2018-01-04 Thu
■ #3174. 高頻度語はスペリングが短い (2) [frequency][spelling][orthography][zipfs_law][statistics][lexicology][corpus]
昨日の記事 ([2018-01-03-1]) と同じ頻度とスペリングの長さに関するデータを,もう少し分析してみた.以下は,頻度ランキングのトップ100語,200語,500語,1000語,2000語,5000語,10000語,20000語,50000語について,それぞれ最低値,第1四分位数,中央値,平均値,第3四分位数,最大値を示した表である.英語の正書法を論じる上での基礎データとしてどうぞ.
| Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. | |
|---|---|---|---|---|---|---|
| Top_100 | 1.0 | 2.0 | 3.0 | 3.1 | 4.0 | 5.0 |
| Top_200 | 1.00 | 3.00 | 4.00 | 3.77 | 4.00 | 10.00 |
| Top_500 | 1.000 | 4.000 | 4.000 | 4.498 | 5.000 | 10.000 |
| Top_1K | 1.000 | 4.000 | 5.000 | 4.968 | 6.000 | 15.000 |
| Top_2K | 1.000 | 4.000 | 5.000 | 5.406 | 7.000 | 15.000 |
| Top_5K | 1.000 | 5.000 | 6.000 | 6.014 | 7.000 | 16.000 |
| Top_10K | 1.000 | 5.000 | 6.000 | 6.488 | 8.000 | 16.000 |
| Top_20K | 1.000 | 5.000 | 7.000 | 6.954 | 8.000 | 17.000 |
| Top_50K | 1.000 | 6.000 | 7.000 | 7.622 | 9.000 | 20.000 |
これをもとに視覚化したのが,以下の箱ひげ図.
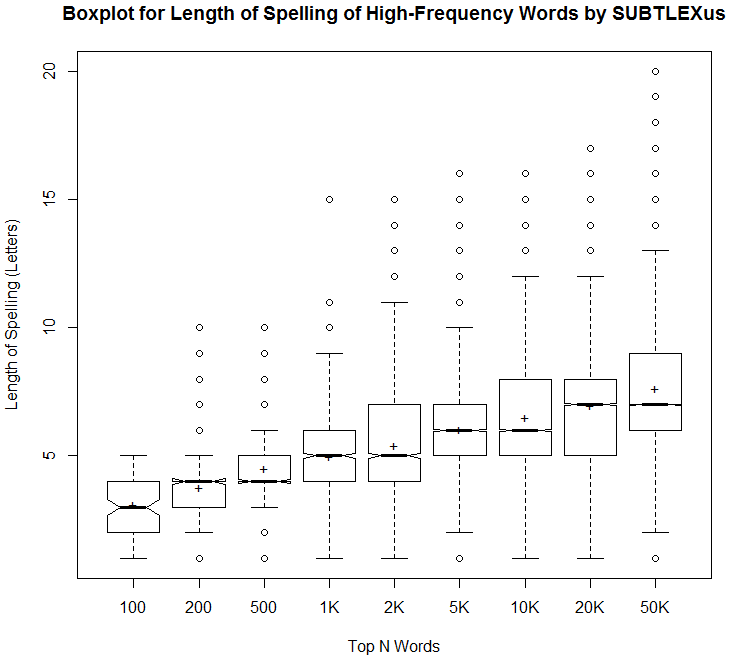
当然予想されたことだが,語数が増えるにしたがってスペリングの平均の長さは徐々に大きくなっていき,バラツキも広がっていく.しかし,トップ数万語でみても平均して7文字程度となっており,さほど長くないのだなという印象を受けた.
[ 固定リンク | 印刷用ページ ]
2018-01-03 Wed
■ #3173. 高頻度語はスペリングが短い (1) [frequency][spelling][orthography][zipfs_law][statistics][lexicology][corpus][three-letter_rule]
標題は特に目新しい指摘ではなく,英語を読み書きする者には直感されていることだと思われる.「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]) や「#1102. Zipf's law と語の新陳代謝」 ([2012-05-03-1]) でも指摘したように,よく読み書きする単語のスペリングは短いほうが効率がよいと考えられるからだ.逆に,滅多に読み書きしない単語であれば少々長くても我慢できる.単語のスペリングに限らず,単語の音形についても同様の原理が作用していると思われる.
また,英語の正書法には内容語は3文字以上で綴られなければならないという「#2235. 3文字規則」 ([2015-06-10-1]) がある.これは機能語という頻度のきわめて高い語類については適用されない.したがって,この規則は上記の効率の問題とも関わる実用的な側面をもつといえる.
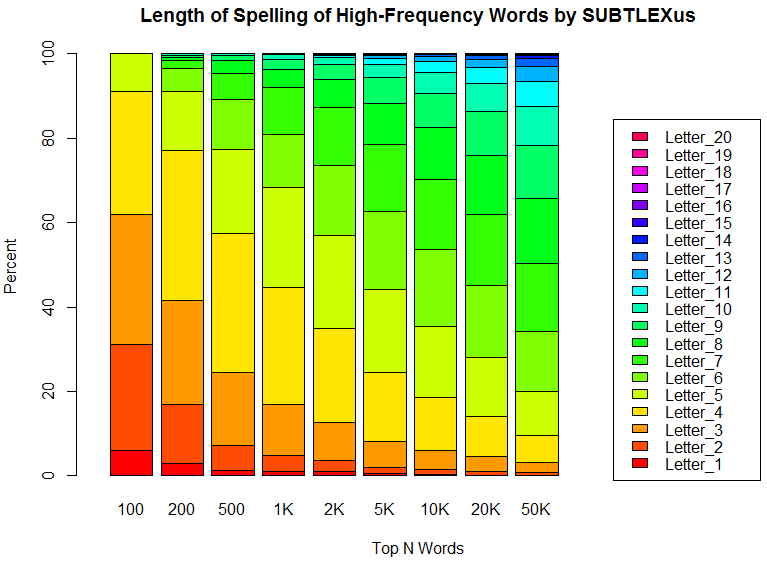
高頻度語であればあるほど,そのスペリングが平均的に短いことを示す方法の1つに,頻度ランキングのトップ100語,1000語,10000語などのリストに基づき,文字数別に単語を数え上げるというやり方がある.「#2096. SUBTLEX-US Word Frequency List」 ([2015-01-22-1]) から引き出した頻度ランキングを利用して,トップ100語,200語,500語,1000語,2000語,5000語,10000語,20000語,50000語について調査した.トップ100語のリストについては先の記事でリストを掲載している通りであり,なかには s, ll などコーパスの仕様に由来するとおぼしき怪しい「語」もあるが,結果の大勢には影響を及ぼさないだろう.
以下にグラフで整理した通り,結果は明白である(数値データはソースHTMLを参照).トップ100語の超高頻度語群では62.00%までが3文字以下のスペリングである.3文字以下の割合(下から3つ分のオレンジの帯まで)ということで比べていくと,トップ200語から50000語の調査結果まで,順に41.50%, 24.60%, 17.00%, 12.65%, 8.06%, 6.01%, 4.55%, 3.20%と目減りしていく.
2017-03-12 Sun
■ #2876. 英語語彙の頻度分布に関する格差上位1%のシェア [lexicology][statistics][frequency][corpus]
昨日の記事「#2875. 英語語彙の頻度分布の格差をジニ係数とローレンツ曲線でみる」 ([2017-03-11-1]) に引き続き,英語語彙頻度の格差について考えてみたい.昨日扱ったジニ係数よりも直感的に格差を認識できる指標として,格差上位1%のシェアというものがある.経済学でいえば,トマス・ピケティも愛用している「トップ富裕層の所得シェア」である.大金持ちがどのくらい金持ちか,という指標と理解すればよい.英語語彙について言えば,生起頻度でトップ1%に入るそれほど多くない語によって,全体のどのくらいのシェアが占められているかを示す指標となる.
昨日と同じように,総頻度数が81.5万ほどの比較的小規模な GSL の語彙頻度表と,1850万ほどの巨大コーパス「#1424. CELEX2」 ([2013-03-21-1]) に基づく語彙頻度表で計算してみた.トップ1%とトップ0.1%での値は,以下の通り.
| GSL | CELEX2 | |
|---|---|---|
| 1% | 47.05% | 69.36% |
| 0.1% | 14.60% | 43.57% |
実際,ここまで高い値になるとは予想していなかった.英語学習という観点からみると,極端な話し,高頻度語のトップ1%を暗記すれば,5?7割ほどの語が認識できることになる.それでテキストを理解できるかというと,それはまったく別問題ではあるが,語彙学習の効率について再考させられる.
参考までに,2000年の時点での日米の所得シェアを見てみると,アメリカではトップ0.1%の富裕層が所得全体の7%ほど,日本では2%ほどである(吉川,p. 226).近年,両国ともに格差は開いてきているようだが,さすがに語彙の世界ほどの格差に至ることはないだろう.語彙の社会は,あらためて不平等な社会である.
