2015-02-05 Thu
■ #2110. 言語(変化)の使用基盤モデル [cognitive_linguistics][usage-based_model][language_change][frequency][collocation][speed_of_change]
認知言語学の言語変化に関するモデルとして,使用基盤モデル (usage-based model) というものが提案されている.谷口による説明と図解 (106, 105) がわかりやすい.
あることばの用法の共通性となるスキーマ [A] から,何らかの点で逸脱し拡がった新しい用法 (B) が生じる.はじめ,(B) はスキーマ [A] に合致しない.しかし,(B) の用法が繰り返され定着するにつれて,(B) は [A] と共にその言語のシステムに取り込まれるようになる.すると,(B) を取り込んだ形であらたなスキーマ [A'] が抽出され,それによって (B) が容認されるようになっていくのである.このような変化のシステムを,「使用基盤モデル」あるいは「用法基盤モデル」 (usage-based model) という (Langacker 2000) .(谷口,106)
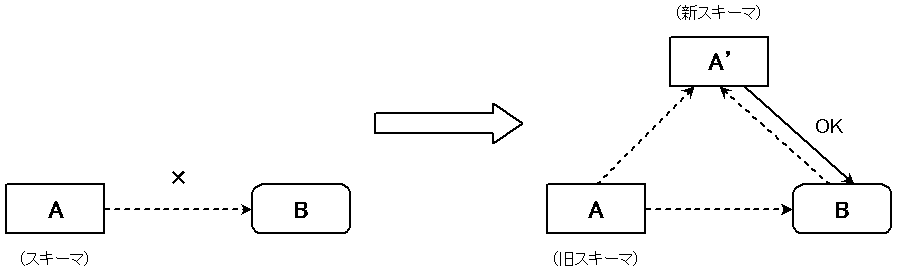
新しいスキーマの創出は,抽象化であるという点で,文法規則の創出とも比較される.しかし,通常文法規則は静的であるのに対して,スキーマは動的であり,柔軟であるという違いがある.スキーマは,逸脱した事例が徐々に定着するにつれて,常に変更されていく.また,変化の過程において,逸脱した事例が定着する度合いには個人差があるため,必然的にスキーマ自体の個人差も生じることになる.言語変化をこのように位置づけてとらえる使用基盤モデルにおいては,言語の体系そのものが流動的なものにみえるだろう.
新スキーマの定着度に個人差があるということは,言語変化の速度 (speed_of_change) の問題に直結するし,当該の言語項の使用頻度 (frequency) や共起 (collocation) の問題とも関連が深い.使用基盤モデルは,これらの関係する問題にも注目している.言語変化は定義上ダイナミックなものではあるが,言語そのものが常にダイナミックなものであり,そのダイナミズムの源泉は日常の使用のなかにあるということを改めて強調した理論と評価できるだろう.
・ 谷口 一美 『学びのエクササイズ 認知言語学』 ひつじ書房,2006年.
2014-02-17 Mon
■ #1757. synaesthesia とロマン派詩人 (1) [synaesthesia][semantic_change][collocation][rhetoric][literature]
synaesthesia(共感覚)の話題は,多くの人々の関心を引きつける.私の大学のゼミでも,毎年のように卒論の題材に選ぶ学生が現われる.そもそも synaesthesia とは何か.まずは,Bussmann の言語学用語辞典よる説明を引用しよう.
synesthesia [Grk synaísthēsis 'joint perception']
The association of stimuli or the sense (smell, sight, hearing, taste, and touch). The stimulation of one of these senses simultaneously triggers the stimulation of one of the other senses, resulting in phenomena such as hearing colors or seeing sounds. In language, synesthesia is reflected in expressions in which one element is used in a metaphorical sense. Thus, a voice can be 'soft' (sense of touch), 'warm' (sensation of heat), or 'dark' (sense of sight).
つまり,ある感覚を表わすのに,別の感覚に属する表現を用いてすることである.通言語的に広く観察される現象であり,昨日の議論「#1756. 意味変化の法則,らしきもの?」 ([2014-02-16-1]) の流れでいえば,意味に関する傾向というよりは法則と呼ぶべきものに近い.日本語でも,「柔らかい色」(触覚と視覚),「甘い香り」(味覚と嗅覚),「黄色い声援」(視覚と聴覚)など多数ある.
英語でも上記の引用中の日常的な例のほか,より文学的な言語からは "I see a voice: now will I to the chink, To spy an I can hear my Thisby's face" (Sh., Mids. N. D. 5:1:194--95), "As they smelt music" (Sh., Tempest 4:1:178), "eyes which mutter thickly" (E. E. Cummings), "And taste the music of that vision pale" (Keats) などの表現がいくらでも見つかる.
文学史的にいえば,予想されることだが,synaesthesia はロマン派の詩人が好んだ修辞法である.ロマン派の出現と synaesthesia は,無縁ではないどころか,堅く結びついている.Ullmann (272--73) は,18世紀後半の社会史と文学史の展開に,英語における本格的な共感覚表現使用の起源をみている.
In the latter half of the eighteenth century, a number of contributory factors prepared the ground for the romantic vogue of synaesthesia: occult influences (Swedenborg), theories about language origin (Herder), efforts to delimit the various arts (Lessing, Erasmus Darwin), Rousseau's use of sense-metaphors, and various other currents of pre-romantic literature.
All these threads were gathered up by the Romantic Movement. There were also some factors peculiar to that generation: the cult of exoticism and the use of drugs like hashish and opium; the part played by certain synaesthetic temperaments, such as E. T. A. Hoffmann; the tightening of social contacts between writers, artists and musicians; and in a more general way, the new code of aesthetics, with its search for novel and imaginative effects, expressiveness, and evocatory power. For the first time in the history of literature synaesthetic metaphor became a fully-fledged poetic device, and its stylistic potentialities were widely exploited. The most frequent settings in which it automatically presented itself were descriptive passages with strong suggestive power, where synaesthesia, like Leibniz's monads, provided several angles from which the same sensation could be viewed; situations where the organic unity of perceptual states had to be stressed; and last but not least, vague, dreamy, or even uncanny and hallucinatory moods where the semi-pathological implications of intersensorial transfer found a congenial expression. So strong was the interest in these 'correspondences', 'harmonies', and 'transpositions', that entire poems were devoted to synaesthetic themes. (273)
この引用は,意味論の記述であるとともに文学史上の批評ともなっており,実に興味深い.Ullmann が取り上げた作家群には,Byron, Keats, William Morris, Wilde, Dowson, Phillips, Lord Alfred Douglas, Arthur Symons; Longfellow; Leconte de Lisle, Théphile Gautier; and the Hungarian romantic poet Vörösmarty などがいた.
