2013-08-02 Fri
■ #1558. ギネスブック公認,子音と母音の数の世界一 [phonology][phoneme][vowel][consonant][altaic][japanese][language_family][world_languages][austronesian]
日本語のルーツについての有力な説の1つに,オーストロネシア系 (Austronesian) とアルタイ系 (Altaic) の言語が融合したとする説がある.オーストロネシア語族の音韻論的な特徴としては,開音節が多い,区別される音素が少ないというものがあり,確かに日本語の比較的単純な音素体系にも通じる.
日本語の音素が比較的少ない点については「#1021. 英語と日本語の音素の種類と数」 ([2012-02-12-1]) および「#1023. 日本語の拍の種類と数」 ([2012-02-14-1]) で触れたが,そこでは関連してハワイ語にも触れた.ハワイ語もオーストロネシア語族に属する言語で,8つの子音 /w, m, p, l, n, k, h, ʔ/ と5つの母音 /a, i, u, e, o/ を区別するにすぎない(コムリー,p. 95).ところが,世界にはもっと音素が少ない言語があるのである.
地理的にオーストロネシア語族と隣接しているパプア諸語も,音韻体系は単純である.そのなかでも,東パプアニューギニアの Bougainville Province で4千人ほどの話者によって話されているロトカス語 (Rotokas) は,6つの子音 /b, g, k, p, r, t/ と5つの母音 /a, e, i, o, u/ の計11音素(と対応する11の文字)しかもたない(Ethnologue より,関連する言語地図はこちら).コムリー (106) によれば,これは世界最少の音素数であり,とりわけ子音の少なさについては1985年のギネスブック (199) に登録されているほどである.
子音についていえば,最多を誇るのは「#1021. 英語と日本語の音素の種類と数」 ([2012-02-12-1]) でも触れたウビフ語である.80--85個の子音をもつという.母音の最少は,コーカサス地方のアブハズ語で2母音しかもたない.母音音素の最多はベトナム中央部のセダン語で,明確に区別できる55の母音をもつという.世界は広い.
同じギネスブック (198--201) では,言語についての興味深い「世界一」が,他にもいろいろと挙げられており,一見の価値がある.言語のびっくり統計は,Language statistics & facts も参考になる.
・ バーナード・コムリー,スティーヴン・マシューズ,マリア・ポリンスキー 編,片田 房 訳 『新訂世界言語文化図鑑』 東洋書林,2005年.
・ ノリス・マクワーター 編,青木 栄一・大出 健 訳 『ギネスブック』 講談社,1985年.
2013-07-18 Thu
■ #1543. 言語の地理学 [geolinguistics][geography][sociolinguistics][demography][language_shift][language_death][world_languages][terminology]
ブルトンの『言語の地理学』を読み,地理学の観点から言語を考察するという新たなアプローチに気づかされた.言語における地理的側面は,方言調査,言語変化の伝播の理論,言語圏 (linguistic area; see [2012-12-01-1]) の研究などで前提とはされてきたが,あまりに当然のものとみなされ,表面的な関心しか払われてこなかったといえるかもしれない.このことは,「#1053. 波状説の波及効果」 ([2012-03-15-1]) の記事でも触れた.
言語の地理学,言語地理学,地理言語学などと呼び方はいろいろあるだろうが,これはちょうど言語の社会学か社会言語学かという区分の問題に比較される.Trudgill (56) の用語集で geolinguistics を引いてみると,案の定,この呼称には2つの側面が区別されている.
(1) A relatively recent label used by some linguists to refer to work in sociolinguistics which represents a synthesis of Labovian secular linguistics and spatial dialectology. The quantitative study of the geographical diffusion of words or pronunciations from one area to another is an example of work in this field. (2) A term used by human geographers to describe modern quantitative research on geographical aspects of language maintenance and language shift, and other aspects of the spatial relationships to be found between languages and dialects. An example of such work is the study of geographical patterning in the use of English and Welsh in Wales. Given the model of the distinction between sociolinguistics and the sociology of language, it might be better to refer to this sort of work as the geography of language.
伝統的な方言研究や言語変化の伝播の研究では,言語項目の地理的な分布を明らかにするという作業が主であるから,それは「地理言語学」と呼ぶべき (1) の領域だろう.一方,ブルトンが話題にしているのは,「言語の地理学」と呼ぶべき (2) の領域である.後者は,民族や宗教や国家や経済などではなく言語という現象に焦点を当てる地理学である,といえる.
言語の地理学で扱われる話題は多岐にわたるが,その代表の1つに,「#1540. 中英語期における言語交替」 ([2013-07-15-1]) で具体的にその方法論を適用したような言語交替 (language shift) がある.また,失われてゆく言語の保存を目指す言語政策の話題,言語の死の話題も,話者人口の推移といった問題も言語の地理学の重要な関心事だろう.世界の諸言語の地理的な分布という観点からは,先述の言語圏という概念も関与する.諸文字の地理的分布も同様である.
ブルトンが打ち立てようとしている言語の地理学がどのような性格と輪郭をもつものなのか,直接ブルトンに語ってもらおう.
結局,地理学者は,社会史学的・経済学的な次元の人文現象と言語とのあいだの空間的相関関係の確立に習熟しているのである.そして中でも,自然環境や生物地理的環境との相関関係はお手のものである.言語が,自然環境に直接働きかけるものでない以上,言語については本来の生態学を語ることはできない.しかしすべての言語は,住民の中に独自の分布を示しており,住民は言語の環境でもある.したがってまた共通の言語を備えた人間集団の生態学が存在するのである.そしてある文化的特徴――言語――がある一つの環境――またはいくつかの環境――の中で,他の文化的・社会的・経済的特質と同様の,あるいは異なったしかたで,どのように拡大しどのように維持されどのように定着できたかを明らかにするには,地理学者はまさに資格十分である.(29--30)
実際にはブルトンは,言語の地理学を,さらに大きな文化地理学へと結びつけようとしている.
自然現象と文化現象の2つの領域を厳密に分けることによってのみ,人種や人類学的圏域のような概念を理解し利用することが可能となり,これら人種圏の範囲と文化的な集合体の範囲とを比較することができる.この文化的集合体の中でも,言語的,宗教的,政治的属性といった異なる次元のあいだの相違は,長いあいだ,より明確に認識されてきた.そこからエスニー(民族言語的共同体)や信仰社会集団や国家といったような,それぞれの区別に対応する共同体や構造についての認識が派生してきたのである./文化の諸特徴の地理学から,われわれはいまや文化それ自体の地理学へと近づくことができる.すなわち,社会の言語的・宗教的・歴史政治的な遺産を結びつけ,そして思考と仲間意識との個性的な諸体系を生みだすような文化の集合体に関する地理学へ,である.この文化地理学はそれゆえに,大きなあるいは社会全体の人間集団を見極めることを目的とする.これらの集団は,場合に応じて部族,エスニー,国家,大文明の一大単位などと同列視されるのである.地理学者はこれらの集団の生態学を,その内部運動,偶発的な相互依存,さらにそれらの機能的な階層性,依存度または支配度,文化の受容と放棄といった個別的または集団的な現象による浸透力などの側面から研究する.経済活動の優先性が一般に認められている世界では,文化地理学は社会の中で経済人の反対の側に生きいきと存在しているものを見分けるという使命を帯びているのである.(32--33)
要するに,ブルトンの姿勢は,社会における言語という大局観のもとで言語の地理的側面に焦点を当てるということである.以下は,その大局観と焦点の関係を図示したものである(ブルトン,p. 47,「エスニーの一般的特徴」).言語の社会学や社会言語学のための見取り図としても解釈できる.
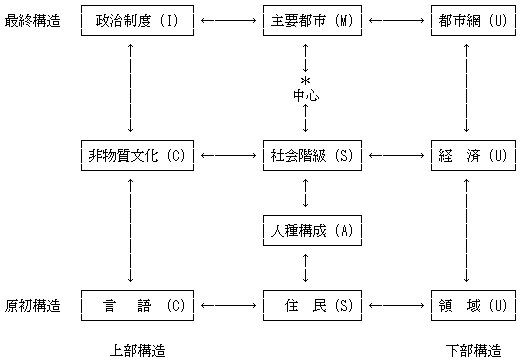
なお,上の引用文で用いられているエスニーという概念と用語については,「#1539. ethnie」 ([2013-07-14-1]) を参照.
・ Trudgill, Peter. A Glossary of Sociolinguistics. Oxford: Oxford University Press, 2003.
・ ロラン・ブルトン 著,田辺 裕・中俣 均 訳 『言語の地理学』 白水社〈文庫クセジュ〉,1988年.
2013-07-06 Sat
■ #1531. pidgin と creole の地理分布 [pidgin][creole][map][geography][world_languages][tok_pisin][caribbean]
数え方にもよるが,世界中で100以上のピジン語やクレオール語が日常的に用いられているといわれる.なかには200万人を超える話者を擁する Tok Pisin のような活発な言語もある.実際,Tok Pisin は南太平洋における最大の言語である.英語を lexifier とする「#463. 英語ベースのピジン語とクレオール語の一覧」 ([2010-08-03-1]) についてはすでに本ブログで言及したが,かつての大英帝国の影響力から予想される通り,英語ベースのものが最も多い.
Romain (170--73) の地図を参照して lexifier 言語別にピジン語とクレオール語の個数を数え上げると,英語が35,フランス語が14,ポルトガル語が9,スペイン語が3,オランダ語が3,その他の言語が26となる. * *
世界に散在する種々のピジン語とクレオール語を分類するのに,上記のように語彙を提供している言語,すなわち superstratum の言語を基準とする方法があるが,ほかに地域を基準とする分類もある.地理的な分布の観点からピジン語やクレオール語を大きく2分すると,大西洋系列と太平洋系列とに分かれる.Romain (174--75) を引用しよう.
