2012-05-04 Fri
■ #1103. GSL による Zipf's law の検証 [lexicology][statistics][frequency][zipfs_law][corpus]
[2012-05-02-1], [2012-05-03-1]の記事で取り上げてきた Zipf's law を検証(というよりは体験)するために,General Service List (GSL) の最頻2000語余りのデータを利用して計算してみた(データファイルはこちら).
![]()
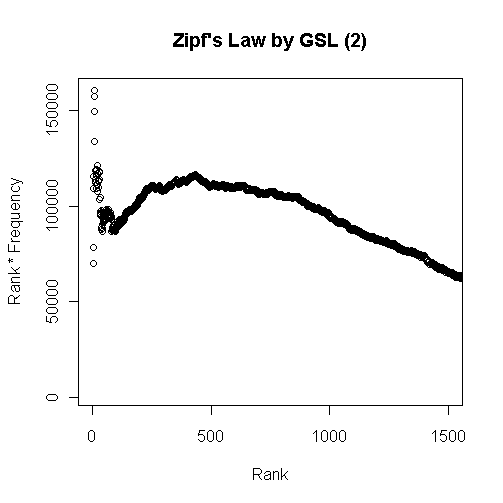
最初のグラフは頻度順位と頻度を掛け合わせたグラフで,頻度順で100位ほどまでの語を対象とした.以下はひたすら漸減してゆくのみなので省略.累積頻度のグラフを作成するまでもなく,最頻の数十語ほどで延べ語数のほとんどを覆ってしまう様子がよくわかる.
次のグラフは,Zipf's law によると定数になるとされる頻度順位と頻度の積を縦軸にとったものである.上位数十語までは「定数」は上下に大きく揺れて安定しないが,以後1000語ぐらいまでは,緩やかな増減はあるものの,落ち着く.その後のグラフ外ではひたすら漸減を続ける.したがって,「定数」を云々できるのは大目に見ても上位1000語ぐらいまでだろう.
これを法則と呼ぶのはあまりに外れていると考えるか,統計的傾向がよく出ているととらえるかは,観察者の見方ひとつである.Zipf's law における「定数」は「およそ定数」と解釈するのが暗黙の了解だが,「およそ」の幅がどの程度であるのかは明示されていない.また,Zipf's law が主張しているのと異なり,グラフの線は頻度をとるコーパスのサイズにも依存するようだ.
2012-05-03 Thu
■ #1102. Zipf's law と語の新陳代謝 [information_theory][frequency][statistics][zipfs_law][shortening][language_change]
昨日の記事[2012-05-02-1]で Zipf's law について概説した.Zipf's law には派生した「法則」が多くあり,その1つに,[2012-04-22-1]の記事「#1091. 言語の余剰性,頻度,費用」でも指摘した「言語要素は,頻度が高ければ音形が短い」というものがある.これを,より動的に,通時的に表現すると「言語要素は,頻度が高くなれば音形が短くなる」となる.ある語の頻度が高くなってゆくと,ある程度の遅延はあるものの,その音形が短くされてゆく傾向のあることは,私たちも経験的によく知っていることである.「#878. Algeo と Bauer の新語ソース調査の比較」([2011-09-22-1]) や「#879. Algeo の新語ソース調査から示唆される通時的傾向」([2011-09-23-1]) で見たとおり,現代英語の新語ソースとして短縮 (shortening) による語形成が増加しており,例には事欠かない.
この Zipf's law の派生法則のもつ共時的意義と通時的意義を合わせて考えると,語の頻度と長さによって,それが老いゆく語 (senescent word) なのか,生まれつつある語 (nascent word) なのかを区別できるという可能性が生じる.Zipf 著 Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology の書評を著わした Chao (399) より,関連箇所を引用しよう.
A very interesting application of the tool analogy is that of senescent and nascent tools in connection with the Principle of Economical Specialization. Reasoning from tool efficiency yields the result that 'whenever we find a tool (or word) whose magnitude is smaller than that of its neighbors in the frequency range, we may conclude that the tool (or word) of below-average size is an older tool (or word) whose usage is on the decrease (hereinafter we shall call this a senescent tool)', and 'whenever we find a tool (or word) whose magnitude is above average for its frequency, we may conclude not only that it is a newer tool (or word), but that its usage may well be directed toward an increase (hereinafter we shall call this a nascent tool)' (72). The application to words is verified to a fair degree for English of various periods (111). By regarding all behavior as work and words as tools, the analogy becomes a case and the qualifier 'or word' can be omitted.
