LAEME text database で扱われている scribal texts の数は,LAEME Index of Sources (PDF) によると,ざっと168個だが,そのなかで地図上の位置が特定されているものは121個(約72%)である.位置情報は Ordinance Survey National Grid Reference として得られるし,各テキストについてタグ付けされている語数も得られるので,組み合わせれば,データ点ごとにどの程度の規模のテキストがコーパスとして利用できるか,地図上に表現することができることになる.この作業を,[2011-08-21-1]の記事「HelMapperUK --- hellog 仕様の英国地図作成 CGI」で公開した地図作成ツールを用いて行なった.以下が結果である.
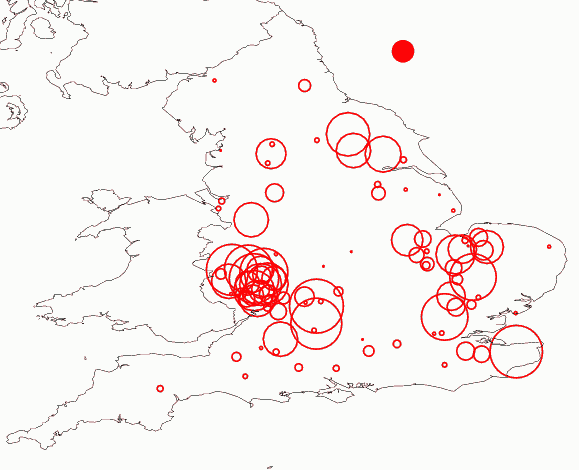
異なるデータ点は96を数え,データ点と関連づけられるテキスト(群)を構成する語数の平均値は6307語ほどである(タグ付けされた語数はこれより若干下回る).凡例として地図の右上に示した赤塗りの円の面積がこの平均語数に相当し,この面積を基準として,各データ点が,語数に相当する面積をもつ白抜きの赤丸として描かれている(参考までに,HelMapperUK に読み込ませたデータはこちら).
地図を眺めて直感的にわかることは,データ点にせよ収録語数にせよ,South-West Midland と South-East Midland に随分と集中しているということである.これは,LAEME の編者の1人である Laing が自らの論文 "Never the twain shall meet" で注意を喚起している通りである.LAEME のテキストの位置特定は,LALME が編み出した "fit technique" という理論的手法に負っているが,この手法の成否の鍵は "anchor texts" と呼ばれる確実な出発点が多く手に入るかどうかという点にある.だが,残念なことに,後期中英語と異なり初期中英語では "anchor texts" が格段に少ない."anchor texts" は,後の理論的な位置特定に際して磁石のように機能するため,出発点が東や西に離れて分布していると,これから "fit" させようと思っているテキストも相対的に東西のどちらか側に引きつけられてしまうという結果になることが多い.Midland の中央にデータ点がまばらなのは,このような事情にも帰せられる.
地図作成ツール HelMapperUK は,半ば LAEME の活用のために作ったようなものだが,LAEME 自体を分析するのにも利用できそうだ.
なお,LAEME Index of Sources は先に貼り付けたリンク より PDF で入手できるが,その他にもLAEME のトップページ から Auxiliary Data Sets -> Index of Sources とたどると,様々なパラメータによりソーステキストの情報検索ができる.
・ Laing, Margaret. "Never the twain shall meet: Early Middle English --- The East-West Divide." Placing Middle English in Context. Ed. I. Taavitsainen et al. Berlin: Mouton de Gruyter, 2000. 97--124.
・ McIntosh, Angus, M. L. Samuels, and M. Benskin. A Linguistic Atlas of Late Mediaeval English. 4 vols. Aberdeen: Aberdeen UP, 1986.