2015-01-18 Sun
■ #2092. アルファベットは母音を直接表わすのが苦手 [grammatology][grapheme][vowel][alphabet][greek][latin][spelling][digraph][diacritical_mark]
「#1826. ローマ字は母音の長短を直接示すことができない」 ([2014-04-27-1]) で取り上げた話題をさらに推し進めると,標記のように「アルファベットは母音を直接表わすのが苦手」と言ってしまうこともできるかもしれない.この背景には3千年を超えるアルファベットの歴史がある.
「#423. アルファベットの歴史」 ([2010-06-24-1]) でみたように,古代ギリシア人は子音文字であるフェニキアのアルファベットを素材として今から3千年ほど前に初めて母音字を創案したとされるが,その創案は,ギリシア語の子音表記にとって余剰的なフェニキア文字のいくつかをギリシア語の母音に当ててみようという,どちらかというと消極的な動機づけに基づいていた.つまり,母音を表す母音字を発明しようという積極的な動機があったわけではない.実際,ギリシア語の様々な母音を正確に表わそうとするならば,フェニキア・アルファベットからのいくつかの余剰的な文字だけでは明らかに数が不足していた.だが,だからといって新たな母音字を作り出すというよりは,あくまで伝統的な文字セットを用いて子音と同時にいくつかの母音「も」表わせるように工夫したということだ.フェニキア文字以後のローマン・アルファベットの歴史的発展の記述を Horobin (48--49) より要約すると,次のようになる.
The Origins of the Roman alphabet lie in the script used by Phoenician traders around 1000 BC. This was a system of twenty-two letters which represented the individual consonant sounds, in a similar way to modern consonantal writing systems like Arabic and Hebrew. The Phoenician system was adopted and modified by the Greeks, who referred to them as 'Phoenician letters' and who added further symbols, while also re-purposing existing consonantal symbols not needed in Greek to represent vowel sounds. The result was a revolutionary new system in which both vowels and consonants were represented, although because the letters used to represent the vowel wounds in Greek were limited to the redundant Phoenician consonants, a mismatch between the number of vowels in speech and writing was created which still affects English today.
この消極的な母音字の創案とその伝統は,そのままエトルリア文字,それからローマ字へも伝わり,結果的には現代英語にもつらなっている.もちろん,英語史を含め,その後ローマ字を用いてきた多くの言語変種の歴史的段階において,母音をより正確に表わす方法は編み出されてきた.英語史に限っても,二重字 (digraph) など文字の組み合わせにより,ある母音を表すということはしばしば行われてきたし,magic <e> (cf. 「#1289. magic <e>」 ([2012-11-06-1])) にみられるような発音区別符(号) (diacritical mark; cf. 「#870. diacritical mark」 ([2011-09-14-1])) 的な <e> の使用によって先行母音の音質や音量を表す試みもなされてきた.だが,現代英語においても,これらの方法は間接的な母音表記にとどまり,ずばり1文字で直接ある母音を表記するという作用は限定的である.数千年という長い時間の歴史的視座に立つのであれば,これはアルファベットが子音文字として始まったことの呪縛とも称されるものかもしれない.
・ Horobin, Simon. Does Spelling Matter? Oxford: OUP, 2013.
2014-12-06 Sat
■ #2049. <sh> とその異綴字の歴史 [grapheme][alphabet][consonant][spelling][orthography][timeline][ormulum][digraph]
英語史において無声歯茎硬口蓋摩擦音 /ʃ/ は安定的な音素だったといえるが,それを表わす綴字はヴァリエーションが豊富だった.近現代英語では二重字 (digraph) の <sh> が原則だが,とりわけ中英語では様々な異綴字が行われていた.その歴史の概略は「#1893. ヘボン式ローマ字の <sh>, <ch>, <j> はどのくらい英語風か」 ([2014-07-03-1]) で示し,ほかにも「#479. bushel」 ([2010-08-19-1]) や「#1238. アングロ・ノルマン写字生の神話」 ([2012-09-16-1]) の記事で関連する話題に軽く触れてきた.
今回は OED sh, n.1 の説明に依拠して,英語史上,問題の子音がどのように綴られてきたのか,もう少し細かく記述したい.まずは,OED の記述に基づいてあらあらの年表を示そう.正確を期しているわけではないので,参考までに.
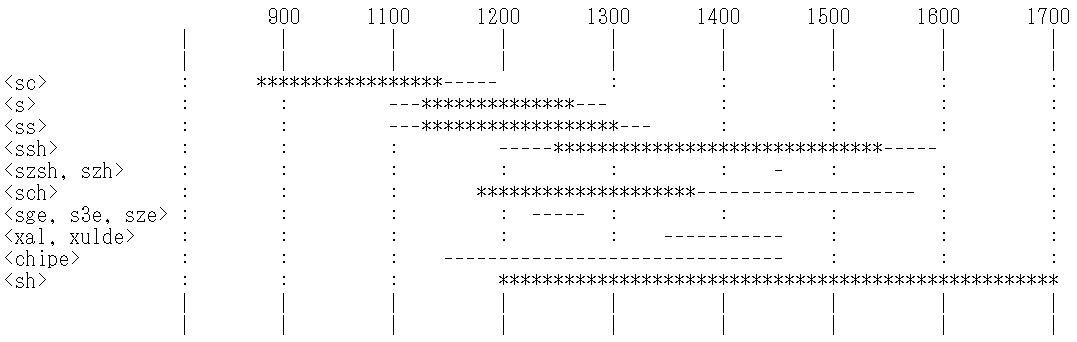
以下注記を加える.後期古英語の標準綴字だった <sc> は中英語に入ると衰微の一途をたどり,他の種々の異綴字に置き換えられることになった.この子音は当時のフランス語の音素としては存在しなかったため,フランス語で書くことに慣れていた中英語の写字生は,何らかの工夫を強いられることになった.最も単純な試みは単独の <s> を用いる方法で,初期近代英語では語頭と語末の /ʃ/ を表わすのに利用されたが,一般的にはならなかった.その点,重子音字 <ss> は環境を選ばずに用いられたこともあり,より広く用いられた.語中と語末では <ssh> も成功を収め,長く16世紀まで用いられた.16世紀の変わり種としては,Coverdale (1535) でしばしば用いられた <szsh> や <szh> が挙げられるが,あまりに風変わりで真似る者は出なかった.<ss> や <sch> のほかに中英語の半ばで優勢だった異綴字としては,現代ドイツ語綴字を思わせる <sch> を挙げないわけにはいかない.とりわけ語頭では広く行われ,北部方言では16世紀末まで続いた.
特定の語や形態素に現われる /ʃ/ を表わすのに,特定の綴字が用いられたケースがある.例えば she を表わすのに,13世紀には <sge>,
最後に,1200年頃の Ormulum でもすでに規則的に用いられていたが,<sh> が優勢な二重字として他を圧することになる.14世紀末のロンドン文書や Chaucer でも一般的であり,Caxton では標準となった.
近現代英語では,いくつかの語においてこの子音を表わすのに他の字を用いることもあるが,いずれも語源的あるいは発音上説明されるべき周辺的な例である.例えば,machine, schedule, Asia, -tion (cf. 「#2018. <nacio(u)n> → <nation> の綴字変化」 ([2014-11-05-1])) などである.
2014-10-20 Mon
■ #2002. Richard Hodges の綴字改革ならぬ綴字教育 [spelling_reform][spelling][orthography][alphabet][emode][final_e][silent_letter][mulcaster][diacritical_mark]
「#1939. 16世紀の正書法をめぐる議論」 ([2014-08-18-1]) や「#1940. 16世紀の綴字論者の系譜」 ([2014-08-19-1]) でみたように,16世紀には様々な綴字改革案が出て,綴字の固定化を巡る議論は活況を呈した.しかし,Mulcaster を代表とする伝統主義路線が最終的に受け入れられるようになると,16世紀末から17世紀にかけて,綴字改革の熱気は冷めていった.人々は,決してほころびの少なくない伝統的な綴字体系を半ば諦めの境地で受け入れることを選び,むしろそれをいかに効率よく教育していくかという実際的な問題へと関心を移していったのである.そのような教育者のなかに,Edmund Coote (fl. 1597; see Edmund Coote's English School-maister (1596)) や Richard Hodges (fl. 1643--49) という顔ぶれがあった.
Hodges については「#1856. 動詞の直説法現在形語尾 -eth は17世紀前半には -s と発音されていた」 ([2014-05-27-1]) でも触れたように,綴字史への関与のほかにも,当時の発音に関する貴重な資料を提供してくれているという功績がある.例えば Hodges のリストには,cox, cocks, cocketh; clause, claweth, claws; Mr Knox, he knocketh, many knocks などとあり,-eth が -s と同様に発音されていたことが示唆される (Horobin 129) .また,様々な発音区別符(号) (diacritical mark) を綴字に付加したことにより,Hodges は事実上の発音表記を示してくれたのである.例えば,gäte, grëat のように母音にウムラウト記号を付すことにより長母音を表わす方式や,garde, knôwn のように黙字であることを示す下線を導入した (The English Primrose (1644)) .このように,Hodges は当時のすぐれた音声学者といってもよく,Shakespeare 死語の時代の発音を伝える第1級の資料を提供してくれた.
しかし,Hodges の狙いは,当然ながら後世に当時の発音を知らしめることではなかった.それは,あくまで綴字教育にあった.体系としては必ずしも合理的とはいえない伝統的な綴字を子供たちに効果的に教育するために,その橋渡しとして,上述のような発音区別符の付加を提案したのである.興味深いのは,その提案の中身は,1世代前の表音主義の綴字改革者 William Bullokar (fl. 1586) の提案したものとほぼ同じ趣旨だったことである.Bullokar も旧アルファベットに数々の記号を付加することにより,表音を目指したのだった.しかし,Hodges の提案のほうがより簡易で一貫しており,何よりも目的が綴字改革ではなく綴字教育にあった点で,似て非なる試みだった.時代はすでに綴字改革から綴字教育へと移り変わっており,さらに次に来たるべき綴字規則化論者 ("Spelling Regularizers") の出現を予期させる段階へと進んでいたのである.
この時代の移り変わりについて,渡部 (96) は「Bullokar と同じ工夫が,違った目的のためになされているところに,つまり17世紀中葉の綴字問題が一種の「ルビ振り」に似た努力になっている所に,時代思潮の変化を認めざるをえない」と述べている.Hodges の発音区別符をルビ振りになぞらえたのは卓見である.ルビは文字の一部ではなく,教育的配慮を含む補助記号である.したがって,形としてはほぼ同じものであったとしても,文字の一部を構成する不可欠の要素として Bullokar が提案した記号は,決してルビとは呼べない.ルビ振りの比喩により,Bullokar の堅さと Hodges の柔らかさが感覚的に理解できるような気がしてくる.
・ Horobin, Simon. Does Spelling Matter? Oxford: OUP, 2013.
