2019-06-29 Sat
■ #3715. 音節構造に Rhyme という単位を認める根拠 [syllable][phonetics][phonology][terminology]
「#1563. 音節構造」 ([2013-08-07-1]) で論じたように,音韻論的には英語の音節構造として「右枝分かれ構造」 (right-branching structure) を想定することが多い.図式的に表現すれば,以下のようにまず音節 (syllable = σ) が頭子音 (onset) と韻 (rhyme) に分かれ,後者がさらに核 (nucleus) と尾子音 (coda) に分かれる構造である.
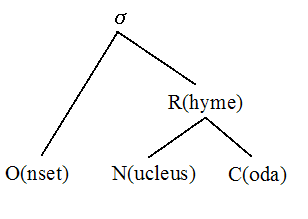
ところで,なぜこのような構造を想定するのが理論的に好都合なのだろうか.先の記事でも多少論じたが,今回は服部 (66) に従って,音声学・音韻論の観点からもう少し具体的に根拠を示そう.
英語の母音には,音節末に生起可能な開放母音と不可能な抑止母音の2種類が区別される.原則として,他の条件が同じであれば,抑止母音よりも開放母音のほうが長く発音される.また,開放母音に関しては,尾子音が後続しない場合に最も長く,次に有声尾子音が続くとき,そして無声尾子音が続くときという順序で母音の長さが短くなっていく.具体的な単語例で示せば,母音の短い順に bit < bid, beet < bead < bee と並べられることになる.
この事実を尾子音の種類に着目して言い換えれば,無声子音は有声子音よりも長く発音されるということになる.つまり,無声子音は比較的長い発音をもっているから,先行する母音はその分短く発音され,逆に有声子音は比較的短い発音をもっているから,先行する母音はその分長く発音されると解釈することができる.
このように考えると,核の母音と尾子音は長さに関して相補的・代償的な関係にあるといえる.同様の関係は頭子音と核の間には確認されないことから,上のような構造を想定するのが妥当だという結論に至るのである.
主として英語の韻文における伝統的な技巧として脚韻 (rhyme) が存在することは,それ自体では上の構造を想定する強力な根拠とはならないが,同構造が妥当であることの傍証にはなるだろう.
・ 服部 義弘 「第4章 音節・音連鎖・連続音制過程」服部 義弘(編)『音声学』朝倉日英対照言語学シリーズ 2 朝倉書店,2012年.64--83頁.
2019-04-19 Fri
■ #3644. 現代英語は stress-timed な言語だが,古英語は syllable-timed な言語? [prosody][phonology][stress][vowel][typology][syllable][poetry]
「#1647. 言語における韻律的特徴の種類と機能」 ([2013-10-30-1]) でみたように,英語は stress-timed なリズム,日本語は syllable-timed (or mora-timed) なリズムをもつ言語といわれる.前者は強勢が等間隔で繰り返されるリズムで,後者は音節(モーラ)が等間隔で繰り返されるリズムである.英語に近隣の言語でいえばドイツ語は stress-timed で,フランス語やスペイン語は syllable-timed である.
このように共時的な類型論の観点からは諸言語をいずれかのリズムかに振り分けられるが,通時的にみると各言語のリズムは不変だったのだろうか,あるいは変化してきたのだろうか.
英語に関していえば,ある見方からは確かに変化してきたといえる.現代英語の stress-timed リズムの基盤にあるのは曖昧母音 /ə/ の存在である.強勢のある明確な音価と音量をもつ母音と,弱く短く発音される曖昧母音とが共存しているために,前者を核とした韻律の単位が定期的に繰り返されることになるのだ.しかし,古英語では曖昧母音が存在しなかったので,stress-timed リズムを成立させる基盤が弱かったことになる.古英語はむしろ syllable-timed リズムに近かったともいえるのである.Cable (23--24) の議論を聞こう.
To begin with, Old English did not have reduced vowels. The extensive system of inflectional endings depended on the full values of the short vowels, especially [ɑ], [ɛ], [u], and [ɔ]; and in polysyllabic words these and other short vowels were not reduced to schwa. The surprising effect is that in its lack of reduced vowels Old English can be said to have similarities with the phonological structure of a syllable-based language like Spanish. In this respect, both Old English and Spanish differ from Late Middle English and Modern English. Consequently, Old English can be hypothesized to have more of the suprasegmental structure of syllable-based languages---that is, the impression of syllable-timing---despite our thinking of Old English as thoroughly Germanic and heavily stressed.
Cable は,古英語が完全な syllable-timed な言語だと言っているわけではない.強勢ベースのリズムの要素もあるし,音節ベースのそれもあるとして,混合的なリズムだと考えている.上の節に続く文章も引用しておこう.
These deductions and hypotheses from theoretical and experimental phonology are supported in the most recent studies of the meter of Old English poems. Beowulf has never been thought of as a poem in syllabic meter. Yet the most coherent way to imagine Old English meter is as a precisely measured mix of "accentual" elements (as the meter has traditionally been understood), "syllabic" elements (which may seem more appropriate for French verse), and "quantitative" elements (which are most familiar in Greek and Latin). (Cable 24)
・ Cable, Thomas. "Restoring Rhythm." Chapter 3 of Approaches to Teaching the History of the English Language: Pedagogy in Practice. Introduction. Ed. Mary Heyes and Allison Burkette. Oxford: OUP, 2017. 21--28.
2015-12-26 Sat
■ #2434. 形容詞弱変化屈折の -e が後期中英語まで残った理由 [adjective][ilame][syllable][pronunciation][prosody][language_change][final_e][speed_of_change][schedule_of_language_change][language_change][metrical_phonology][eurhythmy][inflection]
英語史では,名詞,動詞,形容詞のような主たる品詞において,屈折語尾が -e へ水平化し,後にそれも消失していったという経緯がある.しかし,-e の消失の速度や時機 (cf speed_of_change, schedule_of_language_change) については,品詞間で差があった.名詞と動詞の屈折語尾においては消失は比較的早かったが,形容詞における消失はずっと遅く,Chaucer に代表される後期中英語でも十分に保たれていた (Minkova 312) .今回は,なぜ形容詞弱変化屈折の -e は遅くまで消失に抵抗したのかについて考えたい.
この問題を議論した Minkova の結論を先取りしていえば,特に単音節の形容詞の弱変化屈折における -e は,保持されやすい韻律上の動機づけがあったということである.例えば,the goode man のような「定冠詞+形容詞+名詞」という統語構造においては,単音節形容詞に屈折語尾 -e が付くことによって,弱強弱強の好韻律 (eurhythmy) が保たれやすい.つまり,統語上の配置と韻律上の要求が合致したために,歴史的な -e 語尾が音韻的な摩耗を免れたのだと考えることができる.
ここで注意すべき点が2つある.1つは,古英語や中英語より統語的に要求されてきた -e 語尾が,eurhythmy を保つべく消失を免れたというのが要点であり,-e 語尾が eurhythmy をあらたに獲得すべく,歴史的には正当化されない環境で挿入されたわけではないということだ.eurhythmy の効果は,積極的というよりも消極的な効果だということになる.
2つ目に,-e を保持させるという eurhythmy の効果は長続きせず,15--16世紀以降には結果として語尾消失の強力な潮流に屈しざるを得なかった,という事実がある.この事実は,eurhythmy 説に対する疑念を生じさせるかもしれない.しかし,eurhythmy の効果それ自体が,時代によって力を強めたり弱めたりしたことは,十分にあり得ることだろう.eurhythmy は,歴史的に英語という言語体系に広く弱く作用してきた要因であると認めてよいが,言語体系内で作用している他の諸要因との関係において相対的に機能していると解釈すべきである.したがって,15--16世紀に形容詞屈折の -e が消失し,結果として "dysrhythmy" が生じたとしても,それは eurhythmy の動機づけよりも他の諸要因の作用力が勝ったのだと考えればよく,それ以前の時代に関する eurhythmy 説自体を棄却する必要はない.Minkova (322--23) は,形容詞屈折語尾の -e について次のように述べている.
. . . the claim laid on rules of eurhythmy in English can be weakened and ultimately overruled by other factors such as the expansion of segmental phonological rules of final schwa deletion, a process which depends on and is augmented by the weak metrical position of the deletable syllable. The 15th century reversal of the strength of the eurhythmy rules relative to other rules is not surprising. Extremely powerful morphological analogy within the adjectives, analogy with the demorphologization of the -e in the other word classes, as well as sweeping changes in the syntactic structure of the language led to what may appear to be a tendency to 'dysrhythmy' in the prosodic organization of some adjectival phrases in Modern English. . . . The entire history of schwa is, indeed, the result of a complex interaction of factors, and this is only an instance of the varying force of application of these factors.
英語史における形容詞屈折語尾の問題については,「#532. Chaucer の形容詞の屈折」 ([2010-10-11-1]),「#688. 中英語の形容詞屈折体系の水平化」 ([2011-03-16-1]) ほか,ilame (= Inflectional Levelling of Adjectives in Middle English) の各記事を参照.