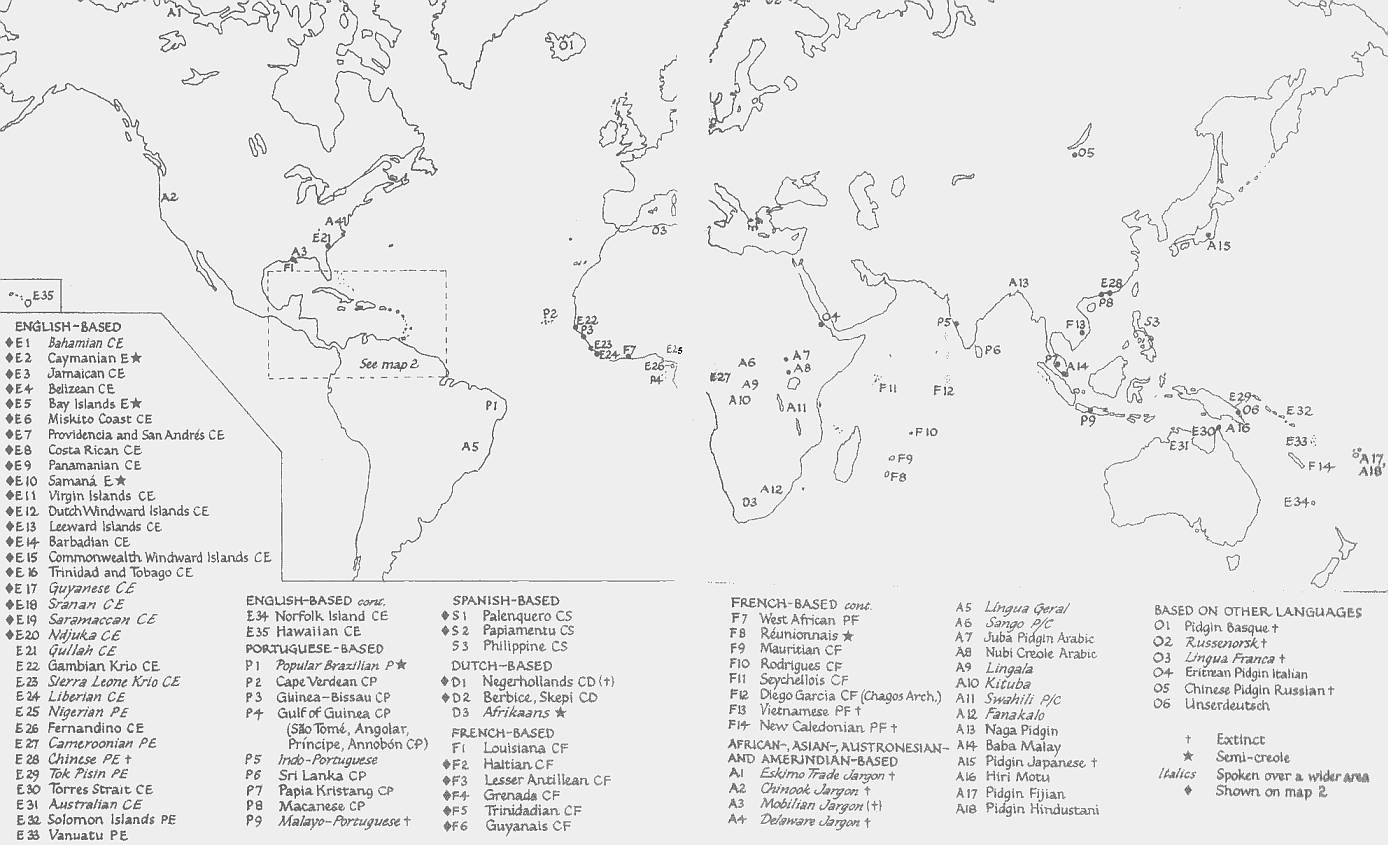{kind=link}
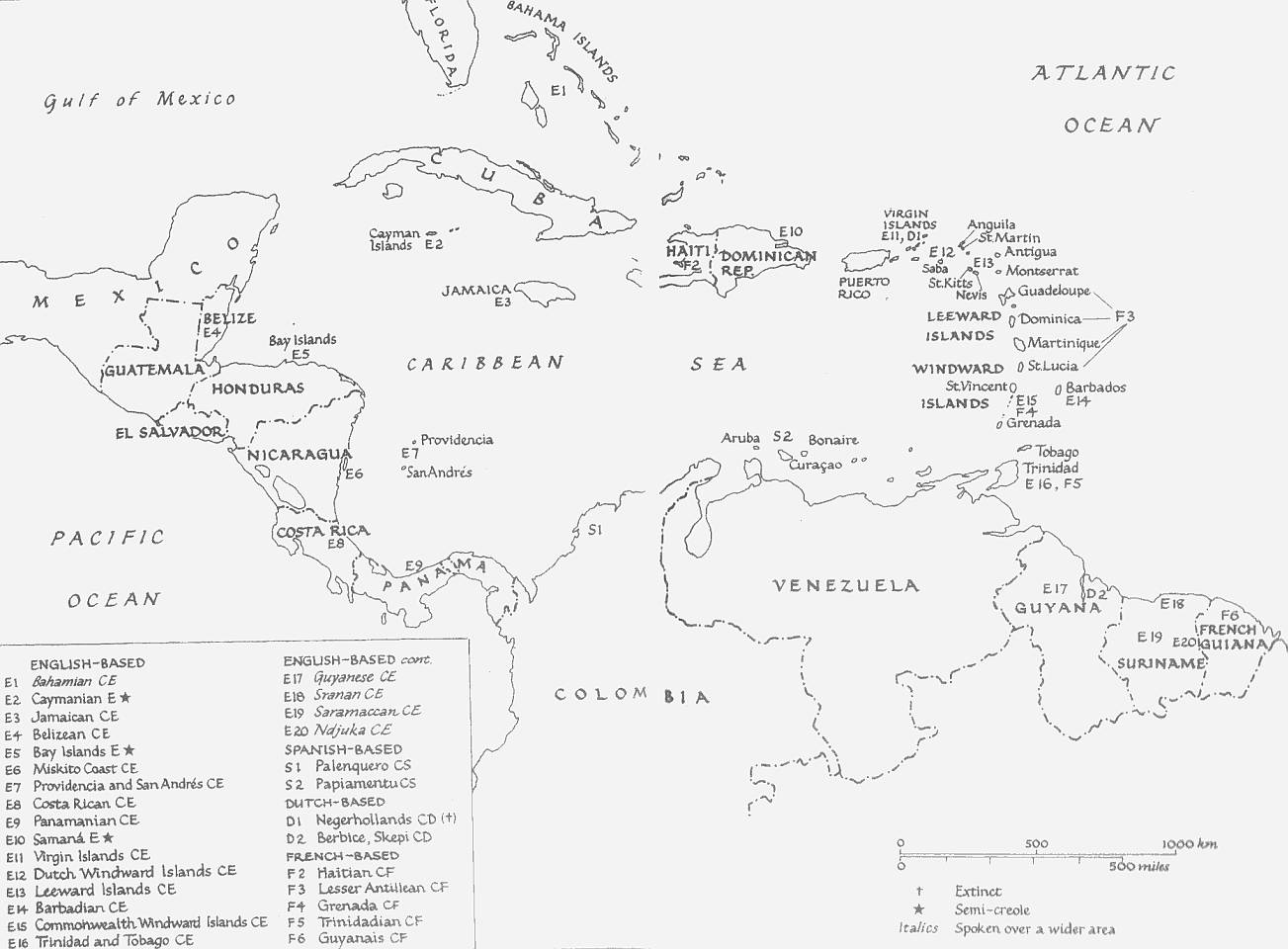{kind=link}
Creolists recognize two major groups of languages, the Atlantic and the Pacific, according to historical, geographic, and linguistic factors. The Atlantic group was established primarily during the seventeenth and eighteenth centuries in the Caribbean and West Africa, while the Pacific group originated primarily in the nineteenth. The Atlantic creoles were largely products of the slave trade in West Africa which dispersed large numbers of West Africans to the Caribbean. Varieties of Caribbean creoles have also been transplanted to the United Kingdom by West Indian immigrants, as well as to the USA and Canada. The languages of the Atlantic share a West African common substrate and display many common features . . . . / In the Pacific different languages formed the substratum and socio-cultural conditions were somewhat different from those in the Atlantic. Although the plantation setting was crucial for the emergence of pidgins in both areas, in the Pacific laborers were recruited and indentured rather than slaves. Apart from Hawai'i, a history of more gradual creolization has distinguished the Pacific from the Atlantic (particularly Caribbean) creoles, whose transition has been more abrupt.
このように地理的な分布による2分法は明快だが,両系列のあいだに複雑な関係があることを見えにくくしているきらいがあることには注意しておきたい.例えば,両系列に共有されている語彙 (savvy "to know" や picanniny "child, baby") の存在は,2つの海をまたいで活躍した船乗りの役割を考慮せずにうまく説明することはできないだろう.
・ Romain, Suzanne. Language in Society: An Introduction to Sociolinguistics. 2nd ed. Oxford: OUP, 2000.
2013-05-30 Thu
■ #1494. multilingualism は世界の常態である [bilingualism][world_languages][model_of_englishes][native_speaker_problem][linguistic_imperialism]
日本で生まれ育ち,ほぼ日本語唯一の環境で生活している多くの日本人にとって,ある人が bilingual であるとか,さらに multilingual であるなどと聞くと,驚嘆や賞賛の念が生じるのではないだろうか.同じような反応は,多くの西洋諸国でも認められる(実際には,[2013-01-30-1]の記事でみたように「#1374. ヨーロッパ各国は多言語使用国である」にもかかわらず).複数の言語を操れるということは特殊な能力あるいは偉業であり,少なくとも普通ではないとの印象を受ける.
