2023-06-17 Sat
■ #5164. 綴字体系は母語話者にヒントを与えるべく発達してきたものにすぎない [spelling][orthography][redundancy]
綴字体系は,話し言葉の要素を完璧に写し取っている必要はない.母語話者にとっては,それは話し言葉のヒントを与えさえすれば十分である.敷衍していえば,綴字体系は母語話者のためにあり,母語話者のために発達してきたのである.言語とは本来的にそのようなものだ.
Lass and Laing は,綴字体系の不完全性と余剰性について,"A spelling system is a mnemonic for native speakers." と喝破している.
A spelling system is a mnemonic for native speakers. . . . [A] literate native speaker can routinely understand spellings that may seem strikingly 'defective'.21 All spelling systems have built-in redundancy, and interpretation of even bizarre spellings is possible as long as the reader knows the system and has a good idea in advance of what a word is likely to be, or what the range of choices is. In the present context, no reader who knows English would have any difficulty reconstituting the defective representations <spllng> or <rthgrphc>.
21 For instance, the Cypriot syllabary failed to represent half the vowels and two-thirds of the consonantal contrasts . . . ; and Latin did not represent vowel length, which means that roughly half of the possible graphic word-forms available were potentially ambiguous.
これは,非英語母語話者が英語の綴字を評価する際に忘れてはならない点である.英語を非母語話者として学んでいる私たちは,しばしば英語の綴字に欠点が多いことをぼやく.しかし,それもそのはずで,英語の綴字体系は,英語母語話者のために解読できるだけの最低限のヒントを与えさえすればよい,というほどの原理で発達してきたのだ.そもそも非母語話者の存在は念頭に置かれていない.
・ Lass, Roger and Margaret Laing. "Interpreting Middle English." Chapter 2 of "A Linguistic Atlas of Early Middle English: Introduction." Available online at http://www.lel.ed.ac.uk/ihd/laeme2/laeme_intro_ch2.html .
2016-01-07 Thu
■ #2446. 形態論における「補償の法則」 [morphology][category][functionalism][redundancy][information_theory][markedness][category]
昨日の記事「#2445. ボアズによる言語の無意識性と恣意性」 ([2016-01-06-1]) で引用した,樋口(訳)の Franz Boaz に関する章の最後 (p. 98) に,長らく不思議に思っていた問題への言及があった.
多くの言語が単数形で示しているほど複数形では明確で論理的な区別をしていないのはなぜか,という疑問を,解答困難なものとしてボアズは引用している.しかし,ヴィゴ・ブレンダル (Viggo Bröndal) は,形態論的形成の中の角の複雑さを避けるための手段が一般的に講じられている傾向があることを指摘した.しばしば分類上の一つの範疇に関して複雑である形式は他の範疇に関しては比較的単純である.この「補償の法則」によって,単数形よりも完全に特定されている複数形は,通例は比較的少数の表現形式を持っている.
英語史でいえば,この問題はいくつかの形で現われる.古英語において,名詞や形容詞の性や格による屈折形は,概して複数系列よりも単数系列のほうが多種で複雑である.3人称代名詞でもも,単数では hē (he), hēo (she), hit (it) と性に応じて3種類の異なる語幹が区別されるが,複数では性の区別は中和して hīe (they) のみと簡略化する.動詞の人称語尾も,単数主語では人称により異なる形態を取るのが普通だが,複数主語では人称にかかわらず1つの形態を取ることが多い.つまり,文法範疇の構成員のうち有標なものに関しては,おそらく意味・機能がそれだけ複雑である補償あるいは代償として,対応する形式は比較的単純なものに抑えられる,ということだろう.
しかし,考えてみれば,これは言語が機能的な体系であることを前提とすれば当前のことかもしれない.有標でかつ複雑な体系は,使用者に負担がかかりすぎ,存続するのが難しいはずだからだ.「補償の法則」は,頻度,余剰性,費用といった機能主義的な諸概念とも深く関係するだろう (see 「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1])) .
もっとも,この「補償の法則」は一般的に観察される傾向というべきものであり,通言語的にも反例は少なからずあるだろうし,逆の方向の通時的な変化もないわけではないだろう.
・ 樋口 時弘 『言語学者列伝 ?近代言語学史を飾った天才・異才たちの実像?』 朝日出版社,2010年.
2015-08-21 Fri
■ #2307. 綴字の余剰性 (2) [spelling][redundancy][statistics][information_theory][alphabet][final_e][silent_letter]
「#2249. 綴字の余剰性」 ([2015-06-24-1]) で取り上げた話題.別の観点から英語綴字の余剰性を考えてみよう.