音形の比較的短いある単語 A を考える.Zipf's law によれば,A は比較的頻度の高い語だと予想されるが,実際には同程度の頻度を示す他の多くの語に比べると音形が短すぎたとする.この場合,おそらく A はさかりを過ぎて頻度が徐々に低まってきた senescent word と考えてよいだろう.反対に,音形の比較的長いある単語 B を考える.Zipf's law によれば,B は比較的頻度の低い語だと予想されるが,実際には同程度の頻度を示す他の多くの語に比べると音形が長すぎたとする.この場合,おそらく B はこれから頻度がますます増してゆき,短縮を起こしてゆくと予想される nascent word と考えてよいだろう.これは,Zipf's law に,冒頭に述べた時間的遅延とを掛け合わせた応用法則といってよい.
通常 Zipf's law は静的で共時的な統計的法則ととらえられているが,動的で通時的な観点から,語の新陳代謝の法則として再解釈してみるとおもしろい.
・ Chao, Y. R. "Review of Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology by George Kingsley Zipf." Language 26 (1950): 394--401.
2012-05-02 Wed
■ #1101. Zipf's law [information_theory][frequency][statistics][language_change][zipfs_law][shortening][pragmatics][zipfs_law]
##1089,1090,1091,1098 の記事で,情報理論 (information theory) が言語学に与えてくれる知見について,いくつか見てきた.情報理論からの貢献として,最もよく知られているものの1つに,アメリカの言語学者 George Kingsley Zipf (1902--50) が1949年に Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology において提唱した Zipf's law (ジップの法則)がある.語の頻度についての経験的な法則であり,語の頻度を f とし,その頻度の順位を r とすると,その積 C はほぼ定数となるという.
r × f = C
この法則は,言語,テキストの主題,著者,その他の言語的な変数にかかわらず成り立つとされるが,実際には頻度が最高および最低の語群については誤差の大きいことがわかっており,信頼性は高くないとして批判も多い.また,r (頻度順位)は当然ながら f (頻度)に依存しており,f が増えれば r が減るのは自明であるから,その積が近似値をとるということは驚くべき帰結ではない,一種のトートロジーであるという批判がある.しかし,経験的事実に照らして法則とまではいわずとも傾向をよく表わしているということはでき,これを明示的に指摘した意義は大きい.
Zipf's law の波及効果は多岐にわたる.例えば,この法則によれば,使用頻度の高い語からその使用頻度の累計を求めて行くと比較的少数の語で延べ語数の大部分を占めることから,学習基本語彙の設定に根拠を与えるものとなる.また,この法則に適合しない頻度分布を示す語彙があるとすれば,他の特殊な要因が関与している可能性が疑われるとされる(少数の語の頻度があまりに高すぎれば語彙の貧弱化が生じていると診断されるし,頻度の低いはずの語が高頻度で用いられている場合には爆発的な新造語彙や精神分裂症が原因と想定される等々).
Zipf's law は,人間の行動を司るとされるより大きな原則,the Principle of Least Effort (最小努力の原則)の一部であり,その言語への応用は,上記の最もよく知られた頻度と頻度順の関係の公式化のみならず,他の公式の提案にも及んでいる.例えば,語の頻度と語の長さは反比例の関係にある,というものもある.最頻語は単音節であることが多いという事実(音節数の分布調査については ##348,349,355 を参照)や,頻度が高くなると頭字語などのように短縮・省略されることが多いという事実も,この公式で説明される.ほかには,ある頻度範囲とそれに属する語の数の関係を表わす公式,調音の難しい音素は頻度が低いとする原則など,派生した法則は数多い.語用論の cooperative principle (協調の原則)における量の格律「(その状況において)必要とされている(だけの)情報を与えよ」とも関与するだろう."effort" の定義などの難しい問題が残っており,また最小努力が人間の行動を司る唯一の原則であるとは考えることもできないが,真理の一面をついたものとして重要な学説であることは間違いない.
なお,諸文献では,上記のいずれの原則も Zipf's law として言及されることがあり,また Zipf's laws と複数形でまとめられたり,the Principle of Least Effort と総括されたりすることもあるので注意が必要である.Zipf の著書の書評としては Chao を参照.類似の統計的法則については,Crystal (86--87) を参照.
・ Chao, Y. R. "Review of Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology by George Kingsley Zipf." Language 26 (1950): 394--401.
・ Crystal, David. The Cambridge Encyclopedia of Language. 2nd ed. Cambridge: CUP, 1997.
2012-04-22 Sun
■ #1091. 言語の余剰性,頻度,費用 [redundancy][information_theory][frequency][shortening][grammaticalisation][idiom][intensifier][language_change]
本ブログでも度々取り上げている André Martinet (1908--99) は,情報理論の知見を言語学に応用し,独自の地平を開いた構造言語学者である.[2012-04-20-1], [2012-04-21-1]の記事で,言語の余剰性 (redundancy) の問題に触れてきたが,Martinet は余剰性と関連させて確率 (probability) ,情報 (information) ,頻度 (frequency) ,費用 (cost) といった概念をも導入し,これらの関係のなかに言語変化の原因を探ろうとした.以下は,これらの用語を導入した後の一節である(拙訳つきで).
