2014-07-18 Fri
ЂЃ #1908. НїРЄђЩНЄяЄЙИьЄЮАеЬЃЄЮАВН (1) [semantic_change][gender][lexicology][semantics]
ЁЁЁж#473. АеЬЃЪбВНЄЮХЕЗПХЊЄЪЅбЅПЁМЅѓЁз ([2010-08-13-1]) ЄЮ (3) ЄЧМЈЄЗЄПАеЬЃЄЮАВН (pejoration) ЄЯЁЄБбИьЛЫЄЫЄЊЄЄЄЦЮуЄЌТПЄЄЁЅЮЩЄЄАеЬЃЁЄЄЂЄыЄЄЄЯОЏЄЪЄЏЄШЄтУцЮЉХЊЄЪАеЬЃЄРЄУЄПИьЄЫЅЭЅЌЅЦЅЃЅєЄЪВСУЭЄЌЩеЄЕЄьЄыИНОнЄЧЄЂЄыЁЅЄГЄьЄоЄЧЄЮЕЛіЄШЄЗЄЦЄЯЁЄЁж#505. silly ЄЮАеЬЃЪбВНЁз ([2010-09-14-1])ЁЄЁж#683. semantic prosody ЄШРАРтЁз ([2011-03-11-1] )ЁЄЁж#742. amusing, awful, and artificialЁз ([2011-05-09-1]) ЄЪЄЩЄЧЖёТЮЮуЄђИЋЄЦЄЄПЁЅ
ЁЁЄЗЄЋЄЗЁЄБбИьЛЫЄЫЄЊЄБЄыАеЬЃЄЮАВНЄЮЮуЄШЄЗЄЦЄШЄъЄяЄБЄшЄЏУЮЄщЄьЄЦЄЄЄыЄЮЄЯЁЄНїРЄђЩНЄяЄЙИьзУЄРЄэЄІЁЅБбИьЛЫЄђФЬЄИЄЦЁЄЁжНїРЁзЄђАеЬЃЄЙЄыИьЗВЄЯЁЄИЎЪТЄпЩюЪЮХЊЄЪДоУпХЊАеЬЃ (connotation) ЄђГЭЦРЄЗЄЦЄЄЄЏЗЙИўЄђМЈЄЙЁЅЁжНїРЁзЂЊЁжРХЊЄЫЄРЄщЄЗЄЪЄЄНїРЁзЂЊЁжОЋЩиЁзЄШЄЄЄІЄЮЄЌХЕЗПХЊЄЪЅбЅПЁМЅѓЄЧЄЂЄыЁЅЄГЄЮЯУТъЄђРЕЬЬЄЋЄщАЗЄУЄП Schulz ЄЮЯРЪИ "The Semantic Derogation of Woman" ЄЫЄшЄыЄШЁЄЁжНїРЄђЩНЄяЄЙИьЄЮТФЭюЁзЄЌЄЄЄЋЄЫАьШЬХЊЄЪИНОнЄЧЄЂЄыЄЋЄЌЁЄЄГЄьЄЧЄтЄЋЄШИРЄяЄѓЄаЄЋЄъЄЫМЈЄЕЄьЄыЁЅ3ВеНъЄЋЄщАњЭбЄЗЄшЄІЁЅ
Again and again in the history of the language, one finds that a perfectly innocent term designating a girl or woman may begin with totally neutral or even positive connotations, but that gradually it acquires negative implications, at first perhaps only slightly disparaging, but after a period of time becoming abusive and ending as a sexual slur. (82--83)
. . . virtually every originally neutral word for women has at some point in its existence acquired debased connotations or obscene reference, or both. (83)
I have located roughly a thousand words and phrases describing women in sexually derogatory ways. There is nothing approaching this multitude for describing men. Farmer and Henley (1965), for example, have over five hundred terms (in English alone) which are synonyms for prostitute. They have only sixty-five synonyms for whoremonger. (89)
ЁЁSchulz ЄЮЯРЪИЦтЄЫЄЯЁЄПєТПЄЏЄЮЮуЄЌЮѓЕѓЄЕЄьЄЦЄЄЄыЁЅЯРЪИЦтЄЫИНЄяЄьЄы99ИьЄђЅЂЅыЅеЅЁЅйЅУЅШНчЄЫЪТЄйЄЦЄпЄПЁЅЄЙЄйЄЦЄЌЁжРХЊЄЫТФЭюЄЗЄПНїЁзЁжОЋЩиЁзЄЫЄоЄЧАеЬЃЄЌАВНЄЗЄПЄяЄБЄЧЄЯЄЪЄЄЄЌЁЄБбИьЛЫЄЮЄЪЄЋЄЧОЏЄЪЄЏЄШЄтЄЂЄыЛўДќЄЫЩюЪЮХЊЄЪДоАеЄђЄтЄУЄЦНїРЄђЛиМЈЄЗЦРЄПУБИьЗВЄЧЄЂЄыЁЅ
abbess, academician, aunt, bag, bat, bawd, beldam, biddy, Biddy, bitch, broad, broadtail, carrion, cat, cleaver, cocktail, courtesan, cousin, cow, crone, dame, daughter, doll, Dolly, dolly, dowager, drab, drap, female, flagger, floozie, frump, game, Gill, girl, governess, guttersnipe, hack, hackney, hag, harlot, harridan, heifer, hussy, jade, jay, Jill, Jude, Jug, Kitty, kitty, lady, laundress, Madam, minx, Miss, Mistress, moonlighter, Mopsy, mother, mutton, natural, needlewoman, niece, nun, nymph, nymphet, omnibus, peach, pig, pinchprick, pirate, plover, Polly, princess, professional, Pug, quean, sister, slattern, slut, sow, spinster, squaw, sweetheart, tail trader, Tart, tickletail, tit, tramp, trollop, trot, twofer, underwear, warhorse, wench, whore, wife, witch
ЁЁНХЭзЄЪЄЮЄЯЁЄЄГЄьЄщЄЫТаБўЄЙЄыУЫРЄђЩНЄяЄЙИьЗВЄЯЩЌЄКЄЗЄтАеЬЃЄЮАВНЄђШяЄУЄЦЄЄЄЪЄЄЄГЄШЄРЁЅspinster ЁЪЦШПШНїРЁЫЄЫТаЄЙЄы bachelor ЁЪЦШПШУЫРЁЫЁЄwitch ЁЪЫтНїЁЫЄЫТаЄЙЄы warlock ЁЪУЫЄЮЫтЫЁЛШЄЄЁЫЄЯЅЭЅЌЅЦЅЃЅєЄЪДоАеЄЯЄЪЄЄЄЗЁЄЄЩЄСЄщЄЋЄШЄЄЄІЄШЅнЅИЅЦЅЃЅєЄЪЩОВСЄђЩеЄЕЄьЄЦЄЄЄыЁЅЯЗНїРЄђЩНЄяЄЙ trot, heifer ЄЪЄЩЄЯЩюЪЮХЊЄРЄЌЁЄЯЗУЫРЄђЩНЄяЄЙ geezer, codger ЄЯОЏЁЙЩюЪЮХЊЄРЄШЄЗЄЦЄтЄНЄЮХйЙчЄЄЄЯОЎЄЕЄЄЁЅqueen ЁЪНїВІЁЫЄЯ quean ЁЪЄЂЄаЄКЄьНїЁЫЄШФЬЄИЁЄByron ЄЯ "the Queen of queans" ЄЪЄЩЄШИРЭеЭЗЄгЄђЄЗЄЦЄЄЄыЄЌЁЄТаЄЙЄы king ЁЪВІЁЫЄЫЄЯЩюЪЮЄЮДоАеЄЯЄЪЄЄЁЅprincess ЄШ prince ЄтЦБЭЭЄЫТаОШХЊЄРЁЅmother, sister, aunt, niece ЄЮАеЬЃЄЯТФЭюЄЗЄПЄГЄШЄЌЄЂЄУЄПЄЌЁЄТаБўЄЙЄы father, brother, uncle, nephew ЄЫЄЯЄНЄЮЕЄЬЃЄЯЄЪЄЄЁЅУЫРЄЮПІЖШЁІЬђГфЄђЩНЄяЄЙ footman, yeoman, squire ЄЯАеЬЃЄЮВМЭюЄђЬШЄьЄыЄЌЁЄabbess, hussy, needlewoman ЄЪЄЩНїРЄЮПІЖШЁІЬђГфЄЮТПЄЏЄЯ professional ЄНЄЮИьЄЌМЈЄЗЄЦЄЄЄыЄшЄІЄЫЁЄЭЦАзЄЫЁжЬыЄЮПІЖШЁзЄиЄШХОВНЄЗЄЦЄцЄЏЁЅМуЄЄУЫРЄђЩНЄяЄЙИьЄЯ boy, youth, stripling, lad, fellow, puppy, whelp ЄЪЄЩУцЮЉХЊЄРЄЌЁЄdoll, girl, nymph ЄЯЩюЪЮХЊЄШЄЪЄыЁЅ
ЁЁНїРЄђЩНЄяЄЙИЧЭЬОЛьЄтЁЄЄЗЄаЄЗЄаАеЬЃЄЮАВНЄЮТаОнЄШЄЪЄыЁЅЄоЄПЁЄУЫРЄШНїРЄЮЮОМдЄђЛиМЈЄЙЄыЄГЄШЄЌЄЧЄЄы dog, pig, pirate ЄЪЄЩЄЮИьЄЧЄтЁЄНїРЄђЛиМЈЄЙЄыОьЙчЄЫЄЯЁЄЅЭЅЌЅЦЅЃЅєЄЪАеЬЃЄЌЩеЄЕЄьЄыЄтЄЮЄтОЏЄЪЄЏЄЪЄЄЁЅЄЄЄфЄЯЄфЁЄПяЪЌЄШЮрЕСИьЄђРИЄпНаЄЗЄЦЄЄПЄтЄЮЄЧЄЂЄыЁЅ
ЁЁЁІ Schulz, Muriel. "The Semantic Derogation of Woman." Language and Sex: Difference and Dominance. Ed. Barrie Thorne and Nancy Henley. Rowley, MA: Newbury House, 1975. 64--75.