Roman alphabet のような単音文字体系にあっては,1文字と1音素が対応するのが原理的に望ましい.しかし,言語的,歴史的,その他の事情で,この理想はまず実現されないといってよい.現実は理想の1対1から逸脱しているのだが,では,具体的にはどの程度逸脱しているのだろうか.
ここで,「#1159. MRC Psycholinguistic Database Search」 ([2012-06-29-1]) を利用して,文字と音素の対応の度合いをおよそ計測してみることができる.もし理想通りの単音文字体系であれば,単語の綴字を構成する文字数と,その発音を構成する音素数は一致するだろう.英語語彙を構成する各単語について,文字数と音素数の比を求め,その全体の平均値などの統計値を出せば,具体的な指標が得られるはずだ.綴字が余剰的 (redundancy) であるということはこれまでの議論からも予想されるところではあるが,具体的に,文字数対音素数の比は,2:1 程度なのか 3:1 程度なのか,どうなのだろうか.
まずは,MRC Psycholinguistic Database Search を以下のように検索して,単語ごとの,文字数,音素数,両者の比(=余剰性の指標)の一覧を得る(SQL文の where 以下は,雑音を排除するための条件指定).
select WORD, NLET, NPHON, NLET/NPHON as REDUNDANCY, PHON from mrc2 where NPHON != "00" and WORD != "" and PHON != "";
この一覧をもとに,各種の統計値を計算すればよい.文字数と音素数の比の平均値は,1.192025 だった.比を0.2刻みにとった度数分布図を示そう.
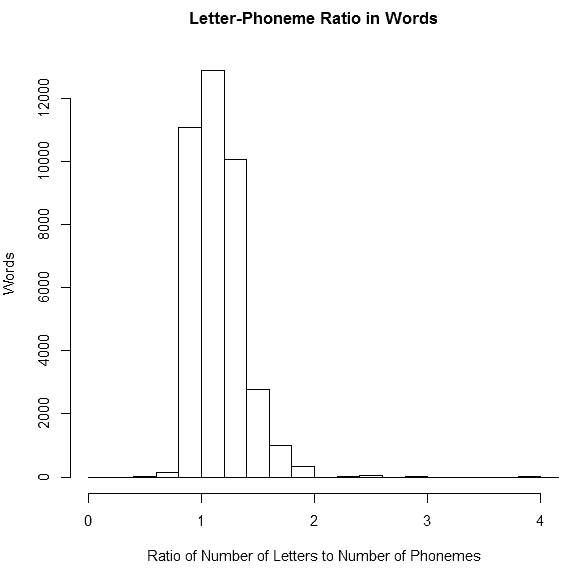
文字数別に比の平均値をとってみると,興味深いことに3文字以下の単語では余剰性は 1.166174 にとどまり,全体の平均値より小さくなる.一方,4文字から7文字までの単語では平均より高い 1.231737 という値を示す.8文字以上になると再び余剰性は小さくなり,1.157689 となる.文字数で数えて中間程度の長さの単語で余剰性が高く,短い単語と長い単語ではむしろ相対的に余剰性が低いようだ.この理由については詳しく分析していないが,「#1160. MRC Psychological Database より各種統計を視覚化」 ([2012-06-30-1]) でみたように,英単語で最も多い構成が8文字,6音素であるということや,final_e をはじめとする黙字 (silent_letter) の分布と何らかの関係があるかもしれない.
さて,全体の平均値 1.192025 で示される余剰性の程度がどれくらいのものなのか,ほかに比較対象がないので評価にしにくいが,主観的にいえば理想の値 1.0 から案外と隔たっていないなという印象である.英単語における文字と音素の関係は,「#2292. 綴字と発音はロープでつながれた2艘のボート」 ([2015-08-06-1]) の比喩でいえば,そこそこよく張られた短めのロープで結ばれた関係ともいえるのではないか.
ただし,今回の数値について注意すべきは,英単語における文字と音素の対応を一つひとつ照らし合わせてはじき出したものではなく,本来はもっと複雑に対応するはずの両者の関係を,それぞれの長さという数値に落とし込んで比を取ったものにすぎないということだ.最終的に求めたい綴字の余剰性そのものではなく,それをある観点から示唆する指標といったほうがよいだろう.それでも,目安となるには違いない.
