2019-12-01 Sun
■ #3870. 中英語の北部方言における wh- ならぬ q- の綴字 [spelling][me_dialect][labiovelar][lalme][laeme][map]
中英語方言学ではよく知られているが,イングランドの北部や東部の方言では,疑問詞に典型的に現われる軟口蓋唇音 (labiovelar) が,一般的な wh- などの綴字ではなく,quh-, qvh, qwh, qh などの綴字で現われることが多い.たとえば what に対応する綴字をいくつか挙げてみると,qwhat, qwat, quat, quad, qhat のごとくである.これは問題の子音の調音が北部系方言と南部系方言の間で異なっていたことを示唆するが,具体的にどのような違いだったのかについては議論がある.(なお,北部系方言においては wh- などの綴字も普通に使われており,それと平行して q- もよく使われていたということである.)
後期中英語における q- の地理的な分布は,実にきれいである.eLALME の Item 44 として取り上げられている,"WH-: q-, all spellings." と題された Dot Map を以下に再掲しよう.
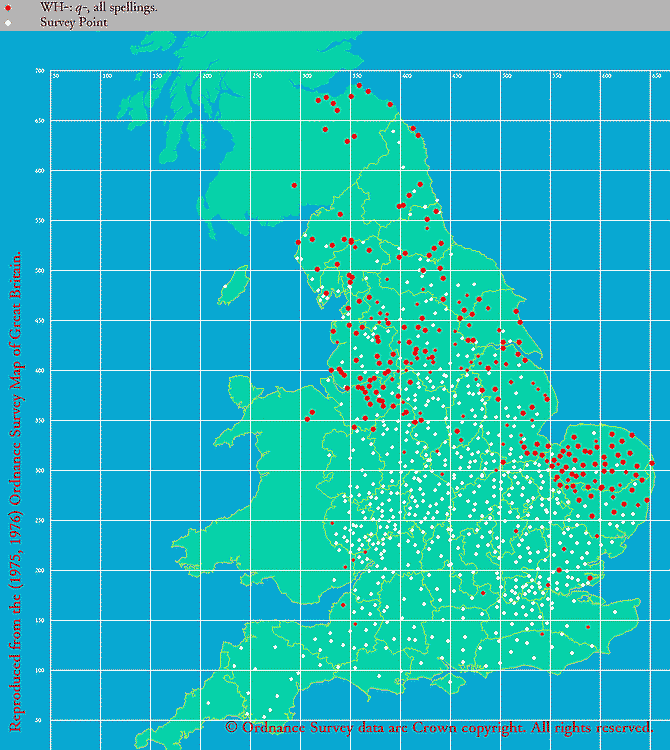
少しさかのぼって初期近代英語においても,LAEME の Map 28285405 の Dot Map を見るとわかるように,数こそ少ないが,やはり北部と東部に分布している.
当時,イングランド北部と地続きのスコットランドでも quh- などの綴字が一般的に用いられていた.しかし,16世紀以降になると,イングランドの標準的綴字の影響により,スコットランド英語でも quh- の立場は弱まっていった.そのくだりについては明日の記事で.
2019-11-30 Sat
■ #3869. ヨーロッパ諸言語が初期近代英語の書き言葉に及ぼした影響 [spelling][j][v][punctuation][standardisation][apostrophe][capitalisation][punctuation]
ラテン語が初期近代英語(ひいては後の現代英語)の書き言葉に及ぼした影響については,語源的綴字 (etymological_respelling) がよく知られている.ラテン語は,威信のある言語としてルネサンス期に英語の標準化の第一のお手本になったことは確かだろう.しかし,同時代のヨーロッパの土着語であるフランス語,スペイン語,イタリア語も,英語の書き言葉に少なからぬ影響を与えてきた.英語史でもあまり強調されることはないが,地味に重要な事実である.
Scholfield (158) によれば,次の点が指摘されている.
・ <i> と <j>,<u> と <v> の区別は,ラテン語ではなくスペイン語やイタリア語にあった区別により促された(cf. 「#1650. 文字素としての j の独立」 ([2013-11-02-1]), 「#2415. 急進的表音主義の綴字改革者 John Hart による重要な提案」 ([2015-12-07-1]))
・ long <s> の衰退は,おそらく大陸からの影響である(cf. 「#584. long <s> と graphemics」 ([2010-12-02-1]),「#2997. 1800年を境に印刷から消えた long <s>」 ([2017-07-11-1]))
・ アポストロフィ (apostrophe) の導入も大陸から
・ 大文字化 (capitalisation) が広く行なわれるようになった習慣も大陸から
・ 大陸の言語から語を借用したときに,借用元言語での綴字を英語化せずに取り入れる傾向も,上記の諸傾向と同じ方向性を示す
・ 初期の印刷字体もイタリアやフランスなど大陸から来たものだった
Scholfield (158) の以下の指摘は,「ラテン語が英語に及ぼした影響」以上に「ヨーロッパ諸言語が英語に及ぼした影響」へと目を向けさせてくれる.
. . . those with influence over how English writing developed were at least in the sixteenth/seventeenth centuries motivated to locate English as a modern European national language perhaps rather more than as another classical language.
初期近代英語は,理想のモデルとしてこそラテン語を念頭においていたが,現実的な敵対者かつ協力者として注視していたのは,同時代のヨーロッパの諸言語だったということになりそうだ.
・ Scholfield, Phil. "Modernization and Standardization since the Seventeenth Century." Chapter 9 of The Routledge Handbook of the English Writing System. Ed. Vivian Cook and Des Ryan. Abingdon: Routledge, 2016. 143--61.
2019-11-29 Fri
■ #3868. 現代英語の綴字にみられる「不変異の原則」 [spelling][standardisation][orthography][spelling_pronunciation_gap]
英単語の各々には決まった1つの綴字がある.これは現代標準英語の読み書きを習ってきた私たちにとって,あまりに当たり前のことで疑うべくもない.なぜ doubt には発音されない <b> があるのか,なぜ one で /wʌn/ と発音するのかなど,いろいろと突っ込みどころはあるが,なぜあれこれの単語の綴字は1つに決まっていて2つめの綴り方がないのか,などと問うことはしない.標準的な綴字,あるいは「正しい」綴字 は1つに決まっているものだと思い込んでいるし,そうでない状況を思い浮かべるのも難しいかもしれない.そこから逸脱したらすべて「間違い」というのが,正書法 (orthography) の発想の根幹である.これは綴字の「不変異の原則」 (the principle of invariance) と呼ばれる.Cook (12--13) から引用する.
The principle of invariance
One implicit assumption about the modern English writing system is that a word is always spelled in the same way, regardless of its sound correspondence: scissors has to be spelled <scissors> not <sizerz>, even if the latter corresponds more accurately to its pronunciation /sɪzəz/. A written word is seen as fixed and unchanging. A limited dispensation from invariance is afforded to proper-names, as in Vivian, Vyvyen, and Vivien, Vivienne (with a gender difference between the first two and last two in British English); the possessor of a name can insist on how it is spelled or said, say Keynes /keɪnz/ for the economist or Menzies /miŋgɪs/ or C. J. Cherryh with final silent <h> for the novelist. / This insistence on invariance is comparatively new in English, and is often at odds with consistent letter to sound correspondence rules.