2014-07-06 Sun
ЂЃ #1896. ЦќЫмИьЄЫЦўЄУЄПРОЭЮИь [loan_word][borrowing][japanese][lexicology][borrowing][portuguese][spanish][dutch][italian][russian][german][french]
ЁЁЦќЫмИьЄЫРОЭЮИьЄЌНщЄсЄЦЛ§ЄСЙўЄоЄьЄПЄЮЄЯЁЄ16РЄЕЊШОЄаЄЧЄЂЄыЁЅЁж#1879. ЦќЫмИьЄЫЄЊЄБЄыЅэЁМЅоЛњЄЮЮђЛЫЁз ([2014-06-19-1]) ЄЧЄтПЈЄьЄПЄшЄІЄЫЁЄЅнЅыЅШЅЌЅыПЭЄЮХЯЭшЄЌЗРЕЁЄРЄУЄПЁЅЅЅъЅЙЅШЖЕЭбИьЄШЄШЄтЄЫАьШЬХЊЄЪЭбИьЄтЄтЄПЄщЄЕЄьЄПЄЌЁЄСАМдЄЯИхЄЫЖиЖЕЄШЄЪЄУЄПЄГЄШЄтЄЂЄУЄЦФъУхЄЗЄЪЄЋЄУЄПЁЅИхМдЄЧЄЯЁЄЅЂЅыЅиЅЄЅШЅІЁЪЭЪПХќЁЫ(alfeloa) ЁЄЅЋЅЙЅЦЅщ (Castella)ЁЄЅЋЅУЅб (capa)ЁЄЅЋЅмЅСЅуЁЪЦюБЛЁЄCambodia)ЁЄЅЋЅыЅЕЅѓЁЪЗкъзЁЄcalsãnЁЫЁЄЅЋЅыЅП (carta)ЁЄЅГЅѓЅкЅЄЅШЅІЁЪЖтЪПХќЁЄconfeitosЁЫЁЄЅЕЅщЅЕЁЪЙЙМгЁЄsaraçaЁЫЁЄЅЖЅмЅѓ (zamboa)ЁЄЅЗЅуЅмЅѓ (sabão)ЁЄЅИЅаЅѓЁЪыЁълЁЄgibãoЁЫЁЄЅПЅаЅГЁЪБьС№ЁЄtabacoЁЫЁЄЅСЅуЅыЅсЅщ (charamela)ЁЄЅШЅПЅѓ (tutanaga)ЁЄЅбЅѓ (pão)ЁЄЅгЅЄЅЩЅэ (vidro)ЁЄЅгЅЙЅЋЅУЅШЁЪЅгЅЙЅБЅУЅШЁЄbiscoitoЁЫЁЄЅгЅэЁМЅЩ (veludo)ЁЄЅеЅщЅЙЅГ (frasco)ЁЄЅжЅщЅѓЅГ (blanço)ЁЄЅмЅЊЅэ (bolo)ЁЄЅмЅПЅѓ (botão) ЄЪЄЩЄЌЛФЄУЄПЁЅ16РЄЕЊЫіЄЫЄЯЅЙЅкЅЄЅѓИьЄтЦўЄУЄЦЄЄПЄЌЁЄФъУхЄЗЄПЄтЄЮЄЯЅсЅъЅфЅЙ (medias) ЄАЄщЄЄЄРЄУЄПЁЅ
ЁЁЖсРЄУцДќЄЫЭіГиЄЌЕЏЄГЄыЄШЁЄЅЊЅщЅѓЅРИьЄЮМкЭбИьЄЌЮЎЄьЙўЄѓЄЧЄЏЄыЁЅМЋСГВЪГиЄЮИьзУЄЌТПЄЏЁЄИхЄЫЗГЛіДиЗИЄЮИьзУЄтЦўЄУЄПЁЅЄоЄКЁЄАхГиЁІЬєГиЄЧЄЯЁЄЅЈЁМЅЦЅы (ether)ЁЄЅЈЅЅЙ (extract)ЁЄЅЊЅжЅщЁМЅШ (oblaat)ЁЄЅЋЅыЅЗЅІЅр (calcium)ЁЄЅЋЅѓЅеЅы (kamfer, kampher)ЁЄЅГЅьЅщ (cholera)ЁЄЅИЅЎЅПЅъЅЙ (digitalis)ЁЄЅЙЅнЅЄЅШ (spuit)ЁЄЅкЅЙЅШ (pest)ЁЄЅсЅЙ (mes)ЁЄЅтЅыЅвЅЭ (morphine)ЁЅВНГиЁІЪЊЭ§ЁІХЗЪИЄЧЄЯЁЄЅЂЅыЅЋЅъ (alkali)ЁЄЅЂЅыЅГЁМЅы (alcohol)ЁЄЅЈЅьЅЅЦЅы (electriciteit)ЁЄЅГЅѓЅбЅЙ (kompas)ЁЄЅНЁМЅР (soda)ЁЄЅЦЅьЅЙЅГЁМЅз (telescoop)ЁЄЅдЅѓЅШ (brandpunt)ЁЄЅьЅѓЅК (lenz)ЁЅРИГшДиЗИЄЧЄЯЁЄЅЊЅыЅДЁМЅы (orgel)ЁЄЅЎЅфЅоЅѓ (diamant)ЁЄЅГЁМЅв (koffij)ЁЄЅГЅУЅЏ (kok)ЁЄЅГЅУЅзЁЪkop; cf. Ёж#1027. ЅГЅУЅзЄШЅЋЅУЅзЁз ([2012-02-18-1])ЁЫЁЄЅДЅр (gom)ЁЄЅЗЅэЅУЅз (siroop)ЁЄЅЙЅГЅУЅз (schop)ЁЄЅКЅУЅЏ (doek)ЁЄЅНЅУЅзЁЪЅЙЁМЅзЁЄsoepЁЫЁЄЅСЅчЅУЅ (jak)ЁЄЅгЁМЅы (bier)ЁЄЅжЅъЅ (blik)ЁЄЅкЅѓ (pen)ЁЄЅкЅѓЅ (pek), ЅнЅѓЅз (pomp)ЁЄЅлЅУЅЏ (hoek)ЁЄЅлЅУЅз (hop)ЁЄЅщЅѓЅз (lamp)ЁЅЗГЛіДиЗИЄЧЄЯЁЄЅЕЁМЅйЅы (sabel)ЁЄЅдЅЙЅШЅы (pistool)ЁЄЅщЅѓЅЩЅЛЅы (ransel)ЁЅ
ЁЁЬРМЃЛўТхЄЫЄЯРОЭЮИьЄЮЄЪЄЋЄЧЄЯБбИьЄЌЭЅРЊЄШЄЪЄУЄЦЄЏЄыЄЌЁЄЬРМЃНщДќЄЫЄЯЄЄЄоЄРЁжЅГЅУЅзЁзЁжЅЩЅЏЅШЅыЁзЄЪЄЩЅЊЅщЅѓЅРМкЭбИьЄЮЛШЭбЄЌЩ§ЄђЭјЄЋЄЛЄЦЄЄЄПЁЅЄЗЄЋЄЗЁЄТчРЕУцДќАЪЙпЄЯБбИьЗЯЄЌТчШОЄђРъЄсЄыЄшЄІЄЫЄЪЄъЁЄЅЊЅщЅѓЅРЩїЄЮЁжЅНЅУЅзЁзЄЌБбИьЩїЄЮЁжЅЙЁМЅзЁзЄиУжДЙЄЕЄьЄПЄшЄІЄЫЁЄШЏВЛЄтБбИьЩїЄиЄШХ§АьЄЕЄьЄЦЄЏЄыЁЅБбИьАЪГАЄЮРОЭЮИьЄШЄЗЄЦЄЯЁЄТчРЕЄЋЄщОМЯТЄЫЄЋЄБЄЦЅЩЅЄЅФИьЁЪМчЄЫАхГиЁЄХаЛГЁЄХЏГиДиЗИЁЫЁЄЅеЅщЅѓЅЙИьЁЪМчЄЫЗнНбЁЄЩўОўЁЄЮСЭ§ДиЗИЁЫЁЄЅЄЅПЅъЅЂИьЁЪМчЄЫВЛГкДиЗИЁЫЁЄЅэЅЗЅЂИьЄтИЋЄщЄьЄыЄшЄІЄЫЄЪЄУЄПЁЅЄНЄьЄОЄьЄЮЮуЄђЕѓЄВЄЦЄпЄшЄІЁЅ
ЁЁЁІ ЅЩЅЄЅФИьЁЇЅЮЅЄЅэЁМЅМЁЪNeuroseЁЫЁЄЅЋЅыЅЦЁЪKarteЁЫЁЄЅЌЁМЅМЁЪGazeЁЫЁЄЅЋЅзЅЛЅыЁЪKapselЁЫЁЄЅяЅЏЅСЅѓЁЪVakzinЁЫЁЄЅЄЅЧЅЊЅэЅЎЁМЁЪIdeologieЁЫЁЄЅМЅпЅЪЁМЅыЁЪSeminarЁЫЁЄЅЦЁМЅоЁЪThemaЁЫЁЄЅЦЁМЅМЁЪTheseЁЫЁЄЅъЅхЅУЅЏЅЕЅУЅЏЁЪRucksackЁЫЁЄЅЖЅЄЅыЁЪSeilЁЫЁЄЅвЅхЅУЅЦЁЪHütteЁЫЁЄЅЊЅжЅщЁМЅШ (Oblate), ЅЏЅьЅЊЅНЁМЅШ (Kreosot)ЁЅ
ЁЁЁІ ЅеЅщЅѓЅЙИьЁЇЅЧЅУЅЕЅѓЁЪdessinЁЫЁЄЅГЅѓЅЏЁМЅыЁЪconcoursЁЫЁЄЅЗЅуЅѓЅНЅѓЁЪchansonЁЫЁЄЅэЅоЅѓЁЪromanЁЫЁЄЅЈЅЙЅзЅъЁЪespritЁЫЁЄЅИЅуЅѓЅыЁЪgenreЁЫЁЄЅЂЅШЅъЅЈЁЪatelierЁЫЁЄЅЏЅьЅшЅѓЁЪcrayonЁЫЁЄЅыЁМЅИЅхЁЪrougeЁЫЁЄЅЭЅАЅъЅИЅЇЁЪnégligeЁЫЁЄЅЊЅрЅьЅФЁЪomeletteЁЫЁЄЅГЅЫЅуЅУЅЏЁЪcognacЁЫЁЄЅЗЅуЅѓЅбЅѓЁЪchampagneЁЫЁЄЅоЅшЅЭЁМЅКЁЪmayonnaiseЁЫ
ЁЁЁІ ЅЄЅПЅъЅЂИьЁЇЅЊЅкЅщЁЪoperaЁЫЁЄЅНЅЪЅПЁЪsonataЁЫЁЄЅЦЅѓЅнЁЪtempoЁЫЁЄЅеЅЃЅЪЁМЅьЁЪfinaleЁЫЁЄЅоЅЋЅэЅЫЁЪmacaroniЁЫЁЄЅЙЅбЅВЅУЅЦЅЃЁЪspaghettiЁЫ
ЁЁЁІ ЅэЅЗЅЂИьЁЇЅІЅЉЅУЅЋЁЪvodkaЁЫЁЄЅЋЅѓЅбЁЪkampaniyaЁЫЁЄЅкЅСЅЋЁЪpechkaЁЫЁЄЅЮЅыЅоЁЪnormaЁЫ
ЁЁКЃЦќЁЄРОЭЮИьЄЮ8ГфЄЌБбИьЗЯЄЧЄЂЄъЁЄМкЭбЄЮТаОнЄШЄЪЄыБбИьЄЮЪбМяЄШЄЗЄЦЄЯТРЪПЭЮРяСшЄђЄЯЄЕЄѓЄЧБбЄЋЄщЪЦЄиЄШРкЄъТиЄяЄУЄПЁЅ
ЁЁАЪОхЁЄКДЦЃ (179--80, 185--86) ЄЊЄшЄгВУЦЃТО (74) ЄђЛВОШЄЗЄЦМЙЩЎЄЗЄПЁЅДиЯЂЄЗЄЦЁЄЁж#1645. ИНТхЦќЫмИьЄЮИьМяЪЌЩлЁз ([2013-10-28-1])ЁЄЁж#1526. БбИьЄШЦќЫмИьЄЮИьзУЛЫТаОШЩНЁз ([2013-07-01-1])ЁЄЁж#1067. НщДќЖсТхБбИьЄШИНТхЦќЫмИьЄЮИьзУМкЭбЁз ([2012-03-29-1]) ЄЮЕЛіЄтЛВОШЄЕЄьЄПЄЄЁЅ
ЁЁЁІ КДЦЃ Щ№ЕС ЪдУјЁЁЁиГЕРтЁЁЦќЫмИьЄЮЮђЛЫЁйЁЁФЋСвНёХЙЁЄ1995ЧЏЁЅ
ЁЁЁІ ВУЦЃ ОДЩЇЁЄКДМЃ ЗНЛАЁЄПЙХФ ЮЩЙд ЪдЁЁЁиЦќЫмИьГЕРтЁйЁЁЄЊЄІЄеЄІЁЄ1989ЧЏЁЅ
2014-06-21 Sat