・ 吉川 洋 『人口と日本経済』 中央公論新社〈中公新書〉,2016年.
[ 固定リンク | 印刷用ページ ]
2017-03-11 Sat
■ #2875. 英語語彙の頻度分布の格差をジニ係数とローレンツ曲線でみる [lexicology][statistics][frequency][zipfs_law][corpus]
「#1103. GSL による Zipf's law の検証」 ([2012-05-04-1]) で,General Service List (GSL) の最頻2000語余りの語彙頻度表を用いて,zipfs_law が成立する様子を実演した.頻度順位の高い少数の語がただの高頻度語ではなく超高頻度語であること,一方でそれ以外の大多数の語がおしなべて低頻度語であるということが確認された.このことは,英語(そして,おそらくあらゆる言語)の語彙の頻度分布がきわめて不平等・不均衡であり,大きなばらつきと格差に特徴づけられていることを示すものである.
このような分布の格差を示す代表的な指標に,イタリアの経済学者ジニが所得や資産の分布の不平等を計測する指標として1936年に考案したジニ係数 (Gini's coefficient) がある.考え方は次の通りだ.X軸に沿って左から右へ最も頻度の低い語から高い語へと順に並べ,その累積頻度のシェアをY軸方向に取っていく.この点をつなげると,何らかの形の右肩上がりの曲線となる.これをローレンツ曲線 (Lorenz curve) という.すべての語が同頻度で現われるときにはローレンツ曲線は45度の右肩上がりの直線となり「完全平等」を示す.逆に,極端な例として,1つの語のみが生起頻度のすべてを占有し,他のすべての語が頻度ゼロの場合に「完全不平等」となり,ローレンツ曲線は左右逆L字型となる.普通は,ローレンツ曲線は,45度の右肩上がりの線の下部に,三日月形の弧として描かれる.ジニ係数は,三日月の面積と,45度の右肩上がりの線を直角の対辺とする直角二等辺三角形の比率として表現される.したがって,値0が完全平等,値1が完全不平等ということになる.
さて,GSL のデータファイルで計算した結果,ジニ係数は0.812と出た.ローレンツ曲線を描くと,以下のようになる.
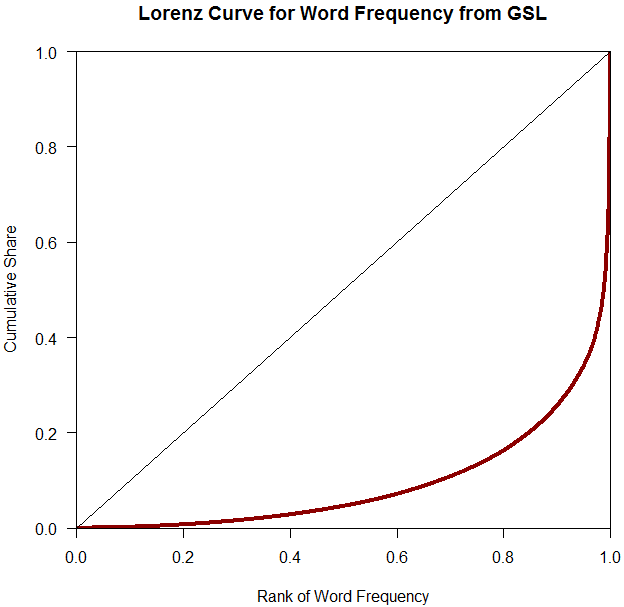
明らかに不平等な分布といえる.ちなみに,GSL よりも巨大なコーパスの語彙頻度表を使うと,さらにジニ係数は上がる(例えば,1790万語からなるコーパス「#1424. CELEX2」 ([2013-03-21-1]) に基づいた計算では,0.950 というすさまじい値が出た!).
参考までに,吉川 (122) に拠って2010年の諸国の所得格差を示すジニ係数をいくつか挙げると,日本が 0.336,アメリカが 0.380,チリが 0.510,アイスランドが 0.246 である.語彙の社会が極めて不平等な社会であることが分かるだろう.
・ 吉川 洋 『人口と日本経済』 中央公論新社〈中公新書〉,2016年.
2016-09-07 Wed
■ #2690. N-gram Tool [cgi][n-gram][statistics][corpus][web_service][frequency][cgi]
n-gram は,言語統計やコーパス言語学の世界における基本的な概念・手段である(「#2324. n-gram」 ([2015-09-07-1]), 「#956. COCA N-Gram Search」 ([2011-12-09-1]) を参照).テキストを指定してその n-gram を得るツールはネットその他にも遍在しているが,あえて簡易ツールをCGIで実装してみた.バックエンドに Perl モジュールの Text::Ngrams を用いている.
使い方はおよそ自明だろう.適当な長さの英文テキストを投げ込めば,デフォルトでは単語ベースの 3-gram (およびそれ以下の 2-gram と 1-gram も含む)の一覧が絶対頻度の高い順に返される(出力行の制限はなし).オプションにより単語ベースではなく文字ベースにも変更でき,n-gram のサイズも変えられる.出力については,頻度順ではなくアルファベット順にすること,出力行に制限を設けること,絶対頻度ではなく相対頻度(各 n-gram 内で合計すると1.0となる)で返すことも可能.
なお,1-gram は入力テキストを構成する単語の頻度表となるので,その用途にも利用できる.簡易的な n-gram ツールとしてどうぞ.
[ 固定リンク | 印刷用ページ ]
2016-08-09 Tue
■ #2661. Swadesh (1952) の選んだ言語年代学用の200語 [glottochronology][lexicology][frequency][statistics]
「基本語彙」 (basic vocabulary) という用語は,言語の調査や議論において様々な機会に出くわす.しかし,昨日の記事「#2660. glottochronology と基本語彙」 ([2016-08-08-1]) でも触れたように,個別言語においても,言語一般においても,基本語彙とは何なのか,どこまでの範囲を含むのかを客観的に定めることは難しい.
glottochronology に携わる人類言語学者は,独自の通言語的,通時的な観点から,基本語彙リストに相当するものを編集し,改訂してきた.例えば,この分野の草分けである Swadesh (456--57) は,完璧なリストは作り得ないということを認めつつ,次の200語からなる一覧を挙げている.その一覧を,Hymes ("Lexicostatistics" 6) 経由で掲げよう.
all, and, animal, ashes, at, back, bad, bark, because, belly, big, bird, bite, black, blood, blow, bone, breathe, burn, child, cloud, cold, come take, count, cut, day, die, dig, dirty, dog, drink, dry, dull, dust, ear, earth, eat, egg, eye, fall, far, fat-grease, father, fear, feather, few, fight, fire, fish, five, float, flow, flower, fly, fog, foot, four, freeze, fruit, give, good, grass, green, guts, hair, hand, he, head, hear, heart, heavy, here, hit, hold-take, how, hunt, husband, I, ice, if, in, kill, know, lake, laugh, leaf, leftside, leg, lie, live, liver, long, louse, man-male, many, meat-flesh, mother, mountain, mouth, name, narrow, near, neck, new, night, nose, not, old, one, other, person, play, pull, push, rain, red, right-correct, rightside, river, road, root, rope, rotten, rub, salt, sand, say, scratch, sea, see, seed, sew, sharp, short, sing, sit, skin, sky, sleep, small, smell, smoke, smooth, snake, snow, some, spit, split, squeeze, stab-pierce, stand, star, stick, stone, straight, suck, sun, swell, swim, tail, that, there, they, thick, thin, think, this, thou, three, throw, tie, tongue, tooth, tree, turn, two, vomit, walk, warm, wash, water, we, wet, what, when, where, white, who, wide, wife, wind, wing, wipe, with, woman, woods, worm, ye, year, yellow
この一覧は理論と実践を組み合わせたものであり,その後も数々の改訂を経ることになった.だが,もとより完璧な基本語彙リストは作り得ないのだから,何らかの言語調査を行なう場合に,この一覧を拠り所にするというのは,1つの便法ではある.なお,Swadesh が言語年代測定の診断のために用いたのは,別途厳選された100語のリストであり,それは「#1128. glottochronology」 ([2012-05-29-1]) で掲載した通りである(100語リストのほうが言語年代学的に有用性が高いという意見もある (Hymes, "More" 341)).
基本語彙の問題については,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]),「#1101. Zipf's law」 ([2012-05-02-1]),「#1961. 基本レベル範疇」 ([2014-09-09-1]),「#1965. 普遍的な語彙素」 ([2014-09-13-1]),「#2625. 古ノルド語からの借用語の日常性」 ([2016-07-04-1]) などの記事も要参照.
・ Swadesh, Morris. "Lexico-Statistic Dating of Prehistoric Ethnic Contacts: With Special Reference to North American Indians and Eskimos." Proceedings of the American Philosophical Society 96 (1952): 452--63.
