2014-02-03 Mon
■ #1743. ICE Frequency Comparer [corpus][web_service][cgi][frequency][new_englishes][variety][ice]
「#1730. AmE-BrE 2006 Frequency Comparer」 ([2014-01-21-1]), 「#1739. AmE-BrE Diachronic Frequency Comparer」 ([2014-01-30-1]) で,the Brown family of corpora ([2010-06-29-1]の記事「#428. The Brown family of corpora の利用上の注意」を参照)を利用した,変種間あるいは通時的な頻度比較ツールを作った.Brown family といえば,似たような設計で編まれた ICE (International Corpus of English) も想起される([2010-09-26-1]の記事「#517. ICE 提供の7種類の地域変種コーパス」を参照).1990年以降の書き言葉と話し言葉が納められた100万語規模のコーパス群で,互いに比較可能となるように作られている.
そこで,手元にある ICE シリーズのうち,Canada, Jamaica, India, Singapore, the Philippines, Hong Kong の英語変種コーパス計6種を対象に,前と同じように頻度表を作り,データベース化し,頻度比較が可能となるツールを作成した.使い方については,「#1730. AmE-BrE 2006 Frequency Comparer」 ([2014-01-21-1]) を参照されたい.
どんな使い道があるかは,アイデア次第だが.例えば,"^snow(s|ed|ing)?$", "^Japan(ese)?$", "^bananas?$", "^Asia(n?)s?$" などで検索してみるとおもしろいかもしれない.
2014-01-30 Thu
■ #1739. AmE-BrE Diachronic Frequency Comparer [corpus][ame_bre][web_service][cgi][frequency][representativeness]
「#1730. AmE-BrE 2006 Frequency Comparer」 ([2014-01-21-1]) で,2006年前後の書き言葉テキストを編纂した英米各変種コーパスを紹介し,それに基づいた頻度比較ツールを作成・公開した.そのツールを作成しながら気づいたのだが,同じ方法で編纂され,規模も同じく100万語程度の the Brown family of corpora (「#428. The Brown family of corpora の利用上の注意」 ([2010-06-29-1]))と連携させれば,直近50年間ほどの通時的な英米間頻度比較が容易に可能となる.
そこで,前の記事で紹介した Professor Paul Baker - Linguistics and English Language at Lancaster University による AmE06 と BrE06 に加えて,書き言葉アメリカ英語を代表する Brown (1961), Frown (1992),書き言葉イギリス英語を代表する LOB (1961), FLOB (1991) より語形頻度表を抽出し,合わせてデータベース化した.利用の仕方は,AmE-BrE 2006 Frequency Comparer とほぼ同じなので,そちらの取説 ([2014-01-21-1]) を参照されたい.ただし,出力される表では,問題の語形が出現するテキストの数や頻度順位は省いており,純粋に約100万語当たりの頻度を表示するにとどめているので,AmE06 と BE06 について前者の情報が必要な場合には,AmE-BrE 2006 Frequency Comparer をどうぞ.
例えば,^movies?$ と入力してみると,伝統的にアメリカ英語的とされてきたこの語の分布が,過去50年ほどの間に,イギリス英語にも浸透してきている様子がわかる.
英米差の通時的な変化を調査したいのであれば,単語だけではなく語句も受けつけ,かつ規模も巨大な「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) のほうが簡便だろう.しかし,今回のツールは,the Brown family of corpora をベースにしているがゆえに,(1) 均衡かつ比較可能であり,(2) 「素性」がわかっている(再現可能性が確保されている)という利点があることは指摘しておきたい.望ましいのは,小型できめ細かなコーパスと,大型で傾向を大づかみにするコーパスとを上手に連携させることだろう.
2014-01-21 Tue
■ #1730. AmE-BrE 2006 Frequency Comparer [corpus][ame_bre][web_service][cgi][frequency][spelling]
先日,Professor Paul Baker - Linguistics and English Language at Lancaster University というページを教えてもらった.Baker 氏の編纂した現代英語・米語コーパス BE06 と AmE06 の情報と,そこから抽出した単語リストが得られる.当該のコーパス自体は,ユーザIDを請求すれば,ランカスター大学の CQP (Corpus Query Processor) system よりアクセスできる.
BE06 と AmE06 は,2006年前後に出版されたイギリス変種とアメリカ変種の書き言葉均衡コーパスである.編纂方式や構成は「#428. The Brown family of corpora の利用上の注意」 ([2010-06-29-1]) で紹介した The Brown family に準じており,500テキスト×2000語の計100万語ほどの規模だ.
さて,上のページからダウンロードできる BE06 Wordlist in WordSmith 5 format と AmE06 Wordlist in WordSmith 5 format より(見出し語ではなく)語形による頻度表を抽出し,それぞれをデータベース化して,英米変種の語の頻度を比較してくれる AmE-BrE Frequency 2006 Comparer なるツールを作成してみた.
入力するのは原則としてPerl5相当の正規表現だが,カンマ,タブ,改行などで区切った(非正規表現の)単語リストも受け付ける.1つの語形のみを入力したい場合には ^ と $ で挟んで ^loves$ のようにするか,あるいは "nothing (non-regex mode only)" のラジオボックスをオンにする.
出力形式は,デフォルトではアメリカ英語コーパスにおける頻度の高い順でソートされるようになっている ("by AmE freq") が,イギリス英語コーパスの頻度順 ("by BrE freq"),語形のアルファベット順 ("alphabetically") も可能.単語リストで入力した場合に,入力したそのままの順序で出力したいときには,"nothing (non-regex mode only)" をオンにする.
いずれも100万語規模の(今となっては)小さめのコーパスなので,語形によっては十分な頻度が得られないこともあるが,簡便に英米差をチェックしたいときには便利だろう.出力結果の WORD, AME_2006, BRE_2006 の3列を切り出して,最後の行にコーパスサイズとして "total\t1000000\t1000000" と補ったうえで,Log-Likelihood Tester, Ver. 1 に放り込めば,英米差を統計的に検定することができる.
例として,「#244. 綴字の英米差のリスト」 ([2009-12-27-1]) のうち,とりわけよく知られている類の米英綴字のペアを抜き出したリストを挙げよう.以下をコピーして,上のテキストボックスに放り込み,"nothing (non-regex mode only)" を選択して実行すると,数値として米英差が実感できる.
acknowledgment, acknowledgement, aging, ageing, aluminum, aluminium, analyze, analyse, apologize, apologise, armor, armour, behavior, behaviour, center, centre, civilization, civilisation, color, colour, defense, defence, disk, disc, endeavor, endeavour, favor, favour, favorite, favourite, fiber, fibre, flavor, flavour, fulfill, fulfil, gray, grey, harbor, harbour, honor, honour, humor, humour, inquiry, enquiry, judgment, judgement, labor, labour, license, licence, liter, litre, marvelous, marvellous, mold, mould, mom, mum, neighbor, neighbour, neighborhood, neighbourhood, odor, odour, organize, organise, pajamas, pyjamas, parlor, parlour, program, programme, realize, realise, recognize, recognise, skeptic, sceptic, specter, spectre, sulfur, sulphur, theater, theatre, traveler, traveller, tumor, tumour
これまでは,語彙や綴字に関する英米差のコーパスによる比較は,「#708. Frequency Sorter CGI」 ([2011-04-05-1]) を用いたり,「BNC Frequency Extractor」 ([2012-12-08-1]) と「#1322. ANC Frequency Extractor」 ([2012-12-09-1]) を組み合わせたり,the Brown Family corpora を併用するなど,各変種コーパスの個別比較により対処してきたが,今回のツールにより多少便利な環境ができた.
2013-08-24 Sat
■ #1580. 補充法研究の限界と可能性 [suppletion][analogy][arbitrariness][frequency][taboo][preterite-present_verb]
補充法 (suppletion) は広く関心をもたれる言語の話題である.go -- went -- gone, be -- is -- am -- are -- was -- were -- been, good -- better -- best, bad -- worse -- worst, first -- second -- third など,なぜ同一体系のなかに異なる語幹が現われるのか不思議である.言語における不規則性の極みのように思われるから,とりわけ学習者の目にとまりやすい.