なお,私自身もこの問題について論文を2本ほど書いています([1] Hotta, Ryuichi. "The Levelling of Adjectival Inflection in Early Middle English: A Diachronic and Dialectal Study with the LAEME Corpus." Journal of the Institute of Cultural Science 73 (2012): 255--73. [2] Hotta, Ryuichi. "The Decreasing Relevance of Number, Case, and Definiteness to Adjectival Inflection in Early Middle English: A Diachronic and Dialectal Study with the LAEME Corpus." 『チョーサーと中世を眺めて』チョーサー研究会20周年記念論文集 狩野晃一(編),麻生出版,2014年,273--99頁).
・ Minkova, Donka. "Adjectival Inflexion Relics and Speech Rhythm in Late Middle and Early Modern English." ''Papers from the 5th International
2015-06-07 Sun
■ #2232. High Vowel Deletion [high_vowel_deletion][phonetics][vowel][syllable][inflection][morphology][sound_change]
標記の音韻過程について「#1674. 音韻変化と屈折語尾の水平化についての理論的考察」 ([2013-11-26-1]),「#2017. foot の複数はなぜ feet か (2)」 ([2014-11-04-1]),「#2225. hear -- heard -- heard」 ([2015-05-31-1]) で触れてきたが,今回はもう少し詳しく説明したい.この過程は,i-mutation よりも後に,おそらく前古英語 (pre-OE) の後期に生じたとされる音韻変化であり,古英語の音韻形態論に大きな影響を及ぼした.Lass (98) の端的な説明によれば,HVD (High Vowel Deletion) は以下のようにまとめられる.
The fates of short high */i, u/ in weak positions are largely determined by the weight of the preceding strong syllable. In outline, they deleted after a heavy syllable, but remained after a light one, in the case of */i/ usually lowering to /e/ at a later stage.
語幹音節が重い(rhyme が3モーラ以上からなる)場合に,続く弱い音節の高母音 (/i/, /u/) が消失するという過程である.先行する語幹音節が重い場合には,すでに全体として重いのだから,さらに高母音を後続させて余計に重くするわけにはいかない,と解釈してもよい.かくして,語幹音節の軽重により,続く高母音の有無が切り替わるケースが生じることとなった.Lass (99--100) を参考に,古英語からの例を挙げよう.HVD が作用した例は赤で示してある.
| Syllable weight | pre-OE | OE |
|---|---|---|
| heavy | *ðα:ð-i | dǣd 'deed' |
| heavy | *wurm-i | wyrm 'worm' |
| light | *win-i | win-e 'friend' |
| heavy | *flo:ð-u | flōd 'flood' |
| heavy | *xαnð-u | hand 'hand' |
| light | *sun-u | sun-u 'son' |
| heavy | *xæur-i-ðæ | hīer-de 'heard' |
| light | *nær-i-ðæ | ner-e-de 'saved' |
古英語の形態論では,以下の屈折において HVD の効果が観察される (Lass 100) .
(i) a-stem neuter nom/acc sg: light scip-u 'ships' vs. heavy word 'word(s)', bān 'bone(s)'.
(ii) ō-stem feminine nom sg: light gief-u 'gift' vs. heavy lār 'learning'.
(iii) i-stem nom sg: light win-e 'friend' vs. heavy cwēn 'queen'
(iv) u-stem nom sg: light sun-u 'son' vs. heavy hand 'hand'.
(v) Neuter/feminine strong adjective declension: light sum 'a certain', fem nom sg, neut nom/acc sg sum-u vs. heavy gōd 'good', fem nom sg gōd.
(vi) Thematic weak verb preterites . . . .
これらのうち,現代英語にまで HVD の効果が持続・残存している例はごくわずかである.しかし,過去・過去分詞形 heard や複数形 sheep に何らかの不規則性を感じるとき,そこではかつての HVD の影響が間接的にものを言っているのである.
・ Lass, Roger. Old English: A Historical Linguistic Companion. Cambridge: CUP, 1994.
2014-12-12 Fri
■ #2055. 「母音」という呼称 [vowel][comparative_linguistics][family_tree][terminology][metrical_phonology][syllable]
「#1537. 「母語」にまつわる3つの問題」 ([2013-07-12-1]) や「#1926. 日本人≠日本語母語話者」 ([2014-08-05-1]) で「母語」という用語についてあれこれと考えた.一般に言語(学)のディスコースには,「母」がよく顔を出す.「母語」や「母方言」はもとより,比較言語学では諸言語の系統的な関係を「母言語」「娘言語」「姉妹言語」と表現することが多い.なぜ「父」や「息子」や「兄弟」ではないのかと考えると,派生関係を表わす系統図では生む・生まれる(産む・産まれる)の関係が重視されるからだろうと思われる.言語の派生においては,男女のペアから子が生まれるという前提はなく,いわば「単為生殖」(より近似した比喩としてはセイヨウタンポポなどに代表される「産雌単為生殖」)である.これに関連しては「#807. 言語系統図と生物系統図の類似点と相違点」 ([2011-07-13-1]),「#1578. 言語は何に喩えられてきたか」 ([2013-08-22-1]),「#1579. 「言語は植物である」の比喩」 ([2013-08-23-1]) も参照されたい.
「母語」や「母・娘言語」については上のようなことを考えており,言語のディスコースにおける「女系」性に気づいていたが,ある授業で学生がもう1つの興味深い例を指摘してくれた.標題に掲げた「母音」という用語である.盲点だったので,なるほどと感心した.確かに,なぜ「父音」ではなく「母音」なのだろうか.少し調べてみた.
英語で「母音」は vowel,対する「子音」は consonant である.これらの英語の用語の語源には,特に母とか子とかいう概念は含まれていない.前者はラテン語 vōcālem (有声の)に遡り,語根は vōx (声)である.後者は,ラテン語 consonans (調和する,一緒に響く)に遡り,これ自体はギリシア語 súmphōnon([母音と]ともに発音するもの)のなぞりである.つまり,特に親子の比喩は関与していない.他の西洋語も事情は似たり寄ったりである.
とすると,「母音」「子音」という呼称は,日本語独自のものらしいということになる.『日本国語大辞典』によると「ぼいん」には【母音】と【母韻】の項が別々にあり,それぞれ次のようにある.
【母音】*百学連環(1870--71頃)〈西周〉一「文字に consonants (子音)及び vowel (母音)の二種あり」*病牀譫語(1899)〈正岡子規〉五「父音母音の区別無き事等に因る者にして,其解し難きは,同音の字多き漢語を仮名に直したるに因るなり」*金毘羅(1909)〈森鴎外〉「苦しい間に,をりをり一言づつ云ふ詞が,濁音勝で母音を長く引くので」
【母韻】「ぼいん(母音)」に同じ.*小学日本文典(1874)〈田中義廉〉一・二「此五十音のうち,アイウエオの五字を,母韵と云ひ」*広日本文典(1897)〈大槻文彦〉三二「也行の発生は,甚だ阿行の『い』に似,和行の発生は,甚だ阿行の『う』に似て,更に,之に母韻を添へて,二母韻,相重なりて発するものの如し」*国語のため第二(1903)〈上田万年〉促音考「第一 P(H)TKRS 等の子音が Unaccented の母韻に従はれて,P(H)TKS を以てはじめらるるシラブルの前に立つ時は」
ここで【母音】の項の例文として触れられている「父音」という用語に着目したい.これは,今日いうところの子音の意味で使われている.では,同じ辞典で【父音】(ふいん)の項を引いてみる.
「しいん(子音)」に同じ.*広日本文典別記(1897)〈大槻文彦〉一七「英の Consonant を,子音,又は,父音(フイン)など訳するあるは,非なり」*国語音声学(1902)〈平野秀吉〉一四・一「父音は,其の音質の上から区別すれば,左の二類となる.有声父音 無声父音」
近代言語学が入ってきた明治初期には,consonant の訳語として「子音」とともに「父音」という言い方が行われていたようだ.「母」に対するものは「父」なのか「子」(=娘?)なのかという競合を経て,最終的には「子」で収まったということのようだ.ここでいう「子」の性別は分からないが,音声学のディスコースにおいて「父」権が失墜したようにも見えるから,「娘」である可能性が高い(?).
さらに,根本となる【母】(ぼ)とは何かを同辞典で調べてみると,
(2)親もと.帰るべきところ.そだった所./母岩,母艦,母港,母船,母校,母国,母語,母斑/(3)物を生じるもととなるもの./酵母,字母/母音,母型,母集団,母数,母船/
とある.その中で「母音」(なるほど「字母」という用語もあった!)は,「物を生じるもととなるもの」の意の「母」の用例として挙げられている.
ここで思い浮かぶのは,韻律音韻論における音節構造の記述だ.現在最も広く導入されている音節構造 (cf. 「#1563. 音節構造」 ([2013-08-07-1])) の記述では,onset, rhyme, nucleus, coda などの位置をもった階層構造が前提とされている.音節構造において核であり母体となるのは文字通り nucleus であり,典型的にはそこに母音が収まり,その周辺に「ともに響く音」としての子音が配される.母音は比喩的に「母体」や「母艦」などと表現したくなる位置に収まる音であり,一方で子音はその周辺に配される「子分」である(なお「子分」というとむしろ男性のイメージだ).明治初期と韻律音韻論というのは厳密にはアナクロだが,「母音」「子音」という言葉遣いの背景にある基本的な音韻のとらえ方とは関わってくるだろう.
