昨日の記事 ([2020-10-29-1]) に引き続き,コーパス周りの用語を解説する.
concordance とは,もともとは「用語索引」ほどを意味し,ある本に出てくる単語を1つ1つ取り出してアルファベット順にリスト化したものである.その本に例えば the という単語が何回出現したか,さらに具体的にどこに出現したがが分かるような作りになっていることもあり,文献学研究や言語研究では馴染みのツールだった.聖書のコンコーダンスやChaucer のコンコーダンスなどがよく知られている.
しかし,電子コーパスが普及してからは,concordance という用語は別の意味でも用いられるようになった.昨今の電子コーパスで何らかの語なり表現なりを検索式の形にして検索すると,その条件にあった形式を含む例文がコーパス全体から収集され,ずらっと画面上に提示される.この全体が,その形式の concordance ということになる.そして,例文を含む個々の行のことを concordance line と呼ぶ.たとえていえば,ある単語を Google 検索して1万件ヒットしたという場合,その1万件全体が concordance ということになり,その1件1件が concordance line ということになる.
たいていのコーパス検索では,注目している形式の前後にどのような語が共起しているかを知りたいことが多いので,注目する形式が各 concordance line の中央に位置するように表示されると都合がよい.前後の文脈 (context) も合わせてその形式の用例を確認できることから,この表示法はコーパス研究ではある種のデフォルトといってよく,KWIC (= Key Word in Context) という名前すらついている.
昨日の記事で取り上げたが,BNCweb で "{love/V}" として検索してみると,14,195行もの concordance lines が得られる.その先頭の10行ほどを KWIC で表示すると,次のようになる.読みやすいし分析しやすい表示法であることがわかるだろう.
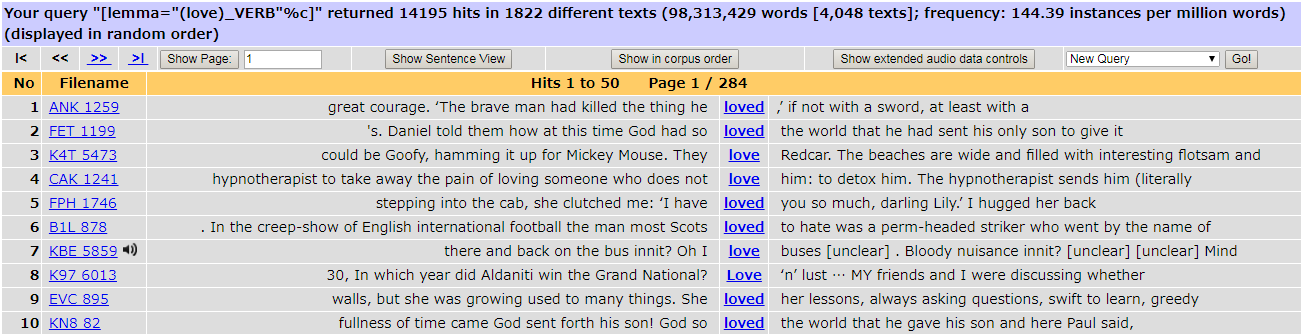
このように電子コーパスでは,ある形式の concordance が容易に得られる.もちろん concordance を産出するプログラムが背後で動いてくれているおかげであり,そのようなプログラムやアプリケーションを concordancer と呼んでいる.