しかし,専門の言語学においては,補充法への関心は必ずしも高くない.補充法を掘り下げて研究することには限界があると感じられているからだろう.その理由としては,(1) 単発であること,(2) 形態的に不規則で分析不可能であること,(3) 範列的な圧力 (paradigmatic pressure) から独立しており,形態的な類推 (analogy) が関与しないこと,などが挙げられる.つまり,個々の補充形は,文法のなかで体系的に扱うことができず,語彙項目として個別に登録されているにすぎないものと理解されている.一般にある語がなぜその形態を取っているのかが恣意的 (arbitrary) であるのと同様に,補充形がなぜその形態なのかも恣意的であり,より深く掘り下げられる種類の問題ではないということだろう.補充法の特徴を何かあぶりだせるとすれば,一握りの極めて高頻度の語にしか見られないということくらいである.
Hogg は,一見すると矛盾するように思われる "Regular Suppletion" という題名を掲げて,補充法研究の限界を打ち破り,可能性を開こうとした.補充法は,形態理論の研究に重要な意味をもつという.Hogg は,英語史からの補充法の例により,次の4点を論じている.
1つ目は,"the replacement of one suppletion by another" の例がみられることである.すでに古英語では yfel -- wyrsa -- wyrsta の補充法の比較が行なわれていたが,中英語では原級の語幹が入れ替わり,現代英語の bad -- worse -- worst へと至った.現在では,前者は evil -- more evil -- most evil となっている.yfel は極めて一般的な語義「悪い」を失い,宗教的な語義へ転じていったことにより,worse -- worst に対応する原級の地位を失い,後から一般的な語義を獲得した bad に席を譲ったということになる.Hogg は,古英語 *bæd はタブーだったために文証されていないだけであり,実際には14--18世紀に文証される badder -- baddest とともに,規則的な比較変化を示していたはずだと推測している (72) .あくまで仮説ではあるが,evil と bad について,比較級変化は以下のような歴史的変化を経ただろうとしている (72) .
evil → worse → worse, more evil → more evil bad → badder → worse, badder → worse
2つ目は,"the preference for suppletion over regularity" であり,go -- went に例をみることができる."to go" の補充過去形として古英語 ēode が中英語 went に置き換えられたことはよく知られている.それによって went の本来の現在形 wend が wended という規則的な過去形を獲得したことが,英語史上も話題になっている.went の例で重要なのは,規則形よりも補充形が好まれるという補充法の傾向を示すものではないかということだ.ただし,北部方言やスコットランド方言では,別途,規則形 gaid や gaed が生み出されたという事実もある.
3つ目は,"the addition of regularity without disturbance of the suppletion" である.古英語 bēon の3人称複数現在形の1つ syndon は,印欧祖語 *-es からの歴史的な発展形である synd や synt という補充形に,過去現在動詞 (preterite-present_verb) の現在複数屈折語尾 -on を加えたものである.本来的に形態的類推を寄せつけないはずの語幹に,形態的類推による屈折語尾を付加した興味深い例である.これは,上で触れた (2), (3) の反例を提供する.
4つ目は,"the creation of a new regular inflection on the basis of suppletion" である.古英語 bēon の1人称現在単数形の1つ (e)am は,Anglia 方言では語尾 -m の類推により非歴史的な bīom を生み出した.同方言ではこれが一般動詞に及び,非歴史的な1人称現在単数形 flēom (I flee) や sēom (I see) をも生み出すことになった.本来,補充形の内部にあって分析されないはずの -m がいまや形態素化したことになる.
Hogg (80--81) は,以上のように補充法の語彙的,形態的な注目点を明らかにしたうえで,"[S]uppletion is not merely a linguistic freak which does no more than give a small amount of pleasure to a rather giggling schoolboy. . . . [S]uppletion is a dynamic process." と述べ,補充法研究の可能性を探りながら,論文を閉じている.
・ Hogg, Richard. "Regular Suppletion." Motives for Language Change. Ed. Raymond Hickey. Cambridge: CUP, 2003. 71--81.
2013-04-06 Sat
■ #1440. 音節頻度ランキング [syllable][corpus][lexicon][phonetics][frequency][statistics]
「#1424. CELEX2」 ([2013-03-21-1]) で紹介した巨大データベースで何かしてみようと考え,Version 2 で新たに加えられた音節頻度 (English Frequency, Syllables) のサブデータベースにより,現代英語で最も多い音節タイプのランキングを得た.
これは,CELEX2 のもとになっているコーパス全体のうち,7.26%を構成する約130万語の話し言葉サブコーパスから引き出された音節頻度であり,タイプ頻度ではなくトークン頻度によるものである.つまり,話し言葉におけるある単語の頻度が高ければ,その分,その単語に含まれる音節タイプの頻度も高くなるということである.例えば,of を構成する "Ov" (= /ɒv/) と表現される音節は,第4位の頻度である.なお,強勢の有無は考慮せずに頻度を数えている.
以下のリストに挙げる音素表記は,IPA ではなく CELEX 仕様の独特の表記なので,先に対応表を挙げておこう.
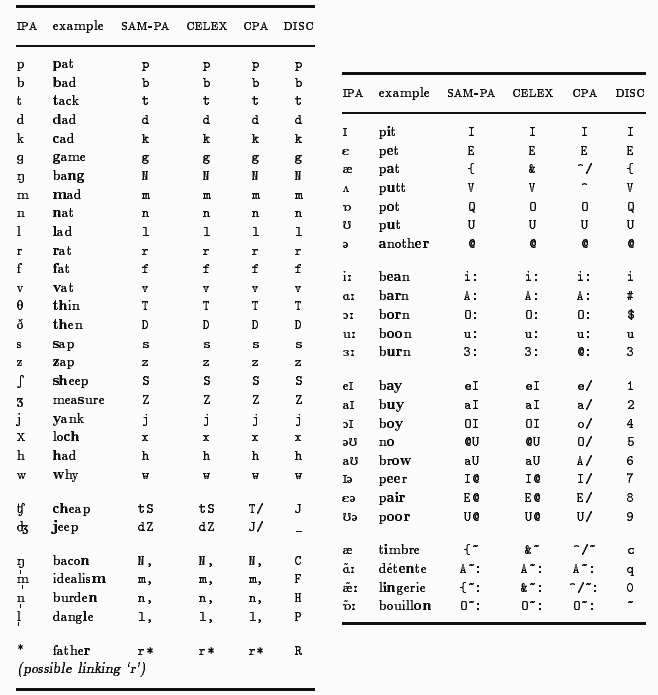
では,以下にランキング表でトップ50位までを掲載する.高頻度の単音節語の音節タイプがそのまま上位に反映されていて,あまりおもしろい表ではないが,何かの役に立つときもあるかもしれない.
