2014-07-24 Thu
■ #1914. <g> の仲間たち [grammatology][grapheme][alphabet][consonant][g][yogh][z]
英語史における <g> とその仲間の文字の関係は,とりわけ中英語期において,非常に複雑である.古英語期より,<g> という文字素 (grapheme) には,異文字 (allograph) として,平らな頭部をもつ <<Ӡ>> という字形 (insular <g>) と丸い閉じた頭部をもつ <<g>> という字形 (Carolingian <g>) があった.古英語では,前者が普通であり,後者は主としてラテン語を写すのに使われたにすぎない.当時の <g> は,後母音(字)の前では軟口蓋閉鎖音の /g/,前母音(字)の前では硬口蓋摩擦音の /j/ に対応した.<god> (God), <gear> (year) の如くである.しかし,写字生の中には2つの音価の混用を嫌い,/j/ に <i> を当てたり,二重字 <ge> を用いた者もいた.yoke に相当する語を <ioc>, <geoc> などと綴った例がある.
ノルマン・コンクェストが起こり中英語期に入ると,<<g>> (Carolingian <g>) が一般化した.原則としてその音価は /g/ だったが,「#1651. j と g」 ([2013-11-03-1]) で見たように /ʤ/ にも対応することがあった.一方,<<Ӡ>> (insular <g>) は,従来通り硬口蓋摩擦音 /j/ を表わし続けて残ったが,さらに軟口蓋摩擦音 /x/ をも表わすようになった.ここから,両音を中に含む yogh がその呼び名となった.yogh の字形は <<Ӡ>> (insular <g>) から,より数字の <3> やフランス語式の <z> に近い字形である <<ȝ>> へと発展し,中英語期を通じて広く行われたが,15世紀に各々の音価は <y> や <gh> の文字により置き換えられた.<ȝet> (yet), <ȝou> (you), <niȝt> (night), <liȝt> (light) を参照.
しかし,この <<ȝ>> は,15世紀後半に印刷技術が導入されたときに,Scotland でちょっとしたひねりを加えられた.先に述べたように,その字形はフランス語式の <z> の字形に類似していたため,スコットランドの印刷家たちは見慣れない <<ȝ>> を <<z>> と混同してしまった.そこで,<<ȝ>> と綴るべきところに誤って <<z>> と綴る例が見られるようになる.<zeir> (year), <ze> (ye), <capercailzie> (capercailye) の如くである.固有名詞にもその混同の痕跡を残しており,「#447. Dalziel, MacKenzie, Menzies の <z>」 ([2010-07-18-1]) で見たとおりである.
このように,insular <g> および yogh は,古英語以来,近代の入り口に至るまで,他の複数の文字と複雑に関わり合い,時に混乱を引き起こしながらも活躍した文字として,英語文字史の一時代を飾ったのである.以上,Horobin (86, 91) を参考にして執筆した.
・ Horobin, Simon. Does Spelling Matter? Oxford: OUP, 2013.
2014-07-13 Sun
■ #1903. 分かち書きの歴史 [punctuation][manuscript][writing][grammatology][syntagma_marking][alphabet][distinctiones]
単語と単語の間にスペースを挿入する書記慣習を分かち書きと呼んでいる.本ブログでは,「#1112. 分かち書き (1)」 ([2012-05-13-1]),「#1113. 分かち書き (2)」 ([2012-05-14-1]),「#1114. 草仮名の連綿と墨継ぎ」 ([2012-05-15-1]) の記事で取り上げてきた.分かち書きは,現代英語を含めローマ字を用いる書記体系では当然視されているが,古代ローマのラテン語表記において,分かち書きが習慣的に行われていたわけではない.英語史としてみれば,分かち書きは,古英語期にキリスト教ともにアイルランドの修道僧によってもたらされた慣習であり,その歴史は意外と新しい.Horobin (72) 曰く,
. . . we need to remember that word division and the use of blank spaces between words was a relatively new phenomenon when the Beowulf manuscript was written. In Antiquity manuscripts were written using scriptio continua, a continuous script without any breaks between words at all. The practice of dividing words in the way we do today was introduced by the Irish monks who brought Christianity to the Northumbrians.
古代ローマの伝統的な続け書き (scriptio continua) に代わり,革新的な分かち書き (distinctiones) が最初にラテン語を解さないアイルランド人,そして後にアングロサクソン人によって採用されることになったことは,偶然ではない.日本語母語話者は,分かち書きも句読点もない,ひらがなだけの文章を非常に読みにくく感じるだろうが,日本語を知っている以上,なんとかなる.しかし,日本語を母語としない学習者にとっては,さらに読みにくく感じられるだろう.同様に,ラテン語を母語とするものは scriptio continua で書かれたラテン語の文章を読むのに耐えられたかもしれないが,非母語としてのラテン語の学習者であった古英語期のアイルランド人やイングランド人は苦労を強いられたろう.そこで彼らは,読みやすさと解釈のしやすさを求めて,句読法に一大革新をもたらすことになったのである.この辺りの事情について,Clemens and Graham より2箇所引用する.
In late antiquity, scribes wrote literary texts in scriptura continua (also sometimes called scriptio continua), that is, without any separation between the words. Moreover, often they did not enter any marks of punctuation on the page. In many cases, punctuation was added by the reader, in particular by the reader who had to recite the text aloud. Such punctuation was often only sporadic, inserted at those points where it was necessary to counteract possible ambiguity (for example, when it was not immediately clear where one word ended and another began). (83)
Irish and Anglo-Saxon scribes made notable contributions to the use and development of the distinctiones system. Following their conversion to Christianity in the fifth and sixth through seventh centuries, respectively, the Irish and the Anglo-Saxons copied Latin texts avidly. Because their native languages were not directly related to Latin, these scribes required more visual cues to understand Latin than did Italian, Spanish, or French scribes. It was Irish scribes who were primarily responsible for the introduction of the practice of word separation, a major contribution to what has been called the "grammar of legibility." Once word separation became common, later scribes sometimes "updated earlier manuscripts by placing a punctus between words in texts originally written in scriptura continua. (83--84)
イギリス諸島の修道僧たちは,ラテン語の scriptio continua の読みにくさを疎んじ,自らが書くときには語と語の間にスペースを入れる慣習を確立した.すでに scriptio continua で書かれてしまっている文章については,語と語の間に句読点を挿入することで,読みやすさを確保しようとした.したがって,統語的な区切り ("grammar of legibility") を明確にするために,彼らは分かち書き以外にもいくつかの手段を編み出したのだが,その中でもとりわけ有効な慣習として確立したのが,分かち書きだった.
現在私たちが英語の書き言葉において当然視している分かち書きという慣習は,外国語学習者がその言語の読み書きを容易にするために編み出した語学学習のテクニックに由来するのである.この点では,語句注釈や漢文の訓点とも通じるところがある.
・ Horobin, Simon. Does Spelling Matter? Oxford: OUP, 2013.
・ Clemens, Raymond and Timothy Graham. Introduction to Manuscript Studies. Ithaca & London: Cornel UP, 2007.
2014-07-03 Thu
■ #1893. ヘボン式ローマ字の <sh>, <ch>, <j> はどのくらい英語風か [alphabet][japanese][writing][grammatology][orthography][romaji][j][norman_french][digraph]
昨日の記事 ([2014-07-02-1]) の最後に,ヘボン式ローマ字の綴字のなかで,とりわけ英語風と考えられるものとして <sh>, <ch>, <j> の3種を挙げた.現代英語の正書法を参照すれば,これらの綴字が,共時的な意味で「英語風」であることは確かである.しかし,この「英語風」との認識の問題を英語史という立体的な観点から眺めると,問題のとらえ方が変わってくるかもしれない.歴史的には,いずれの綴字も必ずしも英語に本来的とはいえないからである.
まず,<sh> = /ʃ/ が正書法として確立したのは15世紀中頃のことにすぎない.古英語では,この子音は <sc> という二重字 (digraph) で規則的に綴られていた.この二重字は中英語へも引き継がれたが,中英語では様々な異綴りが乱立し,そのなかで埋没していった.例えば,現代英語の <ship> に対応するものとして,中英語では <chip>, <scip>, <schip>, <ship>, <sip>, <ssip> などの綴字がみられる.このなかで,中英語期中最もよく用いられたのは <sch> だろう.現代的な <sh> は,13世紀初頭に Orm が初めてかつ規則的に用いたが,ある程度一般的になったのは14世紀のロンドンで Chaucer などが <sh> を常用するようになってからである.その後,<sh> は15世紀中頃に広く受け入れられるようになり,17世紀までに他の異綴りを廃用へ追い込んだ.このように,二重字 <sh> の慣習は,英語の土壌から発したことは確かだが,中英語期の異綴りとの長い競合の末にようやく定まった慣習であり,英語の規準となってからの歴史はそれほど長いものではない (Upward and Davidson 157) .
次に,<ch> = /ʧ/ の対応の起源は,疑いなく外来である.この子音は,古英語では典型的に前舌母音の前位置に現われ,規則的に <c> で綴られた.しかし,音韻変化の結果,<c> は同じ音韻環境で /k/ をも表わすようになり,二重の役割をもつに至った.この両義性が背景にあったことと,中英語期に Norman French の綴字慣習が広範な影響力をもったことにより,英語では自然と Norman French の <ch> = /ʧ/ が受け入れられる結果となった.12世紀には,早くも古英語的な <c> = /ʧ/ の対応はほとんど廃れ,古英語由来の単語も以降こぞって <ch> で綴り直されるようになった.二重字 <ch> の受容には,文字と音韻の明確な対応を目指す言語内的な要求と,Norman French の綴字習慣の進出という言語外的な要因とが関与しているのである (Upward and Davidson 100) .
<j> については,「#1828. j の文字と音価の対応について再訪」 ([2014-04-29-1]) と「#1650. 文字素としての j の独立」 ([2013-11-02-1]) で見たように,フランス借用語を大量に入れた中英語期に,やはりフランス語の綴字習慣をまねたものが,後に英語でも定着したにすぎない.実際,<j> で始まる英単語は原則として英語本来語ではない.
以上のように,今では「英語風」と認識されている <sh>, <ch>, <j> も,定着するまでは不安定な綴字だったのであり,当初から典型的に「英語風」だったわけではない.<ch> と <j> の2つに至っては,当時のファッショナブルな言語であるフランス語の綴字習慣の模倣であった.英語が当時はやりのフランス語風を受容したように,日本語が現在はやりの英語風を受容したとしても驚くには当たらないだろう.綴字習慣や正書法も,時代の潮流とともに変化することもあれば変異もするのである.そして,言語接触における影響の方向は,流行や威信などの社会言語学的な要因に依存するのが常である.ローマ字の○○式の評価も,歴史的な観点を含めて立体的になされる必要があると考える.
・ Upward, Christopher and George Davidson. The History of English Spelling. Malden, MA: Wiley-Blackwell, 2011.
