2012-11-11 Sun
■ #1294. 英語語源分析ツールの夢 [etymology][lexicology][statistics][web_service]
英文を投げ込むと,各単語(あるいは形態素)が語源別に色づけされて返ってくるような語源分析ツールがあるとよいなと思っている.しかも,各単語に語源辞書のエントリーへのリンクが張られているような.語彙研究や英語教育にも活かせるだろうし,出力を眺めているだけでもおもしろそうだ.このようなツールを作成するには精度の高い形態素分析プログラムと語源データベースの完備が欠かせないが,完璧を求めてしまうと実現は不可能だろう.
同じことを考える人はいるようだ.例えば,Visualizing English Word Origins はツールを公開こそしていないが,Douglas Harper による Online Etymology Dictionary に基づく自作のツールで,いくつかの短い英文一節を色づけ語源分析している.テキストの分野別に本来語やラテン語の割合が何パーセントであるかなどを示しており,およそ予想通りの結果が出されたとはいえ,実におもしろい.この分析に関して,The Economist に記事があった.
また,今は残念ながらリンク切れとなっているが,かつて http://huco.artsrn.ualberta.ca/~mburden/project/message.php?thread=Shakspere&id=174 に簡易的な語源分析ツールが公開されていた.こちらの紹介記事 にあるとおりで,なかなか有望なツールだった.私も少し利用した記憶があるのだが,どこへ消えてしまったのだろうか.
英語語源関連のオンライン・コンテンツも増えてきた.以下にいくつかをまとめておく.
・ 「#485. 語源を知るためのオンライン辞書」: [2010-08-25-1]
・ Etymology 関連の外部リンク集
・ 「#361. 英語語源情報ぬきだしCGI(一括版)」: [2010-04-23-1]
・ Behind the Name: The Etymology and History of First Names
・ Behind the Name: The Etymology and History of Surnames
・ 語源別語彙統計に関する本ブログ内の記事: lexicology loan_word statistics
・ Etymologic! The Toughest Word Game on the Web: 英語語源クイズ.
2012-11-02 Fri
■ #1285. FLASHで英語史略年表 [timeline][history][flash][web_service][world_languages][loan_word][link]
マンチェスター大学の発信する,子供向け教育コンテンツを用意しているこちらのサイトのなかに,Timeline of English Language なるFLASHコンテンツを発見した.粗い英語史年表で,あくまで導入的な目的での使用を念頭に置いたものだが,話の種には使えるかもしれないので紹介しておく.
言語に関する他のコンテンツへのリンクは,こちらにある.次のものなどは,結構おもしろい.
・ World Language Map
・ Borrowing Game
簡易年表ということでいえば,A brief chronology of English なるものを見つけた.本ブログ内では,timeline を参照.
2012-10-26 Fri
■ #1278. BNC を中心とするコーパス研究関連のリンク集 [corpus][bnc][link][web_service][lltest]
コーパス言語学の勢いが止まらない.分野が分野だけに,関連情報はウェブ上で得られることが多く,便利なようにも思えるが,逆に情報が多すぎて,選択と判断に困る.せめて自分のためだけでも便利なリンク集をまとめておこうと思うのだが,学界のスピードについて行けない.私が最もよく用いる BNC に関連するものを中心に,断片的ではあるが,リンクを張る.リンク集をまとめる労を執るよりは,芋づる式にたどるかキーワード検索のほうが効率的という状況になりつつある・・・.
1. BNC インターフェース
・ BNCweb (要無料登録)
・ BYU-BNC (要無料登録)
・ BNC ( The British National Corpus )
2. BNC のレファレンス・ガイド
・ Quick Reference for Simple Query Syntax (PDF)
・ Reference Guide for the British National Corpus (XML Edition)
・ 上の Reference Guide の目次
* 6.5 Guidelines to the Wordclass Tagging
* The BNC Basic (C5) Tagset
* 9.8 Simplified Wordclass Tags
* 9.7 Contracted forms and multiwords
* 1 Design of the Corpus
* 9.6 Text and genre classification code
3. コーパス関連の総合サイト
・ David Lee による Bookmarks for Corpus-based Linguists
* Corpora, Collections, Data Archives
* Software, Tools, Frequency Lists, etc.
* References, Papers, Journals
* Conferences & Project
4. hellog 内の記事
・ 「#568. コーパスの定義と英語コーパス入門」: [2010-11-16-1]
・ 「#506. CoRD --- 英語歴史コーパスの情報センター」: [2010-09-15-1]
・ 「#308. 現代英語の最頻英単語リスト」: [2010-03-01-1]
・ コーパス関連記事: corpus
・ BNC 関連記事: bnc
・ COCA 関連記事: coca
5. 計算ツール
・ Corpus Frequency Wizard
・ Paul Rayson's Log-likelihood Calculator
・ VassarStats
・ hellog の「#711. Log-Likelihood Tester CGI, Ver. 2」: [2011-04-08-1]
・ Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee, and Ylva Berglund Prytz. Corpus Linguistics with BNCweb : A Practical Guide. Frankfurt am Main: Peter Lang, 2008.
2012-10-18 Thu
■ #1270. 類義語ネットワークの可視化ツールと類義語辞書 [web_service][thesaurus][link][synonym][dictionary][polysemy]
[2010-08-11-1]の記事「#471. toilet の豊富な婉曲表現を WordNet と Visuwords でみる」で,オンラインで利用できる類義語ネットワークの可視化ツールを2点紹介したが,同趣旨のツールとして WordNet のデータベースに基づいた Graph Words を追加したい.以下に,関連するツールのリンクを挙げておく.
・ Graph Words: フリー.出力がシンプル.
・ Visuwords: フリー.出力が凝っている.
・ Visual Thesaurus: 有料だがトライアルあり.出力が凝っている.
あわせて,今では通常の類義語辞典もオンラインで豊富にアクセスできるが,いくつか挙げておこう.
・ Merriam-Webster Thesaurus: 語義ごとに豊富な類義語群が得られる.
・ The Free Online Dictionary, Thesaurus and Encyclopedia: 語義もついており,単語学習によい.
・ Thesaurus.com: 手早く類義語リストを得られる.
・ HyperDictionary.com: 上に同じ.
類義語リストを簡便に得られるスタンドアロンの辞書ソフトウェアとしては,以下のものを利用することがある.
・ WordWeb:英語辞書ソフトウェアとして人気がある.
・ TheSage's English Dictionary and Thesaurus:インターフェースがきれい.
歴史英語類義語辞典は,以下の二つ.