| Rank | Syllable | Frequency |
|---|---|---|
| 1 | eI | 72971 |
| 2 | Di: | 60967 |
| 3 | tu: | 31446 |
| 4 | Ov | 30108 |
| 5 | In | 29906 |
| 6 | &nd | 28709 |
| 7 | aI | 23822 |
| 8 | lI | 19728 |
| 9 | @ | 19566 |
| 10 | rI | 14356 |
| 11 | ju: | 12598 |
| 12 | dI | 12465 |
| 13 | D&t | 12118 |
| 14 | It | 11504 |
| 15 | wOz | 10834 |
| 16 | fO:r* | 9778 |
| 17 | Iz | 9517 |
| 18 | tI | 9161 |
| 19 | fO | 9042 |
| 20 | Sn, | 8969 |
| 21 | hi: | 8928 |
| 22 | r@n | 8638 |
| 23 | bi: | 8505 |
| 24 | bI | 7936 |
| 25 | nI | 7068 |
| 26 | wID | 7046 |
| 27 | On | 7030 |
| 28 | &z | 6919 |
| 29 | O:l | 6569 |
| 30 | h&d | 6240 |
| 31 | E | 6165 |
| 32 | bl, | 6021 |
| 33 | sI | 5836 |
| 34 | @U | 5824 |
| 35 | t@r* | 5687 |
| 36 | &t | 5652 |
| 37 | hIz | 5564 |
| 38 | bVt | 5416 |
| 39 | mI | 5397 |
| 40 | s@ | 5391 |
| 41 | nOt | 5357 |
| 42 | D@r* | 5339 |
| 43 | I | 5283 |
| 44 | tId | 5259 |
| 45 | DeI | 5162 |
| 46 | IN | 5063 |
| 47 | t@ | 5053 |
| 48 | s@U | 4974 |
| 49 | baI | 4894 |
| 50 | h&v | 4769 |
全ランキング表を見たい方は,タブ区切り形式で Syllable Frequency Rank Table by CELEX2 を参照.ブラウザ上で閲覧したい方は,こちらからどうぞ.全体としては11492の異なる音節タイプが登録されており,頻度が1以上のものは7934タイプある.「#1023. 日本語の拍の種類と数」 ([2012-02-14-1]) の最後で,英語の音節タイプが日本語に比べて驚くほど多種多様であることに触れたが,この数をみれば納得できるだろう.関連して,syllable の各記事を参照.
なお,CELEX2 のマニュアルには以下の但し書きが記されていたので,再掲しておく.
Please note that the English corpus used by CELEX for deriving these frequencies contains only 7.3% spoken material. This means there is a rather tenuous relationship between the full frequency figures, which are based on written forms, and the syllable frequencies, which merely refer to phonemic conversions of these graphemic transcriptions. Of course it could be argued that frequencies of syllables, as lexical sub-units, are less liable to get skewed from differences in medium than full words, but it has to be taken into account that NO FIRM EVIDENCE ABOUT SPOKEN FREQUENCIES can be derived from these data.
2013-03-21 Thu
■ #1424. CELEX2 [corpus][dictionary][statistics][frequency][lexicology]
英単語の頻度に関連する諸研究(Betty Phillips など)で,CELEX という語彙データベースが使用されているのを見かけることがある.現在取りかかっている研究で,巨大コーパスに基づいた信頼できる語彙頻度統計が必要になったので,郵送料込みで350ドルするこの高価なデータベースを入手してみた.現行版は第2版であり,CELEX2 として購入できる.(なお,予想していなかったが,入手した CD-ROM には,LDC99T42 というデータベースも含まれていた.ここには tagged Brown Corpus, Wall Street Journal, Switchboard tagged など Treebank 系のコーパスが入っている.)
さて,CELEX2 には,英語語彙に関する複数のデータベースが納められている.それぞれのデータベースには,正書法,音韻,音節,形態,統語の各観点から,見出し語 (lemma) あるいは語形 (wordform) ごとに,ソース・コーパス内での頻度等の情報が格納されている.具体的には,次の11のデータベースが利用可能である.
ect (English Corpus Types)
efl (English Frequency, Lemmas)
efs (English Frequency, Syllables)
efw (English Frequency, Wordforms)
eml (English Morphology, Lemmas)
emw (English Morphology, Wordforms)
eol (English Orthography, Lemmas)
eow (English Orthography, Wordforms)
epl (English Phonology, Lemmas)
epw (English Phonology, Wordforms)
esl (English Syntax, Lemmas)
見出し語あるいは語形ごとの token 頻度の取り出しに強いデータベースという認識で購入したが,実際には,含まれている情報の種類は驚くほど豊富で,11のデータベースすべてを合わせたフィールド数はのべ250以上に及ぶ.行数は efl で52,447行,efw で160,595行という巨大さだ.検索用の SQLite DB をこしらえたら,容量にして90MBを超えてしまった.
CELEX2 のソースは,辞書情報については Oxford Advanced Learner's Dictionary (1974) 及び Longman Dictionary of Contemporary English (1978) であり,頻度情報については 1790万語からなる COBUILD/Birmingham corpus である.このコーパスの構成は,1660万語 (92.74%) が書き言葉コーパス,130万語 (7.26%) が話し言葉コーパスで,前者を構成する284テキストのうち44テキスト (15.49%) がアメリカ英語である.しかし,これらのアメリカ英語はほとんどがイギリス英語の綴字に直されていることに注意したい.
CELEX2 における "lemma" の定義は,以下の5点に依存する.
(1) orthography of the wordforms: peek vs peak
(2) syntactic class: meet (adj.) vs meet (adv.)
(3) inflectional paradigm: water (v.) vs water (n.)
(4) morphological structure: rubber (someone or something that rubs) vs rubber (the elastic substance)
(5) pronunciation of the wordforms: recount [ˈriː-kaʊnt] vs recount [rɪ-ˈkaʊnt]
したがって,通常異なる lexeme として扱われる bank (土手)と bank (銀行)などは,CELEX2 では同一の lemma として扱われているので注意が必要である.
このように CELEX2 は非常に強力な語彙頻度データベースだが,その他にも語彙頻度研究に資するデータベースやツールは存在する.本ブログで触れたものとしては,frequency statistics lexicology の各記事や,特に以下の記事が参考になるだろう.
・ 「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1])
・ 「#607. Google Books Ngram Viewer」 ([2010-12-25-1])
・ 「#708. Frequency Sorter CGI」 ([2011-04-05-1])
・ 「#1159. MRC Psycholinguistic Database Search」 ([2012-06-29-1])
・ Baayen R. H., R. Piepenbrock and L. Gulikers. CELEX2. CD-ROM. Philadelphia: Linguistic Data Consortium, 1996.
2013-01-09 Wed
■ #1353. 後舌高母音の長短 [pronunciation][phonetics][spelling][vowel][phoneme][frequency][variation]
[2012-02-13-1]の記事「#1022. 英語の各音素の生起頻度」で確認できるように,/ʊ/ は英語の短母音音素のなかで最も生起頻度の低いものである.綴字としては,典型的に <oo> や <u> で表わされる音素だが,前者は /uː/,後者は /ʌ/ として実現されることも多いので,実際にはそれほど現われない.具体的にはどのくらいあるのだろうか.
「#1191. Pronunciation Search」 ([2012-07-31-1]) で,「/ʊ/ + 子音」で終わる単音節語を拾ってみた.検索欄に "^[^AEIOU]*(?<!Y )UH[012]? [^AEIOUHWY]+$" と入れてみると次の159語が挙がった.
bloor, book, book's, booked, books, books', boor, boord, boors, bourque, brook, brook's, brooke, brooke's, brookes, brooks, brooks's, bruehl, bull, bull's, bulls, bulls', cook, cook's, cooke, cooked, cooks, could, crook, crooke, crooks, duerr, duerst, flook, fluhr, fooks, foor, foot, foote, foote's, foots, fuhr, fuld, full, full's, fulp, fults, fultz, gloor, good, good's, goode, goods, gook, hood, hoods, hoofed, hoofs, hook, hook's, hooke, hooked, hooks, hooves, joong, jure, kook, kooks, koors, kuehl, kuhrt, look, looked, looks, loong, luehrs, luhr, luhrs, lure, lured, lures, mook, moor, moore, moore's, moored, moores, moors, muhr, nook, nooks, poor, poor's, poore, poors, pull, pulled, pulls, puls, pultz, put, puts, rook, rooke, rooks, routes, ruehl, ruhr, schnooks, schnoor, schoof, schook, schultz, schulz, schulze, schuur, shook, should, shultz, shure, snook, snooks, soot, soots, spoor, spoor's, stood, stroock, stuhr, suire, sure, took, tooke, tookes, tour, tour's, toured, tours, ture, uhr, wolf, wolf's, wolfe, wolfe's, wolff, wolves, wood, wood's, woods, wool, woolf, wools, woong, would, wuertz, wulf, wulff, zook, zuehlke
一方で,対応する長母音 /uː/ や中舌母音 /ʌ/ をもつ単音節語は,同様の条件検索 "^[^AEIOU]*(?<!Y )UW[012]? [^AEIOUHWY]+$" および "^[^AEIOU]*(?<!Y )AH[012]? [^AEIOUHWY]+$" によれば,それぞれ596語,966語がヒットした.限定された音声環境における調査ではあるが,相対的に /ʊ/ をもつ単語が少ないことがわかる.