引用の最後にあるように,実際に「不変異の原則」が遵守されてきた歴史は非常に浅く,せいぜい後期近代以降といってよい.この約250年ほどの間といっておこうか.「不変異の原則」を打ち立てようとしてきた経緯が別名「綴字の標準化」と称され,英語においてその道のりは実に長かった.後期中英語期に緩やかに始まり,後期近代英語期までダラダラと続いたのである.その概略については「#2321. 綴字標準化の緩慢な潮流」 ([2015-09-04-1]) を参照されたい.
いずれにせよ,英語史において「不変異の原則」は新しいものであるという事実を銘記しておきたい.
・ Cook, Vivian. "Background to the English Writing System." Chapter 2 of The Routledge Handbook of the English Writing System. Ed. Vivian Cook and Des Ryan. Abingdon: Routledge, 2016. 5--23.
2019-11-18 Mon
■ #3857. 『英語教育』の連載第9回「なぜ英語のスペリングには黙字が多いのか」 [rensai][notice][silent_letter][consonant][spelling][spelling_pronunciation_gap][sound_change][phonetics][etymological_respelling][latin][standardisation][sobokunagimon][link]
11月14日に,『英語教育』(大修館書店)の12月号が発売されました.英語史連載「英語指導の引き出しを増やす 英語史のツボ」の第9回となる今回の話題は「なぜ英語のスペリングには黙字が多いのか」です.

黙字 (silent_letter) というのは,climb, night, doubt, listen, psychology, autumn などのように,スペリング上は書かれているのに,対応する発音がないものをいいます.英単語のスペリングをくまなく探すと,実に a から z までのすべての文字について黙字として用いられている例が挙げられるともいわれ,英語学習者にとっては実に身近な問題なのです.
今回の記事では,黙字というものが最初から存在したわけではなく,あくまで歴史のなかで生じてきた現象であること,しかも個々の黙字の事例は異なる時代に異なる要因で生じてきたものであることを易しく紹介しました.
連載記事を読んで黙字の歴史的背景の概観をつかんでおくと,本ブログで書いてきた次のような話題を,英語史のなかに正確に位置づけながら理解することができるはずです.
・ 「#2518. 子音字の黙字」 ([2016-03-19-1])
・ 「#1290. 黙字と黙字をもたらした音韻消失等の一覧」 ([2012-11-07-1])
・ 「#34. thumb の綴りと発音」 ([2009-06-01-1])
・ 「#724. thumb の綴りと発音 (2)」 ([2011-04-21-1])
・ 「#1902. 綴字の標準化における時間上,空間上の皮肉」 ([2014-07-12-1])
・ 「#1195. <gh> = /f/ の対応」 ([2012-08-04-1])
・ 「#2590. <gh> を含む単語についての統計」 ([2016-05-30-1])
・ 「#3333. なぜ doubt の綴字には発音しない b があるのか?」 ([2018-06-12-1])
・ 「#116. 語源かぶれの綴り字 --- etymological respelling」 ([2009-08-21-1])
・ 「#1187. etymological respelling の具体例」 ([2012-07-27-1])
・ 「#579. aisle --- なぜこの綴字と発音か」 ([2010-11-27-1])
・ 「#580. island --- なぜこの綴字と発音か」 ([2010-11-28-1])
・ 「#1156. admiral の <d>」 ([2012-06-26-1])
・ 「#3492. address の <dd> について (1)」 ([2018-11-18-1])
・ 「#3493. address の <dd> について (2)」 ([2018-11-19-1])
・ 堀田 隆一 「なぜ英語のスペリングには黙字が多いのか」『英語教育』2019年12月号,大修館書店,2019年11月14日.62--63頁.
2019-11-16 Sat
■ #3855. なぜ「新小岩」(しんこいわ)のローマ字表記は *Shingkoiwa とならず Shinkoiwa となるのですか? [sobokunagimon][nasal][consonant][japanese][romaji][phonetics][phonology][phoneme][allophone][spelling][orthography][digraph][phonemicisation]
標題は,すでに「素朴な疑問」の領域を超えており,むしろ誰も問わない疑問でしょう.昨日までの3つの記事 ([2019-11-13-1], [2019-11-14-1], [2019-11-15-1]) で,なぜ「新橋」(しんばし)のローマ字表記 Shimbashi には n ではなく m が用いられるかという疑問について議論してきましたが,それを裏返しにしたような疑問となっています(なので,先の記事を是非ご一読ください).
[ŋ] の発音を ng の文字(2文字1組の綴字)で表わすことは現代英語では一般的であり,これは音韻論的に /ŋ/ が一人前の音素として独立している事実に対応していると考えられます.同じ鼻子音であっても [n] や [m] と明確に区別されるべきものとして [ŋ] が存在し,だからこそ n や m と綴られるのではなく,ng という独自の綴り方をもつのだと理解できます.とすれば,新小岩の発音は [ɕiŋkoiwa] ですから,英語(あるいはヘボン式ローマ字)で音声的に厳密な表記を目指すのであれば *Shingkoiwa がふさわしいところでしょう.同様の理由で,英語の ink, monk, sync, thank も *ingk, *mongk, *syngc, *thangk などと綴られてしかるべきところです.しかし,いずれもそうなっていません.
その理由は,/ŋ/ については /n/ や /m/ と異なり,自立した音素としての基盤が弱い点にありそうです.歴史的にいえば,/ŋ/ が自立した音素となったのは後期中英語から初期近代英語にかけての時期にすぎません(cf. 「#1508. 英語における軟口蓋鼻音の音素化」 ([2013-06-13-1]))./n/ や /m/ が印欧祖語以来の数千年の歴史を誇る大人の音素だとすれば,/ŋ/ は赤ん坊の音素ということになります./ŋ/ は中英語期まではあくまで音素 /n/ の条件異音という位置づけであり,音韻体系上さして重要ではなく,それゆえに綴字上も特に n と区別すべきとはみなされていなかったのです.言い換えれば,[k] や [g] の前位置における [ŋ] は条件異音として古来当たり前のように実現されてきましたが,音素 /ŋ/ としては存在しなかったため,書き言葉上は単に n で綴られてきたということです.
中英語で kingk (king), dringke (drink), thingke (think) などの綴字が散発的にみられたことも確かですが,圧倒的に普通だったのは king, drink, think タイプのほうです.近代以降,音韻論的には /ŋ/ の音素化が進行したとはいえ,綴字的には前時代からの惰性で ng, nk のまま標準化が進行することになり,現代に至ります.
標題の疑問に戻りましょう.「新小岩」の「ん」は音声的には条件異音 [ŋ] として実現されますが,英語では条件異音 [ŋ] を綴字上 ng として表記する習慣を育んでこなかった歴史的経緯があります.そのため,英語表記,およびそれに基づいたヘボン式ローマ字では,*Shingkoiwa とならず,n を代用して Shinkoiwa で満足しているのです.
2019-11-15 Fri
■ #3854. なぜ「新橋」(しんばし)のローマ字表記 Shimbashi には n ではなく m が用いられるのですか? (3) [sobokunagimon][nasal][consonant][japanese][romaji][phonetics][phonology][phoneme][allophone][assimilation][spelling][orthography][digraph]
この2日間の記事 ([2019-11-13-1], [2019-11-14-1]) で標題の素朴な疑問について考えてきました.表面的にみると,日本語では「しんじゅく」「しんばし」という表記で「ん」を書き分けない一方,英語(あるいはヘボン式ローマ字)では Shinjuku と Shimbashi を書き分けているのですから,英語の表記は発音の違いに実に敏感に反応する厳密な表記なのだな,と思われるかもしれません.しかし,n と m の書き分けのみを取り上げて,英語表記が音声的に厳密であると断言するのは尚早です.他の例も考察しておく必要があります.
n と m という子音の違いが重要であるのは,両言語ともに一緒です.英語で nap と map の違いが重要なのと同様に,日本語で「な(名)」 na と「ま(間)」 ma の違いは重要です.ですから,日本語単語のローマ字表記において na と ma のように書き分けること自体は不思議でも何でもありません.ただし,問題の鼻子音が次に母音が来ない環境,つまり単独で立つ場合には日本語では鼻子音の違いが中和されるという点が,そうでない英語と比べて大きく異なるのです.
