2015-03-09 Mon
Ę£ #2142. √śĪ—łž§ň§™§Ī§Ž3√ĪłĹ§™§Ť§” £łĹ§őłž»Ý§ő żłņ ¨…Ř [map][laeme][lalme][me_dialect][me][3sp][3pp][verb][conjugation][nptr]
°°…ł¬Í§őŐš§§§ňľÍ§√ľŤ§ÍŃŠ§ĮŇķ§®§Ž§ň§Ō°§ľ°§ő…ŧ«ĽŲ¬≠§Í§Ž° Görlach (68) §ň§Ť§Ž…ŧőįž…ۧŤ§Í°ň°•
| South | Midland | North | ||
| Present Indicative | 3sg. | -(e)þ | -(e)þ | -(e)s |
| pl. | -(e)þ | -(e)n | -(e)s | |
°°§≥§ž§Ú√ŌŅř匧ňľ®§Ļ§»°÷#790. √śĪ—łž żłņ§ň§™§Ī§Ž∆įĽž∂Ģņřłž»Ý§ő ¨…Ř°◊ ([2011-06-26-1]) §őńէͧ»§ §Ž§¨°§§Ť§Í勧∑§§ ¨…اÚ∆ņ§Ņ§§§»§≠§ň§Ō LAEME ° ĹťīŁ√śĪ—łž°ň§» eLALME ° łŚīŁ√śĪ—łž°ň§ÚĽ≤廧Ļ§Ž§ő§¨ ōÕݧ«§Ę§Ž (cf. °÷#1622. eLALME°◊ ([2013-10-05-1])) °•į ≤ľ§«§Ō°§őĺ•Ę•»•ť•Ļ§Ť§Í∆ņ§ť§ž§Ņ√ŌŅř§ő≤ŤŃŁ§ÚŇŧͅ’§Ī§Ť§¶° •Į•Í•√•Į§Ļ§Ž§»§Ť§Í¬Á§≠§ĮŚļőÔ§ ≤ŤŃŁ§¨∆ņ§ť§ž§Ž°ň°•§ř§ļ§Ō°§1150--1325«Į§Ú•ę•–°ľ§Ļ§Ž LAEME §Ť§Í°§3√ĪłĹ° ļł°ň§» £łĹ° Ī¶°ň§őłž»Ý§ő ¨…اڧŧž§ĺ§žľ®§Ļ°•
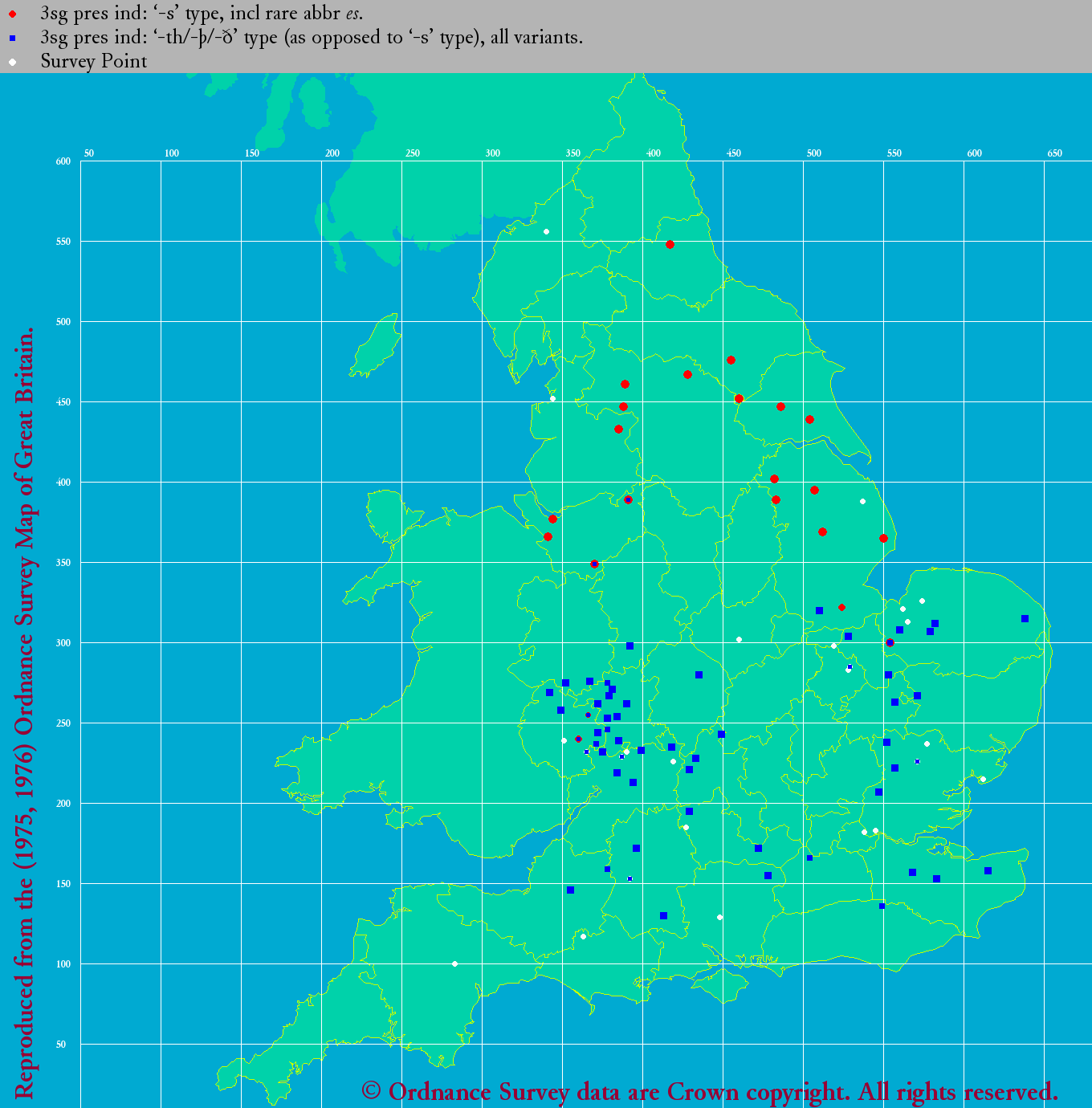 |
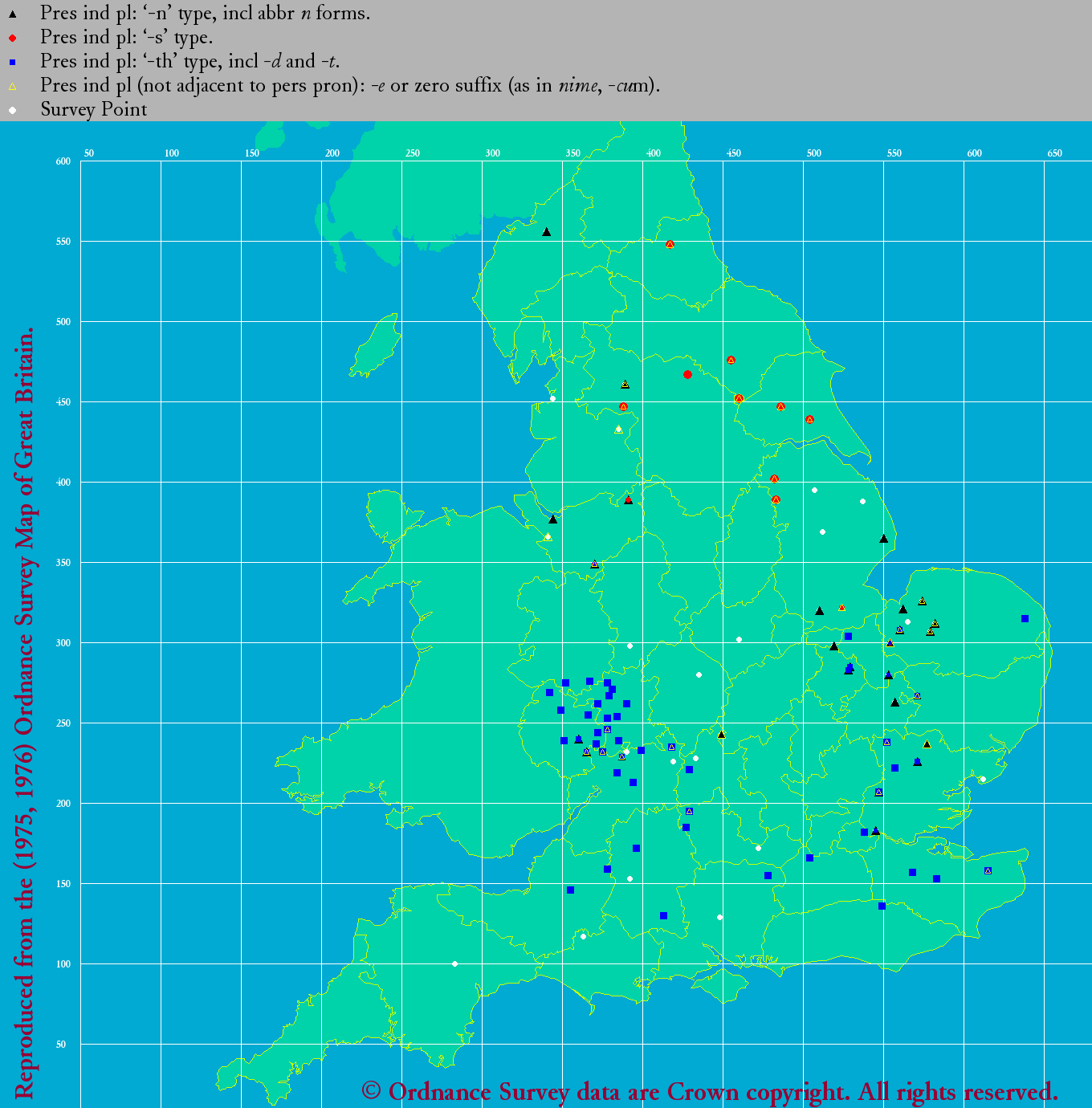 |
| LAEME: 3sp 's' and 'th' | LAEME: pp 's', 'th', 'n', 'e', and zero |
°°őĺ√ŌŅř§«ňՅۧňĹł§ř§Žņ÷ī›§¨ -s §Ú°§∆ӅۧňĹł§ř§ŽņńĽÕ≥—§¨ -th §Ú…ŧĻ°•Ī¶§ő £łĹ§őłž»Ý§«§ŌŇž√ś…ۧŧő¬ĺ§ňĻűĽį≥—§¨Ľ∂ļŖ§∑§∆§§§Ž§¨°§§≥§ž§Ō -n łž»Ý§Ú…ŧĻ°•ľ°§ň°§ £Ņ۬ŚŐ弞§»ņ‹§Ļ§Ž∆įĽž§őłĹļŖ∑ѧ¨ -e §ř§Ņ§Ō•ľ•Ū§őłž»Ý§Ú§»§Ž "Northern Present Tense Rule" (NPTR; cf. °÷#689. Northern Personal Pronoun Rule §»Ī— łň°§ň§™§Ī§Ž•Ī•Ž•»łž§őĪ∆∂Ń°◊ ([2011-03-17-1])°§nptr) §ő ¨…ŘŅř§Úłę§Ť§¶°•