上の171語のうち,<oo> = /ʊ/ の関係を示すものは95語ある.この綴字と発音の関係の背景には,「#547. <oo> の綴字に対応する3種類の発音」 ([2010-10-26-1]) および「#1297. does, done の母音」 ([2012-11-14-1]) で述べた通り,長母音の短母音化という音韻変化があった.
この音韻変化は過去のものではあるが,その余波は現代でも少数の語において散発的に見られる.例えば,「発音の揺れを示す語の一覧」 ([2010-08-28-1]) で確認できる限り,room, bedroom, broom の発音は,長母音と短母音の間で揺れを示す.LPD の Preference polls によれば,揺れの分布は以下の通り.
| BrE /ruːm/ | BrE /rʊm/ | AmE /ruːm/ | AmE /rʊm/ | |
|---|---|---|---|---|
| room | 81% | 19 | 93 | 7 |
| bedroom | 63 | 37 | - | - |
| broom | 92 | 8 | - | - |
関連して,「#1094. <o> の綴字で /u/ の母音を表わす例」 ([2012-04-25-1]) も参照.長母音 /uː/ については,「#841. yod-dropping」 ([2011-08-16-1]) も関与する.
・ Wells, J C. ed. Longman Pronunciation Dictionary. 3rd ed. Harlow: Pearson Education, 2008.
2013-01-02 Wed
■ #1346. 付加疑問はどのくらいよく使われるか? [interrogative][tag_question][ame_bre][corpus][frequency][statistics]
現代英語の会話では,付加疑問がよく使われる.だが,具体的にどのくらいよく使われるのだろうか.そもそも一般的に疑問文はどのくらいの頻度で生起するのか.そのなかで,付加疑問はどれくらいの割合を占めるのか.このような疑問を抱いたら,まず当たるべきは Biber et al. の LGSWE である.
最初の問題については,p. 211 に解答が与えられている.疑問符の数による粗い調査だが,CONV(ERSATION) では40語に1つ疑問符が含まれているという.会話コーパスでは,転写上,疑問符が控えめに反映されている可能性が高く,実際には数値以上の頻度で疑問文が生起しているはずである.テキストタイプでいえば,次に大きく差を開けられて FICT(ION) が続き,NEWS と ACAD(EMIC) では疑問文の頻度は限りなく低い.
次に,各サブコーパスにおいて,疑問文全体における付加疑問の生起する割合はどのくらいか.p. 212 に掲載されている統計結果を以下のようにまとめた.各列を縦に足すと100%となる表である.
| (* = 5%; ~ = less than 2.5%) | CONV | FICT | NEWS | ACAD | |
|---|---|---|---|---|---|
| independent clause | wh-question | **** | ******* | ********* | ********** |
| yes/no-question | ***** | ***** | ******* | ******* | |
| alternative question | ~ | ~ | ~ | ~ | |
| declarative question | ** | * | ~ | ~ | |
| fragments | wh-question | * | ** | ** | * |
| other | *** | *** | * | * | |
| tag | positive | * | ~ | ~ | ~ |
| negative | **** | * | ~ | ~ | |
CONV において付加疑問の生起比率が高いことは当然のように予測されたが,同サブコーパスの疑問表現全体のなかで25%を占めるということは発見だった.そのなかでも,肯定の is it? よりも否定の isn't it? のタイプのほうがずっと多い.また,FICT が CONV におよそ準ずる分布を示すのは,フィクション内の会話部分の貢献だろう.一方,NEWS と ACAD で付加疑問の比率が低いのは,この表現と対話との結びつきを強く示唆するものである.また,この2つのサブコーパスでは,完全な独立節での疑問文,特に wh-question が相対的に多いのが注意を引く.
付加疑問の生起比率に関心をもったのは,実は,Schmitt and Marsden (192) に次のような記述を見つけたからだった.
Tag questions (i.e., regular questioning expressions tagged onto a sentence) exist in both American and British English, with British speakers perhaps using them more than Americans: "That's not very nice, is it?" Peremptory and aggressive tags tend to be used more in British English than in American English: "Well, I don't know, do I?" (192)
残念ながら,Biber et al. では付加疑問の頻度の英米差を確かめることはできない.別途,英米のコーパスで調べる必要があるだろう.
・ Schmitt, Norbert, and Richard Marsden. Why Is English Like That? Ann Arbor, Mich.: U of Michigan P, 2006.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
2012-12-12 Wed
■ #1325. 会話で否定形が多い理由 [corpus][negative][frequency]
Cheshire (115) を読んでいて,現代英語に関する記述として,会話において否定形が多く使われるという言及に遭遇した.直感的には確かにそのように思われるが,客観的な裏付けはあるのだろうかと,LGSWE に当たってみた.すると,関連する記述が pp. 159--60 に見つかった.
否定形にも様々な種類があるが,4つの使用域のそれぞれについて,コーパスを用いて "Distribution of not/n't v. other negative forms" を調査した結果が示されていた.100万語当たりの生起数を,グラフと表で示そう.
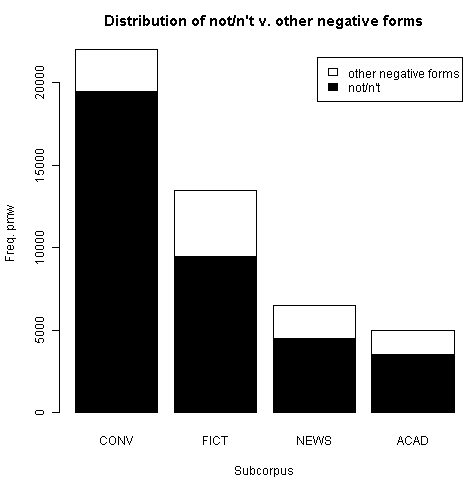
| not/n't | other negative forms | |
|---|---|---|
| CONV | 19500 | 2500 |
| FICT | 9500 | 4000 |
| NEWS | 4500 | 2000 |
| ACAD | 3500 | 1500 |
会話で否定形が頻出する理由として,LGSWE は以下を挙げている.
(1) 会話では他のレジスターよりも動詞が多い.否定は動詞と最も強く結びつくので,会話で否定が多いのは当然予想される.
(2) 会話では他のレジスターよりも節が短く,多い.その分,否定の節も多くなることは当然予想される.
(3) 会話では表現の反復が多い.否定形の反復もそれに含まれる.
(4) 多重否定や付加疑問など,話しことばに典型的な否定構文というものがある.
(5) not と強く共起する動詞があり,それらはとりわけ会話において頻度が高い.例えば,forget, know, mind, remember, think, want, worry などの心理動詞など.
(6) 会話には相手がおり,意見の一致や不一致に関わる表現が多くなる.会話では,not のみならず no や他の否定辞も頻出する.
CONV の次に FICT に否定形が多いのは,おそらくフィクションにおける対話部分が貢献しているからだろう.また,(1) については,会話には全体として動詞が多く生起するという事情も関与しているだろう.
・ Cheshire, Jenny. "Double Negatives are Illogical." Language Myths. Ed. Laurie Bauer and Peter Trudgill. London: Penguin, 1998. 113--22.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
[ 固定リンク | 印刷用ページ ]
2012-12-09 Sun
■ #1322. ANC Frequency Extractor [cgi][web_service][frequency][corpus][anc]
昨日の記事「#1321. BNC Frequency Extractor」 ([2012-12-08-1]) に引き続き,ANC (American National Corpus) に基づく頻度表がANC Second Release Frequency Data のページに公開されていたので,"ANC Frequency Extractor" を作成した.