2015-06-24 Wed
■ #2249. 綴字の余剰性 [spelling][orthography][cgi][web_service][redundancy][information_theory][punctuation][shortening][alphabet][q]
言語の余剰性 (redundancy) や費用の問題について,「#1089. 情報理論と言語の余剰性」 ([2012-04-20-1]),「#1090. 言語の余剰性」 ([2012-04-21-1]),「#1091. 言語の余剰性,頻度,費用」 ([2012-04-22-1]),「#1098. 情報理論が言語学に与えてくれる示唆を2点」 ([2012-04-29-1]),「#1101. Zipf's law」 ([2012-05-02-1]) などで議論してきた.言語体系を全体としてみた場合の余剰性のほかに,例えば英語の綴字という局所的な体系における余剰性を考えることもできる.「#1599. Qantas の発音」 ([2013-09-12-1]) で少しく論じた通り,例えば <q> の後には <u> が現われることが非常に高い確立で期待されるため,<qu> は余剰性の極めて高い文字連鎖ということができる.
英語の綴字体系は全体としてみても余剰性が高い.そのため,英語の語彙,形態,統語,語用などに関する理論上,運用上の知識が豊富であれば,必ずしも正書法通りに綴られていなくとも,十分に文章を読解することができる.個々の単語の綴字の規範からの逸脱はもとより,大文字・小文字の区別をなくしたり,分かち書きその他の句読法を省略しても,可読性は多少落ちるものの,およそ解読することは可能だろう.一般に言語の変化や変異において形式上の短縮 (shortening) が日常茶飯事であることを考えれば,非標準的な書き言葉においても,綴字における短縮が頻繁に生じるだろうことは容易に想像される.情報理論の観点からは,可読性の確保と費用の最小化は常に対立しあう関係にあり,両者の力がいずれかに偏りすぎないような形で,綴字体系もバランスを維持しているものと考えられる.
いずれか一方に力が偏りすぎると体系として機能しなくなるものの,多少の偏りにとどまる限りは,なんとか用を足すものである.主として携帯機器用に提供されている最近の Short Messages Service (SMS) では,使用者は,字数の制約をクリアするために,メッセージを解読可能な範囲内でなるべく圧縮する必要に迫られる.英語のメッセージについていえば,綴字の余剰性を最小にするような文字列処理プログラムにかけることによって,実際に相当の圧縮率を得ることができる.電信文体の現代版といったところか.
実際に,それを体験してみよう.以下の "Text Squeezer" は,母音削除を主たる方針とするメッセージ圧縮プログラムの1つである(Perl モジュール Lingua::EN::Squeeze を使用).入力するテキストにもよるが,10%以上の圧縮率を得られる.出力テキストは,確かに可読性は落ちるが,慣れてくるとそれなりの用を足すことがわかる.適当な量の正書法で書かれた英文を放り込んで,英語正書法がいかに余剰であるかを確かめてもらいたい.
2014-05-10 Sat
■ #1839. 言語の単純化とは何か [terminology][language_change][pidgin][creole][functionalism][functional_load][entropy][redundancy][simplification]
英語史は文法の単純化 (simplification) の歴史であると言われることがある.古英語から中英語にかけて複雑な屈折 (inflection) が摩耗し,文法性 (grammatical gender) が失われ,確かに言語が単純化したようにみえる.屈折の摩耗については,「#928. 屈折の neutralization と simplification」 ([2011-11-11-1]) で2種類の過程を区別する観点を導入した.
単純化という用語は,ピジン化やクレオール化を論じる文脈でも頻出する.ある言語がピジンやクレオールへ推移していく際に典型的に観察される文法変化は,単純化として特徴づけられる,と言われる.
しかし,言語における単純化という概念は非常にとらえにくい.言語の何をもって単純あるいは複雑とみなすかについて,言語学的に合意がないからである.語彙,文法,語用の部門によって単純・複雑の基準は(もしあるとしても)異なるだろうし,「#293. 言語の難易度は測れるか」 ([2010-02-14-1]) でも論じたように,各部門にどれだけの重みを与えるべきかという難問もある.また,機能主義的な立場から,ある言語の functional_load や entropy を計測することができたとしても,言語は元来余剰性 (redundancy) をもつものではなかったかという疑問も生じる.さらに,単純化とは言語変化の特徴をとらえるための科学的な用語ではなく,ある種の言語変化観と結びついた評価を含んだ用語ではないかという疑いもぬぐいきれない(関連して「#432. 言語変化に対する三つの考え方」 ([2010-07-03-1]) を参照).
