, /θurx/, /clɪmban/ と読むことは比較的たやすいだろう.古英語は,現代英語における発音と綴字の乖離 (spelling_pronunciation_gap) の問題からおよそ免れていたと一般的に言われる.
しかし,古英語における「発音と綴字の一致」を過大評価してはいけない.確かに「ローマ字通りに読めばよい」という原則でおよそうまくいくものの,「#17. 注意すべき古英語の綴りと発音」 ([2009-05-15-1]) で述べたように,発音と綴字が必ずしも1対1にならないものもある.<f, s, þ, ð> は,音声的にはそれぞれ無声と有声 (/f, v, s, z, θ, ð/) があり得るし,<c> と <g> にも軟音(口蓋化音)と硬音があり得る.後者については,現代の入門書では軟音の /ʧ/, /j/ は各々 <ċ>, <ġ> と表記することが多い.古英語でも,発音と綴字がきれいに1対1になっていないケースは,そこそこあるのである.
その最たるものが母音の長短である.英語史においては,古英語から現代英語に至るまで,母音の長短は常に重要な区別であり続けてきた.例えば昨日取り上げた drive (OE drīfan) でいえば,短い母音をもつ drifen であれば過去分詞であり,長い母音をもつ drīfen であれば接続法複数現在として "we/you/they may drive" ほどを表わしたので,母音の長短が意味・機能を大きく違えたのである.しかし,現存する写本においては macron などなく,いずれも <drifen> と綴られていたことに気をつけたい.
この限りにおいて,古英語も現代英語と同様に綴字と発音はさして一致していなかったともいえるのである.程度の問題として論じるならば,確かに古英語は現代英語よりはマシだったろう.しかし,古英語期にも発音と綴字の問題は,とりわけ母音の長短に関していえば,相当のものだったのである.この点は,英語史においてしばしば見逃されてきた非常に重要な事実だと考えている.
関連して「#1826. ローマ字は母音の長短を直接示すことができない」 ([2014-04-27-1]),「#2092. アルファベットは母音を直接表わすのが苦手」 ([2015-01-18-1]),「#2887. 連載第3回「なぜ英語は母音を表記するのが苦手なのか?」」 ([2017-03-23-1]),「#3954. 母音の長短を書き分けようとした中英語の新機軸」 ([2020-02-23-1]) を参照.
2021-04-12 Mon
■ #4368. 年度初めに「英語の先生がこれだけ知っておくと安心というアルファベット関連の話し」の記事セット(2021年度版) [hellog_entry_set][alphabet][hel_education][writing][orthography][grammatology][romaji][spelling][elt]
年度初めのこの時期,児童・生徒たちにローマ字なり英語アルファベットなりの読み書きを教え始める学校の先生も多いと思います.平仮名や片仮名と同じで,何度も読んで書いて練習し慣れていくというスタイルが普通かと思います.
学習者にとってはこのように基礎的な作業となるわけですが,教える先生の側にあっては,是非ともアルファベットの成立や発展などの背景的な知識を持っておくことをお薦めします.学習者からの鋭い質問にも答えられるようになりますし,実際にそのような知識を学習者に教える機会はないとしても,アルファベット1文字1文字に歴史的な深みがあることを知っておくことは大事だと思うからです.そこで,本ブログより関係する記事を集め,以下の記事セットとして整理してみました.
・ 「英語の先生がこれだけ知っておくと安心というアルファベット関連の話し」の記事セット(2021年度版)
同趣旨で,およそ1年前,2020年度の開始期に合わせて「#4038. 年度初めに「英語の先生がこれだけ知っておくと安心というアルファベット関連の話し」の記事セット」 ([2020-05-17-1]) を公開していました.今回のものは,その改訂版ということになります.昨年度中は「hellog ラジオ版」と称して音声コンテンツを多く作ってきたので,今回の改訂版には,アルファベットに関する音声ファイルへのリンクなども加えてあります.
もちろんアルファベットに関する背景知識は,英語の先生に限らず,一般の英語学習者にも持っていてもらいたい知識です.そして,目下「英語史導入企画2021」のキャンペーン中でもありますし,英語史に関心のあるすべての人々に持っていてもらいたい知識でもあります.
2021-01-22 Fri
■ #4288. グラゴール文字とキリル文字 [alphabet][writing][greek][old_slavic][slavic]
昨日の記事「#4287. 古代スラヴ語の運命」 ([2021-01-21-1]) で触れたように,古代スラヴ語は最初にグラゴール文字 (Glagolitic) で,後にキリル文字 (Cyrillic) でも書き記された.後者は現代でもロシア語を中心に東方および南方のスラヴ語圏で用いられており,世界に少なからぬ影響力をもつ文字である.グラゴール文字とキリル文字の成り立ちや相互関係について,またそれらとギリシア文字の関係について,服部 (82--87) に詳しい.以下に要約しよう.