・ Hymes, D. H. "Lexicostatistics So Far." Current Anthropology 1 (1960): 3--44.
・ Hymes, D. H. "More on Lexicostatistics." Current Anthropology 1 (1960): 338--45.
2016-08-08 Mon
■ #2660. glottochronology と基本語彙 [glottochronology][lexicology][statistics][history_of_linguistics][frequency][anthropology]
glottochronology の方法論を批評した Hymes (11) は,もう1人の人類言語学者 Gleason による1950年代の論著を参照しながら,語彙変化確率に関する3つの前提について解説している.
(1) Every lexical item at every given time has a certain probability of change.
(2) This probability of change is variable, and is influenced by both linguistic and non-linguistic factors.
(3) There exist certain sets of largely independent vocabulary items in which the probability of change within the group is large relative to the variability of that probability of change.
glottochronology では,(1) と (2) は当初から前提とされてきた.Hymes が特に重要だと指摘するのは (3) の仮定である.これによれば,語彙にはある種の閉じた語群がいくつかあり,ある語群は比較的安定し,その安定の度合いの揺れも比較的小さいが,別の語群は比較的不安定であり,その不安定の度合いの揺れも比較的大きいという.具体的にはいわゆる "basic vocabulary" と "non-basic vocabulary" などの区別を念頭においていることは間違いないが,必ずしも定義の明らかでない "(non-)basic" という用語を使わずに,集合論的,統計学的な手法で,それらに相当する語彙の部分集合を取り出せる可能性を示している.実際の検証には,多くの言語の語彙について調査し,それぞれについて長期間にわたる通時的な語彙変化確率を求め,それらを比較するという地道な作業が必要であり,すぐに結論が出るというものではないだろう.しかし,検証可能性は確保されているという点が重要である.
言語一般,あるいは個別言語において,基本語彙 (basic vocabulary) とは何かという問題は,客観的に答えるのが案外難しい.母語話者にとっては直感的に分かるものではあるが,その範囲を客観的に定めるのは難しい.昨日の記事「#2659. glottochronology と lexicostatistics」 ([2016-08-07-1]) でも触れたように,基本語彙の同定に関与する属性として (1) 共時的な commonness (or frequency), (2) 通言語的な universality (of semantic reference), (3) 通時的な (historical) persistence の3種が提案されており,これらが互いにおよその相関関係にあることも知られている.しかし,この3つの属性の各々にどの程度の重みをつけ最終的に基本語彙を決定すべきかについて,特に合意はない.
glottochronology にとっては,基本語彙とはあくまで言語の年代を測定するための材料ではあるが,むしろその材料探しの過程で,基本語彙とは何かという肝心な問題に,実践と理論の両側面から迫ることになったのではないかとも思われる.glottochronology という分野の前提と成果については多くの批判がなされてきたが,その過程で繰り広げられてきた議論はしばしば本質的であり,(人類)言語学史的な貢献は大きいといえるだろう.
glottochronology と基本語彙を巡る問題については,Hymes (32--33) が詳しく議論しているので,そちらを参照.
・ Hymes, D. H. "Lexicostatistics So Far." Current Anthropology 1 (1960): 3--44.
2016-08-07 Sun
■ #2659. glottochronology と lexicostatistics [glottochronology][lexicology][statistics][terminology][speed_of_change][frequency]
言語学の分野としての言語年代学 (glottochronology) と語彙統計学 (lexicostatistics) は,しばしば同義に用いられてきた.だが,glottochronology の創始者である Swadesh は,両用語を使い分けている.私自身も「#1128. glottochronology」 ([2012-05-29-1]) の記事で,両者は異なるとの前提に立ち,「glottochronology (言語年代学)は,アメリカの言語学者 Morris Swadesh (1909--67) および Robert Lees (1922--65) によって1940年代に開かれた通時言語学の1分野である.その手法は lexicostatistics (語彙統計学)と呼ばれる.」と述べた.今回は,この用語の問題について考えてみたい.
人類言語学者・社会言語学者の Hymes (4) は Swadesh に依拠しながら,両用語の区別を次のように理解している.
The terms "glottochronology" and "lexicostatistics" have often been used interchangeably. Recently several writers have proposed some sort of distinction between them . . . . I shall now distinguish them according to a suggestion by Swadesh.
Glottochronology is the study of rate of change in language, and the use of the rate for historical inference, especially for the estimation of time depths and the use of such time depths to provide a pattern of internal relationships within a language family. Lexicostatistics is the study of vocabulary statistically for historical inference. The contribution that has given rise to both terms is a glottochronologic method which is also lexicostatistic. Glottochronology based on rate of change in sectors of language other than vocabulary is conceivable, and lexicostatistic methods that do not involve rates of change or time exist . . . .
Lexicostatistics and glottochronology are thus best conceived as intersecting fields.
つまり,glottochronology と lexicostatistics は本来別物だが,両者の重なる部分,すなわち語彙統計により言語の年代を測定する部門が,いずれの分野にとっても最もよく知られた部分であるから,両者が事実上同義となっているということだ.ただし,Swadesh から80年近く経った現在では,lexicostatistics は,電子コーパスの発展により言語の年代測定とは無関係の諸問題をも扱う分野となっており,その守備範囲は広がっているといえるだろう.
上で引用した Hymes の論文は,言語における "basic vocabulary" とは何か,という根源的かつ物議を醸す問題について深く検討を加えており,一読の価値がある."basic vocabulary" は,commonness (or frequency), universality (of semantic reference), (historical) persistence のいずれかの属性,あるいはその組み合わせに基づくものと概ね受け取られているが,同論文はこの辺りの議論についても詳しい.基本語彙の問題については,「#1128. glottochronology」 ([2012-05-29-1]) や「#1965. 普遍的な語彙素」 ([2014-09-13-1]) の記事で直接に扱ったほか,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]),「#1089. 情報理論と言語の余剰性」 ([2012-04-20-1]),「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]),「#1101. Zipf's law」 ([2012-05-02-1]),「#1497. taboo が言語学的な話題となる理由 (2)」 ([2013-06-02-1]),「#1874. 高頻度語の語義の保守性」 ([2014-06-14-1]),「#1961. 基本レベル範疇」 ([2014-09-09-1]),「#1970. 多義性と頻度の相関関係」 ([2014-09-18-1]) なの記事で関与する問題に触れてきたので,そちらも参照されたい.
・ Hymes, D. H. "Lexicostatistics So Far." Current Anthropology 1 (1960): 3--44.
2016-03-21 Mon
■ #2520. 後期中英語の134種類の "such" の異綴字 [spelling][lme][lalme][corpus][scribe][me_dialect][frequency]
「#53. 後期中英語期の through の綴りは515通り」 ([2009-06-20-1]),「#219. eyes を表す172通りの綴字」 ([2009-12-02-1]) に引き続き,英語史における著しい綴字の変異について.今回は,異綴字の種類の多さに定評のある(?) "such" を取り上げる.
「#1622. eLALME」 ([2013-10-05-1]) で紹介した,後期中英語の方言地図 LALME の改訂・電子版 eLALME において,Item List 10 が "such" を扱っている.この一覧から異綴字を抜き出すと,不確かな例を除いて少な目に数えても,以下の134種類が挙がる(かっこ内の数値は文証される頻度).
asoche (1), aswyche (1), schch (1), schech (1), scheche (3), schiche (1), schoche (1), scht (1), schuc (1), schuch (3), schuche (4), schut (1), schute (1), sclik (2), sclike (1), sclyk (2), sclyke (2), scoche (1), scwche (1), sech (8), seche (39), sewyche (2), shich (1), shiche (1), shoch (1), shoche (1), shuch (5), shuche (3), shych (1), sic (6), sic- (1), sich (53), siche (101), sick (1), sɩͨh (1), sik (1), sik- (1), sike (2), silk (3), sli (1), slieke (1), slik (10), slike (26), slilk (2), slkyke (1), slyk (13), slyke (26), soch (12), soche (60), souche (3), sowche (2), soyche (1), squike (1), squilk (2), squylk (1), sqwych (1), sqwyche (1), sswiche (1), suc (1), succh (1), sucche (5), such (242), suche (375), suchee (1), sucheȝ (1), suchet (1), sucht (1), suchte (1), suech (4), sueche (6), suhc (1), suhe (1), suich (9), suiche (7), suilk (6), suilk- (1), suilke (3), suilkin (1), sulc (1), sulk (4), sulke (2), sutche (1), suth (1), suuch (1), suuche (1), suuech (1), suueche (1), suych (13), suyche (15), suylk (7), suylke (6), svche (1), sviche (1), swc (1), swch (7), swche (4), swech (19), sweche (48), swelk (4), swhiche (2), swhilke (2), swhych (2), swhyche (1), swic (2), swich (77), swiche (84), swichee (1), swilc (3), swilk (76), swilke (45), swilkes (1), swisɩͨhe (1), swlk (1), swlke (1), swuch (3), swuche (2), swych (56), swyche (65), swyeche (1), swyk (1), swyke (1), swyl (1), swylk (62), swylke (35), swylle (1), syc- (1), sych (23), syche (67), syge (1), syk (4), syk- (1), syke (5), sylk (3), sylke (2)
方言の別を度外視して頻度の統計を取ると,トップ10が suche, such, siche, swiche, swich, swilk, syche, swyche, swylk, soche である.トップの2種類 suche と such は現代英語を見慣れている者にとって,十分常識的にみえるだろう.実際,この2種類だけで617例が文証され,総1867例のほぼ3分の1を占める.また,トップの10種類だけで,ほぼ3分の2を占める.したがって,異綴字がこれだけ多くあるからといって,そのまま完全なる混沌に等しい,ということにはならない.このような事情は,中英語期に多種類の綴字が認められる多くの語について認められ,混沌のなかにもある程度の秩序らしきものがが宿っているといえる.そうだとしても,当時の書き手と読み手にとってはやはり不便な状況だったに違いない.この点については,「#1311. 綴字の標準化はなぜ必要か」 ([2012-11-28-1]),「#1450. 中英語の綴字の多様性はやはり不便である」 ([2013-04-16-1]) で論じた通りである.