ショダンソン (57) は,クレオール語にみられるといわれる,意味の不明確なこの「単純化」について,3つの考え方を紹介している.
(A) 「最小化」 ―― この仮説は,O・イエスペルセンによって作られた.イエスペルセンは,クレオール語のなかに,いかなる言語にとっても欠かせない特徴のみをそなえた最小の体系をみた.
(B) 「最適化」 ―― L・イエルムスレウの理論で,彼にとって「クレオール語における形態素の表現は最適状態にある」.
(C) 「中立化」 ―― この視点はリチャードソンによって提唱された.リチャードソンは,モーリシャス語の場合,はじめに存在していた諸言語の体系(フランス語,マダガスカル語,バントゥー語)があまりに異質であったために,体系の節減が起こったと考えた.
しかし,ショダンソンは,いずれの概念も曖昧であるとして「単純化」という術語そのものに疑問を呈している.フランス語をベースとするレユニオン・クレオール語からの具体的な例を用いた議論を引用しよう (57--58) .ショダンソンの議論は,本質をついていると思う.
単純化という概念そのものが自明ではない.たとえばレユニオン・クレオール語の mon zanfan 〔わたしのこども〕という表現は,フランス語で mon enfant 〔単数:わたしの子〕と mes enfants 〔複数:わたしの子供たち〕という二つの形に翻訳することができる.これをみて,レユニオン語は単数と複数とを区別しないから,フランス語より単純だといいたくなるかもしれないが,別の面からみれば,同じ理由から,クレオール語の表現はもっとあいまいだから,したがってより「単純」ではないともいえるだろう!実際,「単純」という語の意味は,「複合的ではない」とも,「明晰」「あいまいでない」ともいえるのである.しかし,上の例をさらによく調べるならば,レユニオン語は,はっきりさせる必要があるときは複数をちゃんと表わすことができることに気がつく.その時には mon bane zanfan (私の子供たち)のように〔bane という複数を表わす道具を用いて〕いう.だから,クレオール語とフランス語のちがいは,一部には,もっぱら話しことばであるクレオール語がコンテクストの要素に大きな場所をあたえていることによる.母親がしばらくの間こどもをお隣りさんにあずけるとき,vey mon zanfan! 〔うちの子をみてくださいね〕と頼んだとしよう.このときわざわざ,こどもが一人か複数かをはっきりさせる必要はない.他方で,口語フランス語では,複数をしめすには,たいていの場合,名詞の形態的標識ではなく,修飾語の標識によっている.だから,クレオール語で修飾語の体系を組み立てなおしたならば,それと同時に,数の表示にも手をつけることになるのである.しかし,これは別の過程から来るとばっちりにすぎない.
この数の問題についての逆説をすすめていくと,レユニオン・クレオール語は双数をもっているから,フランス語よりももっと複雑だということにもなろう.事実,レユニオン・クレオール語では,何でも二つで一つになっているもの(目,靴など)に対し,特別のめじるしがある.「私の〔二つの〕目」については,mon bane zyé ということはできず,mon dé zyé といわなければならない.同様に「私の〔一つの〕目」といいたいときは,mon koté d zyé という.koté d と dé は,双数用の特別のめじるしである.したがって,mon bane soulie は,何足かの靴を指すことしかできないのである.
このような事情があるから,「単純化」ということばは使わないにこしたことはない.この語には〔クレオール語を劣ったものとみる〕人種主義的なニュアンスがあるし,機能的,構造的に異なる言語を比較している以上,事柄を具体的に解明するには,あまりに精密を欠き,あいまいだからである.「再構造化」といったほうがずっといい.「再構造化」という語のほうがもっと中立的であるし,他の多くの用語(単純化,最小化,最適化)とことなり,明らかにしようとしている構造的なちがいの原因を,偏見の目で判断しないという利点がある.
上の最初の引用にあるイエスペルセンの言語観については「#1728. Jespersen の言語進歩観」 ([2014-01-19-1]) を,イエルムスレウについては「#1074. Hjelmslev の言理学」 ([2012-04-05-1]) を参照.
・ ロベール・ショダンソン 著,糟谷 啓介・田中 克彦 訳 『クレオール語』 白水社〈文庫クセジュ〉,2000年.
2013-09-12 Thu
■ #1599. Qantas の発音 [acronym][pronunciation][information_theory][redundancy][alphabet][q]
8月後半にオーストラリアに出かけていたが,その往復に初めて Qantas 機を利用した.成田・シドニー路線の機内は非常に広々としており,実に快適なフライトだった.日本語では「カンタス」と呼び習わしているが,機内の放送で [ˈkwɑntəs] の発音を聞いた.Q の文字に対応するだけに,子音は [k] ではなく [kw] なのだ.