ЂЃ #1881. РмШјМ -ee ЄЮЕЏИЛЄШШЏХИ (2) [suffix][pde_language_change][lexicology][statistics][oed][productivity][agentive_suffix]
ЁЁКђЦќЄЮЕЛіЁж#1880. РмШјМ -ee ЄЮЕЏИЛЄШШЏХИ (1)Ёз ([2014-06-20-1]) ЄЫТГЄЁЄХіГКРмШјМЄЮИНТхБбИьЄЫЄЋЄБЄЦЄЮМСХЊЄЪЪбВНЄЊЄшЄгЮЬХЊЄЪШЏХИЄЫЄФЄЄЄЦЁЄIsozaki ЄЫЕђЄъЄЪЄЌЄщЙЭЄЈЄыЁЅ
ЁЁIsozaki ЄЯЁЄOED ЄлЄЋЄЮЛВЙЭЛёЮСЄЫХіЄПЄъЁЄИНТхБбИьЄЋЄщ500ЄђФЖЄЈЄы -ee ИьЄђМ§НИЄЗЄПЁЅЄНЄЗЄЦЁЄЄГЄьЄщЄђНщНаЧЏТхЁЄХ§ИьЁІАеЬЃЄЮМяЪЬЁЄИьДДЄЮИьИЛЄЫЄшЄъЪЌРЯЄЗЁЄИхДќЖсТхБбИьЄЋЄщИНТхБбИьЄЫЄЋЄБЄЦЄЮФЌЮЎЄђ2ХРЦЭЄЛпЄсЄПЁЅКђЦќЄЮЕЛіЄЮНЊЄяЄъЄЧНвЄйЄПЁЄ(1) ЅэЅоЅѓЅЙЗЯИьДДЄЧЄЯЄЪЄЏЫмЭшИьДДЄЫРмТГЄЙЄыЗЙИўЄЌРИЄИЄЦЄЄЦЄЄЄыЄГЄШЁЄЄЊЄшЄг (2) standee ЄЮЄшЄІЄЪЦАКюМчЁЪМчИьЁЫЅПЅЄЅзЄЌС§ЄЈЄЦЄЄЦЄЄЄыЄГЄШЁЄЄЮ2ЄФЄЧЄЂЄыЁЅ
ЁЁ(1) ЄЫЄФЄЄЄЦЄЯЁЄOED ЄђЭбЄЄЄПФДККЗыВЬЄђЅАЅщЅеВНЄЙЄыЄШАЪВМЄЮЄшЄІЄЫЄЪЄы (Isozaki 7) ЁЅ
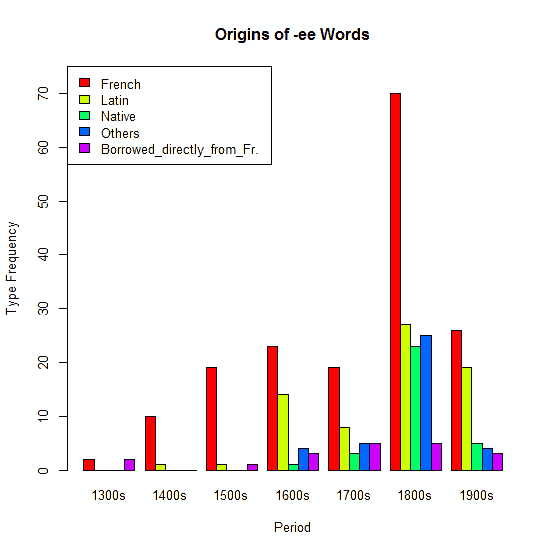
ЁЁЅеЅщЅѓЅЙИьДДЄЫРмТГЄЙЄыЗЙИўЄЌАьДгЄЗЄЦЖЏЄЄЄГЄШЄЯЬРЄщЄЋЄЧЄЂЄыЁЅЄЗЄЋЄЗЁЄЫмЭшИьДДЄЫРмТГЄЙЄыИьЮуЄЌИхДќЖсТхЄшЄъИНЄяЄьЄЦЄЄПЄГЄШЄЯУэЬмЄЫУЭЄЙЄыЁЅЄЪЄЊЁЄ19РЄЕЊЄЮЧњШЏДќЄЮИхЄЧ20РЄЕЊЄЌУЯЬЃЄЫИЋЄЈЄыЄЮЄЯЁЄOED ЄЮИьзУМ§ЯПЄЮЦУФЇЄЫЄшЄыЄШЄГЄэЄЌТчЄЄЄЄЋЄтЄЗЄьЄЪЄЄЁЅ
ЁЁМЁЄЫ (2) ЄЫЄФЄЄЄЦЄРЄЌЁЄЦБЄИЄЏ OED ЄђЭбЄЄЄЦЁЄХ§ИьЁЪАеЬЃЁЫХЊЄЪДбХРЄЋЄщЪЌЮрЄЗЄПЗыВЬЄЯАЪВМЄЮФЬЄъЄЧЄЂЄы (Isozaki 6) ЁЅЅАЅщЅеЄЮЄЪЄЋЄЧЁЄDO ЄЯЦАЛьЄЮФОРмЬмХЊИьЁЄIO ЄЯДжРмЬмХЊИьЁЄPO ЄЯСАУжЛьЬмХЊИьЁЄS ЄЯМчИьЁЄAnom. ЄЯЦАЛьЄШЄЯФОРмЄЫДиЗИЄЗЄЪЄЄЪбТЇХЊЄЪЄтЄЮЄЧЄЂЄыЁЅ
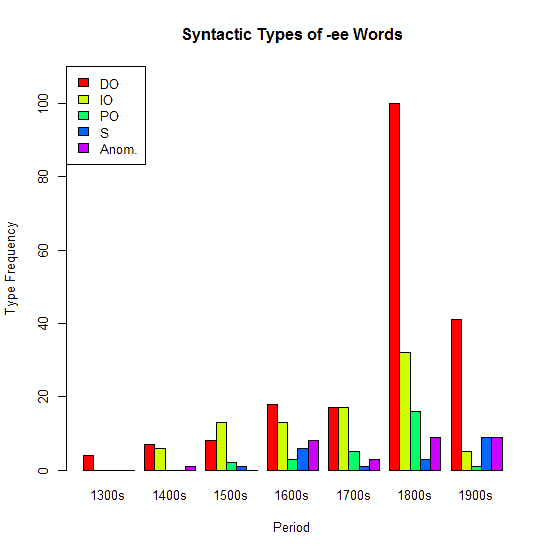
ЁЁНОЭшЗПЄЮ DO ЅПЅЄЅзЄЌОяЄЫЭЅРЊЄЧЄЂЄъТГЄБЄЦЄЄЄыЄГЄШЄЌИВУјЄЧЄЂЄъЁЄS ЅПЅЄЅзЄЮГШФЅЄЯЦУЄЫЬмЮЉЄПЄЪЄЄЄшЄІЄЫЄпЄЈЄыЁЅЄЗЄЋЄЗЁЄOED ЄђЮЅЄьЄЦЁЄ1900--2005ЧЏЄЮМяЁЙЄЮЫмЄфЛВЙЭПоНёЄЧЄЮНаИНЄђЙЭЮИЄЫЦўЄьЄыЄШЁЄDO ЄЌ117ЮуЁЄIO ЄЌ23ЮуЁЄPO ЄЌ4ЮуЁЄS ЄЌ32ЮуЁЄAnom. ЄЌ18ЮуЄШЁЄS ЁЪМчИьЅПЅЄЅзЁЫЄЮПФЅЄЌМЈКЖЄЕЄьЄы (Isozaki 6) ЁЅ
ЁЁ-ee ИьЄЯЮзЛўИьХЊЄЪЛШЄяЄьЪ§ЄЌТПЄЄЄШСлСќЄЕЄьЁЄЛШЭбАшЄЮАьШЬВНЄтПЪЄѓЄЧЄЄЄыЄшЄІЄЫЛзЄяЄьЄыЁЅКЃИхЄЯИьЭбЯРХЊЄЪФДККЄтЩЌЭзЄШЄЪЄУЄЦЄЏЄыЄЋЄтЄЗЄьЄЪЄЄЁЅРмМЄЮРИЛКР (productivity) ЄШЄЄЄІДбХРЄЋЄщЄтЁЄЅЂЅѓЅЦЅЪЄђФЅЄУЄЦЄЊЄЄПЄЄЯУТъЄЧЄЂЄыЁЅ
ЁЁЁІ Isozaki, Satoko. "520 -ee Words in English." Lexicon 36 (2006): 3--23.
2014-06-09 Mon
ЂЃ #1869. ЦќЫмИьЄЫЄЊЄБЄыЪЉЖЕИьзУ [japanese][kanji][loan_word][religion][buddhism][lexicology]
ЁЁНЁЖЕЄЮХСЭшЄЌМѕЄБЦўЄьТІЄЮИРИьЄЫУјЄЗЄЄБЦЖСЄђЕкЄмЄЙЄГЄШЄЫЄФЄЄЄЦЁЄЁж#296. ГАЭшНЁЖЕЄЌБбИьЄШЦќЫмИьЄЫЭПЄЈЄПИРИьХЊБЦЖСЁз ([2010-02-17-1]) ЄЧМшЄъОхЄВЄПЁЅЄНЄЮЕЛіЄЧЄЯЁЄЦќБбЄЫЄЊЄЄЄЦИВУјЄЪЮрЛїХРЄЌЄЂЄыЄГЄШЄђЛиХІЄЗЄПЁЅЅцЁМЅщЅЗЅЂТчЮІЄЮЮОУМЄЧЁЄЛўЄђЄлЄмЦБЄИЄЏЄЙЄы6РЄЕЊЄШЄЄЄІЛўДќЄЫЁЄЄНЄьЄОЄьТчЮІЄЋЄщЪЉЖЕЄШЅЅъЅЙЅШЖЕЄЌХСЄяЄУЄПЁЅГЦЁЙЁЄДСЛњЄШЅэЁМЅоЛњЄђМѕЭЦЄЗЄЦЫмГЪХЊЄЪЪИЛњЪИВНЄЌЛЯЄоЄъЁЄЄНЄЮНЁЖЕЄШДиЯЂЄЗЄПМяЁЙЄЮЪИЪЊЄфИьзУЄЌЮЎЦўЄЗЄПЁЅПЗНЁЖЕЄЯОшЄъЪЊЄШЄЗЄЦЕЁЧНЄЗЄЦЄЊЄъЁЄИьзУЄЯЄНЄьЄЫОшЄУЄЦЁЄЦќЫмЄШЅЄЅѓЅАЅщЅѓЅЩЄиХўУхЄЗЄПЄЮЄЧЄЂЄыЁЅ
ЁЁЅЅъЅЙЅШЖЕЄЌБбИьЄЫЭПЄЈЄПИьзУОхЄЮБЦЖСЄЫЄФЄЄЄЦЄЯЁЄЁж#32. ИХБбИьДќЄЫМкЭбЄЕЄьЄПЅщЅЦЅѓИьЁз ([2009-05-30-1]) ЄфЁж#1439. РЛНёЄЫЭГЭшЄЙЄыЩНИННИЁз ([2013-04-05-1]) ЄЧПЈЄьЁЄЦќБбЄЮИьзУЛЫЄЮШцГгТаОШЄЯЁж#1526. БбИьЄШЦќЫмИьЄЮИьзУЛЫТаОШЩНЁз ([2013-07-01-1]) ЄфЁж#1049. БбИьЄЮТПНХИьЄШДСЛњЄЮАлЄЪЄыЛњВЛЁз ([2012-03-11-1]) ЄЧИРЕкЄЗЄПЁЅКЃВѓЄЯЁЄЦќЫмИьЄЫЄЊЄБЄыЪЉЖЕИьЄЮМѕЭЦЄЫЄФЄЄЄЦМшЄъОхЄВЄыЁЅАЪВМЁЄЁиЦќЫмИьГиИІЕцЛіХЕЁй (407--08) ЄђЛВОШЄЗЄЦЕЄЙЁЅ
ЁЁ6РЄЕЊШОЄаЄЫЪЉЖЕЄЌХСЭшЄЙЄыЄШЁЄАЪЙпЁЄТПЄЏЄЮЪЉЖЕИьЁЪЄЂЄыЄЄЄЯЪЉИьЁЫЄЌЦќЫмИьЄиЮЎЦўЄЗЄПЁЅРЛЦСТРЛвАЪИхЁЄЪЉЖЕЄђПЖЖНЄЗЄПОхТхЄЫЄЯЁжЙсЯЇЁзЁжЯЙПЄЁзЁжЯЦТЉЁзЁжЙтКТЁзЁжИљЦСЁзЁжЖЁЭмЁзЄЪЄЩЄЌЦўЄъЁЄХЗТцЁІППИРЄЮЦѓНЁЄЮБЩЄЈЄПУцИХЄЫЄЯЁжТчЦСЁзЁжНЄЫЁЁзЁжЧАыжЁзЁжПЗШЏАеЁзЁжЛ§ЪЉЁзЁжЬОЙцЁзЁжПєМюЁзЁжВУЛ§ЁзЁжРКПЪЁзЁжШрДпЁзЁжЩлЛмЁзЁжВѓИўЁзЁжНаВШЁзЁЄЄоЄПЁжЦЛЭ§ЁзЁжЫмАеЁзЁжРЄГІЁзЁжРЄДжЁзЁжЙЇЭмЁзЁжишТеЁзЁжЦЛПДЁзЁжЪбВНЁзЁжЕЉЭЁзЁжАІЗЩЁзЁжМЙЧАЁзЄЪЄЩЄЌИЋЄщЄьЄПЁЅУцИХЄЋЄщУцРЄЄЫЄЋЄБЄЦЄЯЁЄПЎЖФЄЌЄЄЄУЄНЄІПМЄоЄъЁЄЪЉЖЕРтЯУЄтТПЄЏИНЄяЄьЁЄЁжНєЙдЬЕОяЁзЁжРЙМдЩЌПъЁзЁжШбЧКЁзЁжНАРИЁзЁжНЄЙдЁзЁжЛАГІЁзЁжУвЗХЁзЁжВсЕюЁзЁЄЄоЄПЁжШЏПДЁзЁжШсДъЁзЁжДЋПЪЁзЁжШљПаЁзЁжАТВКЁзЄЪЄЩ300ИьАЪОхЄЌМкЭбЄЕЄьЄЦЄЄЄыЁЅУцРЄЄЋЄщЖсРЄЄЫЄЋЄБЄЦЄЯЁЄЮзКбЁІСтЦЖЄЪЄЩЄЮСЕНЁЄЮХСЭшЄШЄШЄтЄЫЛШЭбЄЮГШЄЌЄУЄПЁжАЇЛЂЁзЁжАЪПДХСПДЁзЁжИўОхЁзЁжХўФьЁзЁжХўЦЌЁзЁжУМХЊЁзЁжЬЧЕбЁзЁжЬгЦЌЁзЁжЙдЕгЁзЁжДЧЗаЁзЄЫВУЄЈЁЄЁжАьЦРАьМКЁзЁжМчДуЁзЁжМЋНЭЁзЁжТЮЦРЁзЁжТЧГЋЁзЁжУБХсФОЦўЁзЁжЬчГАДСЁзЁжЯЗЧЬПДЁзЄЮЄшЄІЄЫЦќОяВНЄЗЄПЄтЄЮЄтТПЄЄЁЅЄоЄПЁЄЅЄЅѓЅЩЄЮЗаЯРЄЌДСЪИЄЫВЛЬѕЄЕЄьЄПЁЄЄЄЄяЄцЄыл№ИьЄтЁжяфВРЁзЁжВРЭѕЁзЁжеАЧЬЁзЁжТДХуЧЬЁзЁжшИШћЁзЁжУЩЦсЁзЄЮЄшЄІЄЫЦќЫмИьЄиЦўЄУЄЦЄЄЦЄЄЄыЁЅ
