2013-08-17 Sat
■ #1573. amidst の -st 語尾 [preposition][genitive][phonetics][analogy][-st]
「#1554. against の -st 語尾」 ([2013-07-29-1]) や「#1555. unbeknownst」 ([2013-07-30-1]) などの記事に引き続き,-st 添加の話題.
amidst は,古英語 on middan に由来する中英語 amid に副詞的属格語尾 -es を付加して amiddes を作り,そこにさらに -t を付加した語形成である.amid の初例は ?a1200 の Layamon であり,amiddes は14世紀前半に初出している.中英語からの例は,MED の amid(de, amiddes (adv. & prep.) を参照.
-t を添加した amidst 系列については,OED の例文つき初出は "1565 T. Stapleton tr. Bede Hist. Church Eng. 66 Warme with a softe fyre burning amidest therof." であるが,amidest の綴字は15世紀から現われているようだ.その apheresis (語頭音消失)の結果と考えられる myddest が,名詞としてではあるがやはり15世紀に文証されており,amidst と相互に影響し合っていた可能性がある.興味深いのは,OED "midst, n., prep., and adv. の語義 C1 によると,14世紀に m が挿入された綴字ではあるが,mydmeste という形態が文証されることである.
1. In the middle place. Obs.
Only in first, last, and midst and similar phrases recalling Milton's use (quot. 1667).
[c1384 Bible (Wycliffite, E.V.) (Douce 369(2)) (1850) Matt. Prol. 1 In the whiche gospel it is profitable to men desyrynge God, so to knowe the first, the mydmeste, other the last.]
1667 Milton Paradise Lost v. 165 On Earth joyn all yee Creatures to extoll Him first, him last, him midst, and without end.
first, last, and midst という句が示すとおり,最上級の -st との連想(そして Coda での押韻)が作用していることがわかる.
-st の語尾音添加 (paragoge) を受けた against, amidst, amongst, betwixt, whilst などのあいだには,意味的に「間」や最上級と連想されうる要素が共有されているようにも思われるし,機能語としての役割も共通している.初出の時期も,-(e)s 系列も含めて,およそ中英語から近代英語にかけての時期にパラパラと現われている.微弱ながらも,何らかの類推 (analogy) が作用していそうである.
なお,現代英語における amid と amidst の使い分けについて,小西 (70) より記そう.両者ともに文語的だが,専門データベースによると前者のほうが12倍以上の頻度を示す.しかし,amidst はイギリス英語で好まれるという特徴がある.また,OED によると,"There is a tendency to use amidst more distributively than amid, e.g. of things scattered about, or a thing moving, in the midst of others." とある通り,amidst は個別的な意味が強いというが,これが事実だとすれば -st の音韻的な重さと意味上の強調とのあいだに何らかの関係を疑うことができるかもしれない.
-st 語尾音添加については,ほかにも[2013-07-29-1]の記事の末尾につけたリンク先の諸記事を参照.
・ 小西 友七 編 『現代英語語法辞典』 三省堂,2006年.
2013-05-07 Tue
■ #1471. golden を生み出した音韻・形態変化 [i-mutation][analogy][phonetics][analogy][suffix][waseieigo]
今年もゴールデンウィークが終わった.日本語としての「ゴールデンウィーク」は,1951年の連休に上映された映画が正月や盆の興行よりもヒットしたことにちなんだ映画業界発の和製英語である.GW という略記法もすっかり一般化した感がある.
さて,英語の golden は,名詞 gold の形容詞として認知されている.ただし,gold 自体も形容詞的に用いられ,派生形 golden はどちらかというと比喩的あるいは文語的に用いられることが多い.a gold coin (金貨)に対し,golden opportunity (絶好の機会)の如くである.和製英語ではあるが,上述の Golden Week も比喩的用法だろう.
現代英語で材質を表わす形容詞接尾辞 -en は,ラテン語 -īnus,ギリシア語 -inos,サンスクリット語 -īna などの古典語にも同根がみられるほどの古い接尾辞だが,16世紀以降,上記のように基体の名詞がそのまま形容詞として用いられることが多くなり,現在では目立たない接尾辞となっている.例えば,earthen, wheaten, woolen などは健在だが,glassen, oaken, silken, silvern, tinnen などは古めかしいか文語的である.
古英語の gylden (golden), stǣnen (of stone) という形態が示唆する通り,問題の接尾辞はさらに先立つ時代には高母音 i をもっており,直前の音節の母音に i-mutation を引き起こしたことは間違いない.それが,中英語において基体の gold, stone との音韻形態的な類推作用により母音が置換され golden, stonen を生み出した.これは,音韻変化により基体と派生形の差がいったん開いたものの,形態的な類推作用により再び形態が似通ってくるという言語変化に頻繁に観察される過程の好例だろう.なお,類推作用を経ずに伝わった gilden は16世紀に廃語となった.これと関連した別の発展による動詞 gild (金めっきをする)は,現在まで残っている.
さて,古英語 gylden から i-mutation の作用を逆算すると,基体としての名詞は gulden となるはずだが,古英語では gold である.これは,古英語以前のゲルマン時代に,一般的に u が o へと上げの音韻過程を経たためである.ただし,この音韻過程は n や高母音が後続する場合には阻止された.これは,古英語の強変化動詞第III類において,bunden では u が保たれているが,holpen では o へ上げが生じたことなども説明する (Hamer 14--15) .これにより古英語の名詞 gold に対し,形容詞 gylden (< *guldin) も理解されよう.
・ Hamer, R. F. S. Old English Sound Changes for Beginners. Oxford: Blackwell, 1967.
2013-05-07 Tue
■ #1471. golden を生み出した音韻・形態変化 [i-mutation][analogy][phonetics][analogy][suffix][waseieigo]
今年もゴールデンウィークが終わった.日本語としての「ゴールデンウィーク」は,1951年の連休に上映された映画が正月や盆の興行よりもヒットしたことにちなんだ映画業界発の和製英語である.GW という略記法もすっかり一般化した感がある.
さて,英語の golden は,名詞 gold の形容詞として認知されている.ただし,gold 自体も形容詞的に用いられ,派生形 golden はどちらかというと比喩的あるいは文語的に用いられることが多い.a gold coin (金貨)に対し,golden opportunity (絶好の機会)の如くである.和製英語ではあるが,上述の Golden Week も比喩的用法だろう.
現代英語で材質を表わす形容詞接尾辞 -en は,ラテン語 -īnus,ギリシア語 -inos,サンスクリット語 -īna などの古典語にも同根がみられるほどの古い接尾辞だが,16世紀以降,上記のように基体の名詞がそのまま形容詞として用いられることが多くなり,現在では目立たない接尾辞となっている.例えば,earthen, wheaten, woolen などは健在だが,glassen, oaken, silken, silvern, tinnen などは古めかしいか文語的である.
古英語の gylden (golden), stǣnen (of stone) という形態が示唆する通り,問題の接尾辞はさらに先立つ時代には高母音 i をもっており,直前の音節の母音に i-mutation を引き起こしたことは間違いない.それが,中英語において基体の gold, stone との音韻形態的な類推作用により母音が置換され golden, stonen を生み出した.これは,音韻変化により基体と派生形の差がいったん開いたものの,形態的な類推作用により再び形態が似通ってくるという言語変化に頻繁に観察される過程の好例だろう.なお,類推作用を経ずに伝わった gilden は16世紀に廃語となった.これと関連した別の発展による動詞 gild (金めっきをする)は,現在まで残っている.