Ce qu'il convient de retenir de tout ceci pour comprendre la dynamique linguistique se ramène aux constatations suivantes : il existe un rapport constant et inverse entre la fréquence d'une unité et l'information qu'elle apporte, c'est-à-dire, en un certain sens, son efficacité ; il tend à s'établir un rapport constant et inverse entre la fréquence d'une unité et son coût, c'est-à-dire que représente d'énergie consommée chaque utilisation de cette unité. Un corollaire de ces deux constatations est que toute modification de la fréquence d'une unité entraîne une variation de son efficacité et laisse prévoir une modification de sa forme. Cette dernière pourra ne se produire qu'à longe échéance, car les condition réelles du fonctionnement des langues tendent à freiner les évolutions. (189--90)
言語の力学を理解するために,このこと全体について理解すべきことは,次の確認事項である.ある単位の頻度とそれがもつ情報(すなわちある意味ではその効果)のあいだには一定にして反比例の関係がある;それは,ある単位の頻度とその費用(すなわちその単位を使用することで消費されるエネルギー)のあいだの一定にして反比例の関係となる傾向がある.この2つの確認事項の当然の帰結として,ある単位の頻度が変わればその効果も変化するし,その形態の変化も予想されることになる.この後者の変化はあくまで長期間をかけて生じるものである.というのは,言語作用の現実の状況は発達を抑制する傾向があるからだ.
Martinet は,引用した節よりも前の箇所で,余剰性が高いということは予測可能性が高いということであり,それは言語要素の出現確率あるいは頻度とも密接に関連するということを論じている.一般に,言語要素は頻度が高ければ余剰性も高く,情報価値は低い: "plus une unité (mot, monème, phonème) est fréquente, moins elle est informative" (188) .そして,ここに費用という要素を持ち込むことによって,新たな洞察が得られた.話者にとって,頻度が高ければ高いほど,その1回の発音に必要とされるエネルギーの量は少ないほうが都合がよい.多くのエネルギーを要する発音を何度も繰り返すのは不経済だからだ.逆に,頻度の低い表現は,たとえ発音に大きなエネルギーが必要だとしてもあまり困らない.いずれにせよ,発音する機会が稀だからだ.
このように,「費用」を発音にかかるエネルギー量と解釈する場合,厳密には個々の音の発音がどのくらいの費用を要するかを知る必要があるが,その計測は難しい.しかし,仮にすべての単音の発音が同じ程度の費用を要すると仮定すれば,特定の表現に要する費用はその音形の長さに依存するはずである.費用を単純に音形の長さと同値とすれば,次の関係が想定できる:「言語要素は,頻度が高ければ音形が短い」.これを言語変化に当てはめれば「言語要素は,頻度が高くなれば音形が短くなる」となろう.
頻度と費用の反比例の関係は,経験的によく理解できる.よく使われる語句は発音においても表記においても短縮・省略される傾向がある.場合によっては,短縮・省略の究極の結末として,無に帰すことすらある.文法的な慣用表現が短縮した上で固定化する例もよく見られ,これは文法化 (grammaticalisation) として扱われる話題にほかならない.また,[2012-01-14-1]の記事で取り上げた「#992. 強意語と「限界効用逓減の法則」」も,頻度と費用の関係という観点からとらえなおすことができるだろう.
ただし,上の引用の最後にある通り,頻度と費用の関係から言語変化を説明しようとする際には,時間差を考慮する必要がある.ある語の頻度が増してきてからその語形が短縮されるまでには,当然,ある程度の時間が必要だからだ.また,頻度と費用の負の相関関係は,あくまで緩やかなものであることにも注意しておく必要がある.上の一節に先行する標題が "Laxité du rapport entre fréquence et coût" (頻度と費用の関係の緩やかさ)であることを付け加えておこう.
・ Martinet, André. Éléments de linguistique générale. 5th ed. Armand Colin: Paris, 2008.
2012-02-13 Mon
■ #1022. 英語の各音素の生起頻度 [phoneme][frequency][statistics]
昨日の記事「#1021. 英語と日本語の音素の種類と数」 ([2012-02-12-1]) で,音素一覧を掲げた.では,英語の音素のなかでもっとも多く使われる音素は何だろうか.そして,もっとも使われないのは何だろうか.