「さん(三)」は通常は [saɴ] と発音されますが,個人によって,あるいは場合によって [san], [saɲ], [saŋ], [sam], [sã] などと実現されることもあります.いずれの発音でも,日本語の文脈では十分に「さん」として解釈されます.ところが,英語では sun [sʌn], some [sʌm], sung [sʌŋ] のように,いくつかの鼻子音は単独で立つ環境ですら明確に区別しなければなりません.英語はこのように日本語に比べて鼻子音の区別が相対的に厳しく,その厳しさが正書法にも反映されているために,Shinjuku と Shimbashi の書き分けが生じていると考えられます.
しかし,話しはここで終わりません.上に挙げた sung [sʌŋ] のように,ng という綴字をもち [ŋ] で発音される単語を考えてみましょう. sing, sang, song はもちろん king, long, ring, thing, young などたくさんありますね.英語では [ŋ] を [n] や [m] と明確に区別しなければならないので,このように ng という 独自の文字(2文字1組の綴字)が用意されているわけです.とすれば,n と m が常に書き分けられるのと同列に,それらと ng も常に書き分けられているかといえば,違います.例えば ink, monk, sync, thank は各々 [ɪŋk], [mʌŋk], [sɪŋk], [θæŋk] と発音され,紛れもなく [ŋ] の鼻子音をもっています.それなのに,*ingk, *mongk, *syngc, *thangk のようには綴られません.n と m の場合とは事情が異なるのです.
英語は [n], [m], [ŋ] を明確に区別すべき発音とみなしていますが,綴字上それらの違いを常に反映させているわけではありません.n と m を書き分けることについては常に敏感ですが,それらと ng の違いを常に書き分けるほど敏感なわけではないのです.日本語の観点から見ると,英語表記はあるところでは確かに音声的により厳密といえますが,別のところでは必ずしも厳密ではなく,日本語表記の「ん」に近い状況といえます.もしすべての場合に厳密だったとしたら,「新小岩」(しんこいわ) [ɕiŋkoiwa] の英語表記(あるいはヘボン式ローマ字表記)は,現行の Shinkoiwa ではなく *Shingkoiwa となるはずです.
標題の疑問に戻りましょう.なぜ「新橋」(しんばし)のローマ字表記 Shimbashi には n ではなく m が用いられるのでしょうか.この疑問に対して「英語は日本語よりも音声学的に厳密な表記を採用しているから」と単純に答えるだけでは不十分です.「新橋」の「ん」では両唇が閉じており,だからこそ m と表記するのですと調音音声学の理屈を説明するだけでは足りません.その理屈は,完全に間違っているとはいいませんが,Shinkoiwa を説明しようとする段になって破綻します.ですので,標題の疑問に対するより正確な説明は,昨日も述べたように「英語正書法が要求する程度にのみ厳密な音声表記で表わしたもの,それが Shimbashi だ」となります.もっと露骨にいってしまえば「Shimbashi と綴るのは,英語ではそう綴ることになっているから」ということになります.素朴な疑問に対する答えとしては身もふたもないように思われるかもしれませんが,共時的な観点からいろいろと考察した結果,私がぐるっと一周してたどりついた当面の結論です(通時的な観点からはまた別に議論できます).
2019-11-14 Thu
■ #3853. なぜ「新橋」(しんばし)のローマ字表記 Shimbashi には n ではなく m が用いられるのですか? (2) [sobokunagimon][nasal][consonant][japanese][romaji][phonetics][phonology][phoneme][allophone][assimilation][vowel][spelling][spelling][orthography]
昨日の記事 ([2019-11-13-1]) で,日本語の「ん」が音声環境に応じて数種類の異なる発音で実現されることに触れました.この事実について,もう少し具体的に考えてみましょう.
佐藤 (49) によると,撥音「ん」の様々な音声的実現について,次のように説明があります.
後続子音と同じ調音点の鼻音を一定時間引き延ばすことで生じる音である.後続子音が破裂音や鼻音のときは,[p] [b] [m] の前で [m], [t] [ts] [d] [dz] [n] の前で [n], [tɕ] [dʑ], [ɲ] の前で [ɲ], [k] [ɡ] [ŋ] の前で [ŋ] になる.
ンでの言いきり,つまり休止の直前では,口蓋垂鼻音 [paɴ] となる.個人または場面により,[m] や [n] や [ŋ],または鼻母音になることもある.「しんい(真意)」「しんや(深夜)」のような,母音や接近音の前のンも,口蓋垂鼻音 [paɴ] となると説明されることがあるが,実際はよほど丁寧に調音しない限り閉鎖は生じず,[ɕiĩi] のように [i] の鼻母音 [ĩ] となることが多い.
後続子音がサ行やハ行などの摩擦音のときも,破裂音と同じ原理で,同じ調音点の有声摩擦音が鼻音化したものとなるが,前母音の影響も受けるため記号化が難しい.簡略表記では概略,[h] [s] [ɸ] の前で [ɯ̃], [ɕ] [ç] の前で [ĩ] のような鼻母音となると考えておけばよい.
日本語の「ん」はなかなか複雑なやり方で様々に発音されていることが分かるでしょう.仮名に比べれば音声的に厳密といってよい英語表記(あるいはそれに近いヘボン式ローマ字表記)でこの「ん」を書こうとするならば,1種類の書き方に収まらないのは道理です.結果として,Shinjuku だけでなく Shimbashi のような綴字が出てくるわけです.
しかし,仮名と比較すればより厳密な音声表記ということにすぎず,英語(やローマ字表記)にしても,せいぜい n と m を書き分けるくらいで,実は「厳密」などではありません.英語正書法が要求する程度にのみ厳密な音声表記で表わしたもの,それが Shimbashi だと考えておく必要があります.
なお,言いきりの口蓋垂鼻音 [ɴ] について『日本語百科大事典』 (247) から補足すると,「これは積極的な鼻子音であるというよりは,口蓋帆が下がり,口が若干閉じられることによって生じる音」ということです.
・ 佐藤 武義(編著) 『展望 現代の日本語』 白帝社,1996年.
・ 『日本語百科大事典』 金田一 春彦ほか 編,大修館,1988年.
2019-11-14 Thu
■ #3853. なぜ「新橋」(しんばし)のローマ字表記 Shimbashi には n ではなく m が用いられるのですか? (2) [sobokunagimon][nasal][consonant][japanese][romaji][phonetics][phonology][phoneme][allophone][assimilation][vowel][spelling][spelling][orthography]
昨日の記事 ([2019-11-13-1]) で,日本語の「ん」が音声環境に応じて数種類の異なる発音で実現されることに触れました.この事実について,もう少し具体的に考えてみましょう.
佐藤 (49) によると,撥音「ん」の様々な音声的実現について,次のように説明があります.
後続子音と同じ調音点の鼻音を一定時間引き延ばすことで生じる音である.後続子音が破裂音や鼻音のときは,[p] [b] [m] の前で [m], [t] [ts] [d] [dz] [n] の前で [n], [tɕ] [dʑ], [ɲ] の前で [ɲ], [k] [ɡ] [ŋ] の前で [ŋ] になる.