初期中英語や近現代の諸方言形を調べれば,もっと異綴字の種類は増すだろう.出典は失念したが,数え方にもよるものの,500種類ほどという数字を見かけたことがある・・・.
2015-10-16 Fri
■ #2363. hapax legomenon [hapax_legomenon][terminology][lexicology][lexicography][word_formation][productivity][bible][zipfs_law][frequency][corpus][shakespeare][chaucer]
昨日の記事「#2362. haplology」 ([2015-10-15-1]) でギリシア語の haplo- (one, single) に触れたが,この語根に関連してもう1つ文献学や辞書学の用語としてしばしば出会う hapax (legomenon) を取り上げよう.ある資料のなかで(タイプ数えではなくトークン数えで)1度しか用いられていない語(句)を指す.ギリシア語の hapax (once) + legomenon (something said) からなる複合語だ.複数形は hapax legomena という.
"nonce word" を hapax legomenon と同義としている辞書もあるが,前者は「臨時語」と訳され「その時限りに用いる語」を指す.nonce-word は新語の臨時的な生産性を念頭に用いられることが多いのに対し,hapax legomenon は文献に現われる回数が1度であることに焦点が当てられているという違いが感じられる.nonce (その場限りの)という語の語源については,「#1306. for the nonce」 ([2012-11-23-1]) を参照.
hapax legomenon は,聖書の注釈との関連で,しばしば言及されてきた歴史がある.OED によると英語における初例は1692年のことで,"J. Dunton Young-students-libr. 242/1 There are many words but once used in Scripture, especially in such a sence, and are called the Apax legomena." とある.
文献学や語源学において,hapax legomenon はしばしば問題となる.その語の語源はおろか,意味すら不明であることが少なくない.語彙論や辞書学では,それを一人前の「語」として認めてよいのか,何かの間違いではないか,辞書に掲載すべきか否か,という頭の痛い問題がある (see 「#912. 語の定義がなぜ難しいか (3)」 ([2011-10-26-1])) .一方で,語形成やその生産性という観点からは,hapax legomenon は重要な考察対象となる.というのは,1度だけ臨時的に出現するためには,話者の生産的な語形成機構が前提とされなければならないからである (see 「#938. 語形成の生産性 (4)」 ([2011-11-21-1])) .
だが,実際のところ halax legomenon は決して少なくない.このことは,ジップの法則に照らせば驚くべきことではないだろう (see 「#1101. Zipf's law」 ([2012-05-02-1]), 「#1103. GSL による Zipf's law の検証」 ([2012-05-04-1])) .英語の例としては,Chaucer の用いたnortelrye (education) や Shakespeare の honorificabilitudinitatibus, また Dickens の sassigassity (audacity?) などが挙げられる.
2015-09-07 Mon
■ #2324. n-gram [corpus][information_theory][coca][bnc][google_books][statistics][n-gram][collocation][frequency][link]
情報理論や自然言語処理の分野で用いられる n-gram という分析手法がある.コーパス言語学でもすでにお馴染みの概念であり,共起表現 (collocation) の研究などでは当たり前のように用いられるようになった.種々のコーパスのインターフェースにおいても採用されており,「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) では名前に含まれているほどだし,本ブログでも COCA (Corpus of Contemporary American English) の N-gram データベースを用いて「#956. COCA N-Gram Search」 ([2011-12-09-1]) を実装してきた(その応用は,「#953. 頭韻を踏む2項イディオム」 ([2011-12-06-1]),「#954. 脚韻を踏む2項イディオム」 ([2011-12-07-1]),「#955. 完璧な語呂合わせの2項イディオム」 ([2011-12-08-1]) を参照).BNC では,Explore Words and Phrases from the BNC が利用できる.
コンピュータを用いた分析手法というと難しそうに聞こえるが,n-gram の考え方は至って単純である.文字レベルの 2-gram (bigram) を考えてみよう.最長の英単語といわれる pneumonoultramicroscopicsilicovolcanoconiosis (「#63. 塵肺症は英語で最も重い病気?」 ([2009-06-30-1])) を例にとる.まず,先頭の2文字1組の pn を取り出す.次に,2文字目に進んで同じように ne を取り出す.3文字目に進んで eu を,4文字目に進んで um を得る.同じように,1文字ずつ右にずらしながら,最後の is まで2文字1組を次々と拾っていく.これで44組の2文字を得たことになる.この組のなかで,ic と co という組み合わせは各々3回起こり,os, si, no, on の組み合わせは各々2回現われ,それ以外の組み合わせはいずれも1度きりである.したがって,この単語において最高頻度の2文字1組は ic と co となる.
n-gram の単位は,このように文字である必要はなく,音素でもよいし,より大きな単位である形態素や語でもよく,さらに大きな句などのより大きな単位でもよい.英語コーパス言語学では,語という単位で考えるのが普通だろう.Martin Luther King, Jr. の I Have a Dream の演説のテキストで語単位の 4-gram を取ると,最も多い4語の組み合わせは,予想通り "I have a dream" の8回だが,"will be able to" も同じく8回現われる."Let freedom ring from" も7回とよく現われる,等々の分析が可能となる.ここでは4語という「窓」を設定したので 4-gram と呼ばれるが,隣接するいくつの文字を考慮するかにより 1-gram (unigram), 2-gram (bigram), 3-gram (trigram),そして 5-gram 以上ももちろん考えることができる(1-gram の場合,得られるリストは,事実上各語の生起頻度表である).
巨大コーパスから得られた 2-gram や 3-gram の一覧は,それ自体が共起表現の研究などでは基本データとなるため,ウェブ上でもいろいろと公開されている.日本語では「N-gram コーパス - 日本語ウェブコーパス 2010」があるし,現代英語では COCA の n-gram データベース がある.また,Bigram Plus では,歴史英語コーパスを含めた各種英語コーパスから N-Gram Search を行なえる機能を提供している.ほかにも任意のテキストやコーパスを対象に n-gram を取る各種のツールやソフトも,ウェブ上で入手可能だ.
n-gram 分析の言語分野への応用範囲は広い.次に来る語(音,文字)は何か,という予測可能性とも関係が深いため,機械による音声認識,統語分析,言語判定,自動翻訳,スペルチェック,剽窃探知,全文検索用インデックスの作成などに活用される.もちろん,共起表現の研究では,基本にして不可欠の手段となっている.一方,n-gram はもっぱら言語として表面化されたテキストを対象とし,深層にある構造にまったく触れることがないため,生成文法のような言語理論の方面からは批判があるようだ.詳しくは,n-gram in Wikipedia を参照.
n-gram は工夫次第で,まだまだ使い道がありそうだ.歴史英語テキストにも,応用していきたい.
(後記 2015/09/12(Sat): Sketch Engine より N-grams も参照.)
2015-04-12 Sun
■ #2176. 文法化・意味変化と頻度 [frequency][grammaticalisation][semantic_change][schedule_of_language_change][language_change]
言語変化と頻度の関係については,「#1239. Frequency Actuation Hypothesis」 ([2012-09-17-1]),「#1243. 語の頻度を考慮する通時的研究のために」 ([2012-09-21-1]),「#1265. 語の頻度と音韻変化の順序の関係に気づいていた Schuchardt」 ([2012-10-13-1]),「#1864. ら抜き言葉と頻度効果」 ([2014-06-04-1]) などで議論してきた.これらの記事では,高頻度語と低頻度語ではどちらが先に言語変化に巻き込まれるかなどの順序の問題,あるいはスケジュールの問題 (schedule_of_language_change) に主眼があった.だが,それとは別に,高頻度語あるいは低頻度語にしか生じない変化であるとか,むしろ生じやすい変化であるとか,そのようなことはあるのだろうか.
