2023-08-06 Sun
■ #5214. 句動詞の品詞転換と ODPV (2) [dictionary][lexicography][phrasal_verb][conversion][punctuation][hyphen][gerund]
昨日の記事 ([2023-08-05-1]) に引き続き,句動詞辞典 Oxford Dictionary of Phrasal Verbs (= ODPV) を参照しつつ句動詞 (phrasal_verb) の品詞転換 (conversion) について.
ODPV の巻末 (514) に,名詞化した句動詞について概説と凡例が掲載されている.この部分を読むだけで,句動詞の品詞転換をめぐる問題や様々な側面がみえてくる.例えば,2要素の間にハイフンが挟まれるのかどうかを含めた句読法の問題,句動詞のゼロ派生ではなく動詞に -ing を付して動名詞化する別法の存在,一見句動詞の品詞転換のようでいて実はもとの対応する句動詞が欠けているケース,形容詞への品詞転換の事例など.
This index covers all the nominalized forms (ie nouns derived from verbs + particles/prepositions) recorded in the main part of the dictionary (usually but not always the base form of the verb + particle/preposition, with or without a hyphen). For a full treatment of these forms, see The Student's Guide to the Dictionary.
Nominalized forms sometimes consist of the -ing form of the verb + particle/preposition (eg (a) dressing-down, (a) summing-up, (a) telling-off). The more common examples are recorded here.
Each nominal form is listed alphabetically and is followed by the headphrase(s) of the entry (or entries) in which it appears in the main text:
change-over change over (from)(to); change round/over
output put out 7
When the nominalized form is the headphrase itself, the fact is noted as follows:
fall-out (main entry)
(There is no finite verb + particle expression in regular use from which fall-out derives: a sentence such as *The nuclear tests fell out over a large area is unacceptable.)
When a nominalized form is generally used attributively, a noun with which it commonly occurs is given in parentheses after it:
(a) see-through (blouse) see through 1
start-up (capital) start up 2
Whether a nominalized form appears as one word, as one word with a hyphen, or as two words, is often a matter of printing convention or individual usage. The entries in the dictionary and in this index generally show the most accepted form in British usage, but variations are recorded where appropriate, eg. a) poke(-)about/around.
ちなみに第1段落で参照されている The Student's Guide to the Dictionary の該当箇所 (xiii) には,次のようにある.
1 what is a nominalized form?
A nominalized form ('nom form' for short) is a noun formed from a phrasal verb: make-up, for instance, is formed from make up (ie 'apply cosmetics to one's face') and take-off is formed from take off (ie 'leave the ground in an aircraft'). Sometimes nom forms have a spelling which includes the letters -ing: tell off (ie 'reproach, reprimand') has the nom form telling-off.
ただでさえ使いこなすのが難しい句動詞だが,そこからの発展形というべき品詞転換した名詞・形容詞についても相当に複雑な事情があるようだ.
・ Cowie, A. P. and R Mackin, comps. Oxford Dictionary of Phrasal Verbs. Oxford: OUP, 1993.
2023-08-05 Sat
■ #5213. 句動詞の品詞転換と ODPV [dictionary][lexicography][phrasal_verb][conversion][voicy][heldio]
句動詞 (phrasal_verb) の品詞転換 (conversion) について,今朝の Voicy 「英語の語源が身につくラジオ (heldio)」で取り上げました.「#796. get-together, giveaway --- 句動詞の品詞転換」をお聴き下さい.
配信のなかで触れた Oxford Dictionary of Phrasal Verbs (= ODPV) について紹介します.新版も出ているようですが,配信のために私が参照したのは1993年版のこちらでした.

この辞書の巻末 (514--17) に句動詞が品詞転換してできた多くの名詞(ときに形容詞)が一覧されています.400個近くあるのではないでしょうか.出版から20年経っていますが,現在までに品詞転換した句動詞も少なくないものと想像されます.
句動詞の品詞転換については,本ブログでも以下の記事で触れていますのでご参照下さい.
・ 「#420. 20世紀後半にはやった二つの語形成」 ([2010-06-21-1])
・ 「#1695. 句動詞の品詞転換」 ([2013-12-17-1])
また,句動詞に限らず一般の品詞転換の話題については,本ブログの記事としては conversion を,heldio の配信回としてはこの辺りをお訪ねいただければ.
・ Cowie, A. P. and R Mackin, comps. Oxford Dictionary of Phrasal Verbs. Oxford: OUP, 1993.
2023-08-03 Thu
■ #5211. Innsbruck EDD Online 4.0 [dialect][web_service][corpus][lmode][lexicography][edd][dictionary][notice]
Joseph Wright による English Dialect Dictionary のオンライン版である EDD Online について,Manfred Markus が率いる Innsbruck 大学のチームがオンライン化プロジェクトの最終段階の成果として Version 4.0 を公表した,との情報を得ました.Innsbruck EDD Online 4.0 Based on Joseph Wright's English Dialect Dictionary (1898--1905) です.
私はまだ EDD Online の豊富な機能を使いこなせていないのですが,辞書の画像イメージを確認できたり,地図上に示してくれたり等,視覚化の機能が充実している印象です.
Markus 教授による使い方のイントロ動画(5分)もありますので視聴をお勧めします(辞書とは関係ありませんが,動画の最後のインスブルックの景色に心奪われて今すぐオーストリアに行きたい,などと妄想).
EDD については,hellog では以下の記事で取り上げてきましたので,そちらもご参照下さい.
・ 「#869. Wright's English Dialect Dictionary」 ([2011-09-13-1])
・ 「#868. EDD Online」 ([2011-09-12-1])
・ 「#2694. EDD Online (2)」 ([2016-09-11-1]) を参照.
2023-06-04 Sun
■ #5151. 日本語反対語辞典の「まえがき」より [lexicology][semantics][antonymy][synonym][structuralism][thesaurus][dictionary]
「反対語」「対義語」「対照語」「対応語」などと称される antonym は,語彙意味論においても関心を集めてきた.私も反対語辞典の類いは好きでよく引くのだが,日本語で常用しているものとして『反対語対照語辞典 新装版』がある.
反対語といっても「反対」のあり方は様々で,語彙意味論でもまさにその点が問題となる.上記の辞典の「まえがき」 (i--ii) を読めば,その難しさとおもしろさが理解できるだろう.
単語は一つ一つがばらばらに存在しているのではなく,まとまりをもち,いわばネットワークをなしている.たとえば「父」という単語は,「お父さん」「おやじ」「パパ」などと言い換えることができる.これら四語は,同じものを指している.四語の間には敬意の有無やニュアンスの違いなどがあり,完全に同義であるとはいえないが,同義に近い関係ーー類義の関係ーーにあるということができる.一方,「父」の対として「母」という語がある.そして,「母」にも「お母さん」「おふくろ」「ママ」といったような類義の語が存在する.また,「父」と「母」の両者を包含する語として「親」があり,「親」の対として「子」という語がある.このように,単語は相互に関連して複雑な組織網を形成している.