・ HTOED (Historical Thesaurus of the Oxford English Dictionary)
・ TOE (A Thesaurus of Old English)
類義語ネットワークの可視化ツールをいじっているうちに,単にキーワードに関連する語彙のネットワークを示すものとしてだけでなく,キーワードの語義の広がりを示すものとして利用することができることを発見した.例えば,Graph Words で多義語 "star" のネットワークを覗いてみると,およそ区別される語義ごとに枝のグループができていることがわかる.各語義が,単語置換による示唆というかたちではあるが,荒っぽく「定義」されているといえる(以下,拡大は画像をクリック).
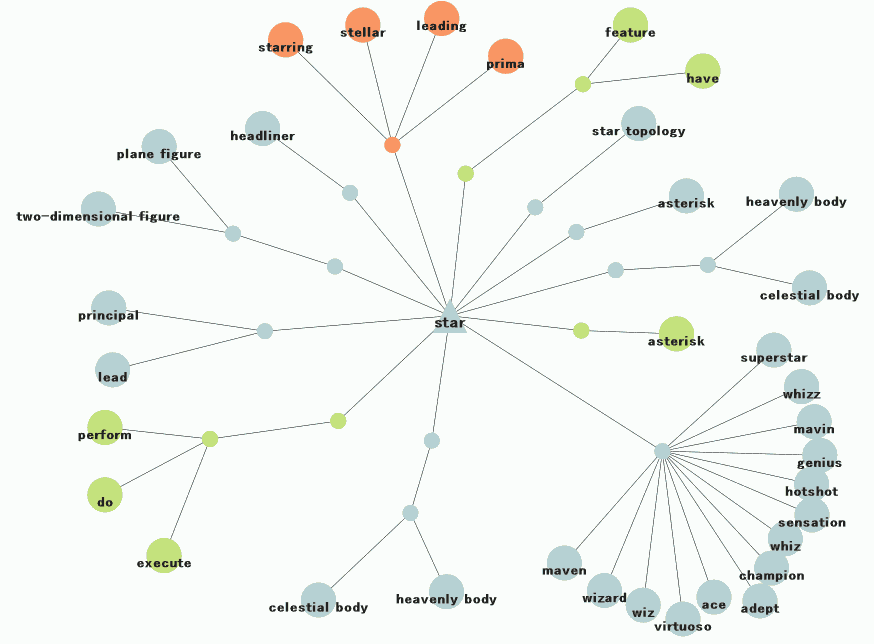
"star" のような多義語については,類義語可視化ツールは語義の広がりを見せてくれる,辞書代わりのツールとしても有効なのではないか.
2012-08-19 Sun
■ #1210. 中英語のフランス借用語の一覧 [french][loan_word][lexicology][me][web_service][cgi]
中英語にフランス語から借用された単語リストはどの英語史概説書にも掲載されているが,本ブログでも簡便に参照できるように一覧化ツールを作ってみた.
フランス借用語の簡易データベースを,Baugh and Cable (169--74, 177) に基づいて作成し,意味その他の基準で9個のカテゴリーに分けた (Miscellany; Fashion, Meals, and Social Life; Art, Learning, Medicine; Government and Administration; Law; Army and Navy; Christian Church; 15th-Century Literary Words; Phrases) .954個の語句からなるデータを納めたテキストファイルはこちら.ここから,カテゴリーごとに10語句をランダムに取り出したのが,以下のリストである.このリストに飽き足りなければ,
をクリックすれば,次々にランダムな一覧が生成される.「こんな語句もフランス語だったとは」と驚かせるプレゼン用途にどうぞ.
- Miscellany
- Fashion, Meals, and Social Life
- Art, Learning, Medicine
- Government and Administration
- Law
- Army and Navy
- Christian Church
- 15th-Century Literary Words
- Phrases
please, curious, scandal, approach, faggot, push, fierce, double, purify, carpenter
train, pullet, mustard, sugar, enamel, mackerel, sole, fashion, jollity, russet
pulse, color, cloister, pen, pillar, ceiling, base, lattice, cellar, sulphur
rebel, retinue, reign, duchess, allegiance, treaty, nobility, court, tax, statute
mainpernor, arson, judge, property, culpable, amerce, convict, bounds, innocent, legacy
arm, array, arms, soldier, chieftain, portcullis, havoc, brandish, stratagem, combat
incense, faith, abbey, passion, immortality, cardinal, friar, legate, virtue, convent
ingenious, appellation, destitution, harangue, prolongation, furtive, sumptuous, combustion, diversify, representation
according to, to hold one's peace, without fail, in vain, on the point of, subject to, to make believe, by heart, at large, to draw near
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
2012-07-31 Tue
■ #1191. Pronunciation Search [pronunciation][web_service][cgi][ame][dictionary]
綴字ではなく発音で引ける(電子)辞書はいくつかあるが,ある発音をもつ語を一覧にするなどの目的には,今ひとつ使い勝手が悪い.特に,本格的なリストを作るというよりは,軽く単語例を列挙したいなどの日常的な目的には,もっと簡便に使える検索ツールが欲しい.そこで,Grady Ward's Moby からダウンロードできる Moby Pronunciator の圧縮ファイルに含まれている,無償で無制限に利用可能な発音データベース The Carnegie Mellon Pronouncing Dictionary を下敷きにした発音検索ツールを作成した.このデータベースは110935個のエントリーからなるアメリカ英語の発音辞書である(3MB以上あるデータファイルはこちら).
検索の指定は,Carnegie Mellon Pronouncing Dictionary の発音表記に対して正規表現で与えるという仕様である.発音表記の凡例は以下の通り.音素間は半角スペースで区切られている.また,強勢は母音表記に続く 0 (no stress), 1 (primary stress), 2 (secondary stress) で示される.例えば,dictionary の発音表記は,"D IH1 K SH AH0 N EH2 R IY0" などとなる.なお,発音検索は,[2012-06-29-1]の記事で公開した「#1159. MRC Psycholinguistic Database Search」の機能の1部を利用することもできる.