例えば,英語史の授業で,中英語期のイングランド社会が英語,フランス語,ラテン語の trilingualism の社会だったとか,当時のイングランド王はフランス語を母語とし,英語を理解しない者も少なくなかったと紹介すると,人々はどのように互いにコミュニケーションを取っていたのか,王はどのように庶民に命令を伝えていたのかという質問が必ず出される.私自身も multilingual 社会で生活したこともないので,そうした質問の意図は理解できるし,想像力を働かせたとしても実感が湧きにくい.
しかし,古今東西の言語状況を客観的に眺めると,日本や主要な西洋諸国のような monolingual をデフォルトと考える言語観のほうが偏っているのだろうということがわかってくる.明確な数字を出すのは難しいが,世界では monolingual な言語共同体,monolingual な話者のほうが珍しいといってもよいだろう.社会言語学の3つの入門書と西江先生の著書より,同趣旨の引用を挙げる.
In view of the need for communication with neighbouring communities and government agencies, it is fair to assume that many members of most communities are multilingual. (Hudson 9)
. . . in many parts of the world an ability to speak more than one language is not at all remarkable. . . . In many parts of the world it is just a normal requirement of daily living that people speak several languages: perhaps one or more at home, another in the village, still another for purposes of trade, and yet another for contact with the outside world of wider social or political organization. These various languages are usually acquired naturally and unselfconsciously, and the shifts from one to another are made without hesitation. (Wardhaugh 93)
It has been estimated that there are some 5,000 languages in the world but only about 185 nation-states recognized by the United Nations. Probably about half the world's population is bilingual and bilingualism is present in practically every country in the world. (Romain 33)
二言語どころか,三言語,四言語はなすのが常識であって,日常生活はそんなものだと思い込んでいる社会も,世界には意外に多いのです.もちろんそれらすべてを一人ひとりの人間が同じレベルでということではない場合が多いのですが,この状況を確認しておくことは,今とても重要なことだと思います.日本では外国語が一つできただけで「すごい」と思うような感覚がありますけど./たとえば,ケニアに住むマサイ人.彼らは家では当然マサイ語を話しています.ところが彼らはマサイ人であると同時にケニア人なので,スワヒリ語と英語ができなかったら,一般的な国民としての生活ができないんですね.町に出て食堂を経営しようが,お店に勤めようが,お客さんはみんな英語やスワヒリ語を使っているわけですから./一人の人間が二つ以上の非常に異なった言語を,日常的に使い分けて話しているという社会が,実は世界には非常に多くあります.中南米では,現在でも,先住民の言語を話している人たちが数多くいます.たとえばそれがメキシコだったら,ユカタン半島のマヤ人たちはマヤ語を母語としていますが,メキシコ人ですから,公用語であるスペイン語も話せなければならないのです.(西江,p. 50--51)
日本人にとって母語以外に1つ以上の言語を操ることができるということは,ほとんどの場合,語学学習の結果としてだろう.そして,義務教育である英語学習を1つとってみても,それがいかに多くの時間と労力を要するか,皆よく知っている.したがって,ある人が multilingual だときくと,不断の学習の成果にちがいないと思い込んで,驚嘆し賞賛するのである.しかし,世界の多くの multilingual な個人は,"naturally and unselfconsciously" に複数の言語を獲得しているのである.そこに努力がまるでないというわけではないが,当該の言語共同体が要求する社会的慣習の1つとして複数の言語を習得するのである.そのような人々は,私たちが案ずるよりもずっと自然で無意識に言語を学習してしまうようだ.
いったん multilingualism が古今東西の言語共同体のデフォルトだと認識すると,むしろ monolingualism こそが説明を要する事態のように見えてくる.さらに議論を推し進めると,とりわけ英語一辺倒となりつつある現代世界の言語状況,すなわち英語の monolingualism は異常であるという意見が現われ,結果として英語帝国主義批判(linguistic_imperialism の記事を参照)やネイティヴ・スピーカー・プロブレム native_speaker_problem) なる問題が生じてきている.「#272. 国際語としての英語の話者を区分する新しいモデル」 ([2010-01-24-1]) も,多言語使用が常態であり,単一言語使用が例外的であるという認識のもとで提起されたモデルである.
・ Hudson, R. A. Sociolinguistics. 2nd ed. Cambridge: CUP, 1996.
・ Wardhaugh, Ronald. An Introduction to Sociolinguistics. 6th ed. Malden: Blackwell, 2010.
・ Romain, Suzanne. Language in Society: An Introduction to Sociolinguistics. 2nd ed. Oxford: OUP, 2000.
・ 西江 雅之 『新「ことば」の課外授業』 白水社,2012年.
2013-02-22 Fri
■ #1397. 断続平衡モデル [punctuated_equilibrium][family_tree][linguistic_area][world_languages][nostratic][sociolinguistics]
近隣言語のあいだにみられる関係を把握する方法には,伝統的に系統樹モデル (family_tree) と波状モデル (wave_theory) が提唱されている.前者が前提とするのは系統樹によって表わされる語族 (language_family) という考え方であり,後者が前提とするのは言語圏 (linguistic_area である.両者の対立については,##999,1118,1236,1302,1303,1313,1314 などの各記事で取り上げてきた.だが,実際には「#1236. 木と波」 ([2012-09-14-1]) で議論したように,両モデルは対立する関係というよりは,相互に補完すべき関係というほうが適切だろう.しかし,互いがどのような関係にあるのか,具体的にはあまり論じられていないのが現状である.
ディクソンは,両モデルを独特な形で融合させようと試みた.その結果として提案された仮説が,断続平衡モデル (punctuated equilibrium) である.
断続平衡モデルの説明は著書のあちらこちらに散らばっているが,最も重要と思われる箇所を,やや長いが,先に引用しよう.
本書で私はある仮説を立てた.一九七二年にエルドリッジとグールドがはじめて発表した生物学における断続平衡 (punctuated equilibrium) というモデル〔種の進化には変化のない長期の安定期と,それと比べて相対的に著しく急速な種分化と形態変化によって特徴づけられる中間期があるとする仮説〕に触発され,この考えを言語の発達と起源に当てはめてみたのである.人類の歴史の大部分の期間は平衡状態が保たれてきた.ある地域には,多くの,似たようなサイズや組織の政治集団があったと考えられる.そこではどの集団も他の集団の上にとりわけ大きな力を持つということはなく,それぞれが自分たちの言語または方言を話していただろう.これらの言語は,比較的平衡を保ちつつ長い期間にわたって言語圏を形づくっていく.しかし何事もまったく静止状態だったわけではない――潮の干満のようにゆったりした変化や推移はあっただろう――が,どちらかといえば小さなものだ.そして平衡が破られる時が訪れ,急激な変化が起きる.この中断は旱魃や洪水などの自然災害によるものかもしれないし,新しい道具や武器の発明,または農耕の発達,新しい土地への移動を可能にした船舶の改良,さらには帝国主義の発達や宗教的侵略によりひき起こされたものかもしれない.平衡状態を破るこのような中断は,往々にして言語の内部や言語間に根本的な変革をもたらす引き金となる.このため人々の集団や言語は拡張したり,分裂したりする.言語の系統樹モデルが適用できるのはこの,非常に長い平衡期の間に挟まっているごく短い中断期なのである.
私の推論では,平衡期の間に,同地域に存在する異なる言語間に種々の言語特徴が伝播する傾向があり,非常に長い時間をかけてではあるが,一つの共通の原型に収束する.そして拡張と分裂で特徴づけられる中断期には,一つの共通祖語から分岐して,一連の新しい言語が発達するのである.
この仮説は当然言語の起源の問題と結びつくが,それにはいくつかの可能性が考えられる.一つは,言語が大変にゆっくりと,つまり千年以上もかかってほんの数百の語や少しの文法項目を増やしていくといった具合に,未発達の言語から原始的な言語に,さらに少し進歩して前近代的言語,そして近代的言語にと進化して現代の姿になる,というものだ.しかし私の考える筋書はこれとは違う.初期の人間は比較的安定した状態のなかで生活し,認知,伝達能力を増やしていっただろうと思うが,言語は持たなかったのではないだろうか.そこに,なんらかの中断期が訪れて言語が発生したのだと考える.この過程はかなり急激に起き,二,三世紀あるいは多分二,三世代のうちには,原始的な言葉の断片というよりむしろ,現在話されている言語の複雑さに劣らないくらい十分発達した,まさに言語と呼べるものができあがったのではないかと思う.そして次にまた長い平衡期が始まる. (4--5)
著者は,この引用の後で,この2千年,特にこの数百年は格段の中断期であり,系統樹モデルでよりよく説明される諸言語の分岐が起こっているのだと主張する.また,系統樹モデルでいう祖語のとらえ方については,次のように述べている.
中断期の前後に横たわる長い言語的平衡期の間,地域の人々は比較的調和を保って生活する.たくさんの言語特徴を含んだ,多くの文化的特性が伝播波及する.同一地域の言語は互いに似通ったものとなっていく――これらの言語は一つの共通の原型に向かって収束するだろう.やがて,この収束によりもとの系統関係すなわち最後の中断期にあった系統樹の先端がぼやけていく. (129)
系統樹モデルで特徴づけられる言語の拡張と分裂という観念に基づいて,比較言語学者はしばしば祖語を,あたかも中断期に起きた急速な分裂の結果生まれたものであるかのようにみなす.だが多分そうではないだろう.中断期は長い平衡期の間に間欠的に挟まるもので,祖語を担う語族の始まりはすでに平衡期に潜在する.つまり,一つの言語圏内で言語間の収束が起き,そこから生まれた言語状態が語族の下地となったのだと思う.実際,一つの語族はたった一つの言語から生まれ出るわけではないのではないか. (138)
最後の点については,「#736. 英語の「起源」は複数ある」 ([2011-05-03-1]) でも少しく触れた問題である.
ディクソンは,オーストラリアを始めとする世界の諸言語のフィールドワークによって得た知見に基づき,断続平衡モデルをありそうな仮説であると提案したが,反証がほぼ不能という点では,彼の酷評する Nostratic 大語族 ([2012-05-16-1]) と異ならない.それでも,しばしば対立させられる系統樹モデルと波状モデルとを,大きな言語史のスパンなのなかで統合して理解しようとする姿勢には共感する.