・ 渡部 昇一 『英語学史』 英語学大系第13巻,大修館書店,1975年.
2014-08-19 Tue
■ #1940. 16世紀の綴字論者の系譜 [spelling][orthography][emode][spelling_reform][mulcaster][alphabet][grammatology][hart]
昨日の記事「#1939. 16世紀の正書法をめぐる議論」 ([2014-08-18-1]) で,数名の綴字論者の名前を挙げた.彼らは大きく表音主義の急進派と伝統主義の穏健派に分けられる.16世紀半ばから次世紀へと連なるその系譜を,渡部 (64) にしたがって示そう.

昨日の記事で出てきていない名前もある.Cheke と Smith は宮廷と関係が深かったことから,宮廷関係者である Waad と Laneham にも表音主義への関心が移ったようで,彼らは Cheke の新綴字法を実行した.Hart は Bullokar や Waad に影響を与えた.伝統主義路線としては,Mulcaster と Edmund Coote (fl. 1597; see Edmund Coote's English School-maister (1596)) が16世紀末に影響力をもち,17世紀には Francis Bacon (1561--1626) や Ben Jonson (c. 1573--1637) を経て,18世紀の Dr. Johnson (1709--84) まで連なった.そして,この路線は,結局のところ現代にまで至る正統派を形成してきたのである.
結果としてみれば,厳格な表音主義は敗北した.表音文字を標榜する ローマン・アルファベット (Roman alphabet) を用いる英語の歴史において,厳格な表音主義が敗退したということは,文字論の観点からは重要な意味をもつように思われる.文字にとって最も重要な目的とは,表語,あるいは語といわずとも何らかの言語単位を表わすことであり,アルファベットに典型的に備わっている表音機能はその目的を達成するための手段にすぎないのではないか.もちろん表音機能それ自体は有用であり,捨て去る必要はないが,表語という最終目的のために必要とあらば多少は犠牲にできるほどの機能なのではないか.
このように考察した上で,「#1332. 中英語と近代英語の綴字体系の本質的な差」 ([2012-12-19-1]),「#1386. 近代英語以降に確立してきた標準綴字体系の特徴」 ([2013-02-11-1]),「#1829. 書き言葉テクストの3つの機能」 ([2014-04-30-1]) の議論を改めて吟味したい.
・ 渡部 昇一 『英語学史』 英語学大系第13巻,大修館書店,1975年.
2014-08-18 Mon
■ #1939. 16世紀の正書法をめぐる議論 [punctuation][alphabet][standardisation][spelling][orthography][emode][spelling_reform][mulcaster][spelling_pronunciation_gap][final_e][hart]
16世紀には正書法 (orthography) の問題,Mulcaster がいうところの "right writing" の問題が盛んに論じられた(cf. 「#1407. 初期近代英語期の3つの問題」 ([2013-03-04-1])).英語の綴字は,現代におけると同様にすでに混乱していた.折しも生じていた数々の音韻変化により発音と綴字の乖離が広がり,ますます表音的でなくなった.個人レベルではある種の綴字体系が意識されていたが,個人を超えたレベルではいまだ固定化されていなかった.仰ぎ見るはラテン語の正書法だったが,その完成された域に達するには,もう1世紀ほどの時間をみる必要があった.以下,主として Baugh and Cable (208--14) の記述に依拠し,16世紀の正書法をめぐる議論を概説する.
個人レベルでは一貫した綴字体系が目指されたと述べたが,そのなかには私的にとどまるものもあれば,出版されて公にされるものもあった.私的な例としては,古典語学者であった John Cheke (1514--57) は,長母音を母音字2つで綴る習慣 (ex. taak, haat, maad, mijn, thijn) ,語末の <e> を削除する習慣 (ex. giv, belev) ,<y> の代わりに <i> を用いる習慣 (ex. mighti, dai) を実践した.また,Richard Stanyhurst は Virgil (1582) の翻訳に際して,音節の長さを正確に表わすための綴字体系を作り出し,例えば thee, too, mee, neere, coonning, woorde, yeet などと綴った.
公的にされたものの嚆矢は,1558年以前に出版された匿名の An A. B. C. for Children である.そこでは母音の長さを示す <e> の役割 (ex. made, ride, hope) などが触れられているが,ほんの数頁のみの不十分な扱いだった.より野心的な試みとして最初に挙げられるのは,古典語学者 Thomas Smith (1513--77) による1568年の Dialogue concerning the Correct and Emended Writing of the English Language だろう.Smith はアルファベットを34文字に増やし,長母音に符号を付けるなどした.しかし,この著作はラテン語で書かれたため,普及することはなかった.
翌年1569年,そして続く1570年,John Hart (c. 1501--74) が An Orthographie と A Method or Comfortable Beginning for All Unlearned, Whereby They May Bee Taught to Read English を出版した.Hart は,<ch>, <sh>, <th> などの二重字 ((digraph)) に対して特殊文字をあてがうなどしたが,Smith の試みと同様,急進的にすぎたために,まともに受け入れられることはなかった.
1580年,William Bullokar (fl. 1586) が Booke at large, for the Amendment of Orthographie for English Speech を世に出す.Smith と Hart の新文字導入が失敗に終わったことを反面教師とし,従来のアルファベットのみで綴字改革を目指したが,代わりにアクセント記号,アポストロフィ,鉤などを惜しみなく文字に付加したため,結果として Smith や Hart と同じかそれ以上に読みにくい恐るべき正書法ができあがってしまった.
Smith, Hart, Bullokar の路線は,17世紀にも続いた.1634年,Charles Butler (c. 1560--1647) は The English Grammar, or The Institution of Letters, Syllables, and Woords in the English Tung を出版し,語末の <e> の代わりに逆さのアポストロフィを採用したり,<th> の代わりに <t> を逆さにした文字を使ったりした.以上,Smith から Butler までの急進的な表音主義の綴字改革はいずれも失敗に終わった.
上記の急進派に対して,保守派,穏健派,あるいは伝統・慣習を重んじ,綴字固定化の基準を見つけ出そうとする現実即応派とでも呼ぶべき路線の第一人者は,Richard Mulcaster (1530?--1611) である(この英語史上の重要人物については「#441. Richard Mulcaster」 ([2010-07-12-1]) や mulcaster の各記事で扱ってきた).彼の綴字に対する姿勢は「綴字は発音を正確には表わし得ない」だった.本質的な解決法はないのだから,従来の慣習的な綴字を基にしてもう少しよいものを作りだそう,いずれにせよ最終的な規範は人々が決めることだ,という穏健な態度である.彼は The First Part of the Elementarie (1582) において,いくつかの提案を出している.<fetch> や <scratch> の <t> の保存を支持し,<glasse> や <confesse> の語末の <e> の保存を支持した.語末の <e> については,「#1344. final -e の歴史」 ([2012-12-31-1]) でみたような規則を提案した.
「#1387. 語源的綴字の採用は17世紀」 ([2013-02-12-1]) でみたように,Mulcaster の提案は必ずしも後世の標準化された綴字に反映されておらず(半数以上は反映されている),その分だけ彼の歴史的評価は目減りするかもしれないが,それでも綴字改革の路線を急進派から穏健派へシフトさせた功績は認めてよいだろう.この穏健派路線は English Schoole-Master (1596) を著した Edmund Coote (fl. 1597) や The English Grammar (1640) を著した Ben Jonson (c. 1573--1637) に引き継がれ,Edward Phillips による The New World of English Words (1658) が世に出た17世紀半ばまでには,綴字の固定化がほぼ完了することになる.
この問題に関しては渡部 (40--64) が詳しく,たいへん有用である.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
・ 渡部 昇一 『英語学史』 英語学大系第13巻,大修館書店,1975年.
2014-07-24 Thu
■ #1914. <g> の仲間たち [grammatology][grapheme][alphabet][consonant][g][yogh][z]
英語史における <g> とその仲間の文字の関係は,とりわけ中英語期において,非常に複雑である.古英語期より,<g> という文字素 (grapheme) には,異文字 (allograph) として,平らな頭部をもつ <<Ӡ>> という字形 (insular <g>) と丸い閉じた頭部をもつ <<g>> という字形 (Carolingian <g>) があった.古英語では,前者が普通であり,後者は主としてラテン語を写すのに使われたにすぎない.当時の <g> は,後母音(字)の前では軟口蓋閉鎖音の /g/,前母音(字)の前では硬口蓋摩擦音の /j/ に対応した.<god> (God), <gear> (year) の如くである.しかし,写字生の中には2つの音価の混用を嫌い,/j/ に <i> を当てたり,二重字 <ge> を用いた者もいた.yoke に相当する語を <ioc>, <geoc> などと綴った例がある.
ノルマン・コンクェストが起こり中英語期に入ると,<<g>> (Carolingian <g>) が一般化した.原則としてその音価は /g/ だったが,「#1651. j と g」 ([2013-11-03-1]) で見たように /ʤ/ にも対応することがあった.一方,<<Ӡ>> (insular <g>) は,従来通り硬口蓋摩擦音 /j/ を表わし続けて残ったが,さらに軟口蓋摩擦音 /x/ をも表わすようになった.ここから,両音を中に含む yogh がその呼び名となった.yogh の字形は <<Ӡ>> (insular <g>) から,より数字の <3> やフランス語式の <z> に近い字形である <<ȝ>> へと発展し,中英語期を通じて広く行われたが,15世紀に各々の音価は <y> や <gh> の文字により置き換えられた.<ȝet> (yet), <ȝou> (you), <niȝt> (night), <liȝt> (light) を参照.
しかし,この <<ȝ>> は,15世紀後半に印刷技術が導入されたときに,Scotland でちょっとしたひねりを加えられた.先に述べたように,その字形はフランス語式の <z> の字形に類似していたため,スコットランドの印刷家たちは見慣れない <<ȝ>> を <<z>> と混同してしまった.そこで,<<ȝ>> と綴るべきところに誤って <<z>> と綴る例が見られるようになる.<zeir> (year), <ze> (ye), <capercailzie> (capercailye) の如くである.固有名詞にもその混同の痕跡を残しており,「#447. Dalziel, MacKenzie, Menzies の <z>」 ([2010-07-18-1]) で見たとおりである.
このように,insular <g> および yogh は,古英語以来,近代の入り口に至るまで,他の複数の文字と複雑に関わり合い,時に混乱を引き起こしながらも活躍した文字として,英語文字史の一時代を飾ったのである.以上,Horobin (86, 91) を参考にして執筆した.
・ Horobin, Simon. Does Spelling Matter? Oxford: OUP, 2013.