グラゴール文字は,昨日の記事でも述べたように,9世紀後半,ギリシア人のコンスタンティノスとその兄メトディオスが,モラヴィア国へのキリスト教布教を目的にスラヴ文章語(=古代スラヴ語)を作り出したときに同時に生み出された新しい文字である.コンスタンティノスの考案だったとされる.各々の字形は独特だが,9世紀のミヌスクラ体のギリシア文字が基盤となっている旨,指摘されている.ギリシア語にはなくスラヴ語には存在する音素に対応する文字が加えられ,スラヴ語表記に特化した文字体系といえる. *
885年のメトディオスの死後,古代スラヴ語の伝統は弟子たちによってブルガリアへ持ち越され,発展することになった.その際,既存のグラゴール文字に飽き足りず,スラヴ語表記に便利な機能性は保持しつつも,字形としては使い慣れたギリシア文字に似せた新たな文字体系を考案した.これがキリル文字である.具体的には,9世紀のウンキリアス書体のギリシア文字がほぼそのまま採用されており,そこへスラヴ語音を表わすためにグラゴール文字から数文字を取って加えたという文字体系である. *
なお,「キリル」の名は,コンスタンティノスの修道士名キュリロスに由来する.ただし,キリル文字はメトディオスの弟子たちが考案したものであり,コンスタンティノス(=キュリロス)が考案したのは先のグラゴール文字である,という分かりにくい事情があるので注意.
その後,キリル文字は広く展開していったが,一方でグラゴール文字は衰退していった.しかし,後者も一部の地域ではずっと後にまで受け継がれた.アドリア海沿岸部ダルマチア地方(現在のクロアチア領)では,実に20世紀に至るまで,一部の教会においてグラゴール文字で書かれた典礼書が細々と用いられていたという.
・ 服部 文昭 『古代スラヴ語の世界史』 白水社,2020年.
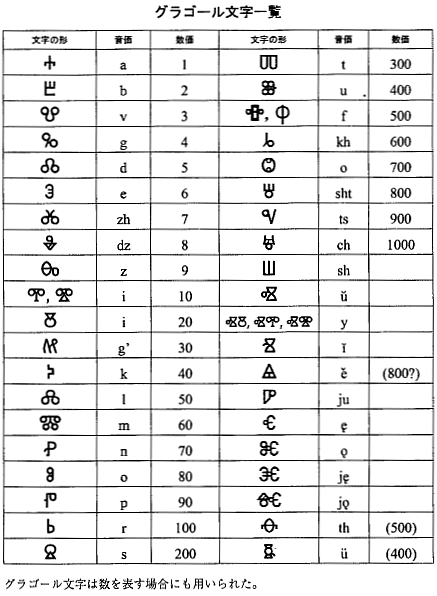{kind=link}
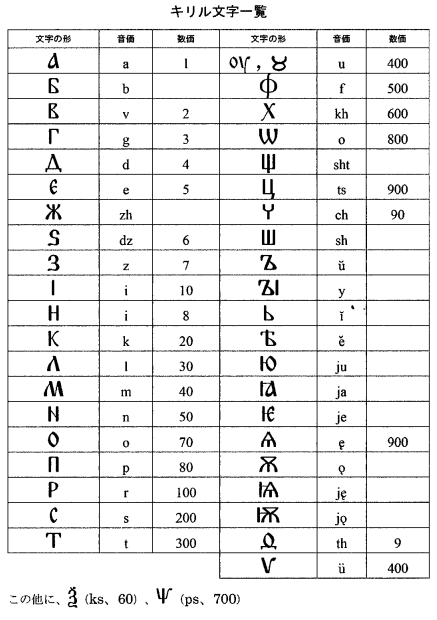{kind=link}
2021-01-21 Thu
■ #4287. 古代スラヴ語の運命 [slavic][old_slavic][balto-slavic][review][alphabet][history]
昨年出版された服部著『古代スラヴ語の世界史』を読んだ.学生時代にロシア語を少しかじった程度でスラヴ系の言語(史)には疎いので,本ブログでもスラヴ語派 (slavic) に関してはあまり記事を書いてきていない.そのような者にとって,たいへん読みやすく学ぶことの多い著書だった.
そもそも古代スラヴ語 (Old Slavic [Slavonic]) とは何か.服部 (114--16) を参照しつつ要約しよう.時代は9世紀半ばに遡る.当時のスラヴ世界には,多少の方言差はあったにせよ共通スラヴ語と呼べる口語が行なわれていたと考えられる.しかし,それは書き言葉に付されることはなかった.862年,ギリシア出身のコンスタンティノスとその兄メドティオスが,モラヴィア国(現在のチェコ東部)にスラヴ語でキリスト教を布教すべく,経典類のためのスラヴ文章語と,それを書き記すためのグラゴール文字を考案した(後者について「#1834. 文字史年表」 ([2014-05-05-1]) を参照).この新生スラヴ文章語こそが「古代スラヴ語」の正体である.
この文章語による布教は当初は順調に進んだが,国内外の政治情勢ゆえに,885年のメトディオスの死後,無に帰した.しかし,弟子たちがブルガリアへ避難し,そこで首長ボリスの庇護を受けるに及んで,古代スラヴ語の伝統は新天地にて延命,いな発展を遂げる.先のグラゴール文字の機能的な長所を保ちつつ,人々が使い慣れていたギリシア文字の字形を導入し,あらたにキリル文字が作られた.ところがブルガリアもやがて滅亡し,古代スラヴ語は再び衰退の危機にさらされた.危機に陥った古代スラヴ語は,しかし,3度目の滞在地を見つけた.キエフ・ルーシである.989年にキエフ公ウラジーミルがキリスト教を国教化すると,この地にて古代スラヴ語が受け継がれることになった.