さて,古英語 gylden から i-mutation の作用を逆算すると,基体としての名詞は gulden となるはずだが,古英語では gold である.これは,古英語以前のゲルマン時代に,一般的に u が o へと上げの音韻過程を経たためである.ただし,この音韻過程は n や高母音が後続する場合には阻止された.これは,古英語の強変化動詞第III類において,bunden では u が保たれているが,holpen では o へ上げが生じたことなども説明する (Hamer 14--15) .これにより古英語の名詞 gold に対し,形容詞 gylden (< *guldin) も理解されよう.
・ Hamer, R. F. S. Old English Sound Changes for Beginners. Oxford: Blackwell, 1967.
2013-03-20 Wed
■ #1423. 初期近代英語の3複現の -s (2) [verb][conjugation][emode][corpus][ppceme][ppcbme][number][agreement][analogy][3pp]
「#1413. 初期近代英語の3複現の -s」 ([2013-03-10-1]) の記事の続き.前の記事では,PPCEME による検索で,3複現の -s の例を50件ほど取り出すことができたと述べたが,文脈を見ながら手作業で整理したところ,全52例が確認された(データのテキストファイルはこちら).
PPCEME では,E1 (1500--1569), E2 (1570--1639), E3 (1640--1710) の3期が区分されているが,その区分ごとに3複現の -s の生起数を示すと以下のようになる(各期のコーパスの総語数も示した).
| Period | Tokens | Wordcount |
|---|---|---|
| E1 (1500--1569) | 13 | 567,795 |
| E2 (1570--1639) | 18 | 628,463 |
| E3 (1640--1710) | 21 | 541,595 |
| Total | 52 | 1,737,853 |
Queen Elizabeth I's Boethius (E2), Thomas Middleton's A chaste maid in Cheapside (E2), Celia Fiennes's journeys (E3) などの特定のテキストに数回以上生起するとはいえ,全体として少ない生起数ながらも,およそむらなく分布しているとは言えるかもしれない.例文を眺めてみると,以下のように主語と動詞の倒置がみられるものがいくつかあり,現代英語の「there is + 複数名詞」のような構文を想起させる.
・ and after them comys mo harolds,
・ Here comes our Gossips now,
・ Now in goes the long Fingers that are wash't Some thrice a day in Vrin,
さて,Lass (166) に3複現の -s について関連する言及を見つけたので,紹介しておこう.Lass は,3複現の -s の起源について,単数に比べれば時代は遅れたものの,北部方言からの伝播だと考えているようだ.
The {-s} plural appears considerably later than the {-s} singular, and if it too is northern (as seems likely), it represents a later diffusion. The earliest example cited by Wyld ([History of Modern Colloquial English] 346) is from the State Papers of Henry VIII (1515): 'the noble folk of the land shotes at hym'. It is common throughout the sixteenth and seventeenth centuries as a minority alternant of zero, and persists sporadically into the eighteenth century.
16,17世紀を通じて行なわれていたということは,上記の PPCEME からの例で確かに認められた.なお,後期近代英語をカバーする PPCMBE で18世紀以降の状況を調べてみると,こちらの6例が挙がった.しかし,実体の数と観念の上で焦点化される数との不一致の例と読めるものも含まれており([2012-06-14-1]の記事「#1144. 現代英語における数の不一致の例」を参照),後期近代英語では3複現の -s は皆無に近いと考えてよさそうだ.
・ Lass, Roger. "Phonology and Morphology." 1476--1776. Vol. 3 of The Cambridge History of the English Language. Ed. Roger Lass. Cambridge: CUP, 1999. 56--186.
2013-03-10 Sun
■ #1413. 初期近代英語の3複現の -s [verb][conjugation][emode][corpus][ppceme][number][agreement][analogy][3pp]
標記について Baugh and Cable (247) に触れられており,目を惹いた.3単現ならぬ3複現における -s は,中英語では珍しくない.中英語の北部方言では,「#790. 中英語方言における動詞屈折語尾の分布」 ([2011-06-26-1]) の下の地図で示したように,直説法3人称複数では -es が基本だった.しかし,初期近代英語の標準変種において3複現の -s が散見されるというのは不思議である.というのは,この時期の文学や公文書に反映される標準変種では,中英語の East Midland 方言の -e(n) が消失した結果としてのゼロ語尾が予想されるし,実際に分布として圧倒的だからだ.しかし,3複現の -s は確かに Shakespeare でも散見される.
この問題について,Baugh and Cable (247) は次のように指摘している.
Their occurrence is also often attributed to the influence of the Northern dialect, but this explanation has been quite justly questioned, and it is suggested that they are due to analogy with the singular. While we are in some danger here of explaining ignotum per ignotius, we must admit that no better way of accounting for this peculiarity has been offered. And when we remember that a certain number of Southern plurals in -eth continued apparently in colloquial use, the alternation of -s with this -eth would be quite like the alternation of these endings in the singular. Only they were much less common. Plural forms in -s are occasionally found as late as the eighteenth century.
ここで,3複現の -s が北部方言からの影響ではないとする Baugh and Cable の見解は,Wyld, History of Modern Colloquial English, p. 340 の言及に負っている.むしろ,この時期の3単現の -s 対 -th の交替が,複数にも類推的に飛び火した結果だろうと考えている.なお,Görlach (89) は,方言からきたものか単数からきたものか決めかねている.
この問題を考察するにあたって,何はともあれ,初期近代英語において3複現の -s なり -th なりが具体的にどのくらいの頻度で現われるのかを確認しておく必要がある.そこで,The Penn-Helsinki Parsed Corpus of Early Modern English (PPCEME) によりざっと検索してみた.約180万語という規模のコーパスだが,3複現の -s の例は50件ほど,3複現の -th の例は60件ほどが挙がった(結果テキストファイルは左をクリック).年代や文脈などの詳細な分析はしていないが,典型的な例を少し挙げておく.
・ and all your children prayes you for your daly blessing.
・ but the carving and battlements and towers looks well;
・ then go to the pot where your earning bagges hangs,
・ as our ioyes growes, We must remember still from whence it flowes,
・ Ther growes smale Raysons that we call reysons of Corans,
・ now here followeth the three Tables,
・ And yf there be no God, from whence cometh good thynges?
・ First I wold shewe that the instruccyons of this holy gospell perteyneth to the vniuersal chirche of chryst.
・ and so the armes goith a sundre to the by crekes.
・ And to this agreith the wordes of the Prophetes, as it is written.
・ Also high browes and thicke betokeneth hardnes:
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
・ Görlach, Manfred. Introduction to Early Modern English. Cambridge: CUP, 1991.
2012-12-03 Mon
■ #1316. analogist and anomalist controversy (2) [history_of_linguistics][onomatopoeia][sound_symbolism][analogy]
昨日の記事に引き続き,古代ギリシアから続く標記の言語論争について.Colson (29--30) は,analogist と anomalist の議論にそれぞれ注意すべき点があるとして,次のように論評している.
基本的には,言語が規則から成っているという analogist の議論は受け入れられる.不規則な例はあるとはいえ,例えば屈折体系が表の形できれいにまとめられるという事実は,言語の背後にある規則の存在を歴然と示している.不規則性を個体による変異ととらえれば,理性に支配されている自然界にも同じ状況があるわけであり,不規則性を示す例があるからといって,すなわち analogist の議論が崩れるということにはならないはずである.
もう1つは,言語過程に見られる規則性を指向する類推作用 (analogy) はしばしば自然 (nature) の力と考えられているが,実際には類推作用自体が慣用 (usage) の産物ではないかという点だ.
このように,analogist と anomalist は二律背反の対立というよりは,論者の態度の方向を示すものであり,同じ論者でも個々の議題によっては揺れ動く可能性のある2つの方向ととらえたほうがよさそうである.