ЁЁЪЉЖЕИьЄЯЄНЄЮТОТППєЄЂЄыЄЌЁЄАЪВМЄЫЁиГиИІЁЁЦќЫмИьЁжИьИЛЁзМХЕЁйЄЫЕѓЄВЄщЄьЄЦЄЄЄыЪЉЖЕИьЁІл№ИьЄЫЭГЭшЄЙЄыЄГЄШЄаЄђЮѓЕѓЄЗЄшЄІЁЅМкЭбЄЕЄьЄПЛўДќЄЯЄоЄСЄоЄСЄРЄЌЁЄЪЉЖЕЄЌЦќЫмИьЄЮИьзУЄфЩНИНЄЫЭПЄЈЄЦЄЄПБЦЖСЄЮПгТчЄЕЄЌУЮЄщЄьЄыЁЅ
АІЗЩЁЬЄЂЄЄЄЄчЄІЁЭЁЄАЇЛЂЁЬЄЂЄЄЄЕЄФЁЭЁЄАІУхЁЬЄЂЄЄЄСЄуЄЏЁЭЁЄАЄвпЁЬЄЂЄІЄѓЁЭЁЄяфВРЁЬЄЂЄЋЁЭЁЄАЫтЁЬЄЂЄЏЄоЁЭЁЄАЄНЄЭхЁЬЄЂЄЗЄхЄщЁЭЁЄХїКЏЁЬЄЂЄаЄПЁЭЁЄЦєЁЬЄЂЄоЁЭЁЄЙдЕгЁЬЄЂЄѓЄЎЄуЁЭЁЄАТПДЁЬЄЂЄѓЄЗЄѓЁЭЁЄАеМБЁЬЄЄЄЗЄЁЭЁЄАЪПДХСПДЁЬЄЄЄЗЄѓЄЧЄѓЄЗЄѓЁЭЁЄАьТчЛіЁЬЄЄЄСЄРЄЄЄИЁЭЁЄАьЧАШЏЕЏЁЬЄЄЄСЄЭЄѓЄлЄУЄЁЭЁЄАьЯЁТёРИЁЬЄЄЄСЄьЄѓЄПЄЏЄЗЄчЄІЁЭЁЄАсШЁЬЄЄЄЯЄФЁЭЁЄАјВЬЁЬЄЄЄѓЄЌЁЭЁЄАјЖШЁЬЄЄЄѓЄДЄІЁЭЁЄАњЦГЁЬЄЄЄѓЄЩЄІЁЭЁЄАјБяЁЬЄЄЄѓЄЭЄѓЁЭЁЄЭАйХОЪбЁЬЄІЄЄЄЦЄѓЄкЄѓЁЭЁЄЭОнЬЕОнЁЬЄІЄОЄІЄрЄОЄІЁЭЁЄЭФКХЗЁЬЄІЄСЄчЄІЄЦЄѓЁЭЁЄЭЅЦоВкЁЬЄІЄЩЄѓЄВЁЭЁЄЭЅЧЬАаЁІЭЅЧЬКЩЁЬЄІЄаЄЄЁІЄІЄаЄНЄЏЁЭЁЄтГЭіЫпЁЬЄІЄщЄмЄѓЁЭЁЄБРПхЁЬЄІЄѓЄЙЄЄЁЭЁЄВёМсЁЬЄЈЄЗЄуЄЏЁЭЁЄБяЕЏЁЬЄЈЄѓЄЎЁЭЁЄБ§РИЁЬЄЊЄІЄИЄчЄІЁЭЁЄБўЭбЁЬЄЊЄІЄшЄІЁЭЁЄЄЊТъЬмЁЬЄЊЄРЄЄЄтЄЏЁЭЁЄВЏЙхЁЬЄЊЄУЄЏЄІЁЭЁЄВюЕДЁЬЄЌЄЁЭЁЄВУЛ§ЕЇХјЁЬЄЋЄИЄЄШЄІЁЭЁЄвъРеЁЬЄЋЄЗЄуЄЏЁЭЁЄВаТ№ЁЬЄЋЄПЄЏЁЭЁЄВцЫ§ЁЬЄЌЄоЄѓЁЭЁЄЖѕЧАЪЉЁЬЄЋЄщЄЭЄѓЄжЄФЁЭЁЄВРЭѕЁЬЄЌЄщЄѓЁЭЁЄВрЮЭЩбВРЁЬЄЋЄъЄчЄІЄгЄѓЄЌЁЭЁЄДЄЁЬЄЋЄяЄщЁЭЁЄДбЧАЁЬЄЋЄѓЄЭЄѓЁЭЁЄДХЯЊЁЬЄЋЄѓЄэЁЭЁЄВРЭхЁЬЄЄуЄщЁЭЁЄЗаЬкЁЬЄЄчЄІЄЎЁЭЁЄЙдНЛКСВщЁЬЄЎЄчЄІЄИЄхЄІЄЖЄЌЁЭЁЄЖьГІЁЬЄЏЄЌЄЄЁЭЁЄЖђУдЁЬЄАЄСЁЭЁЄИљЦСЁЬЄЏЄЩЄЏЁЭЁЄЖЁЭмЁЬЄЏЄшЄІЁЭЁЄИЫЮЂЁЬЄЏЄъЁЭЁЄЙШЯЁЁЬЄАЄьЄѓЁЭЁЄВјыУЁЬЄБЄВЄѓЁЭЁЄЗЖКРЁЬЄБЄЕЁЭЁЄВђУІЁЬЄВЄРЄФЁЭЁЄГАЦЛЁЬЄВЄЩЄІЁЭЁЄИМДиЁЬЄВЄѓЄЋЄѓЁЭЁЄЙсХЕЁЬЄГЄІЄЧЄѓЁЭЁЄЕѕВОЁЬЄГЄБЁЭЁЄЕяЛЮЁЬЄГЄИЁЭЁЄИхРИЁЬЄДЄЗЄчЄІЁЭЁЄИ№ПЉЁЬЄГЄФЄИЄЁЭЁЄИцЭшЗоЁЬЄДЄщЄЄЄДЄІЁЭЁЄИцЭјБзЁЬЄДЄъЄфЄЏЁЭЁЄИЂВНЁЬЄДЄѓЄВЁЭЁЄИРИьЦЛУЧЁЬЄДЄѓЄДЄЩЄІЄРЄѓЁЭЁЄЖтЮиКнЁЬЄГЄѓЄъЄѓЄЖЄЄЁЭЁЄЛЖВкЁЬЄЕЄѓЄВЁЭЁЄиђВљЁЬЄЖЄѓЄВЁЭЁЄЛАХгЄЮРюЁЬЄЕЄѓЄКЄЮЄЋЄяЁЭЁЄЛАЫцЁЬЄЕЄѓЄоЄЄЁЭЁЄЛЭЖьШЌЖьЁЬЄЗЄЏЄЯЄУЄЏЁЭЁЄЛтЛвПШУцЄЮУюЁЬЄЗЄЗЄЗЄѓЄСЄхЄІЄЮЄрЄЗЁЭЁЄУнфФЪжЄЗЁЬЄЗЄУЄкЄЌЄЈЄЗЁЭЁЄМЗЪѕЁЬЄЗЄУЄнЄІЁЭЁЄЛќШсЁЬЄИЄвЁЭЁЄеАЧЬЁЬЄЗЄуЄаЁЭЁЄМЫЭјЁЬЄЗЄуЄъЁЭЁЄНаРЄЁЬЄЗЄхЄУЄЛЁЭЁЄНЄЭхЁЬЄЗЄхЄщЁЭЁЄРКПЪЁЬЄЗЄчЄІЄИЄѓЁЭЁЄРЕЧАОьЁЬЄЗЄчЄІЄЭЄѓЄаЁЭЁЄНъСЇЁЬЄЗЄчЄЛЄѓЁЭЁЄПЗШЏАеЁЬЄЗЄѓЄмЄСЁЭЁЄПяДюЁЬЄКЄЄЄЁЭЁЄЦЌТЫТоЁЬЄКЄРЄжЄЏЄэЁЭЁЄРЄДжЁЬЄЛЄБЄѓЁЭЁЄРЄУЮЁЬЄЛЄСЁЭЁЄЛІРИЁЬЄЛЄУЄЗЄчЄІЁЭЁЄРуБЃЁЬЄЛЄУЄСЄѓЁЭЁЄбыЦсЁЬЄЛЄФЄЪЁЭЁЄРьЧАЁЬЄЛЄѓЄЭЄѓЁЭЁЄСЕЬфХњЁЬЄМЄѓЄтЄѓЄЩЄІЁЭЁЄСъЙЅЁЬЄНЄІЄДЄІЁЭЁЄТЉКвЁЬЄНЄЏЄЕЄЄЁЭЁЄКюжїРИЁЬЄНЄтЄЕЄѓЁЭЁЄТщИяЬЃЁЬЄРЄЄЄДЄпЁЭЁЄТчНАЁЬЄПЄЄЄЗЄхЄІЁЭЁЄшИШћЁЬЄРЄгЁЭЁЄТОЮЯЫмДъЁЬЄПЄъЄЄлЄѓЄЌЄѓЁЭЁЄУЖЦсЁЬЄРЄѓЄЪЁЭЁЄУЧЫіЫтЁЬЄРЄѓЄоЄФЄоЁЭЁЄУЮЗУЁЬЄСЄЈЁЭЁЄФЙЙРхЁЬЄСЄчЄІЄГЄІЄМЄФЁЭЁЄФЙМдЁЬЄСЄчЄІЄИЄуЁЭЁЄФоУЦЄЁЬЄФЄоЄЯЄИЄЁЭЁЄЦЛЖёЁЬЄЩЄІЄАЁЭЁЄЦВЦВНфЄъЁЬЄЩЄІЄЩЄІЄсЄАЄъЁЭЁЄЦЛГкЁЬЄЩЄІЄщЄЏЁЭЁЄЦтНяЁЬЄЪЄЄЄЗЄчЁЭЁЄЦюЬЕЛАЁЬЄЪЄрЄЕЄѓЁЭЁЄЦрЭюЁЬЄЪЄщЄЏЁЭЁЄоКмбЁЬЄЭЄЯЄѓЁЭЁЄйРВкШљОаЁЬЄЭЄѓЄВЄпЄЗЄчЄІЁЭЁЄУШЮќЁЬЄЮЄьЄѓЁЭЁЄЧЯМЏЁЬЄаЄЋЁЭЁЄШрДпЁЬЄвЄЌЄѓЁЭЁЄШцЕжЁІШцЕжЦєЁЬЄгЄЏЁІЄгЄЏЄЫЁЭЁЄШѓЖШЁЬЄвЄДЄІЁЭЁЄВаЄЮМжЁЬЄвЄЮЄЏЄыЄоЁЭЁЄЩдЛзЕФЁЬЄеЄЗЄЎЁЭЁЄЩсРСЁЬЄеЄЗЄѓЁЭЁЄЩлЛмЁЬЄеЄЛЁЭЁЄЪЌЪЬЁЬЄеЄѓЄйЄФЁЭЁЄЫЁЛеЁЬЄлЄІЄЗЁЭЁЄЫЗМчЁЬЄмЄІЄКЁЭЁЄЪ§ЪиЁЬЄлЄІЄйЄѓЁЭЁЄЪюФѓЁЬЄмЄРЄЄЁЭЁЄЫЁЭцЁЬЄлЄщЁЭЁЄШбЧКЁЬЄмЄѓЄЮЄІЁЭЁЄЫрыХЩдЛзЕФЁЬЄоЄЋЄеЄЗЄЎЁЭЁЄЫтЭхЁЬЄоЄщЁЭЁЄвишИЭхЁЬЄоЄѓЄРЄщЁЭЁЄЫўЪзЄЪЄЏЁЬЄоЄѓЄйЄѓЄЪЄЏЁЭЁЄШљПаЁЬЄпЄИЄѓЁЭЁЄЬЄСНЭЁЬЄпЄОЄІЁЭЁЄЬНЭјЁЬЄпЄчЄІЄъЁЭЁЄЬЄЭшЁЬЄпЄщЄЄЁЭЁЄЬЕЙЄЁЬЄрЄЏЁЭЁЄЬЕЛФЁЬЄрЄЖЄѓЁЭЁЄЬЕОяЁЬЄрЄИЄчЄІЁЭЁЄЬЕПдТЂЁЬЄрЄИЄѓЄОЄІЁЭЁЄЬНХкЁЬЄсЄЄЄЩЁЭЁЄЬЧСъЄтЄЪЄЄЁЬЄсЄУЄНЄІЄтЄЪЄЄЁЭЁЄЬЧЫЁЁЬЄсЄУЄнЄІЁЭЁЄЬбСлЁЬЄтЄІЄНЄІЁЭЁЄЬюИбСЕЁЬЄфЄГЄМЄѓЁЭЁЄЬыКЕЁЬЄфЄЗЄуЁЭЁЄЭЃВцЦШТКЁЬЄцЄЄЄЌЄЩЄЏЄНЄѓЁЭЁЄЭЗЛГЁЬЄцЄЕЄѓЁЭЁЄЮЇЕЗЁЬЄъЄСЄЎЁЭЁЄЮиВіЁЬЄъЄѓЄЭЁЭЁЄЮЎХОЁЬЄыЄЦЄѓЁЭЁЄЮмЭўЁЬЄыЄъЁЭЁЄЯЗЧЬПДЁЬЄэЄІЄаЄЗЄѓЁЭЁЄХЯЄъЄЫСЅЁЬЄяЄПЄъЄЫЄеЄЭЁЭ
ЁЁОхНвЄЮЄШЄЊЄъЁЄЦќЫмЄЧЄЯЪЉЖЕЄЌЙёЬБРИГшЄЫПМЄЏПЛЦЉЄЗЄПЄПЄсЄЫЁЄЪЉЖЕИьЄЯЦќЫмИьИьзУЄЫЙЄЏИЋЄщЄьЄыЄРЄБЄЧЄЪЄЏЁЄХОЕСЄђРИЄИЄЦТЏИьЄШЄЪЄУЄПЄтЄЮЄтТПЄЄЁЅБбИьТІЄЧЄтЦБЭЭЄЫЁЄЁж#32. ИХБбИьДќЄЫМкЭбЄЕЄьЄПЅщЅЦЅѓИьЁз ([2009-05-30-1]) ЄфЁж#1439. РЛНёЄЫЭГЭшЄЙЄыЩНИННИЁз ([2013-04-05-1]) ЄЮИьзУЁІЩНИНЅъЅЙЅШЄЫИЋЄщЄьЄыЄшЄІЄЫЁЄХіНщЄЯЅЅъЅЙЅШЖЕЄЮРьЬчЭбИьЄШЄЗЄЦЛЯЄоЄУЄПЄтЄЮЄЮЁЄИхЄЫРьЬчХЊЄЪЖСЄЄђМхЄсЁЄЛШЭбАш (register) ЄђГШЄВЄПИь (ex. candle, master, noon, school, verse) ЄтОЏЄЪЄЏЄЪЄЄЁЅЄГЄЮХРЄЧЄтЁЄЦќБбЮОИРИьЄЫЄЊЄЄЄЦНЁЖЕХСЭшЄШИьзУЛЫЄЮДиЯЂЄђШцГгТаОШЄЙЄыЄГЄШЄЯАеЕСПМЄЄЁЅ