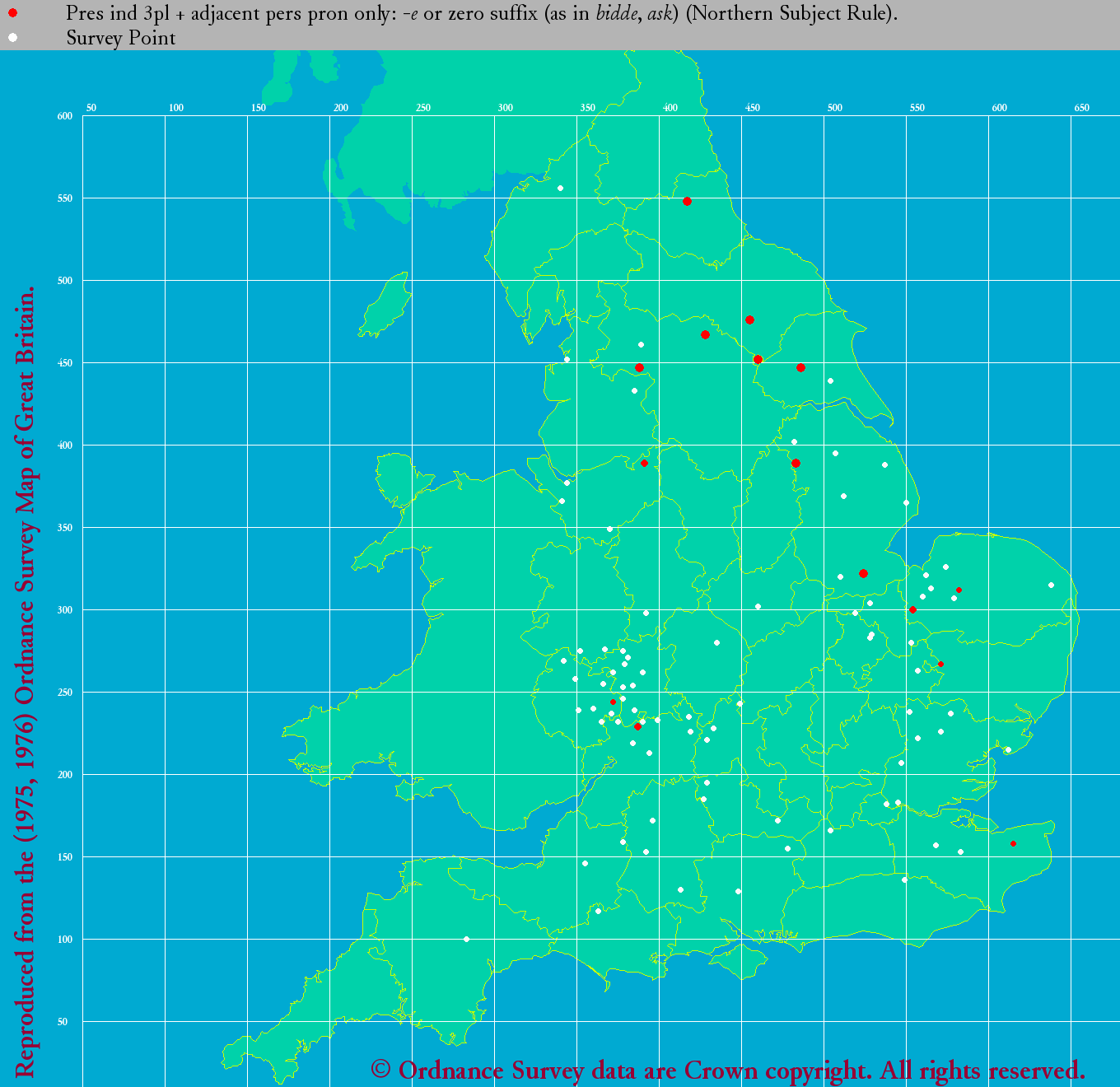
|
| LAEME: NPTR pp 'e' and zero |
°°§«§Ōľ°§ňłŚīŁ√śĪ—łž§ő ¨…اňį‹§Ž°•eLALME §«§Ō°§łž»Ý§őľÔőŗ§ī§»§ň Ő°Ļ§ő√ŌŅř§ÚļÓņģ§∑§Ņ°•§ř§ļ§Ō3√ĪłĹ§ę§ť°•
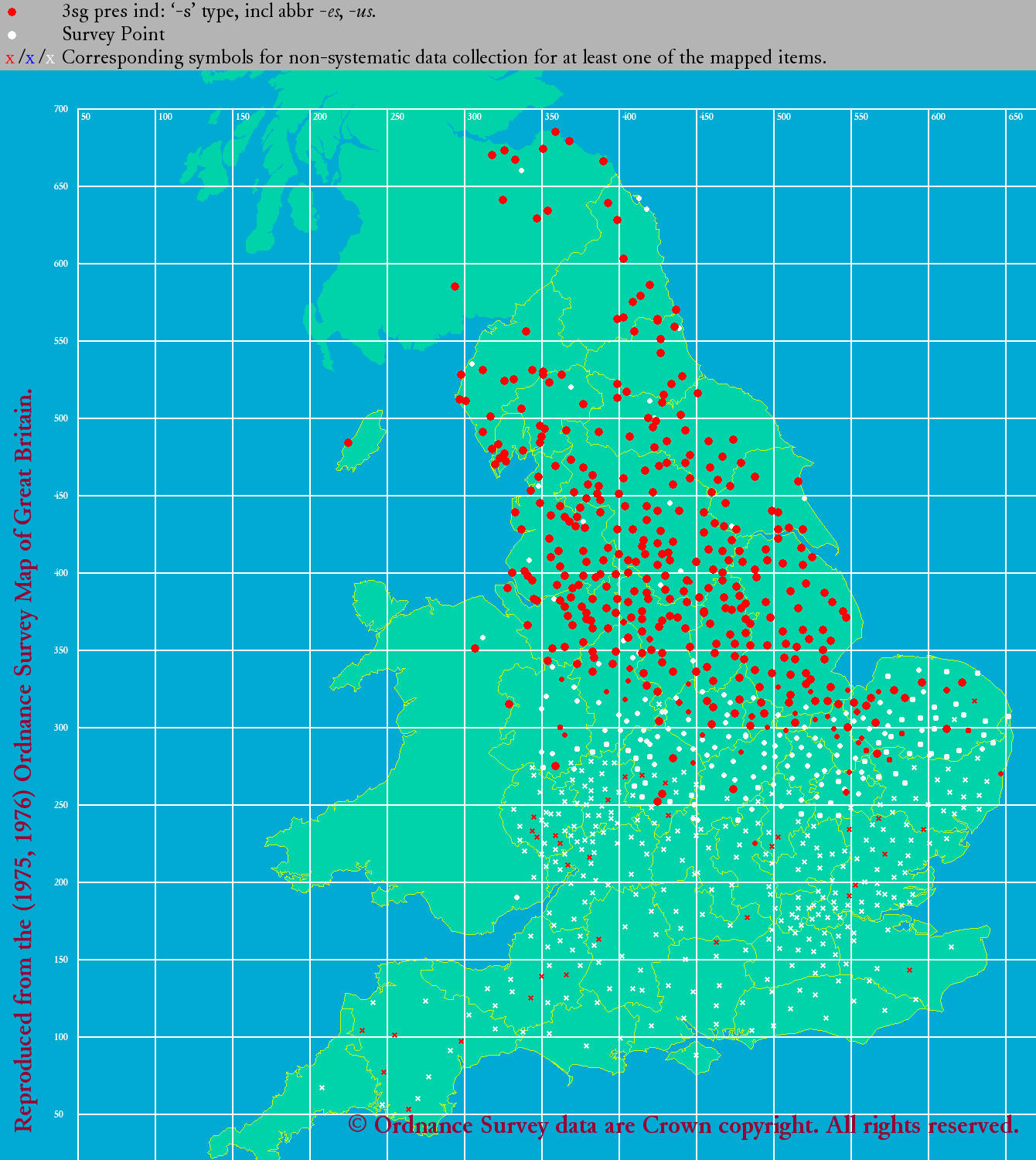 |
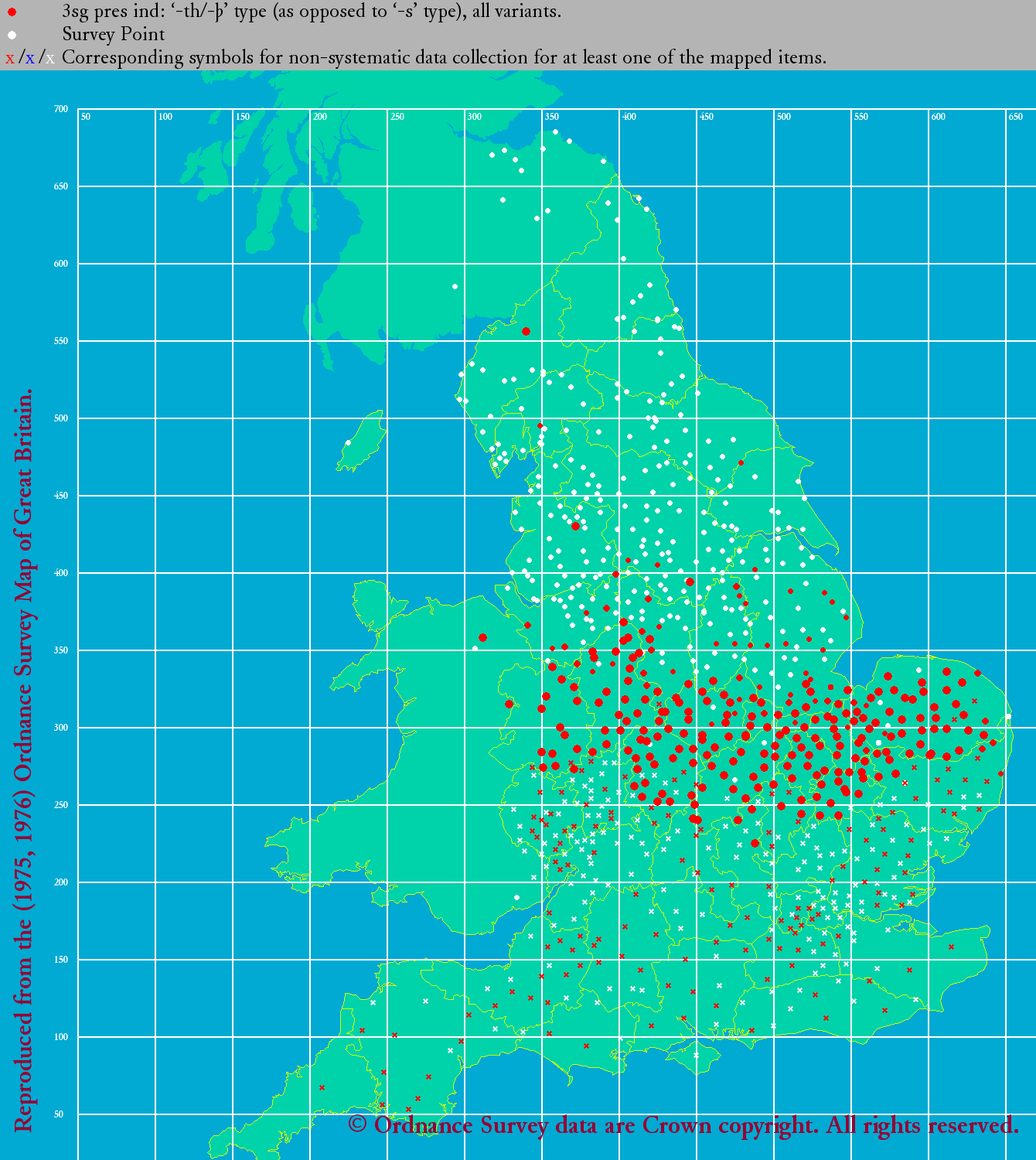 |
| eLALME: 3sp 's' | eLALME: 3sp 'th' |
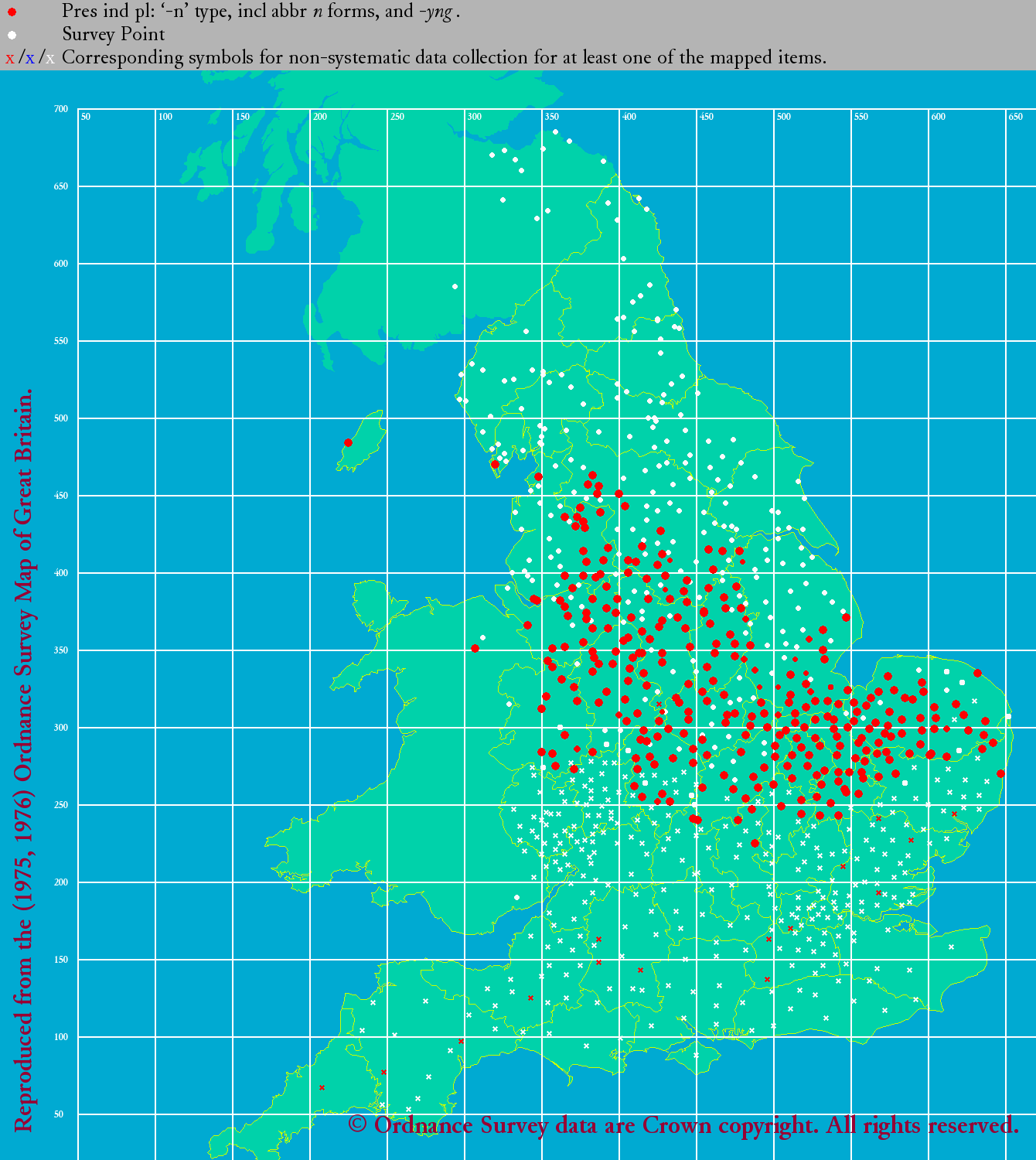
°°ŃįĽĢ¬Ś§ő ¨…اڧŤ§Įľű§Ī∑—§§§«§™§Í°§ļłŅř§őńŐ§Í -s §¨ňՅۧň°§Ī¶Ņř§őńŐ§Í -th §¨√ś…Űį ∆Ó§ň ¨…ا∑§∆§§§Ž§ő§¨§Ô§ę§Ž°• £łĹ§ň§ń§§§∆§Ō°§-s, -th, -n, -e (or zero) §ő4ľÔőŗ§ň§ń§§§∆≥∆°Ļ§ő√ŌŅř§Úłę§∆§Ŗ§Ť§¶°•
 |
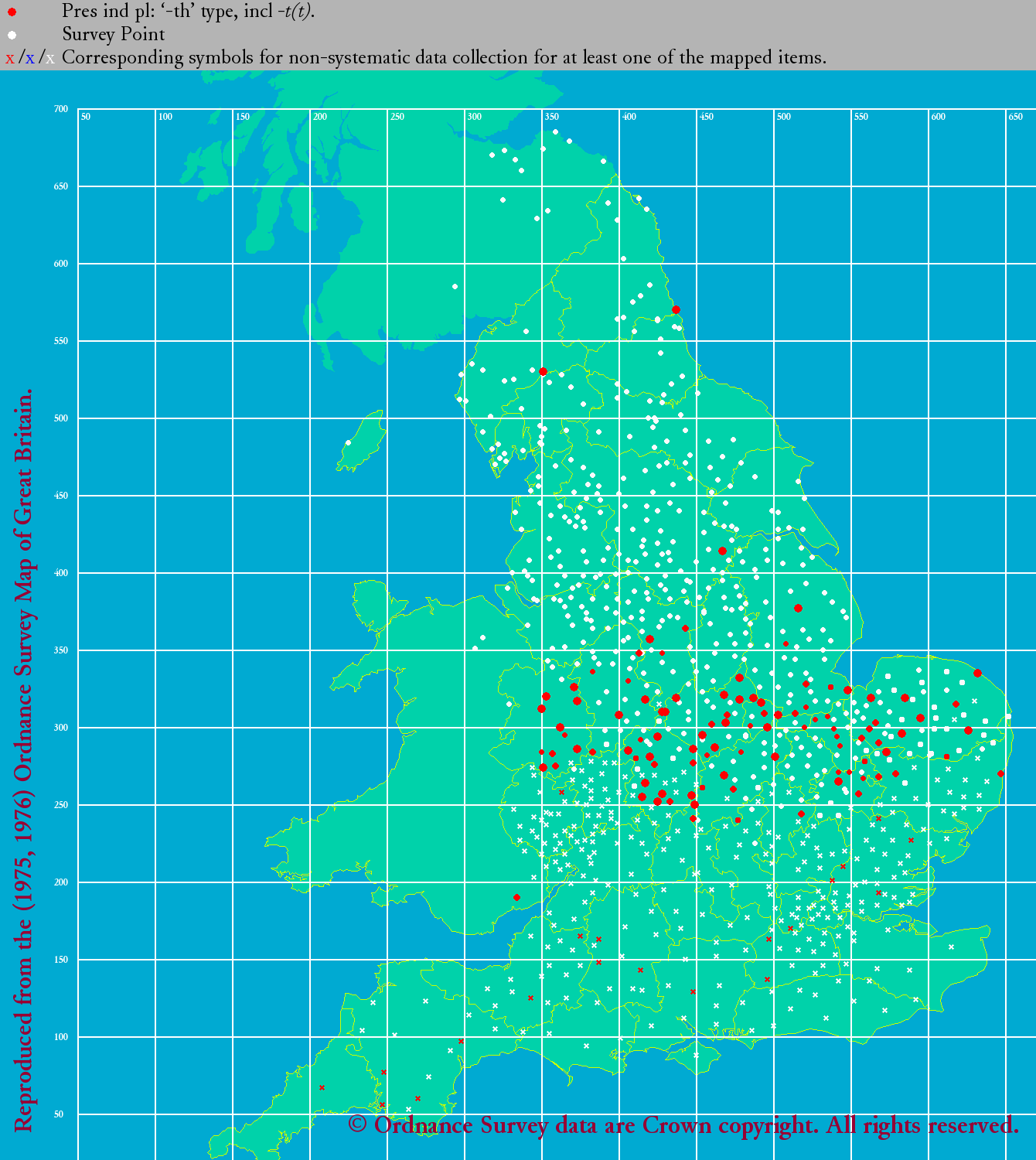 |
| eLALME: pp 's' | eLALME: pp 'th' |
 |
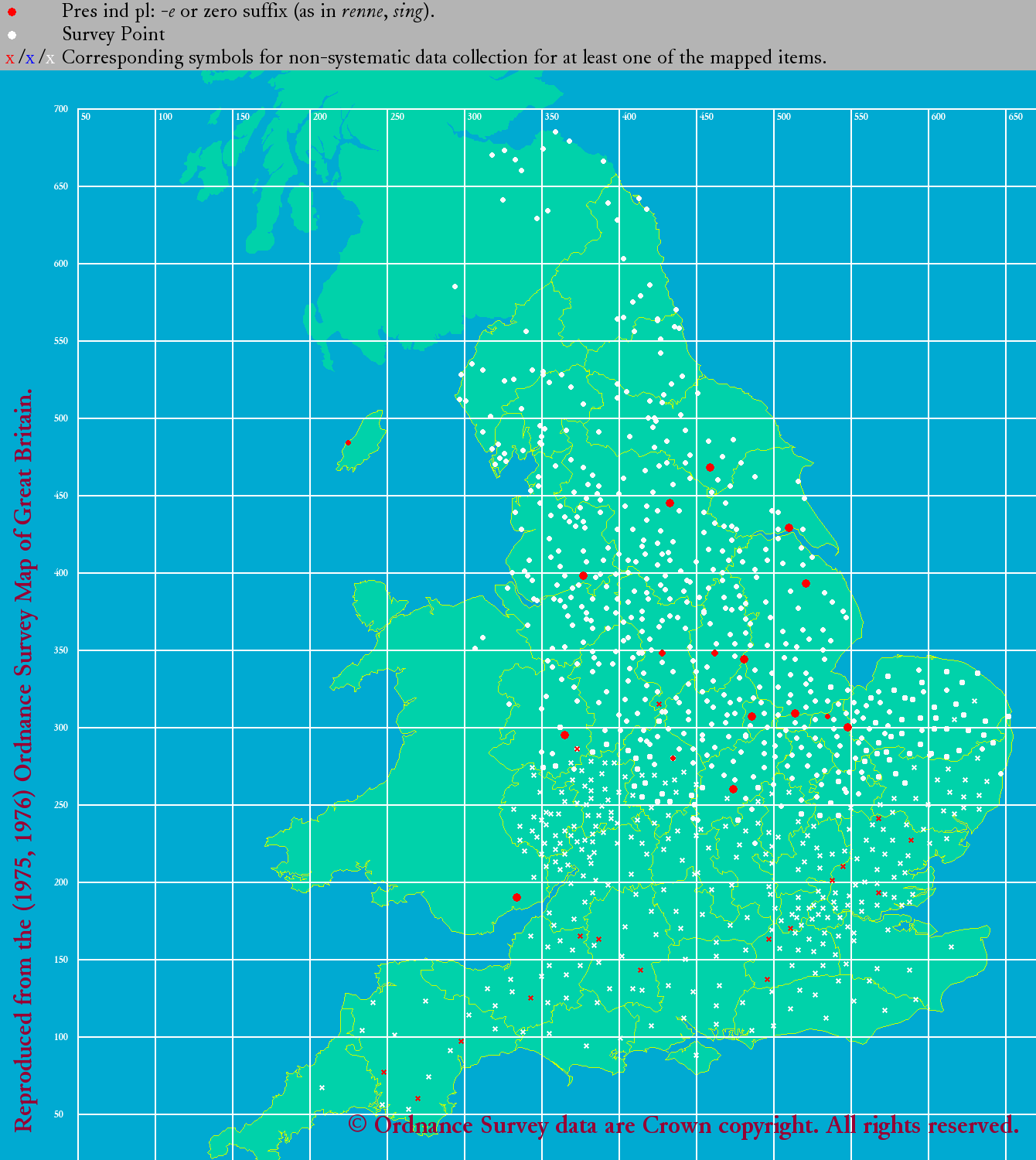 |
| eLALME: pp 'n' | eLALME: pp 'e' or zero |
°°§≥§Ń§ť§‚ŃįĽĢ¬Ś§ő ¨…اڧŤ§Įľű§Ī∑—§§§«§™§Í°§ňՅۧ« -s ° ļłĺŚŅř°ň°§√ś…Űį ∆Ó§« -th ° Ī¶ĺŚŅř°ň§¨Õ•ņ™§ņ§¨°§√ś…ۧ« -n ° ļł≤ľŅř°ň§¨ŃįĽĢ¬Ś§Ť§Í§‚√ݧ∑§Į≥»ń•§∑§∆§§§Ž§≥§»§¨łę§∆ľŤ§ž§Ž°•Ńī¬őŇ™§ň°§ĹťīŁ√śĪ—łž§»łŚīŁ√śĪ—łž§ő ¨…Řī÷§«őŐŇ™§ ļĻ§Ōłę§ť§ž§Ž§¨°§ľŃŇ™§ň§Ō¬Á§≠§ —≤ŧŌ§ §§§»§§§√§∆§Ť§§§ņ§Ū§¶°• *
°°°¶ Görlach, Manfred. The Linguistic History of English. Basingstoke: Macmillan, 1997.