さて,類推作用が ratio ではなく,慣用に由来する exemplum に依存しているという Quintilianus (35?--95?) の見方(Colson 30) は,理論的に興味深い.いや,もとより理性の作用ではなく範例の模倣ということにすぎないのであれば,理論的には扱えないことになる.だが,類推作用には特定の語などに単発に作用する場合もあれば,広く言語体系に作用する場合もあるのも確かであり,後者は前者に比べれば ratio に近いと議論することはできるだろう.畢竟,ここでも程度の問題である.analogist and anomalist controversy は,論争ととらえるよりは,言語に存する2種類の本質としてとらえるほうがわかりやすい.
・ Colson, F. H. "The Analogist and Anomalist Controversy." Classical Quarterly 13 (1919): 24--36.
2012-11-24 Sat
■ #1307. most と mest [analogy][superlative][vowel][me_dialect][corpus][hc][ppcme2][comparison]
中英語には,最上級 most が mest という前舌母音字を伴って現われることが少なくない.近代英語以降,後者は廃れていったが,両形の起源と分岐はどこにあるのだろうか.
most は Proto-Germanic *maistaz に遡ることができ,ゲルマン諸語では Du. meest, G meist, ON mestr, Goth. maists などで文証される.音韻規則に従えば,古英語形は māst となるはずであり,実際にこの形態は Northumbrian 方言で確認されるものの,南部方言では確認されない.南部では,前舌母音を伴う West-Saxon mǣst や Kentish mēst が用いられた.OED によれば,前舌母音形は,lǣst "least" との類推とされる.この前舌母音の系統が,主として mest(e) という形態で中英語の南部方言へも継承され,そこでは15世紀まで使われた.
一方,北部方言に起源をもつ形態は,中英語では後舌母音の系統を発達させ,主として most(e) という形態が多用された.じきに中部,南部でも一般化したが,北部方言形の南下というこの時期の一般的な趨勢に加え,比較級 mo, more の母音との類推も一役買ったのではないかと想像される.
結果的に,近代英語以降にはゲルマン祖語からの規則的な発達形 most が標準的となってゆき,古英語から中英語にかけて用いられた mest は標準からは失われていった.「一番先の」を意味する中英語 formest (cf. 比較級 former) が,15世紀に foremost として再分析された背景には,上述の most による mest の置換が関与しているかもしれない.もっとも,古英語より,最上級語尾の -est 自体が -ost とよく混同されたのであり,最上級に関わる形態論において,両母音の交替は常にあり得たことなのかもしれない.
なお,PPCME2 でざっと後舌母音系統 (ex. most) と前舌母音系統 (ex. mest) の分布を調べてみると,前者が354例,後者が168例ヒットした.Helsinki Corpus でも簡単に調査したが,中英語でも現代標準英語と同様に most 系統が主流だったことは間違いないようだ.
2012-11-04 Sun
■ #1287. 動詞の強弱移行と頻度 [frequency][analogy][verb][conjugation][lexical_diffusion][statistics]
昨日の記事「#1286. 形態音韻変化の異なる2種類の動機づけ」 ([2012-11-03-1]) で紹介した Hooper の論文では,調査の1つとして動詞の強弱移行(強変化動詞の弱変化化)が取り上げられていた.Hooper の議論は単純明快である.強弱移行は類推による水平化 (analogical leveling) の典型例であり,頻度の低い動詞から順に移行を遂げてきたのだという.
Hooper が調査対象とした動詞は古英語の強変化I, II, III類に由来する動詞のみであり,その現代英語における頻度情報については Kučera and Francis の頻度表が参照されている.頻度計算は lemma 単位での綴字のみを基準とした拾い出しであり,drive, ride などの語(下表で * の付いているもの)について品詞の区別を考慮していない荒削りなものだ.また,過去千年以上にわたる言語変化を話題にしているときに,現代英語における頻度のみを参照してよいのかという問題([2012-09-21-1]の記事「#1243. 語の頻度を考慮する通時的研究のために」)についても楽観的である (99) .全体として,解釈するのに参考までにという但し書きが必要だが,以下に Hooper (100) の表を見やすく改変したものを掲げよう.
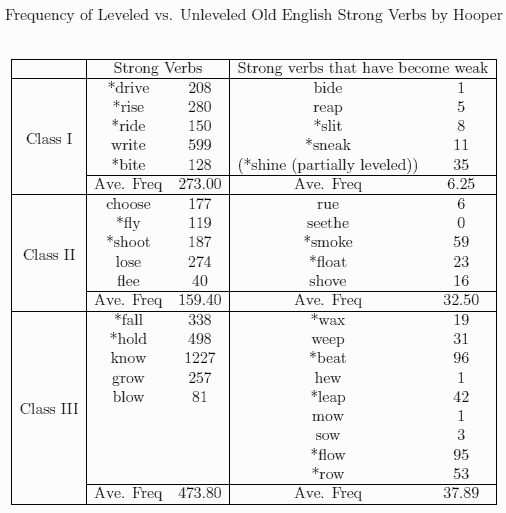
確かにこのように見ると,強弱移行を経た動詞は全体として頻度が相対的にずっと低いことがわかる.関連して,keep, *leave, *sleep や *creep, *leap, weep について,前者3語が伝統的な過去形を保持しているのに対して,後者3語には周辺的に creeped, leaped, weeped の異形も確認されるという.前者の頻度はそれぞれ 531, 792, 132 に対して後者はそれぞれ 37, 42, 31 だという (Hooper 100) .参考までにとはいっても,傾向としては明らかのように思われる.
動詞の強弱移行は英語史において基本的な話題であり,本ブログでも「#178. 動詞の規則活用化の略歴」 ([2009-10-22-1]) ,「#527. 不規則変化動詞の規則化の速度は頻度指標の2乗に反比例する?」 ([2010-10-06-1]) ,「#528. 次に規則化する動詞は wed !?」 ([2010-10-07-1]) などで触れてきたが,案外とわかっていないことも多い.今後の詳細な研究が俟たれる.
・ Hooper, Joan. "Word Frequency in Lexical Diffusion and the Source of Morphophonological Change." Current Progress in Historical Linguistics. Ed. William M. Christie Jr. Amsterdam: North-Holland, 1976. 95--105.
2012-11-03 Sat
■ #1286. 形態音韻変化の異なる源 [phonetics][frequency][causation][neogrammarian][analogy][verb][conjugation][lexical_diffusion]
音韻変化と語の頻度との関係については,Phillips の研究を紹介しながら,「#1239. Frequency Actuation Hypothesis」 ([2012-09-17-1]) や「#1242. -ate 動詞の強勢移行」 ([2012-09-20-1]) で取り上げてきた.「#1265. 語の頻度と音韻変化の順序の関係に気づいていた Schuchardt」 ([2012-10-13-1]) で触れたように,純粋に音声学的な変化は高頻度語から始まるということは早くも19世紀から指摘されていたが,逆に類推作用 (analogy) の関わる形態音韻的な変化は低頻度語から始まるということも,ほぼ同時期に Herman Paul によって指摘されていた(Hooper 95) .
Hooper は,1984年の論文で,語の頻度という観点から,純然たる音声変化と考えられる現代英語における schwa-deletion (memory などの第2母音)と類推による水平化と考えられる動詞の弱変化化を調査し,この2項対立 "phonetic change tends to affect frequent words first, while analogical leveling tends to affect infrequent words first" (101) を支持した.Phillips はこの単純な2項対立によっては説明できない例のあることを示しているが,この対立を議論の出発点とすることは今でも妥当だろう.