2014-07-13 Sun
■ #1903. 分かち書きの歴史 [punctuation][manuscript][writing][grammatology][syntagma_marking][alphabet][distinctiones]
単語と単語の間にスペースを挿入する書記慣習を分かち書きと呼んでいる.本ブログでは,「#1112. 分かち書き (1)」 ([2012-05-13-1]),「#1113. 分かち書き (2)」 ([2012-05-14-1]),「#1114. 草仮名の連綿と墨継ぎ」 ([2012-05-15-1]) の記事で取り上げてきた.分かち書きは,現代英語を含めローマ字を用いる書記体系では当然視されているが,古代ローマのラテン語表記において,分かち書きが習慣的に行われていたわけではない.英語史としてみれば,分かち書きは,古英語期にキリスト教ともにアイルランドの修道僧によってもたらされた慣習であり,その歴史は意外と新しい.Horobin (72) 曰く,
. . . we need to remember that word division and the use of blank spaces between words was a relatively new phenomenon when the Beowulf manuscript was written. In Antiquity manuscripts were written using scriptio continua, a continuous script without any breaks between words at all. The practice of dividing words in the way we do today was introduced by the Irish monks who brought Christianity to the Northumbrians.
古代ローマの伝統的な続け書き (scriptio continua) に代わり,革新的な分かち書き (distinctiones) が最初にラテン語を解さないアイルランド人,そして後にアングロサクソン人によって採用されることになったことは,偶然ではない.日本語母語話者は,分かち書きも句読点もない,ひらがなだけの文章を非常に読みにくく感じるだろうが,日本語を知っている以上,なんとかなる.しかし,日本語を母語としない学習者にとっては,さらに読みにくく感じられるだろう.同様に,ラテン語を母語とするものは scriptio continua で書かれたラテン語の文章を読むのに耐えられたかもしれないが,非母語としてのラテン語の学習者であった古英語期のアイルランド人やイングランド人は苦労を強いられたろう.そこで彼らは,読みやすさと解釈のしやすさを求めて,句読法に一大革新をもたらすことになったのである.この辺りの事情について,Clemens and Graham より2箇所引用する.
In late antiquity, scribes wrote literary texts in scriptura continua (also sometimes called scriptio continua), that is, without any separation between the words. Moreover, often they did not enter any marks of punctuation on the page. In many cases, punctuation was added by the reader, in particular by the reader who had to recite the text aloud. Such punctuation was often only sporadic, inserted at those points where it was necessary to counteract possible ambiguity (for example, when it was not immediately clear where one word ended and another began). (83)
Irish and Anglo-Saxon scribes made notable contributions to the use and development of the distinctiones system. Following their conversion to Christianity in the fifth and sixth through seventh centuries, respectively, the Irish and the Anglo-Saxons copied Latin texts avidly. Because their native languages were not directly related to Latin, these scribes required more visual cues to understand Latin than did Italian, Spanish, or French scribes. It was Irish scribes who were primarily responsible for the introduction of the practice of word separation, a major contribution to what has been called the "grammar of legibility." Once word separation became common, later scribes sometimes "updated earlier manuscripts by placing a punctus between words in texts originally written in scriptura continua. (83--84)
イギリス諸島の修道僧たちは,ラテン語の scriptio continua の読みにくさを疎んじ,自らが書くときには語と語の間にスペースを入れる慣習を確立した.すでに scriptio continua で書かれてしまっている文章については,語と語の間に句読点を挿入することで,読みやすさを確保しようとした.したがって,統語的な区切り ("grammar of legibility") を明確にするために,彼らは分かち書き以外にもいくつかの手段を編み出したのだが,その中でもとりわけ有効な慣習として確立したのが,分かち書きだった.
現在私たちが英語の書き言葉において当然視している分かち書きという慣習は,外国語学習者がその言語の読み書きを容易にするために編み出した語学学習のテクニックに由来するのである.この点では,語句注釈や漢文の訓点とも通じるところがある.
・ Horobin, Simon. Does Spelling Matter? Oxford: OUP, 2013.
・ Clemens, Raymond and Timothy Graham. Introduction to Manuscript Studies. Ithaca & London: Cornel UP, 2007.
2014-07-07 Mon
■ #1897. "futhorc" の acrostic [runic][word_play][acronym][oe][alphabet][alliteration]
「#1875. acrostic と折句」 ([2014-06-15-1]) の記事で,現代英語と日本語から acrostic なる言葉遊びの例をみたが,古英語にも acrostic の詩がある.The Rune Poem と呼ばれる6節からなる詩で,各節の開始文字を取り出すと,アングロサクソン系ルーン文字一式の呼称である "FUÞORC" という単語が浮かび上がる(「#1006. ルーン文字の変種」 ([2012-01-28-1]) を参照).Crystal (13) より,The Rune Poem を味読しよう.各詩行の頭韻 (alliteration) も規則的である.
Feoh byþ frofur fira gehwylcum--- Wealth is a joy to every man--- sceal ðeah manna gehwylc miclun hyt dælan but every man must share it well gif he wile for Drihtne domes hleotan. if he wishes to gain glory in the sight of the Lord. Ur byþ anmod 7 oferhyrned, Aurochs is fierce, with gigantic horns, felafrecne deor, feohteþ mid hornum, a very savage animal, it fights with horns, mære morstapa: þæt is modig wuht! a well-known moor-stepper: it is a creature of courage! Þorn byþ ðearle scearp, ðegna gehwylcum Thorn is very sharp, harmful to every man anfeng ys yfyl, ungemetun reþe who seizes it, unsuitably severe manna gehwylcun ðe him mid resteð. to every man who rests on it. Os byþ ordfruma ælcre spræce, Mouth is the creator of all speech, wisdomes wraþu and witena frofur a supporter of wisdom and comfort of wise men, and eorla gehwam eadnys and tohiht. and a blessing and hope to every man. Rad byþ on recyde rinca gehwylcum Journey is to every warrior in the hall sefte, and swiþhwæt ðam ðe sitteþ onufan pleasant, and bitingly tough to him who sits meare mægenheardum ofer milpaþas. on a mighty steed over the mile-paths. Cen byþ cwicera gehwam cuþ on fyre, Torch is to every living thing known by its fire; blac and beorhtlic, byrneþ oftust bright and brilliant, it burns most often ðær hi æþelingas inne restaþ. where the princes take their rest within.
・ Crystal, David. The Cambridge Encyclopedia of the English Language. 2nd ed. Cambridge: CUP, 2003.
2014-07-03 Thu
■ #1893. ヘボン式ローマ字の <sh>, <ch>, <j> はどのくらい英語風か [alphabet][japanese][writing][grammatology][orthography][romaji][j][norman_french][digraph]
昨日の記事 ([2014-07-02-1]) の最後に,ヘボン式ローマ字の綴字のなかで,とりわけ英語風と考えられるものとして <sh>, <ch>, <j> の3種を挙げた.現代英語の正書法を参照すれば,これらの綴字が,共時的な意味で「英語風」であることは確かである.しかし,この「英語風」との認識の問題を英語史という立体的な観点から眺めると,問題のとらえ方が変わってくるかもしれない.歴史的には,いずれの綴字も必ずしも英語に本来的とはいえないからである.
まず,<sh> = /ʃ/ が正書法として確立したのは15世紀中頃のことにすぎない.古英語では,この子音は <sc> という二重字 (digraph) で規則的に綴られていた.この二重字は中英語へも引き継がれたが,中英語では様々な異綴りが乱立し,そのなかで埋没していった.例えば,現代英語の <ship> に対応するものとして,中英語では <chip>, <scip>, <schip>, <ship>, <sip>, <ssip> などの綴字がみられる.このなかで,中英語期中最もよく用いられたのは <sch> だろう.現代的な <sh> は,13世紀初頭に Orm が初めてかつ規則的に用いたが,ある程度一般的になったのは14世紀のロンドンで Chaucer などが <sh> を常用するようになってからである.その後,<sh> は15世紀中頃に広く受け入れられるようになり,17世紀までに他の異綴りを廃用へ追い込んだ.このように,二重字 <sh> の慣習は,英語の土壌から発したことは確かだが,中英語期の異綴りとの長い競合の末にようやく定まった慣習であり,英語の規準となってからの歴史はそれほど長いものではない (Upward and Davidson 157) .
次に,<ch> = /ʧ/ の対応の起源は,疑いなく外来である.この子音は,古英語では典型的に前舌母音の前位置に現われ,規則的に <c> で綴られた.しかし,音韻変化の結果,<c> は同じ音韻環境で /k/ をも表わすようになり,二重の役割をもつに至った.この両義性が背景にあったことと,中英語期に Norman French の綴字慣習が広範な影響力をもったことにより,英語では自然と Norman French の <ch> = /ʧ/ が受け入れられる結果となった.12世紀には,早くも古英語的な <c> = /ʧ/ の対応はほとんど廃れ,古英語由来の単語も以降こぞって <ch> で綴り直されるようになった.二重字 <ch> の受容には,文字と音韻の明確な対応を目指す言語内的な要求と,Norman French の綴字習慣の進出という言語外的な要因とが関与しているのである (Upward and Davidson 100) .
<j> については,「#1828. j の文字と音価の対応について再訪」 ([2014-04-29-1]) と「#1650. 文字素としての j の独立」 ([2013-11-02-1]) で見たように,フランス借用語を大量に入れた中英語期に,やはりフランス語の綴字習慣をまねたものが,後に英語でも定着したにすぎない.実際,<j> で始まる英単語は原則として英語本来語ではない.
以上のように,今では「英語風」と認識されている <sh>, <ch>, <j> も,定着するまでは不安定な綴字だったのであり,当初から典型的に「英語風」だったわけではない.<ch> と <j> の2つに至っては,当時のファッショナブルな言語であるフランス語の綴字習慣の模倣であった.英語が当時はやりのフランス語風を受容したように,日本語が現在はやりの英語風を受容したとしても驚くには当たらないだろう.綴字習慣や正書法も,時代の潮流とともに変化することもあれば変異もするのである.そして,言語接触における影響の方向は,流行や威信などの社会言語学的な要因に依存するのが常である.ローマ字の○○式の評価も,歴史的な観点を含めて立体的になされる必要があると考える.
・ Upward, Christopher and George Davidson. The History of English Spelling. Malden, MA: Wiley-Blackwell, 2011.