では,ロマン派の詩人は具体的にどのような種類の synaesthesia 表現を用いたのだろうか.これについては,明日の記事で.
・ Bussmann, Hadumod. Routledge Dictionary of Language and Linguistics. Trans. and ed. Gregory Trauth and Kerstin Kazzizi. London: Routledge, 1996.
・ Ullmann, Stephen. The Principles of Semantics. 2nd ed. Glasgow: Jackson, 1957.
2012-10-31 Wed
■ #1283. 共起性の計算法 [corpus][statistics][bnc][collocation][lltest]
[2010-03-04-1]の記事「#311. girl とよく collocate する形容詞は何か」で,語と語の共起 (collocation) を測る計算法 (association measure) にはいくつかの種類があることを見た.コーパス言語学では,Log-Likelihood Test という検定にかかわる計算法が比較的よく使われているが,それぞれの計算法には特徴があるので,なるべく複数の方法を試すのがよい.今回は[2010-03-04-1]の内容と重複する部分もあるが,BNCweb で実装されている7種類の計算法の各々について Hoffmann et al. (149--58) を参照しながら,特徴および利用のヒントを示したい.
各種の計算法は,(a) 共起頻度 (frequency of co-occurrence),(b) 共起有意性 (significance of co-occurrence),(c) エフェクト・サイズ (effect-size) の1つ,あるいは複数の組み合わせに基づいている.(b) は,共起が統計的に有意であるとの確信度を表わす指標であり,共起の強さを表わすものではないことに注意する必要がある.(c) は,観察頻度と期待頻度との比を計算の基本とする指標である.
(1) Rank by frequency
観察される共起頻度そのものを用いる,最も単純で直感的な尺度.他の計算法のような複雑な統計処理はほどこされておらず,指標としては最も粗い.機能語や句読記号などが上位に来ることが多い.通常の共起分析には用いられない.
(2) Log-likelihood
共起有意性を用いる.BNCweb のデフォルトの計算法で,コーパス研究で広く用いられている.機能語や句読記号などの極めて高頻度の語との共起や,逆に極めて低頻度の語(1, 2回など)との共起をはじく傾向がある.しかし,共起頻度の高い組み合わせに高得点を与えるという特徴があり,解釈には注意を要する.
(3) Mutual information (MI)
エフェクト・サイズを用いる.非常によく用いられている計算法だが,利用に当たっては多くの注意を要する.機能語や句読記号などとのありふれた共起を効果的に排除してくれる点はよいが,反面,低頻度の共起表現への偏りが激しい.この偏りの影響を減じるために,BNCweb では "Freq(node, collocate) at least" を10以上に設定することが推奨される.これにより,"conspicuous and intuitively appealing collocations involving words of intermediate frequency" (Hoffmann et al. 154) が浮き彫りとなる.
(4) T-score
共起頻度と共起有意性を考慮する計算法.期待頻度が1以下程度の稀な共起表現については Rank by frequency と似たような振る舞いをし,頻度の高い共起表現については共起有意性を反映した振る舞いをする.また,観察頻度が期待頻度よりも必ず高くなる.Log-likelihood と類似した結果となることが多いが,高頻度へのバイアスは一層強くなる.ノードそのものが1000回を大きく下回る場合に,効果を発揮することがある.
(5) Z-score
共起有意性とエフェクト・サイズを考慮する計算法.高頻度の共起表現にはエフェクト・サイズをより重視するが,低頻度の共起表現にはそこまでエフェクト・サイズに寄りかからない.Log-likelihood と MI の両特徴を兼ね備えたような,バランスの取れた指標である.ただし,MI と同様に,低頻度の共起表現へのバイアスがみられるので,"Freq(node, collocate) at least" を5程度に設定するのがよいとされる.
(6) MI3
共起頻度とエフェクト・サイズを考慮する計算法.MI のもつ低頻度表現への偏重を取り除くべく改善されている.低頻度共起表現にはエフェクト・サイズが,高頻度共起表現には共起頻度が,比較的よく反映される.POS による限定とともに用いると効果的.複数語からなる用語などの取り出しに威力を発揮する.しかし,全体としては高頻度共起表現へのバイアスが強く,一般的な共起分析には向かない.
(7) Dice coefficient
MI3 と同様に,共起頻度とエフェクト・サイズを考慮する計算法.しかし,MI3と異なり,低頻度共起表現には共起頻度が,高頻度共起表現にはエフェクト・サイズがよく反映され,両者の切り替えが急なのが特徴的である.切り替えは,ノードそのものの頻度が共起表現の頻度の10倍ほどの点で起こるとされる.経験的に,Z-score と似たような結果が得られるが,Z-score ほど頻度に基づくバイアスが見られない.
以上のように多種類あって目移りするが,Hoffmann et al. の見解によれば,単一基準の計算法としては Log-likelihood と MI がお勧めで,混合基準の計算法としては Z-score と Dice がお勧めとのことである.
共起性の様々な計算法については,Association measures を参照.
・ Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee, and Ylva Berglund Prytz. Corpus Linguistics with BNCweb : A Practical Guide. Frankfurt am Main: Peter Lang, 2008.