昨日引用した Fortson (659) は,文法化 (grammaticalisation) や意味変化 (semantic_change) と頻度の関係について論じているが,結論としては両者の間に相関関係はないと述べている.つまり,文法化や意味変化は高頻度語にも作用するし,低頻度語にも同じように作用する.これらの問題に,頻度という要因を導入する必要はないという.
We have seen, then, that both frequent and infrequent forms can be reanalyzed; both frequent and infrequent forms can be grammaticalized. If all these things happen, then frequency loses much or all of its force as an explanatory tool or condition of semantic change and grammaticalization. The reasons are not surprising, and underscore the sources of semantic change again. Frequent exposure to an irregular morpheme, for example (such as English is, are), can insure the acquisition of that morpheme because it is a discrete physical entity whose form is not in doubt to a child. By contrast, no matter how frequent a word is, its semantic representation always has to be inferred. Classical Chinese shì was a demonstrative pronoun that was subsequently reanalyzed as a copula; exposure to shì must have been very frequent to language learners, but so must have been the chances for reanalysis.
Fortson がこのように主張するのは,昨日の記事「#2175. 伝統的な意味変化の類型への批判」 ([2015-04-11-1]) でも触れたように,意味変化には,しばしば信じられているように連続性はなく,むしろ非連続的なものであると考えているからだ.その点では,文法化や意味変化も他の言語変化と性質が異なるわけではなく,高頻度語あるいは低頻度語だからどうこうという問題ではないという.頻度が関与しているかのように見えるとすれば,それは diffusion (or transition) の次元においてであって,implementation の次元における頻度の関与はない,と.これは「#1872. Constant Rate Hypothesis」 ([2014-06-12-1]) を想起させる言語変化観である.
・ Fortson IV, Benjamin W. "An Approach to Semantic Change." Chapter 21 of The Handbook of Historical Linguistics. Ed. Brian D. Joseph and Richard D. Janda. Blackwell, 2003. 648--66.
2015-02-16 Mon
■ #2121. 英語史における /t/ の挿入と脱落の例 [phonetics][dialect][consonant][frequency][-st]
標題について「#1620. 英語方言における /t, d/ 語尾音添加」 ([2013-10-03-1]) や「#1575. -st の語尾音添加に関する Dobson の考察」 ([2013-08-19-1]) の記事で取り上げてきた.特に語尾の -st における t の振る舞いについては ##508,509,510,739,1389,1393,1394,1399,1554,1555,1573,1574,1637,1807,2062 の各記事で話題にしてきた.
英語史からの /t/ の挿入と脱落の例は方言を含めると広範に存在するが,Wełna (329--30) が OED や MED から集めた例の一覧を与えてくれているので,それを掲載したい.Wełna は,/t/ の挿入・脱落が "permanent" なもの(現代英語までその効果が持続しているもの)と "sporadic" なもの(一時期その効果が見られたが後にもとの形態へ回帰したもの)とを区別し,さらに本来語か借用語かで区分している.
(1)
(a) Permanent t-insertion in native words: ME behest (<OE behæs); against, amidst, amongst, betwixt
(b) Permanent t-insertion in foreign words: ME ancient (<ME auncien), ME cormorant (<F cormoran), ME ernest) (<ME ernesse) 'earnest' (=pledge money), ME pagent (<ME pagyn 'pageant', ME perchement (<ME parchemin) 'parchment', ME fesaunt (<F fesan) 'pheasant', ME truant (<F truan), ME tirant '<F tiran) 'tyrant'
(c) Sporadic t-insertion followed by t-loss: ME glisten (<OE glisnian, ME listen (ONhb. lysna); ME vermin (<ME vermint <F vermin
. . . .
(2)
(a) Permanent t-loss in native words: (a) anduel (< onfilt) 'anvil'; ME best(a) (<betsta), ME blesse (<bletsen), OE blosma (<blostma), ME last(e) (<lattste); ENE bussle (<bustle), ENE brisle (<ME bristle), ENE miscelto (<ME mistilto) 'mistletoe', ME nestle, ME ?rustle, LME thrissil (<OE þistil) 'thistle', ENE throssle (<ME þrostle), Sc. quhissle (<OE hwistle) 'whistle', ENE wressel (<ME wrestlen); christen (OE cristnian <Lat.), ME fasten (<OE fæstnian); ME offen (<ME often).
(b) Permanent t-loss in foreign words: (a) ME apostle, castle, epistle, ENE iussell (<LME iustil) 'jostle', LME pestle, ME tresselle (<trestle) 'trestle' (obs.); crysmas (<Cristmasse) 'Christmas'; (b) ME chasten, ENE chestnutte (<chest-nut), ENE hasten; (c) ENE craven (<ME cravant), ME orisoun (<ME orizonte) 'horizon'
(c) Sporadic t-loss: ENE paisan (<OF paysant) 'peasant'.
Wełna は中英語から初期近代英語の t の振る舞いを調査し,(1) 本来語では高頻度語が,借用語では低頻度語が当該の音変化の影響を受けやすい,(2) 分布に明らかな方言差はみられない,(3) t の挿入は主として中英語期の現象であり t の脱落は主として初期近代英語期の現象であること,の3点を結論として示唆している.しかし,議論は必ずしも明解ではなく,疑問もいくつか生じる.詳細な調査が望まれる.
・ Wełna, Jerzy. "Insertion and Loss of the Voiceless Dental Plosive [t] in Middle English." Studies in Middle English: Words, Forms, Senses and Texts. Ed. Michael Bilynsky. Frankfurt am Main: Peter Lang, 2014. 329--42.
2015-02-05 Thu
■ #2110. 言語(変化)の使用基盤モデル [cognitive_linguistics][usage-based_model][language_change][frequency][collocation][speed_of_change]
認知言語学の言語変化に関するモデルとして,使用基盤モデル (usage-based model) というものが提案されている.谷口による説明と図解 (106, 105) がわかりやすい.
あることばの用法の共通性となるスキーマ [A] から,何らかの点で逸脱し拡がった新しい用法 (B) が生じる.はじめ,(B) はスキーマ [A] に合致しない.しかし,(B) の用法が繰り返され定着するにつれて,(B) は [A] と共にその言語のシステムに取り込まれるようになる.すると,(B) を取り込んだ形であらたなスキーマ [A'] が抽出され,それによって (B) が容認されるようになっていくのである.このような変化のシステムを,「使用基盤モデル」あるいは「用法基盤モデル」 (usage-based model) という (Langacker 2000) .(谷口,106)
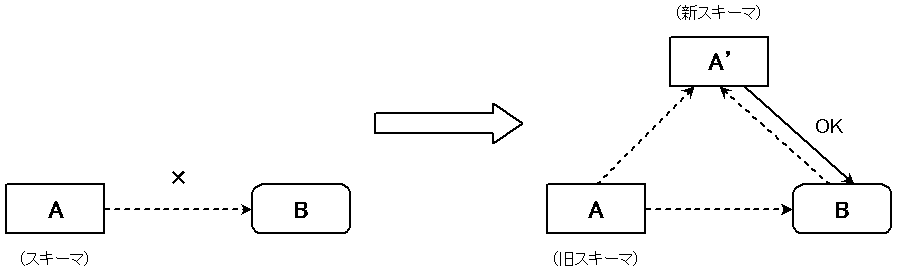
新しいスキーマの創出は,抽象化であるという点で,文法規則の創出とも比較される.しかし,通常文法規則は静的であるのに対して,スキーマは動的であり,柔軟であるという違いがある.スキーマは,逸脱した事例が徐々に定着するにつれて,常に変更されていく.また,変化の過程において,逸脱した事例が定着する度合いには個人差があるため,必然的にスキーマ自体の個人差も生じることになる.言語変化をこのように位置づけてとらえる使用基盤モデルにおいては,言語の体系そのものが流動的なものにみえるだろう.
新スキーマの定着度に個人差があるということは,言語変化の速度 (speed_of_change) の問題に直結するし,当該の言語項の使用頻度 (frequency) や共起 (collocation) の問題とも関連が深い.使用基盤モデルは,これらの関係する問題にも注目している.言語変化は定義上ダイナミックなものではあるが,言語そのものが常にダイナミックなものであり,そのダイナミズムの源泉は日常の使用のなかにあるということを改めて強調した理論と評価できるだろう.
・ 谷口 一美 『学びのエクササイズ 認知言語学』 ひつじ書房,2006年.