2014-07-02 Wed
■ #1892. 「ローマ字のつづり方」 [alphabet][japanese][writing][grammatology][orthography][romaji][language_planning]
「#1879. 日本語におけるローマ字の歴史」 ([2014-06-19-1]) の記事で触れたように,現代の日本語におけるローマ字使用の慣用は,概ね 1954年に政府が訓令として告示した「ローマ字のつづり方」に拠っている.これは様々な議論の末に昭和29年12月に告示されたものであり,それまでの慣用をも勘案して,第一表(=訓令式)と第二表(=ヘボン式と第一表にもれた日本式)を含めた折衷的な提案だった.「まえがき」によれば,第一表を基準としながらも,国際的関係や慣例によって改め難い場合には第二表によってもよいとしている.以下に,2つの表を掲げよう.
| 第1表 | (訓令式) | a | i | u | e | o | |||
| ア | イ | ウ | エ | オ | |||||
| ka | ki | ku | ke | ko | kya | kyu | kyo | ||
| カ | キ | ク | ケ | コ | キャ | キュ | キョ | ||
| sa | si | su | se | so | sya | syu | syo | ||
| サ | シ | ス | セ | ソ | シャ | シュ | ショ | ||
| ta | ti | tu | te | to | tya | tyu | tyo | ||
| タ | チ | ツ | テ | ト | チャ | チュ | チョ | ||
| na | ni | nu | ne | no | nya | nyu | nyo | ||
| ナ | ニ | ヌ | ネ | ノ | ニャ | ニュ | ニョ | ||
| ha | hi | hu | he | ho | hya | hyu | hyo | ||
| ハ | ヒ | フ | ヘ | ホ | ヒャ | ヒュ | ヒョ | ||
| ma | mi | mu | me | mo | mya | myu | myo | ||
| マ | ミ | ム | メ | モ | ミャ | ミュ | ミョ | ||
| ya | (i) | yu | (e) | yo | |||||
| ヤ | イ | ユ | エ | ヨ | |||||
| ra | ri | ru | re | ro | rya | ryu | ryo | ||
| ラ | リ | ル | レ | ロ | リャ | リュ | リョ | ||
| wa | (i) | (u) | (e) | (o) | |||||
| ワ | イ | ウ | エ | オ | |||||
| ga | gi | gu | ge | go | gya | gyu | gyo | ||
| ガ | ギ | グ | ゲ | ゴ | ギャ | ギュ | ギョ | ||
| za | zi | zu | ze | zo | zya | zyu | zyo | ||
| ザ | ジ | ズ | ゼ | ゾ | ジャ | ジュ | ジョ | ||
| da | (zi) | (zu) | de | do | (zya) | (zyu) | (zyo) | ||
| ダ | ジ | ズ | デ | ド | ジャ | ジュ | ジョ | ||
| ba | bi | bu | be | bo | bya | byu | byo | ||
| バ | ビ | ブ | ベ | ボ | ビャ | ビュ | ビョ | ||
| pa | pi | pu | pe | po | pya | pyu | pyo | ||
| パ | ピ | プ | ペ | ポ | ピャ | ピュ | ピョ |
| 第2表 | (標準式)〈ヘボン式〉 | sha | shi | shu | sho | |
| シャ | シ | シュ | ショ | |||
| tsu | ||||||
| ツ | ||||||
| cha | chi | chu | cho | |||
| チャ | チ | チュ | チョ | |||
| fu | ||||||
| フ | ||||||
| ja | ji | ju | jo | |||
| ジャ | ジ | ジュ | ジョ | |||
| (日本式) | di | du | dya | dyu | dyo | |
| ヂ | ヅ | ヂャ | ヂュ | ヂョ | ||
| kwa | ||||||
| クワ | ||||||
| gwa | ||||||
| グワ | ||||||
| wo | ||||||
| ヲ |
「ローマ字のつづり方」の告示に至るまでのローマ字の正書法を巡る議論は熾烈だった.その後も,○○式それぞれの支持者は主張を続けており,論争の火種は今もくすぶっている.昨今は,コンピュータのローマ字漢字変換の普及,日本語の国際化,「#1612. 道路案内標識,ローマ字から英語表記へ」 ([2013-09-25-1]) のような動向がみられることから,ローマ字に関する議論が再燃する可能性がある.
さて,ここではいずれの方式を採るべきかという問題の核心には入り込むことはせずに,英語の正書法に近いとされるヘボン式のどこが英語的なのかを確認するにとどめよう.訓令式と比較するとすぐにわかるが,ヘボン式が体系的に英語風といえるのは,シャ行,チャ行,ジャ行である.訓令式の <sya>, <syu>, <syo>, <tya>, <tyu>, <tyo>, <zya>, <zyu>, <zyo> は,ヘボン式では <sha>, <shu>, <sho>, <cha>, <chu>, <cho>, <ja>, <ju>, <jo> に対応する.また,これと関連して,体系的というよりは個別的だが,訓令式 <si>, <ti>, <zi> は,ヘボン式 <shi>, <chi>, <ji> に対応する.ほかにヘボン式には <fu> や <tsu> もあるが,ヘボン式の体系的かつ顕著な「英語風」は,とりわけ <sh>, <ch>, <j> の3種の綴字といってよいだろう.しかし,実は,これらの綴字を「英語風」と認識するのは,あくまで近現代の発想である.英語史の観点からみると,これらは必ずしも典型的に「英語風」といえるものではない.これについては,明日の記事で.
2014-06-19 Thu
■ #1879. 日本語におけるローマ字の歴史 [alphabet][japanese][writing][grammatology][orthography][romaji][language_planning]
ローマン・アルファベット誕生の歴史については,アルファベットの派生を扱った「#423. アルファベットの歴史」 ([2010-06-24-1]),「#1822. 文字の系統」 ([2014-04-23-1]),「#1834. 文字史年表」 ([2014-05-05-1]),「#1849. アルファベットの系統図」 ([2014-05-20-1]),「#1853. 文字の系統 (2)」 ([2014-05-24-1]) の記事で概観してきた.ラテン語を書き表すために発展したローマン・アルファベットは,その後,西ヨーロッパを中心に広がり,さらに世界史の経緯とともにヨーロッパ外へ拡散し,「#1861. 英語アルファベットの単純さ」 ([2014-06-01-1]) も相まって,現在では世界化している(関連して「#1838. 文字帝国主義」 ([2014-05-09-1]) を参考).日本語におけるローマ字の使用は室町時代後期に遡るが,これもローマン・アルファベットの世界的拡散の歴史の一コマである.以下,日本語におけるローマ字の歴史を,古藤 (118--24) に拠って要約しよう.
日本に初めてローマ字が伝えられたのは,16世紀後半,室町時代の末である.キリスト教の宣教師とともにもたらされた.1590年(天正18年),イタリア人のワリニャーニ (1539--1609) が島原に活字印刷機をもたらし,それでローマ字による初の書『サントスの御作業の内抜書き』 (1591) を刊行した.続いて,長崎,天草,京都などで数多くのローマ字書きの「キリシタン資料」が出版されることになったが,『ドチリナ・キリシタン(吉利支丹教義)』 (1592) などでは,ポルトガル語の発音に基づいて日本語が表記されており,当時の日本語の発音を知る上で貴重な資料となっている.
続く江戸時代には鎖国が行われ,一時期,ローマ字の普及が妨げられることとなった.その間に,新井白石 (1657--1725) が1708年(宝永5年)に屋久島に漂流したローマ人宣教師シドッチを訊問してローマ字その他の知識を得て,洋語に対して初めて一貫してカタカナを当てた『西洋紀聞』を世に送ったが,日本におけるローマ字の発展に直接は貢献しなかった.江戸時代後期には蘭学が盛んになるとともにオランダ語式のローマ字が用いられ,やがてドイツ語式やフランス語式も現われたが,明治維新のころには英語式が最も優勢となっていた.英語式ローマ字が一般化したのは,1767年(慶応3年)にアメリカの眼科医・宣教師のヘボン (James Curtis Hepburn; 1815--1911) が著わした日本初の和英辞典『和英語林集成』に負うところが大きい.この第3版で採用されたローマ字表記が「ヘボン式(標準式)」の名で広く普及することになった.
明治時代になると,ローマ字を国字にしようという運動が高まったが,英語表記に近いヘボン式(標準式)をよしとせず,日本語表記に特化した「日本式」こそを採用すべしと田中館愛橘 (1856--1952) が提唱するに至り,両派閥の対立が始まった.この対立はその後も長く続くことになり,大正時代には文部省,外務省などがヘボン式を,陸海軍,逓信省などは日本式をそれぞれ支持した.政府は統一を目指して臨時ローマ字調査会を組織し,6年の議論の末,1937年に日本式を基礎にヘボン式を多少取り入れた「訓令式」を公布した.
だが,議論は収まらず,1954年に,政府は第一表(=訓令式)と第二表(=ヘボン式と第一表にもれた日本式)を収録した「ローマ字のつづり方」を訓令として告示することになった.すでに駅名やパスポートの人名に採用されていたヘボン式にも配慮しつつの折衷的な方式だったが,その後,ある程度の承認を得たとはいえるだろう.現在の教育では,ローマ字は小学校4年生で学ぶことになっている.
町の看板にローマ字があふれ(「#1746. 看板表記のローマ字」 ([2014-02-06-1])),コンピュータのローマ字漢字変換が普及し,日本語の国際化も進んでいる現在,新たな観点から日本語におけるローマ字使用の問題を論じる時期が来ているように思われる.
・ 古藤 友子 『日本の文字のふしぎふしぎ』 アリス館,1997年.
2014-06-01 Sun
■ #1861. 英語アルファベットの単純さ [writing][grammatology][alphabet][orthography][diacritical_mark]
「#423. アルファベットの歴史」 ([2010-06-24-1]),「#1822. 文字の系統」 ([2014-04-23-1]),「#1834. 文字史年表」 ([2014-05-05-1]),「#1849. アルファベットの系統図」 ([2014-05-20-1]),「#1853. 文字の系統 (2)」 ([2014-05-24-1]) でアルファベットの派生を見てきた.通常の系統図ではローマン・アルファベットあるいはラテン文字以降の派生は省略されることが多いが,実際には英語アルファベット,フランス語アルファベット,ドイツ語アルファベットなど言語ごとに区別されてゆくし,英語でも古英語アルファベット,中英語アルファベット,現代英語アルファベットはそれぞれ異なる.
これらの様々な派生アルファベットのなかでも,現代英語アルファベットは文字体系としては非常に単純な部類に入る.幾何学的に単純な字形の26文字のみからなり,特殊な発音区別符(号) (diacritical mark; cf. 「#870. diacritical mark」 ([2011-09-14-1])) も原則として用いられない.確かに,文字の組み合わせ方に関する規則,すなわち綴字の正書法は複雑だし,大文字と小文字の区別や句読法の規範もいくらかはある.また,印刷では分綴 (hyphenation) や合字 (ligature) などを考慮する必要もある.運用上は必ずしも単純な文字体系とはいえないということは事実だろう.しかし,種々の規則を考慮に入れても,古今東西の主要な文字体系と比較すれば,現代英語アルファベットという文字体系はやはり単純と言わざるをえない.
この単純さを,コンピュータ時代に適応させるべくさらに単純化し,標準化した結晶ともいえるのが,ASCIIコード (American Standard Code for Information Interchange) である.もともとはアメリカの規格だが,現在では同じ内容の ISO 646 IRV (International Reference Version) に裏付けられた国際規格である.太田 (45--46) によれば,ASCII の単純さは以下の諸点に帰せられる.