上記のように,「母」とは,何かを派生的に生み出す源であり,生成文法の発想に近いこともあって,日本語の言語学のディスコースには女系用語の伝統がすでに根付いて久しいということかもしれない.
2014-09-12 Fri
■ #1964. プロトタイプ [prototype][phonology][phoneme][phonetics][syllable][prosody][terminology][semantic_change][family_resemblance][philosophy_of_language][onomasiology]
認知言語学では,プロトタイプ (prototype) の考え方が重視される.アリストテレス的なデジタルなカテゴリー観に疑問を呈した Wittgenstein (1889--1951) が,ファジーでアナログな家族的類似 (family resemblance) に基づいたカテゴリー観を示したのを1つの源流として,プロトタイプは認知言語学において重要なキーワードとして発展してきた.プロトタイプ理論によると,カテゴリーは素性 (feature) の有無の組み合わせによって表現されるものではなく,特性 (attribute) の程度の組み合わせによって表現されるものである.程度問題であるから,そのカテゴリーの中心に位置づけられるような最もふさわしい典型的な成員もあれば,周辺に位置づけられるあまり典型的でない成員もあると考える.例えば,「鳥」というカテゴリーにおいて,スズメやツバメは中心的(プロトタイプ的)な成員とみなせるが,ペンギンやダチョウは周辺的(非プロトタイプ的)な成員である.コウモリは科学的知識により哺乳動物と知られており,古典的なカテゴリー観によれば「鳥」ではないとされるが,プロトタイプ理論のカテゴリー観によれば,限りなく周辺的な「鳥」であるとみなすこともできる.このように,「○○らしさ」の程度が100%から0%までの連続体をなしており,どこからが○○であり,どこからが○○でないかの明確な線引きはできないとみる.
考えてみれば,人間は日常的に事物をプロトタイプの観点からみている.赤でもなく黄色でもない色を目にしてどちらかと悩むのは,プロトタイプ的な赤と黄色を知っており,いずれからも遠い周辺的な色だからだ.逆に,赤いモノを挙げなさいと言われれば,日本語母語話者であれば,典型的に郵便ポスト,リンゴ,トマト,血などの答えが返される.同様に,「#1962. 概念階層」 ([2014-09-10-1]) で話題にした FURNITURE, FRUIT, VEHICLE, WEAPON, VEGETABLE, TOOL, BIRD, SPORT, TOY, CLOTHING それぞれの典型的な成員を挙げなさいといわれると,多くの英語話者の答えがおよそ一致する.
英語の FURNITURE での実験例をみてみよう.E. Rosch は,約200人のアメリカ人学生に,60個の家具の名前を与え,それぞれがどのくらい「家具らしい」かを1から7までの7段階評価(1が最も家具らしい)で示させた.それを集計すると,家具の典型性の感覚が驚くほど共有されていることが明らかになった.Rosch ("Cognitive Representations of Semantic Categories." Journal of Experimental Psychology: General 104 (1975): 192--233. p. 229) の調査報告を要約した Taylor (46) の表を再現しよう.
| Member | Rank | Specific score |
|---|---|---|
| chair | 1.5 | 1.04 |
| sofa | 1.5 | 1.04 |
| couch | 3.5 | 1.10 |
| table | 3.5 | 1.10 |
| easy chair | 5 | 1.33 |
| dresser | 6.5 | 1.37 |
| rocking chair | 6.5 | 1.37 |
| coffee table | 8 | 1.38 |
| rocker | 9 | 1.42 |
| love seat | 10 | 1.44 |
| chest of drawers | 11 | 1.48 |
| desk | 12 | 1.54 |
| bed | 13 | 1.58 |
| bureau | 14 | 1.59 |
| davenport | 15.5 | 1.61 |
| end table | 15.5 | 1.61 |
| divan | 17 | 1.70 |
| night table | 18 | 1.83 |
| chest | 19 | 1.98 |
| cedar chest | 20 | 2.11 |
| vanity | 21 | 2.13 |
| bookcase | 22 | 2.15 |
| lounge | 23 | 2.17 |
| chaise longue | 24 | 2.26 |
| ottoman | 25 | 2.43 |
| footstool | 26 | 2.45 |
| cabinet | 27 | 2.49 |
| china closet | 28 | 2.59 |
| bench | 29 | 2.77 |
| buffet | 30 | 2.89 |
| lamp | 31 | 2.94 |
| stool | 32 | 3.13 |
| hassock | 33 | 3.43 |
| drawers | 34 | 3.63 |
| piano | 35 | 3.64 |
| cushion | 36 | 3.70 |
| magazine rack | 37 | 4.14 |
| hi-fi | 38 | 4.25 |
| cupboard | 39 | 4.27 |
| stereo | 40 | 4.32 |
| mirror | 41 | 4.39 |
| television | 42 | 4.41 |
| bar | 43 | 4.46 |
| shelf | 44 | 4.52 |
| rug | 45 | 5.00 |
| pillow | 46 | 5.03 |
| wastebasket | 47 | 5.34 |
| radio | 48 | 5.37 |
| sewing machine | 49 | 5.39 |
| stove | 50 | 5.40 |
| counter | 51 | 5.44 |
| clock | 52 | 5.48 |
| drapes | 53 | 5.67 |
| refrigerator | 54 | 5.70 |
| picture | 55 | 5.75 |
| closet | 56 | 5.95 |
| vase | 57 | 6.23 |
| ashtray | 58 | 6.35 |
| fan | 59 | 6.49 |
| telephone | 60 | 6.68 |
プロトタイプ理論は,言語変化の記述や説明にも効果を発揮する.例えば,ある種の語の意味変化は,かつて周辺的だった語義が今や中心的な語義として用いられるようになったものとして説明できる.この場合,語の意味のプロトタイプがAからBへ移ったと表現できるだろう.構文や音韻など他部門の変化についても同様にプロトタイプの観点から迫ることができる.
また,プロトタイプは「#1961. 基本レベル範疇」 ([2014-09-09-1]) と補完的な関係にあることも指摘しておこう.プロトタイプは,ある語が与えられたとき,対応する典型的な意味や指示対象を思い浮かべることのできる能力や作用に関係する.一方,基本レベル範疇は,ある意味や指示対象が与えられたとき,対応する典型的な語を思い浮かべることのできる能力や作用に関係する.前者は semasiological,後者は onomasiological な視点である.
・ Taylor, John R. Linguistic Categorization. 3rd ed. Oxford: OUP, 2003.
2014-07-26 Sat
■ #1916. 限定用法と叙述用法で異なる形態をもつ形容詞 [adjective][syllable][pronunciation][prosody][participle][euphony][numeral][personal_pronoun]
「#643. 独立した音節として発音される -ed 語尾をもつ過去分詞形容詞」 ([2011-01-30-1]), 「#712. 独立した音節として発音される -ed 語尾をもつ過去分詞形容詞 (2)」 ([2011-04-09-1]), 「#752. 他動詞と自動詞の特殊な過去分詞形容詞」 ([2011-05-19-1]) で関連する話題に触れたが,現代英語には過去分詞の用法に応じて2つの異なる形態を示す drunk / drunken, bent / bended, proved / proven, beloved / belovèd のようなペアがある.短い前者は叙述的に,1音節分長い後者は限定的に用いられる傾向がある.以前の記事では,リズムと関連づけて,この使い分けについて論じた.
上記のペアはいずれも動詞の過去分詞形容詞の例だが,動詞由来ではない形容詞にも,2つの異形態をもつ例が近代英語に見られた.両者がどの程度関連するかはわからないが,使い分けがあるという点で類似しているので紹介したい.two / twain, my / mine, thy / thine, old / olden の各ペアにおいて,後者の形態は語尾に /n/ を含む分だけ長いという形態上の特徴があるが,用法としても後者は前者に比べていくぶん癖がある.荒木・宇賀治 (462) を参照して,それぞれの特徴をまとめよう.
(1) two / twain
twain は古英語 tweġen の男性主格・対格の形態に由来し,two は対応する女性・中性の形態に由来する.twain は two とともに中英語を通じて広く用いられ,近代英語期に入ってからも,(i) 名詞の後置修飾語として,(ii) 代名詞の後置同格語として,(iii) 叙述用法として,用いられていた.twain は two に押され続けてはきたが,用法を狭めながらも近代英語まで生き延びたことになる.
・ I have receivyd twaine your lettres. (1554 Cdl. Pole in Eng. Hist. Rev.)
・ lovers twain (MND. V. i. 151)
・ O Perdita, what have we twain forgot! (Wint. IV. iv. 673)
・ I must become a borrower of the night For a dark hour or twain. (Mac. III. i. 26--27)
・ Thou and my bosom henceforth shall be twain. (Rom. III. v. 240)
twain が脚韻のために利用されやすかったことは言うまでもない.