2014-07-02 Wed
■ #1892. 「ローマ字のつづり方」 [alphabet][japanese][writing][grammatology][orthography][romaji][language_planning]
「#1879. 日本語におけるローマ字の歴史」 ([2014-06-19-1]) の記事で触れたように,現代の日本語におけるローマ字使用の慣用は,概ね 1954年に政府が訓令として告示した「ローマ字のつづり方」に拠っている.これは様々な議論の末に昭和29年12月に告示されたものであり,それまでの慣用をも勘案して,第一表(=訓令式)と第二表(=ヘボン式と第一表にもれた日本式)を含めた折衷的な提案だった.「まえがき」によれば,第一表を基準としながらも,国際的関係や慣例によって改め難い場合には第二表によってもよいとしている.以下に,2つの表を掲げよう.
| 第1表 | (訓令式) | a | i | u | e | o | |||
| ア | イ | ウ | エ | オ | |||||
| ka | ki | ku | ke | ko | kya | kyu | kyo | ||
| カ | キ | ク | ケ | コ | キャ | キュ | キョ | ||
| sa | si | su | se | so | sya | syu | syo | ||
| サ | シ | ス | セ | ソ | シャ | シュ | ショ | ||
| ta | ti | tu | te | to | tya | tyu | tyo | ||
| タ | チ | ツ | テ | ト | チャ | チュ | チョ | ||
| na | ni | nu | ne | no | nya | nyu | nyo | ||
| ナ | ニ | ヌ | ネ | ノ | ニャ | ニュ | ニョ | ||
| ha | hi | hu | he | ho | hya | hyu | hyo | ||
| ハ | ヒ | フ | ヘ | ホ | ヒャ | ヒュ | ヒョ | ||
| ma | mi | mu | me | mo | mya | myu | myo | ||
| マ | ミ | ム | メ | モ | ミャ | ミュ | ミョ | ||
| ya | (i) | yu | (e) | yo | |||||
| ヤ | イ | ユ | エ | ヨ | |||||
| ra | ri | ru | re | ro | rya | ryu | ryo | ||
| ラ | リ | ル | レ | ロ | リャ | リュ | リョ | ||
| wa | (i) | (u) | (e) | (o) | |||||
| ワ | イ | ウ | エ | オ | |||||
| ga | gi | gu | ge | go | gya | gyu | gyo | ||
| ガ | ギ | グ | ゲ | ゴ | ギャ | ギュ | ギョ | ||
| za | zi | zu | ze | zo | zya | zyu | zyo | ||
| ザ | ジ | ズ | ゼ | ゾ | ジャ | ジュ | ジョ | ||
| da | (zi) | (zu) | de | do | (zya) | (zyu) | (zyo) | ||
| ダ | ジ | ズ | デ | ド | ジャ | ジュ | ジョ | ||
| ba | bi | bu | be | bo | bya | byu | byo | ||
| バ | ビ | ブ | ベ | ボ | ビャ | ビュ | ビョ | ||
| pa | pi | pu | pe | po | pya | pyu | pyo | ||
| パ | ピ | プ | ペ | ポ | ピャ | ピュ | ピョ |
| 第2表 | (標準式)〈ヘボン式〉 | sha | shi | shu | sho | |
| シャ | シ | シュ | ショ | |||
| tsu | ||||||
| ツ | ||||||
| cha | chi | chu | cho | |||
| チャ | チ | チュ | チョ | |||
| fu | ||||||
| フ | ||||||
| ja | ji | ju | jo | |||
| ジャ | ジ | ジュ | ジョ | |||
| (日本式) | di | du | dya | dyu | dyo | |
| ヂ | ヅ | ヂャ | ヂュ | ヂョ | ||
| kwa | ||||||
| クワ | ||||||
| gwa | ||||||
| グワ | ||||||
| wo | ||||||
| ヲ |
「ローマ字のつづり方」の告示に至るまでのローマ字の正書法を巡る議論は熾烈だった.その後も,○○式それぞれの支持者は主張を続けており,論争の火種は今もくすぶっている.昨今は,コンピュータのローマ字漢字変換の普及,日本語の国際化,「#1612. 道路案内標識,ローマ字から英語表記へ」 ([2013-09-25-1]) のような動向がみられることから,ローマ字に関する議論が再燃する可能性がある.
さて,ここではいずれの方式を採るべきかという問題の核心には入り込むことはせずに,英語の正書法に近いとされるヘボン式のどこが英語的なのかを確認するにとどめよう.訓令式と比較するとすぐにわかるが,ヘボン式が体系的に英語風といえるのは,シャ行,チャ行,ジャ行である.訓令式の <sya>, <syu>, <syo>, <tya>, <tyu>, <tyo>, <zya>, <zyu>, <zyo> は,ヘボン式では <sha>, <shu>, <sho>, <cha>, <chu>, <cho>, <ja>, <ju>, <jo> に対応する.また,これと関連して,体系的というよりは個別的だが,訓令式 <si>, <ti>, <zi> は,ヘボン式 <shi>, <chi>, <ji> に対応する.ほかにヘボン式には <fu> や <tsu> もあるが,ヘボン式の体系的かつ顕著な「英語風」は,とりわけ <sh>, <ch>, <j> の3種の綴字といってよいだろう.しかし,実は,これらの綴字を「英語風」と認識するのは,あくまで近現代の発想である.英語史の観点からみると,これらは必ずしも典型的に「英語風」といえるものではない.これについては,明日の記事で.
2014-06-19 Thu
■ #1879. 日本語におけるローマ字の歴史 [alphabet][japanese][writing][grammatology][orthography][romaji][language_planning]
ローマン・アルファベット誕生の歴史については,アルファベットの派生を扱った「#423. アルファベットの歴史」 ([2010-06-24-1]),「#1822. 文字の系統」 ([2014-04-23-1]),「#1834. 文字史年表」 ([2014-05-05-1]),「#1849. アルファベットの系統図」 ([2014-05-20-1]),「#1853. 文字の系統 (2)」 ([2014-05-24-1]) の記事で概観してきた.ラテン語を書き表すために発展したローマン・アルファベットは,その後,西ヨーロッパを中心に広がり,さらに世界史の経緯とともにヨーロッパ外へ拡散し,「#1861. 英語アルファベットの単純さ」 ([2014-06-01-1]) も相まって,現在では世界化している(関連して「#1838. 文字帝国主義」 ([2014-05-09-1]) を参考).日本語におけるローマ字の使用は室町時代後期に遡るが,これもローマン・アルファベットの世界的拡散の歴史の一コマである.以下,日本語におけるローマ字の歴史を,古藤 (118--24) に拠って要約しよう.
日本に初めてローマ字が伝えられたのは,16世紀後半,室町時代の末である.キリスト教の宣教師とともにもたらされた.1590年(天正18年),イタリア人のワリニャーニ (1539--1609) が島原に活字印刷機をもたらし,それでローマ字による初の書『サントスの御作業の内抜書き』 (1591) を刊行した.続いて,長崎,天草,京都などで数多くのローマ字書きの「キリシタン資料」が出版されることになったが,『ドチリナ・キリシタン(吉利支丹教義)』 (1592) などでは,ポルトガル語の発音に基づいて日本語が表記されており,当時の日本語の発音を知る上で貴重な資料となっている.
続く江戸時代には鎖国が行われ,一時期,ローマ字の普及が妨げられることとなった.その間に,新井白石 (1657--1725) が1708年(宝永5年)に屋久島に漂流したローマ人宣教師シドッチを訊問してローマ字その他の知識を得て,洋語に対して初めて一貫してカタカナを当てた『西洋紀聞』を世に送ったが,日本におけるローマ字の発展に直接は貢献しなかった.江戸時代後期には蘭学が盛んになるとともにオランダ語式のローマ字が用いられ,やがてドイツ語式やフランス語式も現われたが,明治維新のころには英語式が最も優勢となっていた.英語式ローマ字が一般化したのは,1767年(慶応3年)にアメリカの眼科医・宣教師のヘボン (James Curtis Hepburn; 1815--1911) が著わした日本初の和英辞典『和英語林集成』に負うところが大きい.この第3版で採用されたローマ字表記が「ヘボン式(標準式)」の名で広く普及することになった.
明治時代になると,ローマ字を国字にしようという運動が高まったが,英語表記に近いヘボン式(標準式)をよしとせず,日本語表記に特化した「日本式」こそを採用すべしと田中館愛橘 (1856--1952) が提唱するに至り,両派閥の対立が始まった.この対立はその後も長く続くことになり,大正時代には文部省,外務省などがヘボン式を,陸海軍,逓信省などは日本式をそれぞれ支持した.政府は統一を目指して臨時ローマ字調査会を組織し,6年の議論の末,1937年に日本式を基礎にヘボン式を多少取り入れた「訓令式」を公布した.
だが,議論は収まらず,1954年に,政府は第一表(=訓令式)と第二表(=ヘボン式と第一表にもれた日本式)を収録した「ローマ字のつづり方」を訓令として告示することになった.すでに駅名やパスポートの人名に採用されていたヘボン式にも配慮しつつの折衷的な方式だったが,その後,ある程度の承認を得たとはいえるだろう.現在の教育では,ローマ字は小学校4年生で学ぶことになっている.
町の看板にローマ字があふれ(「#1746. 看板表記のローマ字」 ([2014-02-06-1])),コンピュータのローマ字漢字変換が普及し,日本語の国際化も進んでいる現在,新たな観点から日本語におけるローマ字使用の問題を論じる時期が来ているように思われる.
・ 古藤 友子 『日本の文字のふしぎふしぎ』 アリス館,1997年.
2014-06-01 Sun
■ #1861. 英語アルファベットの単純さ [writing][grammatology][alphabet][orthography][diacritical_mark]
「#423. アルファベットの歴史」 ([2010-06-24-1]),「#1822. 文字の系統」 ([2014-04-23-1]),「#1834. 文字史年表」 ([2014-05-05-1]),「#1849. アルファベットの系統図」 ([2014-05-20-1]),「#1853. 文字の系統 (2)」 ([2014-05-24-1]) でアルファベットの派生を見てきた.通常の系統図ではローマン・アルファベットあるいはラテン文字以降の派生は省略されることが多いが,実際には英語アルファベット,フランス語アルファベット,ドイツ語アルファベットなど言語ごとに区別されてゆくし,英語でも古英語アルファベット,中英語アルファベット,現代英語アルファベットはそれぞれ異なる.
これらの様々な派生アルファベットのなかでも,現代英語アルファベットは文字体系としては非常に単純な部類に入る.幾何学的に単純な字形の26文字のみからなり,特殊な発音区別符(号) (diacritical mark; cf. 「#870. diacritical mark」 ([2011-09-14-1])) も原則として用いられない.確かに,文字の組み合わせ方に関する規則,すなわち綴字の正書法は複雑だし,大文字と小文字の区別や句読法の規範もいくらかはある.また,印刷では分綴 (hyphenation) や合字 (ligature) などを考慮する必要もある.運用上は必ずしも単純な文字体系とはいえないということは事実だろう.しかし,種々の規則を考慮に入れても,古今東西の主要な文字体系と比較すれば,現代英語アルファベットという文字体系はやはり単純と言わざるをえない.