(1) 固定長で,各文字を前後関係に関係なく直接指定できる
・ 文字の種類がバイトの大きさに比べて少ない
・ 横書き,左端から右に書くだけで,双方向性問題がない
・ 文字の図形表現が前後関係で変形しない(リガチャーがない)
(2) 大文字,小文字の対応が規則的ではっきりしている
・ 飾り文字がない
(3) 大文字,小文字の区別をするかしないかという場合を除いて,文字同定が完璧で,字形のゆれの範囲に,徹底した共通認識がある
(4) 大文字,小文字の区別をするかしないかを除いて,異なる文字の組み合わせを同じ文字列と考える必要がない
(5) 文字幅が一定でかまわない
(6) デフォールトで利用できる
・ 広く普及した国際標準である
ASCII の単純さは,しかし,その主たる構成要素である現代英語アルファベットの単純さがそのまま反映されたものというよりは,それが電子処理にふさわしく一段と単純に整備された結果と考えるべきだろう.このように,現代英語アルファベットと ASCII 文字セットとは一応のところ区別してとらえる必要はあるが,両者のもつ単純さの根っこは,当然つながっている.
文字コードを巡る現代の諸問題は,技術者任せにしておくわけにはいかず,言語学の1分野としての文字学が積極的に扱うべき領域である.そこには,古今東西の文字の記述の問題,文字の理論の問題,(多言語主義はもとより)多文字主義の問題,文字帝国主義の問題 ([2014-05-09-1]) ,書き言葉と話し言葉の峻別の問題などが密接に関わってくる.
・ 太田 昌孝 『いま日本語が危ない 文字コードの誤った国際化』 丸山学芸図書,1997年.
2014-05-24 Sat
■ #1853. 文字の系統 (2) [writing][grammatology][alphabet][family_tree][hieroglyph]
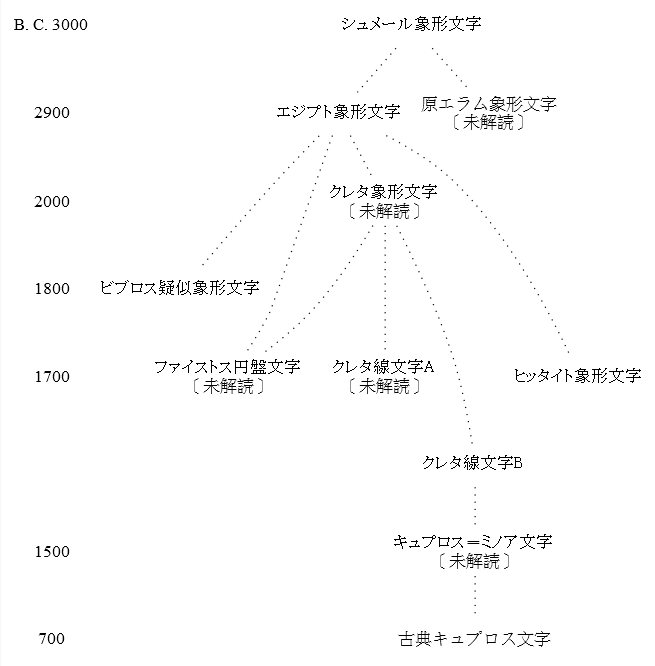
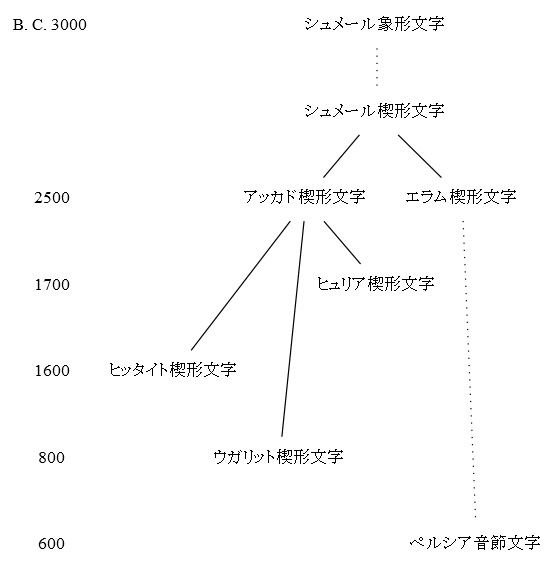
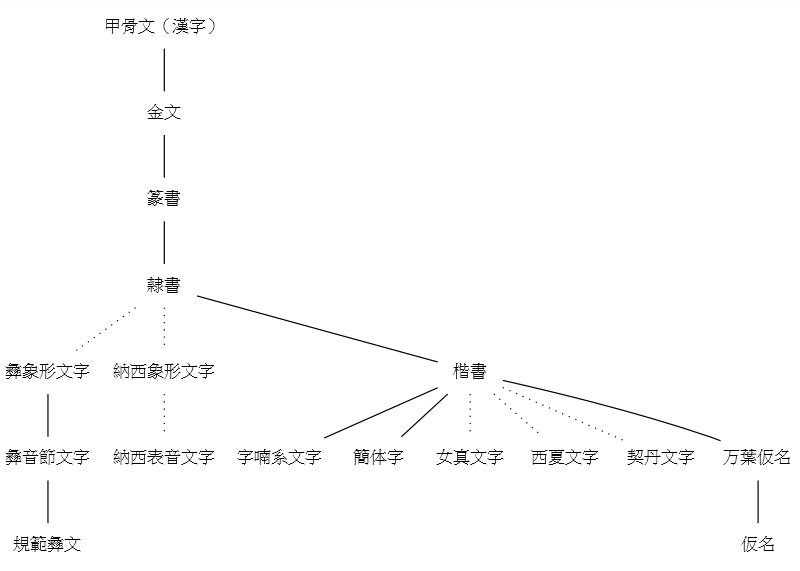
「#423. アルファベットの歴史」 ([2010-06-24-1]),「#1822. 文字の系統」 ([2014-04-23-1]),「#1834. 文字史年表」 ([2014-05-05-1]),「#1849. アルファベットの系統図」 ([2014-05-20-1]) に引き続き,もう1組の文字の系統図を示したい.先の記事でも述べたように,比較言語学の成果として描かれる言語の系統図と同様に,比較文字学の成果としての文字の系統図も,一つの仮説である.もちろん大筋で合意されている部分などはあるが,極端に言ってしまえば,論者の数だけ系統図があるということにもなる.したがって,系統図のようなものは複数見比べる必要がある.今回は,西田 (232--34) による1組の系統図を参照する.以下の4つの系統が区別されている.年代は暫定的なものである.
(1) エジプト象形文字が表音字形として発展した系統

(2) シュメール象形文字が象形字形を保存した系統
(3) シュメール楔形文字の系統
(4) 東アジアの象形文字の系統
・ 西田 龍雄(編) 『言語学を学ぶ人のために』 世界思想社,1986年.
2014-05-20 Tue
■ #1849. アルファベットの系統図 [writing][grammatology][alphabet][runic][family_tree][neogrammarian][comparative_linguistics]
「#423. アルファベットの歴史」 ([2010-06-24-1]),「#1822. 文字の系統」 ([2014-04-23-1]),「#1834. 文字史年表」 ([2014-05-05-1]) の記事で,アルファベットの歴史や系統を見てきたが,今回は寺澤 (376) にまとめられている「英語アルファベットの発達概略系譜」を参考にして,もう1つのアルファベット系統図を示したい.言語の系統図と同じように,文字の系統図も研究者によって細部が異なることが多いので,様々なものを見比べる必要がある.
以下の図をクリックすると拡大.実線は直接発達の関係,破線は発達関係に疑問の余地のあることを示す.
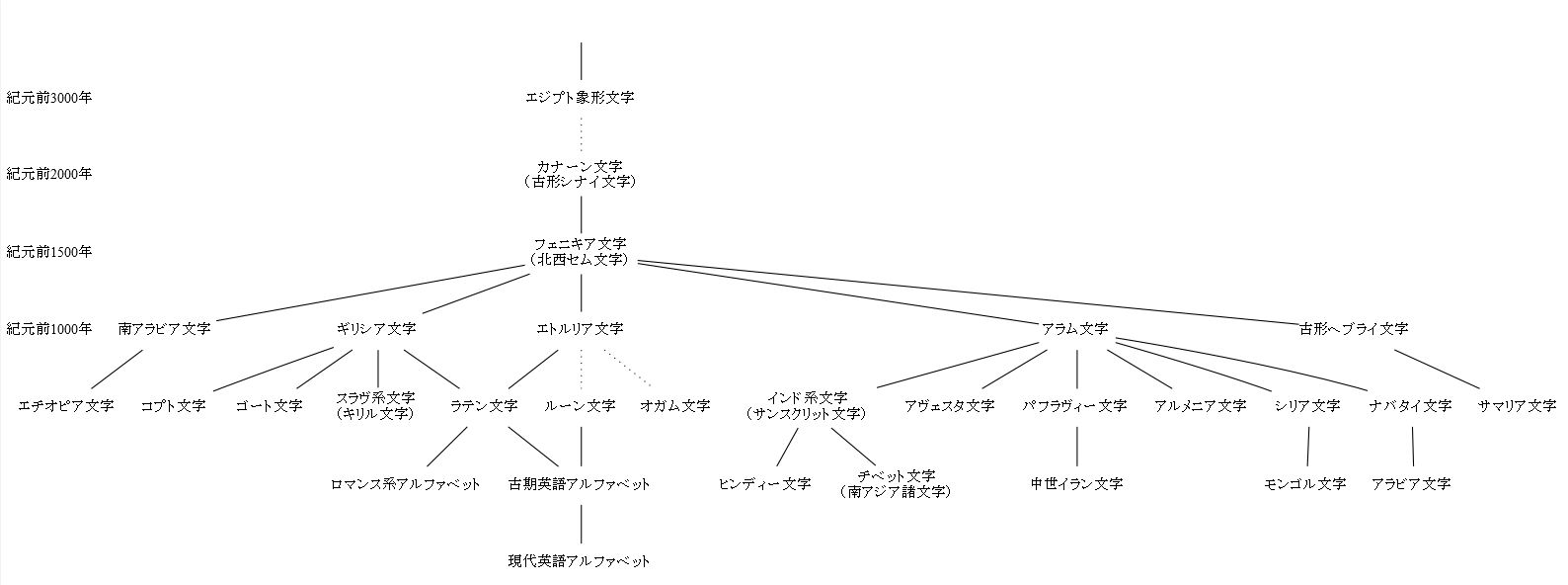
文字 (writing) の系統図を読む際には,印欧語族など言語そのもの (speech) の系統図を読む場合とは異なる視点が必要である.まず,speech の系統図の根幹には,青年文法学派 (neogrammarian) による「音韻変化に例外なし」の原則がある.そこには調音器官の生理学に裏付けられた自然な音発達という考え方があり,その前提に立つ限りにおいて,系統図は科学的な意味をもつ.一方,文字の系統図の根幹には,「原則」に相応するものはない.例えば筆記に伴う手の生理学に裏付けられた字形の自然な発達というものが,どこまで考えられるか疑問である.筆記具による字形の制約であるとか,縦書きであれば上から下へ向かうであるとか,何らかの原理はあるものと思われるが,音韻変化におけるような厳密さを求めることはできないだろう.