2015-01-22 Thu
■ #2096. SUBTLEX-US Word Frequency List [frequency][statistics][corpus][lexicology][zipfs_law][cgi][web_service]
従来の英語学研究において,権威ある語彙頻度表といえばアメリカ英語に関する Kucera and Francis (1967) のものや,イギリス英語に比重を置いたより新しいものとして CELEX (1993) やその2版 (cf. 「#1424. CELEX2」 ([2013-03-21-1])) がよく用いられてきた.しかし,最近,これらを批判し,新しい手法に基づいたアメリカ英語の語彙頻度表が現われた.ベルギー,ヘント大学の実験心理学科の提供する SUBTLEXus である.左のHPから,SUBTLEXus の一群の頻度表のファイルや記述がダウンドーロできる.
SUBTLEXus の基盤にあるコーパスは,8388件の映画の字幕の集成であり,総語数は5100万語に及ぶ.SUBTLEXus の頻度表は,Kucera and Francis や CELEX の頻度表と比べて,いくつかの算出された指標においてすぐれていると主張されている.頻度は,見出し語 (lemma) ごとではなく語形 (word form) ごとに数えられており,例えば名詞であれば単数形と -s 語尾などをもつ複数形は別扱いされる(異なる語形は74,286種類).名詞と動詞など複数の品詞として用いられる語形については,それぞれの品詞ごとの頻度にもアクセスできるし,より優勢な品詞 (Dominant POS) のほうへ合算した頻度へもアクセスできる.データには,ほかに何件の映画に現われているか,小文字として現われているのは何回か,頻度の対数を取った指標,Zipf 指標 (cf. 「#1101. Zipf's law」 ([2012-05-02-1])) なども含まれている.これだけの種類のデータが含まれていると,目的とアイデア次第でおおいに有効に利用できるだろう.話し言葉ベースであることも顕著な特徴だ.
ダウンロードできるいくつかのデータのなかで "a zipped Excel file of SUBTLEX-US with the Zipf values included" をダウンロードし,少しいじってみた.例えば,(1) 全体的に多く現われ,かつ (2) 多くの映画にも現われる語形は,総合的な意味で頻度が高いと考えられるだろう.そこで (1) と (2) に関する対数の指標を掛け合わせて,それを降順に並べて最初の100語を取ると,正真正銘の最頻単語100語が得られるはずだ.省略形の片割れなども含まれているが,以下がそのリストである.
you, I, the, to, s, a, it, t, that, and, of, what, in, me, is, we, this, he, on, for, my, m, your, don, have, do, re, no, be, know, was, not, can, are, all, with, just, get, here, but, there, ll, so, they, like, right, out, go, up, about, she, if, him, got, at, now, come, oh, one, how, well, want, yeah, her, think, good, see, let, did, why, who, as, going, his, will, from, when, back, time, yes, look, d, take, an, where, man, would, them, been, some, or, tell, us, had, were, say, could, gonna, didn, hey
ほかには,最頻10語,25語,50語,100語,250語,500語,1,000語,2,500語,5,000語,10,000語,25,000語,50,000語,100,000語について,Dominant POS ごとに数え上げてみることもたやすい.「#666. COCA 最頻5000語で品詞別の割合は?」 ([2011-02-22-1]),「#667. COCA 最頻50万語で品詞別の割合は?」 ([2011-02-23-1]),「#1132. 英単語の品詞別の割合」 ([2012-06-02-1]) の記事でも,別のコーパスにより似たような調査を行ったが,SUBTLEX-US 版の調査結果は次のグラフにまとめられる.
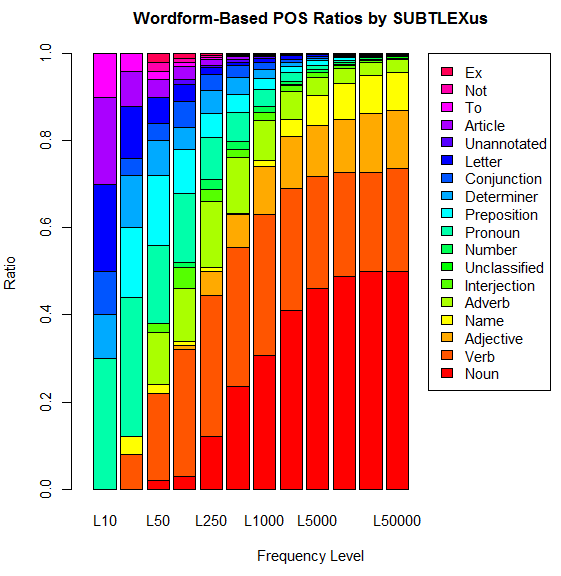
以下はおまけの検索ツール (SUBTLEX-US Word Frequency Extractor) .おまけなので,10例までしか結果が出力されない仕様です.SUBTLEXus の提供する複雑な検索も可能な,SUBTLEXus Online Search もどうぞ.
2014-09-18 Thu
■ #1970. 多義性と頻度の相関関係 [polysemy][zipfs_law][information_theory][frequency][statistics]
基本語彙と呼ばれるものの多面的な性質について「#1960. 英語語彙のピラミッド構造」 ([2014-09-08-1]) で触れた.基本語彙とは,日常的で頻度が高く,早期に習得され,変化しにくく,意味・用法が多岐にわたるなどの特徴をもつ.関連する話題は,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]),「#1089. 情報理論と言語の余剰性」 ([2012-04-20-1]),「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]),「#1101. Zipf's law」 ([2012-05-02-1]),「#1874. 高頻度語の語義の保守性」 ([2014-06-14-1]),「#1961. 基本レベル範疇」 ([2014-09-09-1]),「#1965. 普遍的な語彙素」 ([2014-09-13-1]) その他の記事でいろいろと扱ってきた.
今回は,この問題と関連して,高頻度語は多義的であるという命題について考えてみたい.頻度の高い語ほど語義を多くもち,頻度の低い語は語義を多くもたないということは言語使用の事実に照らして実証されるだろうか.また,理論的にいかに説明されるだろうか.Zipf's law で知られる Zipf は,情報理論の立場からこの課題に挑んだ.
Zipf は,E. L. Thorndike の英語最頻20,000語と Thorndike-Century Senior Dictionary に基づき,語の頻度と語義数の相関関係を探った.この辞書は,古語や廃語などの特殊な register をもつ語義は掲載しておらず,一般的に用いられる語義のみを掲載している.丹念に調査した結果,ある頻度域と,そこに属する語が示す平均語義数との間に,明らかな相関関係が見いだされた.以下は,Zipf (253) に示されているグラフを再現したものである.両軸ともに対数軸であり,X軸は頻度順位を,Y軸は頻度域の平均語義数を表わす.
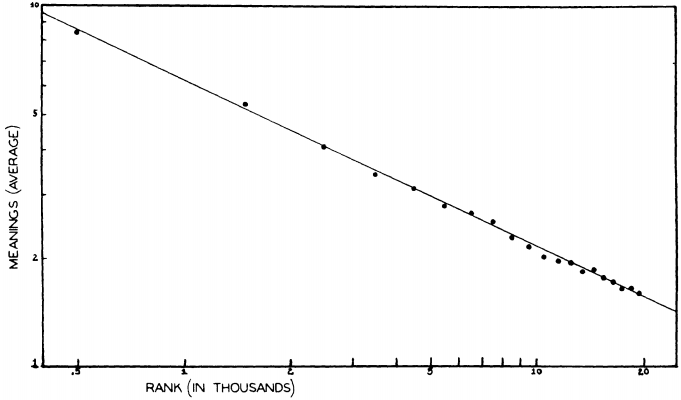
傾きはほぼ0.5に等しく,これは話者の発話と聴者の聴解にかかる費用に関する理論の予測と符合するという.その理論の数学的裏付けは私の理解を超えるので解説できないが,Zipf は結論として語の語義数と頻度(順位)の関係について次のように定式化した (Zipf 255) .
. . . different meanings of a word will tend to be equal to the square root of its relative frequencies (with the possible exception of the few dozen most frequent words)
背景には,多義の定義やある語の語義をいかに区分するかといった意味論の側で問うべき問題もおおいにあるが,示唆に富んだ結論である.関連して,「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]) や zipfs_law の各記事も参照されたい.
・ Zipf, G. K. "The Meaning-Frequency Relationship of Words." Journal of General Psychology 33 (1945): 251--66.
2014-07-16 Wed
■ #1906. 言語変化のスケジュールは言語学的環境ごとに異なるか [speed_of_change][schedule_of_language_change][lexical_diffusion][wave_theory][frequency]
「#1872. Constant Rate Hypothesis」 ([2014-06-12-1]) で Kroch の唱える言語変化のスケジュールに関する仮説を見た.新形が旧形を置き換える過程はおよそS字曲線で表わされ,そのパターンは異なる言語学的環境においても繰り返し現われるという仮説だ.異なる環境においても,その変化が同じタイミング,同じ変化率で進行するというのが,この仮説の要点である.もし環境ごとの曲線がパラレルではないように見える場合には,それは環境ごとに新形を受容する程度が,機能的,文体的な要因により異なるからである,と解釈する.