しかし,10世紀末のこの段階までに,話し言葉としてのスラヴ語は相当の方言化を経ていた.キエフ・ルーシでも,人々の母方言と,共通文章語としての役割を果たしてきた古代スラヴ語との差が目立ってきていたのである.古代スラヴ語の経典類は,書写されていくにつれて母方言的な要素が多く混入し,いつしか純粋な古代スラヴ語と呼び得ないほどまでになった.この段階をもって,古代スラヴ語は「ロシア教会スラヴ語」や「古代ロシア文語」と呼ぶべきものに変化したと考えられている.古代スラヴ語は消滅したにはちがいないが,より正確には「ロシア教会スラヴ語」へ同化・吸収されていったといえる.
古代スラヴ語は,このように9世紀後半から1100年ほどまでスラヴ人が用いた文章語であった.言語史の1コマといえばそうだが,歴史的な意義として服部 (5) は2点を挙げている.
このような歴史の中で見ると,古代スラヴ語とはどのような重要性を持つのであろうか.まず古代スラヴ語によってスラヴ人は初めて文字を手に入れ,文章を書き記すことを始めた.つまり,スラヴ人自身の言葉によって文献を書き残せるようになった歴史的意味は無視し難いであろう.次に,スラヴ人は,自分たちの言葉を通してキリスト教世界と関わりを持つことにより,その存在感を徐々に高めてゆくことになる.とりわけ,東方教会の圏内において,今日に繋がるような大きな存在となってゆくことは重要である.
たいへん勉強になった.スラヴ語派,あるいはより広くバルト=スラヴ語派については,「#1469. バルト=スラブ語派(印欧語族)」 ([2013-05-05-1]) を参照.
・ 服部 文昭 『古代スラヴ語の世界史』 白水社,2020年.
2020-11-15 Sun
■ #4220. <x> の不思議あれこれ --- hellog ラジオ版 [hellog-radio][sobokunagimon][x][alphabet]
英語の世界において <x> という文字は,魅力的かつ不思議な文字です.今回の hellog ラジオ版は,このちょっと素性の怪しい文字 <x> に注目したいと思います.
英語アルファベット26文字の1つとして大事な文字ではありますが,皆さんも薄々感じている通り,どうにもちょっと信用できない,日陰者的な文字ですよね.<x> からこのように独特な雰囲気が醸し出されているのは,なぜなのでしょうか.本当はこれだけで90分話したいところですが,短く収めてみました(とはいえ,10分近くの長尺).
いかがでしょうか.<x> は,決してもともとの英語と調和しないわけではないのですが,概していえば外来語との親和性が高いといえます.その性格が現代まで受け継がれ,<x> という文字は,半ば先進的で半ば胡散臭い雰囲気を醸しているのです.多くの人々が <x> に関心を寄せるのは,この何ともいえない得体のしれなさゆえだろうと思います.
変革の時代には,「得体のしれなさ」はポジティヴなキャッチフレーズです.これを機に,改めて <x> について考えてみませんか?
<x> について関心をもった方は,ぜひ##2280,3654,2918,4219の記事セットをご一読ください.また,昨日の記事「#4219. なぜ DX が digital transformation の略記となるのか?」 ([2020-11-14-1]) もどうぞ.
2020-09-09 Wed
■ #4153. なぜ w の文字は v が2つなのに double-u なのですか? --- hellog ラジオ版 [hellog-radio][sobokunagimon][hel_education][w][grapheme][alphabet][norman_french][u][v]
hellog ラジオ版の第23回は,しばしば寄せられる <w> の文字の呼称に関する疑問です.英語ではこの文字は "double-u "と呼ばれますが,フランス語などを学んだことがある方は,"double-v" と呼ばれているのを知っているかと思います.見た目は確かに v が2つですね.では,英語ではなぜ u が2つという呼び方をするのでしょうか.背景には,なかなか興味深い歴史があります.
英語がラテン語からローマ字一式を借りたときに,そのなかに <w> の文字がなかったのが,そもそもの出発点です./w/ 音を多用する英語は,相当する文字がなくては不便で仕方がないので,自ら文字を考案することにしました.ローマ字一式には <u> はあった(ただし <v> はなかった)ので,それを2つ合わせて <uu> とすることで,この難局を乗り切ろうとしました.一方,英語は以前より使っていたルーン文字から /w/ 音を表わす <ƿ> (wynn) を流用する慣習も発達させ,先に考案した <uu> はあまり使われなくなりました.
ところが,英語で不使用となった <uu> は,お隣のフランスに渡り,そこで「亡命」生活をして生き延びることとなりました.その後11世紀頃に,亡命していた <uu> は再び英語に舞い戻る機会を得て,<ƿ> を置き換えることになりました.こうして英語で "double-u" の <uu>,転じて <w> が定着することになりました.
ちなみに,亡命先のフランスでは <u> から派生した(<u> の先を尖らせた) <v> の文字も早くから使われており,例の文字を "double-v" の <vv> と解釈したのです.
この疑問のキモは,<u>, <v>, <w> (そして実は <f> も!)の文字が,歴史的にはすべて近親関係にあるという点です.関心のある方は,ぜひ##2411,373,374,3391,3927,1825の記事セットをじっくりお読みください.