系統樹モデルの抱える問題に関しては,第III章「系統樹モデルはどこまで有効か」が秀逸である.
・ ディクソン,R. M. W. 著,大角 翠 訳 『言語の興亡』 岩波書店,2001年.
2013-01-31 Thu
■ #1375. インターネットの使用言語トップ10 [elf][statistics][internet][demography][world_languages]
世界のインターネット使用が爆発的に増加している.Miniwatts Marketing Group による Internet World Stats: Usage and Population Statistics から Internet World Users by Language: Top 10 Languages のデータを参照すると,2000--2011年のあいだに全世界での使用者数が約5倍増えたと報告されている.では,インターネットの使用言語の分布についてはどうか.同ページより,インターネットにおけるトップ10言語の統計値を再掲しよう.2011年5月31日現在の数値である.
| TOP TEN LANGUAGES IN THE INTERNET | Internet Users by Language | Internet Penetration by Language | Growth in Internet (2000--2011) | Internet Users% of Total | World Population for this Language (2011 Estimate) |
|---|---|---|---|---|---|
| English | 565,004,126 | 43.4% | 301.4% | 26.8% | 1,302,275,670 |
| Chinese | 509,965,013 | 37.2% | 1,478.7% | 24.2% | 1,372,226,042 |
| Spanish | 164,968,742 | 39.0% | 807.4% | 7.8% | 423,085,806 |
| Japanese | 99,182,000 | 78.4% | 110.7% | 4.7% | 126,475,664 |
| Portuguese | 82,586,600 | 32.5% | 990.1% | 3.9% | 253,947,594 |
| German | 75,422,674 | 79.5% | 174.1% | 3.6% | 94,842,656 |
| Arabic | 65,365,400 | 18.8% | 2,501.2% | 3.3% | 347,002,991 |
| French | 59,779,525 | 17.2% | 398.2% | 3.0% | 347,932,305 |
| Russian | 59,700,000 | 42.8% | 1,825.8% | 3.0% | 139,390,205 |
| Korean | 39,440,000 | 55.2% | 107.1% | 2.0% | 71,393,343 |
| TOP 10 LANGUAGES | 1,615,957,333 | 36.4% | 421.2% | 82.2% | 4,442,056,069 |
| Rest of the Languages | 350,557,483 | 14.6% | 588.5% | 17.8% | 2,403,553,891 |
| WORLD TOTAL | 2,099,926,965 | 30.3% | 481.7% | 100.0% | 6,930,055,154 |
トップの言語は,いまだ英語である.トップを守っているという点では,「#1084. 英語の重要性を示す項目の一覧」 ([2012-04-15-1]) で見た通り,1980--90年代の状況と異ならない.しかし,増加率という点では,おそらく当時の勢いから大きく減退している.少なくとも,中国語,スペイン語,ポルトガル語,アラビア語,ロシア語などと比べて相対的に勢いは衰えているといえる([2009-10-08-1]の記事「#164. インターネットの非英語化」を参照).インターネット使用者数そのものでみれば,英語は早晩中国語に抜かれることは間違いないが,第3位のスペイン語との間にはまだ隔たりがある.現在は,英中ツートップの時代といえそうだ.
なお,最右列の言語話者の人口統計は U.S. Census Bureau に基づくものだというが,そこでは英語話者人口が約13億7千万とされている.これは,母語話者のみならず第2言語話者も含めた値であることは疑いない.
第2列と最右列の下の3行をみると,いかに少数の言語が世界の大部分を占めているかがわかる.関連して,「#274. 言語数と話者数」 ([2010-01-26-1]) のピラミッド状の分布を参照されたい.
ほかに英語話者人口にまつわる統計は,本ブログ内の以下の記事でも触れているので,参考までに.
・ 「#375. 主要 ENL,ESL 国の人口増加率」 ([2010-05-07-1])
・ 「#397. 母語話者数による世界トップ25言語」 ([2010-05-29-1])
・ 「#759. 21世紀の世界人口の国連予測」 ([2011-05-26-1])
2013-01-30 Wed
■ #1374. ヨーロッパ各国は多言語使用国である [bilingualism][world_languages]
ヨーロッパには各国に定められた公用語があり,国民は一様にそれを母語として用いて暮らしている,という理解は一般的なのかもしれない.確かにスイスやベルギーなどの多言語使用国もあるが,概ね,イギリス=英語,フランス=フランス語,ドイツ=ドイツ語,スペイン=スペイン語のように,国家と言語が一対一で対応しているものと理解されているのではないか.
しかし,これは誤りである.近代国家成立の過程で「1国家=1言語」という思想が一般的になり,現代もその余波のなかにあるが,事実には明らかに反している.ヨーロッパ各国は,世界のほぼすべての国や地域と同じように,紛れもなく multilingual である.アイスランド(や日本)のような例外中の例外ともいえる事実上の単一言語国はあるにせよ,である.
Ethnologue などの世界の言語統計の資料でヨーロッパの項目を一見すればわかるとおり,ヨーロッパ各国では驚くほど多くの言語が行なわれている.逆に,言語名から探るにしても,ある言語がいかに多くの異なる国で行なわれているかがわかる.「1国家=1言語」が事実に反することは明らかである.ヨーロッパの各国と言語の対応をここで細かく挙げる必要はないだろうが,主要な対応をまとめておくと便利だろうと思われるので,Trudgill (121--22) の一覧を再現しよう.以下の表の見出しの言語は,通常,ヨーロッパの特定の国家と結びつけられる主要な言語だが,その言語は右に示す国でも少数言語として行なわれている.
| German | Denmark, Belgium, France, Italy, Slovenia, Serbia, Romania, Russia, Ukraine, Kazakhstan, Hungary, Czechia, Poland | |
| Turkish | Greece, Macedonia, Serbia, Bulgaria, Romania, Moldova, Ukraine | |
| Greek | Italy, Macedonia, Albania, Bulgaria, Romania, Ukraine, Turkey | |
| Albanian | Greece, Serbia, Montenegro, Macedonia, Italy | |
| Hungarian | Austria, Serbia, Romania, Slovenia, Slovakia, Ukraine | |
| Finnish | Sweden, Norway, Russia | |
| Swedish | Finland | |
| French | Italy | |
| Polish | Lithuania, Czechia, Ukraine | |
| Bulgarian | Romania, Greece, Ukraine | |
| Danish | Germany | |
| Dutch | France | |
| Italian | Slovenia, Croatia | |
| Russian | Estonia, Latvia, Lithuania, Ukraine | |
| Ukrainian | Romania, Slovakia, Poland | |
| Slovak | Hungary, Romania, Czechia | |
| Czech | Poland, Romania, Slovakia | |
| Slovene | Austria, Italy | |
| Macedonian | Greece, Albania | |
| Lithuanian | Poland | |
| Rumanian | Greece, Bulgaria, Albania, Serbia, Macedonia |
次の表で見出しに挙がっているのは,どの国においても少数派である言語である.右側に,その言語が行なわれている国が挙げられている.
| Sami (Lapp) | Norway, Sweden, Finland, Russia | |
| Frisian | Germany, Netherlands | |
| Basque | Spain, France | |
| Catalan | Spain, France | |
| Breton | France | |
| Sorbian | Germany | |
| Kashubian | Poland | |
| Welsh | UK | |
| Gaelic | UK |
上の最後にあるように,イギリスですら英語のほか Welsh や Scottish Gaelic が部分的に行なわれているし,インド亜大陸からの移民に由来する Punjabi や Bengali などの言語も行なわれている.そのほか,Yiddish や Romany などは,ヨーロッパ大陸の多くの国で少数言語として用いられている.
おそらくヨーロッパで最も多言語の国の1つとして挙げられるのは,ルーマニアだろう.Ethnologue の Romania の項から分かるとおり,公用語の Romanian が人口の9割に用いられているものの,その他23もの言語が少数言語として行なわれている (Armenian, Aromanian, Bulgarian, Crimean Tatar, Czech, Eastern Yiddish, Gagauz, German (Standard), Gheg Albanian, Greek, Hungarian, Italian, Polish, Romani (Balkan), Romani (Carpathian), Romani (Vlax), Romanian Sign Language, Romany, Russian, Serbian, Slovak, Turkish, Ukrainian) .
・ Trudgill, Peter. Sociolinguistics: An Introduction to Language and Society. 4th ed. London: Penguin, 2000.
2012-12-01 Sat
■ #1314. 言語圏 [linguistic_area][phonetics][borrowing][world_languages][geolinguistics]
昨日の記事「#1313. どのくらい古い時代まで言語を遡ることができるか」 ([2012-11-30-1]) で,言語圏 (linguistic area) という考え方を導入した.今日は,これについてもう少し説明を加えたい.
地理的に隣り合う言語どうしが長いあいだ接触し続けると,言語特徴が互いに似通ってくるのではないかと想像することができる.多くの言語特徴が束になって言語境界を越えて往来し,結果的に周辺の言語がまとまった類似性を示すということがあるだろう.このようにして生じたと想定される地理空間のことを,言語圏と呼んでいる."linguistic area" のほか,"Sprachbund", "diffusion area", "adstratum", "convergence area" などとも呼ばれることがある.言語圏という概念は,借用されやすい語彙よりも,とりわけ音声や文法において顕著な類似性が見られる場合に言及されることが多い.