2012-05-06 Sun
■ #1105. 美女の形容としての grey eyes (2) [romance][adjective][collocation][bnc][corpus]
昨日の記事[2012-05-05-1]に引き続き grey eyes の話題.昨日は,中英語ロマンスの grey eyes について考えたが,この共起表現は現代にも続いている.BNCWeb で,"(grey|gray) {eye/N}" として検索すると,287例がヒットした.grey eyes がさらに別の形容詞に先行されている例をみると,clear, dark, deep, pale が比較的多い.beautiful や bright の例もわずかながらあった.
このような例から判断すると,grey 自体は輝きの有無を表わす意味を担当していないように思われる.もし担当しているとすれば,むしろ pale 寄りの「薄い,輝きのない」という解釈に引き寄せられるだろう.英英辞書で確認する限り,現代英語の grey の一般的な語感は,日本語のそれとよく似て,negative だからだ.老年,陰気,病気,憂鬱,退屈,悪天候のイメージだ.したがって,現代英語の grey eyes は,negative なニュアンスを特に含意しない読みを求めるとするならば,純粋に色としての「灰色」あるいは「青みのいくぶん混じった灰色」を表わすものと考えられる.あるいは,grey eyes は,意味の薄まった共起表現の伝統として用いられているにすぎないという可能性もあるかもしれない.
すると,ますます中英語の美女の典型的な描写としての grey eyes がわからない.もし,MED や Silverstein が述べている通り,中英語の grey が輝きを表わしたのだとすれば,現代英語の輝きのない grey は180度の意味変化を経たことになる.
色は gradation を描くものであり,かつて覆っていた範囲や意味を推定して復元することは,なかなか難しい.英語のみならず日本語においても,色彩語を巡る議論は厄介である.
なお,中世の美女の典型的な描写を示しておこう.Brewer (258) は,Matthew of Vandôme による Helen of Troy の描写が,以下の要約の通り,1つの型であるとしている.
. . . her hair is golden, forehead white as paper, eyebrows black and thin. The space between the eyes (in contrast to the Greek ideal) is white and clear, a 'milky way'; the face is a shining star; the eyes are like stars. She has a little smile, a nose neither too big nor too small. Her face is rosy, her colouring white and red, like rose and snow. Teeth are like ivory, lips are small, slightly swelling, honeyed. Her mouth smells like a rose, her neck is smooth, shoulders radiant, well-spaced (dispatiati), breasts small, and figure incomparable.
こんな女性,いるんでしょうか,ぜひ会ってみたい・・・.
・ Silverstein, Theodore, ed. Sir Gawain and the Green Knight. Chicago: U of Chicago P, 1983.
・ Brewer, D. S. "The Ideal of Feminine Beauty in Medieval Literature, Especially 'Harley Lyrics', Chaucer, and Some Elizabethans." The Modern Language Review 50 (1955): 257--69.
2012-01-08 Sun
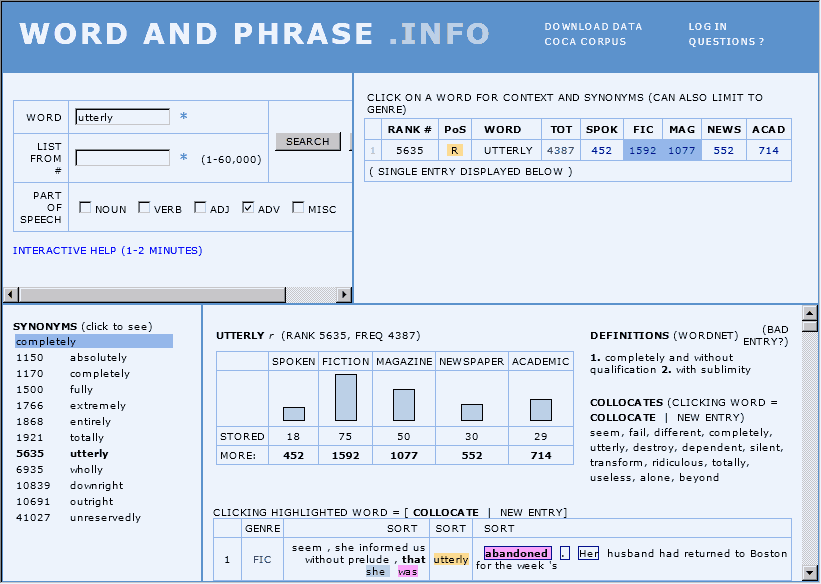
■ #986. COCA の "WORD AND PHRASE . INFO" [coca][corpus][dictionary][synonym][collocation][semantic_prosody][intensifier][web_service]
COCA ( Corpus of Contemporary American English ) を運営する Mark Davies 氏が,年末に,COCAベースで語に関する諸情報を一覧できるサービス WORD AND PHRASE . INFO を公開した.語(lemma 頻度で上位60,000語以内に限る)を入力すると,ジャンルごとの生起頻度やそのコンコーダンス・ラインはもとより,WordNet に基づいた定義や類義語群までが画面上に現われる.ほとんどの項目がクリック可能で,さらなる機能へとアクセスできる.インターフェースが直感的で使いやすい.
類義語研究や collocation 研究には相当に役立つ仕様になったのではないか.例えば,semantic_prosody を扱った[2011-03-12-1]の記事「#684. semantic prosody と文法カテゴリー」で,強意語 utterly, absolutely, perfectly, totally, completely, entirely, thoroughly についての研究を紹介したが,WORD AND PHRASE . INFO で utterly を入力すれば,これらの類義語群が左下ウィンドウに一覧される.あとは,各語をクリックしてゆくだけで,頻度や collocation の詳細が得られる.このような当たりをつけるのに効果を発揮しそうだ.
2011-12-09 Fri
■ #956. COCA N-Gram Search [cgi][web_service][coca][corpus][collocation][n-gram]
##953,954,955 の記事で,最近公開された COCA ( Corpus of Contemporary American English ) の n-gram データベースを利用してみた.COCA に現われる 2-grams, 3-grams, 4-grams, 5-grams について,それぞれ最頻約100万の表現を羅列したデータベースで,手元においておけば,工夫次第で COCA のインターフェースだけでは検索しにくい共起表現の検索が可能となる.