その統計をとった研究がある.Fry, D. B. "The Frequency of Occurrence of Speech Sounds in Southern English." Archives Néerlandaises de Phonétique Expérimentale 20 (1947) で出された統計が Crystal (239, 242) に掲載されているので,ここに再掲する.一定の長さの談話における延べ音素で数えたものである.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | total | ||||
| /iː/ | /ɪ/ | /e/ | /æ/ | /ʌ/ | /ɑː/ | /ɒ/ | /ɔː/ | /ʊ/ | /uː/ | /ɜː/ | /ə/ | /eɪ/ | /aɪ/ | /ɔɪ/ | /əʊ/ | /aʊ, ɑʊ/ | /ɪə/ | /eə/ | /ʊə/ | |||||
| 1.65 | 8.33 | 2.97 | 1.45 | 1.75 | 0.79 | 1.37 | 1.24 | 0.86 | 1.13 | 0.52 | 10.74 | 1.71 | 1.83 | 0.14 | 1.51 | 0.61 | 0.21 | 0.34 | 0.06 | 39.21 | ||||
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | |
| /p/ | /b/ | /t/ | /d/ | /k/ | /g/ | /ʧ/ | /ʤ/ | /f/ | /v/ | /θ/ | /ð/ | /s/ | /z/ | /ʃ/ | /ʒ/ | /h/ | /m/ | /n/ | /ŋ/ | /l/ | /r/ | /w/ | /j/ | |
| 1.78 | 1.97 | 6.42 | 5.14 | 3.09 | 1.05 | 0.41 | 0.60 | 1.79 | 2.00 | 0.37 | 3.56 | 4.81 | 2.46 | 0.96 | 0.10 | 1.46 | 3.22 | 7.58 | 1.15 | 3.66 | 3.51 | 2.81 | 0.88 | 60.78 |
母音が39.21%,子音が60.78%.頻度の高い順にソートすると,以下のようになる.
/ə/ (10.74), /ɪ/ (8.33), /n/ (7.58), /t/ (6.42), /d/ (5.14), /s/ (4.81), /l/ (3.66), /ð/ (3.56), /r/ (3.51), /m/ (3.22), /k/ (3.09), /e/ (2.97), /w/ (2.81), /z/ (2.46), /v/ (2.00), /b/ (1.97), /aɪ/ (1.83), /f/ (1.79), /p/ (1.78), /ʌ/ (1.75), /eɪ/ (1.71), /iː/ (1.65), /əʊ/ (1.51), /h/ (1.46), /æ/ (1.45), /ɒ/ (1.37), /ɔː/ (1.24), /ŋ/ (1.15), /uː/ (1.13), /g/ (1.05), /ʃ/ (0.96), /j/ (0.88), /ʊ/ (0.86), /ɑː/ (0.79), /aʊ, ɑʊ/ (0.61), /ʤ/ (0.60), /ɜː/ (0.52), /ʧ/ (0.41), /θ/ (0.37), /eə/ (0.34), /ɪə/ (0.21), /ɔɪ/ (0.14), /ʒ/ (0.10), /ʊə/ (0.06).
上位9音素までが,弛緩母音あるいは歯・歯茎を用いる音である.最下位の2重母音や摩擦音も覚えておきたい.音声変化を考える上で,このように音素別の頻度を頭に入れておくと役立つことがあるだろう.主要なものだけでも音節別の頻度でこのようなランキング表はないだろうか.
(後記 2012/04/22(Sun):石橋 幸太郎 編 『現代英語学辞典』の "Frequency of occurrence of phonemes" (323--24) に類似した他の統計値あり.)
・ Crystal, David. The English Language. 2nd ed. London: Penguin, 2002.
2011-12-28 Wed
■ #975. 3人称代名詞の斜格形ではあまり作用しなかった異化 [personal_pronoun][dissimilation][homonymic_clash][case][frequency]
昨日の記事「#974. 3人称代名詞の主格形に作用した異化」([2011-12-27-1]) で,子音を違えるという異化作用によって homonymic clash を回避した可能性について論じたが,それは3人称代名詞の主格に限っての議論だった.では,斜格はどうだったかというと,状況は異なっていた.
3人称複数代名詞の th- 形の受容のタイミングが格により異なっていたことは,英語史上,よく知られている.複数主格形 they の受容は初期中英語だが,斜格形の their や them などは後期中英語の Chaucer でも一般的ではなかった.そして,この受容の時間差は,通常,頻度の差と関係していると説明される.主格は斜格に比べて使用頻度が高く,それだけ区別する必要性も大きい.homonymic clash を回避すべき機会が多い分,主格のほうが早く刷新形を受け入れた,というわけだ.