よく知られている言語圏としては,昨日の記事で触れたインド諸語に関する South Asian (or Indian subcontinent) linguistic area のほか,Balkan linguistic area, Baltic linguistic area, Ethiopian linguistic area, Mesoamerican linguistic area, Northwest coast (of North America) linguistic area などが挙げられる.とりわけ Balkan linguistic area は有名である.バルカン半島には, いずれも印欧語族には属するが,Serbo-Croatian, Macedonian, Bulgarian (Slavic) ,Romanian (Italic),Greek (Hellenic), Albanian (Albanian) など異なる語派の諸言語がひしめき合っている.系統的には互いに遠いといってよいが,何世紀ものあいだ隣接して暮らしてきたことにより,いくつかの共通の特徴をもつにいたった.これらはバルカン的特徴 (Balkanisms) と呼ばれている.バルカン的特徴は,たとえ系統的には近い関係であっても圏外の諸言語には観察されない特徴である.その1つとして,Albanian, Bulgarian, Macedonian, Romanian に共通して見られる冠詞の後置を挙げておこう.他のヨーロッパ諸語で冠詞の後置をおこなうのは地理的に遠く離れた北欧諸語のみであるから,バルカン言語圏を想定しない限り,この特徴は説明できない.
もう1つ有名なのは,南アフリカで話されている Sotho, Zulu, Xhosa などの Bantu 諸語や,Bushman, Khoikhoi などの Khoisan 諸語にまたがって行なわれている舌打ち音 (click) である.世界の言語のなかでも非常に珍しい発音であり,これが1地域の諸言語に共通して用いられているのは偶然とは考えられない.[2012-03-17-1]の記事で取り上げた「#1055. uvular r の言語境界を越える拡大」も言語圏に関する話題である.
以上,主としてトラッドギル (188--93) を参考にして執筆した.
・ Campbell, Lyle and Mauricio J. Mixco, eds. A Glossary of Historical Linguistics. Salt Lake City: U of Utah P, 2007.
・ P. トラッドギル 著,土田 滋 訳 『言語と社会』 岩波書店,1975年.
2012-11-30 Fri
■ #1313. どのくらい古い時代まで言語を遡ることができるか [family_tree][comparative_linguistics][typology][origin_of_language][reconstruction][linguistic_area][indo-european][world_languages]
言語学では,言語の過去の姿を復元する営みを続けてきた.かつての言語がどのような姿だったのか,諸言語はどのように関係していたか.過去の言語資料が残っている場合には,直接その段階にまで遡ることができるが,そうでない場合には理論的な方法で推測するよりほかない.
これまでに3つの理論的な手法が提案されてきた.(1) 19世紀に発展した比較言語学 (comparative_linguistics) による再建 (reconstruction),(2) 言語圏 (linguistic area) における言語的類似性の同定,(3) 一般的な類似性に基づく推測,である.(1), (2), (3) の順に,遡ることができるとされる時間の幅は大きくなってゆくが,理論的な基盤は弱い.Aitchison (166) より,関連する言及を引用しよう.
Comparing relatives --- comparing languages which are descended from a common 'parent' --- is the oldest and most reliable method, but it cannot go back very far: 10,000 years is usually considered its maximum useful range. Comparing areas --- comparing similar constructions across geographical space --- is a newer method which may potentially lead back 30,000 years or more. Comparing resemblances --- comparing words which resemble one another --- is a highly controversial new method: according to its advocates, it leads back to the origin of language.
比較言語学の系統樹モデルでたどり着き得る極限はせいぜい1万年だというが,これすら過大評価かもしれない.印欧語族でいえば,仮により古くまで遡らせる Renfrew の説([2012-05-18-1]の記事「#1117. 印欧祖語の故地は Anatolia か?」を参照)を採るとしても,8500年程度だ(Nostratic 大語族という構想はあるが疑問視する向きも多い;nostratic の記事を参照).再建の手法は,理論的に研ぎすまされてきた2世紀近くの歴史があり,信頼をおける.
2つ目,言語圏の考え方は地理的に言語間の類似性をとらえる観点であり,言語項目の借用の分布を利用する方法である.例えば,インドの諸言語では,語族をまたいでそり舌音 (retroflex) が行なわれている.比較的借用されにくい特徴や珍しい特徴が地理的に偏在している場合には,言語圏を想定することは理に適っている.系統樹モデルに対抗する波状モデル (wave_theory) に基づく観点といってよいだろう.
最近,Johanna Nicholas が "population typology" という名のもとに,新しい言語圏の理論を提起している.人類の歴史的な人口移動はアフリカを基点として主に西から東への移動だったが,それと呼応するかのように一群の言語項目が西から東にかけて特徴的な分布を示すことがわかってきた.例えば,inclusive we と exclusive we の対立,名詞複数標識の中和,所有物の譲渡の可否による所有表現の差異などは,東へ行けば行くほど,それらを示す言語の割合は高まるという.もし Nicholas の理論が示唆するように,人類の移動と特定の言語項目の分布とが本当に関連づけられるのだとすれば,人類の移動の歴史に匹敵する古さまで言語を遡ることができることになる.そうすれば,数万年という幅が視野に入ってくる.予想されるとおり,この理論は広く受け入れられているわけではないが,大きく言語の歴史を遡るための1つの新機軸ではある.この理論に関する興味深い案内としては,Aitchison (169--72) を参照.
3つ目は,まったく異なる諸言語間に偶然の一致を多く見いだすという手法(というよりは幸運)である.例えば,原義として「指」を意味していたと想定される tik という形態素が,一見すると関連のない多くの言語に現われるという事実が指摘されている.そして,この起源は10万年前に遡り得るというのである.しかし,これは単なる偶然として片付けるべきもので,歴史言語学の理論としてはほとんど受け入れられていない.
比較言語学で最もよく研究されている印欧語族においてすら,正確な再建の作業は困難を伴う.population typology も,うまくいったとしても,特定の言語項目の大まかな再建にとどまらざるをえないだろう.現時点の持ち駒では,遡れる時間の幅は,大目に見て1万年弱というところではないか.
・ Aitchison, Jean. The Seeds of Speech: Language Origin and Evolution. Cambridge: CUP, 1996.
2012-11-02 Fri
■ #1285. FLASHで英語史略年表 [timeline][history][flash][web_service][world_languages][loan_word][link]
マンチェスター大学の発信する,子供向け教育コンテンツを用意しているこちらのサイトのなかに,Timeline of English Language なるFLASHコンテンツを発見した.粗い英語史年表で,あくまで導入的な目的での使用を念頭に置いたものだが,話の種には使えるかもしれないので紹介しておく.
言語に関する他のコンテンツへのリンクは,こちらにある.次のものなどは,結構おもしろい.
・ World Language Map
・ Borrowing Game
簡易年表ということでいえば,A brief chronology of English なるものを見つけた.本ブログ内では,timeline を参照.
2012-10-25 Thu
■ #1277. 文字をもたない言語の数は? [world_languages][writing][statistics]
世界の言語の数を把握するのが困難なことは,「#270. 世界の言語の数はなぜ正確に把握できないか」 ([2010-01-22-1]) や「#1060. 世界の言語の数を数えるということ」 ([2012-03-22-1]) の記事で取り上げてきた.私は,言語学概説書の記述や Ethnologue の統計に従って,現在,世界で行なわれている言語は6000--7000個ほどと認識しているが,あくまで仮の数字である.この数のうちどれほどの言語が文字をもっているのかに関心があるが,これまで文献上で概数の言及すらみつけたことがなかった.
先日,Crystal (17) に,軽い言及を見つけた.そこでは,4割ほどの言語(計2000言語を越える)が文字に付されたことがない言語であると述べられている.だが,この推計の根拠が何であるかが知りたいところである.また,逆算すると世界の言語の数は約5000個となるが,これは Crystal の他書での推計よりも少ないのではないか.また,文字をもたない言語数でなく,文字を読み書きできない話者数で考えると,世界人口の何割くらいになるのだろうか.ある言語に文字が備わっているということと,その話者がその文字を読み書きできることとは別の問題であるはずだ.いろいろと疑問がわき出して止まらないが,言語の数にもまして,実際上,数え上げは困難を極めるだろう.
勘としては,Crystal の言及よりもずっと多くの言語が無文字ではないかと思っていたので,意外ではあった.大した根拠のないのが勘というものだが,「#274. 言語数と話者数」 ([2010-01-26-1]) の統計から見当をつけて,話者数が数千人以下の言語に無文字言語が多いのではないかと踏んでいた.
通時的な観点からは,文字をもつ言語がどのくらいの速度で増えていったのか,世界の人々の識字率がどのように推移してきたのかという設問も興味深い.前者は文字文化の伝播の問題,後者は識字能力の独占の歴史や読み書き教育の推進といった問題にかかわる.どの問題1つをとっても,すぐには解答を得られないだろう.
本格的に調べれば,適当な概数の提案に行き当たるのかもしれない.この問題に触れている文献をご存じの方がいましたら,ぜひ教えてください.
関連して,文字の発生については「#41. 言語と文字の歴史は浅い」 ([2009-06-08-1]) ,書き言葉の話し言葉に対する二次的な性質については「#748. 話し言葉と書き言葉」 ([2011-05-15-1]) を参照.
・ Crystal, David. How Language Works. London: Penguin, 2005.
2012-05-17 Thu
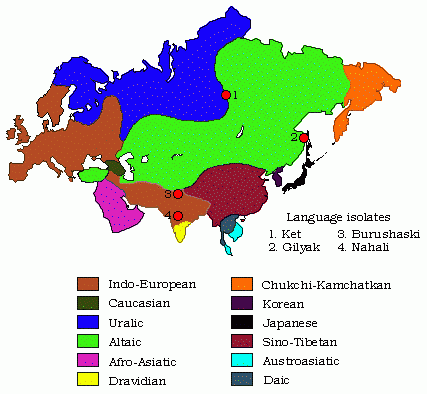
■ #1116. Nostratic を超えて Eurasian へ [language_family][indo-european][nostratic][eurasian][world_languages][map][family_tree][comparative_linguistics]
昨日の記事[2012-05-16-1]で「#1115. Nostratic 大語族」の仮説 (The Nostratic Theory) を紹介したが,現在,歴史言語学および言語類型論の関心から,さらに上を行く壮大な言語系統図の構想が抱かれている.