ただし,各 n-gram のデータベースは,数十メガバイトの容量のテキストファイルで,直接検索するには重たい.そこで,SQLite データベースへと格納し,SQL 文による検索が可能となるように検索プログラムを組んだ.以下は,検索結果の最初の10行だけを出力する CGI である.
以下,使用法の説明.テーブル名は n-gram の "n" の値に応じて,"two", "three", "four", "five" とした.ちなみに,1-grams のデータベース(事実上,COCA に3回以上現われる語の頻度つきリスト)も付随しており,こちらもテーブル名 "one" としてアクセス可能にした.フィールドは,全テーブルに共通して "freq" (頻度)があてがわれているほか,"n" の値に応じて,"word1" から "word5" までの語形 (case-sensitive) と,"pos1" から "pos5" までの COCA の語類標示タグが設定されている.select 文のみ有効.以下に,典型的な検索式を例として載せておく.
# 1-grams で,前置詞を頻度順に取り出す(ただし,case-sensitive なので再集計が必要)
select * from one where pos1 like "i%" order by freq desc;
# 2-grams で,ハンサムなものを頻度順に取り出す
select * from two where word1 = "handsome" and pos1 = "jj" and pos2 like "nn_" order by freq desc;
# 2-grams で,"absolutely (adj.)" で強調される形容詞を頻度順に取り出す([2011-03-12-1]の記事「#684. semantic prosody と文法カテゴリー」を参照)
select * from two where word1 = "absolutely" and pos2 = "jj" order by freq desc;
# 3-grams で,高頻度の as ... as 表現を取り出す
select * from three where word1 = "as" and word3 = "as" order by freq desc;
# 4-grams で,高頻度の from ... to ... 表現を取り出す
select * from four where word1 = "from" and pos1 = "ii" and word3 = "to" and pos3 = "ii" order by freq desc;
# 5-grams で,死因を探る; "die of" と "die from" の揺れを観察する
select * from five where word1 in ("die", "dies", "died", "dying") and pos1 like "vv%" and word2 in ("of", "from") and pos2 like "i%" order by word3;
n-gram データベースを最大限に使いこなすには,このようにして得られた検索結果をもとにさらに条件を絞り込んだり,複数の検索結果を付き合わせるなどの工夫が必要だろう.
2011-12-08 Thu
■ #955. 完璧な語呂合わせの2項イディオム [binomial][rhyme][corpus][coca][collocation][euphony][n-gram][suffix][proverb]
[2011-12-06-1], [2011-12-07-1]の記事で,COCA ( Corpus of Contemporary American English ) の 3-gram データベースから取り出した,現代英語における頭韻を踏む2項イディオム (binomial) と脚韻を踏む2項イディオムの例を見てきた.分析するなかで,両リストのなかで重複する2項イディオムが散見されたので,取り出してみた.これぞ,頭韻と脚韻の両方を兼ねそなえた,完璧な語呂合わせとしての共起表現である.(検索結果を収めたテキストファイルはこちら.)整理した50表現を挙げよう.
Saturday and Sunday, personal and professional, himself or herself, quantity and quality, morbidity and mortality, quantitative and qualitative, security and stability, best and brightest, latitude and longitude, sixteenth and seventeenth, whenever and wherever, sensitivity and specificity, watching and waiting, majority and minority, basketball and baseball, fight or flight, ranting and raving, forties and fifties, cooperation and coordination, nature and nurture, pushing and pulling, tossing and turning, twisting and turning, grandchildren and great-grandchildren, skiers and snowboarders, communication and collaboration, cooking and cleaning, psychiatrists and psychologists, biggest and best, development and deployment, slipping and sliding, communication and cooperation, Dungeons and Dragons, heterosexual and homosexual, healthier and happier, grandmother and grandfather, stopping and starting, sixteen or seventeen, hooting and hollering, competence and confidence, stalactites and stalagmites, waxing and waning, positive and productive, reading and rereading, patience and perseverance, bedroom and bathroom, consultation and collaboration, going and getting, grandfather and grandmother, protection and promotion
多くは,頭韻と脚韻が語呂として偶然に一致したと考えるよりは,語幹どうしに語源的な関連があるがゆえに頭韻を踏んでいるのであり,同じ接尾辞を用いているがゆえに脚韻を踏んでいるのだ,と解釈すべきだろう.
単なる語呂遊びというなかれ.上記の例は,音と意味の調和をいやおうなく感じさせ,2項の間に一種の必然性すら呼び起こすかのような,高度に修辞的な表現といえるだろう.fight or flight, nature and nurture, competence and confidence, positive and productive などは,単なる高頻度の共起表現であるという以上に,教訓的,ことわざ的ですらある.
2011-12-07 Wed
■ #954. 脚韻を踏む2項イディオム [binomial][rhyme][corpus][coca][collocation][euphony][n-gram][suffix][compound]
昨日の記事「#953. 頭韻を踏む2項イディオム」 ([2011-12-06-1]) に引き続き,今回は,脚韻を踏む高頻度の binomial を COCA ( Corpus of Contemporary American English ) の n-gram データベースにより拾い出したい.昨日と同様に,3-gram を用い,"A and/but/or B" の形の共起表現で,かつ A と B が脚韻を踏んでいるような例を取りだした.検索結果を納めたテキストファイルはこちら.
検索結果を眺めていて今更ながら気付いたことなのだが,脚韻は頭韻に比べてパターンが見つけやすい.特に顕著なのは,脚韻の多くが,語幹の語尾に依存しているというよりは,接尾辞に依存していることだ.-ing, -ed, -ly, -al, -y, -ion, -er などの屈折接尾辞や派生接尾辞が活躍している.
positive and negative, national and international, internal and external, Friday and Saturday, teaching and learning, gifted and talented, elementary and secondary, hunting and fishing, personal and professional, presence or absence, reliability and validity, coming and going, winners and losers, physical and psychological, formal and informal, directly and indirectly, advantages and disadvantages, rising and falling, physically and mentally, buyers and sellers
また,これも考えてみれば,さもありなんという事例なのだが,複合語の第2要素に同じ形態素を用いることにより韻を踏んでいる例も多い.一種の self-rhyme ではある.