しかし,Kroch のこの仮説に対立する仮説も提出されている.1つは「#1811. "The later a change begins, the sharper its slope becomes."」 ([2014-04-12-1]) で紹介した議論である.変化を表わす曲線は,環境ごとにパラレルではない.環境ごとに開始時期も異なるし変化率(速度)も異なる,という考え方だ.この仮説は,さらに一歩進んで,早く開始した環境では変化は相対的にゆっくり進行するが,遅く開始した環境では変化は相対的に急速に進行する,すなわち「早緩遅急」を主張する.私自身もこの議論に基づいて著わした論文がある (Hotta 2010, 2012) .
さらに別の仮説もある.変化を表す曲線が環境ごとにパラレルではなく,環境ごとに開始時期も異なるし変化率(速度)も異なる,と主張する点では上述の「早緩遅急」の仮説と同じだが,むしろそれと逆のスケジュールを唱えるものがある.つまり,早く開始した環境では変化は相対的に急速に進行するが,遅く開始した環境では変化は相対的にゆっくりと進行する,と.「早緩遅急」ならぬ「早急遅緩」である.これは,Bailey が言語変化の原理として主張しているものの1つである.
Bailey は言語変化のスケジュールに関して,2つの原理を唱えている.1つは言語変化はS字曲線を描くというもの,もう1つは上記の言語変化の「早急遅緩」という主張だ.それぞれ,主張箇所を引用しよう.
A given change begins quite gradually; after reaching a certain point (say, twenty per cent), it picks up momentum and proceeds at a much faster rate; and finally tails off slowly before reaching completion. The result is an ʃ-curve: the statistical differences among isolects in the middle relative times of the change will be greater than the statistical differences among the early and late isolects. (77)
What is quantitatively less is slower and later; what is more is earlier and faster. (If environment a is heavier-weighted than b, and if b is heavier than c, then: a > b > c.) (82)
2点目の「早急遅緩」については,上の引用から分かるとおり,量的に多いか少ないか(端的にいえば頻度)というパラメータが関与しているしていることに注意されたい.結局のところ,言語変化のスケジュールが環境ごとに異なるかという問題は,言語変化のスケジュールを巡るもう1つの大きな問題,すなわち頻度と言語変化の順序という問題とも関与せざるを得ないのかもしれないと思わせる.
現時点では,どの仮説を採るべきか決定することはできない.個別の言語変化について,事実を経験的に集めていくしかないのだろう.
・ Kroch, Anthony S. "Reflexes of Grammar in Patterns of Language Change." Language Variation and Change 1 (1989): 199--244.
・ Hotta, Ryuichi. "Leaders and Laggers of Language Change: Nominal Plural Forms in -s in Early Middle English." Journal of the Institute of Cultural Science (The 30th Anniversary Issue II) 68 (2010): 1--17.
・ Hotta, Ryuichi. "The Order and Schedule of Nominal Plural Formation Transfer in Three Southern Dialects of Early Middle English." English Historical Linguistics 2010: Selected Papers from the Sixteenth International Conference on English Historical Linguistics (ICEHL 16), Pécs, 22--27 August 2010. Ed. Irén Hegedüs and Alexandra Fodor. Amsterdam: John Benjamins, 2012. 94--113.
・ Bailey, Charles-James. Variation and Linguistic Theory. Washington, DC: Center for Applied Linguistics, 1973.
2014-06-14 Sat
■ #1874. 高頻度語の語義の保守性 [semantics][semantic_change][frequency][speed_of_change]
高頻度語は形態的に保守的だということは,よくいわれる.頻度と変化しやすさとの間に相関関係があるらしいことは,最近でも「#1864. ら抜き言葉と頻度効果」 ([2014-06-04-1]) で取り上げ,その記事の冒頭にもいくつかの記事へのリンクを張った (##694,1091,1239,1242,1243,1265,1286,1287,1864) .高頻度語はたいてい日常的な基礎語でもあることから,この問題は基礎語彙の保守性という問題にも通じる.実際,「#1128. glottochronology」 ([2012-05-29-1]) は,基礎語彙の保守性を前提とした仮説だった.
語という記号 (sign) や形態という記号表現 (signifiant) について頻度と保守性の関係が指摘されるのならば,記号のもう1つの側面である記号内容 (signifié),すなわち意味についても同様の関係が指摘されてもよいはずだ.高頻度の意味であれば,変化しにくいといえるのではないか.Stern (185) は,高頻度語の語義の保守性に触れている.
It is well known that the most common words of a language retain most tenaciously old and otherwise discarded forms and inflections. It is reasonable to assume that a strong tradition has similar effects on meanings. Note, however, that the retention of one or more old meanings is no obstacle to the acquisition of new ones: frequency is only a conservative factor for already established meanings.
高頻度の語義をもつ語はそれ自体が高頻度であり,日常的な基礎語である確率が高く,全体として保守的だろうとは予想される.しかし,なるほど Stern の述べる通り,その高頻度の語義は保守的だとしても,その語に比喩的・派生的な語義が新たに付加されることが妨げられるわけではない.むしろ,多くの場合,基礎語は多義である.
Stern の言うように,形態についても意味についても,高頻度と保守性との相関関係は等しく認められるように思われる.しかし,1つ大きな違いがある.形態の変化を論じる場合には,新形が旧形に取って代わる過程,あるいは少なくとも両形が variants として並び立つ状況が前提とされる.一応のところ 各々の variant は明確に区別される.しかし,意味の変化を論じる場合には,新しい語義が古い語義を必ずしも置き換えるのではなく,その上に累積されてゆくことが多い.新旧 variants の置換や並立というよりは,それらが多義として積み重なっていく過程である.形態の保守性と意味の保守性は,この違いを意識しながら理解しておく必要があるだろう.関連して,「#1692. 意味と形態の関係」 ([2013-12-14-1]) の第3引用を参照されたい.
・ Stern, Gustaf. Meaning and Change of Meaning. Bloomington: Indiana UP, 1931.
2014-06-04 Wed
■ #1864. ら抜き言葉と頻度効果 [frequency][lexical_diffusion][japanese][ranuki][japanese]
言語変化における項目の頻度 (frequency) の役割について,frequency の各記事,とりわけ「#694. 高頻度語と不規則複数」 ([2011-03-22-1]),「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]),「#1239. Frequency Actuation Hypothesis」 ([2012-09-17-1]),「#1242. -ate 動詞の強勢移行」 ([2012-09-20-1]),「#1243. 語の頻度を考慮する通時的研究のために」 ([2012-09-21-1]),「#1265. 語の頻度と音韻変化の順序の関係に気づいていた Schuchardt」 ([2012-10-13-1]),「#1286. 形態音韻変化の異なる2種類の動機づけ」 ([2012-11-03-1]),「#1287. 動詞の強弱移行と頻度」 ([2012-11-04-1]) で様々に議論してきた.
理論的な扱いとしては Phillips による「#1239. Frequency Actuation Hypothesis」 ([2012-09-17-1]) に関心を抱いているが,先日,現代日本語(東京共通語)のら抜き言葉 (innovative potential) の拡散を頻度の観点から調査した論文を見つけ,そこで提起されている "Revised Frequency Hypothesis of Analogical Leveling (RFH)" に目を引かれた.
その論文で,著者の Matsuda はこれまでに指摘されてきた様々な言語学的,社会言語学的,文体的な要因がいかに関与的かを量的に明らかにしようとした.考慮されている変数は以下の通りである (12) .
I. Linguistic
1. Length of the stem [measured in mora]
2. Conjugation type of the verb: i-stem/e-stem
3. Conjugation form following the potential suffix: Negative/Others
4. Morphological structure of the preceding stem: Monomorphemic verb/Compound verb/Auxiliary verb/Causative verb
5. Type of clause in which the potential form is embedded:
Main clause
Semi-embedded clause (Adverbial clause/Gerund)
Embedded clause (Quote/Relative clause/Predicate complement clause/Noun complement clause)
II. Social
1. Age
2. Sex
3. Area of residence: Uptown/Downtown
III. Style (taken from Labov & Sankoff, 1988)
Casual (narrative, group, kids, tangent)
Careful (response, language, soapbox, careful)
Matsuda はこれらの変数(の組み合わせ)の効き目を量的に確かめていき,概ね各々がら抜き言葉の革新に関与的であることを示したが,Sex や Area of residence など有意差の出ない変数もあった.そして,これらの分析のあとで,従来の研究では考慮されてこなかった頻度という変数を導入した.Matsuda は,頻度効果というものを考えようとするときに,いったい何の頻度を考慮すればよいのかという本質的な問題に言及している.例えば mirare(ru)/mire(ru) (見られ(る)/見れ(る))の場合には,語幹 mir- の頻度を数えるべきのか,あるいは問題の接辞 -are/-e の頻度を数えるべきなのか.前者であれば,mir- のトークン頻度とタイプ頻度のどちらを問題にすべきなのか.英語の drive--drove など不規則変化動詞に見られる屈折現象を頻度の観点から分析する場合には,屈折した語形そのものの頻度を問題にすればよさそうだが,膠着的な日本語の mir-e(-ru) (見れ(る))の場合には,どの形態素の頻度を数えればよいのだろうか.