| Phoneme | Example | Translation |
|---|---|---|
| AA | odd | AA D |
| AE | at | AE T |
| AH | hut | HH AH T |
| AO | ought | AO T |
| AW | cow | K AW |
| AY | hide | HH AY D |
| B | be | B IY |
| CH | cheese | CH IY Z |
| D | dee | D IY |
| DH | thee | DH IY |
| EH | Ed | EH D |
| ER | hurt | HH ER T |
| EY | ate | EY T |
| F | fee | F IY |
| G | green | G R IY N |
| HH | he | HH IY |
| IH | it | IH T |
| IY | eat | IY T |
| JH | gee | JH IY |
| K | key | K IY |
| L | lee | L IY |
| M | me | M IY |
| N | knee | N IY |
| NG | ping | P IY NG |
| OW | oat | OW T |
| OY | toy | T OY |
| P | pee | P IY |
| R | read | R IY D |
| S | sea | S IY |
| SH | she | SH IY |
| T | tea | T IY |
| TH | theta | TH EY T AH |
| UH | hood | HH UH D |
| UW | two | T UW |
| V | vee | V IY |
| W | we | W IY |
| Y | yield | Y IY L D |
| Z | zee | Z IY |
| ZH | seizure | S IY ZH ER |
2012-07-18 Wed
■ #1178. MED Spelling Search [dictionary][cgi][web_service]
MED (Middle English Dictionary) が2001年にオンライン化されてから,中英語の研究環境はとてつもなく便利になった.見出し語と異綴りの検索に関しては,通常のインターフェースのほか正規表現対応インターフェースも用意されており,自由度が高い.
しかし,いずれの検索結果の出力も,見出し語とそのエントリーへのリンクが張られているだけで,異綴りの種類を一覧したい場合には不便である.それを確認するには,いちいちエントリーの本文へ飛ばなければならない.そこで,Perl5相当の正規表現に対応し,出力結果で見出し語とともに異綴りも確認できる検索ツールを作成した.綴字に注目したMED検索にどうぞ.
検索対象は,辞書の各エントリーの "headword and forms" 部分である.正規表現検索では,辞書上の母音に付された長音記号や短音記号のは無視される.<æ, Æ> は <A>, <þ, Þ, ð, ð> は <T>, <ȝ, Ȝ> は <3>, <œ> は <O> として検索文に指定できる.例として,一般の見出し語検索には "^taken\b" を,-li 副詞を一覧するには "li\b \(adv\.\)" を指定(前後の引用符は除く).
2012-07-03 Tue
■ #1163. オンライン語彙データベース DICT.ORG [web_service][dictionary][lexicology][link]
The DICT Development Group による DICT.ORG は,ウェブ上の様々な語彙データベースや辞書を利用するための統一的な仕様を提供するサービスである.登録されている語彙データベースを利用するインターフェースはこちら.
辞書というよりは語彙データベースと呼ぶ方が適切なのは,ある語の定義や発音などを与えてくれるというよりは,ある条件(主として綴字上の条件)を満たす語の一覧を作成するのが得意だからだ.ある特定の目的で行なわれる語彙研究のために,単語リストを準備するのに役立つ.
DICT.ORG で利用できる辞書はオンライン上で公開されている無料のものが多いが,語彙データベースとしての使用を前提とすれば,機能的には十分である.条件指定の方法("strategy" と呼ばれる;以下参照)は,電子辞書などでお馴染みの,綴字の完全一致,前方一致,後方一致,部分一致のほか,正規表現も完全にサポートしており,近似した綴字の語を取り出す Levenshtein distance 検索や Soundex algorithm 検索も実装されている.
Strategy Description
--------- -----------
first : Match the first word within headwords
exact : Match headwords exactly
re : POSIX 1003.2 (modern) regular expressions
last : Match the last word within headwords
nprefix : Match prefixes (skip, count)
soundex : Match using SOUNDEX algorithm
lev : Match headwords within Levenshtein distance one
word : Match separate words within headwords
suffix : Match suffixes
regexp : Old (basic) regular expressions
substring : Match substring occurring anywhere in a headword
prefix : Match prefixes
出力が非常にシンプルであり,まさに語の一覧という体裁なので,この一覧を拾い上げて,別の語彙ツールに投げ込むという使い方もできる.語彙研究に役立つツールを開発するためのベースとして利用できるのではないか.ウェブ上のインターフェースのほか,ローカルからは,Perl で書かれた dict というクライアントなどを経由して利用できる.
DICT.ORG からは,英語の語彙データベースや辞書への役立つリンクが張られていて便利.特に Dictionary Database Site や Other Database Information や Linguistic Data Resources on the Internet: Dictionaries, Lexica, and Lexical Resources の情報が有用.
2012-06-29 Fri
■ #1159. MRC Psycholinguistic Database Search [cgi][web_service][lexicology][frequency][statistics]
昨日の記事[2012-06-28-1]で紹介した英語語彙データベース MRC Psycholinguistic Database を,本ブログ上から簡易検索するツールを作成した.実際には検索ツールというよりは,MRC Psycholinguistic Database を用いると,こんなことができるということを示すデモ版にすぎず,出力結果は10行のみに限定してある.本格的な使用には,昨日示したページからデータベースと検索プログラムをダウンロードするか,ウェブ上のインターフェース (Online search (answers limited to 5000 entries) or Online search (limited search capabilities)) よりどうぞ.
以下,使用法の説明.SQL対応で,テーブル名は "mrc2" として固定.フィールドは以下の27項目:ID, NLET, NPHON, NSYL, K_F_FREQ, K_F_NCATS, K_F_NSAMP, T_L_FREQ, BROWN_FREQ, FAM, CONC, IMAG, MEANC, MEANP, AOA, TQ2, WTYPE, PDWTYPE, ALPHSYL, STATUS, VAR, CAP, IRREG, WORD, PHON, DPHON, STRESS.各パラメータが取る値の詳細については,原データファイルの仕様を参照のこと(仕様中に示されている各種統計値はそれ自身が非常に有用).select 文のみ有効.以下に,典型的な検索式を例として載せておく.