Qantas は "Queensland and Northern Territory Aerial Services" の頭字語 (acronym) である.1920年に名前の通りオーストラリアのローカルな航空会社として創設されたが,47年に国営化され,現在では世界有数の国際的な航空会社である.創業してから無事故とされ(事故の定義にもよるが),安全面での評価も高い.
英語本来語あるいは英語に入って歴史の長い語のなかでは,通常 <q> は単独で用いられることはなく,<qu> と必ず直後に <u> を伴う.歴史的には,古英語で <cw> と綴られていたものが,中英語でフランスの写字習慣に習って <qu> と綴られるようになったものだ.<q> の後に原則として <u> が続くということは,情報価値という観点から言い換えれば「<u> の情報量はゼロである」ということになる.<u> が続くことは100%予想できるので,<u> はなくても同じということになるからだ.機能上,<q> の後の <u> は不要ということになるのだが,<qu> の連続に慣れてしまった目には <q> 単独は妙に見える.綴字レベルでも,言語の余剰性 (redundancy) が作用している証だろう.
もっとも,頭字語,アラビア語や中国語からの借用語など,完全に英語に同化したとはみなせない語群では,<q> の後に <u> が続かないことも多い.表題の Qantas は綴字としては <q> 単独で用いられているが,発音としては単独の [k] ではなく [kw] を示している.Qatar [ˈkæːtɑː], qibla(h) [ˈkɪblə], Qing [ʧɪŋ], また <u> が後続するものの [kw] を示さない Quran [kɔːˈrɑːn] も参照.
なお,「#308. 現代英語の最頻英単語リスト」 ([2010-03-01-1]) の末尾で見たように,<q> は英語で <z> に次いで最も使用頻度の低いアルファベットの文字である(<z> については z の各記事を参照).キーボードのQWERTY配列でも,その名が示すとおり,<Q> は左手の小指を差しのばして打たなければならない日陰者である.QWERTY 自体が一種の頭字語であり,<q> の後に <w> が続き,かつ [w] が発音されるまれな例である.
2012-04-29 Sun
■ #1098. 情報理論が言語学に与えてくれる示唆を2点 [information_theory][redundancy][corpus]
##1089,1090,1091 の記事で,言語学が情報理論 (information theory) から得られる知見について,特に言語の余剰性 (redundancy) に注目しながら紹介した.今回は,Jakobson による "Linguistics and Communication Theory" と題する論文にしたがって,情報理論が言語学に与えてくれるヒントを考えてみたい.
Jakobson は,彼の提示した二進法的な音素の示差的特徴 (distinctive feature) と,情報理論における基本単位である "digit" あるいは "bit" との親和性に気づき,(構造)言語学と情報理論の接点に注目した.Jakobson は両分野の共通点と相違点を洗い出し,言語学が情報言語から学べることは何か,両者の間で同一視してはいけないことは何かということを論じている.その中で特に2点が私の関心に引っかかったので,紹介したい.
(1) 情報理論は,もっぱら物理的な情報伝達の効率や情報体系の仕組み (code) に関心があり,その発信者,受信者,文脈,意味は考慮しない.言語体系も code ではあるが,それは言語行動が必要とする諸側面の1つにすぎず,code のみに注目する態度は避けるべきである.code が1側面にすぎないことは「#1070. Jakobson による言語行動に不可欠な6つの構成要素」 ([2012-04-01-1]) で見たとおりである.
There is a similar danger when interpreting human inter-communication in terms of physical information. Attempts to construct a model of language without any relation either to the speaker or to the hearer and thus to hypostasize a code detached from actual communication threaten to make a scholastic fiction from language. (250)
(2) 言語学が (1) の注意点を意識した上で,情報理論の手法を用いて言語体系の効率を測ろうとするとき,二項対立の体系としての理論的な効率と,言語項目の頻度を考慮した実際上の効率との両方を視野に入れておかなければならない.前者は type 的,langue 的な意味での効率,後者は token 的,parole 的な意味での効率といえばわかりやすいだろうか.Jakobson は,音素の示唆的特徴だけでなく形態カテゴリーも二項対立で記述でき,最終的には統語をも "bit" によって記述できると考えており,それにより言語Aと言語Bの文法情報の効率なども比較できるだろうとしているが,これは抽象化された言語体系としての code の効率のことを指している.一方で,言語使用の実際における情報伝達の効率を測ろうとすれば,言語項目の出現頻度を加味した情報の重みづけという作業が必要である.理論と実際のバランスが肝要ということである.