このように頻度と音韻変化の関係にこだわっているように見える Hooper だが,実のところ,話者は語の頻度情報にアクセスできないはずだと考えている (102) .
I do not think the relative frequency of words is a part of native speaker competence, so I would not propose to make the rule sensitive to word frequency.
それでも語の頻度と音韻変化の進行順序に相関関係があることを認め続けるのであれば,両者の接点は,話者の言語能力ではなく言語運用のなかにあるということになるのだろうか.Hooper は子供の言語獲得に答えを見つけようとしているようだ.
語の頻度と音韻変化の順序に関する議論のもつ理論的な意義は,(形態)音韻変化には源の異なる複数の種類があり得ることが示唆される点にある.変化の順序が異なるということは,おそらく変化のメカニズムが異なるということであり,変化の源が異なるということではないか.そうだとすれば,変化の順序がわかれば,変化の動機づけもわかることになる.従来はそのような源の異なる変化に「純然たる音声変化」や「類推的な形態音韻変化」というラベルを貼り付けてきたが,今後はより細かい分類が必要だろう.Hooper (103) の結語を引いておきたい.
. . . if it turned out that vowel shifts and some other phonetic changes affect infrequent forms before frequent forms, then we would have an interesting indication that phonetic changes arise from different sources, and furthermore, if my hypotheses are correct, a way of determining which types of changes are traceable to which source. Thus it appears that lexical diffusion, studied in terms of word frequency, may turn up some interesting evidence concerning the source of morpho-phonological change. (103)
・ Hooper, Joan. "Word Frequency in Lexical Diffusion and the Source of Morphophonological Change." Current Progress in Historical Linguistics. Ed. William M. Christie Jr. Amsterdam: North-Holland, 1976. 95--105.
・ Phillips, Betty S. "Word Frequency and the Actuation of Sound Change." Language 60 (1984): 320--42.
・ Phillips, Betty S. "Word Frequency and Lexical Diffusion in English Stress Shifts." Germanic Linguistics. Ed. Richard Hogg and Linda van Bergen. Amsterdam: John Benjamins, 1998. 223--32.
2012-10-13 Sat
■ #1265. 語の頻度と音韻変化の順序の関係に気づいていた Schuchardt [frequency][lexical_diffusion][history_of_linguistics][analogy][creole][neogrammarian]
語の頻度と語彙拡散 (lexical diffusion) の進行順序の関係については,[2012-09-17-1], [2012-09-20-1], [2012-09-21-1]の各記事で扱ってきた.19世紀の青年文法学派 (Neogrammarians) によれば,音韻変化は "phonetically gradual and lexically abrupt" であるということが常識だったが,近年の語彙拡散の研究により,音韻変化にも形態変化に典型的に見られる "lexically gradual" の過程が確認されるようになってきている.形態であれ音韻であれ,言語変化のなかには徐々に波及してゆくものがあるという知見は,言語変化の原理としての類推作用 (analogy) とも相性がよく,音韻変化と類推を完全に対置していた Neogrammarians がもしこのことを知ったら相当の衝撃を受けたことだろう.
徐々に進行する音韻変化が確認される場合,それがどのような順序で進行するのかという点が問題となる.そこで,語の頻度という観点が提案されているのだが,この観点からの研究はまだ緒に就いたばかりである.ところが,観点ということだけでいえば,その提案は意外と早くなされていた.青年文法学派に対抗した Hugo Ernst Maria Schuchardt (1842--1927) は1885年という早い段階で,語の頻度と音韻変化の順序に目を付けていたのだ.以下は,Phillips (321) に掲載されている Schuchardt からの引用(英訳)である.
The greater or lesser frequency in the use of individual words that plays such a prominent role in analogical formation is also of great importance for their phonetic transformation, not within rather small differences, but within significant ones. Rarely used words drag behind; very frequently used ones hurry ahead. Exceptions to the sound laws are formed in both groups.
Neogrammarian 全盛の時代において,語の頻度と音韻変化の順序に注目した Schuchardt の炯眼に驚かざるをえない.この識見は,当時,生きた言語の研究における最先端の場であり,ラテン語を母体とする資料の豊富さで確かな基盤のあったロマンス語学の分野に彼が身を投じていたことと関係する.彼は,現実の資料には Neogrammarian の音法則に反する例が豊富にあることをはっきりと認識しており,音法則による言語史の再建だけでは言語の真の理解は得られないことを痛感していた.語族という考え方にも否定的で,言語に混合や波状拡散の過程を想定していた.特に彼の混交言語への関心は果てしなく,その先駆的な研究が評価されるようになったのは,1世紀も後,クレオール語研究の現われだした1960年代のことである.
Schuchardt がこのような言語思想をもっていたことを知れば,上記の引用も自然と理解できるだろう.Schuchardt とクレオール学の発展との関係については,田中 (188--96) が詳しい.
・ Phillips, Betty S. "Word Frequency and the Actuation of Sound Change." Language 60 (1984): 320--42.
・ Schuchardt, Hugo. Über die Lautgesetze: Gegen die Junggrammatiker. 1885. Trans. in Shuchardt, the Neogrammarians, and the Transformational Theory of Phonological Change. Ed. Theo Vennemann and Terence Wilbur. Frankfurt: Altenäum, 1972. 39--72.
・ 田中 克彦 『言語学とは何か』 岩波書店〈岩波新書〉,1993年.
2012-06-24 Sun
■ #1154. 言語変化のゴミ箱としての analogy [analogy][lexical_diffusion][phonetics][neogrammarian]
analogy (類推作用)は,言語変化の原因として,最も広く知られているが,同時に最も軽視されているといってよい.「音韻変化に例外なし」と唱えた19世紀の青年文法学派 (Neogrammarians) は,法則から漏れる事例は,類推か借用によって個別に説明にできると主張した.これによって,とりわけ類推は,例外を投げ込むべきゴミ箱と化していった.
青年文法学派の音韻変化の考え方は "phonetically gradual and lexically abrupt" というものだが,現実の音韻変化のなかには "phonetically abrupt and lexically gradual" のものがあることが分かってきている.語彙拡散 (lexical diffusion) の諸事例だ.また,音韻変化から形態変化へ視野を広げると,むしろ "morphologically abrupt and lexically gradual" の事例が通常である.この性質は,まさに類推による言語変化に典型的に見られる性質である.伝統的な音韻法則の立場から見れば,類推はゴミ箱のようなものだが,逆に類推を中心とした視点からすると,音韻法則こそが特異な事例のように思えてくる.両者の性格の異同を整理した上で,より高次の音韻変化理論,さらには言語変化理論を作り出すことが必要なのではないか.
類推の置かれている不幸な立場について,また類推と音韻変化とが不当に対置されてきた不幸な状況について,Postal (234) の注3で,次のように述べられている.
'Analogy' is really an unfortunate term. There is reason to believe that rather than being some sharply defined process, analogy actually is a residual category into which is put every kind of linguistic change which does not meet some set of a priori notions about the nature of change. In particular, I think that the term 'analogy' has been used very misleadingly to refer to cases of perfectly regular phonological change in which part of the conditioning environment involves Surface Constituent Structure; i.e. changes which happen only in nouns, or only in verb stems, etc. I suspect that an analytic survey of cases which have been referred to as 'analogy' would yield many instances of regular phonological change with nonphonetic environments . . . .
Postal は,"the regularity of phonetic change と "its putative purely phonetic character" (281) とが混同されてきたという根本的な問題を指摘しながら,いわゆる音韻変化と類推との距離はそれほど大きくないのではないかと示唆している.