(2) my / mine, thy / thine
それぞれ古英語の人称代名詞の属格形 mīn, þīn に遡る.所有を表わす限定用法において,各ペアの前者の形態 my, thy では子音の前位置で /n/ が脱落したもので,後者の形態 mine, thine では母音の前で /n/ が保持されたものである.この使い分けは,13世紀頃から18世紀初期まで続いた.一方,単独で用いられる叙述用法では,mine, thine の /n/ を有する形態だけが選ばれ,現在に至る.
(3) old / olden
olden は15世紀前半に初出したが,常に頻度の低い異形態だった.Shakespeare では1度のみ "Blood hath been shed ere now, i' the olden time," (Mac. III. iv. 75) として現われ,おそらくここから the olden time という表現が広まったものと思われる.Scott にも olden times という例が見られる.19世紀に例外的に叙述用法が生じたが,現代英語では原則としてもっぱら上記の限定句内で用いられる.
いずれのペアでも長い形態には /n/ が語末に加えられているが,実際に音節を増やす(したがってリズムに関与しうると考えられる)のは (3) のみである.(3) では2音節の olden が限定用法としての使用に限られており,これは ##643,712 で示したリズムによる説明に合致する.(1), (2) では,音節は追加しないものの /n/ を付した長い形態のほうが,むしろ限定用法を失ってきたのが,(3) に比して対照的である.
・ 荒木 一雄,宇賀治 正朋 『英語史IIIA』 英語学大系第10巻,大修館書店,1984年.
2013-08-07 Wed
■ #1563. 音節構造 [syllable][phonetics][phonology][metrical_phonology][terminology]
昨日の記事「#1562. 韻律音韻論からみる yod-dropping」 ([2013-08-06-1]) で,説明抜きで音節構造 (syllable structure) の分析を示したが,今日は Hogg and McCully (35--38) に拠って,音節構造の教科書的な概説を施したい.以下では,grind /graind/ という1音節語の音節構造を例に取る.
最も直感的な分析方法は,音節を構成する各分節音をフラットに並べる下図の (1) の方法である.ただし,音声学的にも音韻論的にも,母音と子音とを区別することは前提としておいてよいと思われるので,その標示は与えてある.
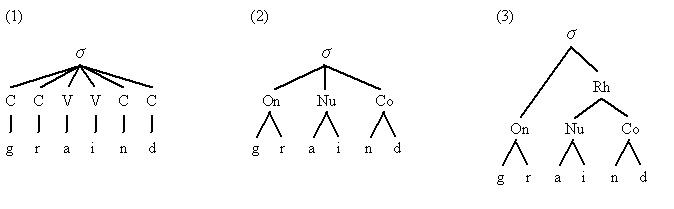
(1) を一見して明らかなように,子音は子音どうしの結合をなし,母音は母音どうしの結合をなすのが通常である.したがって,それぞれをグループ化して音節内での位置に応じてラベルをつけることは自然である.音節の始まりを担当する子音群を Onset,本体を占める母音群を Nucleus,終わりを担当する子音群を Coda と分けることが一般的に行なわれている.これが,(2) の分析である.
この段階でも有効な音節構造の分析はできるが,さらに階層化を進めると,理論上,便利である.(3) のように Nucleus と Coda をまとめる Rhyme を設定し,Onset に対応させるという分析が広く受け入れられている.
では,(3) のような一見すると複雑な階層化がなぜ理論的に有意味なのだろうか.1つは,Onset には独自の制限がかかっているということがある.英語では /graind/ という音連続は許されるが,例えば */pfraind/ は許されない.これは,Onset /pfr/ にかかっている子音連続の制限ゆえであり,Onset より右の部分の構造からは独立した理由によるものである.同様に,brim, bread, bran, brock, brunt と *bnim, *bnead, *bnan, *bnock, *bnunt を比較すれば,問題は Onset が /br/ か */bn/ かにかかっているのであり,その後の部分は全体の可否に影響していないことがわかるだろう.また,Rhyme という語そのものが示すとおり,脚韻の伝統により,この単位が直感的にもまとまりをなすものだという認識は強い.
さらに,Rhyme (あるいはそれより下のレベル)の分岐の仕方により,多くの音韻過程や強勢が記述できるという利点がある.分岐していれば重い音節 (heavy syllable) であると言われ,分岐していなければ軽い音節 (light syllable) であると言われる.Nucleus と Coda の構造に別々に言及せずとも,Rhyme 以下の構造として一括して言及できるので,Rhyme というレベルの設定は説明の経済性に資する.
以上の理由で,Onset に対して Rhyme を区別する合理性はあるといえる.しかし,Rhyme 以下を Nucleus と Coda へ区分せずに,音をフラットに横並びにする音韻論など,(3) の変種といえるものもあることに注意したい.いずれも合理的に音韻や韻律の分析を可能にするための仮説であり,道具立てである.
・ Hogg, Richard and C. B. McCully. Metrical Phonology: A Coursebook. Cambridge: CUP, 1987.
2013-08-06 Tue
■ #1562. 韻律音韻論からみる yod-dropping [phonetics][phonology][diphthong][vowel][syllable][metrical_phonology][variation][yod-dropping]
現代英語には /juː/ という上昇2重母音 (rising diphthong) がある.英語変種によっても異なるが,この2重母音にはいくつかの特徴がある.そのうちの共時的な変異と通時的な変化に関わる特徴として,「#841. yod-dropping」 ([2011-08-16-1]) がある.時に /juː/ から /j/ が脱落し,/uː/ として実現される音韻過程のことだ.
現在進行中の yod-dropping を記述・説明するのに,Hogg and McCully (42--45) で述べられている metrical phonology (韻律音韻論)による分析が利用できるかもしれないと思ったので,紹介しておきたい.子音 X + /juː/ からなる音節は,下図の左の基底構造をもっていると分析される.
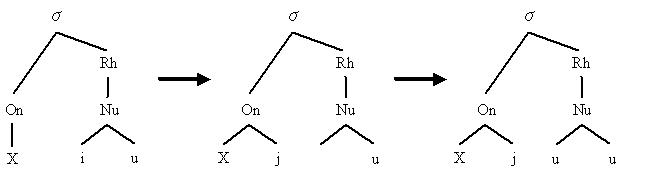
次に,この基底構造の Nucleus における /i/ が,/j/ として Onset へ移動すると想定する.引き続き,/i/ が移動したことによって空いた Nucleus の第1の位置に,後続の /u/ のコピーが作り出される.
このように分析する利点はいくつかある.まず,基底構造の Onset に /Xj/ を想定してしまうと,cue /kjuː/, few /fjuː/ などでは問題ないが,new /njuː/, lewd /ljuː/ などでは問題が生じる.なぜならば2モーラからなる Onset において第1モーラの聞こえ度は無声摩擦音と同等かそれ以下でないといけないという一般的な制限があるからである.この制限に従えば,/n/ や /l/ は聞こえ度が高すぎるために,Onset の第1モーラとなることはできないはずだ.しかし,実際には第1モーラになっているので,これは例外的に派生したものとして分析する必要があることになる.
また,この分析は /Xj/ の後には長母音しか生起し得ないことと符合する.というのは,Nucleus の第2モーラには /i/ か /u/ しか起こり得ず,それが前位置にコピーされることをこの分析は要求しているからである.
さらに,clue, drew, threw など,もともと Onset が2モーラ(2子音結合)からなる場合には,/j/ が左へ移動してゆくための空きスペースがないために,/j/ 自身が最終的に脱落してしまうと説明することができる.つまり,子音連続の直後の yod-dropping が必須であることをうまく説明する.
変異としての yod-dropping は,英語変種によっても異なるが,dew, enthuse, lewd, new, suit, tune などの語における /j/ の有無の揺れによって示される.共時的にも通時的にも,yod-dropping の起こりやすさは先行する子音 X が何であるかによってある程度は決まることが知られているが,これをいかに上の分析に組み込むことができるかが次の課題となるだろう.
・ Hogg, Richard and C. B. McCully. Metrical Phonology: A Coursebook. Cambridge: CUP, 1987.
2013-06-19 Wed
■ #1514. Sonority Analyser [phonetics][sonority][syllable][web_service][cgi]
昨日の記事「#1513. 聞こえ度」 ([2013-06-18-1]) で,音節を定義づけるに当たっての聞こえ度の役割を解説した.また,Sonority Sequencing Generalisation (SSG) という原則を導入し,分節音が聞こえ度の原則に従って配置されることを示した.聞こえ度の果たすこのような役割を理解し,確認するために,昨日の記事ではいくつかの単語による分析を示したが,任意の単語で分析できると便利である.
そこで,正書法にしたがって単語を入力すると,自動的にその発音を分節音へ分解し,各分節音へ sonority scale に即した聞こえ度の値を割り振り,山と谷を図示してくれるツールを作成した.以下に,"Sonority Analyser" を公開する.1つの語でもよいし,カンマ区切りで複数の語を見出し語の形で入力してもよいが,聞こえ度の山と谷の図が適切に出力される仕様である.