反対語の定義はきわめて難しい.同義語・類義語には同じものを指すといった基準があるが,反対語の条件は単純ではない.反対語という場合,まず両者の間に共通する意味がなければならない.「母」が「父」の反対語になるのは,両者が<親>という共通の意味をもっているからである.しかし,共通する意味をもっているだけでは,もちろん反対語にはならない.「母」が「父」の反対語になるのは,男性ではなく女性であるということによる.つまり,男性か女性かという基準から見て反対の意味になるのである.反対語の条件は,
(1) 共通する意味をもっていること
(2) その上で,ある基準から見て,反対の意味をもっていること
の二点であるということになるだろう.
もう一つの例をあげよう.「大勝」の反対語には,「大敗」と「辛勝」とがあげられるが,前者は,(1) 大差で勝負がつくという共通点をもち,(2) 勝ち負けという基準から見て反対の意味をもっており,後者,つまり「辛勝」は,(1) 勝つという共通の意味をもち,(2) 勝ち方が大差か小差かという基準から見て反対の意味をもっている.ある語の反対語は,一つとは限らない.基準が変わると,いくつも存在することになる.
以上のように説明すると,反対語の判定は比較的容易なように見えるが,一語一語について具体的に考えていく段になると,反対の意味とは何かということが問題になってきて,判断に苦しむことが多い.
上記で例に挙げられている「大勝」に関する辞典内の図を参照しよう.構造主義的な,きれいなマトリックスとなる.
| <大差> | <小差> | ||
| <勝利> | 圧勝(大勝・快勝) | ←───→ | 辛勝 |
| ↑ | ↑ | ||
| │ | │ | ||
| ↓ | ↓ | ||
| <敗北> | 惨敗(大敗・完敗) | ←───→ | 惜敗 |
しかし,多くの場合,そこまできれいなマトリックスにはならない.反対関係はもっと複雑になることも多い.例えば「水」を中心とした語彙の関係図を示そう.
┌─┐ │油│ └─┘ ┌─┐ ↑ ┌─┐ │ │ │ │ │ │ │ ↓ │ │ │水│←──────→┌─┐ │ │ │ │ ┌─┐ │ │ │ │ │蒸│ │湯│←─→│水│←─→│氷│ │ │ └─┘ │ │ │ │ │気│ └─┘ │ │ │ │ ↑ │ │ │ │←────────┼───→│ │ └─┘ ↓ └─┘ ┌─┐ │火│ └─┘
反対語の意味論については,hellog および heldio より以下を参照.
・ hellog 「#1800. 様々な反対語」 ([2014-04-01-1])
・ hellog 「#1804. gradable antonym の意味論」 ([2014-04-05-1])
・ hellog 「#1968. 語の意味の成分分析」 ([2014-09-16-1])
・ hellog 「#4102. 反意と極性」 ([2020-07-20-1])
・ heldio 「#353. 反対語っていろいろあっておもしろい!」
・ heldio 「#354. long と short は対等な反対語ではない?」
・ 北原 保雄・東郷 吉男(編) 『反対語対照語辞典 新装版』 東京堂出版,2015年.
2023-01-23 Mon
■ #5019. 辞書比較の前に押さえておきたいこと [dictionary][genius6][lexicography][methodology][voicy][heldio][masanyan][aokikun]
昨日の記事「#5018. khelf メンバーと4人でジェンダーとコロナ禍周りのキーワードで『ジーニアス英和辞典』の版比較 in Voicy」 ([2023-01-22-1]) で紹介しましたが,6つの版を縦に比較した Voicy 放送「#600. 『ジーニアス英和辞典』の版比較 --- 英語とジェンダーの現代史」が,嬉しいことに多く聴かれています.ちょっとした khelf(慶應英語史フォーラム)企画というつもりでの収録でしたが,辞書比較のおもしろさが伝わったようであれば嬉しいです.
今回は身近な語句で辞書の版比較を導入しておもしろさを感じていただくという趣旨でしたが,辞書の版違いを用いるという手法は,現代英語の本格的な通時的研究にも利用できます.英和辞書でも英英辞書でも,「売れ筋」系の老舗辞書であれば,おおよそ定期的に新版が出版されています.例えば老舗でポピュラーな The Concise Oxford Dictionary のシリーズ(最新は12版)を利用すれば,優に100年を超える通時的な観察が可能です.Webster 系の辞書などでは,約200年にわたる英語の記述を追いかけることもできます.私自身も複数の辞書の異なる版を比較して英語史研究を行なってきました.例えば以下の論文では,ひたすら辞書を比較しています.
・ Hotta, Ryuichi. "Thesauri or Thesauruses? A Diachronic Distribution of Plural Forms for Latin-Derived Nouns Ending in -us." Journal of the Faculty of Letters: Language, Literature and Culture 106 (2010): 117--36.
・ Hotta, Ryuichi. "Noun-Verb Stress Alternation: An Example of Continuing Lexical Diffusion in Present-Day English." Journal of the Faculty of Letters: Language, Literature and Culture 110 (2012): 39--63.
研究手法としてはシンプルで応用が利きやすいように見えますが,注意が必要です.同一シリーズの辞書であっても編纂方針が一貫しているとは限らないからです.辞書作りは,出版社によって,編纂者によって,その時々の言語学の潮流やニーズによって,記述主義と規範主義の間で揺れ動くものだからです.したがって,研究に先立って辞書批評が必要となります.そのために,研究者には辞書学や辞書の歴史に関する素養も必要となってきます.異なるシリーズの辞書を組み合わせて研究する場合には,さらに慎重な事前評価が求められるでしょう.
今回の『ジーニアス英和辞典』の版比較の heldio 放送は,あくまで導入的なものです.本格的な研究に耐える議論へ発展させようとすれば,同シリーズの辞書の textual criticism が必要となることを強調しておきたいと思います.
2023-01-22 Sun
■ #5018. khelf メンバーと4人でジェンダーとコロナ禍周りのキーワードで『ジーニアス英和辞典』の版比較 in Voicy [dictionary][genius6][gender][covid][voicy][heldio][language_change][sociolinguistics][lexicography][methodology]
昨日の Voicy 「英語の語源が身につくラジオ (heldio)」 では,khelf(慶應英語史フォーラム)の大学院生メンバー3名とともに「#600. 『ジーニアス英和辞典』の版比較 --- 英語とジェンダーの現代史」をお届けしました.ジェンダーとコロナ禍に関するキーワードについて『ジーニアス英和辞典』の初版から最新の第6版までを引き比べ,英語史を専攻する4人があれやこれやとおしゃべりしています.意外な発見が相次いで,盛り上がる回となりました.30分ほどの長さです.ぜい時間のあるときにお聴きいただければと思います.Voicy のコメント機能により,ご感想などもお寄せいただけますと嬉しいです.