2020-07-18 Sat
■ #4100. 現存する最古の英文は何か? --- hellog ラジオ版 [hellog-radio][sobokunagimon][hel_education][runic][alphabet][writing][direction_of_writing]
hellog ラジオ版の第8回目として,英語(史)の専門家にも意外と知られていない事実を紹介します.前回の第7回 ([2020-07-15-1]) でも実は少し触れたのですが,今回は詳しく取り上げます.
現在,世界の約20億人によって話されるともいわれる lingua franca たる英語.現代における威信が注目されるあまり,その最古の姿がいかなるものだったかについては関心をもたれません.しかし,調べてみるとメチャクチャおもしろいのです.英語の現存する最古の証拠の1つに "Undley bracteate" があります.これは1982年に Suffolk の Undley で発見された直径2.3cmの金のメダルに付けられた名前で,年代は紀元450--80年のものとされます.メダルの円周に沿って,ルーン文字で反時計回りに,つまり「右から左に」書かれています.まさにロマンを掻きたてるメダルです.
実におもしろいでしょう."gægogæ mægæ medu" とは何なのか? 呪文? 祈祷? 無味乾燥な散文? 今を時めく英語という言語が,いわば少数民族の言語だった最初期の時代の証拠です.
関連する記事を挙げておきましょう.ぜひ##572,1435,1453の記事セットをじっくりご覧ください.
2020-07-01 Wed
■ #4083. なぜ q の後には必ず u がくるのですか? --- hellog ラジオ版 [hellog-radio][sobokunagimon][hel_education][alphabet][digraph][q][spelling]
hellog ラジオ版の第3弾.英語を学んでいる多くの大学生からも質問自体がなるほどと思った,というコメントが寄せられた興味深い素朴な疑問です.私たちは <qu> のスペリングには読むときにも書くときにも頻繁に触れているわけですが,あまりに慣れすぎているために,<q> の後にはほぼ必ず <u> が続くというこの事実に,意識的に気づいたことがあまりなかったのだろうと思います.
6分間の音声にまとめました.以下からどうぞ.
今回は /kw/ という子音連鎖を表わすのにどのようなスペリングをもってするかという話題でしたが,/k/ という1つの子音を表わすにも,英語には <q(u)> だけでなく <c> もあれば <k> もあり,意外とややこしいことになっています.この発展的な問題も含め,今回の内容を文章でじっくり読みたいという方は,ぜひ##3649,1599,2249,2367,1824の記事セットをご覧ください.
今回の疑問のように,当たり前すぎて見過ごしてきた事実は意外に多いものです.このような疑問を発掘するのも,楽しい知的作業です.
2020-06-23 Tue
■ #4075. なぜ大文字と小文字があるのですか? --- hellog ラジオ版 [hellog-radio][sobokunagimon][hel_education][alphabet][capitalisation][notice]
昨日の記事「#4074. 「素朴な疑問」にひたすら音声で答える英語史の講義を行ないました」 ([2020-06-22-1]) で予告したように,恥を晒して「hellog ラジオ版」をオープンします.
初回となる今回は「なぜ大文字と小文字があるのですか?」という疑問に答えます.2分20秒ほどの音声 (mp3) によるお手軽な話題です.以下よりどうぞ.
皿洗いをしながらでも気軽に聴けるようなコンテンツかと思います.とはいっても,完全な聞き流しをするには濃密なコンテンツかもしれません.深く知りたいと思ったら,やはり文字情報がベストです.じっくりと文章で読みたい方は,hellog より##1309,3668の記事セットをご覧ください.
今後たまに発信していく予定の「hellog ラジオ版」では,新しい話題を提示するというよりも,すでに hellog 本体で扱ってきた話題へと誘う「入り口」を提供することを意識していきます.各メディアの特性を活かして,皆さんの英語史への好奇心を掻き立てることができればと思います.
2020-05-23 Sat
■ #4044. なぜ活字体とブロック体の小文字 <a> の字形は違うのですか? [sobokunagimon][alphabet][writing][calligraphy][a][g]
本年度より英語の教員となったゼミの卒業生から,標記の素朴な疑問をもらっていました.中学1年生にアルファベットの書き方を教えるに当たって,第1文字から早速ハテナが飛ぶ敏感な生徒もいるのではないか,という問題意識からだと思います.私も深く考えたことはありませんでしたが,以下のような書き方練習のドリルを見てみると,確かに,とうなずける問いです.上段が(印刷用の)活字体,下段が(手書き用の)ブロック体です.

小文字 <a> の字形について,活字体では上部に左向きの閉じていない半ループがみえる <<a>> ("open a") が,ブロック体では円の形に近い <<ɑ>> ("closed a") がそれぞれ用いられます.
ついでにいえば,右端にみえる小文字 <g> についても2つの異なる字形が確認されます.活字体では下のループが閉じた <<g>> ("closed g") となり,ブロック体では下のループの開いている <<ɡ>> ("open g") となります.
他の24文字の小文字については活字体とブロック体の字形にさほど大きな違いはありませんが,この <a> と <g> に関しては看過できない差がみられます.なぜこの2文字には妙な差異が観察されるのでしょうか.