1つには,Nostratic 大語族とは独立した大語族として,North Caucasian, Sino-Tibetan, Yeniseian, Eyak-Athapascan の4語族を含む Sino-Caucasian あるいは Dene-Caucasian 大語族が提案されている([2011-02-08-1]の記事「#652. コーカサス諸語」の一番下の図を参照).それに加えて,アメリカ・インディアンのほとんどの言語を含むといわれる Amerind 大語族(この語族の設定自体が論争の的となっている)の仮説が唱えられている.Ruhlen は,究極の Eurasian 祖語を仮設し,上記の大語族間の系統関係を次のように想定した(Gelderen, pp. 31 の図をもとに作成).
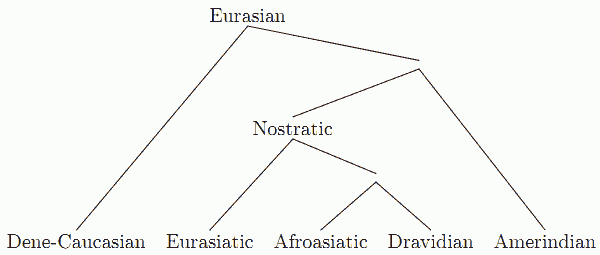
Eurasian を仮定したとしても,アフリカの3語族,オーストラリアの語群,太平洋の語群は,これに包含されず,孤立している.いずれも Eurasian 祖語以前に分裂したものと想定される.
Geldren (29--32) は,英語史概説書としては珍しく,このような大語族の仮説にまで踏み込んで記述しており,有用.世界の諸語族については,[2010-05-30-1]の記事「#398. 印欧語族は世界人口の半分近くを占める」や,Ethnologue より language family index が参考になる.Oxford 提供のユーラシア大陸の簡単な言語地図も参照. *
・ Gelderen, Elly van. A History of the English Language. Amsterdam, John Benjamins, 2006.
・ Ruhlen, Merritt. The Origin of Language. New York: Wiley, 1994.
{kind=link}
2012-05-16 Wed
■ #1115. Nostratic 大語族 [language_family][indo-european][nostratic][comparative_linguistics][reconstruction][world_languages][map]
19世紀,印欧語比較言語学は飛躍的に進歩を遂げたが,印欧語族内にとどまらず,語族と語族の間の2言語を比較する試みは,すでに同世紀より見られた.しかし,異なる語族からの2言語の比較ではなく,語族レベルでの比較が本格的になされたのは20世紀後半になってからのことである.1964年,Illich-Svitych と Dolgopolsky という2人の比較言語学者が,独立して重要な論文を発表した.そこでは,Indo-European, Afro-Asiatic (Hamito-Semitic), Kartvelian, Uralic, Altaic, Dravidian の6つの主要語族が比較され,その同系が唱えられた.これらを包括する大語族の名前として,1903年に Pedersen が提案していた "Nostratic" というラベルが与えられた.現在,Nostratic 大語族には,さらに5つの語族 (Eskimo-Aleut, Chukchi-Kamchatkan, Niger-Kordofanian, Nilo-Saharan, Sumerian) が付け加えられている.
Nostratic 大語族を比較言語学的に検証する上での大きな問題の1つは,比較する語彙素の選定である.Dolgopolsky は,もっとも借用されにくく安定性のある語彙素として15語を選び出した ("I, me", "two, pair", "thou, thee", "who, what", "tongue", "name", "eye", "heart", "tooth", verbal NEG (negation and prohibition), "finger/toe nail", "louse", "tear" (n.), "water", "dead") .それから各言語の対応する語彙素を比較し,祖語の形態を再建 (reconstruction) していった.
一方,Illich-Svitych は,Nostratic 祖語の形態と統語の再建も試み,次のような銘句を作詩すらしている.

Nostratic 大語族の仮説 (The Nostratic Theory)は,単一語族を超える規模の比較として,ある程度の根拠に支えられているものとしては,現在,唯一のものである.しかし,比較すべき語彙素の選定や,再建の各論は激しい論争の的となっている.この仮説に熱心な研究者もいれば,比較言語学の限界の前にさじを投げる研究者も多い.19世紀,20世紀と踏み固められてきたようにみえる印欧語比較言語学ですら多くの問題を残しており,その起源について決定的な説がない([2011-01-24-1]の記事「#637. クルガン文化と印欧祖語」を参照)のだから,Nostratic の仮説など途方もないと考えるのも無理からぬことである.しかし,ズームアウトして視野を広げることで見えてくる細部の特徴もあるかもしれない.それが,野心的な Nostratic 仮説の謙虚な狙いの1つといえるかもしれない.
以上は Kaiser and Shevoroshkin の論文を参照して執筆した. *
・ Kaiser, M. and V. Shevoroshkin. "Nostratic." Annual Review of Anthropology 17 (1988): 309--29.
{kind=link}
2012-03-22 Thu
■ #1060. 世界の言語の数を数えるということ [sociolinguistics][world_languages][contact][saussure]
Ethnologue の冒頭では,現在の世界の言語の数について,次のように謳われている."An encyclopedic reference work cataloging all of the world’s 6,909 known living languages." ただし,論者によってはその半分の数を挙げるものもあり,他にも様々な数が提案されており,確定することは難しい.世界の言語の数を数えることの困難な理由は,[2010-01-22-1]の記事「#270. 世界の言語の数はなぜ正確に把握できないか」で取り上げた.また,関連する話題を「#274. 言語数と話者数」 ([2010-01-26-1]) で考察した.今回は,議論をもう一歩推し進めたい.
現在,世界にいくつの言語があるのか.この問いは言語についての最も素朴な疑問のようにも思われるが,実のところ,この素朴さのなかには非常に厄介な問題が含まれている.言語を数えるということは,当然ながら言語が複数あることが前提となっている.また,言語が複数あるということは,ある言語と他の言語との境界が明確であり,それぞれが個別化,個体化,個数化していることが前提となっている.しかし,自然状態におかれている言語は,通常,境がぼんやりとしているものではないか.特に隣接する言語であれば,互いに混交して,中間的な特徴を備えた言語が間に入っているものではないか.
しかし,このように本来は音の連続である茫洋とした言語の平面に,強引に線引きをする主がいる.そして,私たちは,その主の存在を疑わずに,むしろ前提としているからこそ,標記の問題がいかにも素朴な疑問に聞こえるのである.その線引きの主とは,近代国家である.田中 (150) の適格な表現を引用しよう.
近代はまた,ことばとことばとの間に境界を設けて,その数を数えられるものにした.言語の数が数えられるものになったのは,主として国家の成立による./言語の数はしかし,本来は――自然の状態では――数えられないものであった.数えようにも,まず名前がついていなかった.ヨーロッパでは,こうしたいわゆる「俗語」,すなわち,ラテン語以外の言語が文字で書かれるようになり,その文法が書かれることによって,「○○語」が確立されたのである.
つまり,言語を数えるということは,「国家=言語」という等式を無意識のうちに前提としている発想であり,言語の自然状態を観察していては決して生まれてこない発想だということになる.では,上記の素朴な疑問は,素人的な疑問として片付けてしまってよいのだろうか.否である.実のところ,近代科学としての言語学こそが,「国家=言語」を前提として成立してきたのである.もっと言えば,「国家≧言語(学)」ですらあった.田中 (154--55) を引こう.
近代言語学に成立の動機を与えたのは,国家であった.国家が,言語に境界を与え,○○語という,区切りのある単位を与えたからである.そして,言語学は,このような,国家によって提供された,いわゆる個別言語 (Einzelsprache) の研究に従事してきた.少し誇張して言うと,国家が個別言語を創り出し――その統合,均質化の過程によって――それを言語学が当然のようにおしいただいて研究したのであるから,この点から言うと,言語学は国家に従属したのである.
このように,近代言語学は国家観を強烈に含みながら創始された.自然状態の言語を,国家という概念を介入させず,ありのままに観察するという態度は,20世紀のソシュール言語学を待たねばならなかったのである.20世紀言語学は,いよいよ国家をはぎ取った状態で言語そのものを観察し始めたのだが,世紀の後半になって国家なり社会なりの服を,改めて今度は意識的に,裸の言語に着させるという試みを開始した.
21世紀に入った言語学は,いまだ標題の素朴な疑問に明確な解答を与えうる段階にない.しかし,言語学は,何もしてこなかったわけではない.むしろ,素朴な外見を装った標題の疑問の本質は,素朴どころか,政治のどろどろした問題をはらんでいるという事実を,言語学はありありと示してきたのである.
・ 田中 克彦 『言語学とは何か』 岩波書店〈岩波新書〉,1993年.
2011-05-23 Mon
■ #756. 世界からの借用語 [loan_word][lexicology][pde_characteristic][world_languages]
現代英語の最大の特徴の1つである cosmopolitan vocabulary については pde_characteristic を始めとする記事で,また時にそれを "asset" とみなす見方については批判的に[2009-09-27-1], [2010-05-22-1]の記事などで扱ってきた.関連して,現代英語語彙が借用語に満たされていることについては,[2010-05-16-1]にリンクを張った諸記事や loan_word の各記事で話題にしてきた.