今回比較した『ジーニアス英和辞典』の6つの版の出版年をまとめておきます.5--8年刻みで,おおよそ定期的に出版されており,1つのシリーズ辞典で英語の記述を通時的に追いかけることが可能となっています.
| 版 | 出版年 |
|---|---|
| G1 | 1987年 |
| G2 | 1993年 |
| G3 | 2001年 |
| G4 | 2006年 |
| G5 | 2014年 |
| G6 | 2022年 |
昨年11月に発売開始となった最新版の『ジーニアス英和辞典』第6版については,hellog および heldio で何度か取り上げてきました.以下をご参照ください.
・ hellog 「#4892. 今秋出版予定の『ジーニアス英和辞典』第6版の新設コラム「英語史Q&A」の紹介」 ([2022-09-18-1])
・ hellog 「#4950. 最近の英語の変化のうねり --- 『ジーニアス英和辞典』第6版のまえがきより」 ([2022-11-15-1])
・ hellog 「#4975. 2重目的語を取る動詞,取りそうで取らない動詞」 ([2022-12-10-1])
・ heldio 「#532. 『ジーニアス英和辞典』第6版の出版記念に「英語史Q&A」コラムより spring の話しをします」
・ heldio 「#557. まさにゃん対談:supply A with B の with って要りますか? --- 『ジーニアス英和辞典』新旧版の比較」
2022-12-27 Tue
■ #4992. absence 「不在」に関する英語の諺2つ [proverb][voicy][heldio][dictionary]
手持ちの The Oxford Dictionary of Proverbs (6th ed.) を A から順に眺めている.この年末年始にでも少しずつ読み進めていこうと思っている.英語の諺 (proverb) には古い文法や語法が残っていることが多く,英語史と親和性があるのだ.

早速,1ページ目に absence 「不在」に関する諺が2つ出てきた.absence と聞けば,諺にふさわしいどのような人生の知恵を思い浮かべるだろうか.私には想像できなかったが,たいへん異なる2つの諺が飛び出してきて驚いた.
1つめは Absence makes the heart grow fonder である.ある人が不在だと,その人をますます好きになってしまうという教訓だ.ODP を読んでいておもしろいのは,他言語での関連する表現や,英語史上での変異形とその用例を示してくれる点だ.この諺について関連するラテン語の表現が記されている.
Cf. PROPERTIUS elegies II. xxxiiib. I. 43 semper in absentes felicior aestus amantes, passion [is] always warmer towards absent lovers.
英語史上の用例もいくつか挙げられており,最初の例はc1850年のものである.興味深く感じたのは,1923年の Observer 11 Feb. 9 からの用例である.反意の諺として有名な Out of sight, out of mind が言及されている.
These saws are constantly cutting one another's throats. How can you reconcile the statement that 'Absence makes the heart grow fonder' with 'Out of sight, out of mind'?
2つめの諺は He who is absent is always in the wrong である.いわゆる欠席裁判のことだ.欠席者は悪者にされ,不利な立場に追い込まれるというものだ.1640年の諺辞典に "The absent partie is still faultie" と現われているのが初出だが,関連する表現は15世紀の Lydgate に出ている.フランス語にも対応表現があるようだ.
If a person is not present to defend himself it is easy for others to say he is the person at fault. Cf. Fr. les absents ont toujours tort; c 1440 J. LYDGATE Fall of Princes (EETS) m. l. 3927 For princis ofte . . . Wil cachche a qu[a]rel . . . Ageyn folk absent.
1736年の例も機知に富んでいる.
1736 B. FRANKLIN Poor Richard's Almanack (July) The absent are never without fault, nor the present without excuse.
1つのキーワードから様々な発想を引き出すことができた.諺辞典の新たな用途をみつけた感がある.ちなみに今朝の Voicy の「英語の語源が身につくラジオ (heldio)」でも「#575. 英語諺辞典を A から読み始めています!」と題して連動するおしゃべりをしています.ぜひお聴きください.
・ Speake, Jennifer, ed. The Oxford Dictionary of Proverbs. 6th ed. Oxford: OUP, 2015.
2022-10-26 Wed
■ #4930. The early bird catches the worm 「早起きは三文の得」 [proverb][voicy][heldio][rhythm][article][dictionary]
今朝の Voicy で「早起きは三文の得」を推しつつ,その英語版のことわざ The early bird catches the worm を紹介しているのですが,なんと現代では発想を転換させた新しい諺もどき It's the second mouse that gets the cheese. が台頭しつつあるという情報を得ました.たまげつつも,なるほどと納得した次第です.
まずは話しの前提として,古典的な(時間術ならぬ)健康術としての The early bird . . . . について私が語っている今朝の Voicy 放送「#513. 古典的な時間術 --- The early bird catches the worm. 「早起きは三文の得」」をお聴きください.
The Oxford Dictionary of Proverbs より17世紀の初出から現代までの異形や用例を挙げてみましょう.
The EARLY bird catches the worm
The corollary in quot. 2001, it's the second mouse that gets the cheese, is attributed to US comedian Steven Wright (born 1955); it is found particularly in the context of entrepreneurial or technological innovation, where the advantages of being the first (the early bird) may be outweighed by the lower degree of risk faced by a follower or imitator (the second mouse).
□ 1636 W. CAMDEN Remains concerning Britain (ed. 5) 307 The early bird catcheth the worme. 1859 H. KINGSLEY Geoffrey Hamlyn II. xiv. Having worked . . . all the week . . . a man comes into your room at half-past seven . . . and informs you that the 'early bird gets the worm'. 1892 I. ZANGWILL. Big Bow Mystery i. Grodman was not an early bird, now that he had no worms to catch. He could afford to despise proverbs now. 1996 R. POE Return to House of Usher ix. 167 'I got home at midnight last night and I'm here at seven. Where are they? . . . Well, it's the early bird that catches the worm, and no mistake.' 2001 Washington Post 4 Sept. C13 The early bird may catch the worm, but it's the second mouse that gets the cheese. Don't be in a hurry to take a winner. . . .
この英語ことわざ辞典は,英語史を学ぶにも人生訓を学ぶにも最適の読み物です.英語の本で何を読もうかと迷ったら,本当にお勧めです.hellog より proverb の各記事もご一読ください.
・ Speake, Jennifer, ed. The Oxford Dictionary of Proverbs. 6th ed. Oxford: OUP, 2015.