2つ目に,「#748. 話し言葉と書き言葉」 ([2011-05-15-1]) を含む ##748,849,1001,1665 の記事で話題にしてきたように,話し言葉(音声)と書き言葉(文字)には各々の特性がある.音声は時間と空間に限定されるが,文字はそれを超越する.文字は,借用や混成などを通じて,時間と空間を超えて,ある言語共同体から別の言語共同体へと伝播してゆくことが,音声よりもずっと容易であり,頻繁である.とりわけ音素文字であるアルファベットは,あらゆる話し言語に適用できる普遍的な性質をもっているだけに,言語の垣根を軽々と越えていくことができる.この点で,文字の系統,あるいは文字の発達や伝播は,人間が生み出した道具や技術のそれに近い.文化ごとの自然な発達も想定されるが,一方で他の文化からの影響による変化も想定される.
3つ目に,音声に基づく系統関係は音韻変化のみを基準に据えればよいが,文字,とりわけ音素文字においては,字形という基準のほかに,字形と対応する音素が何かという基準,すなわち文字学者の西田龍雄 (223) がいうところの「文字の実用論」の考慮が必要となる.字形と実用論は独立して発達することも借用することもでき,その歴史的軌跡を表わす系統図は,音声の場合よりも,ややこしく不確かにならざるをえない.
比較言語学と平行的に比較文字学というものを考えることができるように思われるが,素直に見えるこの平行関係は,実は見せかけではないか.比較文字学には,独自の解くべき問題があり,独自の方法論が編み出されなければならない.
・ 寺澤 芳雄(編) 『辞書・世界英語・方言』 研究社英語学文献解題 第8巻.研究社.2006年.
・ 西田 龍雄(編) 『言語学を学ぶ人のために』 世界思想社,1986年.
2014-05-09 Fri
■ #1838. 文字帝国主義 [linguistic_imperialism][alphabet][grammatology][sociolinguistics]
「#1606. 英語言語帝国主義,言語差別,英語覇権」 ([2013-09-19-1]) や「#1607. 英語教育の政治的側面」 ([2013-09-20-1]) ほか linguistic_imperialism の各記事で,言語帝国主義(批判)の話題を取り上げてきた.言語帝国主義というときの言語とは,書き言葉であれ話し言葉であれソシュール的な langage を指すものと考えられるが,この概念は langage とは異なる次元にある文字体系にも応用できるのではないか.英語帝国主義論というものがあるのならば,アルファベット帝国主義論,ローマ字帝国主義論なるものもあるはずではないか.
これまでカルヴェのいくつかの著書を通じて,文字と権力にかかわる社会言語学的な議論には接していたが,彼の『文字の世界史』を読み,積極的な文字帝国主義論の立場を知った.近年アフリカで多数の文字が生まれている状況を概説した後で,カルヴェ (199--201) は次のように述べている.
一つだけはっきりしているのは,近年アフリカでこのように多数の文字が生まれたのは,アフリカがおかれた政治的状況によるということで,大半はイスラム教化や植民地化の結果,自分たちの言語もアラビア語やフランス語,英語,ポルトガル語と同じように文字をもつことができる,と誇示することが最大の目的であったと考えられる.アフリカの住民は文字という概念を独自に得たのではなく,他の文字を借用するか模倣したのである.この意味でブラック・アフリカの言語がことごとくローマ字で書かれているという事実はよく考える必要がある.つまり独自の文字を作り出そうという試みの背景にナショナリズムや民族主義があるとすれば,アフリカにおけるローマ字の制覇は客観的に見てローマ字の方が優っているということではなく(因みにデビッド・ダルビーはローマ字には欠陥があり,新たな文字を加えるなど修正を加えることが望ましいとしている),アフリカとそれ以外の地域の間に認められる力関係がこの場合は文字に現れていると見るべきなのである.もっと端的にいえば,現地で独自に作った文字がローマ字に優っているというのではなく,言語戦争があるとすれば文字戦争もあり,アフリカの状況はその好例だという事である.各地で独自の文字を作ろうという試みがあったのは改宗や植民地化でアフリカに文字が持ち込まれた結果だが,アフリカ諸国にとっての最大の課題はどれを公式文字として採用するかということだった.その際ローマ字の方が優れているという権力関係の存在が容認されたのではないだろうか.「はじめに」でも書いたように,アルファベットが文字として絶対のものではなく,漢字使用者が10億人以上いるのは事実だとしても,アフリカの状況が示しているのは,第一に今日文字を持たない言語を表記しようとするときまず考えられるのはローマ字であるということ,第二に次章で見るアラビア数字と同じで,世界に数多くあるアルファベットのうち最も勢力があるのはローマ字であるということである.そして見かけ上恩恵的と思われるこの記号学上の支配は,西欧が全世界に対して握っている権力の現われであることに変わりはないのである.
カルヴェが文字の権力について力を込めて論じているもう1つの箇所がある (238--39) .
メソポタミアの楔形文字,古代中国の甲骨文字,中米の表音表意文字などが示唆するように,初期の文字は物語や詩歌を著すためではなく,税収などの会計や契約を記録し,法令を伝達・保存し,あるいは重要人物の名と功績を墓に刻むといった役割,さらには占いや儀式をとり行うといった宗教的役割を果たしていた.つまり文字と権力は密接な関係にあるのである.
社会学者で言語学者でもあったマルセル・コーエンは「一般的にいって,文字と呼べるものはどれも都市で生まれているが,これは都市における生産,輸送といった経済活動が複雑であると同時に,都市の人間関係が複雑なことが要因である」と書いている.文字が「都市的」な性質を持つという指摘は重要で,というのは権力が生まれるものもやはり都市なのである.肝心なのは,文字は発生の段階ではあくまで国家運営の原型に相当する極めて実用的な機能を担うもので,詩歌,伝承,工芸といった社会遺産を口承に代わって記録するようになるのはずっと後のことに過ぎないということである.文字と権力の関係にはさらに支配階級の社会的地位という問題がかかわって来る.例えば楔形文字についてJ=M・デュランが,「楔形文字は余りにも複雑で,習得に膨大な時間を要する.楔形文字が民衆に普及せず,一握りの専門家だけが使っていたと考えられる理由はそこにある」としているのは妥当だが表面すぎる見方である.楔形文字がごく一部の階級から外に出なかったのは,読み書きが複雑だということもあるだろうが,同時に文字の持つ権力を独占しようという意図の現われと見ることもできるからである.重要なのは,楔形文字や象形文字といった発生期の文字が習得に多大な時間を要するということは,習得すれば特権が手中にできるということであり,さらには文字そのものが特定の階級だけに所属するものであるという事である.同時に,文字の権力を握っているものはその独占に努めこそすれ,簡略化による文字の民主化や,教育による普及は思いもつかなかったに違いないと考えられるのである.
このことはなにも4000年前の古代文字に限ったことではない.今日でも行政が文字に関わる場合,表面上は単に国語表記の問題のように見えるが,実はそれ以外の意図があることは見逃せない.例えば旧ソヴィエト政府が連邦内の言語に対しローマ字化を経て段階的にキリル文字化を断行したのはロシア帝国主義の記号学的表現であり,中国が漢字の簡略化を推進したのも明らかに文字の民主化という政治的方針に基づくものである.現在各国でローマ字化が進んでいるアフリカは旧宗主国の言語が官庁用語という国が大多数を占めるが,これは現地語を駆逐しようという,いわば「食言的」意図の現われである.要するに文字の問題は本書で述べたような歴史的考察の対象にもなるが,同時に社会的考察の対象にもなるのである.文字は宗教も含めた権力を行使するために作り出され,次の段階では権力を担うものに転化するが,これは今日でもある程度まで言えることである.
カルヴェの著書を監訳した文字学者の矢島は,別に監修した『文字の歴史』の序文 (4) で,多文字教育の必要性を訴えている.上記の引用を読んだあとでは,この必要性は納得しやすいのではないか.
世界は日ごとに“情報化”しつつあり,日本はますます“国際化”しつつある.大国のみならず中・小国の民族文化・異文化を知る必要は増えるばかりだ.情報の伝達・交換は,ある程度までは科学技術が助けてくれるかもしれない――テレビの文字放送(広義での),多機能的ワープロ(パソコン),今後さらに改良されるであろう翻訳・字訳・読み取り機などなど.しかし文化記号としての文字をわれわれ自身が学ぶことが,それぞれ異なる文化の伝統をもつ民族間の理解を深める鍵ではなかろうか.そのためには,多言語教育とともに多文字教育が必要であり,言い換えれば国際的な“識字”運動を進めるべきではないだろうか.
・ ルイ=ジャン・カルヴェ 著,矢島 文夫 監訳,会津 洋・前島 和也 訳 『文字の世界史』 河出書房,1998年.
・ ジョルジュ・ジャン 著,矢島 文夫 監修,高橋 啓 訳 『文字の歴史』 創元社,1990年.
2014-05-08 Thu
■ #1837. ローマ字とギリシア文字の字形の差異 [alphabet][greek][latin][grammatology][map][dialect]
「#1832. ギリシア・アルファベットの文字の名称 (1)」 ([2014-05-03-1]) の記事で,ギリシア・アルファベット (Greek alphabet) の一覧を示した.ローマン・アルファベット (Roman alphabet) と比べると,文字数,字形,音価において若干の違いが見られるが,この違いの背後にどのような事情があったのだろうか.
まず,一般論を述べておくと,ある言語を表記する文字体系を別の言語へ移植・適用するときには,決まって多少の改変が加えられる.とりわけ,音韻体系をもっともよく反映するアルファベットのような音素文字であれば,なおさらである.まったく同じ音韻体系をもっている言語(方言)はないといってよく,既存の文字セットを移植するときには,必ずいくつかの文字の過剰と不足が生じる.そこで,過剰な文字を新しい音価に割り当てたり,新しい文字を創り出すなどの手段が講じられる.しかし,文字には保守的な側面もあり,総文字数を大きく変化させるような事態には至らないことが多い.アルファベット史をみても,およそ20?40文字の範囲に収まっているようである.ギリシア文字→エトルリア文字→ローマ字とアルファベットが伝播してゆく過程でも多少の改変と本質的な不変が見られるが,これは文字の伝播においては普通に観察されることである.
次に具体論に移ろう.古代におけるギリシア・アルファベットは一枚岩ではなく,多数の方言的変種が存在した.これは,古代ギリシア語の話し言葉が多種多様に方言分化していたのと呼応する.よく言われるように,古代ギリシアは諸都市の独立と自足を特徴とし,後のローマとは対照的に統一国家を生み出すことはなかった.話し言葉や文字体系の方言化も,この独立精神と無関係ではない.話し言葉の方言については「#1454. ギリシャ語派(印欧語族)」 ([2013-04-20-1]) で触れたので繰り返さないが,アルファベットの変種については,細かく分類すれば4種類が区別された.ドイツの学者 Kirchhoff による分類で,地図を4種類の色に塗り分けてその分布を示したことにちなみ,それぞれ色の名前で呼称される慣習がある.Green, Red, Dark blue, Light blue の4変種だ.