端的に答えれば,それはもととなった書体が異なるからです.活字体の <<a>> は,Roman uncial と呼ばれる書体に端を発し,8世紀のシャルルマーニュの教育改革に際して生み出された Carolingian minuscule と呼ばれる書体を経由して現代に受け継がれた字体です.一方,ブロック体の <<ɑ>> は italic と呼ばれる,中世から近代にかけて生じた別の書体における字形に由来します.
では,活字体はすべて Carolingian minuscule の流れを,ブロック体はすべて italic の流れを汲んでいるかといえば,そうでもありません.<g> についていえば,今度は活字体の <<g>> のほうがむしろ italic の系列に連なり,ブロック体の <<ɡ>> のほうが Carolingian minuscule の字形に近いのです.
活字体,ブロック体,筆記体やコンピュータ上のフォントなど,現代のアルファベットには様々な書体があります.それぞれの書体のたどってきた歴史は非常に複雑で,複数の書体が混じったものや,複数の書体の中間的なものなど,その系譜をまとめようとするとなかなか家系図のように綺麗にはいきません.本格的に作図しようとすれば,ある文字の字形はこっちから,別の文字の字形はあっちから,というような複雑なネットワーク図になるでしょう.活字体やブロック体についても,全体としておおまかな系統はたどれるにせよ,英語アルファベットを構成する26文字の個々の字形については,ときに個別に系統を探る必要が生じるのです.
上記は「#3668. なぜ大文字と小文字の字形で異なるものがあるのですか?」 ([2019-05-13-1]) で展開した議論とほとんど同じです.大文字と小文字で字形の異なる文字がいくつかありますが,これももととなった書体の差異に由来します.歴史的にみれば <<A>>, <<a>> , <<ɑ>> は3つの異なる書体に由来し,<<G>>, <<g>>, <<ɡ>> も同様に3つの異なる書体に由来するということになります(特に <g> のたどった歴史は複雑です.g の記事を参照).
漢字に喩えると分かりやすいでしょうか.「令和」の最初の文字「令」は,楷書体などの主として活字用の書体では最終画が真下に伸びますが,国語の授業で習う手書き用の書体では最終画は斜めとなり,片仮名の「マ」のようになります.属する書体が異なり,辿ってきた歴史が異なるからこそ,字形が多少なりとも異なっているということです.
だとすれば,当初の発問を逆転させて,「なぜ他の24文字については活字体とブロック体の字形が似ているのか」と問い直すほうが,もしかしたらベターなのかもしれません.漢字などに比べればローマ字は単純な幾何学的な字形を示すため,歴史上数々の書体が生み出されてきた過程において字形に何らかの「ひねり」や「変形」が加えられたとしても,認識できないほど異なる字形に変化してしまうことは少なかったのでしょう.異なる書体でも結果としておよそ似ている文字が多いのは,このような事情があったためではないでしょうか.
関連して次の記事もご参照ください.
・ 「#1309. 大文字と小文字」 ([2012-11-26-1])
・ 「#3714. 活字体(ブロック体)と筆記体」 ([2019-06-28-1])
・ 「#3674. Harris のカリグラフィ本の目次」 ([2019-05-19-1])
・ 「#1824. <C> と <G> の分化」 ([2014-04-25-1])
・ 「#1914. <g> の仲間たち」 ([2014-07-24-1])
・ 「#2498. yogh の文字」 ([2016-02-28-1])
2020-05-17 Sun
■ #4038. 年度初めに「英語の先生がこれだけ知っておくと安心というアルファベット関連の話し」の記事セット [hellog_entry_set][alphabet][hel_education][writing][orthography][grammatology][romaji][spelling][elt]
本ブログでは,英語のアルファベット (alphabet) に関する記事を多く書きためてきました.今年度はようやく年度が始まっているという学校が多いはずですので,先生方も児童・生徒たちに英語のアルファベットを教え始めている頃かと思います.算数のかけ算九九と同じで,アルファベットの学習も基礎の基礎としてドリルのように練習させるのが普通かと思います.しかし,先生方には,ぜひとも英語アルファベットの成立や発展について背景知識をもっておいてもらえればと思います.その知識を直接子供たちに教えはせずとも,1文字1文字に歴史的な深みがあることを知っているだけで,教えるに当たって気持ちの余裕が得られるのではないでしょうか.以下に,そのための記事セットをまとめました.
・ 「英語の先生がこれだけ知っておくと安心というアルファベット関連の話し」の記事セット
この記事セットは,実際には何年も英語を学び続けてきた上級者に対しても十分に楽しめる読み物となっていると思います.アルファベットに関するネタ集としてもどうぞ.
2020-04-19 Sun
■ #4010. 英語史の始まりはいつか? --- 600年説 [periodisation][anglo-saxon][christianity][history][latin][borrowing][alphabet][oe]
昨日の記事「#4009. 英語史の始まりはいつか? --- 449年説」 ([2020-04-18-1]) に引き続き,英語史の開始時期を巡る議論.今回は,実はあまり聞いたことのなかった(約)600年説について考えてみたい
597年に St. Augustine がキリスト教宣教のために教皇 Gregory I によってローマから Kent 王国へ派遣されたことは英国史上名高いが,この出来事がアングロサクソンの社会と文化を一変させたということは,象徴的な意味でよく分かる.社会と文化のみならず英語という言語にもその影響が及んだことは「#3102. 「キリスト教伝来と英語」のまとめスライド」 ([2017-10-24-1]),「#3845. 講座「英語の歴史と語源」の第5回「キリスト教の伝来」を終えました」 ([2019-11-06-1]),「#296. 外来宗教が英語と日本語に与えた言語的影響」 ([2010-02-17-1]) でたびたび注目してきた.確かに英語史上きわめて重大な事件が600年前後に起こったとはいえるだろう.Mengden の議論に耳を傾けてみよう.