主格と斜格の頻度の差による説明は,3人称複数の th- 形についてなされるのが普通だが,同じ議論は3人称複数以外の代名詞形態についても適用できそうだ.古英語の人称代名詞体系では,昨日取り上げた主格だけではなく,斜格においても homonymy がみられた.例えば,Late West-Saxon 方言の標準的なパラダイム ([2009-09-29-1]) に従えば,his は男性単数属格かつ中性単数属格,him は男性単数与格かつ中性単数与格かつ複数与格,hīe は女性単数対格かつ複数対格であり,衝突の機会は確かにあった.近代英語以降の観点からみれば,結論としてはこれらの衝突も回避されたことになるが,これら斜格での刷新形の受容のタイミングは,主格に比べれば遅かったようである.一例として,中性単数属格の his が its に置換されたのは,[2009-11-11-1]の記事「#198. its の起源」で見たとおり,近代英語になってからだ.
斜格では,中英語期に対格と与格の融合 (syncretism) という一大変化が進行しており,単純に主格の発達と比べることはできない.斜格は,主格にみられるような異化作用によってではなく,格の融合によってそのパラダイムを再編成したといってしかるべきだろう.とはいえ,やはり主格に比べれば衝突が許容されやすい傾向,換言すれば刷新形の受容が(あったとすればの話しだが)遅れる傾向は強いといえそうだ.その際に考えられる理由は,やはり頻度の差ということ以外には考えつかない.
2011-11-18 Fri
■ #935. 語形成の生産性 (1) [productivity][morphology][word_formation][affix][frequency][mental_lexicon]
語形成の生産性 (productivity) については,productivity の各記事で話題にしてきた.そこでは,生産性をどのように定義するか,どのように測定するかは,形態理論における難問であると述べるにとどまったが,今回は,この問題にもう少し踏み込みたい.
まずは,Lieber (61) による,"productive" と "unproductive" の日常語による定義を挙げよう.
Processes of lexeme formation that can be used by native speakers to form new lexemes are called productive. Those that can no longer be used by native speakers, are unproductive; so although we might recognize the -th in warmth as a suffix, we never make use of it in making new words. The suffixes -ity and -ness, on the other hand, can still be used, although perhaps not to the same degree.
この定義により,生産性の指し示している概念は直感的に理解できるが,より専門的に定義しようとするとなかなか難しい.生産性に関与する要因としては,3点が考えられる (Lieber 61--64) .
(1) transparency: 音韻と意味の透明性が確保されており,基体と接辞が明確に区別される語形成は productive である.例えば,candidness や crudity において,それぞれ形態上 candid + -ness, crude + -ity と明確に線引きできるだけでなく,その意味も基体と接辞(「?である状態」)の純粋な和 (compositional) として解釈できる.この点で,-ness や -ity を用いた語形成は透明度が高いと言える.
しかし,-ity は -ness に比べて透明度が低い.1つには,rusticity において,綴字上は rustic + -ity と透明的に分析されるが,発音上は基体の最後の子音が /k/ から /s/ へ変化しており,その分だけ透明性が低くなる.別の例では,timid の強勢は第1音節だが,timidity の強勢は基体の第2音節へ移動しており,透明性が低くなっている.さらに,oddity は,odd + -ity から容易に想像されるとおり,透明的に「異常であること」を意味するのみならず,「変人」をも意味する.後者の語義については,予測可能性(=透明性)が低いとみなすことができる.最後に,dexterity では,基体として *dexter が予想されるところだが,これは実際には存在しない基体である.ここでは,透明性が確保されていない.
oddity (変人)の例で触れた意味の予測(不)可能性という指標は,その派生語が mental lexicon に登録されているかどうかという問題,語彙化 (lexicalization) の問題に関連する.この場合,「異常であること」の語義での oddity は語彙化されていないが,「変人」の意味でのoddity は語彙化されているということになる.したがって,透明性が高いほど語彙化されにくく,透明性が低いほど語彙化されやすいという関係が成り立つ.
(2) frequency of base type: 接辞の付加しうる基体の数や範囲が大きければ大きいほど,その語形成は生産的であるとみなすことができる.接尾辞 -esque (?風の)は名詞に付加されるが,主として固有名詞に限定される.単音節の基体には付加されにくいという条件もあるため,どんな名詞にも付加される接尾辞に比べれば,基体の範囲が狭い分,生産性が低いということになる.([2009-11-29-1]の記事「#216. 人名から形容詞を派生させる -esque の特徴」を参照.)
(3) usefulness: 語形成の有用性.常識的に,すべての形容詞について対応する名詞があることは有用であり,便利であると考えられる.この場合,形容詞を名詞化する接尾辞 -ness, -ity は有用であり,生産的であるということになる.反対に,女性を表わす接尾辞 -ess は,現代の性差別廃止の社会的な風潮により有用性が失われてきており,その分だけ生産性も低くなってきていると考えられる.