[ ł«ńÍ•Í•ů•Į | įűļĢÕ—•ŕ°ľ•ł ]
2013-02-24 Sun
Ę£ #1399. ĹťīŁ√śĪ—łž§ň§™§Ī§Ž between §őįŘ∑Ѭ÷§ő ¨…Ř [laeme][corpus][preposition][me_dialect][methodology]
°°°÷#1389. between §őłžłĽ°◊ ([2013-02-14-1])°§°÷#1393. between §őőÚĽňŇ™įŘ∑Ѭ÷§őň≠…Ŕ§Ķ°◊([2013-02-18-1])°§°÷#1394. between §őįŘ∑Ѭ÷§ő ¨…اőńŐĽĢŇ™ —≤Ĺ°◊ ([2013-02-19-1]) §ň¬≥§§§∆°§ļ£≤ů§Ō LAEME §ÚÕ—§§§∆ńŐĽĢŇ™ —≤ŧ™§Ť§” żłņ Ő ¨…اÚńīļļ§∑§Ņ∑Ž≤Ő§Ú ůĻū§Ļ§Ž°•
°°Helsinki Corpus §ň§Ť§ŽńŐĽĢŇ™ńīļļ ([2013-02-19-1]) §őĺžĻÁ§»∆ĪÕÕ§ň°§¬ŅŅۧőįŘ∑Ѭ÷§Ú§ř§»§Š§Ž§ňŇŲ§Ņ§√§∆°§łž»Ýį ≥į§ň§™§Ī§Ž ž≤Ľ§őį„§§§ŌŐĶĽŽ§∑°§¬Ť2≤ĽņŠį ĻŖ§őĽ“≤Ľ° §»°§§‚§∑§Ę§ž§–łž»Ý§ő ž≤Ľ§‚°ň§őľÔőŗ§»Ń»§ŖĻÁ§Ô§Ľ§ň√ŪŐ‹§∑§Ņ°•lexel §ň "between" §ÚĽōńͧ∑§∆ľŤ§ÍĹ–§∑§Ņő„§Ú§‚§»§ň°§241łń§ő•»°ľ•Į•ů§Ú»ĺņ§Ķ™§ī§»°§ żłņ Ő§ňņįÕż§∑§Ņ° ∂Ť ¨§Ō[2012-10-10-1]§őĶ≠ĽŲ°÷#1262. The LAEME Corpus §ő¬Ś…Ĺņ≠ (1)°◊§«ļőÕ—§∑§Ņ§‚§ő§»∆Ī§ł°ň°•ł∂•«°ľ•Ņ§Ō§≥§Ń§ť§ÚĽ≤ĺ»°•į ≤ľ°§ļ«Ĺť§ň«Į¬Ś Ő°§ľ°§ň żłņ Ő§őĹł∑◊∑Ž≤Ő§Ú∑«§≤§Ž°•
| PERIOD | nn | n | ne | x | xe | xn | xte | hn | he | tn | tx | txn | txe | ths | s | e | yn | zn | Sum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C12b | 18 | 1 | 2 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 28 |
| C13a | 23 | 4 | 19 | 6 | 4 | 4 | 0 | 9 | 14 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 85 |
| C13b | 20 | 3 | 23 | 2 | 1 | 3 | 4 | 1 | 0 | 0 | 0 | 1 | 0 | 2 | 1 | 1 | 1 | 1 | 64 |
| C14a | 5 | 13 | 28 | 9 | 2 | 2 | 0 | 0 | 0 | 3 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 64 |
| Sum | 66 | 21 | 72 | 24 | 7 | 9 | 4 | 10 | 14 | 3 | 2 | 1 | 1 | 2 | 1 | 2 | 1 | 1 | 241 |
| DIALECT | nn | n | ne | x | xe | xn | xte | hn | he | tn | tx | txn | txe | ths | s | e | yn | zn | Sum |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | 0 | 0 | 1 | 9 | 2 | 2 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 15 |
| NEM | 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 14 |
| NWM | 7 | 0 | 6 | 0 | 0 | 0 | 0 | 8 | 14 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 37 |
| SEM | 14 | 20 | 9 | 5 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 52 |
| SWM | 31 | 1 | 26 | 7 | 5 | 7 | 0 | 2 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 84 |
| SW | 0 | 0 | 16 | 3 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 24 |
| SE | 0 | 0 | 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 15 |
| Sum | 66 | 21 | 72 | 24 | 7 | 9 | 4 | 10 | 14 | 3 | 2 | 1 | 1 | 2 | 1 | 2 | 1 | 1 | 241 |
°°łĹ¬ŚĪ—łž§ő between §ňŌʧ §Ž°§n §Úīř§ŗļ«§‚…ŠńŐ§ő•Ņ•§•◊§¨ļł3őů§ňľ®§Ķ§ž§∆§§§Ž§¨°§bitweonen § §…§ő "nn" •Ņ•§•◊§ŌĽĢ¬Ś§»§»§‚§ň "n" •Ņ•§•◊§š "ne" •Ņ•§•◊§ň√÷īĻ§Ķ§ž§∆§ś§ĮÕÕĽ“§¨§¶§ę§¨§®§Ž°•Mustanoja (369) §Ō°§"nn" •Ņ•§•◊§ň§ń§§§∆ "The -en forms occur mainly in the more southern parts of the country" §»Ķ≠Ĺ“§∑§∆§§§Ž§¨°§ľ¬ļ›§ň§Ō NEM §š NWM §ň§‚łĹ§Ô§ž§∆§§§Ž°•§ń§ř§Í°§"nn" •Ņ•§•◊§ő ¨…اŌ°§ żłņ§őŐš¬Í§«§Ę§Žį 匧ňĽĢ¬Ś§őŐš¬Í§«§Ę§Ž≤ń«Ĺņ≠§¨§Ę§Ž°•łž»Ý§ő n §ő√¶ÕÓ§¨§Ť§ÍňՅۧ«°§§ę§ń°§§Ť§Í√Ŕ§§ĽĢ¬Ś§ňłę§ť§ž§Ž§≥§»§Ō°§ÕĹŃا«§≠§Ž§≥§»§ņ§Ū§¶°•
°°n ∑Ōőů§ň§ŌĪů§ĮĶ৖§ §§§¨°§bituix §š bitƿixen § §…§ő x ∑Ōőů§őĽ»Õ—§¨§≥§őĽĢīŁ§ňĶ©§«§ §§§≥§»§Ō°§Helsinki Corpus §őńīļļ∑Ž≤Ő§»…šĻÁ§∑§∆§§§Ž°•x ∑Ōőů§Ō N, SEM, SWM, SW §ň ¨…ا∑§∆§™§Í°§ī÷§ň∂ī§ř§ž§Ņ NEM, NWM §ň§Ō łĺŕ§Ķ§ž§ §§°•§≥§ő ¨…اŌŐĮ§ņ§¨°§Ńī¬ő§»§∑§∆ő„§¨ĹĹ ¨§ň¬Ņ§Į§ §§§Ņ§Š§ň°§North Midlands §őłĹ¬ł•∆•≠•Ļ•»§ňłĹ§Ô§ž§ŽĶ°≤٧¨§ §ę§√§Ņ§»§§§¶§≥§»§ę§‚§∑§ž§ §§°•∂Š¬ŚĪ—łžīŁ§ň§ę§Ī§∆ņģńĻ§Ļ§Ž t §Ú…’≤√§∑§Ņ xte •Ņ•§•◊§Ō°§ĹťīŁ√śĪ—łž§«§Ō C13b SW §ň bitwixte § §…§ő∑Ѭ÷§«§Ô§ļ§ę§ňłĹ§Ô§ž§Ž§ň§»§…§ř§√§∆§§§Ž°•
°°bituhen §š bituhe § §…§ő h ∑Ōőů§Ō°§Helsinki Corpus §ň§Ť§ž§–°§łŇĪ—łžłŚīŁ§Ť§ÍįžĶ§§ňŅͬŗ§∑§Ņ§»§ő§≥§»§ņ§√§Ņ§¨°§LAEME §ň§Ť§ž§–°§ĹťīŁ√śĪ—łž§«§Ō C13a NWM §ňĹł√ś§Ļ§Ž∑ѧ«ņł§≠Ľń§√§∆§§§Ņ§Ť§¶§ņ°•§∑§ę§∑°§§Ĺ§őĽĢ§ř§«§ňŅͬŗ∑ĻłĢ§Ō∑ŤńͧҧĪ§ť§ž§∆§§§Ņ§»łņ§®§Ž§ņ§Ū§¶°•
°°ļ£≤ů§őńīļļ§«ī∂≥–§Ú∆ņ§Ņ§¨°§° ĹťīŁ°ň√śĪ—łžīŁ§ň≥ęĽŌ§∑§Ņ°§§Ę§Ž§§§ŌŅ Ļ‘§∑§∆§§§Ž§»ĶŅ§Ô§ž§Ž —≤ŧň§ń§§§∆ńī§Ŕ§Ž§ň§Ō°§Helsinki Corpus §«ńŐĽĢŇ™ —≤ŧڬÁ§Ň§ę§Ŗ§ň§∑§Ņ匧«°§LAEME §ÚÕ—§§§∆°§§Ť§ÍļŔ§ę§§ĽĢ¬Ś∂Ť ¨§» żłņ§ő Ő§ÚĻÕőł§∑§∆∑°§Í≤ľ§≤§∆§ś§Į§ő§¨§Ť§Ķ§Ĺ§¶§ņ°•
2012-12-17 Mon
Ę£ #1330. ĹťīŁ√śĪ—łž§ň§™§Ī§Ž eth, thorn, <th> §őņĻŅÍ [thorn][th][spelling][laeme][alphabet][graphemics]
°°ļÚ∆Ł§őĶ≠ĽŲ[2012-12-16-1]§«°§Helsinki Corpus §ÚÕ—§§§∆°÷#1329. Ī—łžĽň§ň§™§Ī§Ž eth, thorn, <th> §őņĻŅÍ°◊§Ú≥Ķī—§∑§Ņ°••į•ť•’§ň§Ť§Ž§»°§<þ> §¨ <ð> §Ú≤°§∑§ő§Ī§∆√ݧ∑§ĮņģńĻ§Ļ§Ž§ő§Ō°§M1 (1150--1250) §ę§ť M2 (1250--1350) §ň§ę§Ī§∆§őĽĢīŁ§«§Ę§Í°§§≥§őĽĢīŁ§ň§ń§§§∆ĺ‹ļŔ§ňńīļļ§Ļ§Ž§ň§Ō LAEME §¨§¶§√§∆§ń§Ī§«§Ę§Ž°• żłņ§ň§Ť§ŽļĻįا §…§‚≥ő«ß§«§≠§Ž§ņ§Ū§¶§»ĻÕ§®°§ŃŠ¬ģ°§¬ÁĽ®«ń§ňńīļļ§∑§∆§Ŗ§Ņ°•¬ÁĽ®«ń§»§§§¶§ő§Ō°§ő„§®§–°§1§ń§őłž∑ѧő§ §ę§ň <þ> §¨2≤ůį 匳ŧԧž§Ņ§»§∑§∆§‚1≤ů§»Ņۧ®§Ž§ §…°§ľę∆įĹŤÕżĺŚ§őŇ‘ĻÁ§¨§Ę§Ž§Ņ§Š§«§Ę§Ž°•
°°į ≤ľ§Ō°§ĽĢ¬Ś Ő° »ĺņ§Ķ™√ĪįŐ°ň§™§Ť§” żłņ Ő§ő ¨…اھ®§Ļ•į•ť•’§«§Ę§Ž° ŅŰ√Õ•«°ľ•Ņ§Ō°§HTML•Ĺ°ľ•Ļ§ÚĽ≤ĺ»°ň°•§ §™°§ żłņ…’ÕŅ§ň§ń§§§∆§Ō°§[2012-03-19-1]§őĶ≠ĽŲ°÷#1057. LAEME Index of Sources §őł°ļų•ń°ľ•Ž Ver. 2°◊§«Ņ®§ž§Ņ§Ť§¶§ň°§≤ĺ§ő§‚§ő§«§Ę§Ž°•COUNTY §» DIALECT §ő≤ĺ§ő¬–ĪĢ…ŧŌ§≥§Ń§ť§ÚĽ≤ĺ»°•
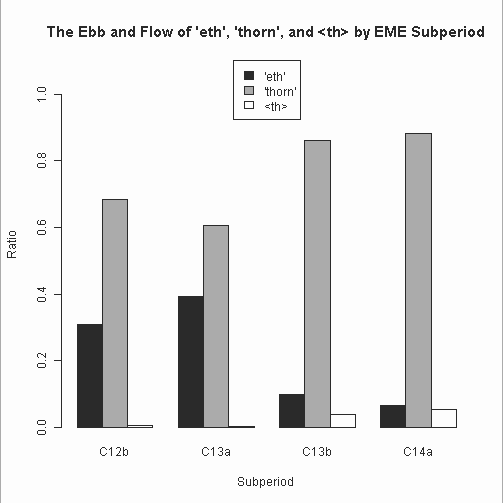
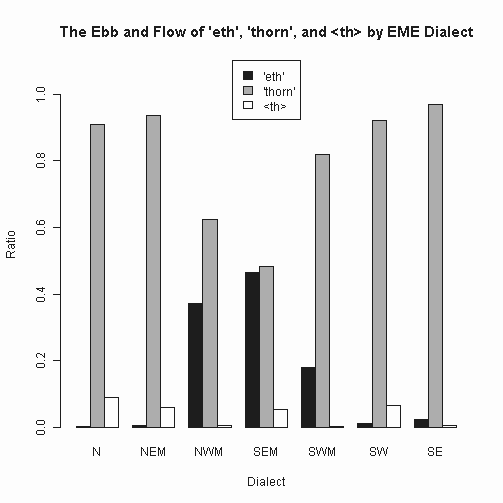
°°LAEME §ň§Ť§ŽĽĢ¬Ś Ő§őńīļļ∑Ž≤Ő§Ō°§ļÚ∆Ł§ő Helsinki Corpus §ň§Ť§Žńīļļ∑Ž≤Ő§»…šĻÁ§Ļ§Ž°•C13a §» C13b §őī÷§ň <ð> §őłļĺģ§» <þ> §őŃż≤√§¨√ݧ∑§Įī—Ľ°§Ķ§ž§Ž°•į ĻŖ°§ŅŰĹĹ«Įī÷§Ō <ð> ∆»ŃŲ§őĽĢ¬Ś§»§§§√§∆§Ť§§§ņ§Ū§¶°•įž ż°§ żłņ Ő§ň§Ŗ§Ž§»≥Ķ§Õ <þ> §¨ĽŔ«ŘŇ™§ņ§¨°§NWM §ÚĹŁ§Į√ś…ۧň§™§§§∆§Ō <ð> §‚§Ę§ŽńÝŇŔ§Ō∑Ú∆ģ§∑§∆§§§Ž§≥§»§¨§Ô§ę§Ž°• żłņ Ő§ő ¨…اŌ°§§Ť§Íĺ‹ļŔ§ ńīļļ§¨…¨Õ◊§ę§‚§∑§ž§ §§°•
2012-12-11 Tue
Ę£ #1324. two §ő /w/ §Ō§§§ńÕӧѧŅ§ę [numeral][spelling][pronunciation][laeme][lalme]
°°°÷#184. two §ő /w/ §¨»Į≤Ľ§Ķ§ž§ §§§ő§Ō§ §ľ§ę°◊ ([2009-10-28-1]) §«°§two §ő»Į≤Ľ§ňīř§ř§ž§Ž»ĺ ž≤Ľ /w/ §¨°§§§§ń§…§ő§Ť§¶§ň√¶ÕÓ§∑§Ņ§ę§ň§ń§§§∆ī √Ī§ňŅ®§ž§Ņ°•15?16ņ§Ķ™§ň√¶ÕÓ§∑§Ņ§»§Ķ§ž§Ž§¨°§ń÷Ľķ§«≥ő«ß§Ļ§Žł¬§Í§«§Ō°§ żłņ§ň§Ť§√§∆§Ō§‚§√§»ŃŠ§Į√śĪ—łžīŁ§ň√¶ÕÓ§∑§∆§§§Ņ§≥§»§Úľ®§ĻĺŕĶÚ§¨§Ę§Ž°•
°°§ř§ļ°§łŚīŁ√śĪ—łž§ň§ń§§§∆°•LALME §ő Dot Map 548--57 §ň two §őįŘń÷§Í§ő żłņ ¨…ا¨ľ®§Ķ§ž§∆§§§Ž°•ľÁÕ◊§ įŘń÷§Í§ň§ń§§§∆≥Ķņ‚§Ļ§ž§–°§twa •Ņ•§•◊ (Dot Map 548) §ŌňŐ…Ű żłņ§ňł¬ńͧĶ§ž§∆§§§Ž§ő§ň¬–§∑§∆°§ļ«§‚…ŠńŐ§ő two •Ņ•§•◊ (Dot Map 550) §ŌňՅۧÚīř§ŗ•§•ů•į•ť•ů•…ŃīįŤ§ň§ř§ů§Ŕ§ů§ §Įő„ĺŕ§Ķ§ž§Ž°•Őš¬Í§ő <w> §őń÷Ľķ§Úīř§ř§ §§ to(o) •Ņ•§•◊ (Dot Map 557) §Ō°§Ļ≠§Į∆Ӆۧňłę§ť§ž°§§»§Í§Ô§Ī East Anglia §š South-West Midland §ň«Ľ§Į ¨…ا∑§∆§§§Ž°•§≥§ő§Ť§¶§ň°§łŚīŁ√śĪ—łž§«§Ō°§§Ļ§«§ň w §őÕӧѧŅ∑Ѭ÷§¨•§•ů•į•ť•ů•…∆ӻ姫ńѧ∑§Į§ §ę§√§Ņ§≥§»§¨§Ô§ę§Ž°•
°°§«§Ō°§ĹťīŁ√śĪ—łž§«§Ō§…§¶§ņ§√§Ņ§Ū§¶§ę°•LAEME §«ńī§Ŕ§∆§Ŗ§Ņ°•TO §Ę§Ž§§§Ō TO- §őń÷Ľķ§Ú§‚§ń "two" §ÚľŤ§ÍĹ–§∑°§ żłņ Ő°§ĽĢ¬Ś Ő§ňņįÕż§Ļ§Ž§»į ≤ľ§ő§Ť§¶§ň§ §√§Ņ°•
| C12b | C13a | C13b | C14a | |
|---|---|---|---|---|
| N | 1 | |||
| NEM | 1 | |||
| NWM | ||||
| SEM | 28 | 6 | ||
| SWM | 1 | 1 | ||
| SW | 4 | 20 | ||
| SE |
°°§Ń§Á§¶§… LALME §ő Dot Map 557 §« to(o) §¨»ś≥”Ň™«Ľ§§ ¨…اھ®§∑§∆§§§Ņ√ŌįŤ§ň°§TO(-) §¨Ĺł§ř§√§∆§§§Ž°•ĹťīŁ√śĪ—łž§ę§ťłŚīŁ√śĪ—łž§ō§ő ¨…اőŌʬ≥ņ≠§¨§Ť§Į…ŧԧž§∆§§§Žő„§»§§§®§Ž§ņ§Ū§¶°•<w> §Ú§‚§Ņ§ §§ń÷Ľķ§Ō°§ĽĢ¬Ś§»§∑§∆§Ō§™§Ť§Ĺ13ņ§Ķ™łŚ»ĺį ĻŖ§ň°§∆Ó…ŰĹŰ żłņ§Ú√śŅī§ňĽŌ§ř§√§Ņ§»ĻÕ§®§∆§Ť§Ķ§Ĺ§¶§ņ°•¬–ĪĢ§Ļ§Ž≤Ľņľ§ň§™§Ī§Ž /w/ §ő√¶ÕÓ§‚∆ĪÕÕ§ňĻÕ§®§Ž§ő§¨¬ŇŇŲ§ņ§Ū§¶°•
°°√śĪ—łž§ň§™§Ī§Ž§≥§őłž§őŅŰ°Ļ§őįŘń÷§Í§ň§ń§§§∆§Ō°§MED§ÚĽ≤ĺ»°•
°°°¶ McIntosh, Angus, M. L. Samuels, and M. Benskin. A Linguistic Atlas of Late Mediaeval English. 4 vols. Aberdeen: Aberdeen UP, 1986.
2012-12-07 Fri
Ę£ #1320. LAEME §«łę§Ž most §őįŘ∑Ѭ÷§ő ¨…Ř [vowel][superlative][map][laeme][me_dialect][comparison]
°°[2012-11-24-1]§őĶ≠ĽŲ°÷#1307. most §» mest°◊§«ľŤ§Í匧≤§Ņ√śĪ—łž§őļ«ĺŚĶť most §őįŘ∑Ѭ÷§ň§ń§§§∆°§ĹťīŁ√śĪ—łž§ň§™§Ī§Ž ž≤Ľ Ő§ő ¨…Ř§Ú LAEME §ÚÕ—§§§∆ńīļļ§∑§Ņ°•√ŌŅř匧ňįŐ√÷§Ň§Ī§ť§ž§Ž•∆•≠•Ļ•»§ę§ťľŤ§ÍĹ–§∑§Ņ most §őįŘ∑Ѭ÷§ŌŃī…ۧ«249ő„§Ę§Í°§§≥§ž§Úłžīī ž≤Ľ§ňĹĺ§√§∆ ¨ Ő§∑§Ņ§‚§ő§Ú HelMapperUK §ňőģ§∑ĻĢ§ů§ņ°•∆…§ŖĻĢ§ř§Ľ§Ņ•«°ľ•Ņ•’•°•§•Ž§Ō§≥§Ń§ť°••ř°ľ•Į§ő¬Á§≠§Ķ§Ō…—ŇŔ§ň»śő„§Ļ§Ž°•
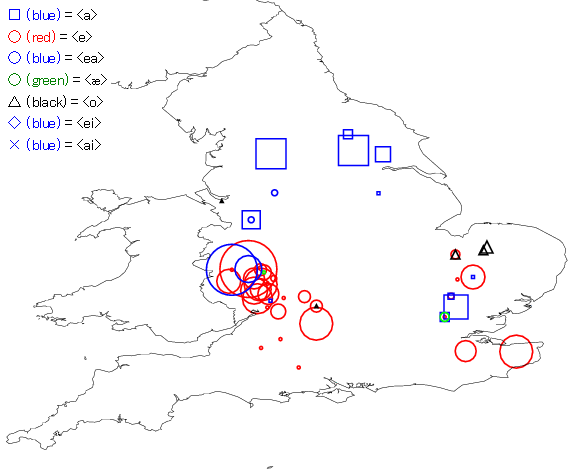
°°<mast> § §… <a> §Úľ®§Ļ§‚§ő§ŌľÁ§»§∑§∆ňՅۧň ¨…ا∑°§<mest>, <meast>,
2012-10-12 Fri
Ę£ #1264. őÚĽňłņłž≥ō§őł¬≥¶§»°§§Ĺ§őĻÓ…Ģ§ō§ő∆Ľ [methodology][uniformitarian_principle][writing][history][sociolinguistics][laeme][corpus][representativeness][evidence]
°°[2012-10-10-1], [2012-10-11-1]§őĶ≠ĽŲ§«°§The LAEME Corpus §ő¬Ś…Ĺņ≠§ň§ń§§§∆ľŤ§Í§Ę§≤§Ņ°•Ľš§ő…ĺ≤ѧ»§∑§∆§Ō°§•ę•–°ľ§∑§∆§§§Ž żłņ§»ĽĢ¬Ś§»§§§¶ī—Ňņ§ę§ť§Ŗ§∆¬Ś…Ĺņ≠§Ō√ݧ∑§Į¬Ľ§ §Ô§ž§∆§§§Ž§‚§ő§ő°§łĹļŖÕÝÕ—§«§≠§ŽĹťīŁ√śĪ—łž•≥°ľ•—•Ļ§»§∑§∆§Ō¬ő∑ŌŇ™§ň ‘§ř§ž§Ņļ«¬ÁĶ¨ŐŌ§ő•≥°ľ•—•Ļ§«§Ę§Í°§ĹĹ ¨§ √Ūį’§Ú ߧ√§Ņ§¶§®§«łņłžł¶Ķś§ň≥ŤÕ—§Ļ§Ŕ§≠•ń°ľ•Ž§«§Ę§Ž°•The LAEME Corpus §ő≤ĢŃĪ§Ļ§Ŕ§≠Ňņ§Ō§‚§Ń§Ū§ů§Ę§Ž§∑°§¬ĺ§ő•≥°ľ•—•Ļ§ň§Ť§Ž šīį§‚Ő‹Ľō§Ķ§ž§Ž§Ŕ§≠§ņ§»§ŌĻÕ§®§Ž§¨°§łņłž§ÚőÚĽňŇ™§ňł¶Ķś§Ļ§Žļ›§ň…¨Ń≥Ň™§ň§ń§≠§ř§»§¶ł¬≥¶§‚ĻÕőł§∑§Ņ匧«…ĺ≤ѧ∑§ §§§»•Ę•ů•’•ß•Ę§«§Ę§Ž°•
°°őÚĽňłņłž≥ō§Ō°§łņłž§ő≤ŠĶÓ§őĺű¬÷§Úī—Ľ°§∑°§…ŁłĶ§Ļ§Ž§»§§§¶≤›¬Í§Úľę§ť§ň≤›§∑§∆§§§Ž°•≤ŠĶÓ§Úį∑§¶ļÓ∂»§ň§Ō°§łĹļŖ§Úį∑§¶ļÓ∂»§ň§Ōłę§ť§ž§ §§§Ę§Žł¬≥¶§¨§ń§≠§ř§»§¶°•Milroy (45) §őĽōҶ§Ļ§ŽőÚĽňłņłž≥ōł¶Ķś§ő2§ń§őł¬≥¶ (limitations of historical inquiry) §Úľ®§Ĺ§¶°•
[P]ast states of language are attested in writing, rather than in speech . . . [W]ritten language tends to be message-oriented and is deprived of the social and situational contexts in which speech events occur.