# 文字数で語彙を分別
select NLET, count(NLET) from mrc2 group by NLET;
# 音素数で語彙を分別
select NPHON, count(NPHON) from mrc2 group by NPHON;
# 音節数で語彙を分別
select NSYL, count(NSYL) from mrc2 group by NSYL;
# -ed で終わる形容詞を頻度順に
select WORD, K_F_FREQ from mrc2 where WTYPE = 'J' and WORD like '%ed' order by K_F_FREQ desc;
# 2音節の名詞,形容詞,動詞を強勢パターンごとに分別 (「#814. 名前動後ならぬ形前動後」 ([2011-07-20-1]) 及び「#801. 名前動後の起源 (3)」 ([2011-07-07-1]) を参照)
select WTYPE, STRESS, count(*) from mrc2 where NSYL = 2 and WTYPE in ('N', 'J', 'V') group by WTYPE, STRESS;
# <gh> の綴字で終わり,/f/ の発音で終わる語
select distinct WORD, DPHON from mrc2 where WORD like '%gh' and DPHON like '%f';
# 不規則複数形を頻度順に
select WORD, K_F_FREQ from mrc2 where IRREG = 'Z' and TQ2 != 'Q' order by K_F_FREQ desc;
# 馴染み深く,具体的な意味をもつ語
select distinct WORD, FAM from mrc2 where FAM > 600 and CONC > 600;
# イメージしやすい語
select distinct WORD, IMAG from mrc2 order by IMAG desc limit 30;
# 「有意味」な語
select distinct WORD, MEANC, MEANP from mrc2 order by MEANC + MEANP desc limit 30;
# 名前動後など品詞によって強勢パターンの異なる語
select WORD, WTYPE, DPHON from mrc2 where VAR = 'O';
2012-06-28 Thu
■ #1158. MRC Psycholinguistic Database [web_service][lexicology][frequency][statistics]
心理言語学の分野ではよく知られた英語の語彙データベースのようだが,「#1131. 2音節の名詞と動詞に典型的な強勢パターン」 ([2012-06-01-1]) と「#1132. 英単語の品詞別の割合」 ([2012-06-02-1]) で参照した Amano の論文中にて,その存在を知った.MRC Psycholinguistic Database は,150837語からなる巨大な語彙データベースである.各語に言語学的および心理言語学的な26の属性が設定されており,複雑な条件に適合する語のリストを簡単に作り出すことができるのが最大の特徴だ.特定の目的をもった心理言語学の実験に用いる語彙リストを作成するなどの用途に特に便利に使えるが,検索パラメータの組み合わせ方次第では,容易に語彙統計学の研究に利用できそうだ.
パラメータは実に多岐にわたる.文字数,音素数,音節数の指定に始まり,種々のコーパスに基づく頻度の範囲による絞り込みも可能.心理言語学的な指標として,語の familiarity, concreteness, imageability, meaningfulness なども設定されている.品詞などの統語カテゴリーはもちろん,接頭辞,接尾辞,略語,ハイフン形などの形態カテゴリーの指定もできる.発音や強勢パターンの指定にも対応している.組み合わせによって,およそのことができるのではないかと思わせる精緻さである.
全データベースと検索プログラムはこちらからダウンロードできるが,プログラムをコンパイルするなど面倒が多いので,ウェブ上のインターフェースを用いるのが便利である.2つのインターフェースが用意されており,それぞれ機能は限定されているが,通常の用途には十分だろう.
・ Online search (answers limited to 5000 entries): パラメータの細かい指定が可能だが,出力結果は5000語までに限られる.
・ Online search (limited search capabilities): 出力結果の数に制限はないが,言語学的なパラメータの細かい指定(綴字や発音のパターンの直接指定など)はできない.
・ Amano, Shuichi. "Rhythmic Alternation and the Noun-Verb Stress Difference in English Disyllabic Words." 『名古屋造形大学名古屋造形芸術大学短期大学部紀要』 15 (2009): 83--90.
2012-03-19 Mon
■ #1057. LAEME Index of Sources の検索ツール Ver. 2 [laeme][web_service][cgi][dialect]
[2011-11-25-1]の記事「#942. LAEME Index of Sources の検索ツール」で SQL による検索用 CGI を公開した.最近,研究で LAEME を本格的に使う機会があり,検索用のデータベースに少しく情報を追加した.そこで,上位互換となる Ver. 2 を作ったので,公開する.
追加した情報は,PERIOD, COUNTY, DIALECT の3フィールド.PERIOD は,もともとの IOS で与えられていたテキストの DATE をもとに,半世紀区切りで大雑把に区分しなおしたもの.C13b2--C14a1 など区分のまたがる場合には,早いほうをとって C13b と読み替えた."ca. 1300" なども同様に,早いほうへ倒して C13b とした.DATE において C13, C14 など半世紀で区切れない年代が与えられている場合には,C13, C14 のようにそのまま残した.
COUNTY は,LOC に与えられていた情報をもとに,3文字の略字表記で示した.DIALECT は,所属する州 (county) をもとに大雑把に N (Northern), NWM (North-West Midland), NEM (North-East Midland), SEM (South-East Midland), SWM (South-West Midland), SW (Southwestern), SE (Southeastern) の7方言に区分したものである.方言線は州境と一致しているわけではないし,方言線そのものの選定も,「#130. 中英語の方言区分」 ([2009-09-04-1]) や「#1030. England の現代英語方言区分 (2)」 ([2012-02-21-1]) で見たように,難しい.したがって,今回の DIALECT の付与も,[2009-09-04-1]の中英語方言地図に大雑把に照らしての仮のものである.参考までに,COUNTY と DIALECT の対応表はこちら.
使用法は[2011-11-25-1]の旧版と同じで,テーブル名は "ios" (for "Index of Sources") で固定.フィールドは,全部で23フィールド (ID, MS, TEXT_ID, FILE, DATE, PERIOD, TEXT, GRID, LOC, COUNTY, DIALECT, COMMENT, SAMPLING, TAGGED_WORDS, PLACE_NAMES, PERSONAL_NAMES, WORDS, SCRIPT, OTHER, STATUS, BIBLIO, CROSS_REF, URL) .select 文のみ有効.以下,典型的な検索式を挙げておく.
# 各 PERIOD に振り分けられたテキストの数
select distinct PERIOD, count(*) from ios group by PERIOD;
# 各 COUNTY に振り分けられたテキストの数
select distinct COUNTY, count(*) from ios group by COUNTY;
# 各 DIALECT に振り分けられたテキストの数
select distinct DIALECT, count(*) from ios group by DIALECT;
# DIALECT/PERIOD ごとに,所属するテキストの多い順にリストアップ
select distinct DIALECT, PERIOD, count(*) from ios group by DIALECT, PERIOD order by count(*) desc;
# Worcestershire のテキストを取り出し,PERIOD 順に諸情報を羅列
select TEXT_ID, FILE, MS, COUNTY, PERIOD, TAGGED_WORDS from ios where COUNTY = 'WOR' order by PERIOD;
2012-03-03 Sat
■ #1041. COCA の "ANALYZE TEXT" [coca][corpus][web_service][academic_word_list][text_tool]
COCA ( Corpus of Contemporary American English ) を運営する Mark Davies 氏が,[2012-01-08-1]の記事「#986. COCA の "WORD AND PHRASE . INFO"」で紹介した機能 (Frequency List) に加え,英文を投げ込むとCOCAベースで各語に関する諸情報を色づけして返してくれるサービス WORD AND PHRASE . INFO, ANALYZE TEXT を公開した.