仕様は,"BNC Frequency Extractor" と少々異なる.データベースは SQLite で,select 文のみ有効というのは同様.テーブルは "anc" (コーパス全体),"written" (書き言葉コーパス),"spoken" (話し言葉コーパス) ,"token" (語形ごとの頻度と生起率)の4種類.フィールドは,"anc", "written", "spoken" の各テーブルについては,"word", "lemma", "pos", "freq" の4つ,"token" のテーブルについては,"word", "freq", "ratio" の3つである.POS-tag については,Penn Treebank Tagset を参照.
以下に,検索式をいくつか挙げておこう.
# 書き言葉テキストで,英米差があるとされる "diarrhoea" vs. "diarrhea" の綴字の生起頻度を確認
select * from written where word like "diarrh%"
# 書き言葉テキストで,英米差があるとされる "judgement" vs. "judgment" の綴字の生起頻度を確認.(その他,[2009-12-27-1]の記事「#244. 綴字の英米差のリスト」の綴字を放り込んでゆくとおもしろい.)
select * from written where word like "judg%ment%"
# -ly で終わらない副詞を探す(flat adverb かもしれない例を探す)
select * from anc where lemma not like "%ly" and pos like "RB%"
# -s で終わる副詞を探す(adverbial genitive の名残かもしれない例を探す)
select * from anc where pos like "RB%" and word like "%s"
# 単数名詞と複数名詞の token 数の比較を written subcorpus と spoken subcorpus で([2011-06-07-1]の記事「#771. 名詞の単数形と複数形の頻度」を参照)
select pos, sum(freq) from written where pos in ("NN", "NNS") group by pos
select pos, sum(freq) from spoken where pos in ("NN", "NNS") group by pos
select pos, sum(freq) from anc where pos in ("NN", "NNS") group by pos
ANC は有料だが,そこから抜粋された OANC (Open American National Corpus) は無料.ANC 及び OANC については,「#708. Frequency Sorter CGI」 ([2011-04-05-1]) や「#509. Dracula に現れる whilst (2)」 ([2010-09-18-1]) を参照.
"BNC Frequency Extractor" と "ANC Frequency Extractor" を組み合わせて使えば,語彙の英米差について頻度の観点から簡単に調査できる.
2012-12-08 Sat
■ #1321. BNC Frequency Extractor [cgi][web_service][frequency][corpus][bnc]
Adam Kilgarriff が公開している BNC database and word frequency lists から,見出し語化されていない頻度表 (unlemmatised lists) をダウンロードし,検索できるようにデータベースをこしらえた.
仕様の説明.データベースには SQLite を用いており,SQL対応.select 文のみ有効.テーブルは "bnc" (コーパス全体),"written" (書き言葉コーパス),"demog" ('demographic' spoken material) ,"cg" ('context-governed' spoken material) ,"variances" (計算された分散その他の値を含む)の5種類.variances を除く4テーブルについては,フィールドは "freq" (頻度), "word" (語形), "pos" (品詞;BNC CLAWS POS-tags の一覧を参照), "files" (その語形が生起しているテキスト数)の4つ.variances のテーブルについては,上記4フィールドに加えて,"mean" (= freq / files) ,"variance" (分散),"variance_to_mean" (= variance / mean) の3つが設定されている.variances の計算基準となっているサブコーパスは,5000語以上を含む書き言葉テキストということで,全体としては約1千万語(BNC全体の約1割)である.具体的には,"select * from bnc limit 10" や "select * from variances limit 10" などとすれば,データの格納のされ方を確かめることができる.
以下に,典型的な検索式を挙げておこう.
# 書き言葉テキストで,英米差があるとされる "diarrhoea" vs. "diarrhea" の綴字の生起頻度を確認
select * from written where word like "diarrh%"
# s で始まる語形を分散の高い順に
select * from variances where word like "s%" order by variance desc limit 100
# 母音変異の複数形を示す語の単数形の頻度(cf. 「#708. Frequency Sorter CGI」([2011-04-05-1]) の例では lemma 検索だった)
select * from bnc where word in ("foot", "goose", "louse", "man", "mouse", "tooth", "woman") and pos = "nn1" order by freq desc
# 母音変異の複数形の頻度
select * from bnc where word in ("feet", "geese", "lice", "men", "mice", "teeth", "women") and pos = "nn2"
# POSでまとめて頻度の高い順に(話し言葉 'demog')
select pos, sum(freq) from demog group by pos order by sum(freq) desc
# 最も広く多く使われる名詞
select * from variances where pos like "n%" order by variance desc limit 100
# 最も広く多く使われる形容詞
select * from variances where pos like "aj%" order by variance desc limit 100
なお,見出し語化されている頻度表 (lemmatised list) については,頻度にして800回以上現われる,上位6318位までの見出し語のみに限定されており,その検索ツールは「#708. Frequency Sorter CGI」 ([2011-04-05-1]) として実装してある.関連して,「#956. COCA N-Gram Search」 ([2011-12-09-1]) も参照.
2012-11-04 Sun
■ #1287. 動詞の強弱移行と頻度 [frequency][analogy][verb][conjugation][lexical_diffusion][statistics]
昨日の記事「#1286. 形態音韻変化の異なる2種類の動機づけ」 ([2012-11-03-1]) で紹介した Hooper の論文では,調査の1つとして動詞の強弱移行(強変化動詞の弱変化化)が取り上げられていた.Hooper の議論は単純明快である.強弱移行は類推による水平化 (analogical leveling) の典型例であり,頻度の低い動詞から順に移行を遂げてきたのだという.
Hooper が調査対象とした動詞は古英語の強変化I, II, III類に由来する動詞のみであり,その現代英語における頻度情報については Kučera and Francis の頻度表が参照されている.頻度計算は lemma 単位での綴字のみを基準とした拾い出しであり,drive, ride などの語(下表で * の付いているもの)について品詞の区別を考慮していない荒削りなものだ.また,過去千年以上にわたる言語変化を話題にしているときに,現代英語における頻度のみを参照してよいのかという問題([2012-09-21-1]の記事「#1243. 語の頻度を考慮する通時的研究のために」)についても楽観的である (99) .全体として,解釈するのに参考までにという但し書きが必要だが,以下に Hooper (100) の表を見やすく改変したものを掲げよう.
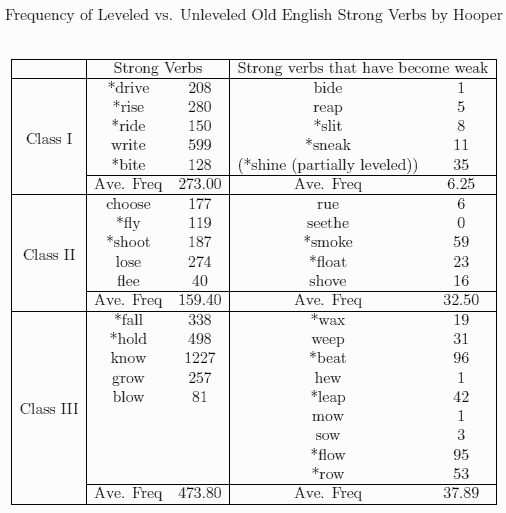
確かにこのように見ると,強弱移行を経た動詞は全体として頻度が相対的にずっと低いことがわかる.関連して,keep, *leave, *sleep や *creep, *leap, weep について,前者3語が伝統的な過去形を保持しているのに対して,後者3語には周辺的に creeped, leaped, weeped の異形も確認されるという.前者の頻度はそれぞれ 531, 792, 132 に対して後者はそれぞれ 37, 42, 31 だという (Hooper 100) .参考までにとはいっても,傾向としては明らかのように思われる.
動詞の強弱移行は英語史において基本的な話題であり,本ブログでも「#178. 動詞の規則活用化の略歴」 ([2009-10-22-1]) ,「#527. 不規則変化動詞の規則化の速度は頻度指標の2乗に反比例する?」 ([2010-10-06-1]) ,「#528. 次に規則化する動詞は wed !?」 ([2010-10-07-1]) などで触れてきたが,案外とわかっていないことも多い.今後の詳細な研究が俟たれる.