以上のような考察を経て,Matsuda は屈折型と膠着型とでは考慮すべき頻度の単位が異なっているのではないかという仮説を唱える.これが上述の "Revised Frequency Hypothesis of Analogical Leveling (RFH)" (24) である.
In analogical leveling, the token frequency of the unit undergoing the leveling and its degree/rate of leveling tend to show an inverse correlation, where the "unit" is defined according to the degree of fusion of the form undergoing the leveling with its neighboring morpheme(s). If the form is highly fused with the neighboring morpheme, the whole (morpheme, form) combination counts as a "unit" whose frequency is to be measured. If it is not, the form alone counts as a "unit," and its own frequency suffices as a correlate of the rate of leveling.
この仮説を採用すれば,今回のら抜き言葉の調査の結果が無理なく解釈できるという.つまり,ら抜き言葉の拡散に対して(反比例的に)関与的な頻度とは,問題の可能を表わす接辞 -are/-e それ自体のトークン頻度であり,前接する動詞語幹のトークン頻度やタイプ頻度ではない,と.
おもしろい仮説のようにも思えるが,素朴な疑問として,頻度の低い接辞だからといって,なぜそれ自身の水平化(ら抜き化)が進むことになるのだろうか.-are にしても -e にしても頻度が低いのであれば,なぜ前者が後者に置換されてゆくことになるのだろうか.
・ Matsuda, Kenjiro. "Dissecting Analogical Leveling Quantitatively: The Case of the Innovative Potential Suffix in Tokyo Japanese." Language Variation and Change 5 (1993): 1--34.
2014-04-03 Thu
■ #1802. ARCHER 3.2 [corpus][archer][mode][frequency]
昨年末のことになるが,近代英米語コーパス ARCHER: A Representative Corpus of Historical English Registers の Untagged 版が公開された.詳細は,公式の Documentation,あるいは VARIENG によるコーパスの解説からどうぞ.英語史研究会のオンライン会報より,三浦あゆみさんの記事「ARCHERの新版公開」も参考になる.
ARCHER は,1990年代初頭より Biber and Finegan が編纂してきたもので,現在では14の大学が合同で管理している.2013年に公開されたこの3.2版は Manchester 大学 ( David Denison and Nuria Yáñez-Bouza) による提供である.コーパスの内容と用途を端的に表現すれば,"a multi-genre historical corpus of British and American English covering the period 1600--1999. The corpus has been designed as a tool for the analysis of language change and variation in a range of written and speech-based registers of English." ということである.
コーパスの規模は1,710ファイル,3,298,080語からなり,語数での英米比は6:4ほど.また,時期として8期,内容により12種類にジャンル分けされている (a = advertising, d = drama, f = fiction, h = sermons, j = journals, l = legal, m = medicine, n = news, p = early prose, s = science, x = letters, y = diaries) .ファイル数と語数の内訳は以下の通り.
| BRITISH | a | d | f | h | j | l | m | n | p | s | x | y | TOTAL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1600--49 | files | 0 | 10 | 0 | 0 | 0 | 10 | 0 | 0 | 10 | 0 | 0 | 0 | 30 |
| words | 0 | 32,342 | 0 | 0 | 0 | 21,026 | 0 | 0 | 32,741 | 0 | 0 | 0 | 86,109 | |
| 1650--99 | files | 0 | 10 | 11 | 10 | 10 | 10 | 21 | 10 | 0 | 10 | 75 | 10 | 177 |
| words | 0 | 30,328 | 41,667 | 21,818 | 21,186 | 20,466 | 23,811 | 22,304 | 0 | 21,427 | 38,767 | 20,488 | 262,262 | |
| 1700--49 | files | 0 | 10 | 11 | 10 | 11 | 10 | 14 | 10 | 0 | 10 | 77 | 10 | 173 |
| words | 0 | 27,862 | 44,057 | 21,511 | 23,265 | 21,315 | 22,066 | 21,612 | 0 | 20,812 | 33,896 | 20,495 | 256,891 | |
| 1750--99 | files | 10 | 10 | 10 | 10 | 10 | 10 | 20 | 10 | 0 | 10 | 70 | 11 | 181 |
| words | 25,386 | 27,484 | 45,198 | 21,752 | 21,284 | 20,367 | 21,002 | 23,172 | 0 | 20,599 | 29,589 | 23,043 | 278,876 | |
| 1800--49 | files | 10 | 10 | 10 | 10 | 11 | 10 | 10 | 10 | 0 | 10 | 25 | 10 | 126 |
| words | 30,804 | 31,211 | 45,107 | 21,777 | 23,249 | 20,531 | 20,286 | 22,951 | 0 | 21,015 | 12,671 | 20,883 | 270,485 | |
| 1850--99 | files | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 0 | 10 | 26 | 10 | 126 |
| words | 30,684 | 34,856 | 43,427 | 21,322 | 21,243 | 20,757 | 22,265 | 23,072 | 0 | 21,810 | 10,819 | 21,789 | 272,044 | |
| 1900--49 | files | 10 | 11 | 10 | 10 | 10 | 10 | 10 | 10 | 0 | 10 | 29 | 10 | 130 |
| words | 26,717 | 31,391 | 45,408 | 21,123 | 22,208 | 21,160 | 20,213 | 21,977 | 0 | 21,664 | 12,529 | 22,424 | 266,814 | |
| 1950--99 | files | 10 | 11 | 10 | 10 | 10 | 10 | 13 | 10 | 0 | 10 | 28 | 10 | 132 |
| words | 23,437 | 32,200 | 45,109 | 21,093 | 22,723 | 20,721 | 20,994 | 22,935 | 0 | 21,385 | 11,361 | 22,060 | 264,018 | |
| TOTAL | files | 50 | 82 | 72 | 70 | 72 | 80 | 98 | 70 | 10 | 70 | 330 | 71 | 1,075 |
| words | 137,028 | 247,674 | 309,973 | 150,396 | 155,158 | 166,343 | 150,637 | 158,023 | 32,741 | 148,712 | 149,632 | 151,182 | 1,957,499 | |
| AMERICAN | a | d | f | h | j | l | m | n | p | s | x | y | TOTAL | |
| 1750--99 | files | 3 | 10 | 10 | 10 | 10 | 12 | 9 | 10 | 0 | 10 | 58 | 10 | 152 |
| words | 9,214 | 29,980 | 38,980 | 21,271 | 21,896 | 41,177 | 23,541 | 22,265 | 0 | 20,668 | 27,860 | 21,315 | 278,167 | |
| 1800--49 | files | 1 | 10 | 10 | 0 | 10 | 12 | 0 | 10 | 0 | 10 | 10 | 10 | 83 |
| words | 2,822 | 40,568 | 44,676 | 0 | 21,476 | 33,409 | 0 | 37,107 | 0 | 20,904 | 20,739 | 20,695 | 242,396 | |
| 1850--99 | files | 8 | 10 | 11 | 10 | 10 | 10 | 10 | 10 | 0 | 10 | 28 | 11 | 128 |
| words | 24,480 | 32,721 | 44,394 | 21,056 | 22,436 | 28,506 | 20,547 | 21,994 | 0 | 21,311 | 11,361 | 23,419 | 272,225 | |
| 1900--49 | files | 10 | 10 | 10 | 0 | 10 | 11 | 0 | 15 | 0 | 10 | 52 | 10 | 138 |
| words | 30,460 | 52,514 | 53,430 | 0 | 21,661 | 21,607 | 0 | 22,802 | 0 | 20,984 | 25,021 | 20,731 | 269,210 | |
| 1950--99 | files | 10 | 10 | 10 | 10 | 10 | 12 | 10 | 10 | 0 | 12 | 30 | 10 | 134 |
| words | 29,563 | 31,037 | 44,382 | 21,051 | 22,109 | 25,517 | 22,617 | 23,069 | 0 | 25,623 | 11,961 | 21,654 | 278,583 | |
| TOTAL | files | 32 | 50 | 51 | 30 | 50 | 57 | 29 | 55 | 0 | 52 | 178 | 51 | 635 |
| words | 96,539 | 186,820 | 225,862 | 63,378 | 109,578 | 150,216 | 66,705 | 127,237 | 0 | 109,490 | 96,942 | 107,814 | 1,340,581 | |
Documentation のページより,完全単語リストをダウンロード可能.タグ付きの検索が可能な版もいずれ公開されるということなので,期待したい.「#1752. interpretor → interpreter (2)」 ([2014-02-12-1]) の記事で少し使ってみたので,そちらも参照を.
Powered by WinChalow1.0rc4 based on chalow