この単純さを,コンピュータ時代に適応させるべくさらに単純化し,標準化した結晶ともいえるのが,ASCIIコード (American Standard Code for Information Interchange) である.もともとはアメリカの規格だが,現在では同じ内容の ISO 646 IRV (International Reference Version) に裏付けられた国際規格である.太田 (45--46) によれば,ASCII の単純さは以下の諸点に帰せられる.
(1) 固定長で,各文字を前後関係に関係なく直接指定できる
・ 文字の種類がバイトの大きさに比べて少ない
・ 横書き,左端から右に書くだけで,双方向性問題がない
・ 文字の図形表現が前後関係で変形しない(リガチャーがない)
(2) 大文字,小文字の対応が規則的ではっきりしている
・ 飾り文字がない
(3) 大文字,小文字の区別をするかしないかという場合を除いて,文字同定が完璧で,字形のゆれの範囲に,徹底した共通認識がある
(4) 大文字,小文字の区別をするかしないかを除いて,異なる文字の組み合わせを同じ文字列と考える必要がない
(5) 文字幅が一定でかまわない
(6) デフォールトで利用できる
・ 広く普及した国際標準である
ASCII の単純さは,しかし,その主たる構成要素である現代英語アルファベットの単純さがそのまま反映されたものというよりは,それが電子処理にふさわしく一段と単純に整備された結果と考えるべきだろう.このように,現代英語アルファベットと ASCII 文字セットとは一応のところ区別してとらえる必要はあるが,両者のもつ単純さの根っこは,当然つながっている.
文字コードを巡る現代の諸問題は,技術者任せにしておくわけにはいかず,言語学の1分野としての文字学が積極的に扱うべき領域である.そこには,古今東西の文字の記述の問題,文字の理論の問題,(多言語主義はもとより)多文字主義の問題,文字帝国主義の問題 ([2014-05-09-1]) ,書き言葉と話し言葉の峻別の問題などが密接に関わってくる.
・ 太田 昌孝 『いま日本語が危ない 文字コードの誤った国際化』 丸山学芸図書,1997年.
2014-05-24 Sat
■ #1853. 文字の系統 (2) [writing][grammatology][alphabet][family_tree][hieroglyph]
「#423. アルファベットの歴史」 ([2010-06-24-1]),「#1822. 文字の系統」 ([2014-04-23-1]),「#1834. 文字史年表」 ([2014-05-05-1]),「#1849. アルファベットの系統図」 ([2014-05-20-1]) に引き続き,もう1組の文字の系統図を示したい.先の記事でも述べたように,比較言語学の成果として描かれる言語の系統図と同様に,比較文字学の成果としての文字の系統図も,一つの仮説である.もちろん大筋で合意されている部分などはあるが,極端に言ってしまえば,論者の数だけ系統図があるということにもなる.したがって,系統図のようなものは複数見比べる必要がある.今回は,西田 (232--34) による1組の系統図を参照する.以下の4つの系統が区別されている.年代は暫定的なものである.
(1) エジプト象形文字が表音字形として発展した系統

(2) シュメール象形文字が象形字形を保存した系統
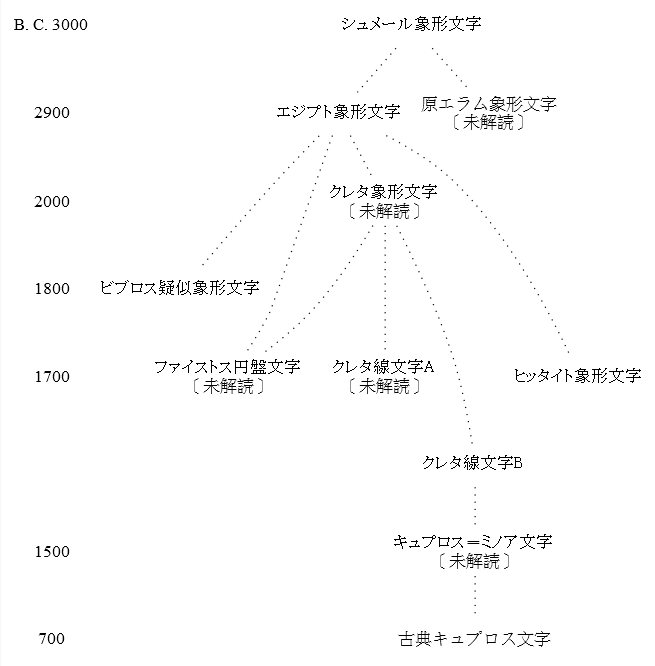
(3) シュメール楔形文字の系統
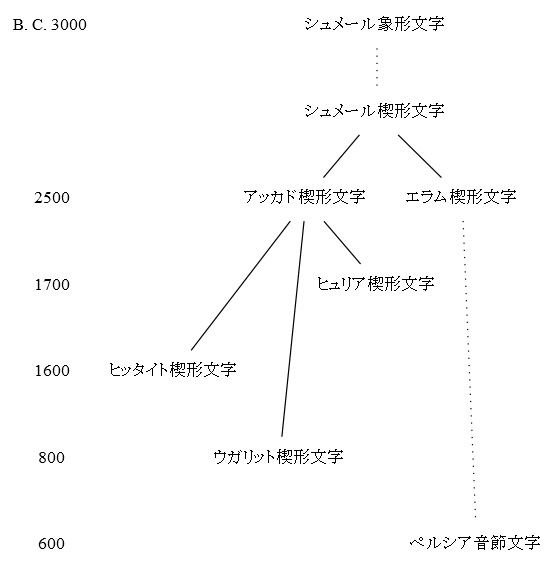
(4) 東アジアの象形文字の系統
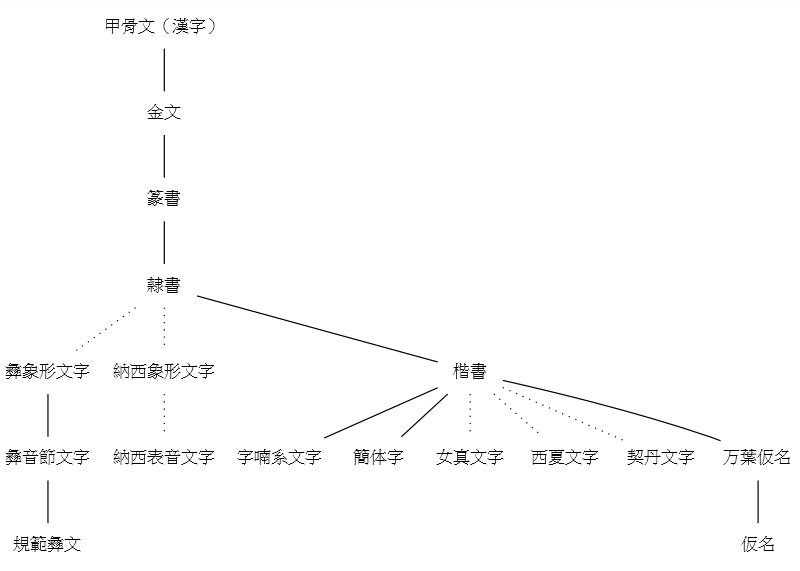
・ 西田 龍雄(編) 『言語学を学ぶ人のために』 世界思想社,1986年.
2014-05-20 Tue
■ #1849. アルファベットの系統図 [writing][grammatology][alphabet][runic][family_tree][neogrammarian][comparative_linguistics]
「#423. アルファベットの歴史」 ([2010-06-24-1]),「#1822. 文字の系統」 ([2014-04-23-1]),「#1834. 文字史年表」 ([2014-05-05-1]) の記事で,アルファベットの歴史や系統を見てきたが,今回は寺澤 (376) にまとめられている「英語アルファベットの発達概略系譜」を参考にして,もう1つのアルファベット系統図を示したい.言語の系統図と同じように,文字の系統図も研究者によって細部が異なることが多いので,様々なものを見比べる必要がある.
以下の図をクリックすると拡大.実線は直接発達の関係,破線は発達関係に疑問の余地のあることを示す.
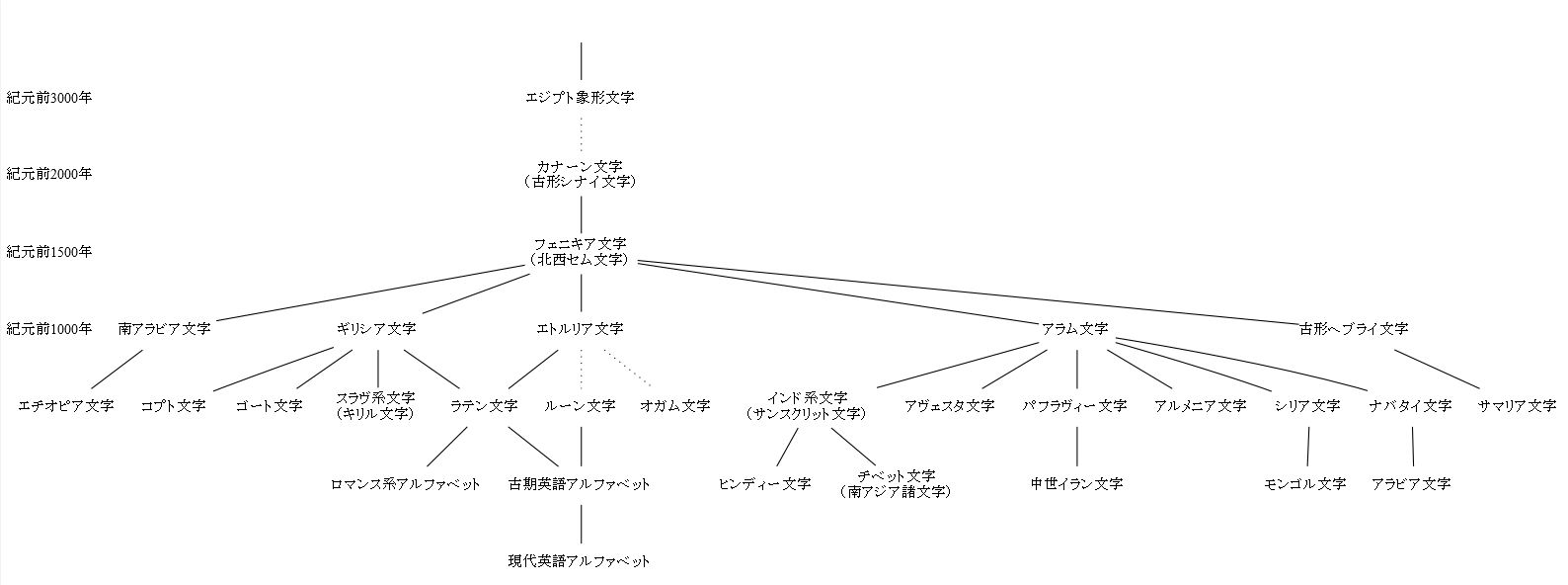
文字 (writing) の系統図を読む際には,印欧語族など言語そのもの (speech) の系統図を読む場合とは異なる視点が必要である.まず,speech の系統図の根幹には,青年文法学派 (neogrammarian) による「音韻変化に例外なし」の原則がある.そこには調音器官の生理学に裏付けられた自然な音発達という考え方があり,その前提に立つ限りにおいて,系統図は科学的な意味をもつ.一方,文字の系統図の根幹には,「原則」に相応するものはない.例えば筆記に伴う手の生理学に裏付けられた字形の自然な発達というものが,どこまで考えられるか疑問である.筆記具による字形の制約であるとか,縦書きであれば上から下へ向かうであるとか,何らかの原理はあるものと思われるが,音韻変化におけるような厳密さを求めることはできないだろう.