類推は,心理的で不規則的な作用として,言語変化の議論においても扱いが難しいとされてきた.しかし,伝統的な音韻法則にすら,心理的な解釈は提出されてきたし,実際には不規則性が見られるからこそ,ゴミ箱が必要とされてきたのである.analogy の復権は図られてしかるべきだろう.
・ Postal, P. Aspects of Phonological Theory. New York: Harper & Row, 1968.
2012-06-13 Wed
■ #1143. 中英語期はいつ始まったか (2) [me][periodisation][inflection][analogy][me_dialect]
昨日の記事[2012-06-12-1]に引き続き,中英語の開始時期の話題.古英語と中英語の境を1000年頃におく Malone の見解は,極端に早いとして,現在,ほとんど受け入れられていない.その対極にあるのが,1200年頃におくべきだとする Kitson の論考である.
Kitson (221--22) は,まず,現在の主流の見解である1100年あるいは1150年という年代が,どのような議論から生み出されてきたかを概説している.[2009-12-19-1]の記事「#236. 英語史の時代区分の歴史 (5)」で示したように,Henry Sweet の3区分は後に圧倒的な影響力をもつことになったが,Sweet 自身の中英語期の開始時期についての意見は揺れていた.1888年の段階では1150年,それから4年後の1892年の段階では1200年に区切りを設定していたからである(後者は[2009-12-20-1]の記事「#237. 英語史の時代区分の歴史 (6)」で示されている見解).その後,1150年とする見解は比較的多くの支持者を得たが,現在では Hogg (9) の "by about 1100 the structure of our language was beginning to be modified to such a considerable degree that it is reasonable to make that the dividing line between Old English and Middle English" との見解が広く受け入れられているようだ.いずれの場合も,試金石は,屈折語尾の母音がいつ [ə] へ水平化したかという点である.
Kitson の議論を要約すれば,中英語の開始時期を巡る問題が難しいのは,母音の水平化が一夜に生じたものではなく,時間をかけて,方言によって異なる速度で進行したからである.また,母音の水平化は,ただ機械的な音韻変化として進行したわけではなく,複雑な類推作用 (analogy) の絡んだ形態変化として進行したのであり,その過程を跡づけることは余計にややこしい.そこで,中英語の開始時期を決めるにあたっては,(1) どの方言における母音水平化を中心に据えるか,(2) 母音水平化の始まった時期を重視するのか,あるいは完了した時期を重視するのか,あるいは中間時期を重視するのか,などの基本方針を決めなければならない.
Kitson (222--23) は,(1) の方言の問題については,後期古英語の標準語の中心が Winchester だったこと,初期中英語の標準化された言語の代表例として South-West Midland 方言の "AB-language" があったこと,母音水平化を詳細に跡づけることが可能なほどに多くの写本がこの方言から現存していること,Sweet の区分でも South-West Midland 方言の Laȝamon を基準として用いていることなどを指摘しながら,"the area between, broadly, Wiltshire and Herefordshire" あるいは "the north Wessex--south-west midland area" (223) を基本に据えるべきだと結論づけている.(2) の母音水平化の完了の程度という問題については,音韻形態変化としての母音水平化が決して逆行しえない段階,すなわち完全に終了した段階をもって中英語の開始を論じるのが理に適っていると結論している.
And bearing in mind that the linguistic processes of the transition were to a large extent analogical rather than strictly regular sound-changes, it seems most reasonable to date the beginning of Middle English, as against Old English whether or not with a sub-period specified as Transitional, to the point of time from which even if external events influencing linguistic change had taken so different a course as to lead to directions of analogy violently different from the actual ones, reduction of inflectional variety to the single-un-stressed-vowel level characteristic of actual Middle English was irrevocable. (223)
Kitson は,この移行期間に南部方言で書かれた文書における綴字と発音の関係を精密に調査し,1200年頃までは,いまだ前舌母音と後舌母音の区別が残っていたと主張し,次のように結論づけている.
. . . even at the end of the twelfth century the replacement of language with at least some variety of inflections by language with fully levelled inflections was not absolutely irrevocable. . . . Granting the level of fuzziness at the edges inescapable in all tidy divisions of linguistic periods, Sweet's 1892 dating really is right after all.
・ Malone, Kemp. "When Did Middle English Begin?" Language 6 (1930): 110--17.
・ Kitson, Peter R. "When did Middle English begin? Later than you think!." Studies in Middle English Linguistics. Ed. Jacek Fisiak. Berlin: Mouton de Gruyter, 1997. 221--269.
・ Hogg, Richard M., ed. The Cambridge History of the English Language: Vol. 1 The Beginnings to 1066. Cambridge: CUP, 1992.
2012-04-11 Wed
■ #1080. なぜ five の序数詞は fifth なのか? [numeral][adjective][inflection][oe][phonetics][assimilation][analogy][sobokunagimon][shocc]
標題は,先日素朴な疑問への投稿に寄せられた質問.基数詞 five に対して序数詞 fifth であるのはなぜか.基数詞 twelve に対して序数詞 twelfth であるのはなぜか,というのも同じ問題である.
今回の疑問のように「基本形 A に対して,関連する A' が不規則形を帯びているのはなぜか」というタイプの問題は少なくないが,問題提起を逆さに見るほうが歴史的事実に対して忠実であるということが,しばしばある.今回のケースで言えば,「 /v/ をもつ基数詞 five に対して,関連する序数詞が不規則な /f/ をもつ fifth となっているのはなぜか」ではなく「 /f/ をもつ序数詞 fifth に対して,関連する基数詞が不規則な /v/ をもつ five となっているのはなぜか」と考えるべき問題である.歴史的には fifth の /f/ は自然であり,five の /v/ こそが説明を要する問題なの である.
古英語に遡ると,基数詞「5」は fīf であり,基数詞「12」は twelf だった.綴字に示されている通り,語尾は無声音の [f] である(cf. 現代ドイツ語の fünf, zwölf).古英語で序数詞を作る接尾辞は -(o)þa だったが,この摩擦子音は [f] の後では破裂音 [t] として実現され,古英語での対応する序数詞は fīfta, twelfta として現われた.中英語以降に,他の序数詞との類推 (analogy) により t が th に置き換えられ,現代英語の fifth, twelfth が生まれた.
もう1つ説明を加えるべきは,古英語で「5番目の」は fīfta と長母音を示したが,現在では短母音を示すことだ.これは,語末に2子音が後続する環境で直前の長母音が短化するという,中英語にかけて生じた一般的な音韻変化の結果である.同じ音韻変化を経た語を含むペアをいくつか示そう.現代英語ではたいてい母音の音価が交替する.([2009-05-14-1]の記事「#16. 接尾辞-th をもつ抽象名詞のもとになった動詞・形容詞は?」も参照.)
・ feel -- felt
・ keep -- kept
・ sleep -- slept
・ broad -- breadth
・ deep -- depth
・ foul -- filth
・ weal -- wealth
・ wide -- width
fifth については,このように接尾辞の子音の声や語幹の母音の量に関して多少の変化があったが,語幹の第2子音としては古英語以来一貫して無声の /f/ が継承されてきており,古英語の基数詞 fīf からの直系の子孫といってよいだろう.