Friday and Saturday, children and grandchildren, Saturday and Sunday, hardware and software, himself or herself, formal and informal, parents and grandparents, direct and indirect, buyers and sellers, mother and grandmother, father and grandfather, Afghanistan and Pakistan, anything and everything, football and basketball, indoor and outdoor, direct or indirect, servicemen and women, likes and dislikes, urban and suburban, indoor and outdoor
接尾辞を多用する屈折や派生,そして right-headed な複合を好む英語においては,脚韻を利用した2項イディオムの形成が容易であり,頻繁であることは,自然に理解できそうだ.逆から見れば,語幹の語頭音を利用する頭韻の2項イディオムの形成は,相対的に難しいということになるのかもしれない.
2011-12-06 Tue
■ #953. 頭韻を踏む2項イディオム [binomial][alliteration][corpus][coca][collocation][euphony][n-gram]
[2011-07-26-1]の記事「#820. 英仏同義語の並列」で,2項イディオム (binomial idiom) を紹介した.and, but, or などの等位接続詞で結ばれる2項からなる表現は現代英語でも顕在であり,よく見られるものには,語呂のよいもの (euphony) が多い.英語において語呂の良さといえば,[2011-11-26-1]の記事「#943. 頭韻の歴史と役割」で取り上げた頭韻 (alliteration) が,典型の1つとして挙げられる.
ところで,11月22日に,大規模オンライン・コーパス COCA ( Corpus of Contemporary American English ) などで知られるコーパス言語学者 Mark Davies が,COCA に基づく n-gram を無償で公開した.2, 3, 4, 5語からなる,それぞれ最頻100万の共起表現 (collocation) を,頻度数とともに列挙したデータベースで,ダウンロードしてオフラインで自由に処理できる.
・ Visit N-GRAMS: from the COCA and COHA corpora of American English. For downloading, directly visit Free lists.
・ Also visit Word frequency lists and dictionary: from the Corpus of Contemporary American English for other COCA-derived n-grams and frequency lists.
ここで,COCA n-gram から現代英語の2項イディオムに見られる頭韻を探して出してみようと思い立った.3-gram データベースを利用し,"A and/but/or B" の形の共起表現を探った.話者の意識していないところでも,頭韻は日常表現のなかに相当活用されているはずだとの予想のもとでの検索だったが,実際に多数の例を拾い出すことができた.検索結果のテキストファイルはこちら.2項の語頭の子音字が一致しているものを取り出しただけなので,それが表わす子音が一致しているとは限らず,注意が必要である.それでも,相当数の生きた日常的な頭韻の例を拾い出すことができた.
検索結果上位には,his or her, four or five, six or seven, this or that, Saturday and Sunday など,なるほどとは思わせるが,それほど興味深く感じられない例が少なくない.しかし,イディオム的な性格のもう少し強い,次のような共起表現も次々と挙がり,検索の甲斐があったと満足した.
public and private, rules and regulations, pots and pans, command and control, flora and fauna, free and fair, death and destruction, go and get, safety and security, signs and symptoms, fame and fortune, families and friends, fresh or frozen, peace and prosperity, past and present, quantity and quality, morbidity and mortality, slowly but surely, professional and personal, name and number, facts and figures, pencil and paper, state and society, small but significant, clear and convincing
n-gram については,[2010-12-25-1]の記事「#607. Google Books Ngram Viewer」も参照.
2011-03-03 Thu
■ #675. collocation, colligation, semantic preference, semantic prosody [semantics][corpus][collocation][semantic_prosody]
昨日の記事[2011-03-02-1]で取りあげた semantic prosody に関連する話題.語と語の共起関係には4つの種類が区別される.以下,McEnery et al. (84--85, 149--52) を参照して,抽象度の低いものから高いものへと並べ,それぞれの概要を記す.
(1) collocation: 語彙項目と語彙項目との関係
(2) colligation: 語彙項目と文法カテゴリーとの関係.
(3) semantic preference: 語彙項目と,意味的に関連する語群との関係
(4) semantic prosody: 感情的意味を生み出す語彙項目の共起関係
(1) collocation は単純に語と語が共起するという関係を指し,基本的には統計的な概念と考えられている.しかし,どの程度の頻度をもって共起すれば "collocate" していると見なすことができるのかに関して,論者のあいだで統計的な基準は異なる( see [2010-03-23-1], [2010-03-04-1] ) .通常は,常識的に「高頻度」であれば collocation と呼んでいるようだ.
(2) 名詞 house と最も高頻度で共起する語に the や a などの冠詞があるが,これは collocation を研究する上であまり有意味でない.名詞であれば冠詞と共起するのは自明であり,house に限定された話しではないからだ.collocation を有意味な術語として保つためには,house と冠詞のような,語と文法カテゴリーの関係を表わす術語が必要となる.これが colligation である.
(3) semantic preference は,ある意味的特性を共有する,高頻度で共起する語の集合に関わる関係である.例えば,large は数量・規模を表わす語群 ( ex. number(s), scale, part, quantities, amount(s) ) と共起し,utterly は特徴の欠如や状態の変化を表わす語群 ( ex. helpless, useless, unable, forgotten; changed, different ) と共起する.large や utterly は共起する語句の意味範囲を選んでいる.
(4) semantic prosody の定義は昨日の記事[2011-03-02-1]で記した通りで,態度や評価といった感情的な意味を生み出す共起関係を指す.母語話者の意識に上らない,隠された含意であることが多い.semantic preference の特殊な現われと見ることもでき,その境目は必ずしも明確ではない.