2つ目に,「#748. 話し言葉と書き言葉」 ([2011-05-15-1]) を含む ##748,849,1001,1665 の記事で話題にしてきたように,話し言葉(音声)と書き言葉(文字)には各々の特性がある.音声は時間と空間に限定されるが,文字はそれを超越する.文字は,借用や混成などを通じて,時間と空間を超えて,ある言語共同体から別の言語共同体へと伝播してゆくことが,音声よりもずっと容易であり,頻繁である.とりわけ音素文字であるアルファベットは,あらゆる話し言語に適用できる普遍的な性質をもっているだけに,言語の垣根を軽々と越えていくことができる.この点で,文字の系統,あるいは文字の発達や伝播は,人間が生み出した道具や技術のそれに近い.文化ごとの自然な発達も想定されるが,一方で他の文化からの影響による変化も想定される.
3つ目に,音声に基づく系統関係は音韻変化のみを基準に据えればよいが,文字,とりわけ音素文字においては,字形という基準のほかに,字形と対応する音素が何かという基準,すなわち文字学者の西田龍雄 (223) がいうところの「文字の実用論」の考慮が必要となる.字形と実用論は独立して発達することも借用することもでき,その歴史的軌跡を表わす系統図は,音声の場合よりも,ややこしく不確かにならざるをえない.
比較言語学と平行的に比較文字学というものを考えることができるように思われるが,素直に見えるこの平行関係は,実は見せかけではないか.比較文字学には,独自の解くべき問題があり,独自の方法論が編み出されなければならない.
・ 寺澤 芳雄(編) 『辞書・世界英語・方言』 研究社英語学文献解題 第8巻.研究社.2006年.
・ 西田 龍雄(編) 『言語学を学ぶ人のために』 世界思想社,1986年.
2014-05-09 Fri
■ #1838. 文字帝国主義 [linguistic_imperialism][alphabet][grammatology][sociolinguistics]
「#1606. 英語言語帝国主義,言語差別,英語覇権」 ([2013-09-19-1]) や「#1607. 英語教育の政治的側面」 ([2013-09-20-1]) ほか linguistic_imperialism の各記事で,言語帝国主義(批判)の話題を取り上げてきた.言語帝国主義というときの言語とは,書き言葉であれ話し言葉であれソシュール的な langage を指すものと考えられるが,この概念は langage とは異なる次元にある文字体系にも応用できるのではないか.英語帝国主義論というものがあるのならば,アルファベット帝国主義論,ローマ字帝国主義論なるものもあるはずではないか.
これまでカルヴェのいくつかの著書を通じて,文字と権力にかかわる社会言語学的な議論には接していたが,彼の『文字の世界史』を読み,積極的な文字帝国主義論の立場を知った.近年アフリカで多数の文字が生まれている状況を概説した後で,カルヴェ (199--201) は次のように述べている.
一つだけはっきりしているのは,近年アフリカでこのように多数の文字が生まれたのは,アフリカがおかれた政治的状況によるということで,大半はイスラム教化や植民地化の結果,自分たちの言語もアラビア語やフランス語,英語,ポルトガル語と同じように文字をもつことができる,と誇示することが最大の目的であったと考えられる.アフリカの住民は文字という概念を独自に得たのではなく,他の文字を借用するか模倣したのである.この意味でブラック・アフリカの言語がことごとくローマ字で書かれているという事実はよく考える必要がある.つまり独自の文字を作り出そうという試みの背景にナショナリズムや民族主義があるとすれば,アフリカにおけるローマ字の制覇は客観的に見てローマ字の方が優っているということではなく(因みにデビッド・ダルビーはローマ字には欠陥があり,新たな文字を加えるなど修正を加えることが望ましいとしている),アフリカとそれ以外の地域の間に認められる力関係がこの場合は文字に現れていると見るべきなのである.もっと端的にいえば,現地で独自に作った文字がローマ字に優っているというのではなく,言語戦争があるとすれば文字戦争もあり,アフリカの状況はその好例だという事である.各地で独自の文字を作ろうという試みがあったのは改宗や植民地化でアフリカに文字が持ち込まれた結果だが,アフリカ諸国にとっての最大の課題はどれを公式文字として採用するかということだった.その際ローマ字の方が優れているという権力関係の存在が容認されたのではないだろうか.「はじめに」でも書いたように,アルファベットが文字として絶対のものではなく,漢字使用者が10億人以上いるのは事実だとしても,アフリカの状況が示しているのは,第一に今日文字を持たない言語を表記しようとするときまず考えられるのはローマ字であるということ,第二に次章で見るアラビア数字と同じで,世界に数多くあるアルファベットのうち最も勢力があるのはローマ字であるということである.そして見かけ上恩恵的と思われるこの記号学上の支配は,西欧が全世界に対して握っている権力の現われであることに変わりはないのである.
カルヴェが文字の権力について力を込めて論じているもう1つの箇所がある (238--39) .
メソポタミアの楔形文字,古代中国の甲骨文字,中米の表音表意文字などが示唆するように,初期の文字は物語や詩歌を著すためではなく,税収などの会計や契約を記録し,法令を伝達・保存し,あるいは重要人物の名と功績を墓に刻むといった役割,さらには占いや儀式をとり行うといった宗教的役割を果たしていた.つまり文字と権力は密接な関係にあるのである.
社会学者で言語学者でもあったマルセル・コーエンは「一般的にいって,文字と呼べるものはどれも都市で生まれているが,これは都市における生産,輸送といった経済活動が複雑であると同時に,都市の人間関係が複雑なことが要因である」と書いている.文字が「都市的」な性質を持つという指摘は重要で,というのは権力が生まれるものもやはり都市なのである.肝心なのは,文字は発生の段階ではあくまで国家運営の原型に相当する極めて実用的な機能を担うもので,詩歌,伝承,工芸といった社会遺産を口承に代わって記録するようになるのはずっと後のことに過ぎないということである.文字と権力の関係にはさらに支配階級の社会的地位という問題がかかわって来る.例えば楔形文字についてJ=M・デュランが,「楔形文字は余りにも複雑で,習得に膨大な時間を要する.楔形文字が民衆に普及せず,一握りの専門家だけが使っていたと考えられる理由はそこにある」としているのは妥当だが表面すぎる見方である.楔形文字がごく一部の階級から外に出なかったのは,読み書きが複雑だということもあるだろうが,同時に文字の持つ権力を独占しようという意図の現われと見ることもできるからである.重要なのは,楔形文字や象形文字といった発生期の文字が習得に多大な時間を要するということは,習得すれば特権が手中にできるということであり,さらには文字そのものが特定の階級だけに所属するものであるという事である.同時に,文字の権力を握っているものはその独占に努めこそすれ,簡略化による文字の民主化や,教育による普及は思いもつかなかったに違いないと考えられるのである.
このことはなにも4000年前の古代文字に限ったことではない.今日でも行政が文字に関わる場合,表面上は単に国語表記の問題のように見えるが,実はそれ以外の意図があることは見逃せない.例えば旧ソヴィエト政府が連邦内の言語に対しローマ字化を経て段階的にキリル文字化を断行したのはロシア帝国主義の記号学的表現であり,中国が漢字の簡略化を推進したのも明らかに文字の民主化という政治的方針に基づくものである.現在各国でローマ字化が進んでいるアフリカは旧宗主国の言語が官庁用語という国が大多数を占めるが,これは現地語を駆逐しようという,いわば「食言的」意図の現われである.要するに文字の問題は本書で述べたような歴史的考察の対象にもなるが,同時に社会的考察の対象にもなるのである.文字は宗教も含めた権力を行使するために作り出され,次の段階では権力を担うものに転化するが,これは今日でもある程度まで言えることである.
カルヴェの著書を監訳した文字学者の矢島は,別に監修した『文字の歴史』の序文 (4) で,多文字教育の必要性を訴えている.上記の引用を読んだあとでは,この必要性は納得しやすいのではないか.
世界は日ごとに“情報化”しつつあり,日本はますます“国際化”しつつある.大国のみならず中・小国の民族文化・異文化を知る必要は増えるばかりだ.情報の伝達・交換は,ある程度までは科学技術が助けてくれるかもしれない――テレビの文字放送(広義での),多機能的ワープロ(パソコン),今後さらに改良されるであろう翻訳・字訳・読み取り機などなど.しかし文化記号としての文字をわれわれ自身が学ぶことが,それぞれ異なる文化の伝統をもつ民族間の理解を深める鍵ではなかろうか.そのためには,多言語教育とともに多文字教育が必要であり,言い換えれば国際的な“識字”運動を進めるべきではないだろうか.
・ ルイ=ジャン・カルヴェ 著,矢島 文夫 監訳,会津 洋・前島 和也 訳 『文字の世界史』 河出書房,1998年.
・ ジョルジュ・ジャン 著,矢島 文夫 監修,高橋 啓 訳 『文字の歴史』 創元社,1990年.
2014-05-08 Thu
■ #1837. ローマ字とギリシア文字の字形の差異 [alphabet][greek][latin][grammatology][map][dialect]
「#1832. ギリシア・アルファベットの文字の名称 (1)」 ([2014-05-03-1]) の記事で,ギリシア・アルファベット (Greek alphabet) の一覧を示した.ローマン・アルファベット (Roman alphabet) と比べると,文字数,字形,音価において若干の違いが見られるが,この違いの背後にどのような事情があったのだろうか.
まず,一般論を述べておくと,ある言語を表記する文字体系を別の言語へ移植・適用するときには,決まって多少の改変が加えられる.とりわけ,音韻体系をもっともよく反映するアルファベットのような音素文字であれば,なおさらである.まったく同じ音韻体系をもっている言語(方言)はないといってよく,既存の文字セットを移植するときには,必ずいくつかの文字の過剰と不足が生じる.そこで,過剰な文字を新しい音価に割り当てたり,新しい文字を創り出すなどの手段が講じられる.しかし,文字には保守的な側面もあり,総文字数を大きく変化させるような事態には至らないことが多い.アルファベット史をみても,およそ20?40文字の範囲に収まっているようである.ギリシア文字→エトルリア文字→ローマ字とアルファベットが伝播してゆく過程でも多少の改変と本質的な不変が見られるが,これは文字の伝播においては普通に観察されることである.
次に具体論に移ろう.古代におけるギリシア・アルファベットは一枚岩ではなく,多数の方言的変種が存在した.これは,古代ギリシア語の話し言葉が多種多様に方言分化していたのと呼応する.よく言われるように,古代ギリシアは諸都市の独立と自足を特徴とし,後のローマとは対照的に統一国家を生み出すことはなかった.話し言葉や文字体系の方言化も,この独立精神と無関係ではない.話し言葉の方言については「#1454. ギリシャ語派(印欧語族)」 ([2013-04-20-1]) で触れたので繰り返さないが,アルファベットの変種については,細かく分類すれば4種類が区別された.ドイツの学者 Kirchhoff による分類で,地図を4種類の色に塗り分けてその分布を示したことにちなみ,それぞれ色の名前で呼称される慣習がある.Green, Red, Dark blue, Light blue の4変種だ.