では,次に本質的な問題.古英語の基数詞 fīf の語末子音が有声の /v/ となったのはなぜか.現代英語でもそうだが,基数詞は「5」のように単独で名詞的に用いられる場合と「5つの」のように形容詞的に用いられる場合がある.古英語では,形容詞としての基数詞は,他の通常の形容詞と同様に,関係する名詞の性・数・格・定不定などの文法カテゴリーに従って特定の屈折語尾をとった.fīf は,当然ながら,数のカテゴリーに関して複数としての屈折語尾をとったが,それは典型的には -e 語尾だった(他の語尾も,結局,中英語までには -e へ収斂した).古英語では,原則として有声音に挟まれた無声摩擦音は声の同化 (assimilation) により有声化したので,fīfeの第2子音は <f> と綴られていても [v] と発音された.そして,やがてこの有声音をもつ形態が,無声音をもつ形態を置き換え,基本形とみなされるようになった.twelve についても同様の事情である.実際には,基数詞の屈折の条件は一般の形容詞よりも複雑であり,なぜ [v] をもつ屈折形のほうが優勢となり,基本形と認識されるようになったのかは,別に説明すべき問題として残る.
数詞のなかでは,たまたま five / fifth と twelve / twelfth のみが上記の音韻変化の条件に合致したために,結果として「不規則」に見え,変わり者として目立っている.しかし,共時的には不規則と見られる現象も,通時的には,かなりの程度規則的な変化の結果であることがわかってくる.規則的な音韻変化が不規則な出力を与えるというのは矛盾しているようだが,言語にはしばしば観察されることである.また,不規則な形態変化が規則的な出力を与える(例えば類推作用)というのもまた,言語にはしばしば観察されるのである.
2011-11-15 Tue
■ #932. neutralization は異形態の縮減にも貢献した [oe][old_norse][inflection][conjugation][paradigm][contact][language_change][analogy]
[2011-11-11-1]の記事「#928. 屈折の neutralization と simplification」と[2011-11-14-1]の記事「#931. 古英語と古ノルド語の屈折語尾の差異」で,古ノルド語との言語接触に起因する古英語の屈折体系の簡単化について取り上げてきた.O'Neil が neutralization と呼ぶ,この英語形態論の再編成については,両言語話者による屈折語尾の積極的な切り落としという側面が強調されることが多いが,より目立たない側面,allomorphy の縮減という側面も見逃してはならない.
昨日の記事で示したパラダイムの対照表を見れば,屈折語尾の差異を切り落とし,ほぼ同一の語幹により語を識別するという話者の戦略が有効そうであることが分かるが,語幹そのものの同一性が必ずしも確保できないケースがある.パラダイムのスロットによっては,語幹が異形態 (allomorph) として現われることがある.昨日の例では,drīfan の過去形においては,単数1・3人称 (drāf) で ā の語幹母音を示すが,単数2人称および複数 (drife,drifon) で i の語幹母音を示す.
他にも,現在単数2・3人称の屈折において語幹母音が i-mutation を示す古英語の動詞は少なくない.OE lūcan "to lock" の現在形の活用表を示すと,以下のように語幹母音が変異する (O'Neil 262) .
| Old English | |
| Inf | lūcan 'lock' |
| Pres. Sing. 1. | lūce |
| 2. | lȳc(e)st |
| 3. | lȳc(e)ð |
| Plur. | lūcað |
ところが,中英語の典型的なパラダイムでは,現在単数2・3人称の語幹は他のスロットと同じ語幹を取るようになっている.ここで生じたのは allomorphy の縮減であり,結果として,不変の語幹が現在形のパラダイムを通じて用いられるようになった.動機づけのない allormophy をこのように縮減することは,当時,互いに意志疎通を図ろうとしていた古英語や古ノルド語の話者にとっては好意的に迎え入れられただろうし,それ以上にかれらが縮減を積極的に迎え入れたとすら考えることができる.
I think it clear that working from quite similar, often identical, underlying forms but with different sets and intersecting sets of endings associated with them and bewildering allomorphies as a result of the conditions established by the endings, the basic underlying sameness of Old English and Old Norse had become somewhat distorted and thus a superficial barrier to communication between speakers of the two languages had arisen. It is not surprising then that the inflections of the languages were rapidly and radically neutralized, for they were the source of nearly all difficulty. (O'Neil 262--63)
allormophy の縮減は,言語接触による neutralization の過程としてだけでなく,言語内的な類推 (analogy) や 単純化 (simplification) の過程としても捉えることができる.実際には,片方のみが作用していたと考えるのではなく,両者が共に作用していたと考えるのが妥当かもしれない.
allomorphy の縮減は,パラダイム内の levelling (水平化)と読み替えることも可能だろう.この用語については,[2010-11-03-1]の記事「#555. 2種類の analogy」を参照.
・ O'Neil, Wayne. "The Evolution of the Germanic Inflectional Systems: A Study in the Causes of Language Change." Orbis 27 (1980): 248--86.
2011-09-05 Mon
■ #861. 現代英語の語強勢の位置に関する3種類の類推基盤 [diatone][stress][prosody][analogy][gsr][rsr]
英単語の強勢にまつわる歴史は非常に込み入っている.[2009-11-13-1]の記事「アクセントの位置の戦い --- ゲルマン系かロマンス系か」や[2011-04-15-1]の記事「英語の強勢パターンは中英語期に変質したか」で言及にしたように,中英語以降,Germanic Stress Rule と Romance Stress Rule の関係が複雑化してきたことが背景にある.しかし,語強勢の話題が複雑なのは,通時的な観点からだけではない.現代英語を共時的に見た場合でも,多様な analogy による強勢位置の変化と変異が入り乱れており,強勢の位置に統一的な説明を与えるのが難しい.そして,現代英語の語強勢に関する盤石な理論はいまだ存在しないのである.
では,韻律論の理論化を妨げているとされる多様な analogy には,どのようなものがあるのだろうか.Strang (55--56) によれば,主要なものは3種類ある.
(1) GSR に基づく,強勢の前寄り化の一般的な傾向.
"a tendency to move the stress toward the beginning of a word, as in; /ˈædʌlt/ beside /əˈdʌlt/, /ˈækjʊmɪn/ beside /əˈkjuːmɪn/, /ˈsɒnərəs/ beside /səˈnɔːrəs/" (55).
(2) 名前動後の語群に基づく機能分化的な傾向(diatone の各記事を参照).
"Variable stress-placement is exploited for grammatical purposes, in a series of items with root stress in nominals (usually nouns and substantival modifiers) and second-syllable stress in verbs, e.g., absent, concert, desert, perfect, record, subject . . ." (55).
(3) word-family の構成要素間に生じる強勢位置の吸引力.
". . . [analogical pull] of the word family an item belongs to. . . Word-analogy is responsible for variations such as applicable, subsidence (first-syllable stress, or a variant with a second-syllable stress on the model of apply, subside. Secret, borrowed in ME with second-syllable stress, has shifted to first syllable stress; its derivative secretive (a 15c formation), kept the older stress as late as OED, but is now tending to follow the example of the commoner secret, with first-syllable stress" (56).
3種類の類推は互いに排他的ではなく,むしろ干渉しあうことがある.例えば,名詞と動詞の機能をもつ romance は現代英語では双方ともに第2音節に強勢の落ちるのが主流だったが,アメリカ英語では名前動語化の流れがある.そのように聞くと (2) の影響が作用していると言えそうだが,動詞も合わせて強勢が前化している証拠も部分的にある.とすると,(1) の類推が作用している言えなくもない.(3) の観点からは,romance の強勢前化傾向が引き金となって,romancer, romancist, romantic, romanticism などの強勢が前へ引きつけられるという可能性が,今後生じてくるということだろうか.個々の単語(ファミリー)の問題だとすると,確かに強勢位置のルール化は難しそうだ.
・ Strang, Barbara M. H. A History of English. London: Methuen, 1970.