The amount of grammatical information which is potentially contained in the paradigms of a given language (statistics of the code) must be further confronted with a similar amount in the tokens, in the actual occurrences of the various grammatical forms within a corpus of messages. Any attempt to ignore this duality and to confine linguistic analysis and calculation only to the code or only to the corpus impoverishes the research. The crucial question of relationship between the patterning of the constituents of the verbal code and their relative frequency both in the code and in its use cannot be passed over. (251)
(2) の教訓を現代の言語研究に引きつけて解釈すると,構造言語学とコーパス言語学の連携というような課題につながってくるのではないか.コーパスによって得られた統計値をもとに各言語項目に重みづけを行ない,それを対立の集合として記述された言語体系のパラメータとして含めてやる.そうすることによって,Martinet の主張する言語の経済性の原理 ([2012-03-24-1], [2012-04-21-1]) なども検証可能となるのではないか.
・ Jakobson, Roman. "Linguistics and Communication Theory." Structure of Language and Its Mathematical Aspects. Providence: American Mathematical Society, 1961. 245--52.
2012-04-22 Sun
■ #1091. 言語の余剰性,頻度,費用 [redundancy][information_theory][frequency][shortening][grammaticalisation][idiom][intensifier][language_change]
本ブログでも度々取り上げている André Martinet (1908--99) は,情報理論の知見を言語学に応用し,独自の地平を開いた構造言語学者である.[2012-04-20-1], [2012-04-21-1]の記事で,言語の余剰性 (redundancy) の問題に触れてきたが,Martinet は余剰性と関連させて確率 (probability) ,情報 (information) ,頻度 (frequency) ,費用 (cost) といった概念をも導入し,これらの関係のなかに言語変化の原因を探ろうとした.以下は,これらの用語を導入した後の一節である(拙訳つきで).
Ce qu'il convient de retenir de tout ceci pour comprendre la dynamique linguistique se ramène aux constatations suivantes : il existe un rapport constant et inverse entre la fréquence d'une unité et l'information qu'elle apporte, c'est-à-dire, en un certain sens, son efficacité ; il tend à s'établir un rapport constant et inverse entre la fréquence d'une unité et son coût, c'est-à-dire que représente d'énergie consommée chaque utilisation de cette unité. Un corollaire de ces deux constatations est que toute modification de la fréquence d'une unité entraîne une variation de son efficacité et laisse prévoir une modification de sa forme. Cette dernière pourra ne se produire qu'à longe échéance, car les condition réelles du fonctionnement des langues tendent à freiner les évolutions. (189--90)
言語の力学を理解するために,このこと全体について理解すべきことは,次の確認事項である.ある単位の頻度とそれがもつ情報(すなわちある意味ではその効果)のあいだには一定にして反比例の関係がある;それは,ある単位の頻度とその費用(すなわちその単位を使用することで消費されるエネルギー)のあいだの一定にして反比例の関係となる傾向がある.この2つの確認事項の当然の帰結として,ある単位の頻度が変わればその効果も変化するし,その形態の変化も予想されることになる.この後者の変化はあくまで長期間をかけて生じるものである.というのは,言語作用の現実の状況は発達を抑制する傾向があるからだ.
Martinet は,引用した節よりも前の箇所で,余剰性が高いということは予測可能性が高いということであり,それは言語要素の出現確率あるいは頻度とも密接に関連するということを論じている.一般に,言語要素は頻度が高ければ余剰性も高く,情報価値は低い: "plus une unité (mot, monème, phonème) est fréquente, moins elle est informative" (188) .そして,ここに費用という要素を持ち込むことによって,新たな洞察が得られた.話者にとって,頻度が高ければ高いほど,その1回の発音に必要とされるエネルギーの量は少ないほうが都合がよい.多くのエネルギーを要する発音を何度も繰り返すのは不経済だからだ.逆に,頻度の低い表現は,たとえ発音に大きなエネルギーが必要だとしてもあまり困らない.いずれにせよ,発音する機会が稀だからだ.
このように,「費用」を発音にかかるエネルギー量と解釈する場合,厳密には個々の音の発音がどのくらいの費用を要するかを知る必要があるが,その計測は難しい.しかし,仮にすべての単音の発音が同じ程度の費用を要すると仮定すれば,特定の表現に要する費用はその音形の長さに依存するはずである.費用を単純に音形の長さと同値とすれば,次の関係が想定できる:「言語要素は,頻度が高ければ音形が短い」.これを言語変化に当てはめれば「言語要素は,頻度が高くなれば音形が短くなる」となろう.