(1) Green alphabet は,Crete や近隣の島々で行われた変種で,フェニキア・アルファベット (Phoenician alphabet) への追加文字(他変種におけるΦ,Χ,Ψ)を欠いているのが特徴である.
(2) Red alphabet は,Euboea や Laconia で行われた変種で,Φ [ph], Ψ [kh] の追加文字を加えた.また,ΧはΞに代わって [ks] の音価を表わした.Euboea の都市の名を取って Chalcis 型あるいは西方型の変種と呼ばれる.
(3) Dark blue alphabet は,Ionia, Corinth, Rhodes で広く行われた変種で,Φ [ph], Χ [kh], Ψ [ps] の追加文字を加えた.この Ψ [ps] は,Red alphabet のΨ [kh] と音価が異なることに注意.Ionia 型あるいは東方型の変種と呼ばれる.
(4) Light blue alphabet は,Attica で行われた変種である.Φ [ph], Χ [kh] を追加した.Ionia 型の亜種といってよいが,後に標準的な変種となった.
これを2つに大別すれば,Euboea の Chalcis を中心とする西方型と Ionia の Miletus を中心とする東方型に分けられるだろう.フェニキアの商人が去った後,エーゲ海は Chalcis と Miletus の独占舞台となり,両都市は商業的・植民的覇権を争った.Chalcis はトラキアやイタリアに植民して,エトルリア語経由でラテン語に西方型アルファベットを伝えた.一方,Miletus は黒海沿岸地方に植民し,古典ギリシア・アルファベットを確立し,さらにキリル文字などのスラヴ系アルファベットの発展を促した.
ローマン・アルファベットとギリシア・アルファベットの若干の違いは,もととなる変種の違いに起因するということがわかるだろう.大文字でいえば <C> と <Γ>,<D> と <Δ>, <L> と <Λ>,<X> と <Ξ>,<S> と <Σ> の字形の違い,また上述のように <Χ> の音価の [ks] と [kh] の違い,さらに <Η> の音価の [h] と [eː] の違いは,以上の事情による.
参考までに現代ギリシアの地図を掲げておこう.
以上,田中 (57--60) および Comrie et al. (183--87) を参照して執筆した. *
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
・ Comrie, Bernard, Stephen Matthews, and Maria Polinsky, eds. The Atlas of Languages. Rev. ed. New York: Facts on File, 2003.
2014-05-07 Wed
■ #1836. viz. と「流石」 [latin][grapheme][grammatology][japanese][kanji][spelling_pronunciation_gap]
昨日の記事「#1835. viz.」 ([2014-05-06-1]) に引き続き,英語で namely と読み下す viz. について.今回は,文字論の立場から論じる.
英語において viz. と表記される語の構成要素である3文字(省略を表わす period を除く)は,当然ながらいずれもアルファベット文字(=表音文字)である.しかし,個々の文字で考えても,3文字が合わさった全体で考えても,まるで /neɪmli/ の発音を示唆するところがない.<viz.> はこの点において非表音的である.意味についても同様に,字面を個々に考えても全体で考えても,とうてい「すなわち」の意味は浮かび上がってこない.<viz.> はこの点において非表意的である.つまり,英語の <viz.> は,語源形であるラテン語 videlicet を想起するまれな場合を除き,通常は音も意味も示唆しない.
にもかかわらず,<viz.> は英語の副詞 namely と同等であるとして,英語使用者の意識のなかでは密接に結びついている.言い換えれば,<viz.> は,3文字全体としてむりやりに namely を表語している.<viz.> の綴字は,表音 (phonographic) でも表意 (ideographic) でもなく,表語 (logographic) の機能を果たしているのであり,記号論の用語を使えば,<viz.> が指し示しているものは,namely という記号 (signe) の能記 (signifiant) でも所記 (signifié) でもなく,namely という記号そのものである,ということになる.むりやりの結びつきであるから,英語使用者は,この <viz.> = namely の関係を暗記しなければならない.<viz.> のもつこの表語機能は,「#1042. 英語における音読みと訓読み」 ([2012-03-04-1]) で挙げた,<e.g.> (for example), <i.e.> (that is) にも見られる.
そこで,典型的に表語文字といわれる漢字を使いこなす日本語において,これと比較される類例があるだろうかと考えてみた.しかし,案外と見つからないものだ.漢字は確かに表語的ではあるが,同時に表意機能も果たすのが普通だし,形声文字の場合には表音機能も備わっている.英語の <viz.> の場合のように,発音も意味も示唆すらしないという徹底的な例は,なかなかない.
頭をひねってやっと思いついたのが,熟字訓として /さすが/ と読ませる <流石> という例だ.<流> も <石> も,さらにはそれを組み合わせた <流石> 全体も,なんら /さすが/ の発音を示唆するところがないし,「何といってもやはり」の意味を匂わせるところがない.<流石> は表音的でも表意的でもなく,副詞「さすが」をむりやりに表語しているのである.<viz.> と <流石> の唯一の差異は,前者の構成要素であるアルファベット文字が本質的に表音的であるのに対して,後者の構成要素である漢字は本質的に表語・表意的であるという点だろう.しかし,いずれの表記も全体としては結局のところ非表音的かつ非表意的であり,発現している機能はもっぱら表語機能である点では同じだ.
一見すると,「流石」 に代表される熟字訓は,純粋な表語機能(=非表音かつ非表意かつ表語)の好例を提供してくれそうだが,<私語> /ささやき/,<五月雨> /さみだれ/,<海苔> /のり/,<紅葉> /もみじ/ などでは,漢字の組み合わせが意味を匂わせてしまっており(しかも美しく詩的に),<viz.> = namely の純粋な表語機能には達していない.むしろ英語はアルファベットという表音文字体系をベースに置いている言語であるからこそ,<viz.> = namely のような例において,稀ではあるが純粋な表語機能を獲得し得たのかもしれない.文字論の観点からは,この逆説は興味深い.
なお,<流石> を /さすが/ と訓読するのは,以下の故事によるものとするのが通説である(『学研 日本語「語源」辞典』より).
中国,西晋の国の孫楚が「石に枕し,流れに漱ぐ」というべきところを,誤って「石に漱ぎ,流れに枕す」と言ってしまった.これを聞いた親友の王済が「流れは枕にできないし,石では口をすすげない」と言ってからかうと,孫楚は「流れを枕にするのは耳を洗うためであり,石に漱ぐというのは歯を磨くためである」と言って言い逃れたという.この故事を「さすがにうまいこじつけだ」と評し,「流石」の字が当てられたとする説がある.
上の議論では,一般の日本語話者がこの故事を知らない,あるいは普段は特に意識せずに,<流石> = /さすが/ の関係を了解していることを前提とした.故事を意識していれば,<流石> が非常に間接的ながらも何らかの表意機能をもっていると主張できるかもしれないからである.
文字の表語機能については,「#1332. 中英語と近代英語の綴字体系の本質的な差」 ([2012-12-19-1]),「#1386. 近代英語以降に確立してきた標準綴字体系の特徴」 ([2013-02-11-1]),「#1655. 耳で読むのか目で読むのか」 ([2013-11-07-1]),「#1829. 書き言葉テクストの3つの機能」 ([2014-04-30-1]) を参照.
2014-05-06 Tue
■ #1835. viz. [latin][loan_word][abbreviation][grapheme][grammatology][spelling_pronunciation_gap]
viz. は "namely" (すなわち)の意を表わす語で,/vɪz/ と読まれることもあるが,普通は namely /ˈneɪmli/ と発音される.もっぱら書き言葉に現れるので,ある種の省略符合と考えてよいだろう.もとの形は,英語でもまれにそのように発音されることはあるが, videlicet /vɪˈdɛləsɪt/ という語で,これはラテン語で「すなわち,換言すると」を意味する vidēlicet に由来する.このラテン語自体は,vidēre licet (it is permitted to see) という慣用表現のつづまったものである.OED によると,英語での初出は videlicet が1464年,省略形の viz. がa1540年である.
viz. の現代英語における用例をいくつか見てみよう.とりわけイギリス英語の形式張った書き言葉において,より明確に説明を施したり,具体例を列挙したりするのに用いられる.
・ four major colleges of surgery, viz. London, Glasgow, Edinburgh and Dublin
・ We both shared the same ambition, viz, to make a lot of money and to retire at 40.
・ The school offers two modules in Teaching English as a Foreign Language, viz. Principles and Methods of Language Teaching and Applied Linguistics.
関連して,ラテン語 scīre licet (it is permitted to know) のつづまった scilicet /ˈsɪləˌsɛt/ とその略形 scil. sc. も,英語でおよそ同じ意味に用いられる.
それにしても,videlicet が viz. と略されるのはなぜだろうか.中世ラテン語の写本では,<z> の文字は,-et, -(b)us, -m などの省略記号として一般に用いられていた.そこで,<z> = <et> と見立て,表記上 <vi(delic)z> とつづめたのである.古くは,<vidz.>, <vidzt>, <vz.> などとも表記された.ラテン語では et は "and" を意味するのでこの <z> の略記は多用され,古英語や中英語の写本でもそれをまねて and の語(あるいはその音価)に代わって頻繁に現れた.実際の <z> の字形は現在のものとは異なり,数字の <7> に似た <⁊ > という字形 (Unicode ⁊) で,この記号は Tironian et と呼ばれた.古代ローマのキケロの筆記者であった Marcus Tullius Tiro が考案した速記システム (Tironian notes, or notae Tironianae) で用いられた速記記号の1つである.これが,後に字形の類似から <z> に置き換えられるようになった.Irish や Scottish Gaelic では現在も Tironian et が使用されるが,英語では viz. にそのかすかな痕跡を残すのみである.
2014-05-05 Mon
■ #1834. 文字史年表 [grammatology][history][timeline]
ここ数日間,アルファベットを中心に文字の話題に集中してきた.文字に関連する記事は,grammatology, graphemics, grapheme, alphabet, runic, writing などで書いてきた.中心的な記事を抜き出すと,例えば次のようなものがあった.
(1) 「#41. 言語と文字の歴史は浅い」 ([2009-06-08-1])
(2) 「#751. 地球46億年のあゆみのなかでの人類と言語」 ([2011-05-18-1])
(3) 「#1368. Fennell 版,英語史略年表」 ([2013-01-24-1])
(4) 「#1544. 言語の起源と進化の年表」 ([2013-07-19-1])
(5) 「#423. アルファベットの歴史」 ([2010-06-24-1])
(6) 「#490. アルファベットの起源は North Semitic よりも前に遡る?」 ([2010-08-30-1])
(7) 「#1006. ルーン文字の変種」 ([2012-01-28-1])
(8) 「#1005. 平仮名による最古の「いろは歌」が発見された」 ([2012-01-27-1])
(9) 「#422. 文字の種類」 ([2010-06-23-1])
(10) 「#1822. 文字の系統」 ([2014-04-23-1])
今回は,カルヴェ (241--42) による文字史略年表を掲げよう.(1)--(4) などの記事で掲げた年表とは年代や順序が若干異なるところもあるが,とりわけ紀元前において文字の成立年代を特定することの困難は勘案すべきだろう.