2022-10-11 Tue
■ #4915. 英語史のデジタル資料 --- 大学院のデジタル・ヒューマニティーズ入門講義より [hel_education][corpus][dictionary][slide][methodology]
今学期の大学院のオムニバス講座「人文学の方法論(デジタル・ヒューマニティーズ)」の1講義として,主に人文系の履修者を対象に「言語研究とデジタルコーパス・辞書・方言地図」を話す機会がありました.単発の授業ということで,準備した資料も今後活用されることもなさそうですので,差し障りのない形に加工した上でこちらに公開しました.基本的には,英語史を専門としない人文系大学院生向けの講義のために準備した参考資料です.スライド中からは hellog 記事への参照もたくさんあります.
1. 「言語研究とデジタルコーパス・辞書・方言地図」
2. まず,コーパスとは?
3. 1980年代以降の英語史研究
4. 英語コーパス発展の3軸
5. 主な歴史英語コーパス
6. 主な歴史英語辞書
7. 主な歴史英語方言地図
8. コーパス研究の功罪
9. 参考文献
私からは英語史研究におけるデジタル資料との付き合い方というような話しをしたわけですが,ほぼ皆が異なる分野を専攻する学生だったので,議論を通じて各々の分野での "DX" の進展について教えてもらう機会も得られ,たいへん勉強になりました.
2021-10-24 Sun
■ #4563. OALD10 活用ガイド [dictionary][lexicography][notice][elt]
昨年出版された英英辞書 Oxford Advanced Learner's Dictionary of Current English の第10版 (= OALD10) について,以下の記事を書いてきた.
・ 「#4518. OALD10 の世界英語のレーベル15種」 ([2021-09-09-1])
・ 「#4520. Oxford 3000, Oxford 5000, OPAL の語彙」 ([2021-09-11-1])
・ 「#4533. OALD10 が注意を促している同音異綴語の一覧」 ([2021-09-24-1])
入手してからなるべく多くの機会に冊子体なりオンライン版なりを使うようにしているが,いやはや,辞書として本当に進化しているなという印象である.とりわけオンライン版では,辞書の基本機能はもちろん,コロケーションなどの応用機能も利用できる.文法学習のコーナーも充実しているし,先の記事で紹介した Oxford 3000 などのワードリストも入手できる.英文テキストを投げ込むと,各単語が頻度やレベルに応じて色づけされて返ってくる Text Checker というサービスもある.その他,スピーキングやライティングの学習にも役立つリソースが用意されている.サイトを探検しているだけで英語の学習になるほどだ.
旺文社の特設ページより OALD10 の活用ガイドを入手できる.「OALD10活用ガイド 辞書編」と「OALD10活用ガイド アプリ/Web編」の2種類のPDFがあり,とりわけ前者は辞書学の研究者である山田茂氏による,同辞書の使い方の丁寧な解説となっており,たいへん有用.
OALD10 の辞書学の観点からの本格的な分析(100頁以上にわたる!)は Takahashi et al. を参照されたい.
・ Takahashi, Rumi, Yukiyoshi Asada, Marina Arashiro, Kazuo Dohi, Miyako Ryu, and Makoto Kozaki. "An Analysis of Oxford Advanced Learner's Dictionary of Current English, Tenth Edition." Lexicon 51 (2021): 1--106.
2021-10-11 Mon
■ #4550. 歴史的辞書は言語の中立的な情報源ではない [lexicography][dictionary][cawdrey][johnson][philology]
言語研究上,辞書はなくてはならない情報源である.本ブログの中心的な話題である英語史研究においても,各時代の辞書や通時的な辞書はなくてはならないツールだ.しかし,辞書とて人の作ったものである.辞書編纂者の生きた時代の言語態度が反映されているものだし,辞書編纂者個人のバイアスもかかっているのが常である.言語研究のためには,この辺りを意識して歴史辞書(および現代の辞書)を用いる必要があるのだが,このようなすぐれてフィロロジカルな観点は意識の外に置かれることが多い.例えば,威信ある OED の情報であれば間違いがあるはずがない,などと絶対的な信頼を寄せてしまうことはよくある.
近代英語期に目を向けると,例えば英語史上初の英語辞書といわれる 1604年の Robert Cawdrey の A Table Alphabeticall と,時代も下って規範主義が成熟した1755年の Samuel Johnson の A Dictionary of the English Language とでは,編纂された時代背景も異なれば言語態度も異なるので,同じ見出し語の定義などを比べたとしても,そこには確かに通時的な変化が反映されている可能性はあるものの,そもそもの編纂意図が異なるという点を考慮しておかないと痛い目に合うかもしれない.Coleman (99--100) が,この点を指摘している.
For example, the title of Cawdrey's Table Alphabetical (1604) explains that the dictionary was compiled "for the benefit and help of ladies, gentlewomen, or any other unskillful persons. Whereby they may the more easily and better understand many hard English words, which they shall hear or read in scriptures, sermons, or elsewhere, and also be made able to use the same aptly themselves" (spelling modernized). Similarly often quoted is the preface to Johnson's Dictionary of the English Language (1755):
When I took the first survey of my undertaking, I found our speech copious without order, and energetic without rules: wherever I turned my view, there was perplexity to be disentangled, and confusion to be regulated; choice was to be made out of boundless variety, without any established principle of selection. (Johnson 1755: Preface)
These quotations illustrate changing ideas about the status of English and the purpose of a dictionary. Cawdrey acknowledged that the vocabulary of English was varied and challenging, but apparently did not consider this to be a problem. His purpose was to help uneducated people struggling to understand loans from classical and modern languages: the deficit was in English speakers, not the language. Johnson, on the other hand, considered the exuberance of English to be problematic in itself, and for him the priorities were regulation and control of the language.
17世紀初めの Cawdrey は問題は英語話者にあると考えていたが,18世紀半ばの Johnson は問題は英語そのものにあると考えていた.辞書編纂のポリシーが互いに異なっていたのも無理からぬことである.
標題にも掲げた通り「歴史的辞書は言語の中立的な情報源ではない」可能性が高いのだ.一方,この点を逆手に取れば,歴史的辞書を通じて,通時的な言語変化の証拠は得られなくとも,各時代の言語態度をこそ復元できるということなのかもしれない.歴史的辞書は使いようである.
・ Coleman, Julie. "Using Dictionaries and Thesauruses as Evidence." Chapter 7 of The Oxford Handbook of the History of English. Ed. Terttu Nevalainen and Elizabeth Closs Traugott. New York: OUP, 2012. 98--110.
2021-09-24 Fri
■ #4533. OALD10 が注意を促している同音異綴語の一覧 [homonymy][homophony][lexicography][dictionary][lexicology][pronunciation]
昨年出版された Oxford Advanced Learner's Dictionary of Current English の第10版に,以前の版にはなかった新タイプの注記が加えられている.同音異綴 (homophony) を示す2語(あるいは3語)の指摘である(cf. 「#286. homonymy, homophony, homography, polysemy」 ([2010-02-07-1])).