ンでの言いきり,つまり休止の直前では,口蓋垂鼻音 [paɴ] となる.個人または場面により,[m] や [n] や [ŋ],または鼻母音になることもある.「しんい(真意)」「しんや(深夜)」のような,母音や接近音の前のンも,口蓋垂鼻音 [paɴ] となると説明されることがあるが,実際はよほど丁寧に調音しない限り閉鎖は生じず,[ɕiĩi] のように [i] の鼻母音 [ĩ] となることが多い.
後続子音がサ行やハ行などの摩擦音のときも,破裂音と同じ原理で,同じ調音点の有声摩擦音が鼻音化したものとなるが,前母音の影響も受けるため記号化が難しい.簡略表記では概略,[h] [s] [ɸ] の前で [ɯ̃], [ɕ] [ç] の前で [ĩ] のような鼻母音となると考えておけばよい.
日本語の「ん」はなかなか複雑なやり方で様々に発音されていることが分かるでしょう.仮名に比べれば音声的に厳密といってよい英語表記(あるいはそれに近いヘボン式ローマ字表記)でこの「ん」を書こうとするならば,1種類の書き方に収まらないのは道理です.結果として,Shinjuku だけでなく Shimbashi のような綴字が出てくるわけです.
しかし,仮名と比較すればより厳密な音声表記ということにすぎず,英語(やローマ字表記)にしても,せいぜい n と m を書き分けるくらいで,実は「厳密」などではありません.英語正書法が要求する程度にのみ厳密な音声表記で表わしたもの,それが Shimbashi だと考えておく必要があります.
なお,言いきりの口蓋垂鼻音 [ɴ] について『日本語百科大事典』 (247) から補足すると,「これは積極的な鼻子音であるというよりは,口蓋帆が下がり,口が若干閉じられることによって生じる音」ということです.
・ 佐藤 武義(編著) 『展望 現代の日本語』 白帝社,1996年.
・ 『日本語百科大事典』 金田一 春彦ほか 編,大修館,1988年.
2019-11-13 Wed
■ #3852. なぜ「新橋」(しんばし)のローマ字表記 Shimbashi には n ではなく m が用いられるのですか? (1) [sobokunagimon][nasal][consonant][japanese][romaji][phonetics][phonology][phoneme][allophone][assimilation][language_planning][spelling][orthography]
(後記 2021/04/29(Thu):本記事は「素朴な疑問」を扱った記事のなかでもとりわけ多く参照されているようです.これ自体はとても嬉しいことです.ただ,本記事の説明は「教科書的な回答」ではあるものの,筆者としては不十分な回答にとどまると考えています.むしろ,この回答の問題点を指摘し,続編で本格的に議論してゆくつもりで本記事を書いたという経緯があります.ですので,ぜひ続編の3記事も合わせて読んでいただければと思います.誤解を恐れずに言えば,本記事の「教科書的な回答」では不十分です.)
取り上げる例が「新橋」かどうかは別にしても,「ん」がローマ字で m と綴られる問題はよく話題にのぼります.
JR山手線の新橋駅の駅名表記は確かに Shimbashi となっています.日本語の表記としては「しんばし」のように「ん」であっても,英語表記(正確にいえば,JRが採用しているとおぼしきヘボン式ローマ字表記に近い表記)においては n ではなく m となります.これはいったいなぜでしょうか.この問題は,実は英語史の観点からも迫ることのできる非常にディープな話題なのですが,今回は教科書的な回答を施しておきましょう.
まず,基本的な点ですが,ヘボン式ローマ字表記では「ん」の発音(撥音と呼ばれる音)は,b, m, p の前位置においては n ではなく m と表記することになっています.したがって,「難波」(なんば)は Namba,「本間」(ほんま)は Homma,「三瓶」(さんぺい)は Sampei となり,それと同様に新橋(しんばし)も Shimbashi となるわけです.もちろん,問題はなぜそうなのかということです.
b, m, p の前位置において m と表記される理由を理解するためには,音声学の知識が必要です.日本語の撥音「ん」は特殊音素と呼ばれ,日本語音韻論では /ɴ/ と表記されます.理論上1つの音であり,日本語母語話者にとって紛れもなく1つの音として認識されていますが,実際上は数種類の異なる発音で実現されます.「ん」はどのような音声環境に現われるかによって,異なる発音として実現されるのです.
「難波」「本間」「三瓶」の3単語を発音してみると,「ん」の部分はいずれも両唇を閉じた発音となっていることが分かるかと思います.これはマ行子音 m の口構えにほかなりません.日本語母語話者にとっては「ん」として n を発音しているつもりでも,上の場合には実は m を発音しているのです.これは後続する m, b, p 音がいずれも同じ両唇音であるために,その直前に来る「ん」も歯茎音 n ではなく両唇音 m に近づけておくほうが,全体としてスムーズに発音できるからです.発音しやすいように前もって口構えを準備した結果,デフォルトの n から,発音上よりスムーズな m へと調整されているというわけです.
微妙な変化といえば確かにそうですので,日本語表記では,特に発音の調整と連動させずに「ん」の表記のままでやりすごしています(連動させるならば,候補としては「む」辺りの表記となるでしょうか).しかし,このような発音の違いに無頓着ではいられない英語の表記(および,それに近いヘボン式ローマ字表記)にあっては,上記の音声環境においては,n に代えて,より厳密な音声表記である m を用いるわけです.
日本語母語話者にとっては「新宿」(しんじゅく)も「新橋」(しんばし)も同じ「ん」音を含むのだから,同じ「ん」 = n の表記を用いればよいではないかという理屈ですが,英語(やヘボン式ローマ字)では2つの「ん」が実は同じ発音でないという事実を重視して,前者には n の文字を,後者には m の文字を当て,区別して表記するならわしだということです.
ローマ字で書くとはいえ,読者として日本語母語話者を念頭におくのであれば n と表記するほうが分かりやすいのはいうまでもありません.これを実現しているのが訓令式ローマ字です.それによると「新橋」は Sinbasi となります.おそらくJR(を含む鉄道各社)は,想定読者として非日本母語話者(おそらく英語表記であれば理解できるだろうと思われる多くの外国人)を設定し,訓令式ではなくヘボン式(に類似した)ローマ字表記を採用しているのではないかと考えられます.Shimbashi 問題は,日本語と英語にまつわる音声学・音韻論・綴字の問題にとどまらず,国際化を視野に入れた日本の言語政策とも関わりのある問題なのです.
2019-11-10 Sun
■ #3849. 「綴字語源学」 [etymology][lexicology][spelling][spelling_pronunciation_gap][writing][grammatology][orthography][standardisation][terminology]
語源学 (etymology) が単語の語源を扱う分野であることは自明だが,その守備範囲を厳密に定めることは意外と難しい.『新英語学辞典』の etymology の項を覗いてみよう.
etymology 〔言〕(語源(学)) 語源とは,本来,語の形式〔語形・発音〕と意味の変化の歴史を可能な限りさかのぼることによって得られる文献上または文献以前の最古の語形・意味,すなわち語の「真の意味」 (etymon) を指すが,最近では etymon と同時に,語の意味・用法の発達の歴史,いわゆる語誌を含めて語源と考えることが多い.このように語の起源および派生関係を明らかにすることを目的とする語源学は,語の形態と意味を対象とする点において語彙論 (lexicology) の一部をなすが,また etymon を明らかにする過程において,特定言語の歴史的な研究 (historical linguistics) や比較言語学 (comparative linguistics) の方法と成果を用い,ときに民族学や歴史・考古学の成果をも援用する.従って語源学は,単語を中心とした言語発達史,言語文化史ということもできよう.