いずれの種類の共起であれ,共起に関する詳細な研究は電子コーパスで一度に多数の例文を集められるようになったことにより発展してきた.semantic prosody の研究は,意味論の発展に貢献することはいうまでもないが,類義語間の区別を明らかにするのに役立つことが見込まれるので語学教育や辞書学の分野にも貢献することになるだろう.また,この種の研究は語彙論や意味論と強く結びつけられる研究ではあるが,先に utterly との関連で示した「特徴の欠如や状態の変化」という意味特性の関与を考えると,polarity や modality といった文法カテゴリーとの関連も示唆され,統語論との接点も見いだせそうだ.そして,繰り返し共起することにより特定の意味が定着してゆくという過程に焦点を当てれば,当然,通時的な研究対象にもなり得る.
semantic prosody は,このように広範な応用が期待できそうな話題である.McEnery et al. (84) に最近の研究の書誌があるので,参考までに以下に整理しておく.
・ Hunston, S. Corpora in Applied Linguistics. Cambridge: Cambridge UP, 2002.
・ Louw, B. "Irony in the Text or Insincerity in the Writer? The Diagnostic Potential of Semantic Prosodies." Text and Technology: In Honour of John Sinclair. Eds. M. Baker, G. Francis and E. Tognini-Bonelli. Amsterdam: John Benjamins, 1993. 157--76.
・ Louw, B. 2000. "Contextual Prosodic Theory: Bringing Semantic Prosodies to Life." Words in Context: A Tribute to John Sinclair on his Retirement. Eds. C. Heffer, H. Sauntson and G. Fox. Birmingham: U of Birmingham, 2000.
・ Partington, A. Patterns and Meanings. Amsterdam: John Benjamins, 1998.
・ Partington, A. "'Utterly content in each other's company': Semantic Prosody and Semantic Preference." International Journal of Corpus Linguistics 9.1 (2004): 131--56.
・ Schmitt, N. and R. Carter "Formulaic Sequences in Action: An Introduction." Formulaic Sequences. Ed. N. Schmitt. Amsterdam: John Benjamins, 2004. 1--22.
・ Stubbs, M. "Collocations and Semantic Profiles: On the Cause of the Trouble with Quantitative Methods." Function of Language 2.1 (1995): 1--33.
・ Stubbs, M. "Texts, Corpora, and Problems of Interpretation: A Response to Widdowson." Applied Linguistics 22.2 (2001): 149--72.
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2011-03-02 Wed
■ #674. semantic prosody [semantics][corpus][collocation][semantic_prosody][terminology]
semantic prosody は,近年のコーパス言語学の興隆によって生み出された概念であり,研究課題としても注目されるようになってきた.同じくコーパス言語学によって注目を集めるようになった collocation とも深く関連している.Louw (57) によれば,semantic prosody の定義は "a form of meaning which is established through the proximity of a consistent series of collocates" である.もう少し分かりやすい定義として Crystal からも引用しよう.
A term sometimes used in corpus-based lexicology to describe a word which typically co-occurs with other words that belong to a particular semantic set. For example, utterly co-occurs regularly with words of negative evaluation (e.g. utterly appalling). (428)
例として utterly appalling が挙げられているように,utterly という強意の副詞は常に,否定的な性質を表わす語を強調する.他に,happen や set in という(句)動詞も不快な出来事を表わす名詞と共起することが多い.semantic prosody とは,共起によって強く顕現するこのような「意味上の音色」のことを指し,その主たる機能は話者の態度や評価を表わすことである.多くは否定的な評価に関するものであり,肯定的な評価の例は少ない(後者の例としては,否定的な強意副詞 utterly に対して肯定的な強意副詞 perfectly が挙げられよう).semantic prosody が collocation と強く結びつていることは,McEnery et al. (83) の挙げている personal price の例から明らかである.personal も price も単独ではその評価は中立的だが,共起すると通常否定的な意味上の音色を伴う.
特定の共起によって特定の semantic prosody が生じ,それが十分に定着してくると,その共起を故意に逸脱させることによって皮肉,偽善,ユーモアなどの特殊な効果を表わすことができるようにもなる.例えば,Cobuild written corpus に次のような例文がある.
Their relationship in fact was so complete that they were utterly content in each other's company.
semantic prosody に関して避けることのできない議論は,語と語の共起によってなぜ特定の音色(主に否定的な音色)が顕現するのか,あるいは歴史的に獲得されてきたのか,という問題である.utterly はなぜ否定的な音色を帯びるのか.この問いに対して,否定的な語と共起することが多かったから utterly 自体も否定の音色を帯びるようになったという答えがあるかもしれない.しかし,そもそも否定的な語と共起することが多かったのはなぜなのか.それは utterly 自体が本来的に否定的な音色を帯びていたからではないか.まさに鶏が先か卵が先かの問題に陥ってしまう.このような場合の常として,(1) 本来的に否定的な性質と (2) 特定の否定的な語との頻繁な共起,という2つの要因が相互に作用した結果だろうという説明がもっとも穏健かもしれない.しかし,比較的最近,接尾辞 -ish の否定的な含意の獲得について歴史的な研究を行なった私にとっては,この問題は悩ましい問題である.McEnery et al. (84) もこの問題に触れている.
It might be argued that the negative (or less frequently positive) prosody that belongs to an item is the result of the interplay between the item and its typical collocates. On the one hand, the item does not appear to have an affective meaning until it is in the context of its typical collocates. On the other hand, if a word has typical collocates with an affective meaning, it may take on that affective meaning even when used with atypical collocates. As the Chinese saying goes, 'he who stays near vermilion gets stained red, and he who stays near ink gets stained black' --- one takes on the colour of one's company --- the consequence of a word frequently keeping 'bad company' is that the use of the word alone may become enough to indicate something unfavourable . . . .
・ Crystal, David, ed. A Dictionary of Linguistics and Phonetics. 6th ed. Malden, MA: Blackwell, 2008. 295--96.
・ Louw, B. 2000. "Contextual Prosodic Theory: Bringing Semantic Prosodies to Life." Words in Context: A Tribute to John Sinclair on his Retirement. Eds. C. Heffer, H. Sauntson and G. Fox. Birmingham: U of Birmingham, 2000.