適当な英文を投げ込むと,各単語が頻度レベルによって色分けされた状態で返される.上位500語までの超高頻度語は青,3,000語までの高頻度語は緑,それ以下の頻度の語は黄色で示されるほか,academic word が赤字として返される.文章内でのそれぞれの割合も示され,その語彙リストを出すことも容易だ.各語はクリッカブルで,クリックすると用例のサンプルが KWIC で右下ペインに表示される.また,左下ペインには類義語が現われる.以下は,昨日の記事「#1040. 通時的変化と共時的変異」 ([2012-03-02-1]) に引用した英文を投げ込んでのスクリーンショット.
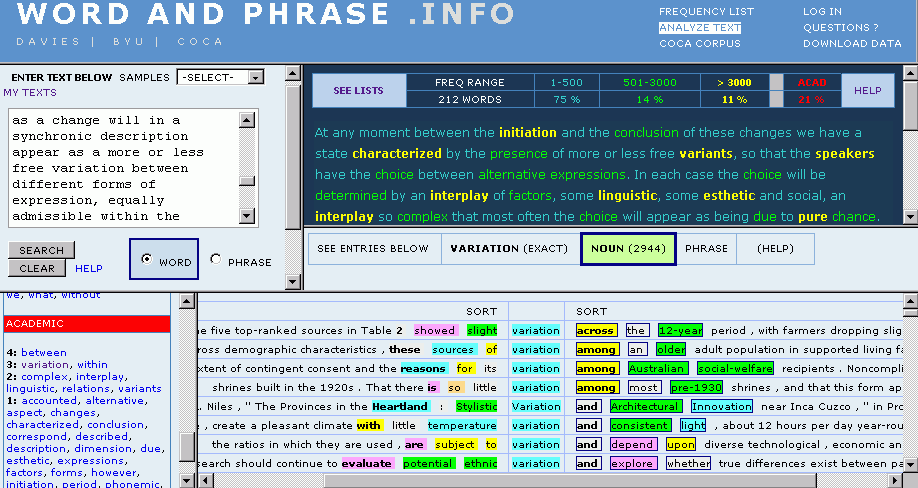
英文を書くときには collocation や synonym を調べながら書くことが多いので,使い方次第では英作文学習に威力を発揮しそうだ.ある文章の academic 度を判定するのにも使える.Academic Word List に含まれる語彙の含有度ということでいえば,[2010-12-30-1]の記事「#612. Academic Word List」で挙げた The AWL Highlighter も類似ツールだ.
2012-01-08 Sun
■ #986. COCA の "WORD AND PHRASE . INFO" [coca][corpus][dictionary][synonym][collocation][semantic_prosody][intensifier][web_service]
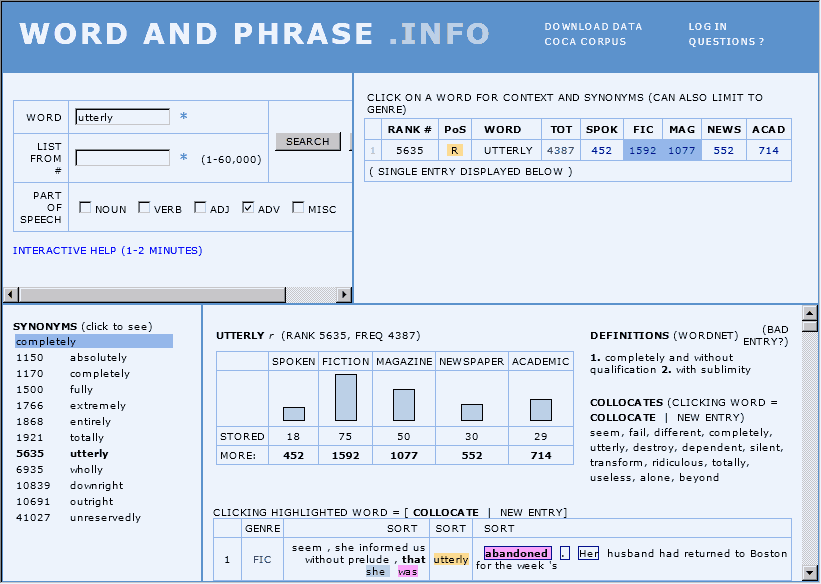
COCA ( Corpus of Contemporary American English ) を運営する Mark Davies 氏が,年末に,COCAベースで語に関する諸情報を一覧できるサービス WORD AND PHRASE . INFO を公開した.語(lemma 頻度で上位60,000語以内に限る)を入力すると,ジャンルごとの生起頻度やそのコンコーダンス・ラインはもとより,WordNet に基づいた定義や類義語群までが画面上に現われる.ほとんどの項目がクリック可能で,さらなる機能へとアクセスできる.インターフェースが直感的で使いやすい.
類義語研究や collocation 研究には相当に役立つ仕様になったのではないか.例えば,semantic_prosody を扱った[2011-03-12-1]の記事「#684. semantic prosody と文法カテゴリー」で,強意語 utterly, absolutely, perfectly, totally, completely, entirely, thoroughly についての研究を紹介したが,WORD AND PHRASE . INFO で utterly を入力すれば,これらの類義語群が左下ウィンドウに一覧される.あとは,各語をクリックしてゆくだけで,頻度や collocation の詳細が得られる.このような当たりをつけるのに効果を発揮しそうだ.
2011-12-09 Fri
■ #956. COCA N-Gram Search [cgi][web_service][coca][corpus][collocation][n-gram]
##953,954,955 の記事で,最近公開された COCA ( Corpus of Contemporary American English ) の n-gram データベースを利用してみた.COCA に現われる 2-grams, 3-grams, 4-grams, 5-grams について,それぞれ最頻約100万の表現を羅列したデータベースで,手元においておけば,工夫次第で COCA のインターフェースだけでは検索しにくい共起表現の検索が可能となる.
ただし,各 n-gram のデータベースは,数十メガバイトの容量のテキストファイルで,直接検索するには重たい.そこで,SQLite データベースへと格納し,SQL 文による検索が可能となるように検索プログラムを組んだ.以下は,検索結果の最初の10行だけを出力する CGI である.
以下,使用法の説明.テーブル名は n-gram の "n" の値に応じて,"two", "three", "four", "five" とした.ちなみに,1-grams のデータベース(事実上,COCA に3回以上現われる語の頻度つきリスト)も付随しており,こちらもテーブル名 "one" としてアクセス可能にした.フィールドは,全テーブルに共通して "freq" (頻度)があてがわれているほか,"n" の値に応じて,"word1" から "word5" までの語形 (case-sensitive) と,"pos1" から "pos5" までの COCA の語類標示タグが設定されている.select 文のみ有効.以下に,典型的な検索式を例として載せておく.