前30000年頃 [陰画手像] 前4000年頃 スサ(現イラン)で土器に書いた文字が現れる 前3300年頃 メソポタミア南部で絵文字が現れる 前3100年頃 エジプト聖刻文字成立 前2700年頃 シュメールの楔形文字成立 前2500年頃 スサで楔形文字が原エラム文字にとって代る 前2300年頃 インダス川流域で「原インド文字」が現れる 前2200年頃 プズル・インチュチナク王の原エラム文字碑文 前2000年頃 シュメールの首都ウル陥落.以降,メソポタミアではアッカド語が共通語として使用される 前1600年頃 原シナイ文字 地中海で線文字A成立 前1300年頃 ラス・シャムラ(現シリア)のウガリット文字 古代中国で甲骨文字成立 前1000年頃 フェニキア文字成立 同じ頃アラム文字,古ヘブライ文字成立 前8世紀 ギリシア文字,エトルリア文字,イタリア文字成立 前6世紀 ローマ字成立 前3世紀 カロシュティー文字,ブラーフミ文字成立 前2世紀 ヘブライ文字成立 前1--1世紀 中国で漢字が完成 1世紀 最古のルーン文字碑文 3世紀 コプト文字,原マヤ文字成立 4世紀頃 漢字,朝鮮半島に伝来 グプタ文字成立 ゴート文字,アラビア文字成立 5世紀頃 漢字,日本に伝来.オガム文字成立 アルメニア文字,グルジア文字成立 7世紀 チベット文字成立 8世紀 ナーガリー文字成立 9世紀 グラゴール文字成立(その後キリル文字となる) 11世紀 ネパール文字成立
人類最古の文字がいつ発生したかを明言することはできない.今なお未発見の文字は眠っているだろうし,文字の書かれた材質ゆえに永遠に失われしまったものも多くあるだろう.カルヴェ (23) は,楔形文字の研究者,ジャン=マリ・デュランの次の記述を引いている.
「それゆえ文字が地上のどこに生まれたかなどと詮索するのはむなしいことである.ある社会が象徴的事物を描きつつ一連の物質的記号を残そうとし,媒体を選び,そこに表記する,こういった社会がある限り文字出現の地点はどこにもあるのである.いくつもの社会が原始的媒体(洞窟壁画)とか保存不能の媒体(粘土以外のもの)を選択したと思われる」
数々の未解読文字とともに,後世に見られることのない多数の文字に思いを馳せざるをえない.
・ ルイ=ジャン・カルヴェ 著,矢島 文夫 監訳,会津 洋・前島 和也 訳 『文字の世界史』 河出書房,1998年.
2014-05-04 Sun
■ #1833. ギリシア・アルファベットの文字の名称 (2) [greek][alphabet][grammatology][runic]
昨日の記事「#1832. ギリシア・アルファベットの文字の名称 (1)」 ([2014-05-03-1]) に引き続き,セム・アルファベットから引き継いだ文字の名称について.昨日の一覧表の最後列に示したが,"alpha", "beta", "gamma" などの名称は, 語源不詳だったり同定されていないものもあるが,セム・アルファベットの有意味な単語に起源をもつと一般に信じられている.
原シナイ文字 (Proto-Sinaitic) から,フェニキア文字 (Phoenician) を含む各種のセム・アルファベット,それから古代ギリシア文字へと至る字形の変化を追っていくと,その連続性がよくつかめるのだが,原初の原シナイ文字の段階ではまだ文字というよりは略画に近い.原シナイ文字の第1字は,確かに「牛」(aleph) の頭部のようにみえる略画であり,これが字形の変化を経てギリシア・アルファベットのΑへと発展した.第2字は,「家」(bet) に見えなくもない字形で,これが後にΒへと発展した.このようにして,各文字は具体的なモノを描いた象形文字に端を発し,そのモノを表わす単語で呼称され,語頭音の音価を獲得するに至った.
セム・アルファベットの起源はたいてい以上のように説明されるのだが,実は1930年代の後半以降に異論が出てきた.異論の首唱者の1人 Hans Bauer は,字形と名称の関係は後付けであると論じている.田中 (40--41) より引用する.
従来の説によれば,古代セム記号は本来絵を表わしているといわれ,‘āleph は牛の頭を,bēth は家の形をというように,すべての記号はある物の形を描いていると考えられている.しかし牡牛の記号は,本来牡牛の絵文字であるから ‘āleph と命名したと解釈すべきでなく,任意に採用した記号が偶々牡牛の形に似ているために,後になってエジプトのアクロフォニーの原理を適用して ‘āleph (牡牛)と呼んだまでのことである.この場合何の名を選ぶかは随意である.現代の児童用「ABC本」などは,例えば,「O は Orange であった,S は Swan であった, B は Butterfly であった」などという風に,文字の形とその文字で始まる物の形との面白い類似によって,文字の記憶を助ける.この場合「O は Olive であった,S は Serpent であった,B は Bee であった」としても一向にかまわない.セム文字の名は,ルーン文字などの名と同様に,単に記憶の便のために付けた mnemonic name である.
冷めた見方ではあるが,mnemonic name 仮説を支持する学者も多いようだ.確かにΒの原型が「家」に見えるかといえば,はなはだ心許ない.そう言われるからそう見えてくるというだけのことかもしれない.
いずれにせよ "alpha", "beta" などの呼称はギリシア・アルファベットへ受け継がれ,ラテン語を経て,英語へも alphabet という語として取り込まれた.蛇足ながら,alphabet という語の由来は,alpha + beta である (Gk alphábētos, LL alphabētum, ME alphabete) .英語での初出は Polychronicon (?a1425) .文字体系の最初の数文字をもって文字一式を表わす例は alphabet のほか,ルーン文字の fuþark(「#1006. ルーン文字の変種」 ([2012-01-28-1]) を参照)や日本語の「いろは」もある(「#1008. 「いろは」と ABC」 ([2012-01-30-1]) を参照).
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
2014-04-30 Wed
■ #1829. 書き言葉テクストの3つの機能 [grammatology][writing][medium][speed_of_change]
エスカルピ著『文字とコミュニケーション』を読み,序論,第一章「文字」,第二章「読み」に文字論に関する啓発的な指摘をいくつか見つけた.以下に,備忘録的に書き留めておく.
著者は,文字,書き言葉,テキストの,話し言葉からの自立性を力説する.確かに書き言葉には話し言葉の写しとしての側面があり,その意味では依存しているとは言えるが,いったん書き言葉としての体系が発展すると,相当の自立性を獲得するというのも事実である.著者いわく,「文字法を,話し言葉を構成する音素の何かそのままの文字への置きかえ (transliteration) のように考えるのは錯覚である」 (22) ,さらに「文字を話し言葉の単なる道具と見なすことはできないといいたいし,また,言語学の伝統にみられる支配的傾向,「音声中心主義」 (phonocentrisme) を告発しよう」 (26) .エスカルピのこの主張について,私も賛同する.phonocentrisme については「#748. 話し言葉と書き言葉」 ([2011-05-15-1]) で,文字言語の独立性については「#1665. 話しことばと書きことば (4)」 ([2013-11-17-1]) や「#1655. 耳で読むのか目で読むのか」 ([2013-11-07-1]) の記事を参照されたい.
書き言葉が言語変化を抑止する,あるいは遅めるという点については,規範主義や教育という問題とも関わるが,エスカルピは文字そのものの本質,文字の記憶装置としての役割に帰せられるべきだと考えている.(36)
文字法の出現は話し言語を定着させ,あるいは少なくともその進化を著しくゆるめることに寄与したと指摘されているが,これはきわめて正しい.書かれない言語は急速に変わり,違ったものになっていく傾向があるために,一世代から次の世代にかけて理解しあうことが至難になった場合すら挙げられている.いうまでもなくこの定着は,痕跡の使用によって記憶が導入されたことによっている.とりわけ,何らかの形の痕跡がなければ,語彙総覧を作るこはできない./とくに単語というものは,本質的に文字言語がもたらしたもののように思われる.
文字が基本的に表語的 (logographic) な機能を果たすという指摘も重要である.アルファベットのような表音文字体系であっても,文字使用の主目的は表語にあると考えられる(「#1332. 中英語と近代英語の綴字体系の本質的な差」 ([2012-12-19-1]) や「#1386. 近代英語以降に確立してきた標準綴字体系の特徴」 ([2013-02-11-1]) も参照).
文字の語記号的性格はタイプライターでの打ち間違いによって証明される.手書きの草書体においては,語は連続したすじであって,書き手が自分のテクストと言説のあいだの絆を掌握していればいるだけ,それが単音文字へと分解されることは少ない.筆相鑑定家たちは,個別的なアルファベット符合が全体的な書き方のうちに消えていく《結合的》な筆蹟を知性のしるしと見なしている.ところで,タイプライターで書くときには単音文字への分解は避けられない.けれども,それは文字の継続的な選択に従ってなされはしない.少なくともいくらかの経験をもつタイピストの場合には.語全体が指の運動の内に《プログラム化》される.そしてこの運動がズレを起こしうるのである.その時 scripteur の代わりに spritceur と書かれることが起こる.語の要素はすべて出現している.外的な要素がまぎれ込むことは非常に珍しい.字の順序は狂うものの,その組成は変化を受けず,意味限定符は一般に無傷のまま残る./語記号――すなわちそれ自身の綴字で書かれた語――はゆえに,文字言語の最小有意味単位と考えねばならない.(38--39)
そして,何よりも啓発的なのは,文字の集合からなる書き言葉テクストには基本的な機能が2つあるという指摘である.1つは口頭の言説を写す言説的機能 (discursif) であり,もう1つは情報の記憶装置としての資料的機能 (documentaire) である(41) .前者は話し言葉に依存するが,後者は必ずしもそうではない.先に話題にした書き言葉が話し言葉の写しであるという見解は,テクストの言説的側面のみに着目した意見であり,テキストのもう1つの機能である資料的機能を考慮に入れていない点に問題がある.資料的機能が最大限に発揮されたテクストは,辞書やカタログなどのデータベースと呼びうる参考図書の類いである.そこでは情報が整理されており,相互参照などの機能も実装されている.このような機能は,話し言葉では容易にまねができない.
エスカルピ (44) は,もう1つ付け加えるべきテクストの機能として図像的機能 (iconique) を挙げている.これは,文字の形や大きさ,文字列の空間的な配列による書き言葉コミュニケーションの働きである.例えば新聞の1頁のレイアウトはテクストの読まれ方に影響を与えるが,これはテクストの図像的な働きゆえである.文字列の配置によって表現力を得ようとする具象詩においても,手紙の末尾の高い位置に宛名を大書する際にも,テクストの図像的機能が活用されている.この機能も,話し言葉に明確に対応するものはなく,書き言葉の自立性を示すものである.