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2011-02-24 Thu
■ #668. Chaucer の knight との脚韻語 [chaucer][bnc][collocation][kyng_alisaunder]
Chaucer の全作品中,knight という語は90回以上,脚韻箇所に現われている.対応する脚韻語を調べ,さらにロンドンの方言で書かれた2つのロマンス Kyng Alisaunder と Arthur and Merlin でも同様に調べてみると,非常におもしろい事実が浮かび上がる.
Chaucer で knight と脚韻を踏む語として5回以上現われるものに,might (32), wight (22), night (9), right (8), bright (5) がある.Kyng Alisaunder では高頻度のものには wiȝth, fiȝth, riȝth / miȝth があり,同じく Arthur and Merlin では ''fiȝt, riȝt, riȝth がある.脚韻語の分布をまとめたのが以下の図である(Burnley, p. 130 の図をもとに作成).
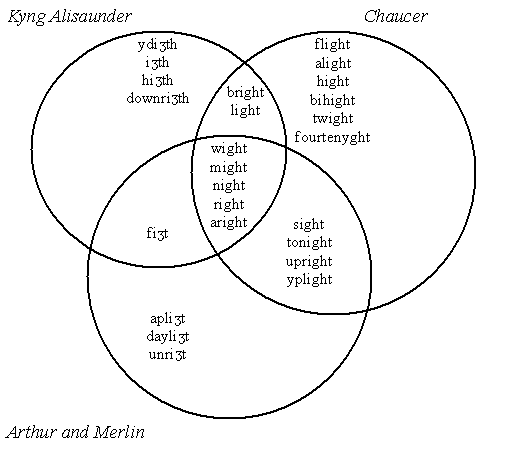
Chaucer の脚韻語は,高頻度のものを中心として大半が他の2つのロマンス作品と重複しており,全体として中英語ロマンスの伝統的な脚韻語を受け継いでいると解釈できる.一方で,Chaucer のみが用いている脚韻語もいくつか確認され,詩人の脚韻語の幅の広さが示唆される.
しかし,比較によってしか得られない非常に興味深い事実がある.他のロマンス2作品,ひいては中英語ロマンス全体として,最も頻度が高い脚韻語とみなしてもよいと思われる fight が,Chaucer には一度も現われないのである.knight と fight は縁語であり,collocation の度合いが高いことは自明であるから,Chaucer における不在は不自然とも思える.Burnley (131) は,脚韻語としての fight の不在は,Chaucer の選択した主題との関連もあるかもしれないが,おそらくは Chaucer が "a hackneyed rhyme" 「使い古された脚韻」とみなして意識的に避けたためだろうという.
Although he [Chaucer] was often content to employ familiar and traditional rhymes, there is also evidence of resourcefulness in seeking unusual rhymes, as well as of avoiding rhymes which might have proved unacceptable to his audience. (Burnley 131)
詩人が用いた脚韻語ではなく,用いなかった脚韻語を指摘することで,その詩人の特徴や詩の言語に対する態度が浮き彫りになりうる好例である.何が不在なのか,何を用いなかったのかを知るには,他と比較しなければならない.対象の本質を知るには,それが置かれている環境を広く見渡す必要がある.文献学の神髄を見せられるような印象的な例である.
ちなみに,knight と fight の collocation は強かったに違いないと述べたが,それは中世での話しである.現代英語における両語の collocation は BNCweb で調べたところそれほど顕著ではない.名詞 knight の前後5語以内に fight が現われる頻度はコーパス中で10回きりである.ただし,[2010-03-23-1]の記事で触れた MI と T-score の値を見ると,それぞれ 3.5415, 2.8907 であり,collocation と認めてよい水準ではある.
・ Burnley, David. The Language of Chaucer. Basingstoke: Macmillan Education, 1983. 13--15.
2010-03-23 Tue
■ #330. Cobuild Concordance and Collocations Sampler [corpus][bnc][cobuild][collocation]
本ブログでは,オンラインで利用できる現代英語のコーパスとして,簡便に使える BNC ( The British National Corpus ),より本格的に使える BNCWeb(要無料登録)を紹介してきた.BNC はその名の如くイギリス英語専門のコーパスで,ほぼ1975年以降の英語が約1億語おさめられている.そのうち9割は書き言葉,1割は話し言葉という構成である.現在オンラインで利用できる最大級の規模の英語コーパスである.
規模だけでいえば,もっと大きな英語コーパスが存在する.常に拡大を続けるモニターコーパス The Bank of English であり,その規模は5億5000万語にまで達する.BNC と異なり,イギリス英語だけでなくアメリカ英語を含めた他の変種もカバーしている.
このうちの一部,約5600万語が Cobuild Concordance and Collocations Sampler としてオンラインで無料で公開されている.コンコーダンス・ラインは40行まで,コロケーションのスコア・ランキングは100位までしか出力されない「デモ版」ではあるが,検索語に簡単なタグ指定ができるなど,手軽な目的であれば十分に使える仕様だろう(有料版 Collins WordbanksOnline もあり).
コロケーションのスコアとしては,T-score か MI ( Mutual Information ) かを選べる.[2010-03-04-1]でも触れたが,それぞれのスコアの特徴を簡単に述べる.
・ MI (mutual information): 共起する2語が持つ意味的特性に焦点が当てられる傾向がある.慣用句,ことわざ,複合語,専門用語など独特の言い回しを構成する語に高い値が与えられる.コーパスのサイズに依存しない.3以上の値をもって collocate しているとみなせるといわれる.イメージとしては,連想ゲーム的な語と語の関係が明らかになると考えるとよい ( = lexical collocation ).低頻度語が強調される傾向があり,独特でおもしろい結果になることがある.
・ T-score: collocation 強度そのものの指標というよりも,互いに関連があると言い切れる確信度の指標.コーパスのサイズが勘案されている.通常は,2以上の値でその collocation が統計的に有意とみなされる.特定の2語の共起頻度に焦点を当てるため,キーワードの前後に頻繁に生起する前置詞,不変化詞,人称代名詞,限定詞などの文法構造を満たすための語のほか,常套句や使い古されてしまった比喩,決まり文句などを構成する語が上位にランクインする.イメージとしては,主に文型や機能語の連語情報が明らかになると考えるとよい ( = grammatical collocation ) .