# 1-grams で,前置詞を頻度順に取り出す(ただし,case-sensitive なので再集計が必要)
select * from one where pos1 like "i%" order by freq desc;
# 2-grams で,ハンサムなものを頻度順に取り出す
select * from two where word1 = "handsome" and pos1 = "jj" and pos2 like "nn_" order by freq desc;
# 2-grams で,"absolutely (adj.)" で強調される形容詞を頻度順に取り出す([2011-03-12-1]の記事「#684. semantic prosody と文法カテゴリー」を参照)
select * from two where word1 = "absolutely" and pos2 = "jj" order by freq desc;
# 3-grams で,高頻度の as ... as 表現を取り出す
select * from three where word1 = "as" and word3 = "as" order by freq desc;
# 4-grams で,高頻度の from ... to ... 表現を取り出す
select * from four where word1 = "from" and pos1 = "ii" and word3 = "to" and pos3 = "ii" order by freq desc;
# 5-grams で,死因を探る; "die of" と "die from" の揺れを観察する
select * from five where word1 in ("die", "dies", "died", "dying") and pos1 like "vv%" and word2 in ("of", "from") and pos2 like "i%" order by word3;
n-gram データベースを最大限に使いこなすには,このようにして得られた検索結果をもとにさらに条件を絞り込んだり,複数の検索結果を付き合わせるなどの工夫が必要だろう.
2011-12-05 Mon
■ #952. Etymology Search [etymology][dictionary][cgi][web_service][metathesis][blend][dissimilation]
[2010-04-03-1]の英語語源情報ぬきだしCGIの上位互換である,[2010-04-23-1]の英語語源情報ぬきだしCGI(一括版)のさらに上位互換となる,多機能版「Etymology Search」を作成した.情報源は引き続き Online Etymology Dictionary.
今回の版で新しいのは,通常の語形による検索に加えて正規表現による検索も可能にしたこと,見出し語とは別に定義(語源解説)内の検索を可能にしたことだ.
初期設定のとおりに "non-regex" かつ "word-form" として検索すると,通常の見出し語検索となる.カンマや改行で区切られた複数の単語を指定すれば,対応する語源記述が得られる.
search mode として "regex" を指定すると,perl5 相当の正規表現(改行区切りで複数指定可)を用いた検索が可能となる.正規表現を駆使すれば,語形の一部のみにマッチさせて,多数の語を拾い出すことも可能だ.
さらに,search range に "definition (in one-line regex)" を指定すれば,定義(語源解説)内の文字列を対象として検索できる.この機能では,search mode の値にかかわらず,自動的に正規表現検索(改行区切りにより複数の正規表現を指定することは不可)となるので注意."(?i)" を正規表現の先頭に付加すれば,case-intensive の機能となる.例えば,次のような検索例は有用かもしれない.
・ 音位転換を経た(かもしれない)語を一覧
(?i)\bmetathesis
・ かばん語(かもしれない)例を一覧
(?i)\bblend(s|ed|ing|ings)\b
・ 異化を経た(かもしれない)語を一覧
(?i)\bdissimilat
・ 日本語からの借用語(かもしれない)語を一覧
(?i)\bJapanese\b
2011-11-25 Fri
■ #942. LAEME Index of Sources の検索ツール [laeme][web_service][cgi]
LAEME で Auxiliary Data Sets -> Index of Sources とメニューをたどると,LAEME が対象としているテキストソースのリスト (The LAEME Index of Sources) を,様々な角度から検索して取り出すことができる.LAEME のテキストデータベースを年代別,方言別,Grid Reference 別などの基準で分析したい場合に,適切なテキストの一覧を得られるので,LAEME 使いこなしのためには非常に重要な機能である.
しかし,もう少し検索式に小回りを利かせられたり,一覧の出力がコンパクトに表形式で得られれば使い勝手がよいだろうと思っていた.そこで,Index of Sources を独自にデータベース化し,SQL を用いて検索可能にしてみた.LAEME の使用者で,かつSQLを扱える人以外には何も役に立たないのだが,せっかく作ったので公開.
以下,使用法の説明.テーブル名は "ios" (for "Index of Sources") で固定.フィールドは,LAEME 本家の検索で対象となっている18のフィールドに加えて,整理番号としての "ID" と,テキスト情報の掲載されたオンラインページへの "URL" を加えた計20フィールド (ID, MS, TEXT_ID, FILE, DATE, TEXT, GRID, LOC, COMMENT, SAMPLING, TAGGED_WORDS, PLACE_NAMES, PERSONAL_NAMES, WORDS, SCRIPT, OTHER, STATUS, BIBLIO, CROSS_REF, URL) .select 文のみ有効.以下に,典型的な検索式を例として載せておく.
# Ancrene Wisse/Riwle のテキスト情報の取り出し
select TEXT_ID, MS, FILE, GRID, LOC, DATE, TEXT from ios where FILE like "%ar%t.tag" and TEXT like "%Ancrene%";
# Poema Morale のテキスト情報の取り出し
select TEXT_ID, MS, FILE, GRID, LOC, DATE, TEXT from ios where FILE like "%pm%t.tag" and TEXT like "%Poema%";
# Grid Reference の与えられているテキストの取り出し
select TEXT_ID, MS, FILE, GRID from ios where GRID != "000 000";
# DATE に "C13a" を含むテキストの取り出し
select TEXT_ID, DATE from ios where DATE like "%C13a%";
# 年代ごとに集計
select DATE, count(DATE) from ios group by DATE order by DATE;
# タグ付けされている語数をテキストごとに確認
select TEXT_ID, TAGGED_WORDS, PLACE_NAMES, PERSONAL_NAMES from ios;
# 全テキスト情報へのリンク集
select TEXT_ID, MS, FILE, URL from ios;
2011-09-12 Mon
■ #868. EDD Online [dialect][web_service][corpus][lmode][lexicography][edd][dictionary]
図書館の reference corner に,古めかしい浩瀚の辞書があるのを日々見ていた.自分ではあまり使うことはないかなと思っていたが,数年前,博士論文研究に関連して eyes (「目」の複数形)に対応する中英語の諸方言形が近代英語や現代英語でどのように発達し,方言分布を変化させてきたかを調べる必要があり,そのときにこの辞書を開いたのが初めてだったように思う(その成果は Hotta (2005) にあり.[2009-12-02-1]の記事「eyes を表す172通りの綴字」も参照).Joseph Wright による6巻ものの辞書 The English Dialect Dictionary (EDD) である.