[H]istorical data have been accidentally preserved and are therefore not equally representative of all aspects of the language of past states . . . . Some styles and varieties may therefore be over-represented in the data, while others are under-represented . . . . For some periods of time there may be a great deal of surviving information: for other periods there may be very little or none at all.
°°ĺŤ§ÍĪا®§¨§Ņ§§ł¬≥¶§«§Ō§Ę§Ž§¨°§ĻÓ…Ģ§őŇōőŌ§Ę§Ž§§§ŌĻÓ…Ģ§ň§«§≠§Ž§ņ§Ī∂Š§Ň§ĮŇōőŌ§Ō°§§§§Ū§§§Ū§ żň°§«§ §Ķ§ž§∆§§§Ž°•§Ĺ§ő§ §ę§«§‚°§Smith §Ō§Ĺ§ő√ÝĹ٧őŅÔĹͧ« (1) Ĺ٧≠łņÕ’§»Ō√§∑łņÕ’§őīō∑ł§őÕż≤Ú§ÚŅľ§Š§Ž§≥§»°§(2) łņłž§ő∆‚ŐŐĽň§»≥įŐŐĽň§ő¬–ĪĢ§ň√ŪŐ‹§Ļ§Ž§≥§»°§(3) łĹļŖ§ő√őłę§ő≤ŠĶÓ§ō§őĪĢÕ—§ő≤ń«Ĺņ≠§Ú√Ķ§Ž§≥§»°§§őĹŇÕ◊ņ≠§ÚĽōҶ§∑§∆§§§Ž°•
°°§»§Í§Ô§Ī (3) §ň§ń§§§∆§Ō°§∂Š«Į°§ľ“≤Ůłņłž≥ō§ň§Ť§Žłņłž —≤ŧőÕż≤Ú§¨Ķř¬ģ§ňŅ §Ŗ°§§Ĺ§őł∂Õż§ő≤ŠĶÓ§ō§őĪĢÕ—§¨ņĻ§ů§ň§ §Ķ§ž§Ž§Ť§¶§ň§ §√§∆§≠§Ņ°•Labov §őŌņ ł§ő…ł¬Í "On the Use of the Present to Explain the Past" §¨°§§≥§ő żň°Ōņ§ÚńĺŔ£§ň ™łž§√§∆§§§Ž°•
°°§≥§ž§»īōŌʧĻ§Ž żň°Ōņ§«§Ę§Ž uniformitarian_principle ° ņ∆įžŌņ§őł∂¬ß°ň§ÚŃįŐŐ§ň≤°§∑Ĺ–§∑§ŅőÚĽňĪ—łž§őŌņ łĹł§¨°§Denison et al. ‘Ĺł§ő§‚§»§ň°§ļ£«ĮĹ–»«§Ķ§ž§Ņ§≥§»§‚…’§Ī≤√§®§∆§™§≥§¶°•
°°°¶ Milroy, James. Linguistic Variation and Change: On the Historical Sociolinguistics of English. Oxford: Blackwell, 1992.
°°°¶ Smith, Jeremy J. An Historical Study of English: Function, Form and Change. London: Routledge, 1996.
°°°¶ Labov, William. "On the Use of the Present to Explain the Past." Readings in Historical Phonology: Chapters in the Theory of Sound Change. Ed. Philip Baldi and Ronald N. Werth. Philadelphia: U of Pennsylvania P, 1978. 275--312.
°°°¶ Denison, David, Ricardo Bermúdez-Otero, Chris McCully, and Emma Moore, eds. Analysing Older English. Cambridge: CUP, 2012.
2012-10-11 Thu
Ę£ #1263. The LAEME Corpus §ő¬Ś…Ĺņ≠ (2) [laeme][corpus][representativeness]
°°ļÚ∆Ł§őĶ≠ĽŲ[2012-10-10-1]§ňįķ§≠¬≥§≠°§The LAEME Corpus §ő¬Ś…Ĺņ≠§őŌ√¬Í°•ļ£≤ů§Ō°§łžŅŰ°§§Ť§ÍņĶ≥ő§ň§Ō∆Ī•≥°ľ•—•Ļ§« łň°ĺū ů§¨…’ÕŅ§Ķ§ž§∆§§§Žłž (tagged words) §őŅۧň§Ť§Í°§ żłņ°¶ĽĢ¬Ś§ī§»§ő¬Ś…Ĺņ≠§ÚĻÕ§®§Ž°•§ř§ļ°§…ŧÚ∑«§≤§Ť§¶°•
Table 2: Dialectal and Diachronic Distribution of Linguistic Evidence by Number of Tagged Words
| C12b | C13a | C13b | C14a | Total | |
|---|---|---|---|---|---|
| N | 0 (0.000%) | 362 (0.062) | 0 (0.000) | 52,883 (9.083) | 53,245 (9.146) |
| NEM | 11,342 (1.948) | 0 (0.000) | 3,980 (0.684) | 2,344 (0.403) | 17,666 (3.034) |
| NWM | 0 (0.000) | 58,332 (10.019) | 16,173 (2.778) | 0 (0.000) | 74,505 (12.797) |
| SEM | 40,082 (6.885) | 26,722 (4.590) | 21,921 (3.765) | 31,408 (5.395) | 120,133 (20.634) |
| SWM | 1,030 (0.177) | 90,400 (15.527) | 106,981 (18.375) | 108 (0.019) | 198,519 (34.098) |
| SW | 1,168 (0.201) | 2,610 (0.448) | 46,032 (7.907) | 30,517 (5.242) | 80,327 (13.797) |
| SE | 0 (0.000) | 4,043 (0.694) | 3,199 (0.549) | 30,561 (5.249) | 37,803 (6.493) |
| Total | 53,622 (9.210) | 182,469 (31.341) | 198,286 (34.058) | 147,821 (25.390) | 582,198 (100.000) |
°°ńĺī∂Ň™§ňÕż≤Ú§«§≠§Ž§Ť§¶§ň°§§≥§ő ¨…اڕ‚•∂•§•Į•◊•Ū•√•»§«…ųŧ∑§Ņ§ő§¨≤ľŅř§«§Ę§Ž° įűļĢÕ—§ň§Ō§≥§Ń§ť§őPDF§Ú§…§¶§ĺ°ň°•
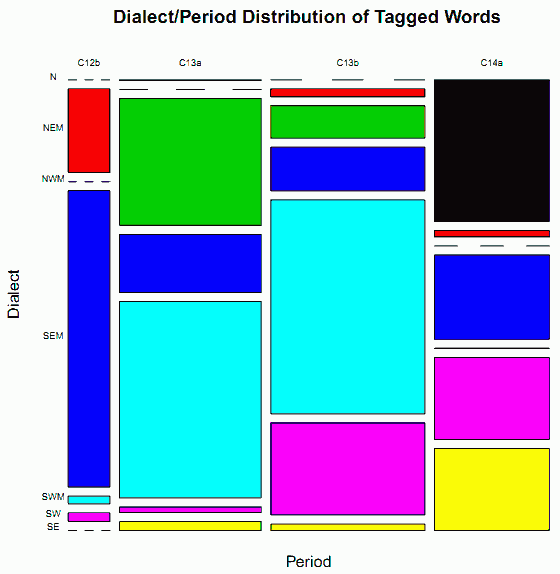
°° ¨…اő –§Í§ŌįžŐ‹ő∆Ń≥§«§Ę§Ž°•§∑§ę§∑°§ żłņ°¶ĽĢ¬Ś§ő≥∆•Ļ•Ū•√•»§ÚĻĹņģ§Ļ§Ž•∆•≠•Ļ•»§őľÔőŗ§ §…§Ú§Ť§ÍļŔ§ę§Įńī§Ŕ§Ž§»°§§Ķ§ť§ňĹŇÕ◊§ Őš¬Í§¨łę§®§∆§Į§Ž°•§§§Į§ń§ę§ő•Ļ•Ū•√•»§«§Ō°§ŃŪłžŅۧő¬Á…Ű ¨§¨§Ř§ů§őįžįģ§Í§ő•∆•≠•Ļ•»§ň§Ť§√§∆ņͧŠ§ť§ž§∆§§§Ž§ő§«§Ę§Ž°•ő„§®§–°§N C14a §»§§§¶•Ļ•Ū•√•»§Ō°§Ńī¬ő§ő§ §ę§«4»÷Ő‹§ňľżŌŅłžŅۧő¬Ņ§§•Ļ•Ū•√•»§ņ§¨°§§Ĺ§őłžŅۧő95.61%§Ō Cursor Mundi §»§§§¶1ļÓ… ° ņĶ≥ő§ň§Ō°§§Ĺ§ž§Ú…ŧԧĻ3ľÔőŗ§őįا §ŽĹŮľŐłņłž§Ú»ŅĪ«§∑§Ņ 3 scribal texts [##296, 297, 298]°ň§«ņͧŠ§ť§ž§∆§§§Ž°•∆ĪÕÕ§ň°§NEM C13b §«§Ō #182 §ő§Ŗ§«80.93%§őłžŅۧ¨•ę•–°ľ§Ķ§ž§∆§§§Ž°•NWM C13b §«§Ō #272 §ő§Ŗ§«93.11%§ņ°•SEM C12b §«§Ōįا §Ž2ŅÕ§őľŐĽķņł§őľÍ§ň§Ť§Ž Trinity Homilies (##1200, 1300) §¨ŃŪłžŅۧő84.06%§ÚņͧŠ°§SEM C13a §«§‚įا §Ž2ŅÕ§őľŐĽķņł§őľÍ§ň§Ť§Ž Vices and Virtues (##64, 65) §¨ŃŪłžŅۧő93.83%§ÚņͧŠ§Ž°•SW C13b §ő #1600 §Ō°§§Ĺ§ž§ņ§Ī§«69.71%§ÚņͧŠ§Ž°§Ňý°Ļ°•
°°§≥§ž§ť§őő„§¨ľ®ļ∂§Ļ§Ž§≥§»§Ō°§Őš¬Í§ő żłņ°¶ĽĢ¬Ś•Ļ•Ū•√•»§Ō…¨§ļ§∑§‚§Ĺ§ő żłņ°¶ĽĢ¬Ś§őłņłž —ľÔ§Ú¬Ś…ŧ∑§∆§§§Ž§Ô§Ī§«§Ō§ §Į°§§ŗ§∑§Ū∆√ńͧő•∆•≠•Ļ•»§ňłĹ§Ô§ž§Žłņłž —ľÔ§Ú¬Ś…ŧ∑§∆§§§Ž§»§§§¶§≥§»§ę§‚§∑§ž§ §»§§§¶§≥§»§ņ°•The LAEME Corpus §őĽ»Õ—§őļ›§ň§Ō°§§ §™įžŃō§ő√Ūį’§¨…¨Õ◊§«§Ę§Ž°•
2012-10-10 Wed
Ę£ #1262. The LAEME Corpus §ő¬Ś…Ĺņ≠ (1) [laeme][corpus][representativeness]
°°Ľš§őīōŅī§ő√śŅī§ŌĹťīŁ√śĪ—łžīŁ§ő∑Ѭ÷Ōņ§«§Ę§Ž°•§≥§őĽĢ¬Ś§ňīōŅī§Ú§‚§ńľ‘§ň§»§√§∆§Ō°§LAEME ° ‘ľ‘§ň§Ť§ž§–°§»Į≤Ľ§Ō /ˈleɪmiː/ °ň§»§Ĺ§≥§ę§ť«…ņł§∑§Ņ The LAEME Corpus (Text Database) §őҖ垧Ō°§∆ĪĽĢ¬Ś§ňīō§Ļ§Žł¶Ķśīń∂≠§Ú√ݧ∑§Į≤ĢŃĪ§∑∆ņ§Ž•ń°ľ•Ž§»§∑§∆°§ļ«¬Áł¬§ňīŅ∑ř§Ķ§ž§Ž°•LAEME §ň§ń§§§∆§Ō°§ň‹•÷•Ū•į§«§‚ laeme §őĶ≠ĽŲ§«ļő§Í§Ę§≤§∆§≠§Ņ§∑°§§»§Í§Ô§Ī•ń°ľ•Ž§»§∑§∆§ő≤ń«Ĺņ≠§Ú√Ķ§Í°§≥»ń•§Ļ§Ŕ§Į°÷#846. HelMapperUK --- hellog ĽŇÕÕ§őĪ—ĻŮ√ŌŅřļÓņģ CGI°◊ ([2011-08-21-1]) °§°÷#856. LAEME text database §ő•«°ľ•ŅŇņ§»•∆•≠•Ļ•»Ķ¨ŐŌ°◊ ([2011-08-31-1]) °§°÷#942. LAEME Index of Sources §őł°ļų•ń°ľ•Ž°◊ ([2011-11-25-1]) °§°÷#1057. LAEME Index of Sources §őł°ļų•ń°ľ•Ž Ver. 2°◊ ([2012-03-19-1]) §ÚłÝ…ŧ∑§∆§≠§Ņ°•
°°¬ÁĻ©§ň§»§√§∆∆Ľ∂٧őľÍ∆Ģ§ž§¨¬ÁĽŲ§ §Ť§¶§ň°§ł¶Ķśľ‘§ň§»§√§∆•ń°ľ•Ž§őł¶Ķś§Ō¬ÁĽŲ§«§Ę§Ž°•∂٬őŇ™§ň The LAEME Corpus §ÚĽ»§√§∆§§§Ž§¶§Ń§ň°§Ńī¬ő§»§∑§∆–Ū‚◊§Ļ§Ž§»§…§ő§Ť§¶§ •≥°ľ•—•Ļ§ §ő§ę°§√ő§Í§Ņ§Į§ §√§∆§≠§Ņ°•[2010-11-16-1]§őĶ≠ĽŲ°÷#568. •≥°ľ•—•Ļ§őńÍĶѧ»Ī—łž•≥°ľ•—•Ļ∆ĢŐÁ°◊§«ľ®§∑§ŅńէͰ§•≥°ľ•—•Ļ§őľÁ§Ņ§Ž∆√ńߧő1§ń§ň representativeness ° ¬Ś…Ĺņ≠°ň§¨§Ę§Ž°•§≥§ž§Ō°§•≥°ľ•—•Ļ…ĺ≤ѧő§Ņ§Š§őĽō…ł§ő1§ń§«§‚§Ę§Ž°•őÚĽň•≥°ľ•—•Ļ§ň§™§Ī§Ž¬Ś…Ĺņ≠§ő≥ő ›§ő∆٧∑§Ķ§ň§ń§§§∆§Ō°§°÷#531. OED §őįķÕ—•«°ľ•Ņ§Ú•≥°ľ•—•Ļ§»§∑§∆Ľ»§®§Ž§ę°◊ ([2010-10-10-1]) §š°÷#1243. łž§ő…—ŇŔ§ÚĻÕőł§Ļ§ŽńŐĽĢŇ™ł¶Ķś§ő§Ņ§Š§ň°◊ ([2012-09-21-1]) §«§‚Ņ®§ž§∆§≠§Ņ§¨°§§≥§őŇņ§«§Ō The LAEME Corpus §‚∂žņÔ§Ú∂Į§§§ť§ž§∆§§§Ž°••ę•–°ľ§∑§∆§§§Ž żłņ ¨…اň§ń§§§∆§Ō°÷#856. LAEME text database §ő•«°ľ•ŅŇņ§»•∆•≠•Ļ•»Ķ¨ŐŌ°◊ ([2011-08-31-1]) §«ļő§Í§Ę§≤§Ņ§¨°§ļ£≤ů§Ō żłņ∂Ť ¨§ň≤√§®§∆ĽĢ¬Ś∂Ť ¨§‚īř§Š§ §¨§ť The LAEME Corpus §ő•ń°ľ•Ž ¨ņŌ§ÚĽÓ§Ŗ§Ņ§§°•
°°§ř§ļ§Ō°§ľżŌŅ§Ķ§ž§∆§§§Ž•∆•≠•Ļ•»§őŅۧÚĻÕ§®§Ž°•ŇŲ≥ļ•≥°ľ•—•Ļ§Ō "scribal text" §»§§§¶√ĪįŐ§«•∆•≠•Ļ•»§¨ľżŌŅ§Ķ§ž§∆§§§Ž§¨°§§≥§ž§Ú żłņ§»ĽĢ¬Ś§ň§∑§Ņ§¨§√§∆ ¨ Ő§Ļ§Ž§»°§Ľ∂§ť§–§Í∂ŮĻÁ§¨§Ô§ę§Ž°•§ §™°§ żłņ∂Ť ¨§»ĽĢ¬Ś∂Ť ¨§Ō§Ĺ§žľę¬ő§¨ żň°Ōņ匧ő¬ÁŐš¬Í§ §ő§ņ§¨°§į ≤ľ§«§Ō°§◊ůį’Ň™§ ∂Ť ¨° §»§Ō§§§√§∆§‚§Ę§ŽńÝŇŔ§őļ¨ĶÚ§Ō§Ę§Ž§¨°ň§»§∑§∆°§ żłņ§Ō7§ń§ō°§ĽĢ¬Ś§Ō4§ń§ō§» ¨§Ī§∆§§§Ž°•§Ļ§ §Ô§Ń°§ żłņ§Ō N (Northern), NEM (North-East Midland), NWM (North-West Midland), SEM (South-East Midland), SWM (South-West Midland), SW (Southwestern), SE (Southeastern) §ō°§ĽĢ¬Ś§Ō C12b ° 12ņ§Ķ™łŚ»ĺ°ň°§C13a, C13b, C14a §ō°•√śĪ—łž§ő żłņ∂Ť ¨§ň§ń§§§∆§Ō°÷#130. √śĪ—łž§ő żłņ∂Ť ¨°◊ ([2009-09-04-1]) §‚Ľ≤ĺ»°•
Table 1: Dialectal and Diachronic Distribution of Linguistic Evidence by Number of Texts
| C12b | C13a | C13b | C14a | Total | |
|---|---|---|---|---|---|
| N | 0 (0.00%) | 1 (0.86) | 0 (0.00) | 7 (6.03) | 8 (6.90) |
| NEM | 1 (0.86) | 0 (0.00) | 5 (4.31) | 2 (1.72) | 8 (6.90) |
| NWM | 0 (0.00) | 9 (7.76) | 5 (4.31) | 0 (0.00) | 14 (12.07) |
| SEM | 4 (3.45) | 7 (6.03) | 14 (12.07) | 7 (6.03) | 32 (27.59) |
| SWM | 2 (1.72) | 13 (11.21) | 17 (14.66) | 1 (0.86) | 33 (28.45) |
| SW | 3 (2.59) | 5 (4.31) | 7 (6.03) | 2 (1.72) | 17 (14.66) |
| SE | 0 (0.00) | 2 (1.72) | 1 (0.86) | 1 (0.86) | 4 (3.45) |
| Total | 10 (8.62) | 37 (31.90) | 49 (42.24) | 20 (17.24) | 116 (100.00) |
°°ĺŚ§ő…ŧÚļÓņģ§Ļ§Ž§ň§Ę§Ņ§Í¬–囧»§∑§Ņ§ő§Ō°§The LAEME Corpus §ňľżŌŅ§Ķ§ž§∆§§§Ž167łń§ő scribal texts §ő§¶§Ń°§»ĺņ§Ķ™§»§§§¶√ĪįŐ§«ĽĢ¬Ś§ő∂Ť ¨§¨§ §Ķ§ž§∆§§§Ž116łń§ő§Ŗ§«§Ę§Ž°•