コンコーダンスやコロケーションの出力は,英語の研究や学習のためだけでなく,汎用の発想ツール,連想ツールとしても使える.例えば,octopus のコロケーションの MI 値を出してみると,上位に squid, dried, october などが現れる.味わい深い.
・ 鷹家 秀史,須賀 廣 『実践コーパス言語学』 桐原ユニ,1998年.113--15頁.
2010-03-04 Thu
■ #311. girl とよく collocate する形容詞は何か [corpus][collocation][bnc]
コーパスを使った collocation 研究は多い.しかし自分では行ったことがなかったので,McEnery et al. (56--57, 210--20) を参考にしつつ,自らお題を一つ掲げて collocation 研究のさわりを試してみた.特に collocation にかかわる様々な統計指標の特徴に注意してみたい.
お題は「girl とよく collocate する形容詞は何か」.使用するコーパスは BNCWeb .girl の左側3語までに現れる形容詞を検索対象とし,collocation の強度を示す様々な指標を出して,指標ごとに上位20個までの形容詞を一覧にしたのが下表である.
| Rank | raw frequency | observed/expected | t-score | z-score | log-likelihood | MI | MI3 |
|---|---|---|---|---|---|---|---|
| 1 | little | 15-year-old | little | little | little | 15-year-old | little |
| 2 | young | 16-year-old | young | young | young | 16-year-old | young |
| 3 | that | dark-haired | good | 15-year-old | good | dark-haired | good |
| 4 | this | 13-year-old | that | dark-haired | clever | 13-year-old | clever |
| 5 | good | nine-year-old | this | 16-year-old | poor | nine-year-old | pretty |
| 6 | one | 14-year-old | old | clever | pretty | 14-year-old | that |
| 7 | old | four-year-old | poor | pretty | old | four-year-old | 15-year-old |
| 8 | other | year-old | other | teenage | that | year-old | dark-haired |
| 9 | poor | clever | clever | 13-year-old | beautiful | clever | poor |
| 10 | clever | teenage | one | nine-year-old | lovely | teenage | 16-year-old |
| 11 | beautiful | blonde | pretty | four-year-old | golden | blonde | this |
| 12 | pretty | pretty | beautiful | head | nice | pretty | old |
| 13 | small | head | nice | 14-year-old | 15-year-old | head | beautiful |
| 14 | any | little | lovely | poor | teenage | little | teenage |
| 15 | nice | wee | big | blonde | dark-haired | wee | lovely |
| 16 | big | eldest | small | good | head | eldest | head |
| 17 | another | brave | golden | golden | 16-year-old | brave | golden |
| 18 | lovely | golden | tall | beautiful | tall | golden | nice |
| 19 | new | silly | dear | lovely | this | silly | tall |
| 20 | golden | young | teenage | year-old | dear | young | blonde |
各指標の読み方を以下にメモ.
・ raw frequency: コーパス内の総頻度.統計計算を加える前のベースとなる値で,それ自体は collocation の強度計測にはほとんど役に立たない.
・ observed/expected: 偶然に collocate している可能性からどれだけ隔たっているか.collocation の指標としては粗い.
・ t-score: 広く使われる指標.コーパスのサイズが勘案されている.通常は,2以上の値でその collocation が統計的に有意とみなされる.collocation 強度そのものの指標というよりも,互いに関連があると言い切れる確信度の指標.(後記 2010/03/21(Sun):特定の2語の共起頻度に焦点を当てるため,キーワードの前後に頻繁に生起する前置詞,不変化詞,人称代名詞,限定詞などの文法構造を満たすための語のほか,常套句や使い古されてしまった比喩,決まり文句などを構成する語が上位にランクインする.つまり,主に文型や機能語の連語情報 [ grammatical collocation ] に寄与する.)
・ z-score: 両語それぞれのコーパス中の全頻度を勘案したうえで,その collocation が期待値よりどれだけ高い頻度で現れているかを示す.広く使われている指標だが,データが正規分布をなすとの前提に立っており,多くの場合に必ずしも適切でない.コーパスが巨大か,あるいは(たいてい関心を引かない)超高頻度語を対象にするのでない限り,問題が生じうる.低頻度語が強調される傾向がある.
・ log-likelihood (LL test): データの正規分布を前提としない.コーパスのサイズが小さめでも有効.高頻度語にも低頻度語にも有効.手堅い統計値.
・ MI (mutual information): LL ほど統計的に厳格ではないが,z-score や LL の代替指標として広く使われている.3以上の値をもって collocate しているとみなせるといわれる.負の値が出ると,むしろ両語が背反し合うという意味になる.コーパスのサイズに依存しない.z-score と同様に低頻度語が強調される傾向がある.unique collocation を知るなど辞書学的な用途には役立つ指標だが,英語教育用には不向き.(後記 2010/03/21(Sun):共起する2語が持つ意味的特性に焦点が当てられる傾向がある.慣用句,ことわざ,複合語,専門用語など独特の言い回しを構成する語に高い値が与えられる.)
・ MI3: MI の低頻度語を強調しがちな傾向を補正した指標の一つ.英語教育用に向いている.同様の趣旨の指標として,log-log test というものもある.
正直なところ,どう読み解けばいいのかよくわからない(あくまで練習題なので・・・).little, young, good, clever などいずれの指標でもランクの高いものはあり,これらは明らかに強い collocation ありとみなしてよいだろう.ほかには, z-score や MI が 15-year-old などの影響を激しく反映しているのに対して,手堅い log-likelihood や補正済みの MI3 の値は -year-old を比較的よくはじいていることがわかる.このことから,-year-old は girl とよく collocate することは確かながらも,いくつかの指標が示唆するような最上位のランクであるというのは言い過ぎであるといえそうである.MI値の上位にはやや個性的と思われる形容詞も含まれており,若干くせのある値だということも肌で感じることができた.だが,統計値の解読はなかなかに難しい・・・.
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
Powered by WinChalow1.0rc4 based on chalow