上記によると,語源学とは語の起源と発達を明らかにする分野ということになるが,そもそも語とは形式と意味の関連づけ(シニフィアンとシニフィエの結合)によって成り立っているものであるから,結局その関連づけの起源と発達を追究することが語源学の目的ということになる.ここで語の「形式」というのは,主として発音のことが念頭に置かれているようだが,当然ながら歴史時代にあっては,文字で表記された綴字もここに含まれるだろう.しかし,上の引用では語の綴字(の起源と発達)について明示的には触れられておらず,あたかも語源学の埒外であるかのように誤解されかねない.語の綴字も語源学の重要な研究対象であることを明示的に主張するために,「綴字語源学」,"etymology of spelling", "orthographic etymology" のような用語があってもよい.
もちろん多くの英語語源辞典や OED において,綴字語源学的な記述が与えられていることは確かである.しかし,英単語の綴字の起源と発達を記述することに特化した語源辞典はない.英語綴字語源学は非常に豊かで,独立し得る分野と思われるのだが.
(英語)語源学全般について,以下の記事も参照.
・ 「#466. 語源学は技芸か科学か」 ([2010-08-06-1])
・ 「#727. 語源学の自律性」 ([2011-04-24-1])
・ 「#1791. 語源学は技芸が科学か (2)」 ([2014-03-23-1])
・ 「#598. 英語語源学の略史 (1)」 ([2010-12-16-1])
・ 「#599. 英語語源学の略史 (2)」 ([2010-12-17-1])
・ 「#636. 語源学の開拓者としての OED」 ([2011-01-23-1])
・ 「#1765. 日本で充実している英語語源学と Klein の英語語源辞典」 ([2014-02-25-1])
・ 大塚 高信,中島 文雄 監修 『新英語学辞典』 研究社,1987年.
2019-10-14 Mon
■ #3822. 『英語教育』の連載第8回「なぜ bus, bull, busy, bury の母音は互いに異なるのか」 [rensai][notice][vowel][spelling][spelling_pronunciation_gap][me_dialect][sound_change][phonetics][standardisation][sobokunagimon][link]
10月12日に,『英語教育』(大修館書店)の11月号が発売されました.英語史連載「英語指導の引き出しを増やす 英語史のツボ」の第8回となる今回の話題は「なぜ bus, bull, busy, bury の母音は互いに異なるのか」です.
英語はスペリングと発音の関係がストレートではないといわれますが,それはとりわけ母音について当てはまります.たとえば,mat と mate では同じ <a> のスペリングを用いていながら,前者は /æ/,後者は /eɪ/ と発音されるように,1つのスペリングに対して2つの発音が対応している例はざらにあります.逆に同じ発音でも異なるスペリングで綴られることは,meat, meet, mete などの同音異綴語を思い起こせばわかります.
今回の記事では <u> の母音字に注目し,それがどんな母音に対応し得るかを考えてみました.具体的には bus /bʌs/, bull /bʊl/, busy /ˈbɪzi/, bury /ˈbɛri/ という単語を例にとり,いかにしてそのような「理不尽な」スペリングと発音の対応が生じてきてしまったのかを,英語史の観点から解説します.記事にも書いたように「現在のスペリングは,異なる時代に異なる要因が作用し,秩序が継続的に崩壊してきた結果の姿」です.背景には,あっと驚く理由がありました.その謎解きをお楽しみください.

今回の連載記事と関連して,本ブログの以下の記事もご覧ください.
・ 「#1866. put と but の母音」 ([2014-06-06-1])
・ 「#562. busy の綴字と発音」 ([2010-11-10-1])
・ 「#570. bury の母音の方言分布」 ([2010-11-18-1])
・ 「#1297. does, done の母音」 ([2012-11-14-1])
・ 「#563. Chaucer の merry」 ([2010-11-11-1])
・ 堀田 隆一 「英語指導の引き出しを増やす 英語史のツボ 第8回 なぜ bus, bull, busy, bury の母音はそれぞれ異なるのか」『英語教育』2019年11月号,大修館書店,2019年10月12日.62--63頁.
2019-07-11 Thu
■ #3727. 題名における compleat の綴字 [spelling]
一昨日の記事「#3725. 語彙力診断テストや語彙関連ツールなど」 ([2019-07-09-1]) で紹介した英語語彙の便利サイト Compleat Lexical Tutor では,タイトルに Compleat という綴字が見える.一般的には complete の綴字が用いられており,compleat は間違いのように思われるかもしれないが,これは古い綴字変種の1つで,意識的な使用だろう.
「#2205. proceed vs recede」 ([2015-05-11-1]) で,標準的な綴字が確立する以前の初期近代期には,同じ単語に対して異綴りがいくつか存在していたことをみたが,標題の単語についても complete, compleat, compleate 等の綴字があった.compleat の綴字は,Izaak Walton 著 The Compleat Angler or the Contemplative Man's Recreation (『釣魚大全』;1653年)という今なお読まれ続けている著名な随筆に現われることから,大全ものの題名として擬古的に採用されることがある.1660年辺りに出版された Edward Cocker による The Compleat Arithmetician (『算術大全』)も教科書としてよく用いられたという.
OED の complete, adj. 5b によると,"Revived in imitation of its 17th-cent. use, as in Walton's The Compleat Angler." とあり,例として1900年の The compleat bachelor,1953年の The compleat imbiber などが挙げられている.古くから読まれている決定版という匂いを出すために擬古的な綴字を用いるのは,「#2432. Bolinger の視覚的形態素」 ([2015-12-24-1]) で触れた通り,綴字という視覚メディアのもつ特性の有効利用といえるだろう.
2019-05-31 Fri
■ #3686. -ate 語尾,-ment 語尾をもつ動詞と名詞・形容詞の発音の違い [gvs][vowel][spelling][spelling_pronunciation_gap][stress][suffix][latin][diatone][-ate]
昨日の記事「#3685. -ate 語尾をもつ動詞と名詞・形容詞の発音の違い」 ([2019-05-30-1]) に引き続き,-ate 語尾をもつ語の発音が,動詞では /eɪt/ となり名詞・形容詞では /ɪt/ となる件について.
Carney でもこの問題が各所で扱われており,特に p. 398 にこの現象を示す単語リストが挙げられている.以下に再現しておこう.網羅的ではないと思われるが,便利な一覧である.
aggregate, animate, appropriate, approximate, articulate, associate, certificate, co-ordinate, correlate, degenerate, delegate, deliberate, duplicate, elaborate, emasculate, estimate, expatriate, graduate, importunate, incorporate, initiate, intimate, moderate, postulate, precipitate, predicate, separate, subordinate, syndicate
Carney がこのリストを挙げているのは,品詞によって発音を替える類いの単語があるという議論においてである.他の種類としては,強勢音節を替える名前動後 (diatone) も挙げられているし,接尾辞 -ment をもつ語も話題にされている.名前動後という現象とその歴史的背景についてについては,すでに本ブログでも diatone の各記事で本格的に紹介してきたが,「品詞によって発音を替える」というポイントで -ate 語とつながってくるというのは,今回の発見だった.
-ment 語については,動詞であれば明確な母音で /-mɛnt/ となるが,名詞・形容詞であれば曖昧母音化した /-mənt/ となる.Carney (398) より該当する単語のリストを挙げておこう.complement, compliment, document, implement, increment, ornament, supplement.