°°…ŧÚįž Õ§Ļ§ž§–§Ô§ę§Ž§Ť§¶§ň°§•∆•≠•Ļ•» ¨…اő –§Í§Ō¬Á§≠§§°• żłņ§«§§§®§– SEM §» SWM §ŌŃō§¨įŘĺÔ§ňłŁ§Į°§Ńī¬ő§ő3 ¨§ő2§Ř§…§Ú•ę•–°ľ§∑§∆§§§Ž§¨°§įž ż§« N, NEM, SE §ŌŃō§¨«Ų§§°•ĽĢ¬Ś§«§Ŗ§Ž§»°§C13a §» C13b §ņ§Ī§«7≥š§ÚĪا®°§C12b §» C14a §ŌŃō§¨«Ų§§°• żłņ°¶ĽĢ¬Ś§őŃ»§ŖĻÁ§Ô§Ľ§«§Ō°§6•Ļ•Ū•√•»§ř§«§¨ "0" §Úľ®§Ļ°•őÚĽň•≥°ľ•—•Ļ ‘Ľľ§ň§™§Ī§Ž representative §ő≥ő ›§ŌņšňĺŇ™§»§Ļ§ťĽ◊§®§∆§Į§Ž°•ĺĮ§ §Į§»§‚°§The LAEME Corpus §ÚÕ—§§§∆∆ņ§ť§ž§Ž żłņ§šĽĢ¬Ś§ň§ń§§§∆§ő•«°ľ•Ņ§š§Ĺ§≥§ę§ť∆ņ§ť§ž§Ž∑ŽŌņ§Ō°§§Ť§Į§Ť§Į√Ūį’§∑§∆≤ÚľŠ§∑§ §Ī§ž§–§ §ť§ §§§»§§§¶§≥§»§¨§§§®§Ž§ņ§Ū§¶°•
°°§≥§ő…ŧŌ scribal text §őŅۧڧ‚§»§ňļÓņģ§Ķ§ž§∆§§§Ž§¨°§≥∆ scribal text §őńĻ§Ķ§Ō§ř§Ń§ř§Ń§«§Ę§Ž°•§Ĺ§≥§«°§•∆•≠•Ļ•»Ņۧ«§Ō§ §Į°§łžŅۧň§Ť§Ž ¨…اő∂ŮĻÁ§‚ńī§Ŕ§∆§Ŗ§Ž…¨Õ◊§¨§Ę§Ž°•łžŅۧňīū§Ň§Į¬Ś…Ĺņ≠§őĶńŌņ§Ō°§Őņ∆Ł§őĶ≠ĽŲ§«°•
2012-03-19 Mon
Ę£ #1057. LAEME Index of Sources §őł°ļų•ń°ľ•Ž Ver. 2 [laeme][web_service][cgi][dialect]
°°[2011-11-25-1]§őĶ≠ĽŲ°÷#942. LAEME Index of Sources §őł°ļų•ń°ľ•Ž°◊§« SQL §ň§Ť§Žł°ļųÕ— CGI §ÚłÝ≥ę§∑§Ņ°•ļ«∂Š°§ł¶Ķś§« LAEME §Úň‹≥ Ň™§ňĽ»§¶Ķ°≤٧¨§Ę§Í°§ł°ļųÕ—§ő•«°ľ•Ņ•Ŕ°ľ•Ļ§ňĺĮ§∑§Įĺū ů§Úń…≤√§∑§Ņ°•§Ĺ§≥§«°§ĺŚįŐłŖīĻ§»§ §Ž Ver. 2 §ÚļÓ§√§Ņ§ő§«°§łÝ≥ę§Ļ§Ž°•
°°ń…≤√§∑§Ņĺū ů§Ō°§PERIOD, COUNTY, DIALECT §ő3•’•£°ľ•Ž•…°•PERIOD §Ō°§§‚§»§‚§»§ő IOS §«ÕŅ§®§ť§ž§∆§§§Ņ•∆•≠•Ļ•»§ő DATE §Ú§‚§»§ň°§»ĺņ§Ķ™∂Ťņŕ§Í§«¬ÁĽ®«ń§ň∂Ť ¨§∑§ §™§∑§Ņ§‚§ő°•C13b2--C14a1 § §…∂Ť ¨§ő§ř§Ņ§¨§ŽĺžĻÁ§ň§Ō°§ŃŠ§§§Ř§¶§Ú§»§√§∆ C13b §»∆…§Ŗ¬ō§®§Ņ°•"ca. 1300" § §…§‚∆ĪÕÕ§ň°§ŃŠ§§§Ř§¶§ōŇ›§∑§∆ C13b §»§∑§Ņ°•DATE §ň§™§§§∆ C13, C14 § §…»ĺņ§Ķ™§«∂Ťņ৞§ §§«Į¬Ś§¨ÕŅ§®§ť§ž§∆§§§ŽĺžĻÁ§ň§Ō°§C13, C14 §ő§Ť§¶§ň§Ĺ§ő§ř§řĽń§∑§Ņ°•
°°COUNTY §Ō°§LOC §ňÕŅ§®§ť§ž§∆§§§Ņĺū ů§Ú§‚§»§ň°§3 łĽķ§őő¨Ľķ…ĹĶ≠§«ľ®§∑§Ņ°•DIALECT §Ō°§Ĺͬį§Ļ§ŽĹ£ (county) §Ú§‚§»§ň¬ÁĽ®«ń§ň N (Northern), NWM (North-West Midland), NEM (North-East Midland), SEM (South-East Midland), SWM (South-West Midland), SW (Southwestern), SE (Southeastern) §ő7 żłņ§ň∂Ť ¨§∑§Ņ§‚§ő§«§Ę§Ž°• żłņņĢ§ŌĹ£∂≠§»įž√◊§∑§∆§§§Ž§Ô§Ī§«§Ō§ §§§∑°§ żłņņĢ§Ĺ§ő§‚§ő§őŃ™ńͧ‚°§°÷#130. √śĪ—łž§ő żłņ∂Ť ¨°◊ ([2009-09-04-1]) §š°÷#1030. England §őłĹ¬ŚĪ—łž żłņ∂Ť ¨ (2)°◊ ([2012-02-21-1]) §«łę§Ņ§Ť§¶§ň°§∆٧∑§§°•§∑§Ņ§¨§√§∆°§ļ£≤ů§ő DIALECT §ő…’ÕŅ§‚°§[2009-09-04-1]§ő√śĪ—łž żłņ√ŌŅř§ň¬ÁĽ®«ń§ň廧ť§∑§∆§ő≤ĺ§ő§‚§ő§«§Ę§Ž°•Ľ≤ĻÕ§ř§«§ň°§COUNTY §» DIALECT §ő¬–ĪĢ…ŧŌ§≥§Ń§ť°•
°°Ľ»Õ—ň°§Ō[2011-11-25-1]§őĶž»«§»∆Ī§ł§«°§•∆°ľ•÷•ŽŐĺ§Ō "ios" (for "Index of Sources") §«ł«ńÍ°••’•£°ľ•Ž•…§Ō°§Ńī…ۧ«23•’•£°ľ•Ž•… (ID, MS, TEXT_ID, FILE, DATE, PERIOD, TEXT, GRID, LOC, COUNTY, DIALECT, COMMENT, SAMPLING, TAGGED_WORDS, PLACE_NAMES, PERSONAL_NAMES, WORDS, SCRIPT, OTHER, STATUS, BIBLIO, CROSS_REF, URL) °•select ł§ő§ŖÕ≠łķ°•į ≤ľ°§ŇĶ∑ŅŇ™§ ł°ļųľį§ÚĶů§≤§∆§™§Į°•
# ≥∆ PERIOD §ňŅ∂§Í ¨§Ī§ť§ž§Ņ•∆•≠•Ļ•»§őŅŰ
select distinct PERIOD, count(*) from ios group by PERIOD;
# ≥∆ COUNTY §ňŅ∂§Í ¨§Ī§ť§ž§Ņ•∆•≠•Ļ•»§őŅŰ
select distinct COUNTY, count(*) from ios group by COUNTY;
# ≥∆ DIALECT §ňŅ∂§Í ¨§Ī§ť§ž§Ņ•∆•≠•Ļ•»§őŅŰ
select distinct DIALECT, count(*) from ios group by DIALECT;
# DIALECT/PERIOD §ī§»§ň°§Ĺͬį§Ļ§Ž•∆•≠•Ļ•»§ő¬Ņ§§ĹÁ§ň•Í•Ļ•»•Ę•√•◊
select distinct DIALECT, PERIOD, count(*) from ios group by DIALECT, PERIOD order by count(*) desc;
# Worcestershire §ő•∆•≠•Ļ•»§ÚľŤ§ÍĹ–§∑°§PERIOD ĹÁ§ňĹŰĺū ů§ÚÕŚőů
select TEXT_ID, FILE, MS, COUNTY, PERIOD, TAGGED_WORDS from ios where COUNTY = 'WOR' order by PERIOD;
2011-11-25 Fri
Ę£ #942. LAEME Index of Sources §őł°ļų•ń°ľ•Ž [laeme][web_service][cgi]
°°LAEME §« Auxiliary Data Sets -> Index of Sources §»•Š•ň•Ś°ľ§Ú§Ņ§…§Ž§»°§LAEME §¨¬–囧»§∑§∆§§§Ž•∆•≠•Ļ•»•Ĺ°ľ•Ļ§ő•Í•Ļ•» (The LAEME Index of Sources) §Ú°§ÕÕ°Ļ§ ≥—ŇŔ§ę§ťł°ļų§∑§∆ľŤ§ÍĹ–§Ļ§≥§»§¨§«§≠§Ž°•LAEME §ő•∆•≠•Ļ•»•«°ľ•Ņ•Ŕ°ľ•Ļ§Ú«Į¬Ś Ő°§ żłņ Ő°§Grid Reference Ő§ §…§őīūĹŗ§« ¨ņŌ§∑§Ņ§§ĺžĻÁ§ň°§Ň¨ņৠ•∆•≠•Ļ•»§őįžÕų§Ú∆ņ§ť§ž§Ž§ő§«°§LAEME Ľ»§§§≥§ §∑§ő§Ņ§Š§ň§Ō»ůĺÔ§ňĹŇÕ◊§ Ķ°«Ĺ§«§Ę§Ž°•
°°§∑§ę§∑°§§‚§¶ĺĮ§∑ł°ļųľį§ňĺģ≤ů§Í§ÚÕݧꧼ§ť§ž§Ņ§Í°§įžÕų§őĹ–őŌ§¨•≥•ů•—•Į•»§ň…Ĺ∑Ńľį§«∆ņ§ť§ž§ž§–Ľ»§§ĺ°ľÍ§¨§Ť§§§ņ§Ū§¶§»Ľ◊§√§∆§§§Ņ°•§Ĺ§≥§«°§Index of Sources §Ú∆»ľę§ň•«°ľ•Ņ•Ŕ°ľ•Ļ≤ŧ∑°§SQL §ÚÕ—§§§∆ł°ļų≤ń«Ĺ§ň§∑§∆§Ŗ§Ņ°•LAEME §őĽ»Õ—ľ‘§«°§§ę§ńSQL§Úį∑§®§ŽŅÕį ≥į§ň§Ō≤Ņ§‚ŐÚ§ňő©§Ņ§ §§§ő§ņ§¨°§§Ľ§√§ę§ĮļÓ§√§Ņ§ő§«łÝ≥ę°•
°°į ≤ľ°§Ľ»Õ—ň°§őņ‚Őņ°••∆°ľ•÷•ŽŐĺ§Ō "ios" (for "Index of Sources") §«ł«ńÍ°••’•£°ľ•Ž•…§Ō°§LAEME ň‹≤»§őł°ļų§«¬–囧»§ §√§∆§§§Ž18§ő•’•£°ľ•Ž•…§ň≤√§®§∆°§ņįÕż»÷Ļś§»§∑§∆§ő "ID" §»°§•∆•≠•Ļ•»ĺū ů§ő∑«ļ‹§Ķ§ž§Ņ•™•ů•ť•§•ů•ŕ°ľ•ł§ō§ő "URL" §Ú≤√§®§Ņ∑◊20•’•£°ľ•Ž•… (ID, MS, TEXT_ID, FILE, DATE, TEXT, GRID, LOC, COMMENT, SAMPLING, TAGGED_WORDS, PLACE_NAMES, PERSONAL_NAMES, WORDS, SCRIPT, OTHER, STATUS, BIBLIO, CROSS_REF, URL) °•select ł§ő§ŖÕ≠łķ°•į ≤ľ§ň°§ŇĶ∑ŅŇ™§ ł°ļųľį§Úő„§»§∑§∆ļ‹§Ľ§∆§™§Į°•
# Ancrene Wisse/Riwle §ő•∆•≠•Ļ•»ĺū ů§őľŤ§ÍĹ–§∑
select TEXT_ID, MS, FILE, GRID, LOC, DATE, TEXT from ios where FILE like "%ar%t.tag" and TEXT like "%Ancrene%";
# Poema Morale §ő•∆•≠•Ļ•»ĺū ů§őľŤ§ÍĹ–§∑
select TEXT_ID, MS, FILE, GRID, LOC, DATE, TEXT from ios where FILE like "%pm%t.tag" and TEXT like "%Poema%";
# Grid Reference §őÕŅ§®§ť§ž§∆§§§Ž•∆•≠•Ļ•»§őľŤ§ÍĹ–§∑
select TEXT_ID, MS, FILE, GRID from ios where GRID != "000 000";
# DATE §ň "C13a" §Úīř§ŗ•∆•≠•Ļ•»§őľŤ§ÍĹ–§∑
select TEXT_ID, DATE from ios where DATE like "%C13a%";
# «Į¬Ś§ī§»§ňĹł∑◊
select DATE, count(DATE) from ios group by DATE order by DATE;
# •Ņ•į…’§Ī§Ķ§ž§∆§§§ŽłžŅۧڕ∆•≠•Ļ•»§ī§»§ň≥ő«ß
select TEXT_ID, TAGGED_WORDS, PLACE_NAMES, PERSONAL_NAMES from ios;
# Ńī•∆•≠•Ļ•»ĺū ů§ō§ő•Í•ů•ĮĹł
select TEXT_ID, MS, FILE, URL from ios;
2011-08-31 Wed
Ę£ #856. LAEME text database §ő•«°ľ•ŅŇņ§»•∆•≠•Ļ•»Ķ¨ŐŌ [map][laeme][lalme]
°°LAEME text database §«į∑§Ô§ž§∆§§§Ž scribal texts §őŅۧŌ°§LAEME Index of Sources (PDF) §ň§Ť§Ž§»°§§∂§√§»168łń§ņ§¨°§§Ĺ§ő§ §ę§«√ŌŅř匧őįŐ√÷§¨∆√ńͧĶ§ž§∆§§§Ž§‚§ő§Ō121łń° Őů72%°ň§«§Ę§Ž°•įŐ√÷ĺū ů§Ō Ordinance Survey National Grid Reference §»§∑§∆∆ņ§ť§ž§Ž§∑°§≥∆•∆•≠•Ļ•»§ň§ń§§§∆•Ņ•į…’§Ī§Ķ§ž§∆§§§ŽłžŅۧ‚∆ņ§ť§ž§Ž§ő§«°§Ń»§ŖĻÁ§Ô§Ľ§ž§–°§•«°ľ•ŅŇņ§ī§»§ň§…§őńÝŇŔ§őĶ¨ŐŌ§ő•∆•≠•Ļ•»§¨•≥°ľ•—•Ļ§»§∑§∆ÕÝÕ—§«§≠§Ž§ę°§√ŌŅř匧ň…ųŧĻ§Ž§≥§»§¨§«§≠§Ž§≥§»§ň§ §Ž°•§≥§őļÓ∂»§Ú°§[2011-08-21-1]§őĶ≠ĽŲ°÷HelMapperUK --- hellog ĽŇÕÕ§őĪ—ĻŮ√ŌŅřļÓņģ CGI°◊§«łÝ≥ę§∑§Ņ√ŌŅřļÓņģ•ń°ľ•Ž§ÚÕ—§§§∆Ļ‘§ §√§Ņ°•į ≤ľ§¨∑Ž≤Ő§«§Ę§Ž°•
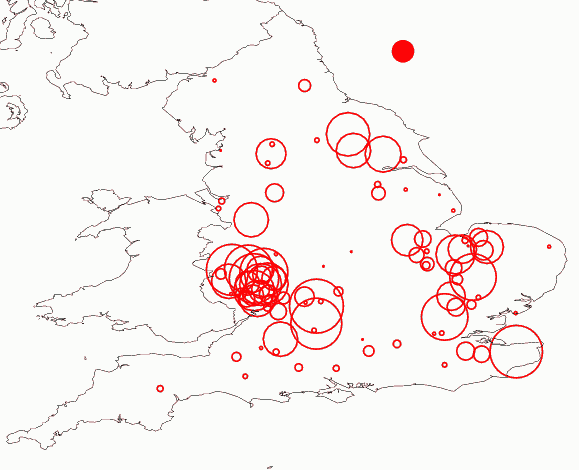
°°įا §Ž•«°ľ•ŅŇņ§Ō96§ÚŅۧ®°§•«°ľ•ŅŇņ§»īōŌʧҧĪ§ť§ž§Ž•∆•≠•Ļ•»° ∑≤°ň§ÚĻĹņģ§Ļ§ŽłžŅۧő Ņ∂—√Õ§Ō6307łž§Ř§…§«§Ę§Ž° •Ņ•į…’§Ī§Ķ§ž§ŅłžŅۧŌ§≥§ž§Ť§Íľ„ī≥≤ľ≤ů§Ž°ň°•ňřő„§»§∑§∆√ŌŅř§őĪ¶ĺŚ§ňľ®§∑§Ņņ÷Ň…§Í§őĪŖ§őŐŐņ—§¨§≥§ő Ņ∂—łžŅۧňŃÍŇŲ§∑°§§≥§őŐŐņ—§ÚīūĹŗ§»§∑§∆°§≥∆•«°ľ•ŅŇņ§¨°§łžŅۧňŃÍŇŲ§Ļ§ŽŐŐņ—§Ú§‚§ń«Ú»ī§≠§őņ÷ī›§»§∑§∆…ѧ꧞§∆§§§Ž° Ľ≤ĻÕ§ř§«§ň°§HelMapperUK §ň∆…§ŖĻĢ§ř§Ľ§Ņ•«°ľ•Ņ§Ō§≥§Ń§ť°ň°•
°°√ŌŅř§ÚńĮ§Š§∆ńĺī∂Ň™§ň§Ô§ę§Ž§≥§»§Ō°§•«°ľ•ŅŇņ§ň§Ľ§ŤľżŌŅłžŅۧň§Ľ§Ť°§South-West Midland §» South-East Midland §ňŅÔ ¨§»Ĺł√ś§∑§∆§§§Ž§»§§§¶§≥§»§«§Ę§Ž°•§≥§ž§Ō°§LAEME §ő ‘ľ‘§ő1ŅÕ§«§Ę§Ž Laing §¨ľę§ť§őŌņ ł "Never the twain shall meet" §«√Ūį’§Úī≠ĶĮ§∑§∆§§§Žńէͧ«§Ę§Ž°•LAEME §ő•∆•≠•Ļ•»§őįŐ√÷∆√ńͧŌ°§LALME §¨ ‘§ŖĹ–§∑§Ņ "fit technique" §»§§§¶ÕżŌņŇ™ľÍň°§ň…ť§√§∆§§§Ž§¨°§§≥§őľÍň°§őņģ»›§őłį§Ō "anchor texts" §»ł∆§–§ž§Ž≥őľ¬§ Ĺ–»ĮŇņ§¨¬Ņ§ĮľÍ§ň∆Ģ§Ž§ę§…§¶§ę§»§§§¶Ňņ§ň§Ę§Ž°•§ņ§¨°§Ľń«į§ §≥§»§ň°§łŚīŁ√śĪ—łž§»įا §ÍĹťīŁ√śĪ—łž§«§Ō "anchor texts" §¨≥ √ §ňĺĮ§ §§°•"anchor texts" §Ō°§łŚ§őÕżŌņŇ™§ įŐ√÷∆√ńͧňļ›§∑§∆ľßņ–§ő§Ť§¶§ňĶ°«Ĺ§Ļ§Ž§Ņ§Š°§Ĺ–»ĮŇņ§¨Ňž§šņĺ§ňő•§ž§∆ ¨…ا∑§∆§§§Ž§»°§§≥§ž§ę§ť "fit" §Ķ§Ľ§Ť§¶§»Ľ◊§√§∆§§§Ž•∆•≠•Ļ•»§‚Ńͬ–Ň™§ňŇžņĺ§ő§…§Ń§ť§ę¬¶§ňįķ§≠§ń§Ī§ť§ž§∆§∑§ř§¶§»§§§¶∑Ž≤Ő§ň§ §Ž§≥§»§¨¬Ņ§§°•Midland §ő√śĪŻ§ň•«°ľ•ŅŇņ§¨§ř§–§ť§ §ő§Ō°§§≥§ő§Ť§¶§ ĽŲĺū§ň§‚ĶʧĽ§ť§ž§Ž°•
°°√ŌŅřļÓņģ•ń°ľ•Ž HelMapperUK §Ō°§»ĺ§– LAEME §ő≥ŤÕ—§ő§Ņ§Š§ňļÓ§√§Ņ§Ť§¶§ §‚§ő§ņ§¨°§LAEME ľę¬ő§Ú ¨ņŌ§Ļ§Ž§ő§ň§‚ÕÝÕ—§«§≠§Ĺ§¶§ņ°•
°°§ §™°§LAEME Index of Sources §ŌņŤ§ňŇŧͅ’§Ī§Ņ•Í•ů•Į §Ť§Í PDF §«∆ĢľÍ§«§≠§Ž§¨°§§Ĺ§ő¬ĺ§ň§‚LAEME §ő•»•√•◊•ŕ°ľ•ł §ę§ť Auxiliary Data Sets -> Index of Sources §»§Ņ§…§Ž§»°§ÕÕ°Ļ§ •—•ť•Š°ľ•Ņ§ň§Ť§Í•Ĺ°ľ•Ļ•∆•≠•Ļ•»§őĺū ůł°ļų§¨§«§≠§Ž°•
°°°¶ Laing, Margaret. "Never the twain shall meet: Early Middle English --- The East-West Divide." Placing Middle English in Context. Ed. I. Taavitsainen et al. Berlin: Mouton de Gruyter, 2000. 97--124.