ЁЁЁІ ЁиЦќЫмИьГиИІЕцЛіХЕЁйЁЁШєХФ ЮЩЪИЄлЄЋ ЪдЁЄЬРМЃНёБЁЁЄ2007ЧЏЁЅ
2014-04-01 Tue
ЂЃ #1800. ЭЭЁЙЄЪШПТаИь [semantics][markedness][antonymy][lexicology]
ЁЁШПТаИь (opposite) ЄЫЄЯШПАеИьЁЄШПЕСИьЄЪЄЩЄЮИЦЄгЬОЄЌЄЂЄыЄЌЁЄЭбИьЄЮЩдАТФъЄЕЄтЄЕЄыЄГЄШЄЪЄЌЄщЁЄВПЄђЄтЄУЄЦШПТаЄШЄЙЄыЄЋЄЫЄФЄЄЄЦЄЮЭ§ВђЄтЭЭЁЙЄЧЄЂЄыЁЅ
ЁЁЙѕЄЮШПТаЄЯЧђЄЋЁЄЄЗЄЋЄЗЧђЄЮШПТаЄЯЙШЁЪРжЁЫЄШЄтЙЭЄЈЄщЄьЄыЄЮЄЧЄЯЄЪЄЄЄЋЁЅЄРЄЌЁиРжЄШЙѕЁйЄШЄЄЄІСШЄпЙчЄяЄЛЄтЄЂЄыЄЗЁЄПЎЙцЕЁЄђЛзЄЄЩтЄЋЄйЄьЄаРжЄШРФЁЪМТКнЄЮПЇЄЯЮаЁЫЄШЄЄЄІТаЮЉЄтЙЭЄЈЦРЄыЁЅЄоЄПЁжЙтЄЄЁзЄЮШПТаЄЫЄЯЁжФуЄЄЁзЄШЁжАТЄЄЁзЄЮ2ЄФЄЌЄЂЄыЄЌЁЄЁжФуЄЄЁзЄЮШПТаЄЫЄЯЁжЙтЄЄЁз1ЄФЄЗЄЋЄЪЄЄЁЅЗЛЄЮШПТаЄЯФяЄЋЁЄЄЂЄыЄЄЄЯЛаЄЋЁЄЄЯЄПЄоЄПЫхЄЋЁЅИЄЄЫТаЄЙЄыЧЁЄЅПЅГЄЫТаЄЙЄыЅЄЅЋЄЯШПТаИьЄШЄЄЄЈЄыЄЮЄЋЁЅhappy ЄЮШПТаЄЯ unhappy ЄЋЁЄЄНЄьЄШЄт sad ЄЋЁЅФЙЄЄЄШУЛЄЄЁЄРИЄШЛрЁЄЛГЄШГЄЁЄЫЬЄШЦюЁЄЩзЄШКЪЄЯЁЄЄНЄьЄОЄьЦБЄИД№НрЄЫЄшЄУЄЦШПТаИьЄШИЦЄйЄыЄЮЄРЄэЄІЄЋЁЅ
ЁЁАеЬЃЯРЄЧЄЯЁЄШПТаИьЄЫЄтЭЭЁЙЄЪМяЮрЄЌЄЂЄыЄГЄШЄЌЧЇЄсЄщЄьЄЦЄЄЄыЁЅАЪВМЄЫ Hofmann (40--46, 57--60) ЄЫЕђЄУЄЦЁЄТхЩНХЊЄЪЄтЄЮЄђЄоЄШЄсЄшЄІЁЅ
(1) (gradable) antonym
ЁЁКЧЄтХЕЗПХЊЄЪШПТаИьЄЯЁЄhigh / lowЁЄlong / short, old / new, hot / cold ЄЮЄшЄІЄЪФјХйЄђЩНЄяЄЙЗСЭЦЛьЄЮТаЄЧЄЂЄыЁЅЄГЄьЄщЄЮШПТаИьЗСЭЦЛьЄЯЁЄБбИьЄЧЄЄЄЈЄаШцГгЕщЄфКЧОхЕщЄЫЄЧЄЄыЁЄvery ЄЧФјХйЄђЖЏЄсЄщЄьЄыЄЪЄЩЄЮЦУФЇЄђЄтЄФЁЅФјХйЄђПвЄЭЄыЕПЬфЄфЬОЛьЗСЄЫЛШЭбЄЕЄьЄыЄЮЄЯЁЄТаЄЮЄІЄСЄЄЄКЄьЄЋЄЧЄЂЄъЁЄЄНЄСЄщЄЌАьЛўХЊЄЫУцЮЉХЊЄЪАеЬЃЄђУДЄІЄГЄШЄЫЄЪЄыЁЅЮуЄЈЄаЁЄlong / short ЄЮТаЄЫДиЄЗЄЦЄЯ long ЄЌЬЕЩИЄШЄЪЄъЁЄHow long is the train? Єф the length of the train ЄЪЄЩЄШУцЯТЄЗЄПАеЬЃЄЧЭбЄЄЄщЄьЄыЁЅЦќЫмИьЄЧЄтЁжЄЩЄЮЄЏЄщЄЄФЙЄЄЄЮЄЋЁзЄШПвЄЭЄыЄЗЁЄЬОЛьЄЯЁжФЙЄЕЁзЄШЄЄЄІЁЅДСЛњЄЧЄЯЁжФЙУЛЁзЁжТчОЎЁзЁжДЈУШЁзЄЪЄЩЄШТаЄЫЄЗЄЦУцЮЉХЊЄЪФјХйЄђЩНЄяЄЙЄГЄШЄЌЄЧЄЄыЄЮЄЌЄЊЄтЄЗЄэЄЄЁЅ
(2) complementary
ЁЁon / offЁЄtrue / false, finite / infinite, mortal / immortal, single / married ЄЪЄЩЄЮЦѓЮЇЧиШПЄЮТаЄђЙНРЎЄЙЄыЁЅ(1) ЄЮТаЄШАлЄЪЄъЁЄvery ЄЪЄЩЄЧЖЏЄсЄыЄГЄШЄЯЄЧЄЄКЁЄФјХйЄШЄЗЄЦЩНИНЄЧЄЄЪЄЄЅЧЅИЅПЅыЄЪДиЗИЄЧЄЂЄыЁЅАьШЬХЊЄЫЁЄШнФъЄЮРмЦЌМЄЌЩеВУЄЕЄьЄЦЄЄЄыОьЙчЄђНќЄЄЄЦЁЄЄЩЄСЄщЄЌЬЕЩИЄЧЄЂЄыЄЋЄђЗшЄсЄыЄГЄШЄЌЄЧЄЄЪЄЄЁЅЄПЄРЄЗЁЄТаЄЮАьЪ§ЄЌ (1) ЄЮРМСЄђЄтЄСЁЄТОЪ§ЄЌ (2ЁЫЄЮРМСЄђЄтЄФЅБЁМЅЙЄтЄЂЄыЁЅЮуЄЈЄаЁЄopen / shut, cooked / raw, invisible / visible ЄЯЁЄЄНЄьЄОЄьЄЮЅкЅЂЄЮЄІЄССАМдЄЯ gradable ЄЧЄЂЄыЁЅ
ЁЁТОЄЮЩЪЛьЄЧЄЯЁЄmale / female, stop / move ЄЪЄЩЄЌЕѓЄВЄщЄьЄыЁЅ
(3) antonymous group
ЁЁblack / white / red / blue / green ЄЮЄшЄІЄЫЁЄЁжШПТаЁзЄШЄЪЄъЄІЄыЄтЄЮЄЌНИЄоЄУЄЦАьЯЂЄЮИьЗВЁЪЄГЄЮОьЙчЄЫЄЯПЇКЬИьзУЁЫЄђЗСРЎЄЙЄыЄтЄЮЁЅЄГЄьЄщЄЯШПТаИьЄШЄЄЄІЄшЄъЄЯЁЄЄрЄЗЄэЦБЄИИьЗВЄЫТАЄЙЄыЄШЄЄЄІАеЬЃЄЧЄЯЮрЕСИьЄШЄтИРЄІЄйЄЄЧЄЂЄыЁЅИпЄЄЄЫЦБЮрЄЧЄЂЄъЄЪЄЌЄщЄтЁЄЄНЄЮТАЄЮЦтЩєЄЧЄЯИЧЭЄЮУЯАЬЄђРъЄсЄЦЄЊЄъИпЄЄЄЫКЙАлХЊЄЧЄЂЄыЄШЄЄЄІХРЄЧЁЄИЋЪ§ЄЫЄшЄУЄЦЄЯЁжШПТаИьЁзЄШЄтЄЕЄьЄыЄЫЄЙЄЎЄЪЄЄЁЅdog ЄШ cat ЄЯЄНЄьЄОЄьЦБЮрЄЧЄЂЄъЄЪЄЌЄщЁЄЦБТАЄЮЦтЩєЄЧСъИпЄЫАлЄЪЄУЄЦЄЄЄыЄЮЄЧЁЄantonymous group ЄЮАьЩєЄђЄЪЄЗЄЦЄЄЄыЄШЄЄЄЈЄыЁЅИЄЄШЧЄЯЦќЫмИьЄЧЄтБбИьЄЧЄтДЗЭбХЊЄЫЅкЅЂЄђЄЪЄЙЄЮЄЧТаИьЄШИЋЄЪЄЕЄьЄыЄЌЁЄЦБЄИЅАЅыЁМЅзЄЮЙНРЎАїЄШЄЗЄЦЄЯЁЄСЭЁЄЦкЁЄИбЁЄМЏЄђДоЄсЄПТПЄЏЄЮЦАЪЊЄђЕѓЄВЄыЄГЄШЄЌЄЧЄЄыЁЅЗСЭЦЛьЄЮЮуЄШЄЗЄЦЄЯЁЄbig / small ЄЧЄЂЄьЄа (1) ЄЮЮуЄШЦБЭЭЄЫЄпЄЈЄыЄЌЁЄhuge / big / small / tiny ЄШЄЄЄІ4УЪГЌРЉЄЮЄЪЄЋЄЧЙЭЄЈЄьЄа (3) ЄђЬфТъЄЫЄЗЄЦЄЄЄыЄГЄШЄЌЄяЄЋЄыЁЅЄФЄоЄъЁЄ(3) ЄЯЁЄ(1) Єф (2) ЄЮ2ЙрТаЮЉЄШЄЯАлЄЪЄъЁЄЪЃПєЙрТаЮЉЄШИРЄЄДЙЄЈЄЦЄтЄшЄЄЄРЄэЄІЁЅnorth / south / east / west ЄЮ4ЙрЬмЄЪЄЩЁЄЪ§ИўЄЫДиЄЗЄЦЦтЩєЙНТЄЄђЄтЄУЄЦЄЄЄыЄшЄІЄЪЅАЅыЁМЅзЄтЄЂЄыЁЅ
ЁЁЦќЫмИьЄЧЛГЄЮШПТаЄЯГЄЁЪЄЂЄыЄЄЄЯРюЁЉЁЫЄЌЩсФЬЄРЄЌЁЄЅЂЅсЅъЅЋЄЧЄЯ mountain ЄЫТаЄЗЄЦЄЯ valley ЄЌЩсФЬЄЧЄЂЄыЁЅЄГЄЮЄшЄІЄЫЁЄЅАЅыЁМЅдЅѓЅАЄЫЪИВНХЊБЦЖСЄЌИЋЄщЄьЄыЄтЄЮЄтТПЄЄЁЅ
(4) reversative
ЁЁЦАЛьЄЮЦАКюЄЫЄФЄЄЄЦЁЄЕеХОДиЗИЄђЩНЄяЄЙЁЅtie ЁЪЗыЄжЁЫЄШ untie ЁЪЄлЄЩЄЏЁЫЁЄclothe ЁЪУхЄЛЄыЁЫЄШ unclothe ЁЪУІЄЌЄЛЄыЁЫЄЪЄЩЁЅВсЕюЪЌЛьЗСЭЦЛьЄЫЄЗЄЦ tied / untied, clothed / unclothed ЄЮТаЮЉЄиХОВНЄЙЄыЄШЁЄ(1) Єф (2) ЄЮЮуЄШЄЪЄыЁЅappear / disappear, enable / disable ЄтЦБЭЭЁЅ
(5) converse
ЁЁhusband / wife, parent / child ЄЮЄшЄІЄЪСъИпЄЫЕеЪ§ИўЄЧЄЂЄъЄЪЄЌЄщЪфЄЄЙчЄІДиЗИЁЅ"X is the (husband) of Y." ЄЮЄШЄЁЄ"Y is the (wife) of X." ЄЌРЎЄъЮЉЄФЁЅЄРЄЌЁЄson / father ЄЯОхЄЮИРЄЄДЙЄЈЄЌЩЌЄКЄЗЄтЄЧЄЄЪЄЄЄЮЄЧЁЄИЋЄЛЄЋЄБЄЮ converse ЄЧЄЂЄы (ex. "X is the father of Liz") ЁЅ