発音データベースには「#1159. MRC Psycholinguistic Database Search」 ([2012-06-29-1]) を用いており,たまたまそこに登録されていない語(綴字)は当然ながら出力は得られない.1つの正書法に対して複数のエントリーがある場合(同綴異義語や品詞違いなど)には,それぞれが図示される.音声表記については,MRC の原データファイルの仕様に基づいたものをそのまま使用した.
sonority scale には,原則として昨日の記事で示したものを利用しているが,(1) /w, j/ を聞こえ度8として挿入し,もともとの高母音,中母音,低母音の値は繰り上げて,それぞれ9, 10, 11とし,(2) 2重母音は下降2重母音 (falling diphthong) を前提とし,第1母音の聞こえ度の値を2重母音全体に割り当てることとした.厳密ではなくとも,プレゼンや確認の用途には十分だろう.
[ 固定リンク | 印刷用ページ ]
2013-06-18 Tue
■ #1513. 聞こえ度 [phonetics][phoneme][sonority][syllable][terminology][phonotactics]
音節 (syllable) には様々な定義が与えられうるが,広く受け入れられているものとして,分節音の音声的な聞こえ度 (sonority) に依存する定義がある.聞こえ度そのものは,"the overall loudness of a sound relative to others of the same pitch, stress and duration" (Crystal 442) のように定義される.各分節音が本来的にもつ聞こえやすさの程度と解釈できる.
分節音の聞こえ度の測定は様々になされており,その値については実験ごとに詳細は異なるかもしれないが,おおまかな分類や順位については研究者のあいだで一致をみている.その1例として,Hogg and McCully (33) に挙げられている英語の分節音の sonority scale を示そう.
| Sounds | Sonority values | Examples |
|---|---|---|
| low vowels | 10 | /a, ɑ/ |
| mid vowels | 9 | /e, o/ |
| high vowels | 8 | /i, u/ |
| flaps | 7 | /r/ |
| laterals | 6 | /l/ |
| nasals | 5 | /n, m, ŋ/ |
| voiced fricatives | 4 | /v, ð, z/ |
| voiceless fricatives | 3 | /f, θ, s/ |
| voiced stops | 2 | /b, d, g/ |
| voiceless stops | 1 | /p, t, k/ |
一般に,子音よりも母音のほうが,無声よりも有声のほうが,口の開きが小さいよりも大きいほうが聞こえ度は高い.子音についていえば,子音の強度と聞こえ度は反比例の関係であり,強度の低い(=弱い=聞こえ度の高い)子音は,音声的な摩耗や消失を被りやすい.
さて,聞こえ度が音節を定義するのに有効なのは,分節音の連続において聞こえ度が頂点 (peak) に達するところが音節の核 (syllabic nucleus) と一致するからである.語を分節音の連続に分け,各分節音に聞こえ度を割り振ると,1つ以上の聞こえ度の頂点が得られる.この頂点の数が,その語の音節数ということになる.ある音節と隣あう音節との境目がどこに落ちるかは理論的な問題を含んでいるが,少なくとも音節の核(頂点)は,このように聞こえ度を分析することで機械的に定まるので都合が良い.
以下に,いくつかの語の聞こえ度分析を示そう.
| Word | Pronunciation | Sonority values | Peaks = Syllables |
|---|---|---|---|
| modest | /modest/ | 5-9-2-9-3-1 | 2 |
| complain | /compleːn/ | 1-9-5-1-6-9-5 | 2 |
| petty | /peti/ | 1-9-1-8 | 2 |
| elastic | /əlæstik/ | 8-6-10-3-1-8-1 | 3 |
| elasticity | /iːlæstisiti/ | 9-6-10-3-1-8-3-8-1-8 | 5 |
| petrol | /petrəl/ | 1-9-1-7-9-6 | 2 |
| button | /bʌtn/ | 2-9-1-5 | 2 |
| bottle | /botl/ | 2-9-1-6 | 2 |
最後の button や bottle では最終音が子音だが,聞こえ度として頂点をなすので,音節の核として機能している.いわゆる音節主音的子音である.
さらに興味深いのは,音節を構成する一連の分節音が聞こえ度に関するある法則を示すことである.これは "Sonority Sequencing Generalisation" (SSG) と呼ばれる原則で,次のように定式化される.
[I]n any syllable, there is a segment constituting a sonority peak that is preceded and/or followed by a sequence of segments with progressively decreasing sonority values. (Crystal 442)
音節によって山の頂点の高さはまちまちだが,典型的に「谷山谷」のきれいな分布になるということを,SSG は示している.onset が s で始まる子音群 (ex. sp-, st-, sk-) の場合などではこの原則は規則的に破られることが知られているが,これを除けば SSG は英語において非常に安定した原則である.
・ Crystal, David, ed. A Dictionary of Linguistics and Phonetics. 6th ed. Malden, MA: Blackwell, 2008. 295--96.
・ Hogg, Richard and C. B. McCully. Metrical Phonology: A Coursebook. Cambridge: CUP, 1987.
2013-04-06 Sat
■ #1440. 音節頻度ランキング [syllable][corpus][lexicon][phonetics][frequency][statistics]
「#1424. CELEX2」 ([2013-03-21-1]) で紹介した巨大データベースで何かしてみようと考え,Version 2 で新たに加えられた音節頻度 (English Frequency, Syllables) のサブデータベースにより,現代英語で最も多い音節タイプのランキングを得た.
これは,CELEX2 のもとになっているコーパス全体のうち,7.26%を構成する約130万語の話し言葉サブコーパスから引き出された音節頻度であり,タイプ頻度ではなくトークン頻度によるものである.つまり,話し言葉におけるある単語の頻度が高ければ,その分,その単語に含まれる音節タイプの頻度も高くなるということである.例えば,of を構成する "Ov" (= /ɒv/) と表現される音節は,第4位の頻度である.なお,強勢の有無は考慮せずに頻度を数えている.
以下のリストに挙げる音素表記は,IPA ではなく CELEX 仕様の独特の表記なので,先に対応表を挙げておこう.
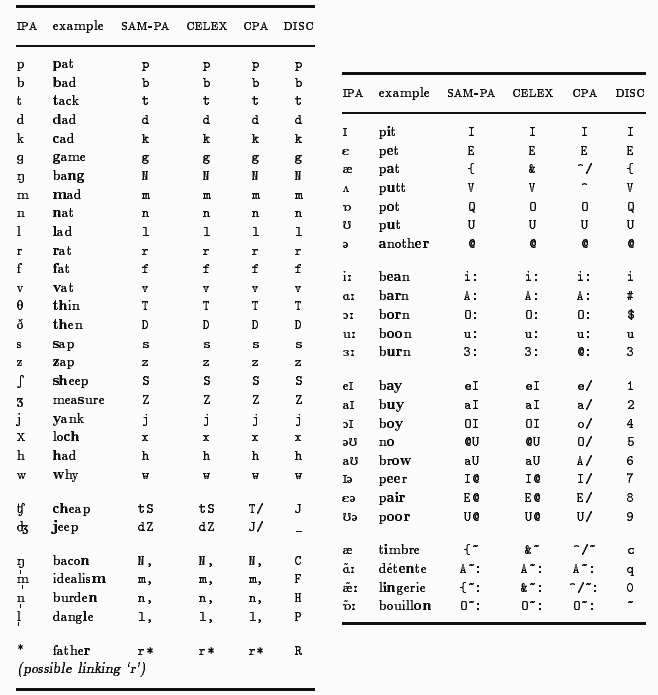
では,以下にランキング表でトップ50位までを掲載する.高頻度の単音節語の音節タイプがそのまま上位に反映されていて,あまりおもしろい表ではないが,何かの役に立つときもあるかもしれない.
| Rank | Syllable | Frequency |
|---|---|---|
| 1 | eI | 72971 |
| 2 | Di: | 60967 |
| 3 | tu: | 31446 |
| 4 | Ov | 30108 |
| 5 | In | 29906 |
| 6 | &nd | 28709 |
| 7 | aI | 23822 |
| 8 | lI | 19728 |
| 9 | @ | 19566 |
| 10 | rI | 14356 |
| 11 | ju: | 12598 |
| 12 | dI | 12465 |
| 13 | D&t | 12118 |
| 14 | It | 11504 |
| 15 | wOz | 10834 |
| 16 | fO:r* | 9778 |
| 17 | Iz | 9517 |
| 18 | tI | 9161 |
| 19 | fO | 9042 |
| 20 | Sn, | 8969 |
| 21 | hi: | 8928 |
| 22 | r@n | 8638 |
| 23 | bi: | 8505 |
| 24 | bI | 7936 |
| 25 | nI | 7068 |
| 26 | wID | 7046 |
| 27 | On | 7030 |
| 28 | &z | 6919 |
| 29 | O:l | 6569 |
| 30 | h&d | 6240 |
| 31 | E | 6165 |
| 32 | bl, | 6021 |
| 33 | sI | 5836 |
| 34 | @U | 5824 |
| 35 | t@r* | 5687 |
| 36 | &t | 5652 |
| 37 | hIz | 5564 |
| 38 | bVt | 5416 |
| 39 | mI | 5397 |
| 40 | s@ | 5391 |
| 41 | nOt | 5357 |
| 42 | D@r* | 5339 |
| 43 | I | 5283 |
| 44 | tId | 5259 |
| 45 | DeI | 5162 |
| 46 | IN | 5063 |
| 47 | t@ | 5053 |
| 48 | s@U | 4974 |
| 49 | baI | 4894 |
| 50 | h&v | 4769 |
全ランキング表を見たい方は,タブ区切り形式で Syllable Frequency Rank Table by CELEX2 を参照.ブラウザ上で閲覧したい方は,こちらからどうぞ.全体としては11492の異なる音節タイプが登録されており,頻度が1以上のものは7934タイプある.「#1023. 日本語の拍の種類と数」 ([2012-02-14-1]) の最後で,英語の音節タイプが日本語に比べて驚くほど多種多様であることに触れたが,この数をみれば納得できるだろう.関連して,syllable の各記事を参照.