. . . because the conversion is the first major change in the society and culture of the Anglo-Saxons that is not shared by the related tribes on the Continent, it is similarly significant for (the beginning of) an independent linguistic history of English as the settlement in Britain. Moreover, the immediate impact of the conversion on the language of the Anglo-Saxons is much more obvious than that of the migration: first, the Latin influence on English grows in intensity and, perhaps more crucially, enters new domains of social life; second, a new writing system, the Latin alphabet, is introduced, and third, a new medium of (linguistic) communication comes to be used --- the book.
600年説の要点は3つある.1つめは,主に語彙借用のことを述べているものと思われるが,ラテン語からキリスト教や学問を中心とした文明を体現する分野の借用語が流れ込んだこと.2つめはローマン・アルファベットの導入.3つめは本というメディアがもたらされたこと.
いずれも英語に直接・間接の影響を及ぼした重要なポイントであり,しかも各々の効果が非常に見えやすいというメリットもある.
・ Mengden, Ferdinand von. "Periods: Old English." Chapter 2 of English Historical Linguistics: An International Handbook. 2 vols. Ed. Alexander Bergs and Laurel J. Brinton. Berlin: Mouton de Gruyter, 2012. 19--32.
2020-02-01 Sat
■ #3932. 分かち書きがなかったら検索も不便だし,辞書の見出しという発想も出てこない [distinctiones][lexicography][word][dictionary][alphabet]
私たちは,非表音文字を含む日本語の書記において続け書き (scriptura continua) がなされるのに慣れており,特に問題を感じていない.しかし,最たる表音文字であるアルファベットを用いる言語圏で,もし続け書きがなされていたらと想像すると,頭が痛くなる.実際には,連日の記事で取り上げてきたように,それが古典ギリシア語や古典ラテン語では常態だったのではあるが (cf. 「#3929. なぜギリシアとローマは続け書きを採用したか? (1)」 ([2020-01-29-1]),「#3930. なぜギリシアとローマは続け書きを採用したか? (2)」 ([2020-01-30-1]),「#3931. 語順の固定化と分かち書き」 ([2020-01-31-1])) .
現代人の感覚からすると,アルファベットの分かち書き (distinctiones) という発明は当たり前すぎて,疑ったこともない.分かち書きがなかったらどうなるのだろうかと想像することすらしない.しかし,よくよく考えてみると,分かち書きにより語の区切りが明確に分かるというのは実にありがたいことである.続け書きでは,読み手がいちいち語の区切りを判断しなければならない.字面が連綿と続くページのなかで,ある語を検索しようとするとき,分かち書きと続け書きでは,検索スピードが天と地ほど異なるだろう.分かち書きは,語の検索という作業に革命的な能率をもたらすのだ.
さらに,語の検索を主たるサービスとして提供する辞書 (dictionary) や語彙集 (glossary) や各種の索引を考えてみよう.現代の辞書では,語彙項目がアルファベット順などの決められた順序で,行頭に見出しとして立てられているからこそ検索しやすいのであって,もし延々と連なる続け書きされた文字列のなかから目的の語彙項目の見出しを探さなければならないとしたら,そもそも検索サービスの用を足していないとみなされるだろう.辞書や索引は分かち書きが前提とされているのである.このことは当たり前すぎて気づきすらしなかったことだ.
このような点に注意を向けさせてくれたのは,Saenger (90) の指摘である.古代的な続け書きが解消され,中世的な分かち書きが発達してきて初めて,用が足りる辞書的なものが現われたのだという.同様に,アルファベット順に並べるという実践も,本質的には中世以降に出現した発想といっていいだろう.
It is difficult to imagine an alphabetical dictionary functioning as a reference tool when written in scriptura continua, even after the codex had supplanted the scroll. For the Greeks and Romans, alphabetical order was chiefly an aid to grammarians in assembling collections of grammatical definitions, such as that of Pompeius Festus, and as a mnemonic tool for relatively short lists of names. The alphabetical principle was never used to facilitate rapid consultation, as in modern indexes.
分かち書き,アルファベット順,辞書編纂というのは,すべて関わりがあるということだ.関連して,「#603. 最初の英英辞書 A Table Alphabeticall (1)」 ([2010-12-21-1]),「#604. 最初の英英辞書 A Table Alphabeticall (2)」 ([2010-12-22-1]),「#1451. 英語史上初のコンコーダンスと完全アルファベット主義」 ([2013-04-17-1]),「#2930. 以呂波引きの元祖『色葉字類抄』」 ([2017-05-05-1]),「#3365. 以呂波引きの元祖『色葉字類抄』 (2)」 ([2018-07-14-1]) も参照.
・ Saenger, P. Space Between Words: The Origins of Silent Reading. Stanford, CA: Stanford UP, 1997.