語形成の生産性は,少なくともこの3点に基づいて論じる必要がある.
音韻形態変化や意味変化によって (1) が,語彙の増加などによって (2) が,社会的な価値観の変化によって (3) が影響を受けるということを考えると,語形成の生産性もまた通時的な変化に晒されているということは明らかだろう.
・ Lieber, Rochelle. Introducing Morphology. Cambridge: CUP, 2010.
2011-03-22 Tue
■ #694. 高頻度語と不規則複数 [plural][analogy][kyng_alisaunder][frequency][animal]
英語に限らず言語において頻度の高い語は妙な振る舞いをする ([2009-09-20-1]) .現代英語では,動詞の過去・過去分詞,名詞の複数,形容詞・副詞の比較級・最上級で不規則な振る舞いをするものには,高頻度語が確かに多い.名詞の複数形に話を絞ると,借用語は別にして本来語で考えると men, children, feet, teeth などがすぐに思い浮かぶ.しかし,geese, mice, oxen, sheep などははたしてそれほど高頻度語といえるだろうか.[2010-03-01-1]で紹介した高頻度語リストから BNC lemma を眺めた限り,goose や ox などは上位6318語に入っていない.( oxen については[2010-08-22-1]を参照.)
しかし,geese や oxen もかつては現代よりも身近な動物であり,使用頻度も高かったと思われる.それが,身近でなくなってからも一種の惰性により不規則形を保持してきたものと考えられるだろう.もちろん,現代あるいは過去における高頻度だけを根拠に,不規則な現象を体系的に説明することはできない.しかし,頻度と規則性の関係が無視しえないことは確かである.関連する議論を McMahon (73) より引用する.
It has been suggested that residual words are often the most frequently occurring, which will be heard and learned earliest by the child and which are furthermore most susceptible to correction if the child does produce a regularised form like **foots. Some objections can be raised; for instance, ox is not a particularly common noun in modern English - although it probably occurred rather frequently in Middle English. Ox might have been expected to regularise as it became less common, but this decrease in frequency probably overlapped with the rise of literacy, which tends to slow down analogical change. In general, the connection of resistance to analogy with frequency seems to hold.
名詞複数形の研究をしていると,古い英語(特に中英語)のテキストに現われる動物名詞の羅列に敏感に反応してしまう.先日も Kyng Alisaunder を読んでいて,次のような文章に出くわした.マケドニア王が,Alisaunder と Philippe のうち荒馬 Bulcifal を操れる者を世継ぎとすることを決め,その競技の前に神に捧げ物をするという場面である.昨日の記事[2011-03-21-1]と同様,Smithers 版から B (MS. Laud Misc. 622 of the Bodleian Library, Oxford) と L (MS. 150 of the Library of Lincoln's Inn, London) の2バージョンを比較しながら引用する(動物複数名詞を赤字とした).
Oxen, sheep, and ek ken, many on he dude slen, And after he bad his goddes feyre He most wyte of his eyre, Of Alisaunder and Philippoun, Who shulde haue þe regioun. (B 759--64) Oxen schep and eke kuyn
Monyon he dude slen
And after he bad his godus faire
He moste y witen of his aire
Of Alisaundre or of Philipoun
Whiche schold haue þe regioun (L 756--61)
もう1つは,Alexander 軍が Darius 軍と戦うために準備をしている場面.
Hij charged many a selcouþe beeste
Of olifauntz, and ek camayles,
Wiþ armure and ek vitayles,
Longe cartes wiþ pauylounes,
Hors and oxen wiþ venisounes,
Assen and mulen wiþ her stouers; (B 1860--65)
Y chargid mony a selcouþ beste
Olifauns and eke camailes
Wiþ armure and eke vitailes
Long cartes wiþ pauelouns
Hors and oxen wiþ vensounes
Assen and muylyn wiþ heore stoueris (L 1854--59)
さらにもう1つ,Darius 軍の進軍の場面より.
Ycharged olifauntz and camaile,
Dromedarien, and ek oxen,
Mo þan ȝe connen asken. (B 3402--04)
And charged olifans and camailes
Dromedaries assen and oxen
Mo þan ȝe can askyn (L 3385--87)
このように動物名詞が列挙されると,中英語期にはこうした動物が(少なくとも物語の設定において)いかに身近であったかを確認できるとともに,当時の規則複数化の攻勢と不規則複数保持の守勢を具体的に把握することができる.
・ McMahon, April M. S. Understanding Language Change. Cambridge: CUP, 1994.
・ Smithers, G. V. ed. Kyng Alisaunder. 2 vols. EETS os 227 and 237. 1952--57.