・ Carney, Edward. A Survey of English Spelling. Abingdon: Routledge, 1994.
2019-05-30 Thu
■ #3685. -ate 語尾をもつ動詞と名詞・形容詞の発音の違い [gvs][vowel][spelling][spelling_pronunciation_gap][stress][analogy][suffix][latin][sobokunagimon][-ate]
標記について質問が寄せられました.たとえば appropriate は動詞としては「私用に供する」,形容詞としては「適切な」ですが,各々の発音は /əˈproʊpriˌeɪt/, /əˈproʊpriˌɪt/ となります.語末音節の母音が,完全な /eɪt/ が縮減した /ɪt/ かで異なっています.これはなぜでしょうか.
動詞の /eɪt/ 発音は,綴字と照らし合わせればわかるように,大母音推移 (gvs) の効果が現われています.<-ate> という綴字で表わされる本来の発音 /-aːt(ə)/ が,初期近代英語期に生じた大母音推移により /eɪt/ へと変化したと説明できます.しかし,同綴字で名詞・形容詞の -ate 語では,そのような発音の変化は起こっていません.そこで生じた変化は,むしろ母音の弱化であり,/ɪt/ へと帰結しています.
この違いは,大母音推移以前の強勢音節のあり方の違いに起因します.一般的にいえば,appropriate のような長い音節の単語の場合,動詞においては後方の音節に第2強勢が置かれますが,形容詞・名詞においては置かれないという傾向があります.appropriate について具体的にいえば,動詞としては第4音節の -ate に(第2)強勢が置かれますが,名詞・形容詞としてはそれが置かれないということになります.
ここで思い出すべきは,大母音推移は「強勢のある長母音」において作用する音過程であるということです.つまり,-ate 語の動詞用法においては,(第2強勢ではありますが)強勢が置かれるので,この条件に合致して /-aːt(ə)/ → /eɪt/ が起こりましたが,名詞・形容詞用法においては,強勢が置かれないので大母音推移とは無関係の歴史を歩むことになりました.名詞・形容詞用法では,本来の /-aːt(ə)/ が,綴字としては <-ate> を保ちながらも,音としては強勢を失うとともに /-at/ へと短化し,さらに /-ət/ や /-ɪt/ へと曖昧母音化したのです.
このような経緯で,-ate 語は品詞によって発音を違える語となりました.いったんこの傾向が定まり,パターンができあがると,その後は実際の発音や強勢位置にかかわらず,とにかく確立したパターンが類推的に適用されるようになりました.こうして,-ate 語の発音ルールが確立したのです.
関連して,「#1242. -ate 動詞の強勢移行」 ([2012-09-20-1]),「#2731. -ate 動詞はどのように生じたか?」 ([2016-10-18-1]) もご参照ください.-age 語などに関しても,ほぼ同じ説明が当てはまると思います.中尾 (310, 313) も要参照.
・ 中尾 俊夫 『音韻史』 英語学大系第11巻,大修館書店,1985年.
2019-05-18 Sat
■ #3673. responsibility はゆるゆるのスペリング [spelling][orthography][haplology]
[2019-05-16-1], [2019-05-17-1] の記事で,オーストラリアの新札で responsibility が responsibilty と誤って綴られていたという話題を取り上げてきた.今回はこの語の綴字そのものについてコメントしておきたい.
この語の規範的な発音は,長い6音節の /rɪˌspɒnsəˈbɪləti/ である.スペリングミスと指摘された最後の <i> に対応するのは,後ろから2音節目の /ə/ である.規範的な発音ですら弱音節の曖昧母音なのだから,カジュアルな発音では脱落することもあろう.その場合には,1音節減の /-bɪlti/ となり,今回のミススペリングはまさにこの発音に忠実な表記となる(だからといって,そのスペリングを特に擁護するわけではないが).
また,<i> の文字が3音節に連続して現われるというのも,うるさいといえばうるさい.最後の <i> の脱落は,haplography (重字脱落)といっては言い過ぎだろうが,その動機づけは分からないでもないのも事実だ (cf. 「#2362. haplology」 ([2015-10-15-1])) .中世の写本などでは,この種の脱落は十分にあり得たろう(だからといって,今回のミススペリングを特に擁護するわけではないが).
次に,問題の <i> の1つ前の音節 bil に注目してみよう.ここにも <i> の文字がみえるが,対応する母音 /ə/ も考えてみれば妙だ.この語の接尾辞 -ibility は -ability の変種だが,この接尾辞の基体というべき形容詞版は -able であり,b と l の間には文字としても発音としても i は存在しない.ability (n.) -- able (adj.) では,正規のスペリングにおいても発音においても,i の有無の対立が見られるのである.さらにおもしろいことに中英語までさかのぼると,able は <able>, <abil>, <abill> などと綴られたし,ability も <abilite>, <abilte>, <ablete> などと綴られた.いずれの語でも <i> がオン・オフしている.今回のミススペリングに直接関係する音節ではないとはいえ,そこでの <i> も,共時的あるいは通時的にみて実に緩い存在なのだ (cf. MED より āble adj., abilitē n.) .
さらに1音節前の si /sə/ をみてみよう.この語の接尾辞は -ability ではなく -ibility となっているが,対応するフランス語をみると responsabilité である(形容詞も responsable).語源はラテン語の第1変化動詞 respōnsāre に由来し,母音は a が正統なのだが,英語では英語にありがちな混同を経て i となったものである.この点でも,やはり何だか緩い.
以上をまとめれば,今回の新札で問題となった最後の <i> のみならず,その前の <i> も,さらにその前の <i> も,揃いも揃って歴史的には揺れてきたのである.全体として responsibility は英語の正書法を代表する「ゆるゆるのスペリング」といってよい.このように見てくると,新札の「誤った」 responsibilty も,ある意味でかわいく思えてくる.
2019-05-17 Fri
■ #3672. オーストラリア50ドル札に responsibility のスペリングミス (2) [spelling][orthography][sociolinguistics][stigma]
昨日の記事 ([2019-05-16-1]) に引き続き,標記の話題.responsibility を responsibilty と綴ったところで,何の誤解も生じるはずがない,とすれば世間は何を騒いでいるのか,という向きもあるにちがいない.しかし,現実的には世界中の英語文化に直接・間接に関与する多数の人々(日本人の英語学習者も含む)にとって,<i> を含む「正しい綴字」には威信 (prestige) があり,<i> が抜けている「誤った綴字」には傷痕 (stigma) が付されているという評価が広く共有されている.今回のスペリングミスについてどの程度積極的に非難するかは別として,少なくとも「オーストラリア,やっちゃったな」とチラとでも思っているようであれば,それは「正しい綴字」の威信を感じていることの証左である.
しかし,そのように感じている人(私も含め)は,なぜ <i> の1文字の有無に左右される「正しい綴字」に威信を認めているのだろうか.今回の「正しい綴字」に積極的・消極的に威信を認めるという行為そのものによって,responsibility という綴字の威信はいやましに高まり,responsibilty を含む正しくない綴字はますます負のレッテルを貼られるようになる.それは英語の正書法全般にもインパクトを与え,ますます「正しい綴字」の威信を高め,「誤った綴字」の傷痕を増す方向へ圧力を加えることになる.威信・傷痕の拡大再生産である.