°°°¶ McIntosh, Angus, M. L. Samuels, and M. Benskin. A Linguistic Atlas of Late Mediaeval English. 4 vols. Aberdeen: Aberdeen UP, 1986.
2011-08-21 Sun
Ę£ #846. HelMapperUK --- hellog ĽŇÕÕ§őĪ—ĻŮ√ŌŅřļÓņģ CGI [cgi][web_service][map][lalme][laeme][bre]
°°√śĪ—łž§ő żłņ§Úł¶Ķś§∑§∆§§§Ž§»°§LALME §ő Dot Map …ų§ő•§•ů•į•ť•ů•…√ŌŅř§Ú…ѧĪ§Ž§» ōÕݧņ§»Ľ◊§¶Ķ°≤٧¨§Ę§Ž°•LALME §ő√ŌŅř§ÚÕ—§§§Ž§ő§«§Ę§ž§–•≥•‘°ľ§∑§Ņ§Í•Ļ•≠•„•ů§∑§Ņ§Í§Ļ§ž§–§Ť§§§∑°§•™•ů•ť•§•ů§ő LAEME §«§Ę§ž§– "Mapping" Ķ°«Ĺ§ę§ť "Feature Maps" §«∆√§ň√ŪŐ‹§Ļ§Ŕ§≠łņłžĻŗŐ‹§ňīō§Ļ§Ž√ŌŅř§Ō•«•ł•Ņ•Ž≤ŤŃŁ§«∆ņ§ť§ž§Ž°•łŚľ‘§«§Ō°§"Create a Feature Map" § §Ž•ś°ľ•∂°ľ§ň§Ť§Ž√ŌŅřļÓņģĶ°«Ĺ§‚§™§§§™§§ń…≤√§Ķ§ž§Ž§»§ő§≥§»§«°§√śĪ—łž żłņ≥ō§ő•Ű•£•ł•Ś•Ę•Ž≤ŧŌļ£łŚ§‚Ņ Ňł§∑§∆Ļ‘§Į§»Ľ◊§Ô§ž§Ž°•
°°§∑§ę§∑°§§Ĺ§ž§«§‚ÕÕ°Ļ§ ļ§∆٧š…‘ ō§Ō§Ę§Ž°•ő„§®§–°§LAEME §«§‚°§ľę ¨§őīōŅī§ő§Ę§ŽłņłžĻŗŐ‹§¨ LAEME ľę¬ő§«į∑§Ô§ž§∆§§§ §Ī§ž§–√ŌŅřļÓņģĶ°«Ĺ§ŌŐÚ§ňő©§Ņ§ §§§∑° ő„§®§–°§Ľš§ő√śĪ—łžŐ弞 £Ņۧőł¶Ķś§«§ŌŐ弞§őőÚĽňŇ™§ łň°ņ≠§¨ĹŇÕ◊§ņ§¨°§LAEME text database §«§Ōņ≠§¨•Ņ•į…’§Ī§Ķ§ž§∆§§§ §§§ő§«•’•Ž§ň§Ō≥ŤÕ—§«§≠§ §ę§√§Ņ°ň°§LALME §ň§ń§§§∆§Ō§Ĺ§‚§Ĺ§‚√ŌŅř§¨•«•ł•Ņ•Ž≤ŧĶ§ž§∆§§§ļĪĢÕ—§∑§ň§Į§§° √ŌŅř§ő•«•ł•Ņ•Ž≤Ĺ°§ĺĮ§ §Į§»§‚•∆•≠•Ļ•»ĺū ů§šļ¬…łĺū ů§ő•«•ł•Ņ•Ž≤ŧ¨įžĻÔ§‚ŃŠ§Įňĺ§ř§ž§Ž°ň°•
°°§Ĺ§ž§«§‚°§ľÍ§Ú§≥§ř§Õ§§§∆¬‘§√§∆§§§Ž§Ô§Ī§ň§ŌĻ‘§ę§ §§°•īŻ¬ł§ő•ń°ľ•Ž§»ľę ¨§őīōŅī§Ō¬Á≥Ķ§ļ§ž§∆§§§Ž§‚§ő§«§Ę§Í°§ľę§ťł¶Ķśīń∂≠§ÚļÓ§Ž…¨Õ◊§ň«ų§ť§ž§Ž§ő§¨ĺÔ§ņ§ę§ť§ņ°•√śĪ—łž§ő żłņ√ŌŅř§ňīō§Ļ§Žł¬§Í°§LALME §š LAEME §ę§ť•∆•≠•Ļ•»§ő żłņ…’ÕŅĺū ů§Ķ§®∆ņ§ť§ž§ž§–°§ľę§ťĹł§Š§ŅłņłžĻŗŐ‹§ňīō§Ļ§Ž•«°ľ•Ņ§Ú√ŌŅř匧ň•◊•Ū•√•»§Ļ§Ž§≥§»§ŌĹĹ ¨§ň≤ń«Ĺ§«§Ę§Ž°•° ľŻÕ◊§ŌĺĮ§ §§§»Ľ◊§Ô§ž§Ž§¨°ň§Ĺ§őļÓ∂»§ÚĺĮ§∑§«§‚ī ō≤ŧĻ§Ž§Ņ§Š§ň°§HelMapperUK § §Ž CGI §ÚļÓņģ§∑§∆§Ŗ§Ņ°•Ī—Ļ٧ő•Ŕ°ľ•Ļ•ř•√•◊匧ň•«°ľ•Ņ•›•§•ů•»§Ú•◊•Ū•√•»§Ļ§Ž§»§§§¶√ĪĶ°«Ĺ§ň∆√≤ŧ∑§∆§™§Í°§ňřő„§Ú§ń§Ī§Ž§ §…§ő…’≤√Ķ°«Ĺ§Ō§ §§§¨°§•Ű•£•ł•Ś•Ę•Ž≤ŧ∑§∆≥Ķī—§Ú§ń§ę§ŗ§»§§§¶Õ—Ň”§ň§ŌĹĹ ¨§»Ľ◊§Ô§ž§Ž°•
°°į ≤ľ§«Ľ»§§ ż§őņ‚Őņ§Ú§Ļ§Ž§¨°§§Ĺ§őŃį§ň°§§ř§ļ§≥§Ń§ť§ő•«°ľ•Ņ•’•°•§•Ž§ő∆‚Õ∆§Ú匧ő•∆•≠•Ļ•»•‹•√•Į•Ļ§ňĺŚĹ٧≠•≥•‘•ŕ§∑§∆Ĺ–őŌ∑Ž≤Ő§ő≥ő«ß§Ú§…§¶§ĺ°•§≥§ž§Ō°§ņŘ√ݧő £ŅŰ∑Ńł¶Ķś§« ¨ņŌ§∑§ŅĹťīŁ√śĪ—łž•∆•≠•Ļ•»§ő ¨…ا«°§ņ÷ī›§¨ľÍļÓ∂»§« ¨ņŌ§∑§Ņ§‚§ő°§ņńĽÕ≥—§¨ LAEME text database §ÚĪÁÕ—§∑§∆ ¨ņŌ§∑§Ņ§‚§ő°§§Ĺ§ž§ĺ§ž§ő∑ѧ«ĺģ§Ķ§§§‚§ő§Ō•∆•≠•Ļ•»§őŃī¬ő§«§Ō§ §Į…Ű ¨§Ú ¨ņŌ§∑§Ņ§‚§ő§Ú…ŧԧĻ°•° ľ¬ļ›°§Hotta (55) §ő√ŌŅř§Ō§™§Ť§Ĺ§≥§ő§Ť§¶§ň§∑§∆…ѧ꧞§Ņ°•°ň
°°§«§Ō°§Ľ»§§ ż§őņ‚Őņ° īūň‹Ň™§ňļÓľ‘łńŅÕĽŇÕÕ§ő§‚§ő§ÚłÝ≥ę§∑§∆§§§Ž§ņ§Ī§ §ő§«•§•ů•Ņ°ľ•’•ß°ľ•Ļ§ŌņŲőż§Ķ§ž§∆§§§ř§Ľ§ů°§§Ę§∑§ę§ť§ļ°ň°••∆•≠•Ļ•»•‹•√•Į•Ļ§ň§Ę§ť§ę§ł§Š∆ĢőŌ§Ķ§ž§∆§§§Ž§»§™§Í°§∆ĢőŌ•«°ľ•Ņ§ŌņŖńÍ…Ű (Configuration) §«ĽŌ§ř§Ž°•į ≤ľ§¨ņŖńÍ≤ń«Ĺ§ —ŅŰ°•
°°°¶ °÷map°◊ —Ņۧň§Ō "England" §ę "UK" §¨∆Ģ§Ž°•§≥§ž§«°§Ĺ–őŌ§Ķ§ž§Ž√ŌŅř§ő»ŌįŌ§Ú∑ŤńÍ°•
°°°¶ °÷scale°◊ —ŅۧŌ°§X żłĢ§»Y żłĢ§ō§ő≥»¬Áő®§ÚĽōńÍ°•≥»¬Á§ §∑ (scale=1 1) §ņ§»°§Ĺ–őŌ≤ŤŃŁ§Ō 386 * 313 Pixels (England) °§529 * 557 Pixels (UK) §ő¬Á§≠§Ķ°•
°°°¶ °÷pattern + ŅŰĽķ°◊ —ŅۧŌ°§•◊•Ū•√•»§ňÕ—§§§ŽĶ≠Ļś§ÚńÍĶѧĻ§Ž°••§•≥°ľ•Ž§őłŚ§ň§Ō•Ļ•ŕ°ľ•Ļ∂Ťņŕ§Í§« (1) ∑Ń ("box", "circle", "cross", "diamond", "invertedtriangle", "plus", or "triangle") °§(2) §Ĺ§ő∑ѧÚŇ…§Í§ń§÷§Ļ§ę»›§ę (ex. "fill" or "stroke") °§(3) Ņß (ex. "aqua", "black", "blue", "cyan", "green", "lime", "magenta", "red"; ¬ĺ§ő¬Áń٧őŅßŐĺ§ň§‚¬–ĪĢ§∑§∆§§§Ž§Ō§ļ§ņ§¨Ĺ–őŌ§Ķ§ž§Ž≤ŤŃŁ§ň»ŅĪ«§Ķ§ž§ §§Ņߧ‚§Ę§Ž) °§(4) ¬Á§≠§Ķ° ņĢ§őńĻ§Ķ§šĪŖ§őńĺ∑¬§ňŃÍŇŲ§Ļ§Ž Pixels°ň§ő4ĻŗŐ‹§ő√Õ§ÚÕŅ§®§Ž°••—•Ņ°ľ•ů§ŌĻ•§≠§ §ņ§Ī•ś°ľ•∂°ľńÍĶŃ≤ń«Ĺ°•
°°§Ĺ§őłŚ§ň•«°ľ•Ņ…Ű (Data points) §¨¬≥§Į°•1Ļ‘§ň1•«°ľ•Ņ•›•§•ů•»§«°§≥∆Ļ‘§Ō•Ņ•÷∂Ťņŕ§Í§« (1) Xļ¬…ł°§(2) Yļ¬…ł°§(3) 匧«ńÍĶѧĶ§ž§Ņ•—•Ņ°ľ•ůŐĺ§ő§§§ļ§ž§ę ("pattern1" § §…°ň§ő3ĻŗŐ‹§ő√Õ§ÚÕŅ§®§Ž° ľ¬ļ›§ň§Ō•—•Ņ°ľ•ůŐĺ§Ōĺ ő¨≤ń«Ĺ°•§Ĺ§őĺžĻÁ°§ľę∆įŇ™§ň "pattern1" §¨Õ—§§§ť§ž§Ž°•°ň°•ļ¬…ł∑Ō§ň§ń§§§∆§Ō°§LALME §š LAEME §«ļőÕ—§Ķ§ž§∆§§§Ž Ordinance Survey National Grid Reference §ő3∑Ś§ļ§ń§őļ¬…ł∑Ō (ex. "372 244") °§§Ę§Ž§§§Ōįž»Ő§ő∑–ŇŔ°¶įřŇŔ (ex. -2.408752393 52.09322081) §ő§§§ļ§ž§‚≤ń«Ĺ° ľę∆į§«»ĹńͧĶ§ž§Ž°ň°•
°°∂űĻ‘°§§Ę§Ž§§§Ō "#" §«ĽŌ§ř§Ž•≥•Š•ů•»Ļ‘§Ō•«°ľ•Ņ§»§∑§∆ŐĶĽŽ§Ķ§ž§Ž°•
°°Ĺ–őŌ∑Ž≤Ő§Ō GIF ∑Ńľį§ő≤ŤŃŁ§»§∑§∆…ŧԧž§Ž°• ŐŇ”°§EPS ∑Ńľį§ő•Ŕ•Į•Ņ°ľ≤ŤŃŁ§»§∑§∆§‚•ņ•¶•ů•Ū°ľ•…§«§≠§Ž§Ť§¶§ň§∑§Ņ° §≥§Ń§ť§ő•’•°•§•Ž§Ú§§§ł§ž§Ž§ő§«§Ę§ž§–°§≥∆ľÔ§őņŖńͧÚīř§Š§ŅļŔ§ę§§•Ń•Ś°ľ•ň•ů•į§¨≤ń«Ĺ°ň°•
°°Ī—ĻŮ•Ŕ°ľ•Ļ•ř•√•◊§őļÓņģ§ň§Ō°§CIA World DataBank II §š DCW Map Interface for Europe §ő•«°ľ•Ņ§ÚĽ≤廧∑§Ņ°•
° łŚĶ≠°°2011/08/31(Wed)°ß[2011-08-31-1]§őĶ≠ĽŲ°÷LAEME text database §ő•«°ľ•ŅŇņ§»•∆•≠•Ļ•»Ķ¨ŐŌ°◊§«°§HelMapperUK §«ļÓņŧ∑§Ņ√ŌŅř§őľ¬ő„§Úľ®§∑§Ņ°•°ň
°°°¶ McIntosh, Angus, M. L. Samuels, and M. Benskin. A Linguistic Atlas of Late Mediaeval English. 4 vols. Aberdeen: Aberdeen UP, 1986.
°°°¶ Laing, Margaret and Roger Lass, eds. A Linguistic Atlas of Early Middle English, 1150--1325. http://www.lel.ed.ac.uk/ihd/laeme1/laeme1.html . Online. Edinburgh: U of Edinburgh, 2007.
°°°¶ Hotta, Ryuichi. The Development of the Nominal Plural Forms in Early Middle English. Hituzi Linguistics in English 10. Tokyo: Hituzi Syobo, 2009.