2020-01-30 Thu
■ #3930. なぜギリシアとローマは続け書きを採用したか? (2) [alphabet][distinctiones][punctuation][reading][writing][latin][greek][literacy][word]
昨日の記事 ([2020-01-29-1]) に引き続き,なぜギリシアとローマが,それ以前の地中海世界で普通に行なわれていた分かち書き (distinctiones) を捨て,代わりに続け書き (scriptura continua) を作用したかという問題について.
Saenger によれば,この問題に迫るには,読むという行為に対する現代的な発想を脇に置き,古代の読書習慣とその社会的文脈を理解する必要があるという.端的にいえば,現代人はみな黙読や速読に慣れており,何よりも「読みやすさ」を重視するが,古代ギリシアやローマの限られた人口の読み手にとって,読む行為とは口頭の音読のことであり,現代的な「読みやすさ」を追求する姿勢はなかったのだという.以下,Saenger の解説を聞いてみよう (11--12) .
. . . the ancient world did not possess the desire, characteristic of the modern age, to make reading easier and swifter because the advantages that modern readers perceive as accruing from ease of reading were seldom viewed as advantages by the ancients. These include the effective retrieval of information in reference consultation, the ability to read with minimum difficulty a great many technical logical, and scientific texts, and the greater diffusion of literacy throughout all social strata of the population. We know that the reading habits of the ancient world, which were profoundly oral and rhetorical by physiological necessity as well as by taste, were focused on a limited and intensely scrutinized canon of literature. Because those who read relished the mellifluous metrical and accentual patterns of pronounced text and were not interested in the swift intrusive consultation of books, the absence of interword space in Greek and Latin was not perceived to be an impediment to effective reading, as it would be to the modern reader, who strives to read swiftly. Moreover, oralization, which the ancients savored aesthetically, provided mnemonic compensation (through enhanced short-term aural recall) for the difficulty in gaining access to the meaning of unseparated text. Long-term memory of texts frequently read aloud also compensated for the inherent graphic and grammatical ambiguities of the languages of late antiquity.
Finally, the notion that the greater portion of the population should be autonomous and self-motivated readers was entirely foreign to the elitist literate mentality of the ancient world. For the literate, the reaction to the difficulties of lexical access arising from scriptura continua did not spark the desire to make script easier to decipher, but resulted instead in the delegation of much of the labor of reading and writing to skilled slaves, who acted as professional readers and scribes. It is in the context of a society with an abundant supply of cheap, intellectually skilled labor that ancient attitudes toward reading must be comprehended and the ready and pervasive acceptance of the suppression of word separation throughout the Roman Empire understood.
引用の最後に示唆されているように,古代人は続け書きにシフトすることで,読みにくさをあえて高めようとした,という言い方さえできるのかもしれない.この観点は,中世後期に再び分かち書きへと回帰していく過程を理解する上でも示唆的である.関連して「#1903. 分かち書きの歴史」 ([2014-07-13-1]) も参照.
・ Saenger, P. Space Between Words: The Origins of Silent Reading. Stanford, CA: Stanford UP, 1997.
2020-01-29 Wed
■ #3929. なぜギリシアとローマは続け書きを採用したか? (1) [alphabet][distinctiones][punctuation][reading][writing][latin][greek][indo-european][word]
アルファベットの分かち書き (distinctiones) と続け書き (scriptura continua) の問題については,最近では「#3926. 分かち書き,表語性,黙読習慣」 ([2020-01-26-1]) で,それ以前にも distinctiones の各記事で取り上げてきた.
Saenger (9) によると,アルファベットに母音表記の慣習が持ち込まれる以前の地中海世界では,スペースによるか点によるかの違いこそあれ,分かち書きが普通に行なわれていた.ところが,ギリシア語において母音表記が可能となるに及び,続け書きが生まれたという.これを時系列で整理すると次のようになる.
まず,アルファベット使用の初期から分かち書きは普通にあった.ところが,ギリシア・ローマ時代にそれが廃用となり,代わって続け書きが一般化した.ローマ帝国が崩壊し,中世後期の8世紀頃になると分かち書きが改めて導入され,その後徐々に一般化して現代に至る.
分かち書きは現在では当然視されているが,母音表記を享受し始めた古典時代の間に,その慣習が一度廃れた経緯があるということだ.では,なぜ母音表記の導入により,私たちにとって明らかに便利に思われる分かち書きが廃用となり,むしろ読みにくいと思われる続け書きが発達したのだろうか.Saenger (9--10) によれば,母音表記と続け書きの間には密接な関係があるという.
The uninterrupted writing of ancient scriptura continua was possible only in the context of a writing system that had a complete set of signs for the unambiguous transcription of pronounced speech. This occurred for the first time in Indo-European languages when the Greeks adapted the Phoenician alphabet by adding symbols for vowels. The Greco-Latin alphabetical scripts, which employed vowels with varying degrees of modification, were used for the transcription of the old forms of the Romance, Germanic, Slavic, and Hindu tongues, all members of the Indo-European language group, in which words were polysyllabic and inflected. For an oral reading of these Indo-European languages, the reader's immediate identification of words was not essential, but a reasonably swift identification and parsing of syllables was fundamental. Vowels as necessary and sufficient codes for sounds permitted the reader to identify syllables swiftly within rows of uninterrupted letters. Before the introduction of vowels to the Phoenician alphabet, all the ancient languages of the Mediterranean world---syllabic or alphabetical, Semitic or Indo-European---were written with word separation by either space, points, or both in conjunction. After the introduction of vowels, word separation was no longer necessary to eliminate an unacceptable level of ambiguity.