頻度と費用の反比例の関係は,経験的によく理解できる.よく使われる語句は発音においても表記においても短縮・省略される傾向がある.場合によっては,短縮・省略の究極の結末として,無に帰すことすらある.文法的な慣用表現が短縮した上で固定化する例もよく見られ,これは文法化 (grammaticalisation) として扱われる話題にほかならない.また,[2012-01-14-1]の記事で取り上げた「#992. 強意語と「限界効用逓減の法則」」も,頻度と費用の関係という観点からとらえなおすことができるだろう.
ただし,上の引用の最後にある通り,頻度と費用の関係から言語変化を説明しようとする際には,時間差を考慮する必要がある.ある語の頻度が増してきてからその語形が短縮されるまでには,当然,ある程度の時間が必要だからだ.また,頻度と費用の負の相関関係は,あくまで緩やかなものであることにも注意しておく必要がある.上の一節に先行する標題が "Laxité du rapport entre fréquence et coût" (頻度と費用の関係の緩やかさ)であることを付け加えておこう.
・ Martinet, André. Éléments de linguistique générale. 5th ed. Armand Colin: Paris, 2008.
2012-04-21 Sat
■ #1090. 言語の余剰性 [redundancy][linguistics][entropy][information_theory][paralinguistics]
ヒトの言語の著しい特徴として,以前の記事で「#766. 言語の線状性」 ([2011-06-02-1]) と「#767. 言語の二重分節」 ([2011-06-03-1]) を取り上げてきたが,もう1つの注目すべき特徴としての余剰性 (redundancy) については,明示的に取り上げたことがなかった.今日は,昨日の記事「#1089. 情報理論と言語の余剰性」 ([2012-04-20-1]) を受けて,この特徴について説明したい.
言語による意味の伝達に最小限に必要とされる以上の記号的要素が用いられるとき,そこに余剰性が含まれているといわれる.言語の余剰性は一見すると無駄で非効率に思われるが,昨日の記事で述べたように,言語使用に伴う種々の雑音 (noise) に対する強力な武器を提供している.急ハンドルの危険を防止するハンドルの遊びと言い換えてもよいし,無用の用と考えてもよい.また,言語の余剰性は,言語習得にも欠かせない.言語構造上また言語使用上の余剰性が十分にあれば未知の言語要素でも意味の予測が可能であり,実際に言語習得者はこの機構を利用して,言語内的・外的な文脈からヒントを得ながら,意味の見当をつけてゆくのである.
余剰性という観点から言語を見始めると,それは言語のあらゆる側面に関わってくる要素だということがわかる.まず,昨日の記事で触れたように,音声と音素の情報量の差に基づく余剰性がある.言語の伝達には数十個の分節された音素を区別すれば事足りるが,その実現は音声の連続体という形を取らざるを得ず,そこには必要とされるよりも約千倍も多くの音声信号が否応なしに含まれてしまう.
音韻体系にみられる対立 (opposition) に関係する余剰性もある.英語において,音素 /n/ は有声歯茎鼻音だが,鼻音である以上は有声であることは予測可能であり,/n/ の記述に声の有無という対立を設定する必要はない.これは,余剰規則 (redundancy rule) と呼ばれる.
音素配列にも余剰性がある.語頭の [s] の直後に来る無声破裂音は必ず無気となるので,無気であることをあえて記述する必要はない([2011-02-18-1]の記事「#662. sp-, st-, sk- が無気音になる理由」を参照).予測可能であるにもかかわらず精密に記述することは不経済だからである.しかし,言語使用の現場で,語頭の [s] は何らかの雑音で聞こえなかったが,直後の [t] は無気として聞こえた場合,直前に [s] があったに違いないと判断し,補うことができるかもしれない.このように,余剰性は安全装置として機能する.
音素配列に似た余剰性は,綴字規則にも見られる.例えば,英語では頭字語などの稀な例外を除いて,<q> の文字の後には必ず <u> が来る.<u> はほぼ完全に予測可能であり,情報量はゼロである.
形態論や統語論における余剰性の例として,These books are . . . . というとき,主語が複数であることが3語すべてによって示されている.It rained yesterday. では,過去であることが2度示されている.英語史上の話題である二重複数 (double_plural),二重比較級 (double_comparative),二重否定 ([2010-10-28-1], [2012-01-10-1]) なども,余剰性の問題としてみることができる.