2011-07-22 Fri
■ #816. homonymic clash がもたらしうる4つの結果 [homonymic_clash][analogy][homonymy]
homonymic_clash の状況になると,その結果として何が生じるか.Malkiel (2--12) の整理した4つの可能性を要約し,解説しよう.
(a) 同音異義を示す2語について,当初は衝突の問題を示すが,問題の程度が比較的小さく,曖昧さを排除する他の手段も見つけられる場合には,最終的に(少なくとも形式張ったレジスターでは)併存し続ける.flea (のみ)と flee (逃げる),straighten (まっすぐにする)と straiten (せばめる),lie (横たわる)と lie (嘘をつく)などが例である.
(b) 一方の同音異義語が他方を駆逐するか,隅に追いやる.勝者の勝因は,(1) 頻度が高い,(2) 既存のパターンに統合しやすい,(3) 適当な代替表現が手近に存在しない,などが考えられる.敗者が駆逐されずに残る場合にも,使用範囲が定型表現に限られるなど大幅な限定を受ける.例えば,cleave (切り裂く)と cleave (くっつく)では,後者は「(ある信念に)執着する」の語義に限定されている.稀なケースでは,両者が消えることもある.
(c) 同音異義語ではあるが互いに意味が相当に類似している場合には,両者が融合してしまうことがある.例えば,light (軽い)と light (薄い)などは話者によっては意識のなかでは1つの多義語と認識されているかもしれない ([2010-02-07-1], [2011-07-21-1]) .また,融合が部分的であると,もともとの2語と新たに生まれた第3の語とが意味を分け合って,3語すべてが併存する可能性もある.
(d) 主に屈折接辞について,1つの接辞が2つの文法機能を担っている場合に生じる衝突においては,機能の一方がパラダイム内でその機能に対応する別の典型的な接辞へと形態をシフトさせるケースがある.Malkiel では英語からの例は挙げられていないが,例えば次のようなケースが相当するだろうか.古英語の強変化動詞 slǣpan "sleep" において現在形と過去形の母音が融合したときに,過去形を明示できる弱変化形 slept が用いられるようになったという場合である.Malkiel (7) はこれを "diachronic differentiation" と呼んでいる.他の3つの結果の場合と異なるのは,複数の文法カテゴリーが密接に関わる屈折語尾の homonymic clash では,(b) の「駆逐」という帰結は考えにくい.屈折体系に大きな変化を来たし,リスクが大きいからである.また,代替手段( sleep の例では弱変化過去の dental suffix )が,関連するパラダイムのなかに容易に見つかるのでシフトしやすいということがあるだろう.
(a), (b), (c) は古典的な分類だが,(d) は Malkiel が独自に提案したものである.従来は単に inflection の問題,あるいは analogy の問題として扱われてきたような例を,改めて homonymic clash の観点から論じなおすことができるのではないかという提案である.
ほかにも,Malkiel (2) は語幹にかかわる lexical homophone と屈折接辞や派生接辞にかかわる grammatical homophone とを区別したり,homonymy のみならず near-homonymy までを考察の射程に含めるなど,homonymic clash の理論化に貢献している.[2011-04-11-1]の記事「言語変化における同音異義衝突の役割をどう評価するか」で触れたように,homonymic clash については懐疑論者が少なくないが,昨日の記事「polysemic clash?」([2011-07-21-1]) で言及した Menner や今回の Malkiel は,homonymic clash を単に風変わりでおもしろい現象としてだけでなく,文法や意味の変化にも関連する本質的な話題としてとらえるべきだと主張している.私もこの主張に賛成したい.
・ Malkiel, Y. "Problems in the Diachronic Differentiation of Near-Homophones." Language 55 (1979): 1--36.
2011-04-04 Mon
■ #707. dragoman [plural][etymology][metanalysis][analogy][kyng_alisaunder]
標題の語は「(アラビア語,トルコ語,ペルシア語国の)通訳者」を意味する.OED の語義は,"An interpreter; strictly applied to a man who acts as guide and interpreter in countries where Arabic, Turkish, or Persian is spoken." である.語源はアラビア語の tarjumān 「通訳者」で,様々な言語を経由し,フランス語から中英語に drugeman として14世紀に借用された( MED を参照).初例は,たまたま最近読んでいる Kyng Alisaunder からだというので,以下に引用する.Alexander の進軍に対して,Darius のいとこ Salome がただちに軍を整えるように促す場面.(Smithers 版より.赤字は引用者.)
For Alisaunder is ypassed Achaye, And is ycome to Arabye, And is on þis half þe flum Jordan, And so me seide a drugeman. Haue we þe feld ar he, We scullen hym wynne, hym maugre.' (B 3395--400)
この語がおもしろいのは,語源的には本来語の man とは無関係にもかかわらず,man を含む複合語と誤って分析され,dragomen なる複数形が早くから現われていることだ.現代の辞書でも,複数形として dragomans に加えて dragomen が記載されている.Quirk et al. (306) でも,". . . the irregular plural can be found also in nouns that are not 'true' compounds with -man; eg: dragoman ? dragomans or dragomen." として言及されている.いわば German を *Germen, human を *humen と複数化してしまうタイプの異分析 ( metanalysis ) に基づく誤用といえるが,使用の歴史が長く,辞書に記載されるほどに一般化したということだろう.BNC の検索では,dragomans が3例,dragomen が1例あった.
通常,名詞の複数形の形成に働く類推 ( analogy ) は,大多数の -s 複数への引きつけという方向に働く.しかし,高度に不規則な i-mutation による複数形であっても,とりわけ頻度の高い men の吸引力は相当に強いと考えられる ([2011-03-22-1]) .現代英語語彙においてタイプの数として圧倒的な吸引力を誇る -s の磁場のなかで,単体の頻度として相当に高い吸引力を有する men が劣勢ながらも反抗している---そんな構図が描けるかもしれない.(ちなみに,初期中英語の名詞複数形を集めた私の研究では,全複数形20496トークンのうち2431トークンが man の複数形だった.あの収集作業のエネルギーの 11.86% が主に men に注がれていたと思うと徒労感が・・・.)
・ Smithers, G. V. ed. Kyng Alisaunder. 2 vols. EETS os 227 and 237. 1952--57.
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
2011-04-01 Fri
■ #704. brethren and sister(e)n [plural][analogy][ame][i-mutation][relationship_noun][corpus][coca][coha]
昨日の記事[2011-03-31-1]で,古英語の親族名詞の屈折表を見た.brethren の起源についても言及したが,これと関連して親族名詞お得意の類推 ( analogy ) の例をもう一つ挙げよう.brethren との類推で sister(e)n という複数形がある.MED の記述にあるように,中英語では -(e)n 形はごく普通であり,-s 形が一般化するのは brother の場合と同じく近代期以降である.この辺りの話題は私の専門領域なので,詳細なデータをもっている.初期中英語でもイングランドの北部や東部では -s が優勢だが,南部や西部ではこの時期の sister の複数形は原則として -n あるいは母音の語尾が圧倒していることは間違いない ( Hotta, p. 256 ) .
さて,sister(e)n は現代英語に生き残っているが,brethren と異なり,通常辞書には記載されていない.BNC ( The British National Corpus ) でもヒットしなかった.しかし,COCA ( Corpus of Contemporary American English ), COHA ( Corpus of Historical American English ) ではそれぞれ4例,15例(19世紀後半以降の例)がヒットし,もっぱらアメリカ英語で聞かれることが分かる.COCA からの例を1つ挙げる.政治討論会番組 "CNN Crossfire" からの用例である(赤字は引用者).