Throughout the antique Mediterranean world, the adoption of vowels and of scriptura continua went hand in hand. The ancient writings of Mesopotamia, Phoenicia, and Israel did not employ vowels, so separation between words was retained. Had the space between words been deleted and the signs been written in scriptura continua, the resulting visual presentation of the text would have been analogous to a modern lexogrammatic puzzle. Such written languages might have been decipherable, given their clearly defined conventions for word order and contextual clues, but only after protracted cognitive activity that would have made fluent reading as we know it impractical. While the very earliest Greek inscriptions were written with separation by interpuncts, points placed at midlevel between words, Greece soon thereafter became the first ancient civilization to employ scriptura continua. The Romans, who borrowed their letter forms and vowels from the Greeks, maintained the earlier Mediterranean tradition of separating words by points far longer than the Greeks, but they, too, after a scantily documented period of six centuries, discarded word separation as superfluous and substituted scriptura continua for interpunct-separated script in the second century A.D.
ここで展開されている議論について,私はよく理解できていない.母音表記の導入の結果,音節が同定しやすくなったという理屈がよくわからない.また,仮にそれが本当だったとして,文字の読み手が従来の分かち書きではなく続け書きにシフトしたとしても何とか解読できる,という点までは理解できるが,なぜ続け書きに積極的にシフトしたのかは不明である.上の議論は,消極的な説明づけにすぎないように思われる.
母音文字を発明してアルファベットを便利にしたギリシア人が,読みにくい続け書きにシフトしたというのは,何か矛盾しているように感じられる.実際,この問題は多くの論者を悩ませ続けてきたようだ (Saenger 10)
ギリシア人による母音文字の導入という文字史上の画期的な出来事については,「#423. アルファベットの歴史」 ([2010-06-24-1]) や「#2092. アルファベットは母音を直接表わすのが苦手」 ([2015-01-18-1]) を参照.
・ Saenger, P. Space Between Words: The Origins of Silent Reading. Stanford, CA: Stanford UP, 1997.
2020-01-27 Mon
■ #3927. 英語におけるローマン・アルファベット一式の歴史的変遷 [alphabet][grapheme][oe][link]
Cook (166) に,"Comparing older letter forms with Modern English" と題する表がある.大雑把ではあるが,英語のローマン・アルファベット一式を構成する文字の目録の変遷がよくまとまっているので,以下に再現する.
| Shared letters | Extra letters | Variants of another letter | Rare letters | Unused letters | |
| Old English (tenth century) | b c d f h l m n p r s t | ȝ ƿ þ ð æ | x (used for -cs occasionally æx) | k q z | g j v |
| a e i o u y | |||||
| Middle English (fourteenth century) | b c d f g h k l m n p q r s t w x z | ȝ þ (later th) | u (medial v) | ||
| a e i o u y | j (initial i) | ||||
| Early Modern English (1500--1700) | b c d f g h k l m n p q r s t w x z | u/v (till 1630) | |||
| a e i o u y | j/i (till 1640) | ||||
| 'long' ʃ | |||||
| Modern English (1700--present-day) | b c d f g h j k l m n p q r s t v w x z | ||||
| a e i o u y |
本ブログでも各文字に関する話題はいろいろと取り上げてきた.g, v など各文字自身のタグが付けられている記事も多いので,ぜひご一読を.以下にもいくつかピックアップしておきたい.
・ 「#3038. 古英語アルファベットは27文字」 ([2017-08-21-1])
・ 「#3049. 近代英語期でもアルファベットはまだ26文字ではなかった?」 ([2017-09-01-1])
・ 「#1824. <C> と <G> の分化」 ([2014-04-25-1])
・ 「#1650. 文字素としての j の独立」 ([2013-11-02-1])
・ 「#1914. <g> の仲間たち」 ([2014-07-24-1])
・ 「#2498. yogh の文字」 ([2016-02-28-1])
・ 「#584. long <s> と graphemics」 ([2010-12-02-1])
・ 「#2997. 1800年を境に印刷から消えた long <s>」 ([2017-07-11-1])
・ 「#3875. 手書きでは19世紀末までかろうじて生き残っていた long <s>」 ([2019-12-06-1])
・ 「#373. <u> と <v> の分化 (1)」 ([2010-05-05-1])
・ 「#374. <u> と <v> の分化 (2)」 ([2010-05-06-1])
・ 「#3391. Johnson にも悩ましかった i/j, u/v の「四つ文字」問題」 ([2018-08-09-1])
・ 「#2411. 英語の <w> = "double u" とフランス語の <w> = "double v"」 ([2015-12-03-1])
・ 「#2280. <x> の話」 ([2015-07-25-1])
・ 「#1830. Y の名称」 ([2014-05-01-1])
・ 「#446. しぶとく生き残ってきた <z>」 ([2010-07-17-1])
・ Cook, Vivian. The English Writing System. London: Hodder Education, 2004.
[ 固定リンク | 印刷用ページ ]
Powered by WinChalow1.0rc4 based on chalow