そのほか,類義語を重ねる with might and main, without let or hindrance や,電話などでアルファベットの文字を伝える際の C as in Charley などの表現も余剰的であるし,Yes と言いながら首を縦に振るといった paralinguistic な余剰性もある.
余剰性と予測可能性 (predictability) は相関関係にあり,また予測可能性は構造の存在を前提とする.したがって,言語に余剰性があるということは,言語に構造があるということである.ここから,余剰性を前提とする情報理論と,構造を前提とする構造言語学とが結びつくことになった.構造言語学の大家 Martinet の主張した言語の経済性の原理でも,余剰性の重要性が指摘されている (183--85) .
情報理論と言語の余剰性の関係については,Hockett (76--89) を参照.
・ Martinet, André. Éléments de linguistique générale. 5th ed. Armand Colin: Paris, 2008.
・ Hockett, Charles F. "Review of The Mathematical Theory of Communication by Claude L. Shannon; Warren Weaver." Language 29.1 (1953): 69--93.
2012-04-20 Fri
■ #1089. 情報理論と言語の余剰性 [information_theory][linguistics][redundancy][entropy][history_of_linguistics]
情報理論 (information theory) は戦後に発達した比較的新しい科学研究だが,言語学はその成果を様々な形で享受してきた.情報の送り手と受け手の問題,コード化の問題,予測可能性 (predictability) の問題,そして何よりも言語の顕著な特徴の1つである余剰性 (redundancy) の問題について,言語学が情報理論から学べることは多い.
情報理論と人工頭脳工学 (cybernetics) の基礎理論は Shannon and Weaver の著作によって固まったとされ,これは言語学史においても有意義な位置を占めている(イヴィッチ,pp. 164--71).しかし,この著作は高度に数学的であり,一般の言語学者が読んで,その成果を言語学へ還元するということは至難の業のようだ.このような場合には,言語学者による書評が役に立つ.アメリカの言語学者 Hockett の書いているレビューを読んでみた.
Shannon and Weaver 自体が難解なのだから,その理論のレビューもある程度は難解とならざるをえない.評者の Hockett が情報理論の考え方を言語学へ応用する可能性について論じている部分では,言語学としても非常に高度な内容となっている.書評を完全に理解できたとは言い難いが,言語の余剰性およびエントロピー (entropy) についての議論はよく理解できた.
Hockett はたいへん大まかな試算であるとしながらも,ある発話の音韻的な情報量と音声的な情報量の比は1:1000ほどの開きがあり,仮に音韻論的単位のみを意思疎通に不可欠な単位とみなすのであれば,言語音の余剰性は99.9%にのぼるとしている (85) .情報理論でいうエントロピー (entropy) は,"1 - redundancy" と定義されるので,言語音のエントロピーは0.1%である.言語は,ある言い方をすれば非効率,別の言い方をすれば予測可能性の高い種類の情報体系ということができるだろう.
情報が物理的に伝達される際には,多かれ少なかれ必ず雑音 (noise) が含まれてしまう.したがって,情報伝達が意図された通りに遂行されるためには,雑音による影響に耐えられるだけの安全策が必要となる.言語にとって,余剰性こそがその安全策である.Hockett 曰く,"channel noise is never completely eliminable, and redundancy is the weapon with which it can be combatted" (75) .このように考えると,言語音の余剰性99.9%(あるいはこれに近似する高い値)は,いかに言語が慎重に雑音対策を施された安全設計の情報体系であるかを示す指標といえるだろう.
The high linguistically relevant redundancy of the speech signal can be interpreted not as a sign of low efficiency, but as an indication of tremendous flexibility of the system to accommodate to the widest imaginable variety of noise conditions. (Hockett 85)
情報理論の立場から,特に余剰性という観点から言語を見始めると,それは言語のあらゆる側面に関わってくる要素だということがわかってくる.言語の余剰性について,明日の記事で詳しく見ることにする.
・ ミルカ・イヴィッチ 著,早田 輝洋・井上 史雄 訳 『言語学の流れ』 みすず書房,1974年.
・ Hockett, Charles F. "Review of The Mathematical Theory of Communication by Claude L. Shannon; Warren Weaver." Language 29.1 (1953): 69--93.
・ Shannon, Claude L. and Warren Weaver. The Mathematical Theory of Communication. Urbana: U of Illinois P, 1949.
Powered by WinChalow1.0rc4 based on chalow