・ ロベール・エスカルピ 著,末松 壽 『文字とコミュニケーション』 白水社〈文庫クセジュ〉,1988年.
2014-04-27 Sun
■ #1826. ローマ字は母音の長短を直接示すことができない [grammatology][grapheme][latin][greek][alphabet][vowel][spelling][spelling_pronunciation_gap]
現代英語の綴字と発音を巡る多くの問題の1つに,母音の長短が直接的に示されないという問題がある.英語も印欧語族の一員として,母音の長短,正確にいえば短母音か長母音・二重母音かという区別に敏感である.換言すれば,母音の単・複が音韻的に対立する.ところが,この音韻対立が綴字上に直接的に反映していない.例えば,bat vs bate や give vs five では同じ <a> や <i> を用いていながら,それぞれ前者では短母音を,後者では二重母音を表わしている.確かに,bat vs bate のように,次の音節の <e> によって,母音がいかに読まれるかを間接的に示すヒントは与えられている(「#1289. magic <e>」 ([2012-11-06-1]) を参照).しかし,母音字そのものを違えることで音の違いを示しているのではないという意味では,あくまで間接的な標示法にすぎない.give vs five では,そのヒントすら与えられていない.
母音字を組み合わせて長母音・二重母音を表わす方法は広く採られている.また,長母音補助記号として母音字の上に短音記号や長音記号を付し,ā や ă のようにする方法も,正書法としては採用されていないが,教育目的では使用されることがある.もとより文字体系というものは音韻対立を常にあますところなく標示するわけではない以上,英語の正書法において母音の長短が文字の上に直接的に標示されないということは,特に驚くべきことではないのかもしれない.
しかし,この状況が,英語にとどまらず,ローマン・アルファベットを採用しているあらゆる言語にみられるという点が注目に値する.母音の長短が,母音字そのものによって示されることがないのである.母音字を重ねて長母音を表わすことはあっても,長母音が短母音とまったく別の1つの記号によって表わされるという状況はない.この観点からすると,ギリシア・アルファベットのε vs η,ο vs ωの文字の対立は,目から鱗が落ちるような革新だった.
アルファベット史上,ギリシア人の果たした役割は(ときに過大に評価されるが)確かに革命的だった.「#423. アルファベットの歴史」 ([2010-06-24-1]) で述べたように,ギリシア人は,子音文字だったセム系アルファベットに初めて母音文字を導入することにより,音素と文字のほぼ完全な結合を実現した.音韻対立という言語にとってきわめて本質的かつ抽象的な特徴を取り出し,それに文字という具体的な形をあてがった.これが第1の革命だったとすれば,それに比べてずっと地味であり喧伝されることもないが,同じくらい本質を突いた第2の革命もあった.それは,母音の音価ではなく音量(長さ)をも文字に割り当てようとした発想,先述の ε vs η,ο vs ω の対立の創案のことだ.ギリシア人はフェニキア・アルファベットのなかでギリシア語にとって余剰だった子音文字5種を母音文字(α,ε,ι,ο,υ)へ転用し,さらに余っていたηをεの長母音版として採用し,次いでωなる文字をοの長母音版として新作したのだった(最後に作られたので,アルファベットの最後尾に加えられた).
ところが,歴史の偶然により,ローマン・アルファベットにつながる西ギリシア・アルファベットにおいては,上記の第2の革命は衝撃を与えなかった.西ギリシア・アルファベットでは,η(大文字Η)は元来それが表わした子音 [h] を表わすために用いられたので,そのままラテン語へも子音文字として持ち越された(後にラテン語やロマンス諸語で [h] が消失し,<h> の存在意義が形骸化したことは実に皮肉である).また,ωの創作のタイミングも,ラテン語へ影響を与えるには遅すぎた.かくして,第2の革命は,ローマ字にまったく衝撃を与えることがなかった.以上が,後にローマ字を採用した多数の言語が母音の長短を直接母音字によって区別する習慣をもたない理由である.
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
2014-04-26 Sat
■ #1825. ローマ字 <F> の起源と発展 [grammatology][grapheme][latin][greek][alphabet][consonant][f][reduplication]
現代英語で <f> はほぼ常に /f/ に対応している(唯一の例外は of).この安定した関係は中英語にまで遡る.それ以前の古英語では <v> を欠いていたので,<f> は [f] とともに [v] にも対応していたが,中英語期にフランス語の綴字習慣に影響されて <v> が導入されることにより,<f> = /f/ の一意の関係が確立した.この経緯については,「#373. <u> と <v> の分化 (1)」 ([2010-05-05-1]),「#374. <u> と <v> の分化 (2)」 ([2010-05-06-1]),「#1222. フランス語が英語の音素に与えた小さな影響」 ([2012-08-31-1]),「#1230. over と offer は最小対ではない?」 ([2012-09-08-1]) を参照されたい.
英語史の範囲内で見る限り,<f> は特に問題となることはなさそうだが,この文字が無声唇歯摩擦音に対応するようになったのは,ラテン語における革新ゆえである.古代ギリシア語のアルファベットを知っている人は,<f> に対応する文字がないことに気づくだろう.しかし,古代ギリシア語でも西方言には <f> に相当する文字が残っていたし,東方言でも最初期の段階にはそれがあった.後に koiné となる東方言の1変種である Attic ではそれが失われていたので,現代に至るギリシア・アルファベットには <f> が含まれていないのである.
初期ギリシア語には存在した <F> は,Γを上下にずらして2つ並べたような字形だったために,"digamma" として知られていた.これは,セム・アルファベットの第6番目の文字(Yに似た字形で,"wāu" と呼ばれる)を引き継いだもので,ギリシア語では半母音 [w] に近い摩擦音の音価を表わした.しかし,東方言ではこの音は消失し,その文字も捨て去られた.半母音 [w] に対して純正の母音 [u] は同起源のΥの文字で表わされ,これが後にラテン語以降の諸言語で <U>, <V>, <W>, <Y> へと分化していった.つまり,ローマ字の <F>, <U>, <V>, <W>, <Y> はすべてセム・アルファベットの wāu に起源をもつことになる.
さて,ラテン語はギリシア語西方言でまだ生き残っていた <F> = [w] の関係を取り入れた.しかし,ラテン語では [w] は <V> で表わす慣習が確立したので,<F> は不要となった.不要となった <F> はギリシア語東方言のときのように廃用となる可能性もあったが,ラテン語はこの余った文字をギリシア語にはなく,ラテン語にはあった無声唇歯摩擦音 [f] を表わすのに転用することを決めた.当初は,直接の転用には抵抗があったらしく,<F> 単体ではなく <FH> のように2文字を合わせて [f] を標示することを試みた証拠がある.例えば,紀元前7世紀の最古のラテン語で記された「マニオス刻文」には,右から左へ "IOISAMVN DEKAHFEHF DEM SOINAM" (Manios made me for Numasios) とあり,第3語目に "FHEFHAKED" (古典ラテン語の fecit に相当する古い加重形 reduplication)が見える(田中,p. 71).しかし,後には <F> 単体で [f] を表わすことになった.この関係が,ラテン語およびそれ以降の諸言語で保持されている.
ある言語のアルファベットが別の言語に移植される際に,不要な文字が廃用となったり,転用されたり,新しい文字が足されるなど,種々の変更が加えられることは,アルファベット史を通じて何度となく繰り返されてきた.文字と音化の関係は,ときに惰性で保持されることはあっても,その都度変化するのも普通のことだったことがわかるだろう.
以上,田中 (pp. 125--28) を参照して執筆した.
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
2014-04-25 Fri
■ #1824. <C> と <G> の分化 [grammatology][grapheme][latin][greek][alphabet][etruscan][rhotacism][consonant][c][g][q]
現代英語で典型的に <c> は /k/, /s/ に,<g> は /g/, /ʤ/ に対応する.それぞれ前者の発音は,古英語期に英語が Roman alphabet を受け入れたときのラテン語の音価に相当し,後者の発音は,その後の英語の歴史における発展を示す(<g> については,「#1651. j と g」 ([2013-11-03-1]) を参照).ラテン語から派生したロマンス諸語でも,種々の音変化の結果として,<c> や <g> が表わす音は,古典ラテン語のものとは異なっていることが多い.しかし,上で規範であるかのように参照したラテン語の <c> = /k/, <g> = /g/ という対応関係そのものも,ラテン語の歴史や前史における発展の結果,確立してきたものである.
ラテン語は,後にローマ字と呼ばれることになるアルファベットを,ギリシア語の西方方言からエトルリア語 (Etruscan) を介して受け取った.ギリシアとローマの両文明の仲介者であるエトルリア人とその言語は,「#423. アルファベットの歴史」 ([2010-06-24-1]) や「#1006. ルーン文字の変種」 ([2012-01-28-1]) でみたように,アルファベット史上に大きな役割を果たしたが,非印欧語であるエトルリア語について多くが知られているわけではない.しかし,エトルリア語の破裂音系列に有声・無声の音韻的対立がなかったことはわかっている.それにより,エトルリア語では,有声破裂音を表わすギリシア語のβとδは不要とされ廃用となった.しかし,γについては生き残り,これが軟口蓋破裂音 [k], [g] を表わす文字として用いられることとなった.
さて,エトルリア語から文字を受け取ったラテン語は,当初,γ = [k], [g] の関係を継続した.したがって,人名の省略形では,GAIUS に対して C. が,GNAEUS に対して CN. が当てられていた.しかし,紀元前300年頃に,この文字はとりわけ [k] に対応するようになり,純正に音素 /k/ を表わす文字として認識されるようになった.字体も rounded Γ と呼ばれる現代的な <C> へと近づいてゆき,<C> = /k/ の関係が確立すると,対応する有声音素 /g/ を表わすのに <C> に補助記号を伏した字形,後に <G> へ発展することになる字形が用いられるようになった.こうして紀元前300年頃に <C> と <G> が分化すると,後者はギリシア・アルファベットにおいてζが収っていた位置にはめ込まれた.ζは,ラテン語では後に <Z> として再採用されアルファベットの末尾に加えられることになったものの,[z] -> [r] の rhotacism を経て初期の段階で不要とされ廃用とされていたのである.
なお,ローマン・アルファベットでは無声軟口蓋破裂音を表わすのに <c>, <k>, <q> など複数の文字が対応しており,この点について英語を含めた諸言語は複雑な歴史を経験してきた.これは,英語の各文字の名称 /siː/, /keɪ/, /kjuː/ が暗示しているように,後続母音に応じた使い分けがあったことに起因する.エトルリア語では,前7世紀あるいはその後まで,CE, KA, QO という連鎖で用いられていた (cf. Greek kappa (Ka) vs koppa (Qo)) .現在にまで続く [k] を表わす文字の過剰は,ギリシア語やエトルリア語からの遺産を受け継いでいるがゆえである.
以上,田中 (pp. 76--79, 119) を参照して執筆した.
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
2014-04-24 Thu
■ #1823. ローマ数字 [numeral][latin][greek][grammatology][alphabet][etruscan]
現代の英語や日本語でも,時々ローマ数字 (Roman numerals) が使われる機会がある.例えば,番号,年号,本のページ,時計の文字盤などに現役で使用されている.現代英語からの例をいくつか挙げよう.