なお,CELEX2 のマニュアルには以下の但し書きが記されていたので,再掲しておく.
Please note that the English corpus used by CELEX for deriving these frequencies contains only 7.3% spoken material. This means there is a rather tenuous relationship between the full frequency figures, which are based on written forms, and the syllable frequencies, which merely refer to phonemic conversions of these graphemic transcriptions. Of course it could be argued that frequencies of syllables, as lexical sub-units, are less liable to get skewed from differences in medium than full words, but it has to be taken into account that NO FIRM EVIDENCE ABOUT SPOKEN FREQUENCIES can be derived from these data.
2012-11-12 Mon
■ #1295. フランス語とラテン語の2重語 [doublet][french][latin][etymology][loan_word][syllable]
「#944. ration と reason」 ([2011-11-27-1]) で,フランス語とラテン語から借用された2重語 (doublet) の例をいくつか見た.reason -- ration, treason -- tradition, poison -- potion, lesson -- lection といったペアである.Schmitt and Marsden (87) に他の例が挙がっていたので,下に示したい.左列は中英語期に先に入っていたものでフランス語,右列は初期近代英語期に改めて借用されたラテン語である.
| French (in ME) | Latin (in EModE) |
|---|---|
| armor | armature |
| chamber | camera |
| choir | chorus |
| frail | fragile |
| gender | genus |
| jealous | zealous |
| prove | probe |
| strait | strict |
| strange | extraneous |
| treasure | thesaurus |
フランス語形をラテン語形と比べてみると,いかに子音が消失あるいは変化したり,音節が失われているかがわかる.概してラテン語形は音節数が多い.英語はこれらの異なる語形を豊富に取り入れることによって,語彙そのものを増やしてきたことはもちろん,語彙の音節数別の分布をも変化させてきたのだろう.英語語彙と音節数については,syllable statistics の各記事を参照.
・ Schmitt, Norbert, and Richard Marsden. Why Is English Like That? Ann Arbor, Mich.: U of Michigan P, 2006.
2012-07-01 Sun
■ #1161. 英語と日本語における語彙の音節数別割合 [lexicology][statistics][syllable][corpus][japanese]
昨日の記事「#1160. MRC Psychological Database より各種統計を視覚化」 ([2012-06-30-1]) の (3) で,英語語彙を音節数により分別して,それぞれの頻度を出した.それによると,対象となった92767語の語彙全体における1音節語,2音節語,3音節語,4音節語の占める割合は,それぞれ13.46%,35.40%,29.91%,15.26%であり,合わせて94.03%に達する.とりわけ2音節語と3音節語を合わせて65.31%である.9万余という大規模な語彙で調査する限り,英語語彙の3分の2近くは2--3音節語であるということになる.
一方,##348,349,355 の記事では,BNC や COLT のコーパスを用いて,最も頻度の高い数百語から数千語を対象に音節数調査を行なった.調査対象となる語彙の規模は格段に小さく,それに従って音節数別の割合も変わる.1音節語と2音節語が優勢であり,最大の6000語規模の調査でもこの2種類だけで68.7%を占める(「#349. BNC Word Frequency List による音節数の分布調査 (2)」 ([2010-04-11-1]) のグラフを参照).対象とする語彙規模により,優勢な占有率を示す音節数が変動することがわかるが,全般的に,英語語彙においては1--3音節語が主要であることは間違いないだろう.
では,日本語の語彙について,音節数別の割合はどうだろうか.加藤ほか (80) では,林大氏による『日本語アクセント辞典』の見出し語形に基づく拍数の分布の調査結果が要約されている.辞典の見出し語形であるから対称語彙は数万語の規模と思われる.以下のような結果が出た.
| 1拍 | 2拍 | 3拍 | 4拍 | 5拍 | 6拍 | 7拍 | 8拍 | 9拍 | 10拍 | 計 |
| 0.3 | 4.8 | 22.7 | 38.8 | 17.7 | 11.0 | 3.3 | 1.2 | 0.2 | 0.1 | 100 |
割合のピークは4拍語にあり,その前後の3拍語と5拍語を合わせて79.2%,6拍語を加えれば90.2%になる.英語の語彙の主たる構成要素が1--3音節語とすれば,日本語の語彙の主たる構成要素は3--5拍語となる.音節数でみる限り,英単語は相対的に短く,日本語単語は相対的に長いことがよくわかる.
両言語間の際だった差異は,音韻数の差と音節構造の差に起因するといってよいだろう.音韻数については,[2012-02-12-1]の記事「#1021. 英語と日本語の音素の種類と数」で見たとおり,著しい差がある.また,音節構造については,日本語の音節がほぼ「子音+母音」の1形式だけであるのに対して,英語の音節は,[2012-02-14-1]の記事「#1023. 日本語の拍の種類と数」で示唆したとおり,数万形式がある.
日本語の語彙は,2拍語を基本としていると考えられる.和語でも漢語でも2±1拍語が多く,語彙の膨張に従って,その結合が増え,結果として4±1拍語が主流となってきた経緯がある.洋語についても,優勢な4拍語に合わせて「マスコミュニケーション」→「マスコミ」,「ハンガーストライキ」→「ハンスト」,「エンジンストップ」→「エンスト」と省略されることが多い.2拍語を基本とした日本語語彙の成立と,その後の発展については,小松 (48--62) が詳しい.
・ 加藤 彰彦,佐治 圭三,森田 良行 編 『日本語概説』 おうふう,1989年.
・ 小松 秀雄 『日本語の歴史 青信号はなぜアオなのか』 笠間書院,2001年.
[ 固定リンク | 印刷用ページ ]
2012-06-30 Sat
■ #1160. MRC Psychological Database より各種統計を視覚化 [lexicology][statistics][syllable][corpus]
[2012-06-28-1], [2012-06-29-1]と連日紹介してきた MRC Psycholinguistic Database に基づいて,4つの英語語彙統計を図示したい.原データファイルの仕様に示されている統計表をもとにグラフを作成しただけだが,別のコーパスに基づいて類似した調査を行なってきたものもあるので,比較に値するだろう.数値データは,HTMLソースを参照.