2010-12-25 Sat
■ #607. Google Books Ngram Viewer [corpus][web_service][ame_bre][google_books][n-gram][statistics][frequency][lexicology]
Google がものすごいコーパスツールを提供してきた.Google Books Ngram Viewer は Google Labs 扱いだが,その規模と可能性の大きさに驚いた.2004年以来1500万冊の本をデジタル化してきた Google が,そのサブセットとなる520万冊の本,5000億語をコーパス化した.英語のほかフランス語,ドイツ語,ロシア語,スペイン語,中国語が含まれているが,英語では British English, American English, English, English Fiction, English One Million からサブコーパスを選択できる.最大の特徴は,指定した5語までの検索語の頻度を過去5世紀(1500--2008年)にわたって追跡し,グラフで表示してくれることだ.Google からの公式な説明はこちらの記事にある.
規模が大きすぎてコーパスとしてどう評価すべきかも分からないが,ひとまずはいじるだけで楽しい.上記の記事内にいくつかのサンプルがあるが,英語史的な関心を引くサンプルとして burnt と burned の分布比較があったので,English, American English, British English の3サブコーパスをグラフを出してみた.
次に,本年度の卒論ゼミ生の扱った話題を拝借し,一般に AmE on the street, BrE in the street とされる前置詞使用の差異を Google Books Ngram Viewer で確認してみた.American English と British English のそれぞれのサブコーパスから出力されたグラフは以下の通り.
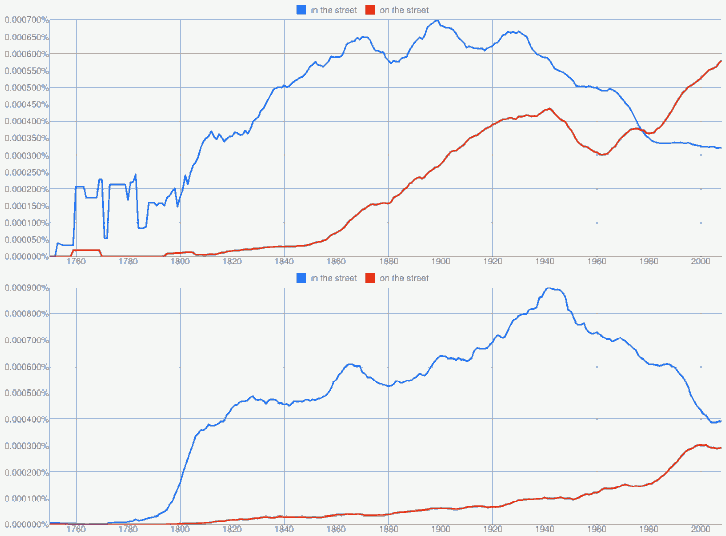
in と on の選択は句の意味(「街路で」か「失業して」か)などにも依存するため単純な形態の頻度比較では不十分だが,傾向はつかめる.
[2010-08-16-1], [2010-08-17-1]の記事で扱った gorgeous についても調べてみた.19世紀には流行っていたが20世紀には落ち目であったこの形容詞が,American English において1980年代以降,再び勢いを盛り返してきている状況がよくわかる.British English でも復調の兆しがあるだろうか?
コーパス言語学一般にいえるが,ツールの使用はアイデア次第である.文化史的な観点からは,[2009-12-28-1]の記事で紹介した American Dialect Society による "Words of the Century" や "Words of the Millennium" のノミネート語句を検索してみるとおもしろい.
他のオンラインコーパスについては[2010-11-16-1]を参照.
2010-10-06 Wed
■ #527. 不規則変化動詞の規則化の速度は頻度指標の2乗に反比例する? [verb][conjugation][statistics][lexical_diffusion][speed_of_change][frequency]
言語進化論の立場からの驚くべき論文を読んだ.古英語の強変化動詞(不規則変化動詞)が時間とともに現在・未来に向かって規則化してゆく速度は,その動詞の頻度指標の2乗に反比例するというのである.不規則形の規則化と頻度に相関関係があることは多くの関連研究で明らかにされてきているが,この研究で驚かされるのは具体的な数式を挙げてきたことである.
古英語から取り出した177の不規則動詞(現在にまで廃語となっていないもののみ)のうち,中英語でも不規則のまま残ったのは145個,近代英語でも不規則のままなのは98個だという.また,未来に計算式を当てはめると西暦2500年までに不規則のまま残っているのは83個であると予測している.
この論文には計算に関わる数々の前提が説明されているが,細かくみればいろいろと疑問点がわき出てくる.
・ 現代英語における各動詞の頻度をコーパスで求めているのはよいとして,古英語と中英語における頻度の求め方は適切か.著者たちは中英語に関しては The Penn-Helsinki Parsed Corpus of Middle English を利用したと述べているが,現代英語の頻度を流用して計算している箇所もあった.もっとも,この流用による値の乱れは大きくないという議論は論文内で展開されてはいるが.