英語の語彙がいかに世界的かをざっと知るには,[2009-11-14-1]の記事「現代英語の借用語の起源と割合 (2)」のグラフをみるのが手っ取り早いが,単語とその借用元言語を具体的にリスト化しておけば,なお手っ取り早い.そこで,主として Crystal ( The English Language, p. 40 and Encyclopedia, pp. 126--27 ) に基づき,他の例も多少付け加えながら,借用元言語で世界一周ツアーしてみたい.
| Language | Words |
|---|---|
| Afrikaans | apartheid, gnu, impala, indri, kraal, mamba, trek, tse-tse |
| Aleutian | parka |
| American Indian | chipmunk, moccasin, pow wow, skunk, squaw, totem, wigwam |
| Anglo-Saxon | God, Sunday, beer, crafty, gospel, house, rain, rainbow, sea, sheep, understand, wisdom |
| Arabic | algebra, assassin, azimuth, emir, ghoul, harem, hashish, intifada, mohair, sheikh, sherbet, sultan, zero |
| Araucanian | coypu, poncho |
| Australian | boomerang, budgerigar, dingo, kangaroo, koala, wallaroo, wombat |
| Brazilian | abouti, ai, birimbao, bossa nova, favela, jaguar, manioc, piranha |
| Canadian Indian | pecan, toboggan |
| Chinese | chopsuey, chow mein, cumquat, kaolin, ketchup, kung fu, litchi, sampan, tea, tycoon, typhoon, yen (=desire) |
| Czech | howitzer, pistol, robot |
| Dutch | bluff, cruise, easel, frolic, knapsack, landscape, poppycock, roster, slim |
| Eskimo | anorak, igloo, kayak |
| Finnish | sauna |
| French | anatomy, aunt, brochure, castle, cellar, challenge, chocolate, crocodile, cushion, debt, dinner, entrance, fruit, garage, grotesque, increase, jewel, justice, languish, medicine, montage, moustache, passport, police, precious, prince, sacrifice, sculpture, sergeant, table, trespass, unique, venison, victory, vogue, voyeur |
| Gaelic | banshee, brogue, galore, leprechaun |
| German | angst, dachshund, gimmick, hamburger, hamster, kindergarten, lager, nix, paraffin, plunder, poodle, sauerkraut, snorkel, strafe, waltz, yodel, zinc |
| Greek | anonymous, catastrophe, climax, coma, crisis, dogma, euphoria, lexicon, moussaka, neurosis, ouzo, pylon, schizophrenia, stigma, therm, thermometer, tonic, topic |
| Haitian | barbecue, cannibal, canoe, peccary, potato, yucca |
| Hawaiian | aloha, hula, lei, nene, ukulele |
| Hebrew | bar mitzvah, kibbutz, kosher, menorah, shalom, shibboleth, targum, yom kippur, ziggurat |
| Hindi | bungalow, chutney, dekko, dungaree, guru, gymkhana, jungle, pundit, pyjamas, sari, shampoo, thug |
| Hungarian | cimbalom, goulash, hussar, paprika |
| Icelandic | geyser, mumps, saga |
| Irish | blarney, brat, garda, taoiseach, whiskey |
| Italian | arcade, balcony, ballot, bandit, ciao, concerto, falsetto, fiasco, giraffe, lava, mafia, opera, scampi, sonnet, soprano, studio, timpani, traffic, violin |
| Japanese | bonsai, geisha, haiku, hara-kiri, judo, kamikaze, karate, kimono, shogun, tycoon, zaitech |
| Javanese | batik, gamelan, lahar |
| Korean | hangul, kimchi, makkoli, ondol, won |
| Latin | alibi, altar circus, aquarium, circus, compact, diocese, discuss, equator, focus, frustrate, genius, include, index, interim, legal, monk, nervous, onus, orbit, quiet, ulcer, ultimatum, vertigo |
| Malagasy | raffia |
| Malay | amok, caddy, gong, kapok, orang-outang, sago, sarong |
| Maori | haka, hongi, kakapo, kiwi, pakeha, whare |
| Nahuatl | axolotl, coyote, mescal, tomato, tortilla |
| Norwegian | cosy, fjord, krill, lemming, ski, slalom |
| Old Norse | both, egg, knife, low, sky, take, they, want |
| Persian | bazaar, caravan, divan, shah, shawl, sofa |
| Peruvian | condor, inca, llama, maté, puma, quinine |
| Polish | horde, mazurka, zloty |
| Polynesian | kava, poe, taboo, tapa, taro, tattoo |
| Portuguese | buffalo, flamingo, marmalade, pagoda, veranda |
| Quechuan | llama |
| Russian | agitprop, borsch, czar, glasnost, intelligentsia, perestroika, rouble, samovar, sputnik, steppe, troika |
| Sanskrit | swastika, yoga |
| Scottish | caber, cairn, clan, lock, slogan |
| Serbo-Croat | cravat, silvovitz |
| Spanish | albatross, banana, bonanza, cafeteria, cannibal, canyon, cigar, cobra, cork, dodo, guitar, hacienda, hammock, junta, marijuana, marmalade, molasses, mosquito, potato, rodeo, sherry, sombrero, stampede, supremo |
| Swahili | bongo, bwana, harmattan, marimba, safari, voodoo |
| Swedish | ombudsman, tungsten, verve |
| Tagalog | boondock, buntal, ylang-ylang |
| Tamil | bandicoot, catamaran, curry, mulligatawny, pariah |
| Tibetan | Koumiss, argali, lama, polo, shaman, sherpa, yak, yeti |
| Tongan | taboo |
| Turkish | aga, bosh, caftan, caviare, coffee, fez, jackal, kiosk, shish kebab, yoghurt |
| Vietnamese | ao dai, nuoc mam |
| Welsh | coracle, corgi, crag, eisteddfod, hwyl, penguin |
| Yiddish | chutzpah, gelt, kosher, nosh, oy vay, schemozzle, schmaltz, schmuk |
・ Crystal, David. The English Language. 2nd ed. London: Penguin, 2002.
・ Crystal, David. The Cambridge Encyclopedia of the English Language. 2nd ed. Cambridge: CUP, 2003.
2010-12-19 Sun
■ #601. 言語多様性と生物多様性 [world_languages][language_death][ecolinguistics]
[2010-06-02-1]の記事で言語の多様性指数 ( diversity index ) について触れた.これは言語密集度と言い換えてもよいだろうが,興味深いことに,この指数は赤道に近いほど高く,両極に近いほど低い傾向がある(柴崎, p. 17).言語多様性指数で世界トップのパプアニューギニアを例に取れば,国土面積でいうと世界の0.4%を占めるにすぎないところに世界総人口の0.055%ほどの人が住んでいるのだが,そこに830もの言語(総言語数の12%)がひしめいている.一方で,例えばグリーンランドは比較的広大だが人口密度は低く,言語数も少ない ( see [2010-01-26-1] ).さらに興味深いことに,言語の死 ( see language_death ) の進行率が不釣り合いに高いのも,やはり赤道に近い地域である.言語密集度と言語消滅可能性は連動していることが知られており,高い値が赤道寄りに偏って分布していることは明らかである(柴崎,p. 21).
赤道に近いほど言語の多様性と消滅可能性が高いというのは,より広く社会的関心を引きつけている別の話題を想起させる.それは生物種の多様性と消滅可能性である.生物種の多様性も赤道直下をピークとして,両極へ向かうほど密集度が低くなっており,消滅可能性もそれと足並みを揃えている.再びパプアニューギニアを例に取ると,国内に約40万種,世界の全生物種の約5%が生息しているとされ,消滅の度合いも大きいという(柴崎, p. 21).
ここまで言語多様性と生物多様性の分布が一致すると,ヒトの言語が生態系の一部であることを認めざるを得ない.[2010-01-30-1]で言及したように ecolinguistics という呼称が現われてきていることも納得できるというものである.英語史の観点からこの状況を考察するとどうなるだろうか.言語生態系という考え方が生じている現代の社会においては,英語に代表される世界語は,かつて世界語と呼ばれ得た諸言語とは異なる役割と責任を負うことになるだろう.言語生態系という視点は,今後の英語を動かす,つまり新しい英語史を駆動する力の一つになってゆくかもしれない.
世界の人口と関連する話題については世界の人口が有益.
・ 柴崎 礼士郎 編 『言語文化のクロスロード --- 沖縄からの事例研究 ---』 文進印刷,2009年.
2010-10-12 Tue
■ #533. 未知の言語 Koro がインド北西部で発見される [language_death][world_languages][map]
10月5日付けの CNN.com より Previously unknown language emerges in India という記事を読んだ.インド北西部の Arunachal Pradesh 州で約800人の話者によって話される言語が発見されたという記事だ.National Geographic の資金援助を受けた the Living Tongues Institute for Endangered Languages の言語学者が,Enduring Voices Project の現地調査によって明らかにした(調査自体は2008年のこと).
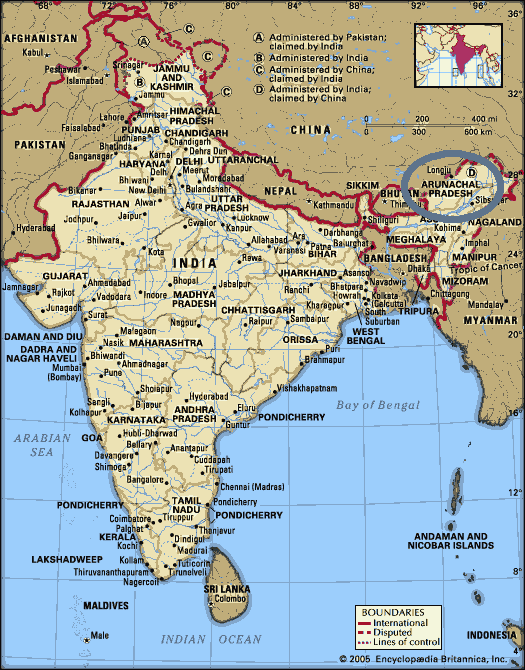
この言語は Sino-Tibetan 語族の Tibeto-Burman 語派に属するとされる.Tibet-Burman 語派にはアジアの400ほどの言語が含まれ,インドだけでも同語族から150ほどの言語が確認されている.Koro 族の言語については真の意味で未知なわけではなかったが,これまでは Hruso-Aka 語と方言関係にあると(当の言語の話者の間ですら!)信じられており,別個の言語として認識されていなかった.それが調査員による Koro 族の戸別訪問により,明らかに周囲の言語とは異なる言語であることが確認されたのである.Ethnologue report for Hruso を見てみると,Koro が Hruso とは別個の言語らしいという示唆はあり,この点を調査員は明らかにしたということだろう.予期せぬ発見だったわけではないようだ.
この地は "the black hole of the linguistic world" あるいは "a language hotspot where there is room to study rich, diverse languages, many unwritten or documented" とみなされており,今後も未調査の言語が掘り出される可能性が高い.インドは[2010-06-02-1]の記事でみた言語多様性指数でいえば,0.940で世界第9位である.また,国内の言語数でいえば,445言語で第4位.この国には今後も言語数が加算されてゆくポテンシャルは十分にある.