同音異綴語 (homophone) は英語に多数ある.flour/flower や knight/night のように比較的意識に上りやすいものがある一方で,cymbal/symbol や flew/flue など言われてみれば確かにそうだなという類いのものもある(ちなみに flour/flower については 「#183. flower と flour」 ([2009-10-27-1]),「#2440. flower と flour (2)」 ([2016-01-01-1]),および 「flower (花)と flour (小麦粉)は同語源!」 (heldio) を参照).
「#2945. 間違えやすい同音異綴語のペア」 ([2017-05-20-1]) でいくつか例を挙げたが,OALD10 の注記を集めると93項目もの同音異綴語が指摘されている.以下に Takahashi et al. (78--80) にまとめられている一覧を引用しよう.
・ allowed/aloud
・ bare/bear
・ base/bass
・ berry/bury
・ blew/blue
・ board/bored
・ brake/break
・ buy/by/bye
・ cell/sell
・ chews/choose
・ chute/shoot
・ coarse/course
・ coward/cowered
・ crews/cruise
・ cue/queue
・ cymbal/symbol
・ days/daze
・ dear/deer
・ desert/dessert
・ dew/due
・ feat/feet
・ flour/flower
・ flew/flu
・ forth/fourth
・ grate/great
・ groan/grown
・ hear/here
・ heal/heel/he'll
・ air/heir
・ higher/hire
・ hole/whole
・ idle/idol
・ colonel/kernel
・ knight/night
・ lead/led
・ lessen/lesson
・ mail/male
・ meat/meet
・ miner/minor
・ missed/mist
・ muscle/mussel
・ knew/new
・ knows/nose
・ oar/or/ore
・ one/won
・ pain/pane
・ passed/past
・ peace/piece
・ pair/pare/pear
・ peak/peek/pique
・ plain/plane
・ praise/prays/preys
・ principal/principle
・ profit/prophet
・ key/quay
・ rap/wrap
・ raise/rays/raze
・ read/red
・ read/reed
・ rain/reign/rein
・ road/rode/rowed
・ role/roll
・ rose/rows
・ rouse/rows
・ sail/sale
・ scene/seen
・ cent/scent/sent
・ seas/sees/seize
・ cereal/serial
・ sight/site
・ soar/sore
・ sole/soul
・ sew/so/sow
・ stationary/stationery
・ steal/steel
・ storey/story
・ suite/sweet
・ son/sun
・ tail/tale
・ threw/through
・ tide/tied
・ toe/tow
・ vain/vein
・ wail/whale
・ waist/waste
・ war/wore
・ weak/week
・ ware/wear/where
・ wait/weight
・ weather/whether
・ whine/wine
・ which/witch
・ warn/worn
眺めていると,各単語の綴字と発音のよい勉強になる.なかにはヘェ?と思うものもあるのでは?
・ Oxford Advanced Learner's Dictionary of Current English. 10th ed. Ed. A. S. Hornby. Oxford: Oxford UP, 2020.
・ Takahashi, Rumi, Yukiyoshi Asada, Marina Arashiro, Kazuo Dohi, Miyako Ryu, and Makoto Kozaki. "An Analysis of Oxford Advanced Learner's Dictionary of Current English, Tenth Edition." Lexicon 51 (2021): 1--106.
2021-09-11 Sat
■ #4520. Oxford 3000, Oxford 5000, OPAL の語彙 [lexicology][lexicography][dictionary][keyword][statistics]
「#4518. OALD10 の世界英語のレーベル15種」 ([2021-09-09-1]) でも紹介したが,昨年 Oxford Advanced Learner's Dictionary of Current English (通称 OALD)の第10版が出版された.改訂とともに進化し続けるこの辞書のファンの1人としては,辞書本文以上に付録的な部分にも注目してしまうのだが,関連して Oxford 3000, Oxford 5000, OPAL と呼ばれる英語学習・教育上の有用な語彙一覧を紹介したい.OALD10 の x--xi に各々の解説がある.
・ The Oxford 3000TM
20億語からなる巨大な The Oxford English Corpus における生起頻度に基づいた,英語学習者を意識して編まれた英単語3000個の一覧.同コーパスは,イギリス英語とアメリカ英語のみならず世界英語を網羅している.最頻2000語で英語テキストの8割の語彙をカバーしているともいわれるが,この3000語の一覧は CEFR (= Common European Framework of Reference) の A1 から B2 までの水準を念頭においた頼りになるリストだ.こちらより一覧をダウンロードできる.
・ The Oxford 5000TM
The Oxford 3000 よりも水準の高い,CEFR の B2 から C1 までの語彙を含めた拡張版の単語一覧.上記と同様こちらから一覧にアクセスできる.
・ The Oxford Phrasal Academic LexiconTM
"OPAL" と略称されている,学術英語 (English for Academic Purposes) に有用な語彙.大学の講義,セミナー,レポート,卒論などの英語を念頭に編まれた単語一覧である.この一覧は,書き言葉コーパス The Oxford Corpus of Academic English (= OCAE) と話し言葉コーパス The British Academic Spoken English (= BASE) をソースとしたキーワード (keyword) 分析に基づくもので,学術英語の習得に役立つ単語一覧である.こちらからアクセスできる.
昨今の英語学習・教育は実に統計的・科学的になっているなあと感心するばかりだが,英語学・英語史のアカデミックな研究においても語彙の頻度情報というのは基本事項であるから,おおいに活用したい.
・ Oxford Advanced Learner's Dictionary of Current English. 10th ed. Ed. A. S. Hornby. Oxford: Oxford UP, 2020.
2021-09-09 Thu
■ #4518. OALD10 の世界英語のレーベル15種 [world_englishes][variety][lexicography][dictionary]
昨年,伝統ある英語学習者用の英英辞書 Oxford Advanced Learner's Dictionary of Current English の第10版 (= OALD10) が出版された.私も第4版や第5版の頃から長らくお世話になっている辞書だが,冊子体のみならず CD/DVD 版で提供される時代になってきたかと思いきや,今回の第10版ではディスク媒体の配布すらなく,アクセスコード付きのオンライン版のみが提供される形となっている.時代は変わったものだ.ただ,重厚な冊子体版は相変わらず健在なので,パラパラめくっては(内容とともに)質感を楽しんでいる.
OALD は伝統的にイギリス英語を基盤とする記述に定評があるが,無視できない存在であるアメリカ英語の記述にも力を割いてきた経緯がある.さらに昨今は World Englishes の時代ということもあり,世界の諸変種の語彙を取り込んだ編纂方針が目立つようになってきた.実際,今回の第10版では,巻末に "English across the world" と題するコラムが掲載されている.小見出しとして "The spread of English" や "Englishes, not English" という文言もみえる.前者の冒頭は次の通り.
English is spoken as a first language by more than 350 million people throughout the world, and used as a second language by as many, if not more. One in five of the world's population speaks English with some degree of competence. It is an official or semi-official language in over 70 countries, and it plays a significant role in many more.