ЁЁРМСЄЯАлЄЪЄыЄЌЁЄbuy / sell, lend / borrow ЄЮЄшЄІЄЫУБАьЄЮНаЭшЛіЄђШПТаЄЮДбХРЄЧИЋЄыЄтЄЮЄфЁЄabove / below, in front of / behind, north of / south of, right / left ЄЮЄшЄІЄЫЖѕДжХЊАЬУжДиЗИЄђЩНЄяЄЙЄтЄЮЄтЁЄconverse ЄШЄЄЄЈЄыЁЅ
ЁЁОхЕЄЮЄшЄІЄЫЄЄьЄЄЄЫЪЌЮрЄЧЄЄЪЄЄЄшЄІЄЪЁжШПТаИьЁзЄтЄЂЄыЄЯЄКЄРЄЌЁЄАьБўЄЮЖшЪЌЄШЄЗЄЦЛВЙЭЄЫЄЪЄыЄРЄэЄІЁЅ
ЁЁЁІ Hofmann, Th. R. Realms of Meaning. Harlow: Longman, 1993.
2014-03-26 Wed
ЂЃ #1794. МкЭбЄЯЄЪЄМЕЏЄГЄыЄЋ (2) [borrowing][lexicology][loan_word][typology]
ЁЁЁж#46. МкЭбЄЯЄЪЄМЕЏЄГЄыЄЋЁз ([2009-06-13-1]) ЄЮЕЛіЄЧЁЄИьзУЄЌТОИРИьЄЋЄщМкЭбЄЕЄьЄыЭ§ЭГЄђЙЭЄЈЄПЁЅЄЗЄЋЄЗЁЄЄГЄЮЁжЄЪЄМЁзЄЯЕцЖЫЄЮЬфЄЄЄЧЄЂЄъЁЄЫмГЪХЊЄЫФЩЕцЄЙЄыЄЮЄЧЄЂЄьЄаЁЄРшЄЫТОЄЮ4W1HЄЮЬфЄЄЄЋЄщФйЄЗЄЦЄЄЄЋЄЪЄБЄьЄаЄЪЄщЄЪЄЄЁЅwhy ЄЮСАЄЫЁЄwhat, who, when, where, how ЄђЬфЄІЩЌЭзЄЌЄЂЄыЄШЄЄЄІЄГЄШЄРЁЅЄНЄГЄЧ borrowing ЄЮЕЛіЄђУцПДЄЫЁЄЫмЅжЅэЅАЄЧЄтЭЭЁЙЄЪЅЂЅзЅэЁМЅСЄђКЮЄУЄЦЄЄПЁЅ
ЁЁМкЭбИьЄЮЁжЄЪЄМЁзЄЫЧїЄыЯРЙЭЄШЄЗЄЦЄЯЁЄHans Käsmann (Studien zum kirchlichen Wortschatz des Mittelenglischen 1100--1350. Eng Beitrag zum Problem der Sprachmischung. Tübingen, 1961.) ЄЫЕђЄУЄП Görlach (149--50) ЄЮЄтЄЮЄЌЄЂЄыЄЮЄЧОвВ№ЄЗЄшЄІЁЅ"causes and situations favouring the transfer" ЄШЄЗЄЦЁЄМЁЄЮЄшЄІЄЪЪЌЮрЩНЄђЗЧЄВЄЦЄЄЄыЁЪИьЮуЄЮСАЄЮ "A11" ЄЪЄЩЄЯЁЅGörlach ЄЮЅЦЅЅЙЅШЛВОШЕЙцЁЫЁЅ
(A) Gaps in the indigenous lexis
1. The word is taken over together with the new content and the new object: A11 myrre, D31 senep, F21 sabat, synagoge.
2. A well-known content has no word to designate it: D32 plant
3. Existing expressions are insufficient to render specific nuances ('misericordia', see blow).
(B) Previous weakening of the indigenous lexis
4. The content had been experimentally rendered by a number of unsatisfactory expressions: E15 leorningcniht||disciple.
5. The content had been rendered by a word weakened by homonymy, polysemy, or being part of an obsolescent type of word-formation: C24 hilid||covered; C25 hǣlan = heal, save; H11 hǣlend||sauyoure.
6. An expression which is connotationally loaded needs to be replaced by a neutral expression.
(C) Associative relations
7. A word is borrowed after a word of the same family has been adopted: D49 iust (after justice; cf. judge n., v., judgement).
8. The borrowing is supported by a native word of similar form: læccan Ёп catchen; the process was particularly important with adoptions from Scandinavian.
9. 'Corrections': an earlier loanword is adapted in form/replaced by a new loanword: F2 engel||aungel.
(D) Special extralinguistic conditions
10. Borrowing of words needed for rhymes and metre.
11. Adoptions not motivated by necessity but by fashion and prestige.
12. Words left untranslated because the translator was incompetent, lazy or anxious to stay close to his source: H10 euangelise EV.
There remain a large number of uncertain classifications, most of these somehow connected with 11), a category which is very difficult to define.
ЁЁ(A), (B), (C) ЄЯЄоЄШЄсЄЦЁЄДћТИЄЮИьзУТЮЗЯЄЋЄщРИЄИЄыМкЭбЄиЄЮАЕЮЯЄШЄЄЄІЄГЄШЄЌЄЧЄЄыЄРЄэЄІЄЋЁЅЁж#901. МкЭбЄЮЪЌЮрЁз ([2011-10-15-1]) ЄЧЄпЄПЅПЅЄЅнЅэЅИЁМЄШЄтИђКЙЄЙЄыЁЅ(D) ЄЯЄЊЄшЄНИРИьГАХЊЄЪЭзАјЄШЄЄЄІЄйЄЄтЄЮЄЧЄЂЄыЁЅФЬОяЁЄИьЄЮМкЭбЄђЯУТъЄЫЄЙЄыОьЙчЄЫЄЯЁЄИРИьГАХЊЄЪЭзАјЄЌУэЬмЄЕЄьЄыЄГЄШЄтТПЄЄЄЌЁЄЄГЄЮЪЌЮрЄЯСъТаХЊЄЫЄНЄЮАЗЄЄЄЌМхЄЄЄЮЄЌЦУФЇЄРЁЅЗыЖЩЄЮЄШЄГЄэЁЄКЧИхЄЫУЂЄЗНёЄЄЧЦЈЄВИ§ОхЄђТЧЄУЄЦЄЄЄыЄшЄІЄЫЁЄЄГЄЮЄшЄІЄЪЪЌЮрЄђЮЉЄЦЄыЄГЄШЄЫИТГІЄЌЄЂЄыЄЮЄРЄэЄІЁЅFischer (105) ЄЯЁЄЄГЄЮЪЌЮрЄЫЩдЫўЄђЩНЬРЄЗЄЦЄЄЄыЁЅ
Like all attempts to "explain" language change, this one suffers from the fact that explanations can only be guessed at and that actual, verifiable proof is hard to come by. Any such typology, therefore, will remain tentative.
ЁЁЫСЦЌЄЧНвЄйЄПЄшЄІЄЫЁЄЄоЄКЄЯМкЭбЄЮ4W1HЄђУхМТЄЫЭ§ВђЄЗЄЦЄцЄЏЄШЄГЄэЄЋЄщЛЯЄсЄыЩЌЭзЄЌЄЂЄыЁЅ
ЁЁЁІ Görlach, Manfred. The Linguistic History of English. Basingstoke: Macmillan, 1997.
ЁЁЁІ Fischer, Andreas. "Lexical Borrowing and the History of English: A Typology of Typologies." Language Contact in the History of English. 2nd rev. ed. Ed. Dieter Kastovsky and Arthur Mettingers. Frankfurt am Main: Peter Lang, 2003. 97--115.