・ Hooper, Joan. "Word Frequency in Lexical Diffusion and the Source of Morphophonological Change." Current Progress in Historical Linguistics. Ed. William M. Christie Jr. Amsterdam: North-Holland, 1976. 95--105.
2012-11-03 Sat
■ #1286. 形態音韻変化の異なる源 [phonetics][frequency][causation][neogrammarian][analogy][verb][conjugation][lexical_diffusion]
音韻変化と語の頻度との関係については,Phillips の研究を紹介しながら,「#1239. Frequency Actuation Hypothesis」 ([2012-09-17-1]) や「#1242. -ate 動詞の強勢移行」 ([2012-09-20-1]) で取り上げてきた.「#1265. 語の頻度と音韻変化の順序の関係に気づいていた Schuchardt」 ([2012-10-13-1]) で触れたように,純粋に音声学的な変化は高頻度語から始まるということは早くも19世紀から指摘されていたが,逆に類推作用 (analogy) の関わる形態音韻的な変化は低頻度語から始まるということも,ほぼ同時期に Herman Paul によって指摘されていた(Hooper 95) .
Hooper は,1984年の論文で,語の頻度という観点から,純然たる音声変化と考えられる現代英語における schwa-deletion (memory などの第2母音)と類推による水平化と考えられる動詞の弱変化化を調査し,この2項対立 "phonetic change tends to affect frequent words first, while analogical leveling tends to affect infrequent words first" (101) を支持した.Phillips はこの単純な2項対立によっては説明できない例のあることを示しているが,この対立を議論の出発点とすることは今でも妥当だろう.
このように頻度と音韻変化の関係にこだわっているように見える Hooper だが,実のところ,話者は語の頻度情報にアクセスできないはずだと考えている (102) .
I do not think the relative frequency of words is a part of native speaker competence, so I would not propose to make the rule sensitive to word frequency.
それでも語の頻度と音韻変化の進行順序に相関関係があることを認め続けるのであれば,両者の接点は,話者の言語能力ではなく言語運用のなかにあるということになるのだろうか.Hooper は子供の言語獲得に答えを見つけようとしているようだ.
語の頻度と音韻変化の順序に関する議論のもつ理論的な意義は,(形態)音韻変化には源の異なる複数の種類があり得ることが示唆される点にある.変化の順序が異なるということは,おそらく変化のメカニズムが異なるということであり,変化の源が異なるということではないか.そうだとすれば,変化の順序がわかれば,変化の動機づけもわかることになる.従来はそのような源の異なる変化に「純然たる音声変化」や「類推的な形態音韻変化」というラベルを貼り付けてきたが,今後はより細かい分類が必要だろう.Hooper (103) の結語を引いておきたい.
. . . if it turned out that vowel shifts and some other phonetic changes affect infrequent forms before frequent forms, then we would have an interesting indication that phonetic changes arise from different sources, and furthermore, if my hypotheses are correct, a way of determining which types of changes are traceable to which source. Thus it appears that lexical diffusion, studied in terms of word frequency, may turn up some interesting evidence concerning the source of morpho-phonological change. (103)
・ Hooper, Joan. "Word Frequency in Lexical Diffusion and the Source of Morphophonological Change." Current Progress in Historical Linguistics. Ed. William M. Christie Jr. Amsterdam: North-Holland, 1976. 95--105.
・ Phillips, Betty S. "Word Frequency and the Actuation of Sound Change." Language 60 (1984): 320--42.
・ Phillips, Betty S. "Word Frequency and Lexical Diffusion in English Stress Shifts." Germanic Linguistics. Ed. Richard Hogg and Linda van Bergen. Amsterdam: John Benjamins, 1998. 223--32.
2012-10-13 Sat
■ #1265. 語の頻度と音韻変化の順序の関係に気づいていた Schuchardt [frequency][lexical_diffusion][history_of_linguistics][analogy][creole][neogrammarian]
語の頻度と語彙拡散 (lexical diffusion) の進行順序の関係については,[2012-09-17-1], [2012-09-20-1], [2012-09-21-1]の各記事で扱ってきた.19世紀の青年文法学派 (Neogrammarians) によれば,音韻変化は "phonetically gradual and lexically abrupt" であるということが常識だったが,近年の語彙拡散の研究により,音韻変化にも形態変化に典型的に見られる "lexically gradual" の過程が確認されるようになってきている.形態であれ音韻であれ,言語変化のなかには徐々に波及してゆくものがあるという知見は,言語変化の原理としての類推作用 (analogy) とも相性がよく,音韻変化と類推を完全に対置していた Neogrammarians がもしこのことを知ったら相当の衝撃を受けたことだろう.
徐々に進行する音韻変化が確認される場合,それがどのような順序で進行するのかという点が問題となる.そこで,語の頻度という観点が提案されているのだが,この観点からの研究はまだ緒に就いたばかりである.ところが,観点ということだけでいえば,その提案は意外と早くなされていた.青年文法学派に対抗した Hugo Ernst Maria Schuchardt (1842--1927) は1885年という早い段階で,語の頻度と音韻変化の順序に目を付けていたのだ.以下は,Phillips (321) に掲載されている Schuchardt からの引用(英訳)である.
The greater or lesser frequency in the use of individual words that plays such a prominent role in analogical formation is also of great importance for their phonetic transformation, not within rather small differences, but within significant ones. Rarely used words drag behind; very frequently used ones hurry ahead. Exceptions to the sound laws are formed in both groups.
Neogrammarian 全盛の時代において,語の頻度と音韻変化の順序に注目した Schuchardt の炯眼に驚かざるをえない.この識見は,当時,生きた言語の研究における最先端の場であり,ラテン語を母体とする資料の豊富さで確かな基盤のあったロマンス語学の分野に彼が身を投じていたことと関係する.彼は,現実の資料には Neogrammarian の音法則に反する例が豊富にあることをはっきりと認識しており,音法則による言語史の再建だけでは言語の真の理解は得られないことを痛感していた.語族という考え方にも否定的で,言語に混合や波状拡散の過程を想定していた.特に彼の混交言語への関心は果てしなく,その先駆的な研究が評価されるようになったのは,1世紀も後,クレオール語研究の現われだした1960年代のことである.
Schuchardt がこのような言語思想をもっていたことを知れば,上記の引用も自然と理解できるだろう.Schuchardt とクレオール学の発展との関係については,田中 (188--96) が詳しい.
・ Phillips, Betty S. "Word Frequency and the Actuation of Sound Change." Language 60 (1984): 320--42.
・ Schuchardt, Hugo. Über die Lautgesetze: Gegen die Junggrammatiker. 1885. Trans. in Shuchardt, the Neogrammarians, and the Transformational Theory of Phonological Change. Ed. Theo Vennemann and Terence Wilbur. Frankfurt: Altenäum, 1972. 39--72.
・ 田中 克彦 『言語学とは何か』 岩波書店〈岩波新書〉,1993年.
2012-09-21 Fri
■ #1243. 語の頻度を考慮する通時的研究のために [frequency][corpus][representativeness]
昨日の記事「#1242. -ate 動詞の強勢移行」 ([2012-09-20-1]) や「#1239. Frequency Actuation Hypothesis」 ([2012-09-17-1]) で取り上げた Phillips の研究のように,語の頻度を考慮する言語変化の研究には多大な関心を寄せているが,方法論上の素朴な疑問として,ある語の頻度それ自体が通時的に変わるという事実をどのように考えればよいのかという問題がある.ある特定の語ではなく,語彙の全体あるいは部分集合を考える場合には,1--2世代の時差は大きな問題ではないだろうと直感される.だが,1世紀の時差ではどうか,2世紀ではどうか,と考えると,どこまで直感に頼れるものか,はなはだ心許ない.Phillips (225--26) は,この問題について次のように楽観している.
The words' frequencies are based on present-day English, but the general pattern of relative frequencies probably holds for the English in our data base (1755--1993) as well. For example, I would be very surprised if the 3-syllable verbs with CELEX frequencies over 100 --- concentrate, demonstrate, illustrate, contemplate, compensate, designate, and alternate --- were not also much more common in 1755 than those with frequencies of 0 --- altercate, auscultate, condensate, defalcate, eructate, exculpate, expuergate, extirpate, fecundate, etc.