続けて世界の地域ごとに英語変種が簡単に解説されていくのだが,辞書で使用される各変種を示すレーベルも同時に紹介される.変種レーベルの一覧は見返しに記載されているが,それを再現すると次の通り15種類が確認される.BrE (= British English), NEngE (= Northern England English), ScotE (= Scottish English), WelshE (= Welsh English), IrishE (= Irish English), US (= American English), CanE (= Canadian English), NAmE (= North American English), AustralE (= Australian English), NZE (= New Zealand English), SAfrE (= South African English), WAfrE (= West African English), EAfrE (= East African English), IndE (= Indian English (the English of South Asia)), SEAsian E (= South-East Asian English) .
World Englishes の地域ベースの分類としては標準的でバランスのとれたものといってよい.伝統的イギリス系辞書も,このような配慮を示す時代になってきたのだなあ.
・ Oxford Advanced Learner's Dictionary of Current English. 10th ed. Ed. A. S. Hornby. Oxford: Oxford UP, 2020.
2021-06-06 Sun
■ #4423. 講座「英語の歴史と語源」の第10回「大航海時代と活版印刷術」を終えました [asacul][notice][history][link][slide][age_of_discovery][spanish][printing][caxton][cawdrey][dictionary][standardisation][age_of_discovery]
去る5月29日(土)の15:30?18:45に,朝日カルチャーセンター新宿教室にて「英語の歴史と語源・10 大航海時代と活版印刷術」を開講しました.全12回のシリーズですが,いよいよ終盤に入ってきました.今回も不自由の多い状況のなか参加していただいた皆さんに感謝致します.いつも通り,質問やコメントも多くいただきました.
今回のお話しの趣旨は以下の通りです.
15世紀後半?16世紀前半のイングランドは,ヨーロッパで始まっていた大航海時代と活版印刷術の発明という歴史上の大事件を背景に,近代国家として,しかしあくまで二流国家として,必死に生き残りを模索していた時代でした.この頃までに,英語はイングランドの国語として復活を遂げていたものの,対外的にいえば,当時の世界語たるラテン語の威光を前に,いまだ誇れる言語とはいえませんでした.英語史では比較的目立たない同時期に注目し,来たるべき飛躍の時代への足がかりを捕らえます.
今回の講座で用いたスライドをこちらに公開します.以下にスライドの各ページへのリンクも張っておきます.
1. 英語の歴史と語源・10「大航海時代と活版印刷術」
2. 第10回 大航海時代と活版印刷術
3. 目次
4. 1. 大航海時代
5. 新航路開拓の略年表
6. 大航海時代がもたらしたもの --- 英語史の観点から
7. 1492年,スペインの栄光
8. 2. 活版印刷術
9. 印刷術の略年表
10. グーテンベルク (1400?--68)
11. ウィリアム・キャクストン (1422?--91)
12. 印刷術と近代国語としての英語の誕生
13. 印刷術の綴字標準化への貢献
14. 「印刷術の導入が綴字標準化を推進した」説への疑義
15. 綴字標準化はあくまで緩慢に進行した
16. 3. 当時の印刷された英語を読む
17. Table Alphabeticall (1604) by Robert Cawdrey
18. まとめ
19. 参考文献
次回のシリーズ第11回は「ルネサンスと宗教改革」です.2021年7月31日(土)の15:30?18:45に開講予定です.英語にとって,ラテン語を仰ぎ見つつも国語として自立していこうともがいていた葛藤の時代です.講座の詳細はこちらからどうぞ.
2021-05-30 Sun
■ #4416. トイレの英語文化史 --- 英語史語彙論研究入門 [taboo][euphemism][khelf_hel_intro_2021][thesaurus][dictionary][lexicology][htoed][semantics][synonym][slang][hel_education][bibliography][link]
4月5日より始まっていた「英語史導入企画2021」のコンテンツ紹介記事は,今回で最終回となります.話題は「office, john, House of Lords --- トイレの呼び方」です.トリを飾るに相応しいテーマですね! トイレの英語文化史あるいは英語文化誌というべき内容で,Historical Thesaurus of the Oxford English Dictionary (= HTOED) を用いてこんなにおもしろい調査ができるのかと教えてくれるコンテンツです.コンテンツ内の図と点線を追っていくだけで,トイレの悠久の旅を楽しむことができます.
タブー (taboo),婉曲表現 (euphemism),類義語 (synonym) といった語彙論 (lexicology) 上の問題は,英語史の卒業論文研究などでも人気のテーマです.英語史語彙論研究に関心をもったら,これらのタグの付いた hellog の記事群を読んでみてください.また,以下に今回のコンテンツと緩く関連した記事も紹介しておきます.
・ 「#470. toilet の豊富な婉曲表現」 ([2010-08-10-1])
・ 「#471. toilet の豊富な婉曲表現を WordNet と Visuwords でみる」 ([2010-08-11-1])
・ 「#992. 強意語と「限界効用逓減の法則」」 ([2012-01-14-1])
・ 「#1219. 強意語はなぜ種類が豊富か」 ([2012-08-28-1])
・ 「#3885. 『英語教育』の連載第10回「なぜ英語には類義語が多いのか」」 ([2019-12-16-1])
・ 「#3392. 同義語と類義語」 ([2018-08-10-1])
・ 「#469. euphemism の作り方」 ([2010-08-09-1])
・ 「#4395. 英語の類義語について調べたいと思ったら」 ([2021-05-09-1])
・ 「#3159. HTOED」 ([2017-12-20-1])
・ 「#847. Oxford Learner's Thesaurus」 ([2011-08-22-1])
・ 「#4334. 婉曲語法 (euphemism) についての書誌」 ([2021-03-09-1])
・ 「#1270. 類義語ネットワークの可視化ツールと類義語辞書」 ([2012-10-18-1])
・ 「#1432. もう1つの類義語ネットワーク「instaGrok」と連想語列挙ツール」 ([2013-03-29-1])
・ 「#4092. shit, ordure, excrement --- 語彙の3層構造の最強例」 ([2020-07-10-1])
・ 「#4041. 「言語におけるタブー」の記事セット」 ([2020-05-20-1])
2021-05-09 Sun
■ #4395. 英語の類義語について調べたいと思ったら [khelf_hel_intro_2021][thesaurus][dictionary][lexicology][htoed][semantics][synonym][corpus][methodology]
英語を学ぶ上で,類義語 (synonym) というのは厄介です.訳語としては同じなのに,実際にはニュアンスの違いがあるというのだから手間がかかります.一般に言語において完全な同義語はないとされますが,意味が微妙に異なる類義語というのは,思っている以上に多く存在します.