(1) Green alphabet は,Crete や近隣の島々で行われた変種で,フェニキア・アルファベット (Phoenician alphabet) への追加文字(他変種におけるΦ,Χ,Ψ)を欠いているのが特徴である.
(2) Red alphabet は,Euboea や Laconia で行われた変種で,Φ [ph], Ψ [kh] の追加文字を加えた.また,ΧはΞに代わって [ks] の音価を表わした.Euboea の都市の名を取って Chalcis 型あるいは西方型の変種と呼ばれる.
(3) Dark blue alphabet は,Ionia, Corinth, Rhodes で広く行われた変種で,Φ [ph], Χ [kh], Ψ [ps] の追加文字を加えた.この Ψ [ps] は,Red alphabet のΨ [kh] と音価が異なることに注意.Ionia 型あるいは東方型の変種と呼ばれる.
(4) Light blue alphabet は,Attica で行われた変種である.Φ [ph], Χ [kh] を追加した.Ionia 型の亜種といってよいが,後に標準的な変種となった.
これを2つに大別すれば,Euboea の Chalcis を中心とする西方型と Ionia の Miletus を中心とする東方型に分けられるだろう.フェニキアの商人が去った後,エーゲ海は Chalcis と Miletus の独占舞台となり,両都市は商業的・植民的覇権を争った.Chalcis はトラキアやイタリアに植民して,エトルリア語経由でラテン語に西方型アルファベットを伝えた.一方,Miletus は黒海沿岸地方に植民し,古典ギリシア・アルファベットを確立し,さらにキリル文字などのスラヴ系アルファベットの発展を促した.
ローマン・アルファベットとギリシア・アルファベットの若干の違いは,もととなる変種の違いに起因するということがわかるだろう.大文字でいえば <C> と <Γ>,<D> と <Δ>, <L> と <Λ>,<X> と <Ξ>,<S> と <Σ> の字形の違い,また上述のように <Χ> の音価の [ks] と [kh] の違い,さらに <Η> の音価の [h] と [eː] の違いは,以上の事情による.
参考までに現代ギリシアの地図を掲げておこう.
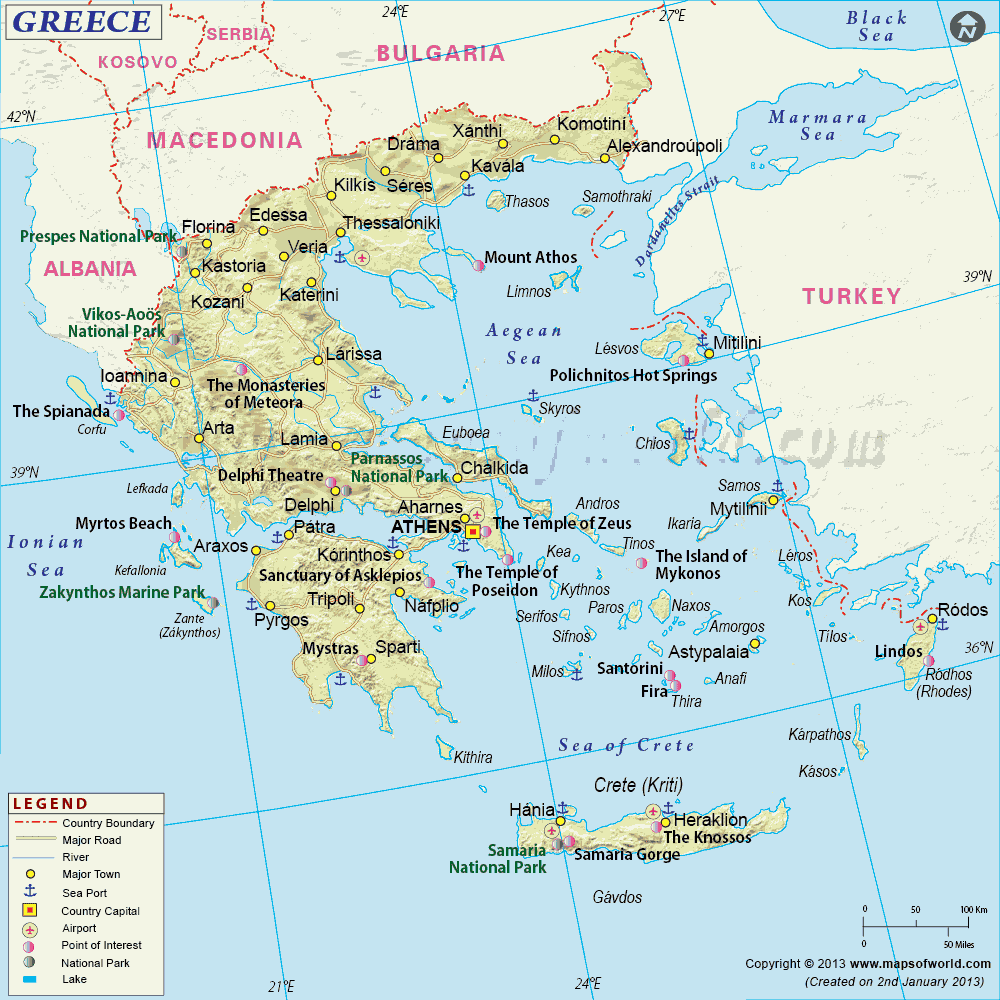
以上,田中 (57--60) および Comrie et al. (183--87) を参照して執筆した. *
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
・ Comrie, Bernard, Stephen Matthews, and Maria Polinsky, eds. The Atlas of Languages. Rev. ed. New York: Facts on File, 2003.
2014-05-04 Sun
■ #1833. ギリシア・アルファベットの文字の名称 (2) [greek][alphabet][grammatology][runic]
昨日の記事「#1832. ギリシア・アルファベットの文字の名称 (1)」 ([2014-05-03-1]) に引き続き,セム・アルファベットから引き継いだ文字の名称について.昨日の一覧表の最後列に示したが,"alpha", "beta", "gamma" などの名称は, 語源不詳だったり同定されていないものもあるが,セム・アルファベットの有意味な単語に起源をもつと一般に信じられている.
原シナイ文字 (Proto-Sinaitic) から,フェニキア文字 (Phoenician) を含む各種のセム・アルファベット,それから古代ギリシア文字へと至る字形の変化を追っていくと,その連続性がよくつかめるのだが,原初の原シナイ文字の段階ではまだ文字というよりは略画に近い.原シナイ文字の第1字は,確かに「牛」(aleph) の頭部のようにみえる略画であり,これが字形の変化を経てギリシア・アルファベットのΑへと発展した.第2字は,「家」(bet) に見えなくもない字形で,これが後にΒへと発展した.このようにして,各文字は具体的なモノを描いた象形文字に端を発し,そのモノを表わす単語で呼称され,語頭音の音価を獲得するに至った.
セム・アルファベットの起源はたいてい以上のように説明されるのだが,実は1930年代の後半以降に異論が出てきた.異論の首唱者の1人 Hans Bauer は,字形と名称の関係は後付けであると論じている.田中 (40--41) より引用する.
従来の説によれば,古代セム記号は本来絵を表わしているといわれ,‘āleph は牛の頭を,bēth は家の形をというように,すべての記号はある物の形を描いていると考えられている.しかし牡牛の記号は,本来牡牛の絵文字であるから ‘āleph と命名したと解釈すべきでなく,任意に採用した記号が偶々牡牛の形に似ているために,後になってエジプトのアクロフォニーの原理を適用して ‘āleph (牡牛)と呼んだまでのことである.この場合何の名を選ぶかは随意である.現代の児童用「ABC本」などは,例えば,「O は Orange であった,S は Swan であった, B は Butterfly であった」などという風に,文字の形とその文字で始まる物の形との面白い類似によって,文字の記憶を助ける.この場合「O は Olive であった,S は Serpent であった,B は Bee であった」としても一向にかまわない.セム文字の名は,ルーン文字などの名と同様に,単に記憶の便のために付けた mnemonic name である.
冷めた見方ではあるが,mnemonic name 仮説を支持する学者も多いようだ.確かにΒの原型が「家」に見えるかといえば,はなはだ心許ない.そう言われるからそう見えてくるというだけのことかもしれない.
いずれにせよ "alpha", "beta" などの呼称はギリシア・アルファベットへ受け継がれ,ラテン語を経て,英語へも alphabet という語として取り込まれた.蛇足ながら,alphabet という語の由来は,alpha + beta である (Gk alphábētos, LL alphabētum, ME alphabete) .英語での初出は Polychronicon (?a1425) .文字体系の最初の数文字をもって文字一式を表わす例は alphabet のほか,ルーン文字の fuþark(「#1006. ルーン文字の変種」 ([2012-01-28-1]) を参照)や日本語の「いろは」もある(「#1008. 「いろは」と ABC」 ([2012-01-30-1]) を参照).
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
2014-05-03 Sat
■ #1832. ギリシア・アルファベットの文字の名称 (1) [greek][etruscan][latin][alphabet]
まず,Greek alphabet の24字の一覧を掲げよう.意外と正確には知らない英語での発音も要チェック.セム語名称と意味については,田中 (22) とカルヴェ (116--19) を参照した.