2011-03-18 Fri
Ę£ #690. Northern Personal Pronoun Rule §Ú LAEME §«ł°ĺŕ [laeme][me_dialect][personal_pronoun][verb][nptr]
°°ļÚ∆Ł§őĶ≠ĽŲ[2011-03-17-1]§«Ķ≠ĽŲ§«ľŤ§Í匧≤§Ņ The Northern Personal Pronoun Rule (NPPR) §ŌňŐ…Ű•§•ů•į•ť•ů•…§«√śĪ—łžīŁ§ňĻ‘§ §Ô§ž§ŅŇżłžĶ¨¬ß§»§Ķ§ž§Ž°•ĹťīŁ√śĪ—łž§«ľ¬ļ›§ň łĺŕ§Ķ§ž§Ž§ę§…§¶§ę§Ú°§LAEME §«≥ő«ß§∑§∆§Ŗ§Ņ§§°•
°°Laing and Lass (26--27) §ň§Ť§ž§–°§LAEME §ő•≥°ľ•—•Ļ§«§Ō NPPR §¨ ∆įĽž§ň•Ņ•į…’§Ī§Ķ§ž§∆§§§Ž§»§§§¶§≥§»§ §ő§«°§ī √Ī§ňŶ§§Ĺ–§Ļ§≥§»§¨§«§≠§Ž°•Tasks •ŕ°ľ•ł§ę§ťį ≤ľ§ő§Ť§¶§ň•Š•ň•Ś°ľ§Ú§Ņ§…§Í°§ł°ļų…ųŧ»§∑§∆ "(-)vps2%apn(%)" ° ¬ŚŐ弞§őń峌§ňłĹ§Ô§ž§Ž∆įĽž§őłĹļŖ∑Ń £ŅŰ°ň§» "(-)vps2%bpn(%)" ° ¬ŚŐ弞§őńĺŃį§ňłĹ§Ô§ž§Ž∆įĽž§őłĹļŖ∑Ń £ŅŰ°ň§«§Ĺ§ž§ĺ§žł°ļų§∑§∆§Ŗ§Ņ°•ł°ļų…ųŧڧŤ§ÍļŔ§ę§ĮĻ©…◊§Ļ§Ž§≥§»§Ō§«§≠§Ž§¨°§§≥§ž§«ŇŲŐŐ§őÕ—§Ō¬≠§Ľ§Ž°•
[LISTS] -> [Make an Item List] -> [Inflections] and [Search by TAG] -> ( [(-)vps2%apn(%)] or [(-)vps2%bpn(%)] ) and Frequency Counts
°°Ĺ–őŌ§Ķ§ž§Ņĺū ů§Ú∆…§Ŗ≤Ú§Į§ň§‚ĺĮ°Ļ§ő√őľĪ§»∑–ł≥§¨§§§Ž§¨°§≥∆Ļ‘§Ō°÷ł°ļų¬–囧»§ §√§Ņ•∆•≠•Ļ•»»÷Ļś°◊°÷§Ĺ§ő•∆•≠•Ļ•»§őłņłž§¨įŐ√÷§Ň§Ī§ť§ž§∆§§§ŽĹ£§őő¨Őĺ°◊°÷Őš¬Í§őłž»Ý§őľÔőŗ§»…—ŇŔ°◊§ę§ť§ §√§∆§§§Ž°•NPPR §«§Ō°§ £ŅŰŅÕĺő¬ŚŐ弞§őŃįłŚ§«∆įĽž§őłĹļŖ∑ѧ¨° -e §š -en §‚§Ę§Í§¶§Ž§¨°ň•ľ•Ūłž»Ý§ÚľŤ§Ž§»§§§¶§ő§¨ļ«§‚ł≤√ݧ ∆√ńߧ §ő§«°§łž»Ý§»§∑§∆ "0" §¨īř§ř§ž§∆§§§ŽĻ‘§Ú√Ķ§∑Ĺ–§Ľ§–§Ť§§°•§Ĺ§őĻ‘§Úį ≤ľ§ň»ī§≠Ĺ–§Ļ°•
[for "(-)vps2%apn(%)"]
| 188 | DUR | +E [2] 0 [2] |
| 285 | NFK | +E [7] +En [4] +ETH [3] +N [2] 0 [2] +EN [1] |
| 295 | YWR | +>I>Ey [17] 0 [9] |
| 296 | YCT | +E [16] 0 [14] +E [2] |
| 297 | YER | 0 [36] +E [10] +IEy [2] |
| 298 | YNR | +E [43] 0 [31] |
| 300 | NFK | 0 [31] |
[for "(-)vps2%bpn(%)"]
| 119 | [-] | 0 [2] |
| 173 | WOR | +Ay [1] +E [1] +Ey [1] 0 [1] |
| 247 | HRF | +E [2] +ET [1] +T [1] 0 [1] |
| 295 | YWR | 0 [4] |
| 296 | YCT | 0 [5] +E [3] |
| 297 | YER | 0 [8] +E [4] |
| 298 | YNR | 0 [22] +E [10] 0+ [2] |
| 2000 | WOR | +E [6] 0 [3] +Ed [1] +IE [1] |
| 2001 | WOR | 0 [3] |
°°Ĺ£Őĺ§ÚįžÕų§Ļ§Ž§»°§Durham, Yorkshire, Hereford, Worcester, Norfolk § §…ňՅۧ꧝√ś…ۧň§ę§Ī§∆ ¨…ا∑§∆§§§Ž§≥§»§¨ ¨§ę§Ž°•∆√§ň•∆•≠•Ļ•»»÷Ļś295--298§Ō Cursor Mundi §»§§§¶ńĻ¬Á§ ĽŪ§ÚĽō§∑°§14ņ§Ķ™Ńį»ĺ§őňŐ…Ű żłņ§Ú¬Ś…ŧĻ§Ž•∆•≠•Ļ•»§»§∑§∆√ő§ť§ž§∆§§§Ž°•
°°•∆•≠•Ļ•»298 (Edinburgh, Royal College of Physicians, MS of Cursor Mundi, hand B, fols. 16r-36v: Extracts from the Northern Homily Collection) §ę§ťő„§Ú»ī§≠Ĺ–§Ļ§»°§ő„§®§–ľ°§ő§Ť§¶§ NPPR §Úľ®§ĻĻ‘§¨∆ņ§ť§ž§Ž°•Őš¬Í§ő∆įĽž§Ōņ÷Ľķ§«Ķ≠§∑§Ņ°•
- Yef þai lef her rihtwislie
- For in hali bok find we
- For if we schrif us clen of sinne
- Ye wen ful wel nou euerilkan
- Þan sau þai in vs goddes sede
- Of his offering today spec we
°°Tasks •ŕ°ľ•ł§ę§ť CONCORDANCING Ķ°«Ĺ§ň§Ť§ÍÕ—ő„§ő•≥•ů•≥°ľ•ņ•ů•Ļ°¶•ť•§•ů§ÚĹ–őŌ§Ļ§Ž§≥§»§‚§«§≠§Ž§¨°§ł°ļų§ő…ŖĶÔ§Ō§Ķ§ť§ňĻ‚§§°•TAGGED TEXTS §ę§ť•∆•≠•Ļ•»•’•°•§•Ž§ÚľŤ§ÍĹ–§∑§∆ľę ¨§«ł°ļų§∑§Ņ§Ř§¶§¨Õ∆į◊§ę§‚§∑§ž§ §§°•
°°°¶ Laing, Margaret and Roger Lass. "Tagging." Chapter 4 of "A Linguistic Atlas of Early Middle English: Introduction." Available online at http://www.lel.ed.ac.uk/ihd/laeme1/pdf/Introchap4.pdf .
2011-02-19 Sat
Ę£ #663. √śĪ—łž żłņ≥ō§ň§™§Ī§Žń÷Ľķ§»»Į≤Ľ§őīō∑ł [lalme][laeme][me_dialect][spelling_pronunciation_gap][grammatology][graphemics][x]
°°ĹťīŁ√śĪ—łž§ő żłņ√ŌŅř LAEME §őĶ°«Ĺ§¨łĢ匧∑§∆§≠§Ņ°•§Ĺ§őņŤ«ŕ§«§‚§Ę§Íņł§Ŗ§őŅ∆§«§‚§Ę§ŽłŚīŁ√śĪ—łž§ő żłņ√ŌŅř LALME §Ō°§ń÷Ľķ§»»Į≤Ľ§őīō∑ł§ÚĻÕĽ°§Ļ§ŽĺŚ§«ĹŇÕ◊§ √őłę§Ú§‚§Ņ§ť§∑§∆§≠§Ņ°•√śĪ—łž§ň§™§Ī§Žń÷Ľķ§ő√ŌÕżŇ™ ¨…ا¨°§»Į≤Ľ§ő√ŌÕżŇ™ ¨…ا»∆ĪÕÕ§ň żłņ≥ōŇ™§ ≤Ń√Õ§Ú§‚§√§∆§§§Ž§≥§»§ÚŐņ§ť§ę§ň§∑§Ņ°•§Ĺ§ž§ř§«§Ō°§ń÷Ľķ§Ō»Į≤Ľ§ňĹĺ¬į§Ļ§Ž∆ůľ°Ň™§ ¬ő∑Ō§«§Ę§Í°§ń÷Ľķ§ő√ŌÕżŇ™ ¨…ا¨ň‹ľŃŇ™§ňĹŇÕ◊§ ≤Ń√Õ§Ú§‚§√§∆§§§Ž§»§Ō§Ŗ§ §Ķ§ž§∆§§§ §ę§√§Ņ§¨°§LALME §Ōń÷Ľķ§Ú∆»ő©§∑§∆ī—Ľ°§Ķ§ž§Ž§Ŕ§≠¬ő∑Ō§»§∑§∆įŐ√÷§Ň§Ī§Ņ§ő§«§Ę§Ž°•ń÷Ľķ§Ú»Į≤Ľ§ę§ť≤Ú Ł§∑§Ņ§»§«§‚łņ§™§¶§ę°•
°°√śĪ—łž żłņ≥ō§Ō°§1986«Į§ő LALME §őҖ垧ň§Ť§√§∆į’…ŧÚ∆Õ§ę§ž§ §¨§ť°§Ņ∑§Ņ§ √ ≥¨§ň∆Ģ§Ž§≥§»§ň§ §√§Ņ°•§≥§≥§ňįžľÔ§ő≤Ú Łī∂§ §ť§Ő≥ę Łī∂§¨§Ę§√§Ņ§≥§»§Ō≥ő§ę§«§Ę§Ž°• łĹ٧«§∑§ęĽń§Ķ§ž§∆§§§ §§√śĪ—łž§őłņłžŇ™ľ¬¬÷°§§≥§»§ň»Į≤Ľ§őľ¬¬÷§ÚŃ…§ť§Ľ§Ņ§§§»Ľ◊§®§–°§ń÷Ľķ§őŐš¬Í§ňĻ‘§≠√Ś§§§∆§∑§ř§¶°•ń÷Ľķ§¨§…§ő§Į§ť§§√ťľ¬§ň»Į≤Ľ§Ú…ŧԧ∑§∆§§§Ž§ő§ę§Ō°§§ř§Ķ§ň≥÷∑§ŃŖŠŕ§Ņ§ŽŐš¬Í§«§Ę§Ž°•ő„§®§–°§į≠ŐĺĻ‚§§§‚§ő§ňłĹ¬ŚĪ—łž§ő shall §ň¬–ĪĢ§Ļ§ŽłŚīŁ√śĪ—łž East Anglia √Ō ż§őń÷Ľķ xul, xal §¨§Ę§Ž° §≥§őłž§ő¬ĺ§őīŮŐĮ§ ń÷Ľķ§Ō MED §ÚĽ≤ĺ»°ň°•§≥§ő <x> §ő łĽķ§«…ŧԧĶ§ž§Ž≤Ľ≤ѧŌ [ks] § §ő§ę [ʃ] § §ő§ę°§§Ę§Ž§§§Ō Ő§ő≤Ľ§ §ő§ę°•§≥§ő§Ť§¶§ ∆ŮŐš§¨ő©§Ń§Ō§ņ§ę§Ž§ §ę§«°§ń÷Ľķ§»»Į≤Ľ§ÚįžŇŔņŕ§Íő•§∑§∆ĻÕ§®§∆§Ŗ§Ť§¶°§ń÷Ľķ§ő¬¶§ņ§Ī§«§‚∆»ő©§∑§∆ĻÕĽ°§∑§∆§Ŗ§Ť§¶°§§»§§§¶ł¶ĶśĺŚ§őŃ™¬ÚĽŤ§¨ÕŅ§®§ť§ž§Ž§≥§»§»§ §√§Ņ°•
°°§∑§ę§∑°§»Į≤Ľ§őľŲ«Ż§ę§ť§ő≤Ú Łī∂§ŌĪ Ķ◊§ň¬≥§Į§Ô§Ī§«§Ō§ §§°•LALME §őĹ–»«łŚ°§° ĽĢ¬Ś§»§∑§∆§Ō§Ť§ÍłŇ§§§¨°ň§Ĺ§ő¬≥ ‘§»§∑§∆ LAEME §ő•◊•Ū•ł•ß•Į•»§¨ĽŌ§ř§√§Ņ§¨°§•◊•Ū•ł•ß•Į•»§őłŚ»ĺ§ę§ťň‹≥ Ň™§ňĽ≤≤√§∑§ŅőÚĽň∑Ѭ÷≤ĽĪ§Ōņ§őÕżŌņ≤» Lass §Ō°§ń÷Ľķ§»»Į≤Ľ§őīō∑ł§Úļ∆ĻÕ§∑§∆ľ°§ő§Ť§¶§ňĹ“§Ŕ§∆§§§Ž°•
The statement in LALME (vol. 1, 6) that the maps constitute 'a dialect atlas of written Middle English', and that texts are 'treated as examples of a system of written language in its own right' is often misinterpreted. The emphasis on the independent value of written evidence was particularly apposite two decades ago, given the post-Bloomfieldian view that was current then (and to a large extent still is) that writing is of no independent linguistic interest, but merely 'parasitic on' speech. But this must not be misunderstood and taken to imply that phonological interpretation is per se unnecessary. The LALME editors take no such line. They were fully aware of the potential phonological implications of their data. LALME is rich in phonological commentary, while the series of Dot Maps (vol. 1) crucially depends on acknowledging the relationship between sound and symbol. (Lass and Laing 11--12)
°°§≥§ž§Ō°§20«Į§Ř§…§ő≤Ú Łī∂§őłŚ§« xul §ő≤Ľ≤ѧŌ≤Ņ§ę§»§§§¶į≠Őī§ő§Ť§¶§ Őš¬Í§ňő©§Ń ÷§ť§ §Ī§ž§–§ §ť§ §§§»§§§¶ņŽłņ§ņ§Ū§¶§ę°•ĺŚ§őŌņ ł§«§ §Ķ§ž§∆§§§Ž Lass and Laing §ő łĽķŌņ°§ĹŮĶ≠Ń«Ōņ§őĻÕĽ°§Ō°§ĹťīŁ√śĪ—łž§őń÷ĽķŐš¬Í§ň§»§…§ř§ť§ļ°§łĹ¬ŚĪ—łž§őń÷Ľķ§»»Į≤Ľ§őīō∑ł§ň§‚łų§ÚÕŅ§®§Ž§‚§ő§«§Ę§Í°§∆…§ŖĪĢ§®§¨§Ę§Ž°•
°°°¶ Lass, Roger and Margaret Laing. "Interpreting Middle English." Chapter 2 of "A Linguistic Atlas of Early Middle English: Introduction." Available online at http://www.lel.ed.ac.uk/ihd/laeme1/pdf/Introchap2.pdf .
°°°¶ McIntosh, Angus, M. L. Samuels, and M. Benskin. A Linguistic Atlas of Late Mediaeval English. 4 vols. Aberdeen: Aberdeen UP, 1986.
2009-07-29 Wed
Ę£ #93. third §ő≤ĽįŐŇĺīĻ§Ō§§§ńĶĮ§≥§√§Ņ§ę (2) [metathesis][spelling][lalme][laeme]
°°ļÚ∆Ł§őĶ≠ĽŲ[2009-07-28-1]§ňįķ§≠¬≥§≠°§third §ő≤ĽįŐŇĺīĻ§¨§§§ńĶĮ§≥§√§Ņ§ę°•ļ£≤ů§Ō°§łŚīŁ√śĪ—łž§Úľť»ų»ŌįŌ§»§Ļ§Ž LALME §Úłę§∆§Ŗ§Ž°•ňŐ…Ű żłņ§ňł¬§√§∆§őįŘń÷§Í•Í•Ļ•»§ §ő§«°§Ńī¬őŃŁ§Ō§Ô§ę§ť§ §§§‚§ő§ő°§ľ®ļ∂Ň™§ ¨…ا«§Ę§Ž°•
terd, thed, therd, therdde, therde, third, thirdde, thirde, thrd, thre, thred, thredd, thredde, threde, thrid, thridd, thridde, thride, thryd, thrydd, thrydde, thryde, thryde, thyrde, thyrd, trid, tyrd, þerd, þerde, þird, þirdde, þirde, þred, þred, þredde, þrede, þrid, þrid-, þridde, þride, þryd, þrydd, þrydde, þryde, þyrd, yerdde, yird, yirdde, yirde, yred, yredde, yrede, yrid, yridde, yride, yryd, yryde
ĹťīŁ√śĪ—łž§«§Ō≤ĽįŐŇĺīĻ§Ō§Ř§»§ů§…ĶĮ§≥§√§∆§§§ §ę§√§Ņ§¨°§łŚīŁ√śĪ—łž§«§Ō≤ĽįŐŇĺīĻ§Ú∑–§Ņ < ž≤Ľ + r> §¨°§3 ¨§ő1∂Į§őń÷§Í§ň≥ő«ß§Ķ§ž§Ž°•∆√§ň…—ŇŔ§őĻ‚§§ń÷§Í§Ō°§third, thrid, thridde, thryd, thyrd §Ę§Ņ§Í§ņ§¨°§§Ĺ§ő§¶§Ń§ő∆ů§ń§¨≤ĽįŐŇĺīĻ§Ú§Ļ§«§ň∑–§∆§§§Žń÷§Í§«§Ę§Ž°•
°°Ľ≤ĻÕ§ř§«§ň°§•™•ů•ť•§•ů»«§ő Middle English Dictionary §ę§ť thrid §Ú§ő§ĺ§§§∆°§įŘń÷§Í§Ú≥ő«ß§∑§∆§Ŗ§Ž§≥§»§Úī꧊§Ž°•
°°ĺŚĶ≠§ę§ť°§≤ĽįŐŇĺīĻ∑ѧŌ∆ÕŃ≥§ňĻ≠§ř§√§Ņ§Ô§Ī§«§Ō§ §Į°§§ś§√§Į§Í§»≥őľ¬§ň ¨…اÚĻ≠§¨§√§∆§≠§Ņ§≥§»§¨ ¨§ę§Ž°•10ņ§Ķ™»ĺ§–§őłŇĪ—łž§őĽĢ¬Ś§ň ðirdda §»§§§¶≤ĽįŐŇĺīĻ∑ѧ¨Õ—§§§ť§ž§∆§§§Žő„§‚§Ę§Í°§§Ĺ§őļʧ꧝īňňż§ň ¨…اÚĻ≠§≤§∆§≠§Ņ§ő§ņ§Ū§¶°•ļ«Ĺ™Ň™§ň third §ňńÍ√Ś§Ļ§Ž§ő§Ō∂Š¬ŚĪ—łžīŁ§ň§ §√§∆§ę§ť§ņ§»ŃŘńͧĶ§ž§Ž§¨°§≥őľ¬§ §≥§»§Ō LAEME §š LALME §ňįķ§≠¬≥§≠°§ĹťīŁ∂Š¬ŚĪ—łž§ő•≥°ľ•—•Ļ§«įŘń÷§Í§őńīļļ§ÚĻ‘§¶…¨Õ◊§¨§Ę§Ž°•
°°°¶Laing, Margaret and Roger Lass, eds. A Linguistic Atlas of Early Middle English, 1150--1325. http://www.lel.ed.ac.uk/ihd/laeme1/laeme1.html . Online. Edinburgh: U of Edinburgh, 2007.
°°°¶McIntosh, Angus, Michael Louis Samuels, Michael Benskin, eds. A Linguistic Atlas of Late Mediaeval English. Aberdeen: Aberdeen UP, 1986.