今回の調査で Ethnologue の主張する世界の言語数6909に1が足されることになるのだろうが ( see [2010-01-22-1] ) ,Koro 語は約800人の話者しか有しておらず,しかも20歳以下の話者がほとんどいないことから,皮肉にも「発見」された瞬間から危機言語の仲間入りを果たすことになった ( see [2010-01-28-1] ) .記事の題名だけを見るとポジティブな話題に思えるが,実態は [2010-02-09-1]で紹介した Bo 語の消滅などの言語の死と紙一重の差しかない.
奇しくも昨日から名古屋で COP10 (国連生物多様性条約第10回締約国会議)が開催されている.紙面では関連する話題が掲載されているが,実際のところ日本では一部の企業などを除き,関心度はそれほど高くないようである.生物多様性ですら人々の関心を集められないのだから,いわんや言語多様性をや,である.
National Geographic の関連記事やビデオクリップはこちらのリンクからどうぞ.
2010-06-02 Wed
■ #401. 言語多様性の最も高い地域 [world_languages][japanese]
[2010-05-29-1], [2010-05-30-1]の記事に引き続き,Ethnologue からの話題.Table 6. Distribution of living languages by country は,世界の諸地域を言語多様性の高い順に並び替えたものである.言語の多様性指数 ( diversity index ) とは,その地域における言語の密度といってもよいが,その地域からランダムに二人を選び出したときにその二人が異なる母語をもつ確率として定義される.取り得る最大の値は1で,このとき同じ母語をもつ人は皆無ということになる.最小値は0で,このとき皆が同じ母語をもつということになる.例えば,日本の多様性指数は,対象となっている224地域のなかでも下から数えた方が早く,202位で 0.028 という値である.日本は言語的に非常に同質的な国であるといえる.
多様性指数のトップ10を見やすく抜き出してみよう.
| Rank | Country | Diversity index | Living languages |
|---|---|---|---|
| 1 | Papua New Guinea | 0.990 | 830 |
| 2 | Vanuatu | 0.974 | 114 |
| 3 | Solomon Islands | 0.967 | 71 |
| 4 | Central African Republic | 0.959 | 82 |
| 5 | Democratic Republic of the Congo | 0.948 | 217 |
| 6 | Tanzania | 0.947 | 129 |
| 7 | Cameroon | 0.946 | 279 |
| 8 | Chad | 0.944 | 133 |
| 9 | India | 0.940 | 445 |
| 10 | Mozambique | 0.932 | 53 |
Papua New Guinea を筆頭に,いずれの言語も 0.9 を優に超えているのだから,日本に住んでいる者からすると驚くべき言語的多様性の地域である.上位国では英語や英語ベースのピジン ( pidgin ) が共通語として使用されている地域が多いが,英語ならずとも何か共通語がないと国内コミュニケーションにすら齟齬をきたすという状況が想像される ( see [2009-10-21-1] ).南国好きの私は Vanuatu と Solomon Islands に訪れた経験があり,対外国人コミュニケーションが英語でなされることは体験していたが,国内コミュニケーションにも英語やピジンが活躍しているだろうことはこの数値から容易に推測される.だが,まさか言語多様性で世界2位と3位を誇る国だとは思っていなかった・・・.
PNG の言語数 830 というのも想像を絶する.多様性指数と言語数は独立した数値なので,今度は言語数の多い順にソートした表を示そう.
| Rank | Country | Diversity index | Living languages |
|---|---|---|---|
| 1 | Papua New Guinea | 0.990 | 830 |
| 2 | Indonesia | 0.816 | 722 |
| 3 | Nigeria | 0.869 | 521 |
| 4 | India | 0.940 | 445 |
| 5 | United States | 0.319 | 364 |
| 6 | Mexico | 0.137 | 297 |
| 7 | China | 0.509 | 296 |
| 8 | Cameroon | 0.946 | 279 |
| 9 | Democratic Republic of the Congo | 0.948 | 217 |
| 10 | Australia | 0.124 | 207 |
やはり PNG がトップを走るが,言語数でいえば Indonesia が猛追している.Nigeria と India も確かに言語数の多い国として言及されることが多い.多様性指数と言語数の両方でトップ10に入っているのは,PNG, Democratic Republic of the Congo, Cameroon の3国である.
いやはや,世界は広い.
2010-05-30 Sun
■ #398. 印欧語族は世界人口の半分近くを占める [indo-european][world_languages][statistics][demography]
印欧語族 ([2009-06-17-1]) は世界最大の語族であり,世界最大の母語話者人口を誇っている.他書(何だったか失念)では印欧語族は世界の 1/4 を占めると記されており,私もその概数をそのまま信じて本ブログでも [2009-08-05-1] で言及したことがあった.ところが Ethnologue の Table 4. Major language families of the world によると相当に異なる数値が提示されている.印欧語族に属する諸言語は,世界人口の 45.67% に相当する27億余りの人々によって話されているという.1/4 どころかほぼ半数であり,大きな違いだ.人口統計は様々な前提・仮定の上ではじき出されるものなのでなかなか評価が難しいが,Ethnologue に基づく限り,2位のシナ・チベット語族 ( Sino-Tibetan ) の人口 12.5 億人を大きく引き離してのトップである.昨日の記事[2010-05-29-1]でまとめた母語話者数による言語のランキング表でも,トップ10言語のなかで7言語までが印欧語族に属するので,世界における影響力が知れよう.
Ethnologue の Summary by language family によると,世界の言語は116の語族 ( language family ) に分かれ,そのなかの主要6語族のみで世界の言語の 2/3 を占め,世界の人口の 5/6 を占めるという.
また,Ethnologue の Indo-European の区分 では,印欧語族を Albanian, Armenian, Baltic, Celtic, Germanic, Greek, Indo-Iranian, Italic, Slavic の9語派に下位分類していることがわかる.
2010-05-29 Sat
■ #397. 母語話者数による世界トップ25言語 [statistics][world_languages][demography]
このブログでも何度も参照している Ethnologue の16版が2009年に出版された.オンライン版の Ethnologue で世界の言語にまつわる様々な数値を眺めていたら,英語の母語話者人口について新事実に出くわした.Table 3. Languages with at least 3 million first-language speakers によると,英語はスペイン語に僅差で追い越され,2位から3位に転落していたのである.すっかり見逃していた.
以下は上記のページから取った上位25位までの言語のデータを見やすくまとめたもの.右隅の列には,1996年出版の Ethnologue 13版に基づく数値を比較のために添えた( Graddol, p. 8 から埋められた部分のみ).Hindi については,Hindi と Urdu を一つとして扱った場合の数値をかっこ内に示した.
| Rank | Language | Primary Country | Countries | Speakers (16th ed, 2009) | (13th ed, 1996) |
|---|---|---|---|---|---|
| 1 | Chinese | China | 31 | 1,213 million | 1,123 |
| 2 | Spanish | Spain | 44 | 329 | 266 |
| 3 | English | United Kingdom | 112 | 328 | 322 |
| 4 | Arabic | Saudi Arabia | 57 | 221 | 202 |
| 5 | Hindi | India | 20 | 182 (242.6 with Urdu) | (236 with Urdu) |
| 6 | Bengali | Bangladesh | 10 | 181 | 189 |
| 7 | Portuguese | Portugal | 37 | 178 | 170 |
| 8 | Russian | Russian Federation | 33 | 144 | 288 |
| 9 | Japanese | Japan | 25 | 122 | 125 |
| 10 | German | Germany | 43 | 90.3 | 98 |
| 11 | Javanese | Indonesia | 5 | 84.6 | |
| 12 | Lahnda | Pakistan | 8 | 78.3 | |
| 13 | Telugu | India | 10 | 69.8 | |
| 14 | Vietnamese | Viet Nam | 23 | 68.6 | |
| 15 | Marathi | India | 5 | 68.1 | |
| 16 | French | France | 60 | 67.8 | 72 |
| 17 | Korean | South Korea | 33 | 66.3 | |
| 18 | Tamil | India | 17 | 65.7 | |
| 19 | Italian | Italy | 34 | 61.7 | 63 |
| 20 | Urdu | Pakistan | 23 | 60.6 | |
| 21 | Turkish | Turkey | 36 | 50.8 | |
| 22 | Gujarati | India | 20 | 46.5 | |
| 23 | Polish | Poland | 23 | 40.0 | |
| 24 | Malay | Malaysia | 14 | 39.1 | 47 |
| 25 | Bhojpuri | India | 3 | 38.5 |
この十数年の間で,トップを走っていた中国語と英語の母語話者数の伸び率は少ないが,4位につけていたスペイン語の伸び率は24%近くになる.一方,十数年前には3位につけていたロシア語が激減した.(ただし,これについては数え方の問題があるようで,別の独立した統計によれば当時のロシア語の母語話者数は 155 million ということだった.Ethnologue の 288 million とは著しい差である.)日本語はなんとかトップ10以内の座を守っているが,ヨーロッパの主要語とされるドイツ語やフランス語は低迷気味だ.
爆発的な影響力を誇るのはインドの言語である.Hindi を筆頭に,Telugu, Marathi, Tamil, Gujarati, Bhojpuri がトップ25位に入っている.トップ50位までに,主としてインドで行われている言語が14も入っているのだから驚きだ.Bengali や Lahnda などを合わせるとインド亜大陸の猛威を感じざるを得ない.
使用されている国の数でいうと,英語が群を抜いている.母語話者の数値だけでは表現されない実力があるということだろう.同様に,非母語話者の数を加えて評価すれば,相当に見栄えの異なるランキング表になるだろう.
英語使用国の人口増加率については[2010-05-07-1]を参照.
・ Graddol, David. The Future of English? The British Council, 1997. Digital version available at http://www.britishcouncil.org/learning-research-futureofenglish.htm.
Powered by WinChalow1.0rc4 based on chalow