Well, you know, I hate to correct you, but you made the same mistake many of your liberal brethren and sisteren, have said in analyzing this dissent by Judge Stevens.
COCA, COHA 両コーパスからの計19例のうち16例までが brethren and sister(e)n として現われ,主にフィクションで用いられ,dear や my が先行する呼びかけの使い方が多い.brethren と同様に宗教的,組合的な文脈で現われているようだが,限定された語義としてのほか,文体的な効果もあるのかもしれない.関連して,OED の sister の語義5を引用しておこう."In the vocative, as a mode of address, chiefly in transferred senses. Also colloq. as a mode of address to an unrelated woman, esp. one whose name is not known."
もっぱらアメリカ英語で用いられることについては,Mencken (502) が触れている.
Sisteren or sistern, now confined to the Christians, white and black, of the Get-Right-with-God country, was common in Middle English and is just as respectable, etymologically speaking, as brethren.
sister(e)n という複数形に関する歴史的な問題は,近現代アメリカ英語での使用を,中英語期以来の継続としてとらえるべきか,あるいはアメリカ英語で改めてもたらされた刷新としてとらえるべきか,である.OED によると,sister(e)n は一般的な文章語としては16世紀半ばに廃れたとある.初期近代英語期の例やイギリス英語を含めた諸方言の例を調査しないと分からないが,(1) brethren との類推は時代を問わずありそうであること,(2) brethren と脚韻を踏むので呼びかけなど口語で特に好まれそうであること,この2点からアメリカ英語での再形成と考えるのが妥当ではないだろうか.中英語で非語源的な sister(e)n が作り出されたくらいだから,近代英語で改めて作られたとしても不思議はない.
sister(e)n は通常の辞書には載っていないくらいのレアな複数形だが,brethren, children, oxen (but see [2010-08-22-1]) と同じ,現代に残る少数派 -en 複数の仲間に入れてあげたい気がする.
・ Hotta, Ryuichi. The Development of the Nominal Plural Forms in Early Middle English. Hituzi Linguistics in English 10. Tokyo: Hituzi Syobo, 2009.
・ Mencken, H. L. The American Language. Abridged ed. New York: Knopf, 1963.
2011-03-31 Thu
■ #703. 古英語の親族名詞の屈折表 [inflection][oe][relationship_noun][plural][double_plural][i-mutation][analogy]
[2011-03-26-1], [2011-03-27-1]の記事で,歯音をもつ5つの親族名詞 father, mother, brother, sister, daughter の形態について論じた.親族名詞はきわめて基本的な語彙であり,形態的にも複雑な歴史を背負っているために,話題に取り上げることが多い.一度,古英語の形態を整理しておきたい.以下は,West-Saxon 方言での主な屈折形を示した表である( Campbell, pp. 255--56; Davis, p. 15 ) .
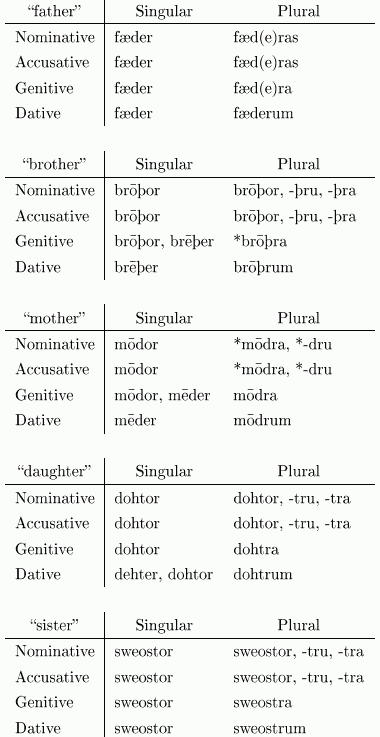
5語のあいだで互いに類推作用が生じ,屈折形が部分的に似通っていることが観察される.相互に密接な語群なので,何が語源的な形態であるかがすでによく分からなくなっている.
古英語でも初期と後期,方言の差を考慮に入れれば,この他にも異形がある.例えば brother の複数形として Anglian 方言には i-mutation([2009-10-01-1]) を経た brōēþre が行なわれた.この母音は現代英語の brethren に痕跡を残している.brethren の語尾の -en は,children に見られるものと同じで,古英語,中英語で広く行なわれた複数語尾に由来する.この形態は i-mutation と -en 語尾が同時に見られる二重複数 ( double plural; see [2009-12-01-1] ) の例である.brethren は「信者仲間;(プロテスタントの福音教会派の)牧師;同一組合員;《米》 (男子大学生)友愛会会員」の語義で用いられる brother の特殊な複数形で,古風ではあるが現役である.近代以降に brothers が優勢になるまでは,brethren は「兄弟」の語義でも普通の複数形であり,広く使われていた.中英語では MED に述べられているように,-s 複数形は稀だったのである.
・ Campbell, A. Old English Grammar. Oxford: OUP, 1959.
・ Davis, Norman. Sweet's Anglo-Saxon Primer. 9th ed. Oxford: Clarendon, 1953.
2011-03-27 Sun
■ #699. father, mother, brother, sister, daughter の歯音 (2) [phonetics][grimms_law][analogy][etymology][relationship_noun]
昨日の記事[2011-03-26-1]に引き続き,親族名詞に含まれる歯音について.昨日示した問題 (2) は次の通り.「sister が仲間はずれとして <t> を示すのはどのように説明されるか.また,daughter も <t> を示すが,sister の事情と関係があるのか.」
先に,daughter がなぜ印欧祖語の親族名詞群に見られる語尾 *-ter を現在まで保っているのかについて述べよう.印欧祖語の再建形は *dhughəter であり,一見すると問題の t は brother の例にならい,グリムの法則 ( Grimms's Law ) を経て þ へ変化しそうだが,そうはならなかった.これは,摩擦音 gh (現代でも綴字に痕跡が残る)の後位置ではグリムの法則が適用されなかったからである ( Skeat, pp. 246--47 ) .(関連して s の前でグリムの法則がブロックされたことについては[2011-01-28-1], [2011-02-18-1]の記事で扱った.)こうして daughter では,IE t が無傷のままに現在まで継承された.
そうすると sister の t も,s が先行するがゆえにグリムの法則をすり抜けたのでは,と考えられそうだが,ここにはまた別の事情がある.sister は,意外なことに印欧祖語の *-ter をもつ親族名詞群とは語源が異なる.印欧祖語の再建形 *swesor は,*swe- "one's own" と *ser "woman" の異形の合成語で,"the woman belonging to on's own kindred" ほどの原義だったと考えられている(梅田,pp. 323--24).このように sister は本来 t をもっていなかったのだが,ゲルマン語の段階で *-ter に由来する他の親族名詞に基づく類推作用 ( analogy ) が働き,*swestr- のように語幹に t が含まれることになった.したがって,sister の t は非語源的である.
現代英語の観点からは,sister は daughter とともに 非 th 系の仲間はずれのように見える.しかし,daughter は最も純粋な印欧祖語歯音の継承者であり,father, mother, brother を代表する立場にあると言えるだろう.一方で, sister はあくまで類推の産物であり,印欧祖語歯音を非語源的に標榜しているにすぎない.当初の質問からぐるっと一回転して,sister はやはり真の仲間はずれと言えるのかもしれない.
この記事を執筆するにあたり,主に Skeat (pp. 108, 147--49, 246--47, 369) を参照した.
・ 梅田 修 『英語の語源事典』 大修館,1990年.
・ Skeat, Walter W. Principles of English Etymology. 1st ser. 2nd Rev. ed. Oxford: Clarendon, 1892.
Powered by WinChalow1.0rc4 based on chalow