日本語で考えてみれば,類義語の多さにはすぐに気づくでしょう.「疲れる」の類義語を挙げてみましょう.「くたびれる」「くたばる」「へたばる」「へばる」「グロッキー」「バテる」「疲労する」「困憊する」「へとへとになる」「ふらふらになる」「疲れ切る」など,それぞれ独特のコノテーションがありますね.
英語で「疲れた」といえば,第一に tired が思い浮かびますが,他に exhausted, drained, weary, worn out, shattered, pooped, fatigued などもあります.学習するには厄介ですが,各々独自のコノテーションをもっており存在意義があるようです.昨日の「英語史導入企画2021」のためのコンテンツは,学部生による「「疲れた」って表現,多すぎない?」です.こちらもご覧ください.
このような類義語に関心をもったら,まず当たるべきは学習者用の英英辞典です.例えば Longman Dictionary of Contemporary English (= LDOCE) などでは,たいてい主要な見出し語(例えば tired)のもとに,THESAURUS という類義語コーナーが設けられており,各類義語の使い分けが簡潔に記されています.
thesaurus というのは,ずばり類義語辞典のこと.とすれば,類義語辞典そのものに当たるのが早いといえば早いですね.例えば,Oxford Learner's Thesaurus によれば,各類義語のニュアンス,用例,コロケーションが細かく解説されています.以下のように,どんどん記述が続いていきます.かゆいところに手が届く辞典ですね.
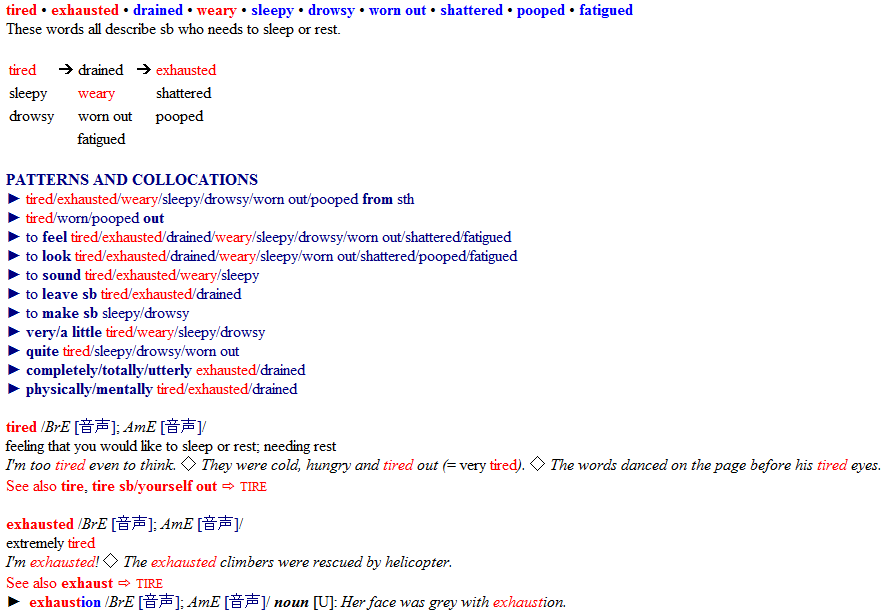
さらに詳しく調べたいのであれば,各類義語が用いられている「現場」からの事例を多数集めて分析することが必要になります.こうなるとコーパスの利用が有用です.まずは,イギリス英語とアメリカ英語の各々について,BNCweb と COCA というコーパスに当たってみるのがお薦めです.
「英語史導入企画2021」の開催中ということで,かなり高度な研究ツールながらも歴史的類義語辞典なるもの紹介しておきましょう.Historical Thesaurus of the Oxford English Dictionary (= HTOED) です.詳細は「#3159. HTOED」 ([2017-12-20-1]) をどうぞ.
2021-04-04 Sun
■ #4360. 英単語の語源を調べたい/学びたいときには [etymology][hel_education][hellog_entry_set][link][dictionary][asacul][note][hellog_entry_set]
4月1日より連日「#4357. 新年度の英語史導入キャンペーンを開始します」 ([2021-04-01-1]) として,英語史の学びを応援するキャンペーンを張っています.
多くの人にとって,英語の歴史への入口は英単語の語源ではないでしょうか.各単語には生まれ育ってきた歴史があります.言語学には "Every word has its own history." という金言があるとおり,単語一つひとつに「人生」があるのです.単語のなかには,生み出された背景に歴史的な事件が関与しているものもあれば,現在までに意味を大きく変化させてきたものもありますし,また死語となったものも多数あります.こういった各単語の歴史は「語誌」とも呼ばれますが,一人ひとりの生涯と同じように独特の魅力を放っています.
というわけで,本ブログでも語源に関する話題は非常に多く取り上げてきました.etymology で検索すると,どれを読めばよいのか目移りするはずです.そこで,とりわけ英単語の語源に関心のある読者の皆さんに向けて,hellog 内の情報を少し整理したいと思います.
(1) まず,道具立てとして語源辞書が必要ですね.オンラインで最も手軽にアクセスできる英語語源辞書は Online Etymology Dictionary です.私の作った「#952. Etymology Search」 ([2011-12-05-1]) もご利用ください.
(2) あわせて American Heritage Dictionary of the English Language (4th ed.) の語源ノートも検索できる,自作の「#1819. AHD Word History Note Search」 ([2014-04-20-1]) もご活用ください.
(3) その他,「#485. 語源を知るためのオンライン辞書」 ([2010-08-25-1]) のリンク先も適宜参照するとよいと思います.
(4) しかし,本格的な語源情報を求めるならば,まだまだ紙媒体の語源辞書や一般辞書が基本です.「#600. 英語語源辞書の書誌」 ([2010-12-18-1]) で一覧した各種辞書を引く習慣をつけていただければと思います(ただし,これらの辞書にも電子化・オンライン化されているものはあります).『英語語源辞典』(研究社)と OED は基本中の基本という文典です.
(5) 2018年7月21日に朝日カルチャーセンター新宿教室で「歴史から学ぶ英単語の語源」という講座を開きました.このときの資料を「#3381. 講座「歴史から学ぶ英単語の語源」」 ([2018-07-30-1]) にて公開していますので,ご自由にどうぞ.
(6) これは宣伝ともなりますが,目下,朝日カルチャーセンター新宿教室で,全12回の講座「英語の歴史と語源」を開いています.第9回まで終わっており,次の第10回は5月29日(土)の15:30?18:45に予定されています.「英語の歴史と語源・10 大航海時代と活版印刷術」です.ご関心のある方は,こちらからどうぞ.第9回までのバックナンバーについては,hellog でも取り上げてきました.こちらの記事セットをご覧ください.
(7) 語源による英単語学習法に関心がある方は,「#3546. 英語史や語源から英単語を学びたいなら,これが基本知識」 ([2019-01-11-1]),「#3698. 語源学習法のすゝめ」 ([2019-06-12-1]) や「#3696. ボキャビルのための「最も役に立つ25の語のパーツ」」 ([2019-06-10-1]) などの記事をどうぞ.