| 大文字 | 小文字 | 名称 | 英語名称 | 英語発音 | セム語名称 | 意味 | |
|---|---|---|---|---|---|---|---|
| 1 | Α | α | アルファ | alpha | /ˈælfə/ | aleph | "ox" |
| 2 | Β | β | ベータ | beta | /ˈbeɪtə, ˈbiːtə/ | bet | "house" |
| 3 | Γ | γ | ガンマ | gamma | /ˈgæmə/ | gaml | "camel" |
| 4 | Δ | δ | デルタ | delta | /ˈdɛltə/ | delt | "door" |
| 5 | Ε | ε | エプシロン | epsilon | /ˈɛpsəˌlɑn/ | hé | ? |
| 6 | Ζ | ζ | ゼータ | zeta | /ˈzeɪtə, ˈziːtə/ | zai | "weapon"? |
| 7 | Η | η | エータ | eta | /ˈeɪtə, ˈiːtə/ | hét | "fence"? |
| 8 | Θ | θ | テータ | theta | /ˈθeɪtə, ˈθiːtə/ | tét | ? |
| 9 | Ι | ι | イオタ | iota | /aɪˈoʊtə/ | yod | "hand" |
| 10 | Κ | κ | カッパ | kappa | /ˈkæpə/ | kaf | "bend hand" |
| 11 | Λ | λ | ラムダ | lambda | /ˈlæmdə/ | lamd | "ox-goad"; "rod of teacher" |
| 12 | Μ | μ | ミュー | mu | /mjuː/ | mém | "water" |
| 13 | Ν | ν | ニュー | nu | /njuː/ | nun | "fish"; "serpent" |
| 14 | Ξ | ξ | クシー | xi | /(k)saɪ, (g)zaɪ/ | ||
| 15 | Ο | ο | オミクロン | omicron | /ˈɑməˌkrɑn/ | ‘ain | "eye" |
| 16 | Π | π | パイ | pi | /paɪ/ | ||
| 17 | Ρ | ρ | ロー | rho | /roʊ/ | rosh | "head" |
| 18 | Σ | σ, ς | シグマ | sigma | /ˈsɪgmə/ | ||
| 19 | Τ | τ | タウ | tau | /taʊ/ | tau | "mark" |
| 20 | Υ | υ | ユプシロン | upsilon | /ˈjuːpsəˌlɑn/ | wau | "peg", "hook" |
| 21 | Φ | φ | ファイ | phi | /faɪ/ | pé | "mouth" |
| 22 | Χ | χ | キー | chi | /kaɪ/ | ||
| 23 | Ψ | ψ | プシー | psi | /(p)saɪ/ | ||
| 24 | Ω | ω | オメガ | omega | /ˌoʊˈmeɪgə, ˌoʊˈmiːgə/ |
昨日の記事「#1831. アルファベットの子音文字の名称」 ([2014-05-02-1]) ほか文字の名称を扱った過去の記事(「#1830. Y の名称」 ([2014-05-01-1]) のリンク先を参照)では,文字の名称は,表音文字であるから当然のごとく対応する音価を含んでいるという前提で議論した.<a> は [eɪ] の音価を表わすのだからそのまま [eɪ] と呼ばれるし,<b> は [b] の音価を表わすのだから [b] を含んだ [biː] と呼ばれる.日本語の仮名も「あ」の文字名は「あ」であり,「い」の文字名は「い」である.文字のこのような呼び方,phonetic name といわれるこの方式は,ごく自然のことのように思われるが,ローマン・アルファベット (Roman alphabet) の祖先の上記ギリシア・アルファベット (Greek alphabet),さらに遡ったセム・アルファベット (Semitic alphabet) では,acrophonic name あるいは mnemonic name といわれる別の方式に従っていた.ギリシア語ではαは "alpha" と読み,βは "beta" と読んだが,これは "alpha" や "beta" という既存の単語を発音したものであり,確かに [a] と [b] は語頭音として含まれているが,英語における呼称とは方式が異なっている.
いま既存の単語を発音したものと述べたが,厳密にいえば "alpha" や "beta" はギリシア語の単語ではない."alpha", "beta", "gamma" 等々の単語はセム語において意味をもつ単語であり,ギリシア・アルファベットの発生以前のセム・アルファベットの段階での呼称だった.ギリシア人は,自らにとって無意味な語で呼称しながら,セム・アルファベットの文字一式を受け入れたのである.逆にいえば,ギリシア・アルファベットの文字がギリシア語で無意味な呼称を与えられている事実こそが,そのセム・アルファベット起源を物語っている.
acrophonic name 方式から phonetic name 方式への移行は,部分的にはギリシア語でも始まっていたが,本格的にはエトルリア語やラテン語がアルファベットをもつようになってからである.田中 (85) は,「ラテン・アルファベットにおける文字の新しい命名法は,古典ギリシアの方法に優る一大進歩」と評価している.
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
・ ルイ=ジャン・カルヴェ 著,矢島 文夫 監訳,会津 洋・前島 和也 訳 『文字の世界史』 河出書房,1998年.
2014-05-02 Fri
■ #1831. アルファベットの子音文字の名称 [alphabet][consonant][latin][etruscan][phonetics][gvs]
過去の記事で,ローマン・アルファベットのいくつかの文字の名称について話題にした(昨日の記事「#1830. Y の名称」 ([2014-05-01-1]) と,その末尾にあるリンク先を参照).個々の文字について語るべきことはあるが,今回は子音字に関する一般論を中心に話を進めたい.以下,田中 (83--85) に依拠する.
現代英語のアルファベット26文字のうち,母音字 <a, e, i, o, u> を除いた21字が子音字である.子音字の名称はいくつかの例外を除き,その子音の音価に [iː] を後続させるグループ (Class I) と,[ɛ] を先行させるグループ (Class II) とに分けられる.
・ Class I: <b, c, d, g, p, t, v, z>
・ Class II:<f, l, m, n, s, x>
この分布を理解するには,歴史的な音価,とりわけ子音についてはラテン語(さらに文字史を遡ってエトルリア語)の音価を意識する必要がある.Class I の最初の6字はラテン語の破裂音 [b, k, d, g, p, t] に対応する.それぞれに後続する長母音 [iː] は,[eː] が大母音推移により,上げを経た結果である.一方,Class II の子音字はラテン語の継続音あるいは複合子音 [f, l, m, n, s, ks] に対応する.Class I の <v> と <z> は破裂音ではなく摩擦音だが,おそらく [ɛv], [ɛz] と呼んでしまうと,対応する無声子音字 <f> [ɛf], <s> [ɛs] と発音上区別がつきにくくなるという理由があったのではないか.
調音音声学的に Class I と II の分布を説明しようとすると,次のようになる(田中,p. 84).
子音文字について,継続宇音には e が先行し,そして破裂音には e が後続した現象は,Isaac Taylor がしたように,生理学的観点から眺めることもできよう.例えば,fe よりも ef という方がやさしく,eb よりも be という方がやさしい.それは継続音を発音する際には発音器官は完全には閉鎖されず,気息が漏れ,従って,子音が聞かれる前に母音が無意識に作られる.これにより,fe に達する前に実際上 ef が得られる.これに反して,破裂音の場合には閉鎖は完全であり,そして開放が行なわれる時,意識的な努力なくして母音が作られる.これにより,b に e を先行させることは明らかに努力を必要とするが,b は,唇が開かれる時,e に後続されることなくして発することはできない.言い換えれば,「最小努力の法則」 ('law of least effort') が,母音が継続音に先行し,そして破裂音に後続することを要求する.そして,この場合,最も容易な母音は中性的な e である.
興味深い説ではある.関連して,「#1141. なぜ mama と papa なのか? (2)」 ([2012-06-11-1]) も参照されたい.
<j> の名称 [ʤeɪ] については「#1828. j の文字と音価の対応について再訪」 ([2014-04-29-1]) で触れた通り,すぐ右どなりの <k> の名称 [keɪ] にならったものとされるが,[keɪ] 自体はなぜこの二重母音を伴っているのだろうか.これは,「#1824. <C> と <G> の分化」 ([2014-04-25-1]) で示唆したように,エトルリア語やラテン語において [k] 音の表記が後続する母音に応じて <c>, <k>, <qu> の間で変異していたことが影響している.[i, e] など前母音が後続するときには <c> が選ばれ,[a] の低母音が後続するときには <k> が選ばれ,[u, o] など後母音が後続するときには <q> が選ばれた.この傾向は英語を含めた後の諸言語にも多かれ少なかれ受け継がれており,英語の各文字の呼称にも間接的に反映されている.すなわち,<c> = [siː] はラテン語の <c> = [keː] から発展し,<k> = [keɪ] はラテン語の <k> = [kaː] から発展し,<q> = [kjuː] はラテン語の <q> = [kuː] から発展した.(前母音の前位置における [k] > [s] の音発達については,ラテン語から古フランス語を経て英語もその影響を被ったが,[kj] > [tj] > [ʧ] > [ʦ] > [s] の経路をたどった.)
最後に <r> の名称 [ɑː] (AmE [ɑr]) について.[r] は継続音として本来 Class II に属しており,ラテン語では少なくとも4世紀以降は [ɛr] のように読まれていた.中英語期に [er] > [ar] の変化が sterre > star, ferre > far など多くの語で生じたのに伴って,この文字の読みも [ar] へと変化した(関連して,「#179. person と parson」 ([2009-10-23-1]) と「#186. clerk と cleric」 ([2009-10-30-1]) を参照).その後,18世紀までに [ar] > [ær] > [æːr] > [ɑː] と規則変化して,現在に至る(田中,pp. 157--58).
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
2014-05-01 Thu
■ #1830. Y の名称 [y][alphabet][grapheme][i-mutation][pronunciation][gvs][ormulum]
「#1825. ローマ字 <F> の起源と発展」 ([2014-04-26-1]) の記事で触れたように,ローマ字の <F>, <U>, <V>, <W>, <Y> はすべてセム・アルファベットの wāu に起源をもつ姉妹文字である.ラテン語からローマ字を譲り受けた英語を含めた多くの言語では,<y> はそれが表わす音価ゆえに <i> と結びつけられることが多いが,むしろ歴史的には <u> と縁が深い.<Y> と <U> が近しい姉妹文字であることは,ギリシア・アルファベットの第20字 upsilon の大文字がΥ,小文字がυであることからも見て取ることができるし,初期古英語で <u> = /u/ がウムラウト化した円唇前舌高母音 /y/ を表わすのに <y> をもってしたことからも知られる.後期古英語では,/y/ の円唇性が失われて /i/ となったため,<y> はむしろ <i> と結びつけられるようになった.
<Y> と <U> の近さを感じさせるもう1つの点は,Y の名称のなかに隠されているかもしれない.英語で Y が [waɪ] と呼ばれる理由について定説はないが,Jespersen によれば,それは <Y> の字形が <U> の下に <I> を加えた字形であるという点と関係する.[uiː] が [wiː] となり,次いで大母音推移により [waɪ] へ変化したという(田中,pp. 183--84).
OED によると,この文字の発音についての最初の言及は,1200年頃に書かれた Ormulum の l. 4320 にある IESOYS の第5文字目の上に現れる ƿı である.1513年には,G. Douglas の Virgil Æneid vii. Prol. 120 に,"Palamedes byrdis crouping in the sky, Fleand on randoune schapin lik ane Y." という押韻がみられる.また,16世紀後半には,より明確な記述がみられる.
1573 J. Baret Aluearie, Y hath bene taken for a greeke vowel among our latin Grammarians a great while, which me thinke if we marke well we shall finde to be rather a diphthong: for it appeareth to be compounded of u and i, which both spelled togither soundeth as we write Wy.
1580 W. Bullokar Bk. Amendm. Orthogr. 8 The olde name of :y: (which is wy).
関連して,H の名称については「#488. 発音の揺れを示す語の一覧」 ([2010-08-28-1]) を,J の名称については「#1828. j の文字と音価の対応について再訪」 ([2014-04-29-1]) を,Z の名称については「#964. z の文字の発音 (1)」 ([2011-12-17-1]) および「#965. z の文字の発音 (2)」 ([2011-12-18-1]) を参照.
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
Powered by WinChalow1.0rc4 based on chalow