2009-07-28 Tue
Ę£ #92. third §ő≤ĽįŐŇĺīĻ§Ō§§§ńĶĮ§≥§√§Ņ§ę [metathesis][spelling][lalme][laeme]
°°[2009-06-27-1]§«ľŤ§Í§Ę§≤§Ņ§¨°§≤ĽįŐŇĺīĻ ( metathesis ) §ő¬Ś…Ĺő„§őįž§ń§ň third §¨§Ę§Ž°•łŇĪ—łž§őń÷§Í þridda §ę§ť°§§ř§ŅłĹ¬ŚĪ—łž§ő¬–ĪĢ§Ļ§ŽīūŅŰĽž three §őń÷§Í§ę§ť ¨§ę§Ž§»§™§Í°§ň‹ÕŤ§Ō <ir> §«§Ō§ §Į <ri> §»§§§¶ĹÁĹݧņ§√§Ņ°•§»§≥§Ū§¨°§łŚ§ň≤Ľ§őįŐ√÷§¨ŇĺīĻ§∑°§łĹ¬Ś…łĹŗłž§őń÷§Í§ňÕÓ§Ń√Ś§§§Ņ°•
°°§«§Ō°§§§§ń§≥§ő≤ĽįŐŇĺīĻ§¨ĶĮ§≥§√§Ņ§ő§ę°•[2009-06-21-1]§«ĺ“≤ū§∑§Ņ LAEME §» LALME §»§§§¶√śĪ—łž§őń÷§Í§ÚĹŗŐ÷ÕŚŇ™§ňĹłņ—§∑§ŅĽŮőѧÚÕ—§§§ž§–¬Á¬ő§ő§≥§»§Ō§Ô§ę§Ž°•ļ£≤ů§Ō°§ĹťīŁ√śĪ—łž ( Early Middle English ) §Úľť»ų»ŌįŌ§»§Ļ§Ž LAEME §«ńī§Ŕ§∆§Ŗ§Ņ°•
°°LAEME §Ō•™•ů•ť•§•ů§«ÕÝÕ—§«§≠§Ž§ő§«°§ľ¬ļ›§ňį ≤ľ§őľÍĹÁ§ÚĽÓ§∑§∆§‚§ť§§§Ņ§§°•TAG DICTIONARY -> Numbers §»§Ņ§…§√§∆Ī¶¬¶§ő•÷•ť•¶•∂§ňłĹ§ž§ŽńĻ§§•Í•Ļ•»§¨°§ŅŰĽž§őįŘń÷§ÍĹł§«§Ę§Ž°•Ķ≠Ļś§ő∆…§Ŗ ż§Ō¬ŅĺĮī∑§ž§Ž…¨Õ◊§¨§Ę§Ž§¨°§"3/qo" §¨°÷3§őĹÝŅŰĽž°◊§ń§ř§Í third §ň¬–ĪĢ§Ļ§Ž•Ņ•į§ §ő§«°§§≥§ž§Ú•≠°ľ•Ô°ľ•…§ňł°ļų§Ú§ę§Ī§ž§–°§13Ļ‘§Ř§…§¨•“•√•»§Ļ§Ž°•įŘń÷§Í§ÚņįÕż§Ļ§Ž§»°§į ≤ľ§őńէͰ•
dridde, Dridðe, thred, thrid, thridde, thride, thrid/de, trhed, tridde, tridde, þerdde, þr/idde, þred, þredde, þri/de, þrid, þrid/de, þrid/den, þridda, þriddan, Þridde, þridde, þridden, þride, þridðe, þrid/de, þrirde, þri[d]/de, ðridde, Ðridde, ðride, yridde, yridden
į 匧꧝°§≤ĽįŐŇĺīĻ§¨ĶĮ§≥§√§∆§§§Ž§ő§Ō þerdde §Į§ť§§§«°§§ř§ņ§ř§ņĹťīŁ√śĪ—łžīŁ§ő√ ≥¨§«§Ō <ri> §¨įĶқҙ§ņ§»§§§¶§≥§»§¨§Ô§ę§Ž°•
°°ľō¬≠§ņ§¨°§≤ś§¨≤»§ň§™§Ī§Žļ«∂Š§ő≤ĽįŐŇĺīĻ§ő•“•√•»ļÓ§Ō°÷őĶ§ő§™ĽŇĽŲ°◊° Ęę°÷•Ņ•ń•ő•™•»•∑•ī°◊°ň§«§Ę§Ž°•§ņ§¨°§§≥§ž§ņ§Ī«Ř√÷¬ō§®§Ķ§ž§∆§∑§ř§√§∆§Ō°§√ĪĹ„§ň≤ĽįŐŇĺīĻ§»ł∆§Ŕ§Ž§ő§ę§…§¶§ę§Ō…‘Őņ§«§Ę§Ž°•
°°°¶Laing, Margaret and Roger Lass, eds. A Linguistic Atlas of Early Middle English, 1150--1325. http://www.lel.ed.ac.uk/ihd/laeme1/laeme1.html . Online. Edinburgh: U of Edinburgh, 2007.
°°°¶McIntosh, Angus, Michael Louis Samuels, Michael Benskin, eds. A Linguistic Atlas of Late Mediaeval English. Aberdeen: Aberdeen UP, 1986.
2009-07-16 Thu
Ę£ #79. ľÍŌ√łņłž≥ō§ę§ť§ő inspiration [sign_linguistics][double_articulation][origin_of_language][lalme][laeme]
°°ļ£∆Ł§Ō°§Ī—łžĽň§ňńĺņ‹§ę§ę§Ô§ŽŌ√§«§Ō§ §§§¨°§łņłž§őĶĮłĽ§šłņłž —≤ŧÚĻÕ§®§Žļ›§ň•“•ů•»§ÚÕŅ§®§∆§Į§ž§ŽľÍŌ√łņłž≥ō ( sign linguistics ) §»§§§¶ ¨ŐÓ§Úĺ“≤ū§∑§Ņ§§°•ĺ“≤ū§Ļ§Ž§»§§§√§∆§‚°§Ľš§‚§ń§§ņŤ∆Ł§Ĺ§ő¬łļŖ§Ú√ő§√§Ņ§–§ę§Í§ §ő§«°§»ůĺÔ§ň§™§≥§¨§ř§∑§§§¨°§ĶŲ§∑§∆§§§Ņ§ņ§≠§Ņ§§°•∑–įř§ÚĹ“§Ŕ§ž§–°§ļ£∑ÓĻś§ő°ō∑Óī©łņłž°Ŕ§¨ľÍŌ√łņłž≥ō§ő∆√Ĺł§ÚŃ»§ů§«§™§Í°§§Ĺ§ž§Ú∆…§ů§« inspiration §Ú§ę§≠ő©§∆§ť§ž§Ņ§ņ§Ī§őŌ√§«§Ę§Ž°•
°°ľÍŌ√łņłž≥ō§ő√śŅ»§ň§ń§§§∆§Ō≤Ņ§‚§Ô§ę§ť§ §§§¨°§§Ĺ§ž§¨łņłž§őĶĮłĽ§šĶ°«Ĺ§ÚĻÕ§®§Žļ›§ň°§¬Ņ§Į§őľ®ļ∂§ÚÕŅ§®§∆§Į§ž§Ĺ§¶§ņ§»§§§¶∆ų§§§Ōī∂§ł§Ž§≥§»§¨§«§≠§Ņ°•§…§ő§Ť§¶§ Ňņ§«ľ®ļ∂Ň™§ §ő§ę°•ŅņŇńŌ¬Ļ¨ĽŠ§ň§Ť§Žį ≤ľ§ő•›•§•ů•»§¨ ¨§ę§Í§š§Ļ§§ (10)°•
°°°¶≤Ľņľłņłž§Ú≥Õ∆ņ§«§≠§ §§Ōłľ‘§¨ľÍŌ√§Ú»Įņł§Ķ§Ľ§Ž§ő§Ō§ §ľ§ę
°°°¶∆į ™§ň§‚•Ķ•§•ů§¨ ¨§ę§Í§š§Ļ§§§ő§Ō§ §ľ§ę
°°°¶≤Ľņľłņłž§¨ńŐ§ł§ §§ŅÕī÷∆ĪĽő§¨Ņ»Ņ∂§Í§«Ňѧ®§Ť§¶§»§Ļ§Ž§ő§Ō§ §ľ§ę
°°°¶≤Ľņľłņłž§Ú»Į§∑§ §¨§ťŐĶį’ľĪ§ň•ł•ß•Ļ•Ń•„°ľ§Ļ§Ž§ő§Ō§ §ľ§ę
°°§ń§ř§Í°§≤Ľņľłņłž§ő»Įņł§ňņŤĻ‘§∑§∆Ņ»Ņ∂§Íłņłž§¨»Įņł§∑§∆§§§Ņ§≥§»§ŌÕ∆į◊§ňŃŘŃŁ§Ķ§ž°§§Ĺ§őŅ»Ņ∂§Íłņłž§¨¬ő∑ŌŇ™§ňņįÕż§Ķ§ž§Ņ§‚§ő§¨ľÍŌ√łņłž§»ĻÕ§®§ž§–°§ľÍŌ√łņłžł¶Ķś§¨łņłžĶĮłĽņ‚§ňĻ◊ł•§∑§¶§Ž§»§§§¶§≥§»§ŌľęŐņ§ő§Ť§¶§ňĽ◊§Ô§ž§Ž°•
°°ņű≥ō»ůļÕ§Ú§Ķ§ť§ĪĹ–§Ļ§¨°§ľÍŌ√łņłž§Ō≤Ľņľłņłž§ň…§Ň®§Ļ§Ž»ůĺÔ§ň £Ľ®§«ņļŚŐ§ ∆‚…۬ő∑Ō§Ú§‚§√§∆§§§Ž§»§§§¶§≥§»§‚Ĺť§Š§∆√ő§√§Ņ°•ľÍŌ√łņłž§ňłž◊√§¨§Ę§Í łň°§¨§Ę§Ž§≥§»§Ō«ýŃ≥§»√ő§√§∆§§§∆§‚°§∑Ѭ÷Ōņ§¨§Ę§Í°§§ §ů§»≤ĽĪ§Ōņ° §ňŃÍŇŲ§Ļ§Ž§‚§ő°ň§‚§Ę§Ž§»§§§¶§ę§ť∂√§≠§ņ°••Ę•ů•…•ž°¶•ř•Ž•∆•£•Õ§ő§§§¶łņłž§ő∆ůĹŇ ¨ņŠ ( double articulation ) §¨ľÍŌ√łņłž§ň§‚őÚŃ≥§»¬łļŖ§Ļ§Ž§»§§§¶°•
°°2008«Į5∑Ó3∆Ł§ň»Įłķ§∑§Ņ°§ĻŮļ›ŌĘĻÁ§ő°÷ĺ„≥≤§ő§Ę§ŽŅÕ§őłĘÕݧňīō§Ļ§ŽĺÚŐů°◊§ő¬Ť∆ůĺÚ°÷ńÍĶŃ°◊§őĻŗ§«°§ľÍŌ√§ §…§ő»ů≤Ľņľłņłž§‚≤Ľņľłņłž§»∆ĪÕÕ§ň°÷łņłž°◊§»įŐ√÷§Ň§Ī§ŽĽ›§¨ŐņĶ≠§Ķ§ž§∆§§§Ž§»§§§¶° ĺÚŐů§őĪ— ł§Ō§≥§Ń§ť°ň°•ľÍŌ√łņłž§Ō°§Ő徬§»§‚§ň°§őÚ§»§∑§Ņłņłž§ §ő§ņ§Ĺ§¶§ņ°•
°°ň‹•÷•Ū•į§őľŮĽ›§ň∂Š§§Ō√¬Í§Ú§Ę§≤§ž§–°§≤Ľņľłņłž§ő żłņ§šłņłž —≤ŧňŃÍŇŲ§Ļ§Ž§‚§ő§¨ľÍŌ√łņłž§ň§‚§Ę§Ž§»§§§¶°•ĻÕ§®§∆§Ŗ§ž§–°§ľÍŌ√łņłž§ň żłņ§šńŐĽĢŇ™ —≤ŧ¨§Ę§√§∆§‚≥ő§ę§ň…‘Ľ◊Ķń§«§Ō§ §§°•∆Łň‹ľÍŌ√łņłž√ŌŅř§őļÓņģ§¨∑◊≤Ť§Ķ§ž§∆§§§Ž§»§§§¶§ő§‚§¶§ §ļ§Ī§Ž°•
°°ľÍŌ√łņłž≥ō§Ō°§°÷łņłž°Š≤Ľņľłņłž°◊§»§§§¶ĹĺÕŤ§őŃįńů§ę§ť§Ōņł§ř§ž∆ņ§ §§°§łņłž§őň‹ľŃ§ň«ų§ŽŅ∑§Ņ§ ĽŽŇņ§Úńů∂°§∑§∆§Į§ž§Ž°§»ĮŃاőľÔ§ň§ §Ž§ę§‚§∑§ž§ §§°•√śĪ—łž§őń÷§ÍĽķ§ő —įاÚ√ŌŅř匧ň•◊•Ū•√•»§∑§Ņ LALME §š LAEME ([2009-06-21-1]) §¨Ī—łžĽňł¶Ķś§ňŅ∑ĽĢ¬Ś§Ú§‚§Ņ§ť§∑§∆§≠§Ņ§≥§»§ÚĻÕ§®§Ž§»°§ĽŽ≥–łņłž§ň§‚§√§»√ŪŐ‹§¨Ĺł§ř§√§∆§‚§Ť§§°•°÷łņłž°Š≤Ľņľłņłž°◊§»§§§¶»»§Ļ§Ŕ§ę§ť§∂§Žłņłž≥ō§ő¬ÁŃįńů§ÚĺĮ§∑Õ…§Ž§¨§∑§∆§Ŗ§Ž§ő§‚ŐŐ«Ú§§§ő§«§Ō§ §§§ę°•§Ĺ§őį’Ő£§«°§ľÍŌ√łņłž≥ō§Ō°§≤Ľņľłņłž§«§Ō§ §Į łĽķłņłž§ň§…§√§◊§ÍŅĽ§ę§√§∆§§§Ž łł•≥ōł¶Ķś§ň§»§√§∆§‚Ņī∂Į§§√Áī÷§ň§ §Ž§ę§‚§∑§ž§ §§°•
°°°¶McIntosh, Angus, Michael Louis Samuels, Michael Benskin, eds. A Linguistic Atlas of Late Mediaeval English. Aberdeen: Aberdeen UP, 1986.
°°°¶Laing, Margaret and Roger Lass, eds. A Linguistic Atlas of Early Middle English, 1150--1325. http://www.lel.ed.ac.uk/ihd/laeme1/laeme1.html . Online. Edinburgh: U of Edinburgh, 2007.
2009-06-21 Sun
Ę£ #54. through įŘń÷§Í•Ŕ•Ļ•»10° •Ô°ľ•Ļ•»10°©°ň [spelling][lalme][laeme][oed][me_dialect][through]
°°ļÚ∆Ł[2009-06-20-1]§őĶ≠ĽŲ§« through §őń÷§Í§¨łŚīŁ√śĪ—łžīŁ§ņ§Ī§«§‚515ńէͧʧ√§Ņ§≥§»§Úĺ“≤ū§∑§Ņ°•§Ĺ§≥§«Ĺ٧≠ňļ§ž§Ņ§ő§ņ§¨°§§…§≥§ę§ť§≥§ő§Ť§¶§ ĺū ů§¨∆ņ§ť§ž§Ž§ę§»§§§¶§≥§»§«§Ę§Ž°•§ř§Ķ§ę°§√į«į§ň√śĪ—łž§ő•∆•≠•Ļ•»§Ú§∑§ť§Ŗ§ń§÷§∑§ň∆…§ů§«°§įž§ńįž§ń through §»§™§‹§∑§≠∑Ѭ÷§Ú§Ľ§√§Ľ§»ľżĹł§∑§Ņ§»§§§¶§Ô§Ī§«§Ō§ §§°•§ř§Ņ°§ŇŇĽ“•≥°ľ•—•Ļ§»§∑§∆Ńī•∆•≠•Ļ•»§¨ł°ļų≤ń«Ĺ§ň§ §√§∆§§§Ņ§»§∑§∆§‚°§lemmatise° łęĹ–§∑łž≤Ĺ°ň§Ķ§ž§∆§§§ §Ī§ž§–°§§Ĺ§‚§Ĺ§‚ł°ļųÕů§ň§…§őń÷§ÍĽķ§Ú∆ĢőŌ§Ļ§ž§–§§§§§ő§ę§¨…‘Őņ§«§Ę§Ž°•
°° żň°§őįž§ń§»§∑§∆ Oxford English Dictionary ( OED ) §őÕÝÕ—§¨§Ę§Ž°•§≥§őĶś∂ň§őĪ—Ī—ľ≠Ĺ٧Ō°§łŇĪ—łž§ę§ťłĹ¬ŚĪ—łž§ř§«§ő≥∆√Īłž§őįŘń÷§Í§ÚŅ۬Ņ§Į∑«ļ‹§∑§∆§§§Ž°•≥ő§ę§ň»∆Õ—Ň™§ňĽ»§®§Ž żň°§ņ§¨°§OED §«through §Úįķ§§§∆§Ŗ§Ž§»°§§Ľ§§§ľ§§ŅŰĹŧőįŘń÷§Í§∑§ę∆ņ§ť§ž§ §§°•
°°§‚§¶įž§ń§ő żň°§Ō°§A Linguistic Atlas of Late Mediaeval English ( LALME ) §őÕÝÕ—§«§Ę§Ž°•§≥§ž§Ō°§Ń™§–§ž§Ņīūň‹łž§őįŘń÷§Í§¨•÷•Í•∆•ůŇÁ§ő√ŌŅř§ő匧ň•◊•Ū•√•»§Ķ§ž§∆§§§Ž°÷ żłņ√ŌŅř°◊§«§Ę§Ž°•ĽĢ¬Ś§ŌłŚīŁ√śĪ—łž§ňł¬§ť§ž§∆§§§Ž§‚§ő§ő°§įŘń÷§Íł¶Ķś§ň§»§√§∆§ŌĶś∂ň§ő•ń°ľ•Ž§«§Ę§Ž°•ļ£≤ů§ő through §őįŘń÷§Í§‚ LALME §«§Ļ§«§ň§ř§»§Š§ť§ž§∆§§§Ž•Í•Ļ•»§Ú¬«§ŃĻĢ§ů§ņ§ņ§Ī§«§Ę§Ž°•LALME §őĹťīŁ√śĪ—łžīŁ§őĽ–ňŚ ‘§»§∑§∆ LAEME § §Ž§‚§ő§‚§Ę§Í°§§≥§Ń§ť§Ō•™•ů•ť•§•ů§«ÕÝÕ—≤ń«Ĺ§ §ő§«°§§ľ§“ĽÓ§Ķ§ž§Ņ§§° URL§ŌňŲ»Ý°ň°•
°°§Ķ§∆°§515ńէͧőőůĶů§ÚńĮ§Š§∆§§§Ž§»Ő‹§¨•Ń•ę•Ń•ę§∑§∆§Į§Ž§¨°§§Ĺ§ő√ś§«Ľš§ő∆»√«§» –łę§«Ń™§÷•Ŕ•Ļ•»10° •Ô°ľ•Ļ•»10§»§‚§§§®§Ž°ň§Ú°§∆Õ§√ĻĢ§Ŗ§Ú∆Ģ§ž§ §¨§ťĶů§≤§∆§Ŗ§Ť§¶°•
°°1. yhurght ° Ęę§Ř§‹ yoghurt°ň
°°2. trghug ° Ęę§Ř§‹»Į≤Ľ…‘≤ń«Ĺ°ň
°°3. thrwght ° Ęę ž≤ĽĽķ§ §∑°§§Ĺ§őįž°ň
°°4. thwrw ° Ęę ž≤ĽĽķ§ §∑°§§Ĺ§ő∆ů°ň
°°5. thrvoo ° Ęęv§√§∆°¶°¶°¶°ň
°°6. throw ° Ęęį„§¶√Īłž§ň§ §√§∆§Ž°ň
°°7. threw ° Ęę§Ĺ§ő≤ŠĶÓ∑ѧř§«§Ę§Ž°ň
°°8. yora ° Ę꧅§¶§∑§∆§≥§¶§ §Ž§ő°©°ň
°°9. ȝour ° Ęę§ §ľ°©°ň
°°10. through ° Ęę§Ń§„§ů§»§Ę§Ž§ł§„§ §§°™°ň
°°°¶McIntosh, Angus, Michael Louis Samuels, Michael Benskin, eds. A Linguistic Atlas of Late Mediaeval English. Aberdeen: Aberdeen UP, 1986.
°°°¶Laing, Margaret and Roger Lass, eds. A Linguistic Atlas of Early Middle English, 1150--1325. http://www.lel.ed.ac.uk/ihd/laeme1/laeme1.html . Online. Edinburgh: U of Edinburgh, 2007.
Powered by WinChalow1.0rc4 based on chalow