(8) 「語源学」そのものに関心をもった方は,上級編となりますが##466,1791,727,598,599,636,1765の記事セットをご覧ください.
なお,英語史という分野は,単語や語彙の歴史という側面には大いに関心を寄せていますが,もちろんそれだけに限定されるわけではありません.英語の発音や文法の歴史も扱いますし,談話,方言,他言語との関わりなどを含む,語用論や社会言語学的な分野も重要な関心事です.
2021-03-12 Fri
■ #4337. Horne Tooke の語源奇書 [etymology][dictionary][lexicography][webster][comparative_linguistics][jones]
昨日の記事「#4336. Richardson の辞書の長所と短所」 ([2021-03-11-1]) で触れたように,Richardson はその独特な言語観と語源記述を Horne Tooke なる人物に負っている.Tooke は,その独善的な語源観により Richardson のみならず Webster をも迷妄に導いた,19世紀後半のイギリスの生んだ個性である.
John Horne Tooke (1736--1812) は,1758年にケンブリッジ大学を卒業後,法律家志望ではあったが,父の希望により聖職に就いた.しかし,1773年に聖職を辞すと,アメリカ独立戦争に際して植民地側に立ち,急進的な政治運動を開始した.後のフランス革命にも同情的な立場を取り,国事犯として検挙されるなどの憂き目にあっている.
そのような政治運動を展開する間,言語哲学への関心から語学的な著述も行なってきた.1778年には接続詞 that に関する著述 A Letter to John Dunning, Esq. を出している.そして,次著が問題の2巻ものの Epea Pteroenta or, the Diversions of Purley (1786, 1805) である.合計1000頁に及ぶ言語哲学と語源論に関する大著だ.これが,今となっては奇書といってしかるべき語源本なのである.
Dixon によるこの奇人・奇書の解説文を引用しよう (150) .
He [Tooke] maintained that originally language consisted just of nouns and verbs with everything else (adjectives, prepositions, pronouns, articles, and so on) being abbreviations of underlying noun and verb sequences. He also believed that each word had a definite meaning which had remained constant from its origin. What makes the modern reader squirm most is the way in which Horne Took applied these principles, absolutely off the top of his head. For example, conjunction through was believed to be related to noun door, and conjunction if was said to have come from the imperative form of verb give. If did have the form gif in Old English and verb give was giefan, but these are not cognate, the similarity of form being coincidental.)
Sometimes there was vague similarity of form, other times not. 'I believe that up means the same as top or head, and is originally derived from a noun of the latter signification'. 'From means merely beginning, and nothing else', so that in 'Lamp hangs from cieling (sic)'), it is the case that 'Cieling (is) the place of beginning to hang.'
There are dozens more of such mental meanderings, lacking any basis in fact. From actually goes back to preposition *per in PIE and up to PIE preposition *upo. It is true that some prepositions have developed from lexical words, but none in the way Horne Tooke imagined. Through relates to the PIE verb *tere- 'to cross over, pass through, overcome'. . . . Door is a development from *dhwer, which meant 'door, doorway' in PIE.
Horne Tooke's book was simply a raft of wild ideas. There may have been other books of this nature, but the scarcely believable fact is that The Diversions of Purley was accepted by the British public as an example of brilliant insight. Philosopher James Mill found Horne Tooke's work 'profound and satisfactory', 'to be ranked with the very highest discoveries which illustrate the names of speculative men'. The account of conjunctions 'instantly appeared to the learned so perfectly satisfactory as to entitle the author to some of the highest honours of literature'.
当時,近代言語学の走りとして William Jones により比較言語学 (comparative_linguistics) の端緒が開かれつつあったものの,イギリスへの本格的な導入はなされておらず,Tooke の俗耳に入りやすい前科学的な語源論は好評を博した(かの哲学者 James Mill も絶賛したほど).いや,むしろ Tooke の書により,イギリスへの比較言語学の導入が遅れたとすらいえるかもしれない(佐々木・木原,p. 353).
しかし,1840年頃までには,イギリスは Tooke の迷妄から抜け出していた.Tooke の書は,"gratuitous", "incorrect", "fallacious", "frivolous" などの形容詞で評される時代となっていたのである (Dixon 151)
・ 佐々木 達,木原 研三 編 『英語学人名辞典』 研究社,1995年.
・ Dixon, R. M. W. The Unmasking of English Dictionaries. Cambridge: CUP, 2018.
2021-03-11 Thu
■ #4336. Richardson の辞書の長所と短所 [etymology][dictionary][lexicography][johnson][oed][webster]
「#3155. Charles Richardson の A New Dictionary of the English Language (1836--37)」 ([2017-12-16-1]) で紹介したように,Richardson (1775--1865) の英語辞書は,Johnson, Webster, OED という辞書史の流れのなかに埋没しており,今ではあまり顧みられることもないが,19世紀半ばにおいては重要な役割を果たしていた.
長所としては,英語辞書史上初めて本格的に「歴史」を意識した辞書だったということがある.引用文による定義のサポートは Johnson に始まるが,Johnson とて典拠にした文献は王政復古以後のものであり,中英語にまで遡ることはしなかった.しかし,Richardson は中英語をも視野に入れ,真の「歴史的原則」の地平を開いたのである.しかも,引用数は Johnson を遥かに上回っている.結果として,小さい文字で印刷されながら2000頁を超すという(はっきりいって使いづらい)大著となった (Dixon 146) .
もう1つ長所を指摘すると,近代期の辞書編纂は善かれ悪しかれ既存の辞書の定義からの剽窃が当然とされていたが,Richardson はオリジナルを目指したことである.手のかかるオリジナルの辞書編纂を選んだのは,前には Johnson,後には OED を挙げれば尽きてしまうほどの少数派であり,この点において Richardson の覇気は評価せざるを得ない.
短所としては,先の記事でも触れたとおり,"a word has one meaning, and one only" という極端な原理を信奉し,主に語源記述において独善に陥ってしまったことだ.この原理は Horne Tooke (1736--1812) という,やはり独善的な政治家・語源論者によるもので,この人物は今では奇書というべき2巻ものの英語語源に関する著 The Diversions of Purley (1786, 1805) をものしている.Richardson の辞書を批判した Webster も,この Tooke の罠にはまった1人であり,この時代,語源学方面で Tooke の負の影響がはびこっていたことが分かる.
いずれにせよ Richardson は,英語辞書史において主要な辞書編纂家のはざまで活躍した19世紀半ばの重要キャラだった.
・ 佐々木 達,木原 研三 編 『英語学人名辞典』 研究社,1995年.
・ Dixon, R. M. W. The Unmasking of English Dictionaries. Cambridge: CUP, 2018.
Powered by WinChalow1.0rc4 based on chalow