(1) 文字数による頻度
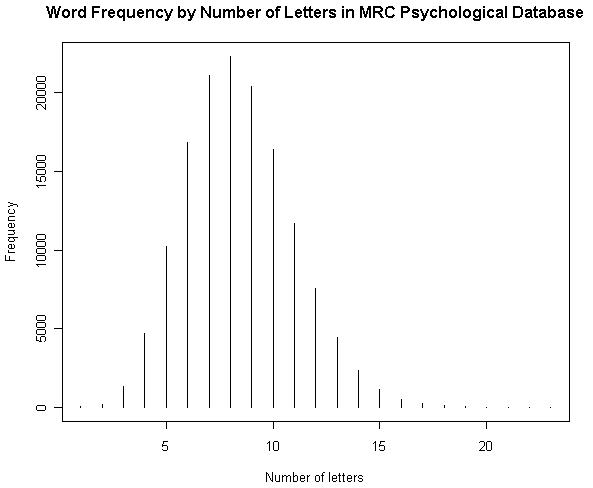
(2) 音素数による頻度
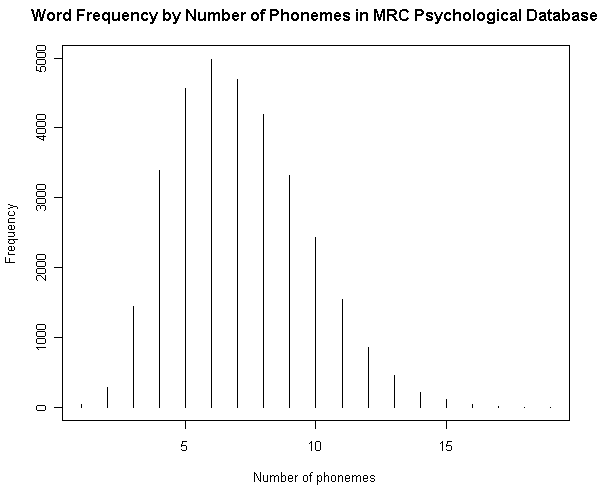
(参考)
・ [2012-02-13-1]: 「#1022. 英語の各音素の生起頻度」
(3) 音節数による頻度
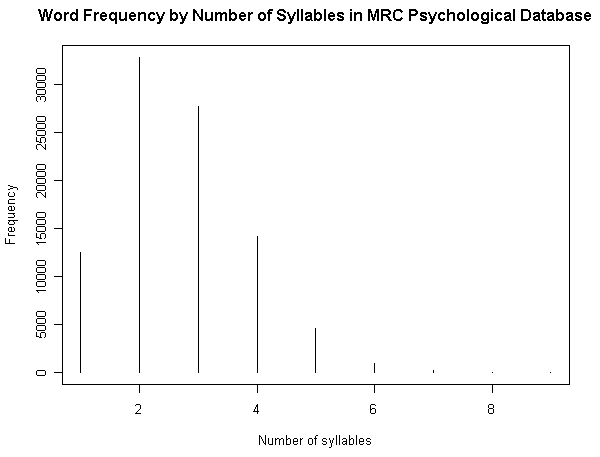
(参考)
・ [2010-04-09-1]: 「#347. 英単語の平均音節数はどのくらいか?」
・ [2010-04-10-1]: 「#348. BNC Word Frequency List による音節数の分布調査」
・ [2010-04-11-1]: 「#349. BNC Word Frequency List による音節数の分布調査 (2)」
・ [2010-04-17-1]: 「#355. COLT Word Frequency List による音節数の分布調査」
(4) 品詞による頻度
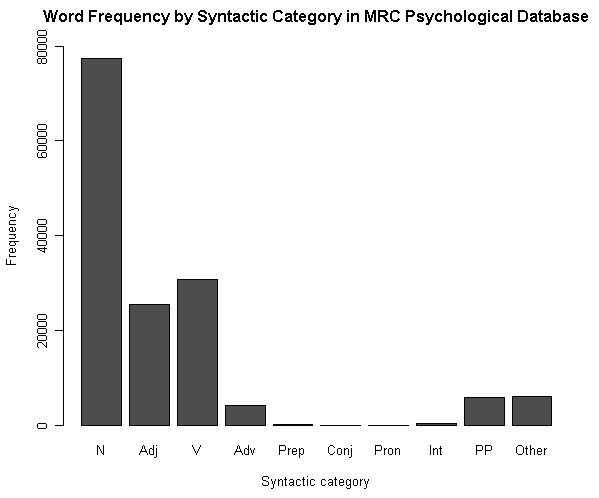
(参考)
・ [2012-06-02-1]: 「#1132. 英単語の品詞別の割合」
・ [2011-02-23-1]: 「#667. COCA 最頻50万語で品詞別の割合は?」
・ [2011-02-22-1]: 「#666. COCA 最頻5000語で品詞別の割合は?」
・ [2011-02-16-1]: 「#660. 中英語のフランス借用語の形容詞比率」
その他,語彙の頻度や,語種別の割合については以下の記事も参照.
・ [2010-03-01-1]: 「#308. 現代英語の最頻英単語リスト」
・ [2011-08-20-1]: 「#845. 現代英語の語彙の起源と割合」
・ [2012-01-07-1]: 「#985. 中英語の語彙の起源と割合」
2012-06-09 Sat
■ #1139. 2項イディオムの順序を決める音声的な条件 (2) [phonetics][syllable][binomial][idiom][prosody][alliteration][phonaesthesia]
昨日の記事[2012-06-08-1]に続いて,binomial (2項イディオム)の構成要素の順序と音声的条件の話題.昨日は「1音節語 and 第1音節に強勢のある2音節語」という構成の binomial が多く存在することを見た.この著しい傾向の背景には,強弱強弱のリズムに適合するということもあるが,Bolinger の指摘するように,「短い語 and 長い語」という一般的な順序にも符合するという要因がある.もっとも典型的な長短の差異は2要素の音節数の違いということだが,音節数が同じ(単音節の)場合には,長短の差異は音価の持続性や聞こえ度の違いとしてとらえることができる.Bolinger の表現でいえば,"openness and sonorousness" (40) の違いである.
分節音を "open and sonorous" 度の高いほうから低いほうへと分類すると,(1) 母音,(2) 有声持続音,(3) 有声閉鎖音・破擦音,(4) 無声持続音,(5) 無声閉鎖音・破擦音,となる.この観点から「短い語 and 長い語」を言い換えれば,「openness and sonorousness の低い語 and 高い語」ということになろう.Bolinger (40--44) は,現実には存在しない語により binomial 形容詞をでっちあげ,構成要素の順序を替えて,英語母語話者の被験者にどちらが自然かを選ばせた."He lives in a plap and plam house." vs "He lives in a plam and plap house." のごとくである.結果は,統計的に必ずしも著しいものではなかったが,ある程度の傾向は見られたという.
でっちあげた binomial による実験以上に興味深く感じたのは,p. 40 の注記に挙げられていた一連の頭韻表現である(関連して,[2011-11-26-1]の記事「#943. 頭韻の歴史と役割」を参照).flimflam, tick-tock, rick-rack, shilly-shally, mishmash, fiddle-faddle, riffraff, seesaw, knickknack. ここでは,2要素の並びは,それぞれの母音の聞こえ度が「低いもの+高いもの」の順序になっている.この順序については,phonaesthesia の観点から,心理的に「近いもの+遠いもの」とも説明できるかもしれない (see ##207,242,243) .
音節数,リズム,聞こえ度,頭韻,phonaesthesia 等々,binomial という小宇宙には英語の音の不思議がたくさん詰まっているようだ.
・ Bolinger, D. L. "Binomials and Pitch Accent." Lingua (11): 34--44.
2012-02-14 Tue
■ #1023. 日本語の拍の種類と数 [syllable][japanese][mora]
[2012-02-12-1]の記事「#1021. 英語と日本語の音素の種類と数」では,音素という単位で両言語の一覧を掲げたが,音節という単位ではどうだろうか.今回は,日本語の拍の一覧表を示したい.以下,出典は金田一 (90) .
| a | i | u | e | o | ja | ju | jo | (je) | wa | (wi) | (we) | wo |
| ha | hi | hu | he | ho | hja | hju | hjo | (hje) | (hwa) | (hwi) | (hwe) | (hwo) |
| ga | gi | gu | ge | go | gja | gju | gjo | (gwa) | ||||
| ka | ki | ku | ke | ko | kja | kju | kjo | (kwa) | ||||
| ŋa | ŋi | ŋu | ŋe | ŋo | ŋja | ŋju | ŋjo | |||||
| da | (di) | (du) | de | do | (dju) | |||||||
| ta | (ti) | (tu) | te | to | (tju) | |||||||
| na | ni | nu | ne | no | nja | nju | njo | |||||
| ba | bi | bu | be | bo | bja | bju | bjo | |||||
| pa | pi | pu | pe | po | pja | pju | pjo | |||||
| ma | mi | mu | me | mo | mja | mju | mjo | |||||
| za | zi | zu | ze | zo | zja | zju | zjo | (zje) | ||||
| sa | si | su | se | so | sja | sju | sjo | (sje) | ||||
| (ca) | ci | cu | (ce) | (co) | cja | cju | cjo | (cje) | ||||
| ra | ri | ru | re | ro | rja | rju | rjo | |||||
| N | T | R |
括弧を付したものは,主として外来語や感動詞に現われるもの.注意すべきものとして,(wha) = ファ,ci = チ,cu = ツ,(ca) = ツァ,cja = チャ.
日本語の音声の単位として,音素より大きな塊を示す用語として,音節 (syllable) ,拍,モーラ (mora) などがあるが,この用語の使い方は研究者によってまちまちである.ここでは,拍と呼んでおくことにする.これによると,日本語は,近年の外来語に現われる音節を別とすると,112の拍をもつことになる.鼻濁音を音素としてもたない話者は,ここから8拍を差し引く必要がある.o と wo については,「お」と「を」は共通語ではともに /o/ として区別されないが,「青うございます」と「淡うございます」などでは対立が生じるので,別の拍として認定する.
金田一 (104) によれば,ハワイ語は,子音が8個,母音5個で,理論上45音節が区別される.中国語は北京標準語で411音節.そして,英語だが,可能な音節数が著しく多いことが知られている ([2012-02-02-1]の記事「#1011. なぜ言語には「閉鎖子音+母音」の組み合わせが多いか?」を参照).日本語学者で英語学者の楳垣実によれば,英語の音節は3万個以下ということはなく,トルンカという学者によれば,86,165個があり得るというから驚きだ.このトルンカの言及には,いずれ当たってみたい.
・ 金田一 春彦 『日本語 新版(上)』 岩波書店,1988年.
2011-06-24 Fri
■ #788. half an hour [syllable][pronunciation][prosody]
「30分」は half an hour と表現されるが,特に米語や形容詞で修飾される環境では a (good) half hour とも用いられる.しかし,冠詞の前に数量形容詞が置かれる例は,他にも all the boys, both the books, many a time などがあり共通の統語的特徴を示している.この統語的特徴の背後には,韻律的な要因が働いているように思われる.上記の例のいずれも,この語順を取ることで強弱格 ( trochee ) となり,英語の一般的なリズムによく適合する.このように語順を整序したり,意味統語的に必要のない冠詞などの無強勢の音節を挿入することによって韻律を整えるという例は,英語では少なくない.