この加圧の主体は,英語を使う社会全体である.社会とは集団のことだが,集団とは個人の集まりである.究極的には,この圧力を加えているのは,それぞれ意識はせずとも一人一人の個人である.英語を非母語として学んでいる私たちの各々も,その集団の(はしくれかもしれないが)一員である以上,0.00000001%以下の貢献度ではあるが,無意識的にこの加圧の主体となっているのである.英語母語話者でもないのにそんな言い方はバカバカしいと思われるかもしれないが,これは事実である.とある綴字にもとから自然に威信があるとか,傷痕があるとか理解してはいけない.社会が,そして究極的には個人が(=あなたや私が),その綴字に威信や傷痕を付しているのである.
発音,文法,語彙,綴字などの言語項それ自体に,おのずからプラスやマイナスの力があるわけはない.それを使う人間が,それらにプラスやマイナスの社会的価値を付しているだけである.responsibility や responsibilty という綴字そのものに内在的な力があるとは考えられない.一方の綴字にプラスの力を,他方にマイナスの力を付しているのは,一人一人の人間なのである.みなが1字の違いで騒ぐのはアホらしいという意見で一致すれば,ニュースにもスキャンダルにもならないだろう.みなが1字の違いが重要だと思っているからこそ,ニュースになりスキャンダルにもなっているのである.つまり,これは明らかに英語に関与するすべての人々が共同で作り上げたニュースであり,スキャンダルなのだ.
2019-05-16 Thu
■ #3671. オーストラリア50ドル札に responsibility のスペリングミス (1) [spelling][orthography][sociolinguistics][stigma]
先週世界を駆け巡ったニュースだが,オーストラリアの最新技術を駆使した新50ドル札に3つめの <i> の抜けた responsibilty (正しくは responsibility)というスペリングミスのあることが発覚した.英語正書法上の大スキャンダル,"spelling blunder" と騒がれている(BBC News の記事 Australia's A$50 note misspells responsibility などを参照).
Reserved Bank of Australia が昨年発行した50ドル紙幣には,オーストラリア議会初の女性議員 Edith Cowan の肖像画が描かれているが,その左隣にみえる芝生の絵の部分は,実は非常に小さな文字列からなっており,そこに Cowan の議会での初演説からの一節が引用されている.具体的には "It is a great responsibility to be the only woman here, and I want to emphasise the necessity which exists for other women being here." という文が何度も繰り返し印刷されているのだが,いずれの文においても responsibility が responsibilty と <i> 抜きで綴られていた.虫眼鏡でなければ読めない小さな文字で書かれているので,発行から半年のあいだ誰にも気付かれずにきたらしい.すでに4600万部が印刷されてしまっており回収不可能なので,RBA は「次回の印刷で正します」とのこと.

オーストラリア人はもとより世界中の多くの人々が,RBA やオーストラリアに対して声高には非難せずとも「やってしまったなぁ」と内心つぶやいていることだろう.私も素直に感想を述べれば「ヘマをやらかしてしまったなあ」である.一方,このようなニュースで世間が騒いでいるのをみて,<i> が抜けた程度でこの単語が誤解されることはない,何を騒ぐのか,という向きもあるだろう.確かに意思疎通という観点からいえば,誤った responsibilty も正しい responsibility と同じように十分な用を足す.
しかし,言語のその他の要素と同様に,スペリングには言及指示的機能 (referential function) と社会指標的機能 (socio-indexical function) の2つの機能がある (cf. 「#2922. 他の社会的差別のすりかえとしての言語差別」 ([2017-04-27-1])) .今回のミススペリングは,「責任」を意味する語の言及指示的機能を損ねるものではないが,スペリングの社会指標的機能について再考を促すものではある.具体的にいえば,<i> 込みの responsibility には威信 (prestige) があり,<i> 抜きの responsibilty には傷痕 (stigma) が付着しているということだ.それぞれのスペリングに,プラスとマイナスの社会的な価値づけがなされているのである.
では,なぜそのような価値づけがなされているのか.誰が価値づけしていて,私たちはなぜそれを受け入れているのか.これは正書法を巡る社会言語学上の大問題である.
さらにいえば,これは歴史的な問題でもある.というのは,1500年を超える英語の歴史のなかで,スペリングの規範を含む厳格な正書法が現代的な意味で確立し,遵守されるようになったのは,たかだか最近の250年ほどのことだからだ.その他の時代には,スペリングに対する寛容さがもっとあった.なぜ後期近代以降,そのような寛容さが英語社会から失われ,<i> 1文字で騒ぎ立てるほどギスギスしてきたのか.
responsibilty 問題は,英語書記体系そのものに対する関心を呼び起こしてくれるばかりか,正書法の歴史や,言語項への社会的価値づけという深遠な話題への入り口を提供してくれる.向こう数週間の授業で使っていけそうな一級のトピックだ.本ブログでも,続編記事を書いていくつもりである.
世界的に有名な他の "spelling blunder" としては,アメリカ元副大統領 Dan Quayle の「potato 事件」がある.これについては,Horobin (2--3) あるいはその拙訳 (16--17) を参照.たかが1文字,されど1文字なのである.
・ Horobin, Simon. Does Spelling Matter? Oxford: OUP, 2013.
・ サイモン・ホロビン(著),堀田 隆一(訳) 『スペリングの英語史』 早川書房,2017年.
2019-05-05 Sun
■ #3660. 変なスペリングの queue [spelling][french][loan_word][doublet][q][vowel][digraph][sobokunagimon]
先日,素朴な疑問として「#3649. q の後には必ず u が来ますが,これはどういうわけですか?」 ([2019-04-24-1]) を本ブログで取り上げたところ,読者の方より,queue (列)という妙なスペリングの単語があることを指摘してもらった.<ueue> と母音字が4つも続くのは,英語のスペリングとしては破格だからだ.フランスからの借用語であるこの語については,意味的な観点および英語の英米差という観点から,かつて「#1754. queue」 ([2014-02-14-1]) で話題にしたが,スペリングについては考えたことはなかったので,ここにコメントを加えておきたい.
先日の記事 ([2019-04-24-1]) では,<qu> ≡ /kw/ と単純にとらえたが,実は <qu> ≡ /k/ であることも少なくない.critique, technique, unique などの語末に現われるケースはもとより,quay, conquer, liquor など語頭や語頭に現われても /kw/ ではなく /k/ となる例は,そこそこ見られる(cf. 「#383. 「ノルマン・コンケスト」でなく「ノルマン・コンクェスト」」 ([2010-05-15-1])).今回注目している queue /kjuː/ もこれらの仲間だ.
queue の母音部分のスペリングをみると <eu> ≡ /juː/ となっており,これは一応英語のスペリング規則に沿ってはいる.neurotic, leukaemia; feudal, neuter; adieu, deuce, lieu など (Upward and Davidson 163) に確認される対応だが,これらは純粋な英語のスペリング規則というよりは,それぞれギリシア語,ラテン語,フランス語からの借用語として原語のスペリング習慣を引き継いだものとみるほうが妥当かもしれない(しかも,これらのいくつかの単語では (yod-dropping) の結果 <eu> ≡ /uː/ となっている).語末の <e> は,借用元のフランス語にもあるからあるのだと説明してもよいが,同時に英語のスペリング規則では <u> で単語を終えることができないからと説くこともできそうだ(「#2227. なぜ <u> で終わる単語がないのか」 ([2015-06-02-1]) を参照).