それ以降もたまに開く機会はあったが,先日参加した学会で,この辞書がオンライン化されたと知った.久しぶりに EDD に触れる良い機会だと思い,早速アクセスしてみることにした.Innsbruck 大学の Prof. Manfred Markus が責任者を務める SPEED (Spoken English in Early Dialects) プロジェクトの成果たる EDD Online の beta-version が公開中である.現時点では完成版ではないとしつつも,すでに検索等の機能は豊富に実装されており(豊富すぎて活用仕切れないほど),学術研究用に使用許可を取得すれば無償でアクセスできる.(使用マニュアルも参照.)
早速,使用許可を得てアクセスしてみた.ただし,調べる題材がない私にとっては,豚に真珠,猫に小判.悲しいかな,見出し語検索に eye を入れてみたりして・・・(←紙で引け!懐かしむな!)(ただし,"structured view" で表示すると,紙版よりずっと見やすいのでそれだけでも有用).Markus 氏が学会でじきじきに宣伝していた通り,様々な検索が可能のようである.見出し語検索や全文検索はもちろんのこと,dialect area 検索では語によっては county レベルで地域を指定できる.usage label 検索では頻度ラベル,意味ラベル(denotation, simile, synonym など),語用ラベル(derogatory, slang など)の条件指定が可能である.etymology 検索の機能も備わっている.これらを組み合わせれば,特定地域と特定の言語からの借用語彙の関係などが見えてくるかもしれない.活用法を考えるに当たっては,まずは EDD がどのような辞書か,EDD Online がどのような機能を実装しているのかを学ばなければ・・・.
EDD そのものについては,VARIENG (Research Unit for Variation, Contacts and Change in English) に掲載されている,Markus 氏による Wright's English Dialect Dictionary computerised: towards a new source of information がよくまとまっている.
(後記 2022/10/21(Fri):EDD や SPEED へのリンクが切れていたのを発見した.EDD は新たにこちらよりどうぞ.)
・ Hotta, Ryuichi. "A Historical Study on 'eyes' in English from a Panchronic Point of View." Studies in Medieval English Language and Literature 20 (2005): 75--100.
・ Wright, Joseph, ed. The English Dialect Dictionary. 6 vols. Henry Frowde, 1898--1905.
2011-08-21 Sun
■ #846. HelMapperUK --- hellog 仕様の英国地図作成 CGI [cgi][web_service][map][lalme][laeme][bre]
中英語の方言を研究していると,LALME の Dot Map 風のイングランド地図を描けると便利だと思う機会がある.LALME の地図を用いるのであればコピーしたりスキャンしたりすればよいし,オンラインの LAEME であれば "Mapping" 機能から "Feature Maps" で特に注目すべき言語項目に関する地図はデジタル画像で得られる.後者では,"Create a Feature Map" なるユーザーによる地図作成機能もおいおい追加されるとのことで,中英語方言学のヴィジュアル化は今後も進展して行くと思われる.
しかし,それでも様々な困難や不便はある.例えば,LAEME でも,自分の関心のある言語項目が LAEME 自体で扱われていなければ地図作成機能は役に立たないし(例えば,私の中英語名詞複数の研究では名詞の歴史的な文法性が重要だが,LAEME text database では性がタグ付けされていないのでフルには活用できなかった),LALME についてはそもそも地図がデジタル化されていず応用しにくい(地図のデジタル化,少なくともテキスト情報や座標情報のデジタル化が一刻も早く望まれる).
それでも,手をこまねいて待っているわけには行かない.既存のツールと自分の関心は大概ずれているものであり,自ら研究環境を作る必要に迫られるのが常だからだ.中英語の方言地図に関する限り,LALME や LAEME からテキストの方言付与情報さえ得られれば,自ら集めた言語項目に関するデータを地図上にプロットすることは十分に可能である.(需要は少ないと思われるが)その作業を少しでも簡便化するために,HelMapperUK なる CGI を作成してみた.英国のベースマップ上にデータポイントをプロットするという単機能に特化しており,凡例をつけるなどの付加機能はないが,ヴィジュアル化して概観をつかむという用途には十分と思われる.
以下で使い方の説明をするが,その前に,まずこちらのデータファイルの内容を上のテキストボックスに上書きコピペして出力結果の確認をどうぞ.これは,拙著の複数形研究で分析した初期中英語テキストの分布で,赤丸が手作業で分析したもの,青四角が LAEME text database を援用して分析したもの,それぞれの形で小さいものはテキストの全体ではなく部分を分析したものを表わす.(実際,Hotta (55) の地図はおよそこのようにして描かれた.)
では,使い方の説明(基本的に作者個人仕様のものを公開しているだけなのでインターフェースは洗練されていません,あしからず).テキストボックスにあらかじめ入力されているとおり,入力データは設定部 (Configuration) で始まる.以下が設定可能な変数.
・ 「map」変数には "England" か "UK" が入る.これで,出力される地図の範囲を決定.
・ 「scale」変数は,X方向とY方向への拡大率を指定.拡大なし (scale=1 1) だと,出力画像は 386 * 313 Pixels (England) ,529 * 557 Pixels (UK) の大きさ.
・ 「pattern + 数字」変数は,プロットに用いる記号を定義する.イコールの後にはスペース区切りで (1) 形 ("box", "circle", "cross", "diamond", "invertedtriangle", "plus", or "triangle") ,(2) その形を塗りつぶすか否か (ex. "fill" or "stroke") ,(3) 色 (ex. "aqua", "black", "blue", "cyan", "green", "lime", "magenta", "red"; 他の大抵の色名にも対応しているはずだが出力される画像に反映されない色もある) ,(4) 大きさ(線の長さや円の直径に相当する Pixels)の4項目の値を与える.パターンは好きなだけユーザー定義可能.
その後にデータ部 (Data points) が続く.1行に1データポイントで,各行はタブ区切りで (1) X座標,(2) Y座標,(3) 上で定義されたパターン名のいずれか ("pattern1" など)の3項目の値を与える(実際にはパターン名は省略可能.その場合,自動的に "pattern1" が用いられる.).座標系については,LALME や LAEME で採用されている Ordinance Survey National Grid Reference の3桁ずつの座標系 (ex. "372 244") ,あるいは一般の経度・緯度 (ex. -2.408752393 52.09322081) のいずれも可能(自動で判定される).
空行,あるいは "#" で始まるコメント行はデータとして無視される.
出力結果は GIF 形式の画像として表われる.別途,EPS 形式のベクター画像としてもダウンロードできるようにした(こちらのファイルをいじれるのであれば,各種の設定を含めた細かいチューニングが可能).