2014-03-24 Mon
ЂЃ #1792. 18--20РЄЕЊЄЮЅеЅщЅѓЅЙМкЭбИь [french][loan_word][lexicology]
ЁЁЁж#117. ЅеЅщЅѓЅЙМкЭбИьЄЮЧЏТхЪЬЪЌЩлЁз ([2009-08-22-1]) ЄЧИЋЄПЄШЄЊЄъЁЄБбИьЛЫЄЧЄЯЁЄЅЮЅыЅоЅѓЁІЅГЅѓЅЏЅЇЅЙЅШАЪЙпЁЄЅеЅщЅѓЅЙМкЭбИьЄЮЮЎЦўЄЌРфЄЈЄПЛўДќЄЯЄЪЄЄЁЅ14РЄЕЊЁЄ16РЄЕЊЄђ2ЄФЄЮЅдЁМЅЏЄШЄЗЄЦЖсТхАЪЙпЄЯСъТаХЊЄЫЮЎЦўЄЯОЏЄЪЄсЄРЄЌЁЄИНКпЄЫЛъЄыЄоЄЧЅеЅщЅѓЅЙМкЭбИьЄЯБбИьЄЮИьзУЄЫУхМТЄЫЙзИЅЄЗЄЦЄЄЦЄЄЄыЁЅ
ЁЁЛўТхЄДЄШЄЮЅеЅщЅѓЅЙМкЭбИьЄЮЦУФЇЄфАьЭїЄЫЄФЄЄЄЦЄЯЁЄЁж#1210. УцБбИьЄЮЅеЅщЅѓЅЙМкЭбИьЄЮАьЭїЁз ([2012-08-19-1])ЁЄЁж#1291. ЅеЅщЅѓЅЙМкЭбИьЄЮМкЭбЛўДќЄЮКЙЁз ([2012-11-08-1])ЁЄЁж#1209. 1250ЧЏЄђЖЄШЄЙЄыЅеЅщЅѓЅЙМкЭбИьЄЮЖшЪЌЁз ([2012-08-18-1])ЁЄЁж#1411. НщДќЖсТхБбИьЄЫЦўЄУЄП "oversea language"Ёз ([2013-03-08-1])ЁЄЁж#678. ШЦЅшЁМЅэЅУЅбХЊЄЪ18РЄЕЊЄЮЅеЅщЅѓЅЙМкЭбИьЁз ([2011-03-06-1])ЁЄЁж#594. ЖсТхБбИьАЪЙпЄЮЅеЅщЅѓЅЙМкЭбИьЄЮЦУФЇЁз ([2010-12-12-1]) ЄЪЄЩЄЧМшЄъОхЄВЄЦЄЄПЄЌЁЄКЃВѓЄЯ Crystal (460) ЄЫЗЧКмЄЕЄьЄЦЄЄЄы18--20РЄЕЊЄЮЅеЅщЅѓЅЙМкЭбИьЄЮШДПшЄђМЈЄНЄІЁЅ
[18th century loanwords]
bouquet, canteen, clique, connoisseur, coterie, cuisine, debut, espionage, etiquette, glacier, liqueur, migraine, nuance, protégé, roulette, salon, silhouette, souvenir, toupee, vignette
[19th century loanwords]
acrobat, baroque, beige, blouse, bonhomie, café, camaraderie, can-can, chauffeur, chef, chic, cinematography, cliché, communism, croquet, debutant, dossier, en masse, flair, foyer, genre, gourmet, impasse, lingerie, matinée, menu, morgue, mousse, nocturne, parquet, physique, pince-nez, première, raison d'être, renaissance, repertoire, restaurant, risqué, sorbet, soufflé, surveillance, vol-au-vent, volte-face
[20th century loanwords]
art deco, art nouveau, u pair, auteur, blasé, brassiere, chassis, cinéma-vérité, cinematic, coulis, courgette, crime passionnel, détente, disco, fromage frais, fuselage, garage, hangar, limousine, microfiche, montage, nouvelle cuisine, nouvelle vague, questionnaire, tranche, visagiste, voyeurism
ЁЁМкЭбИьЄЮЪЌЬюЄШЄЗЄЦЄЯЁЄ18РЄЕЊЄЯМвВёРЉХйЁІНЌДЗЁЄ19РЄЕЊЄЯЗнНбЁЄПЉЪЊЁЄАсЮрЁЄ20РЄЕЊЄЯПЗЗнНбЁЄЕЛНбЄЌЦУФЇХЊЄРЄэЄІЄЋЁЅПєЄРЄБЄЧЄЄЄЈЄаЁЄИхДќЖсТхЄЫЄЊЄБЄыЅеЅщЅѓЅЙМкЭбИьЄЮЅдЁМЅЏЄЯ19РЄЕЊЄЫЄЂЄыЄШЄпЄЦЄшЄЄЄРЄэЄІЁЅ
ЁЁЄЪЄЊЁЄ21РЄЕЊЄЮЅеЅщЅѓЅЙМкЭбИьЄЫЄФЄЄЄЦ OED ЄђИЁКїЄЗЄПЄШЄГЄэЁЄparkour, traceur ЄЮ2ИьЄРЄБЄЌЅвЅУЅШЄЗЄПЁЅСАМдЄЯ2002ЧЏЄЌНщНаЄЧЁЄ"The discipline or activity of moving rapidly and freely over or around the obstacles presented by an (esp. urban) environment by running, jumping, climbing, etc." ЄШФъЕСЄЕЄьЄыЁЅИхМдЄЯ2003ЧЏЄЌНщНаЄЧЁЄ"A person who participates in parkour" ЄШЄЮЄГЄШЁЅБбИьЄЫЄШЄУЄЦЄЯЩхЄьБяЄШЄтЄЄЄЈЄыЅеЅщЅѓЅЙИьЄЋЄщЄЮМкЭбЄЯЁЄ21РЄЕЊЄтТГЄЄЄЦЄцЄЏЁІЁІЁІЁЅ
ЁЁЁІ Crystal, David. The Stories of English. London: Penguin, 2005.
2014-03-10 Mon
ЂЃ #1778. МкЭбИьИІЕцЄЮ to-do list [loan_word][borrowing][semantics][lexicology][typology][methodology]
ЁЁЅМЅпЄЮГиРИЄЮТДЖШЯРЪИИІЕцЄђЄпЄЦЄЄЄыВсФјЄЧЁЄFischer ЄЫЄшЄыМкЭбИьИІЕцЄЮЅПЅЄЅнЅэЅИЁМЄЫЄФЄЄЄЦЄЮЯРЪИЄђЦЩЄѓЄРЁЅБбИьЛЫЄђДоЄсЄПНєИРИьЄЫЄЊЄБЄыМкЭбИьзУЄЮИІЕцЄЯЁЄ3ЄФЄЮДбХРЄЋЄщЄЪЄЕЄьЄЦЄЄПЄШЄЄЄІЁЅ(1) morpho-etymological (or morphological), (2) lexico-semantic (or semantic), (3) socio-historical (or sociolinguistic) ЄЧЄЂЄыЁЅ
ЁЁ(1) ЄЯЁЄЁж#901. МкЭбЄЮЪЌЮрЁз ([2011-10-15-1]) ЄЧЯРЄИЄПЄшЄІЄЫЁЄmodel ЄШ loan ЄШЄЌЗСТжХЊЄЫЄЄЄЋЄЪЄыДиЗИЄЫЄЂЄыЄЋЄШЄЄЄІДбХРЄЧЄЂЄыЁЅЗСТжХЊЄЪДиЗИЄЌЬмЄЫИЋЄЈЄыЄтЄЮЄЌ importationЁЄИЋЄЈЄЪЄЄЄтЄЮЁЪЄЙЄЪЄяЄСАеЬЃЄЮЄпЄЮМкЭбЁЫЄЌ importation ЄЧЄЂЄыЁЅ(2) ЄЯЁЄМкЭбЄЮОзЗтЄЫЄшЄъЁЄМкЭбТІИРИьЄЮАеЬЃТЮЗЯЄШИьзУТЮЗЯЄЌКЦЪдЄЕЄьЄПЄЋШнЄЋЄђЯРЄИЄыДбХРЄЧЄЂЄыЁЅ(3) ЄЯЁЄИьЄЮМкЭбЄЌЄЩЄЮЄшЄІЄЪМвВёИРИьГиХЊЄЪОѕЖЗЄЮЄтЄШЄЫЙдЄяЄьЄПЄЋЁЄЮОМдЄЮСъДиДиЗИЄђЬРЄщЄЋЄЫЄЗЄшЄІЄШЄЙЄыДбХРЄЧЄЂЄыЁЅЄГЄЮ3ЪЌЮрЄЯИпЄЄЄЫИђЄяЄыЄШЄГЄэЄтЄЂЄыЄЗЁЄЛіМТЄНЄЮИђЄяЄъЪ§ЄЮСШЄпЙчЄяЄЛЄГЄНЄЌФЩЕцЄЕЄьЄЪЄБЄьЄаЄЪЄщЄЪЄЄЄЮЄРЄЌЁЄЄЊЄЊЄрЄЭЬРВђЄЪЪЌЄБЪ§ЄРЄШЛзЄІЁЅ
ЁЁFischer ЄЯЁЄЄГЄЮЄЪЄЋЄЧ (3) ЄЮМвВёИРИьГиХЊЄЪДбХРЄЯКЧЄтЖНЬЃЄђЄНЄНЄыЄЌЁЄЬмЄЫИЋЄЈЄыИІЕцРЎВЬЄЯДќТдЄЧЄЄЪЄЄЄРЄэЄІЄШШсДбХЊЄЧЄЂЄыЁЅЄГЄЮДбХРЄђНХЛыЄЗЄП Thomason and Kaufman ЄђЛВОШЄЗЁЄЙтЄЏЩОВСЄЗЄЪЄЌЄщЄтЁЄМкЭбИьИІЕцЄЫЄЯЙзИЅЄЗЄЪЄЄЄРЄэЄІЄШНвЄйЄЦЄЄЄыЁЅ
Of the three types of typologies discussed here, the third, although the most attractive because of its sociolinguistic orientation, is possibly the least useful for a study of lexical borrowing: lexis is an unreliable indicator of the precise nature of a contact situation, and the socio-historical evidence necessary to reconstruct the latter is often not available. Morphological and semantic typologies on the other hand, though seemingly more traditional, can yield a great deal of new information if an attempt is made to study a whole semantic domain and if such studies are truly comparative, comparing different text types, different source languages or different periods. (110)
ЁЁFischer ЄЯ (1) ЄШ (2) ЄЮДбХРЄГЄНЄЌЁЄМкЭбИьИІЕцЄЫЄЊЄЄЄЦДѕЫОЄЮЄтЄЦЄыЪ§ИўЄЧЄЂЄыЄШЛиЦюЄЙЄыЁЅАьИЋЄЙЄыЄШЁЄБбИьЛЫЄЫИТФъЄЗЄПОьЙчЁЄЄГЄЮ2ЄФЄЮДбХРЁЄЄШЄъЄяЄБ (1) ЄЮДбХРЄЋЄщЄЯЁЄСъХіЄЫИІЕцЄЌЄЪЄЕЄьЄЦЄЄЄыЄЮЄЧЄЯЄЪЄЄЄЋЄШЛзЄяЄьЄыЄЌЁЄАЦГАЄШЄНЄІЄЧЄтЄЪЄЄЁЅЮуЄЈЄаЁЄАеЬЃМкЭб (semantic loan) ЄЫТхЩНЄЕЄьЄы substitution ЗПЄЮМкЭбИьЄЫЄФЄЄЄЦЄЯЁЄИІЕцЄЮУпРбЄЌЄНЄьЄлЄЩЄЪЄЄЁЅЄГЄьЄЫЄЯЁЄimportation ЄЫТаЄЗЄЦ substitution ЄЯАеЬЃЄђАЗЄІЄЮЄЧИЋЄЈЄЫЄЏЄЄЄГЄШЁЄЩбХйЄШЄЗЄЦШцГгХЊОЏЄЪЄЄЄГЄШЄЌЭ§ЭГЄШЄЗЄЦЕѓЄВЄщЄьЄыЁЅ
ЁЁЄНЄьЄЫЄЗЄЦЄтЁЄИьЄђМкЭбЄЙЄыЄШЄЄЫЁЄЄЂЄыОьЙчЄЫЄЯ importation ЗПЄЧЁЄЪЬЄЮОьЙчЄЫЄЯ substitution ЗПЄЧМшЄъЙўЄрЄЮЄЯЄЪЄМЄРЄэЄІЄЋЁЅЧиИхЄЫЄЩЄЮЄшЄІЄЪСЊТђИЖЭ§ЄЌЦЏЄЄЄЦЄЄЄыЄЮЄРЄэЄІЄЋЁЅМкЭбТІИРИьЄЮЯУМдЁЪНИУФЁЫЄЮПДЭ§ЄфЁЄИјХЊЁІЛфХЊЄЪИРИьРЏКіЄШЄЄЄУЄПМвВёИРИьГиХЊЄЪЭзАјЄЫЄФЄЄЄЦЄЯИРЕкЄЕЄьЄыЄГЄШЄЌЄЂЄыЄЌЁЄОхЕ (1) Єф (2) ЄЮИРИьГиХЊЄЪДбХРЄЋЄщЄЮЅЂЅзЅэЁМЅСЄЯЄлЄШЄѓЄЩЄЪЄЄЄШЄЄЄУЄЦЄшЄЄЁЅFischer (100) ЄЮЬфТъАеМБЁЄ"why certain types of borrowing seem to be more frequent than others, depending on period, source language, text type, speech community or language policy, to name only the most obvious factors." ЄЯХЊЄђМЭЄЦЄЄЄыЁЅЛфМЋПШЄтЁЄЦБЭЭЄЮЬфТъАеМБЄђЁЄЁж#902. МкЭбЄЕЄьЄфЄЙЄЄИРИьЙрЬмЁз ([2011-10-16-1])ЁЄЁж#903. МкЭбЄЮТПЄЄИРИьЄШОЏЄЪЄЄИРИьЁз ([2011-10-17-1])ЁЄЁж#934. МкЭбЄЮТПЄЄИРИьЄШОЏЄЪЄЄИРИь (2)Ёз ([2011-11-17-1])ЁЄЁж#1619. ЄЪЄМ deus ЄЌМкЭбЄЕЄьЄК God ЄЌЪнЄПЄьЄПЄЮЄЋЁз ([2013-10-02-1]) ЄЪЄЩЄЧМЈКЖЄЗЄЦЄЄПЁЅ
ЁЁБбИьЛЫЄЫЄЊЄБЄыЅщЅЦЅѓМкЭбИьЄђЙЭЄЈЄЦЄпЄьЄаЁЄИХБбИьЄЧЄЯ importation ЄШЪТЄѓЄЧ substitution ЄтТПЄЋЄУЄПЁЪЄрЄЗЄэИхМдЄЮЄлЄІЄЌТПЄЋЄУЄПЄШЄтЕФЯРЄЗЄІЄыЁЫЄЌЁЄУцБбИьАЪЙпЄЯ importation ЄЌМчЮЎЄЧЄЂЄыЁЅFischer (101) ЄЧПЈЄьЄщЄьЄЦЄЄЄыЄшЄІЄЫЁЄStandard High German ЄШ Swiss High German ЄЫЄЊЄБЄыЅэЅоЅѓЅЙЗЯМкЭбИьЄЧЄЯЁЄСАМдЄЌ substitution ДѓЄъЁЄИхМдЄЯ importation ДѓЄъЄЮЗЙИўЄђМЈЄЙЄЗЁЄЅЂЅсЅъЅЋБбИьЄЧЄЮ substitution ЗПЄЮ fall ЄЫТаЄЗЄЦЅЄЅЎЅъЅЙБбИьЄЧЄЮ importation ЗПЄЮ autumn ЄШЄЄЄІЖНЬЃПМЄЄЮуЄтЄЂЄыЁЅЦќЫмИьЄиЄЮРОЭЮИьЄЮМкЭбЄтЁЄЬРМЃДќЄЫЄЯДСИьЄЫЄшЄы substitution ЄЌМчЮЎЄРЄУЄПЄЌЁЄИхЄЫЄЯ importation ЄЌАЕХнХЊЄШЄЪЄУЄПЁЅИРИьЄЫЄшЄУЄЦЁЄЛўТхЄЫЄшЄУЄЦЁЄimportation ЄШ substitution ЄЮШцЮЈЄЌЪбЦАЄЙЄыЄЌЁЄЄГЄГЄЫЄЯМвВёИРИьГиХЊЄЪЭзАјЄШЄЯЪЬЄЫВПЄщЄЋЄЮИРИьГиХЊЄЪЭзАјЄтЦЏЄЄЄЦЄЄЄыВФЧНРЄЌЄЂЄыЄЮЄРЄэЄІЄЋЁЅ
ЁЁFischer (105) ЄЯЁЄЄГЄЮЄшЄІЄЪПЗЄЗЄЄРпЬфЄђТППєЛзЄЄЄФЄЏЄГЄШЄЌЄЧЄЄыЄШЄЗЁЄБбИьЛЫЄЫЄЊЄБЄыРпЬфЮуЄШЄЗЄЦ3ЄФЄђЕѓЄВЄЦЄЄЄыЁЅ
ЁЁЁІ How many of all Scandinavian borrowings have replaced native terms, how many have led to semantic differentiation?