ちなみに,先の記事 ([2014-02-14-1]) でも触れたように,queue と cue (突き棒;弁髪)とは同根語,換言すればスペリングを違えただけの2重語 (doublet) である(ちょうど「#183. flower と flour」 ([2009-10-27-1]) のようなもの).いずれも同一のフランス単語に由来するが,スペリングを違えることで異なる語であるかのようにみなすようになったのは,英語における独自の発達である.
いずれにせよ queue のスペリングは, <ueue> と母音字が4つ続く点で,きわめて破格的であることは間違いない.ご指摘ありがとうございました.
・ Upward, Christopher and George Davidson. The History of English Spelling. Malden, MA: Wiley-Blackwell, 2011.
2019-04-24 Wed
■ #3649. q の後には必ず u が来ますが,これはどういうわけですか? [sobokunagimon][alphabet][digraph][q][spelling]
連日,学生から寄せられた素朴な疑問を取り上げています.今回は英単語のスペリングでよく見かける <qu> という2文字の連続についての疑問です.queen, quick, quiet, quote, quality のように <q> の後にはほぼ必ず <u> が来ます.これは,他の子音字で直後にくる母音字がこれほど限定されているものはないのではないかという観察に基づく発問として,おもしろいと思います.
たしかに,<q> の後には <u> という母音字(正確にいえば /w/ という半子音を表わす半子音字)がほぼ100%の確率で現われます.「#1599. Qantas の発音」 ([2013-09-12-1]) でみたように,略語や借用語などにいくつかの例外はみられるにせよ,事実上 <qu> という連鎖が決め打ちであるといってよいでしょう.<q> が現われた瞬間,次に来るのは <u> であるとほぼ完全に予測できてしまうので,情報理論的にいえば <u> の情報価値はゼロということになり,余剰的な綴字ということができます(cf. 「#2249. 綴字の余剰性」 ([2015-06-24-1])).したがって,綴字に合理性を求めるのであれば,先に挙げた語は *qeen, *qick, *qiet, *qote, *qality と綴ってもよいことになります.<q> = /kw/ という取り決めを作ってしまえば,むしろ簡単便利なのかもしれません.
しかし,英語ではそのような合理化は生じてきませんでした.一般論でいえば,言語は必ずしもすべてが合理的にできているわけではなく,合理的な方向へ変化するものでもありません.むしろある種の無駄を積極的に許容し,上で触れたような余剰性 (redundancy) を確保する傾向がみられます.また,/kw/ という2音を表わすのに <qu> という2文字を用いるというのは,ある意味ではわかりやすいともいえます.
しかし,<qu> が固定セットであり続けた最大の理由は,中英語期の英語話者たちの大陸文化への憧れと,その際に受け入れた綴字伝統の惰性的保持にあったといってよいでしょう.古英語では <qu> はおろか <q> という文字自体が使われておらず,現在の queen, quick は cwen, cwic などと綴られていました.当時は,<cw> が <qu> の役割を果たしていたのです.2音 /kw/ に対応する2文字の組み合わせという点では,同じ方針を採っていたことになります.これはこれで完璧に機能しており,変わる必要もなかったのですが,中英語期になるとラテン語やフランス語に代表される大陸文化への憧れが昂じ,それらの言語ですでに定着していた <qu> でもって従来の <cw> を置き換えるという傾向が出てきました.こうして,<q> という文字,そして <qu> という綴字が英語に導入されたのです.一言でいえば,当時の英語の書き手が,ミーハー的に大陸の流行に飛びついたということです.流行というのは合理性とは別の軸で作用するものであり,むしろ無駄な格好よさを指向するものなのかもしれません.英語は,その後も現在に至るまで,<qu> という大陸文化の香り豊かな見映えを尊重し,それに満足し,保持してきたのです.
結果的に,現代英語では /k/ の音(/kw/ の一部としての音も含め)を表わすのに,少なくとも <c>, <k>, <qu> という3つの綴字を使い分けなければならないはめに陥っています.この三つ巴の抗争の深い歴史的背景(英語史の枠をはみ出し,さらに古い時代にも及ぶ)については,「#2367. 古英語の <c> から中英語の <k> へ」 ([2015-10-20-1]) や「#1824. <C> と <G> の分化」 ([2014-04-25-1]) の記事をご覧ください.
2019-04-05 Fri
■ #3630. なぜ who はこの綴字でこの発音なのか? [spelling][pronunciation][spelling_pronunciation_gap][interrogative_pronoun][sobokunagimon][sound_change][digraph]
標題の who (とその仲間というべき whom, whose, etc.)はあまりに卑近な単語であるだけに,英語学習者は皆,この綴字でこの発音 (= /huː/) であることをそのまま丸暗記しており,特に疑問も抱かないにちがいない.しかし,よく考えてみると,綴字と発音の関係が不規則きわまりない単語である.この綴字であれば,本来 /woʊ/ と発音されるはずだ.
まず子音をみてみよう.<wh> と綴って /h/ と発音されるのは,他の wh 疑問詞と比べればわかる通り,異例である.what, which, when, where, why はいずれも /w/ で始まっている(ただし一部の非標準変種では無声の /ʍ/ もあり得る;cf. 「#1795. 方言に生き残る wh の発音」 ([2014-03-27-1])).疑問詞において /h/ で始まる単語は,規則的に <h> で綴られる how のみである(how が疑問詞のなかでもこのように一風変わっていることについては,「#51. 「5W1H」ならぬ「6H」」 ([2009-06-18-1]) を参照).
次に母音をみてみよう.子音字+ <o> で単語が終わる場合,go, ho, Jo, lo, no, so などにみられるように,母音は /oʊ/ である.who のように /uː/ となるものは,do, to などがあるが,圧倒的に少数派だ.したがって,who は本来 hoo とでも綴られるべき単語であり,現状の綴字は子音においても母音においても不規則といわざるを得ない.
一見すると納得のいかないこの綴字と発音の関係には,歴史的な経緯がある.古英語でこの単語は hwa と綴られ /hwɑː/ と発音された.ここから数世紀をかけて,次のような一連の母音変化が生じた.
/hwɑː/ → /hwɔː/ → /hwoː/ → /hwuː/ → /huː/
つまり,低母音の構えだった舌が,口腔のなかを上方向へはるばると移動して,ついに高母音の舌構えに到達してしまったのである.最終段階の /w/ の消失は,子音と後舌・円唇母音に挟まれた環境で15--16世紀に規則的に生じた音変化で,two, sword などの発音も説明してくれる.つまり who と two の音変化は平行的といってよい.(なので次の記事も参考にされたい:「#184. two の /w/ が発音されないのはなぜか」 ([2009-10-28-1]),「#1324. two の /w/ はいつ落ちたか」 ([2012-12-11-1]),「#3410. 英語における「合拗音」」 ([2018-08-28-1]) .)
綴字については,この子音は古英語では2重字 (digraph) <hw> で書かれたが,中英語では逆転した2重字 <wh> で書かれるようになった.母音字に関しては,途中までは母音変化を追いかけるかのように <a> から <o> へと変化したが,追いかけっこはそこでストップし,<u> や <oo> の綴字へと定着することはついぞなかったのである.かくして,who = /huː/ なる関係が標準化してしまったというわけだ.
言語にあっては,who のように卑近な単語であればあるほど不規則性がよく観察されるものである.関連して,「#1024. 現代英語の綴字の不規則性あれこれ」 ([2012-02-15-1]) の単語リストも参照.
なお,<wh> = /h/ という例外的な子音(字)の対応は,who のほかに whole, whore にもみられる.これについては,「#1783. whole の <w>」 ([2014-03-15-1]) を参照.
Powered by WinChalow1.0rc4 based on chalow