英国ベースマップの作成には,CIA World DataBank II や DCW Map Interface for Europe のデータを参照した.
(後記 2011/08/31(Wed):[2011-08-31-1]の記事「LAEME text database のデータ点とテキスト規模」で,HelMapperUK で作製した地図の実例を示した.)
・ McIntosh, Angus, M. L. Samuels, and M. Benskin. A Linguistic Atlas of Late Mediaeval English. 4 vols. Aberdeen: Aberdeen UP, 1986.
・ Laing, Margaret and Roger Lass, eds. A Linguistic Atlas of Early Middle English, 1150--1325. http://www.lel.ed.ac.uk/ihd/laeme1/laeme1.html . Online. Edinburgh: U of Edinburgh, 2007.
・ Hotta, Ryuichi. The Development of the Nominal Plural Forms in Early Middle English. Hituzi Linguistics in English 10. Tokyo: Hituzi Syobo, 2009.
2011-05-16 Mon
■ #749. hel typist --- hellog 仕様の文字列変換 CGI [cgi][web_service][ipa]
本ブログでは,古英語,中英語,現代フランス語の引用や,IPA 「国際音標文字」などの発音記号を入力する機会が多いのだが,量が多いと,特殊文字や特殊記号の打ち込みが患わしくなってくる.この際だからと思い,ASCII文字だけで入力できる記法を定義し,それを目的の文字・記号へ変換するツールを作成してみた.英語史の周辺で用いることの多い文字・記号だけを変換の対象にしたので,名付けて hel typist.仕様,入力例,記法一覧はこちら.
基本的な使い方だけ簡単に解説する.a#d#eling, t#e_od, g#iue, Vous vous e^tes leve' tre`s to^t . などと入力すると æðeling, þēod, ȝiue, Vous vous êtes levé très tôt. などへ変換されるという単純な置換ツールで,ほとんどの特殊記法が「アルファベット1文字+句読記号1?2文字」で構成される.そこで使われている句読記号そのものを入力する場合には,スペース1文字を先行させることでエスケープする.
また,// // あるいは [[ ]] で囲まれた部分は特別に IPA mode として解釈され,IPA の発音記号用の記法が有効になる.主として現代英語の標準的な音素を表わす記号が,それぞれASCIIの1文字に対応しており,例えば "[[f@'nEtIks]]" と入力するだけで [fəˈnɛtɪks] が得られる.
記法はこれまで個人的に使っていたものが基礎となっているが,できる限り (1) 少ない打数で入力でき( þ などの HTML の実体参照より楽),(2) そのままでも何とか読める視認性を確保する(多少の暗記は必要だが t# で thorn とか,@ で schwa というのは容認可能と考える)記法を心がけた.
コンピュータでは,Unicode など文字の国際化が進んでいるとはいえ,いまだにウェブ上やメール上ではASCIIが優勢だし,ASCIIのテキストファイルのポータビリティの高さは変わっていない.数学の世界では,数式や特殊記号を (La)TeX によるASCII文字のみで表わす記法が広く用いられており,分野内でのコミュニケーションに貢献していると聞いている.言語学の世界でも,あるいはより限定的に英語史関連の世界でも,このような慣習がもっと発達すればよいなと思うのだが.
hel typist で定義されていない発音記号については,IPA入力ツールが便利.
[ 固定リンク | 印刷用ページ ]
2011-04-08 Fri
■ #711. Log-Likelihood Tester CGI, Ver. 2 [corpus][bnc][statistics][web_service][cgi][lltest]
以下に,汎用の Log-Likelihood Tester, Ver. 2 を公開.(後に説明するように,入力データのフォーマットに不備がある場合や,モードが適切に選択されていない場合にはサーバーでエラーが生じる可能性があるので注意.)
[2011-03-25-1]の記事で,コーパス研究でよく用いられる対数尤度検定 ( Log-Likelihood Test ) の計算機 Log-Likelihood Tester, Ver. 1 を公開した.Ver. 1 は,コーパスサイズを加味しながら2つのコーパスでのキーワード(群)の出現頻度を比べ,コーパス間の差が有意であるかどうかを検定するものだった.
Log-Likelihood Test は上述の目的で用いることが多いと思い,Ver. 1 ではあえて機能を特化させたのだが,より一般的に複数行,複数列の分割表で与えられるデータに対応する対数尤度検定を行ないたい場合もある.例えば,昨日の記事[2011-04-07-1]で,現代英語における though と although の出現傾向について BNC に基づいた調査を紹介したが,Text Domain ごとの頻度比率は,両語の間で統計的にどの程度一致している,あるいは一致していないとみなすことができるのだろうか.昨日のグラフから,although は学術散文に多く,though は創作散文に多いという傾向が一目瞭然だが,この直感的な「一目瞭然」は統計的にはどのように表現されるのだろうか.
このような場合には,次のような頻度表(値は100万語当たりの出現頻度に標準化済み)を準備し,これをコピーして入力ボックスに貼り付ける."lump mode" にチェックを入れ替え,"Go!" する.(デフォルトは "each-line mode" で,これは Ver. 1 と同等のモード.)
| though | although | |
|---|---|---|
| Natural and pure sciences | 56.3 | 80.13 |
| Applied science | 37.36 | 68.31 |
| World affairs | 45.81 | 68.2 |
| Social science | 48.98 | 63.38 |
| Commerce and finance | 46.18 | 57.21 |
| Arts | 74.07 | 52.93 |
| Leisure | 45.85 | 49.46 |
| Belief and thought | 70.78 | 46.75 |
| Imaginative prose | 80.2 | 26.37 |
結果は,1行だけの表として出力される.though と although を表わす2列の数値の並びが,統計的にどのくらい近似しているかを計算している.結論としては,両語の Text Domain ごとの頻度の並びの差は p < 0.0001 という非常に高いレベルで有意であり,両語の出現傾向は Text Domain によってほぼ確実に異なるといえる.
入力ボックスに入れるデータの書式は,タブ区切りの分割表.表頭と表側はいずれも省略可.サンプルのように表頭と表側の両方を含める場合には,左上のセルは空白にしておく必要あり.
"each-line mode" の機能は Ver. 1 と互換なので,入力形式もそちらの説明を参照.今回の Ver. 2 の "each-line mode" では,出力結果をシンプルにおさえてある(逆に,詳しい内部計算値を得たい場合には Ver. 1 のほうが有用).
Log-Likelihood Test の概要については,[2011-03-24-1]の記事を参照.
Powered by WinChalow1.0rc4 based on chalow