2世紀余の時差を相手にしていながら,頻度が100回以上の語と0回の語を比べるというのは大雑把にすぎるように思われる.確かに,Phillips は実際の頻度分析でも101回以上,10--100回,1--10回という荒い区分を用いており,大雑把な頻度情報を大雑把なままに用いる慎重さは示している.しかし,もし特に10--100回辺りの中頻度レベルの語をより詳細に調べようとするのであれば,2世紀の間にそれなりに頻度が変化している可能性はある.Phillips ならずとも,頻度を利用した通時的研究に関心をもつ誰もが突き当たるはずの問題だ.
すぐに思いつく単純な解決案は,各時代を代表するできるだけ大きなコーパスを利用して頻度表を作成することである.案としては単純だが,実際に遂行するのは一手間も二手間もかかる.綴字がある程度固定した近代英語であれば,コーパスを用意して頻度表の自動作成ができそうだが,中英語以前では綴字や語形の variation ゆえに lemmatise されていない限りは見出し語単位での頻度表作成は難航しそうだ.また,時代が古くなればなるほど,コーパスに含まれるテキストの representativeness の問題は深刻になる.ただし,荒っぽい頻度表でも,ないよりはあるほうがよい.いずれ作成してみたいと思っている.あるいは,時代によってはすでにあるだろうか?
なお,引用にある CELEX という単語データベースは,現代英語の語や形態に関する量的な研究でよく使われているものである.詳細は,CELEX2 を参照.また,頻度と通時態の関係については,[2012-05-03-1]の記事「#1102. Zipf's law と語の新陳代謝」を参照.
・ Phillips, Betty S. "Word Frequency and Lexical Diffusion in English Stress Shifts." Germanic Linguistics. Ed. Richard Hogg and Linda van Bergen. Amsterdam: John Benjamins, 1998. 223--32.
2012-09-20 Thu
■ #1242. -ate 動詞の強勢移行 [frequency][lexical_diffusion][stress][suffix][-ate]
[2012-09-17-1]の記事「#1239. Frequency Actuation Hypothesis」で,接尾辞 -ate をもつ動詞の強勢が移動してきているという言語変化に触れた.名前動後 (diatone と同様に現在も進行中の強勢移行であり,語彙拡散 (lexical_diffusion) の例としても注目に値する.
この移行については Phillips が語彙拡散の観点から研究しているが,OED の "contemplate, v" にまとまった解説があるので,それを紹介しよう.Danielsson (271--72) でも,OED のこの箇所が触れられている.
In a few rare cases (Shakes., Hudibras) stressed 'contemplate in 16--7th c.; also by Kenrick 1773, Webster 1828, among writers on pronunciation. Byron, Shelley, and Tennyson have both modes, but the orthoepists generally have con'template down to third quarter of 19th c.; since that time 'contemplate has more and more prevailed, and con'template begins to have a flavour of age. This is the common tendency with all verbs in -ate. Of these, the antepenult stress is historical in all words in which the penult represents a short Latin syllable, as ac'celerate, 'animate, 'fascinate, 'machinate, 'militate, or one prosodically short or long, as in 'celebrate, 'consecrate, 'emigrate; regularly also when the penult has a vowel long in Latin, as 'alienate, 'aspirate, con'catenate, 'denudate, e'laborate, 'indurate, 'personate, 'ruinate (L. aliēno, aspīro, etc.). But where the penult has two or three consonants giving positional length, the stress has historically been on the penult, and its shift to the antepenult is recent or still in progress, as in acervate, adumbrate, alternate, compensate, concentrate, condensate, confiscate, conquassate, constellate, demonstrate, decussate, desiccate, enervate, exacerbate, exculpate, illustrate, inculcate, objurgate, etc., all familiar with penult stress to middle-aged men. The influence of the noun of action in -ation is a factor in the change; thus the analogy of ,conse'cration, 'consecrate, etc., suggests ,demon'stration, 'demonstrate. But there being no remonstration in use, re'monstrate, supported by re'monstrance, keeps the earlier stress.
つまり,3音節以上の語においては,歴史的には penult の構成に応じて強勢が penult か antepenult に落ちた.具体的には,penult に子音群が現われる場合には,歴史的にはその音節に強勢が落ちた.ところが,近現代英語において,対応する名詞形 -ation の強勢パターンにもとづく類推が働くためか,該当する語の強勢がさらに一つ左へ,antepenult へと移行してきているというのである.
Danielsson や OED には3音節以上の語についての言及しかないが,Phillips は2音節語についても調査した.興味深いことに,2音節語の -ate 動詞(ただし penult が閉音節のもの)では,正反対の方向の強勢移行が起こっているという.frustrate, dictate, prostrate, pulsate, stagnate, truncate などの語では,歴史的には penult に強勢が落ちたが,現代英語にかけて ultima に強勢が落ちる異形が現われてきている(最初の3語については定着した).そして,いずれの方向の強勢移行についても,Phillips は頻度の高いものから順に変化してきているという事実を突き止めた (226--28) .
これは頻度の低いものから順に変化してきたと Phillips の主張する名前動後の例と,対立する結果である.頻度と語彙拡散の進行順序との問題に,新たな一石が投じられている.
・ Phillips, Betty S. "Word Frequency and Lexical Diffusion in English Stress Shifts." Germanic Linguistics. Ed. Richard Hogg and Linda van Bergen. Amsterdam: John Benjamins, 1998. 223--32.
・ Danielsson, Bror. Studies on the Accentuation of Polysyllabic Latin, Greek, and Romance Loan-Words in English. Stockholm: Almqvist & Wiksell, 1948.
2012-09-17 Mon
■ #1239. Frequency Actuation Hypothesis [frequency][phonetics][language_change][lexical_diffusion][stress][diatone][-ate]
語彙拡散 (lexical diffusion) として進行する音韻変化の道筋や順序が語の頻度と相関しているらしいことは,古くは19世紀末から指摘されてきた.実際に,Phillips (1984: 321) に挙げられているように,頻度の高い語から順に変化を遂げるという音韻変化は数々例証されてきた.一方で,頻度の低い語から順に変化を遂げる例も確認されており,頻度と語彙拡散の順序の関係については,いまだに疑問が多い.この問題について,Phillips は,南部アメリカ英語における glide deletion ,中英語の unrounding ,近代英語の名前動後(diatonic stress shift; diatone の記事を参照)という,頻度の低い順に進行するとされる3つの音韻変化を取り上げて,"Frequency Actuation Hypothesis" を提唱した.これは,"physiologically motivated sound changes affect the most frequent words first; other sound changes affect the least frequent words first" (1984: 336) というものである(前者は surface phonetic form に働きかける変化,後者は underlying phonetic form に働きかける変化を指す).
しかし,Phillips は1998年の -ate で終わる動詞の強勢位置の移動に関する研究において,この生理的に動機づけられていない音韻変化が,予想されるように頻度の低い順には進まず,むしろ頻度の高い順に進んでいることを明らかにした.そこで,改訂版 Frequency Actuation Hypothesis を唱えた.
[F]or segmental changes, physiologically motivated sound changes affect the most frequent words first; other sound changes affect the least frequent words first. For suprasegmental changes, changes which require analysis (e.g., by part of speech or by morphemic element) affect the least frequent words first, whereas changes which eliminate or ignore grammatical information affect the most frequent words first. (1998: 231)
つまり,強勢の移動のような超分節の音韻変化に関しては,話者による分析が入るか入らないかで,頻度と順序の関係が逆転するというわけである.なぜそうなるのかについて,Phillips は Bybee (117--19) の "lexical strength" という考え方を持ち出している.
私は必ずしもこの議論に納得していない.また,Phillips の主張とは異なり,名前動後が頻度の高い順に進行したことを示すデータも独自に得ている.頻度と変化の順序についての研究は緒に就いたばかりであり,研究の余地は多分に残されている.