Bolinger (151--53) は韻律の都合によって説明されうる代替構文をペア(ただし一部非文も含む)で掲げている.右側がより韻律的な代替表現である.
an aloof person vs. an aloof kind of person It's a compact book. vs. It's a compact little book. a half hour vs. half an hour without doubt vs. without a doubt mother mine vs. pal o' mine Outside these I have no preference. vs. Outside of these I have no preference. Beware the Ides of March vs. Beware of Brutus a little bread vs. a bit of bread a dozen eggs vs. a gross of eggs a morsel bread vs. a piece of bread I dare not tell her. vs. We dare to judge. He dared adventure himself. vs. The players dared to satirise. the lessons these things have taught us vs. the lessons these things have taught to all of us He's gone fishing. vs. He's gone a-fishing. Why did you have to go tell her? vs. Why did you have to go and tell her? Who was it that told you? vs. Who was it told you? a quite long report vs. quite a long report *very a long report vs. a very long report *a so pretty girl vs. so pretty a girl so pretty a girl vs. such a pretty girl *a that pretty girl vs. that pretty a girl *a too remote place vs. too remote a place *an enough good reason vs. a good enough reason a good enough reason vs. a reason good enough
[2011-04-09-1]の記事「独立した音節として発音される -ed 語尾をもつ過去分詞形容詞 (2)」や[2011-06-12-1]の記事「過去分詞形容詞 -ed の非音節化」などでも触れたように,韻律は多くの場合,積極的に語順の変更を促す要因というよりは,別の要因によって引き起こされている一般的な変化の方向に多少なりとも抗い,ともすれば消えていく可能性のある代替的な語順を保持させる要因として作用していると考えられる.韻律による説明は,例外が多く「規則」と呼ぶには弱すぎるが,おそらく英語に限らず言語に普遍的に作用していると考えられるほどに応用範囲が広く「傾向」以上の説明力は有しているのではないか.
a Jàpanese stúdent などにおける強勢の back shifting や,Amelia's love makes the burning sand grow green beneath him and the stunted shrubs to blossom. における最後の不定詞標示 to の挿入など,韻律の関わると目される事例は数多い.
・ Bolinger, Dwight L. "Pitch Accent and Sentence Rhythm." Forms of English: Accent, Morpheme, Order. Ed. Isamu Abe and Tetsuya Kanekiyo. Tokyo: Hakuou, 1965. 139--80.
2011-04-09 Sat
■ #712. 独立した音節として発音される -ed 語尾をもつ過去分詞形容詞 (2) [adjective][syllable][pronunciation][prosody][eurhythmy]
aged, beloved, crooked, dogged, jagged, learned, naked, ragged, wicked, wretched などの過去分詞形容詞が2音節として発音される件について,[2011-01-30-1]の記事に補足する.先日の記事では,なぜこのような一部の語群でのみ,第2音節の母音が保持されたかについて疑問を呈した.いずれも高頻度語とはいえず ( Frequency Sorter で確認済み),頻度は関係なさそうだ.ただし,限定用法と叙述用法の差が関与している可能性があることは,記事の最後で示唆した.
形容詞としての用法の違いが音節の問題にどのように関与しうるかを理解するには,韻律 ( prosody ) ,リズムの都合 ( eurythmy ) という観点を導入する必要がある.限定用法として用いられる形容詞は,通常,直後に名詞がくる.直前にはアクセントの弱い冠詞や指示詞のあることが多い.典型的な例として a lovely girl を考えると,アクセントが弱強弱強と続く弱強格 ( iamb ) で現われる.これは,英語で最も典型的で耳に心地よい韻律の1つである.この位置にくる限定形容詞が第1音節にアクセントをもつ2音節であるほうが,英語の韻律上,都合がよいことがわかるだろう.aged, naked, wicked など問題の語群は,まさにこのような「都合のよい」音節構造をなしている.しかも,多くが主として限定用法に用いられる.my aged aunt, their beloved Ireland, a crooked nose, the jagged edges, a learned journal, a naked body, a ragged jacket, a wicked witch, the wretched animal など.英語の過去分詞語尾ではないが,-id 語尾をもつラテン借用語 solid, squalid, timid, vivid における第2音節も,おそらく同じ理由で保持されたと考えられる (Minkova 327--28) .
過去分詞形容詞の語尾に -ed だけでなく -en も含めると,叙述用法 ( predicative use ) と限定用法 ( attributive use ) のそれぞれで用いられる形態の差はより鮮明になる.Minkova (327) に挙げられている例を以下に示そう.
| PREDICATIVE | ATTRIBUTIVE |
|---|---|
| The case is proved. | a proven case |
| The sailor is drunk. | a drunken sailor |
| His knee is bent. | one bended knee |
| The main had burst. | a bursted main |
過去分詞形容詞の -ed や -en の母音は,英語の自然な音声変化の流れに乗っていれば語中音消失 ( syncopation ) を経ていたはずだが,上述のような韻律の都合で,消失傾向にブレーキがかかったものと考えられる.もちろんこの説明は強い説明となり得ない.典型的な弱強格から外れる a dogged determination などは珍しくないからだ.しかし,2つの交替形(母音を発音する2音節語と母音を発音しない1音節語)が競合している場合に,eurhythmy がいずれかの生き残りの確率を高める要因として作用するということは十分にありそうである.この作用を,Minkova (327) は Bolinger に言及しつつ "the operation of a rhythmic principle 'causing one of two alternative constructions to be preferred over the other, contributing to the preservation of a form that might otherwise have been lost. . .'" と記している.
2つの交替形の競合が持久戦になればなるほど,韻律の都合という僅かな要因でも,後々大きく効いてくるのではないだろうか.実際,英語史における曖昧母音の語中音省略は,中英語期から近代英語期にかけてまさにだらだらと締まりなく続いていたのである.
・ Minkova, Donka. "Adjectival Inflexion Relics and Speech Rhythm in Late Middle and Early Modern English." Papers from the 5th International Conference on English Historical Linguistics, Cambridge, 6--9 April 1987. Ed. Sylvia Adamson, Vivien Law, Nigel Vincent, and Susan Wright. Amsterdam: John Benjamins, 1990. 313--36.
2011-01-30 Sun
■ #643. 独立した音節として発音される -ed 語尾をもつ過去分詞形容詞 [adjective][syllable][pronunciation]
Quirk et al. (7.19) によると,通常,以下の過去分詞形容詞は語尾の -ed を /ɪd/ と発音し,音節を追加する.
aged, beloved, crooked, dogged, jagged, learned, naked, ragged, wicked, wretched
ただし,aged /ˈeɪdʒɪd/ は my aged father のように限定的に人の年齢を表わすときや the aged 「老人たち」の場合に使われ,人の形容でなく aged wine などと用いれば /ˈeɪdʒd/ の発音になる.beloved は,my beloved son の場合には /bɪˈlʌvɪd/ だが,She was beloved by everyone. のように動詞としての性格が強ければ /bɪˈlʌvd/ となる.また,a learned professor 「博学な教授」や a learned journal 「学術雑誌」では /ˈlɚːnɪd/ だが,a learned skill 「経験によって身につけた技術」では /lɚːnd/ である.使い分けはなかなか難しい.
本来は,規則的な過去分詞形(及び過去形)の語尾 -ed は,綴字に示されている通り,母音を伴って独立音節として発音されていた.中尾 (320--21) によれば,中英語では弱まった母音で /əd/ と発音されていたが,この母音は北部方言では13世紀から,それ以外の方言でも14世紀から消失していった.この語中音削除 ( syncopation ) は,-ed のみならず -es, -eth, -est, -en, -er などの語末形態素でも広く生じた音声変化である.ただし,消失自体はゆっくりとした過程であり,15世紀には大規模に進行したが,17世紀頃まで母音を保つ例もあった.
母音が現在まで保たれたものとしては,歯擦音 ( sibilant ) や歯破裂音で終わる語幹に接続する場合 ( ex. kisses, houses, edges, hated, ended ) が規則的な例外といえる.他には,過去分詞形容詞に副詞語尾 -ly の接続した assumedly, assuredly, supposedly などがある.これは,3子音の連続を避けるための音便として説明できるだろう.
上記のリストに掲げた一部の過去分詞形容詞で母音が保持された理由はよく分からない.とりわけ頻度が高い語群でもないので,頻度は関係なさそうだ.ただし,いずれも限定用法の形容詞として使われるという共通点があり,beloved の限定・叙述用法の発音の違いからも示唆されるとおり,用法が関与しているということは言えそうである.これについては,The driver is drunk と the drunken driver の比較などが参考になるかもしれない.
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
・ 中尾 俊夫 『音韻史』 英語学大系第11巻,大修館書店,1985年.
Powered by WinChalow1.0rc4 based on chalow