・ 現代英語については標準変種を想定して動詞を数えているが,過去の英語についてはどの変種を選んでいるのかが不明.おそらくは雑多な変種を含めたコーパスを対象としているのだろう.
・ 古英語から現代英語にかけておよそ一定の速度で規則化が起こっているという結果だが,近代期以降は「自然な」言語変化に干渉を加える規範文法の成立や教育の普及という社会的な出来事があった.こうした事情を考え合わせたうえで一定の速度であるということは何を意味するのか.
・ 規則形が現われだした時点ではなく,不規則形が最後に現われた(のちにもう現われないことになる)時点をカウントの基準にしているが,両形が共存している時期の長さについては何か言えることはあるのか.
ただ,非常に大きな視点からの研究なので,あまり細かい点を持ち出して評するのもどうかとは思う.そこで,細かいことは抜きにしてこのマクロな研究結果を好意的に受け入れてみることにして,次にこの研究の後に生じるはずの大きな課題を考えてみたい(論文中には特に further studies が示されていないかったので).
「規則化の速度が動詞の頻度指標の2乗に反比例する」という結果が出たが,この公式は英語の動詞の規則化だけに適用される単発の公式と考えてよいのだろうか.他のいくつかの(望むらくは多くの)言語的規則化にも一般的に適用できるのであればとても有意義だが,おそらくそれほどうまくは行かないだろう.そうすると,今回のように綺麗に公式が導き出される「理想的な」規則化の例は,逆に言うとどのような条件を備えているのだろうか.この条件を一般化することはできるのだろうか,また意味があるのだろうか.
私も「理想的な言語変化の推移」には関心があり,言語変化は slow-quick-quick-slow のパターンのS字曲線を描くとする語彙拡散 ( lexical diffusion ) という理論に注目しているが,上記と同じ課題を抱えている.現実には,理想的な言語変化の推移の起こることは稀だからである.この問題については今後もじっくり考えていきたい.
・ Lieberman, Erez, Jean-Baptiste Michel, Joe Jackson, Tina Tang, and Martin A. Nowak. "Quantifying the Evolutionary Dynamics of Language." Nature 449 (2007): 713--16.
2010-03-01 Mon
■ #308. 現代英語の最頻英単語リスト [lexicology][corpus][link][academic_word_list][alphabet][frequency][statistics][letter_frequency]
現代英語の最頻英単語は何か.この話題についてはコーパス言語学,辞書学,計算機の発展により,様々な頻度表が作られてきた.ウェブ上でも簡単に手に入るので,いくつか代表的なリストや情報源へのリンクを掲げておく.語彙研究に活用したい.
[主要な頻度表]
・ GSL ( General Service List ): 最頻2000語を掲げたリスト.出版が1953年と古いが,現在でも広く参照されているリスト.
・ AWL ( Academic Word List ): 学術テキストに限定した最頻語リスト.2000年に出版され,GSLに含まれる語と重複しないように選ばれた570語を掲載.10のサブリストに分かれている.AWL の前身となる,1984年に出版された808語のリスト UWL ( University Word List ) も参照.
・ BNC Word Frequency Lists: BNC ( The British National Corpus ) による最頻6318語のリスト.頻度表の直接ダウンロードはこちらから.
・ Top 1000 words in UK English: 18人の著者,29作品,460万語のコーパスから抽出したイギリス英語の最頻1000語リスト.
・ Brown Corpus List: Brown Corpus によるアルファベット順リスト.
・ The Longman Defining Vocabulary: LDOCE の1988年版の定義語彙リスト.2000語以上.
[他のリストへのリンク集]
・ Work/Frequency List: 様々な頻度表へのリンク集.(2010/09/10(Fri)現在リンク切れ)
・ Famous Frequency Lists: 様々な頻度表へのリンク集.
・ Basic English and Common Words: ML上の最頻語頻度表についての議論.
[アルファベットの文字の頻度表]
・ Letter Frequencies (rankings for various languages): いくつかのランキング表がある.BNCでは "etaoinsrhldcumfpgwybvkxjqz" の順とある.
(後記 2010/03/07(Sun):American National Corpus に基づいた頻度表を見つけた.Written と Spoken で分別した頻度表もあり.)
(後記 2010/04/12(Mon):COLT: The Bergen Corpus Of London Teenage Language に基づいた最頻1000語のリストを見つけた.)
(後記 2011/02/14(Mon):Corpus of Contemporary American English (COCA) に基づいた Corpus-based word frequency lists, collocates, and n-grams を見つけた.Top 5,000 lemma, Top 500,000 word forms など.)
Powered by WinChalow1.0rc4 based on chalow