・ Phillips, Betty S. "Word Frequency and the Actuation of Sound Change." Language 60 (1984): 320--42.
・ Phillips, Betty S. "Word Frequency and Lexical Diffusion in English Stress Shifts." Germanic Linguistics. Ed. Richard Hogg and Linda van Bergen. Amsterdam: John Benjamins, 1998. 223--32.
・ Bybee, Joan L. Morphology: A Study of the Relation between Meaning and Form. Amsterdam: John Benjamins, 1985.
2012-09-05 Wed
■ #1227. 情報理論と意味作用 [information_theory][frequency][sign][semantics]
「#1108. 言語記号の恣意性,有縁性,無縁性」 ([2012-05-09-1]) や「#1110. Guiraud による言語学の構成部門」 ([2012-05-11-1]) で参照した意味論学者の Guiraud は,情報理論 (information_theory) の言語学への応用にも関心が深く,言語体系や言語記号のもつ余剰性,頻度,費用などの問題を考察している.
1954年の論文を読み,多くの示唆的な洞察が得られた.例えば,シニフィアン,シニフィエ,頻度,長さの関係について次のように述べられている (128) .最初はシニフィエがシニフィアンを「選ぶ」,言い換えれば最も短いシニフィアンが最も頻度の高いシニフィエに割り当てられる.それから,シニフィアンが語の用法を「駆動し」,それに「変更を加える」.
このシニフィアンとシニフィエの相互関係が含意するのは,何らかの理由で頻度や意味や形態が変化してゆくと,それまで保たれていた両者の間の均衡が崩れるために,記号体系の調整機能が発動し,均衡を取り戻そうとするということである.別の見方をすれば,言語変化は,情報伝達の効率が最大限に保たれ得る限りにおいて起こるということになる.言語体系も情報体系の1つである以上,情報に関わる一般原理である「効率」に従わざるを得ないという結論になろう.
情報理論では「効率」が論じられ,「意味」は捨象されるのが普通だが,意味論の専門家としての Guiraud は,次のような方法で情報理論の知見を意味作用の問題に活かそうと考えている.客観的に数字で表わされる頻度と長さという指標を利用して,目に見えないシニフィアンとシニフィエの関係を探れるのではないか.
La relation coût/information (ou forme/fréquence) traduit objectivement ces rapports entre le signe et le concept et permet de poser en termes objectifs le problème de la signification. (128)
費用/情報(あるいは形態/頻度)の関係はシニフィアンとシニフィエの間のこれらの関係を客観的に表わすものであり,意味作用の問題を客観的に提示することを可能にしてくれる.
・ Guiraud, P. "Langage et communication. Le substrat informationnel de la sémantisation." Bulletin de la société de linguistique de Paris 50 (1954): 119--33.
2012-06-29 Fri
■ #1159. MRC Psycholinguistic Database Search [cgi][web_service][lexicology][frequency][statistics]
昨日の記事[2012-06-28-1]で紹介した英語語彙データベース MRC Psycholinguistic Database を,本ブログ上から簡易検索するツールを作成した.実際には検索ツールというよりは,MRC Psycholinguistic Database を用いると,こんなことができるということを示すデモ版にすぎず,出力結果は10行のみに限定してある.本格的な使用には,昨日示したページからデータベースと検索プログラムをダウンロードするか,ウェブ上のインターフェース (Online search (answers limited to 5000 entries) or Online search (limited search capabilities)) よりどうぞ.
以下,使用法の説明.SQL対応で,テーブル名は "mrc2" として固定.フィールドは以下の27項目:ID, NLET, NPHON, NSYL, K_F_FREQ, K_F_NCATS, K_F_NSAMP, T_L_FREQ, BROWN_FREQ, FAM, CONC, IMAG, MEANC, MEANP, AOA, TQ2, WTYPE, PDWTYPE, ALPHSYL, STATUS, VAR, CAP, IRREG, WORD, PHON, DPHON, STRESS.各パラメータが取る値の詳細については,原データファイルの仕様を参照のこと(仕様中に示されている各種統計値はそれ自身が非常に有用).select 文のみ有効.以下に,典型的な検索式を例として載せておく.
# 文字数で語彙を分別
select NLET, count(NLET) from mrc2 group by NLET;
# 音素数で語彙を分別
select NPHON, count(NPHON) from mrc2 group by NPHON;
# 音節数で語彙を分別
select NSYL, count(NSYL) from mrc2 group by NSYL;
# -ed で終わる形容詞を頻度順に
select WORD, K_F_FREQ from mrc2 where WTYPE = 'J' and WORD like '%ed' order by K_F_FREQ desc;
# 2音節の名詞,形容詞,動詞を強勢パターンごとに分別 (「#814. 名前動後ならぬ形前動後」 ([2011-07-20-1]) 及び「#801. 名前動後の起源 (3)」 ([2011-07-07-1]) を参照)
select WTYPE, STRESS, count(*) from mrc2 where NSYL = 2 and WTYPE in ('N', 'J', 'V') group by WTYPE, STRESS;
# <gh> の綴字で終わり,/f/ の発音で終わる語
select distinct WORD, DPHON from mrc2 where WORD like '%gh' and DPHON like '%f';
# 不規則複数形を頻度順に
select WORD, K_F_FREQ from mrc2 where IRREG = 'Z' and TQ2 != 'Q' order by K_F_FREQ desc;
# 馴染み深く,具体的な意味をもつ語
select distinct WORD, FAM from mrc2 where FAM > 600 and CONC > 600;
# イメージしやすい語
select distinct WORD, IMAG from mrc2 order by IMAG desc limit 30;
# 「有意味」な語
select distinct WORD, MEANC, MEANP from mrc2 order by MEANC + MEANP desc limit 30;
# 名前動後など品詞によって強勢パターンの異なる語
select WORD, WTYPE, DPHON from mrc2 where VAR = 'O';
2012-06-28 Thu
■ #1158. MRC Psycholinguistic Database [web_service][lexicology][frequency][statistics]
心理言語学の分野ではよく知られた英語の語彙データベースのようだが,「#1131. 2音節の名詞と動詞に典型的な強勢パターン」 ([2012-06-01-1]) と「#1132. 英単語の品詞別の割合」 ([2012-06-02-1]) で参照した Amano の論文中にて,その存在を知った.MRC Psycholinguistic Database は,150837語からなる巨大な語彙データベースである.各語に言語学的および心理言語学的な26の属性が設定されており,複雑な条件に適合する語のリストを簡単に作り出すことができるのが最大の特徴だ.特定の目的をもった心理言語学の実験に用いる語彙リストを作成するなどの用途に特に便利に使えるが,検索パラメータの組み合わせ方次第では,容易に語彙統計学の研究に利用できそうだ.
パラメータは実に多岐にわたる.文字数,音素数,音節数の指定に始まり,種々のコーパスに基づく頻度の範囲による絞り込みも可能.心理言語学的な指標として,語の familiarity, concreteness, imageability, meaningfulness なども設定されている.品詞などの統語カテゴリーはもちろん,接頭辞,接尾辞,略語,ハイフン形などの形態カテゴリーの指定もできる.発音や強勢パターンの指定にも対応している.組み合わせによって,およそのことができるのではないかと思わせる精緻さである.
全データベースと検索プログラムはこちらからダウンロードできるが,プログラムをコンパイルするなど面倒が多いので,ウェブ上のインターフェースを用いるのが便利である.2つのインターフェースが用意されており,それぞれ機能は限定されているが,通常の用途には十分だろう.
・ Online search (answers limited to 5000 entries): パラメータの細かい指定が可能だが,出力結果は5000語までに限られる.
・ Online search (limited search capabilities): 出力結果の数に制限はないが,言語学的なパラメータの細かい指定(綴字や発音のパターンの直接指定など)はできない.
・ Amano, Shuichi. "Rhythmic Alternation and the Noun-Verb Stress Difference in English Disyllabic Words." 『名古屋造形大学名古屋造形芸術大学短期大学部紀要』 15 (2009): 83--90.
Powered by WinChalow1.0rc4 based on chalow