・ It was built in the time of Henry V.
・ For details, see Introduction page ix.
・ Do question (vi) or question (vii), but not both.
・ a fine XVIII-century' English walnut chest of drawers
ローマ数字は,ほんの数種類の文字と組み合わせ方の単純な原理さえ覚えれば,大きな数も難なく表わすことができるという長所をもち,ヨーロッパで2000年以上にわたる伝統を誇ってきた.10進法のなかに5進法が混在しており,後者にはギリシアのアッティカ式の影響が見られる.IV = 4, IX = 9 など減法も利用したやや特異な記数法である.以下に凡例を掲げよう.
| 1 | I |
| 2 | II |
| 3 | III |
| 4 | IV |
| 5 | V |
| 6 | VI |
| 7 | VII |
| 8 | VIII |
| 9 | IX |
| 10 | X |
| 11 | XI |
| 12 | XII |
| 13 | XII |
| 14 | XIV |
| 19 | XIX |
| 20 | XX |
| 21 | XXI |
| 30 | XXX |
| 40 | XL |
| 45 | XLV |
| 50 | L |
| 60 | LX |
| 90 | XC |
| 100 | C |
| 500 | D |
| 1000 | M |
| 1998 | MCMXCVIII |
ヨーロッパでアラビア数字 (Arabic numerals) の使用が最初に確認されるのは976年のウィギラム写本においてだが,13--14世紀以降に普及するまでは,ローマ時代以来,ローマ数字 (Roman numerals) が一般的に使用されてきた(カルヴェ,pp. 210--11) .それ以降も,上述のような限られた文脈においては,現在まで命脈を保っている.
では,ローマ数字の起源について考えよう.I が1を表わすというのは直感的に理解できるとしても,V, X, C などその他の単位の文字はどのように選ばれたのだろうか.明確なことはわかっていないが,ドイツの歴史家 Theodor Mommsen (1817--1903) の説が有名である.それによると,V は手をかたどった象形文字であり,指の本数である5を表わすという.Vを上下に向かい合わせて重ねると,X (10) となる.L, C, M は,エトルリア語や初期ラテン語を書き表すのに不要とされた西ギリシア文字のΨ (khi; 東ギリシア文字では khi はΧによって表わされるので注意),Θ (theta),Φ (phi) をそれぞれ 50, 100, 1000 の数に割り当てたのが起源とされる.後に字形の類似により,Ψ(後に字形が┴のように変形する)が L と,Θが C(ラテン語 centum の影響もあり)と,Φが M(ラテン語 mille の影響もあり)と結びつけられた.L (50) の字形が C (100) の下半分の字形に似ているという意識,さらに D (500) の字形が M (1000) の右半分の字形に似ているという意識も関与していたのではないかと言われる(田中,p. 75).
・ 田中 美輝夫 『英語アルファベット発達史 ―文字と音価―』 開文社,1970年.
・ ルイ=ジャン・カルヴェ 著,矢島 文夫 監訳,会津 洋・前島 和也 訳 『文字の世界史』 河出書房,1998年.
2014-04-23 Wed
■ #1822. 文字の系統 [writing][grammatology][alphabet][kanji][history][runic][origin_of_language][family_tree][hieroglyph]
本ブログで,これまで文字論や文字の歴史に関する話題として,「#41. 言語と文字の歴史は浅い」 ([2009-06-08-1]),「#422. 文字の種類」 ([2010-06-23-1]),「#423. アルファベットの歴史」 ([2010-06-24-1]),「#490. アルファベットの起源は North Semitic よりも前に遡る?」 ([2010-08-30-1]),「#1006. ルーン文字の変種」 ([2012-01-28-1]) などを取り上げてきた.ほかにも,文字論について grammatology,アルファベットについて alphabet,ルーン文字について runic,漢字,ひらがな,カタカナについてそれぞれ kanji, hiragana, katakana で話題にした.
言語の発生 (origin_of_language) については,現在,単一起源説が優勢だが,文字の発生については多起源説を主張する論者が多い.古今東西で行われてきた種々の文字体系は,発生と進化の歴史によりいくつかの系統に分類することができるが,確かにそれらの祖先が単一の原初文字に遡るということはありそうにない.メソポタミア,エジプト,中国,アメリカなどで,それぞれの文字体系が独立して発生したと考えるのが妥当だろう.
最も古い文字体系は,メソポタミアに居住していたシュメール人による楔形文字である.紀元前4千年紀,おそらく紀元前3500年頃に,楔形文字の体系が整い始めた.楔形文字は,紀元前8000年頃にすでに見られたとされる,帳簿に数量を記録するのためのマークがその原型であるといわれ,数千年の時間をかけてゆっくりと文字体系へと成長していったものである.
同じ紀元前4千年紀,あるいはもう少し遅れて,比較的近いエジプトでもヒエログリフ (hieroglyphic) やそこから派生したヒエラティック (hieratic) が現れる.これらは初めて文証された段階で,すでにほぼ完全な文字体系として機能しており,メソポタミアの楔形文字のような漸次的発展の前史が確認されない.
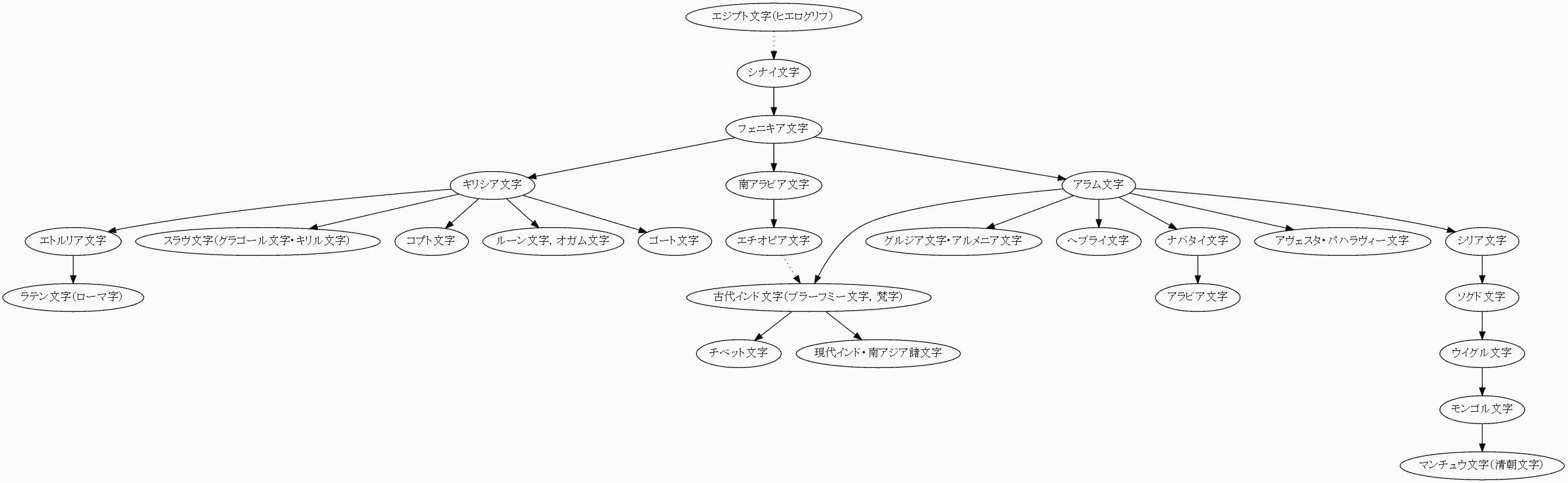
アルファベットの発生については,「#423. アルファベットの歴史」 ([2010-06-24-1]) で概説したとおりなので記述は省略する.
漢字は,紀元前2000年頃に現れ,紀元前1500年頃に文字としての体裁を整えた.文字体系として完成したのは,漢王朝 (BC202--220AD) の時代である.
文字体系の系統としては,以上の4つ,(1) 楔形文字体系,(2) ヒエログリフ文字体系,(3) アルファベット体系,(4) 漢字体系が区別されることになる.ジョルジュ・ジャン (136--37) の図を参照して作った文字の系統図を示そう.実線矢印は直接的影響を,点線矢印は間接的影響を示す.
(1) 楔形文字体系
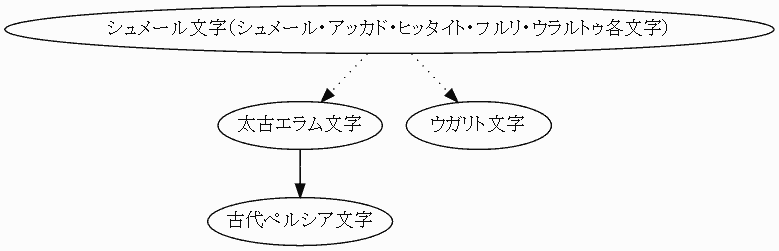
(2) ヒエログリフ文字体系
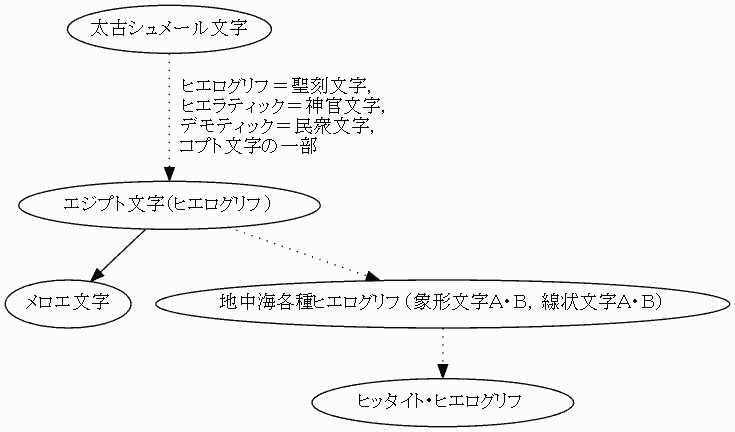
(3) アルファベット体系(図をクリックして拡大)
(4) 漢字体系
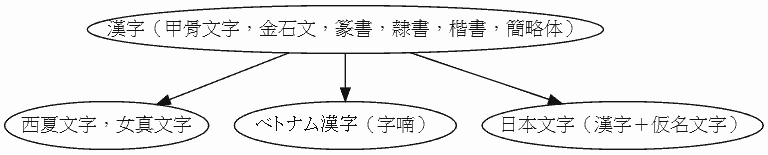
以上の4系統に収らないその他の文字体系もある.未解読文字を含むが,朝鮮文字(ハングル),ロロ文字,モソ文字,バヌム文字,インダス文字(紀元前3000年頃),マヤ・アステカ文字,イースター島文字などである.
古今東西の文字体系については,次のサイトが有用.
・ Omniglot: Writing Systems & Language of the World
・ A Compendium of World-Wide Writing Systems from Prehistory to Today
・ 世界の文字(各国文字)
・ ジョルジュ・ジャン 著,矢島 文夫 監修,高橋 啓 訳 『文字の歴史』 創元社,1990年.
Powered by WinChalow1.0rc4 based on chalow