ЁЁЁІ How does French compare with Scandinavian in this respect?
ЁЁЁІ How many borrowings from language x are importations, how many are substitutions, and what semantic domains do they belong to?
ЁЁHTOED (Historical Thesaurus of the Oxford English Dictionary) ЄЌНаШЧЄЕЄьЄПИНКпЁЄАеЬЃЄЮМкЭбЄЧЄЂЄы substitution ЄЫДиЄЙЄыИІЕцЄтУЧСГЄЗЄфЄЙЄЏЄЪЄУЄЦЄЄПЁЅБбИьМкЭбИьИІЕцЄЮЬЄЭшЄЯЄГЄьЄЋЄщЄтЬРЄыЄНЄІЄРЁЅ
ЁЁЁІ Fischer, Andreas. "Lexical Borrowing and the History of English: A Typology of Typologies." Language Contact in the History of English. 2nd rev. ed. Ed. Dieter Kastovsky and Arthur Mettingers. Frankfurt am Main: Peter Lang, 2003. 97--115.
ЁЁЁІ Thomason, Sarah Grey and Terrence Kaufman. Language Contact, Creolization, and Genetic Linguistics. Berkeley: U of California P, 1988.
2014-02-25 Tue
ЂЃ #1765. ЦќЫмЄЧНММТЄЗЄЦЄЄЄыБбИьИьИЛГиЄШ Klein ЄЮБбИьИьИЛМХЕ [etymology][dictionary][lexicology][hebrew]
ЁЁЦќЫмЄЫЄтЄПЄгЄПЄгЫЌЄьЄЦЄЄЄыБбИьЛЫГІЄЮНХФУЁЄЅнЁМЅщЅѓЅЩЄЮ Fisiak (8) ЄЫЁЄЦќЫмЄЮБбИьИьИЛГиЄЌНММТЄЗЄЦЄЄЄыЛнЁЄИРЕкЄЌЄЂЄыЁЅ
One important area of research in Japan is English etymology. At least two important recent dictionaries should be mentioned: Osamu Fukushima An etymological dictionary of English derivatives, 1992 (in English), and Yoshio Terasawa.(sic) The Kenkyusha dictionary of English etymology, 1997 (in Japanese), I received both of them in 1997. Fushima's (sic) dictionary is unique in its handling solely derivatives. Terasawa's opus magnum is in Japanese but with some explanations it can be used by people who do not read Japanese. . . . The dictionary is a magnificent piece of work. It is the largest etymological dictionary of English. Its scope is unusually wide. In the notes sent to me Professor Terasawa wrote that the dictionary "includes approximately 50.000 words, the majority of which are common words found in general use, new coinages, slang, and such technical terms as seen in science and technology, such components of a word as prefixes, suffixes, linking forms, as well as major place names and common personal names" (private correspondence). It is comprehensive and up-to-date, well-researched and contains a fairly large number of entries thoroughly revised in comparison with earlier etymological dictionaries. Onions' Oxford dictionary of English etymology, 1966 contains 38.000 words with the derivatives and as could be expected many of the etymologies require revisions. From a linguistic point of view Terasawa's dictionary compares favorably with Klein's comprehensive etymological dictionary of the English language, 1966--67.
ЁЁЛћпЗЁЄЪЁХчЄЫЄшЄыИьИЛМХЕЄђАІЭбЄЙЄыМдЄШЄЗЄЦЁЄЄЊЄЊЄЄЄЫДПЗоЄЙЄйЄЩОЄЧЄЂЄыЁЅFisiak ЄЯЁЄЁиБбИьИьИЛМХЕЁйЄђ Klein ЄЮМХЕЄЫШцГгЄЙЄйЄЯЋКюЄЧЄЂЄыЄШЄЗЄЦЄЄЄыЄЌЁЄЄГЄГЄЧАњЄЙчЄЄЄЫНаЄЕЄьЄЦЄЄЄы Klein ЄЮБбИьИьИЛМХЕЄШЄЯЄЩЄЮЄшЄІЄЪЄтЄЮЄЋЁЄГЮЧЇЄЗЄЦЄЊЄГЄІЁЅKlein ЄЫЄФЄЄЄЦЄЯЁЄЛћпЗМЋПШЄЌЁиМНёЁІРЄГІБбИьЁІЪ§ИРЁй (80) ЄЧМЁЄЮЄшЄІЄЫЩОЄЗЄЦЄЄЄыЁЅ
ЫмМХЕЄЯЁЄ'history of words' ЄШЦБЛўЄЫ 'history in words' ЄђЬРЄщЄЋЄЫЄЙЄыЄГЄШЄђЬмЩИЄШЄЗЄЦЄЄЄыЁЅЄНЄЮЩћТъЄт "Dealing with the origin of words and their sense development thus illustrating the history of civilization and culture" ЄШЄЂЄъЁЄДЌЦЌЄЮЅтЅУЅШЁМЄЫЄт "To know the origin of words is to know the cultural history of mankind" ЄШЭШИРЄЕЄьЄЦЄЄЄыЁЅИРЄЄДЙЄЈЄьЄаЁЄУБИьЄђЁЄИРИьЄЮАьЭзСЧЄЧЄЂЄыЄШЦБЛўЄЫЄНЄьЄђЭбЄЄЄыПЭДжЄЮАьЭзСЧЁЄМЋСГЁІПЭЪИЁІВЪГиЄЮНєЪЌЬюЄЮШЏУЃЄђМЬЄЗНаЄЙЖРЄЮЬђЬмЄђЄтЄФЄтЄЮЄШТЊЄЈЄыЁЅЄГЄьЄЌЫмМНёЄЮТшАьЄЮЦУПЇЄЧЄЂЄыЁЅТшЦѓЄЯЁЄАѕВЄИьКЌЄЫСЬЄыОьЙчЁЄНОЭшЄЮБбИьМХЕЄЧЄЂЄоЄъМшЄъОхЄВЄщЄьЄЪЄЋЄУЄПЅШЅЋЅщИь (Tocharian) ЄЮЦБТВИьЄђЕКмЄЙЄыЁЄТшЛАЄЯ750ЄЫЕкЄжЅЛЅрИь (Semitic) ЕЏИЛЄЮИьЄЫЄФЄЄЄЦЁЄАѕВЄИьЄЫНрЄКЄыЕНвЄђЙдЄЪЄІЁЅТшЛЭЄЯПЭЬОЄЮЄлЄЋЁЄПРЯУЁІХСРтОхЄЮИЧЭЬОЛьЁЪЮуЁЇDanaüsЁЅЄПЄРЄЗЁЄЄНЄЮИьИЛВђЄЫЄЯЬфТъЄЂЄъЁЫЄђЫЩйЄЫКЮЯПЁЅТшИоЄЯВЪГиЁІЕЛНбЄЮРьЬчИьЄђНХЛыЄЙЄыЁЄЄЪЄЩЄЧЄЂЄы
ЁЁKlein ЄЯ1Цќ11ЛўДжЁЄ18ЧЏЄЮЧЏЗюЄђЄЋЄБЄЦЄГЄЮМХЕЄђЪдЄѓЄРЄШЄЄЄІЄЋЄщЁЄЄоЄЕЄЫЯЋКюУцЄЮЯЋКюЄЧЄЂЄыЁЅKlein ЄЫЄФЄЄЄЦЄЯЁЄЙг (100) ЄтМЁЄЮЄшЄІЄЫЩОЄЗЄЦЄЄЄыЁЅЁжE. ЅЏЅщЅЄЅѓЄЯЁЄНщЄсЅСЅЇЅУЅГЅЙЅэЅєЅЁЅЅЂЄЧЅщЅгЁЪЅцЅРЅфЖЕЄЮЖЕЛеЁЫЄђЄЗЄЦЄЄЄПЄЌЁЄЅЪЅСЄЮЖЏРЉМ§ЭЦНъЄЫЪсЄЈЄщЄьЁЄЄНЄЮДжЁЄЩуЁЄКЪЁЄАьПЭТЉЛвЁЄЛАПЭЛаЫхЄЮЦѓПЭЄђМКЄУЄПЁЅРяИхЁЄЅЋЅЪЅРЄЫАмЄъЁЄЅЄЅЎЅъЅЙИьЄЮИьИЖМХЕЄЮЪдНИЄђЛзЄЄЮЉЄСЁЄЪИЬРЄШЪИВНЄЫНХХРЄђЄЊЄЁЄЄГЄьЄоЄЧЬЕЛыЄЕЄьЄЦЄЄЄПЅЛЅпЅЦЅЃЅУЅЏЗЯЄЮНєИРИьЄШЄЮДиЗИЄђЕцЬРЄЗЄПХРЄЧЄЯЁЄВшДќХЊЄЪЄтЄЮЁзЄЧЄЂЄыЁЅ
ЁЁЄГЄЮЯЋКюЄШШцИЊЄЙЄыЄтЄЮЄШЄЗЄЦЦќЫмЄЮБбИьИьИЛМХЕЄЌОвВ№ЄЕЄьЄЦЄЄЄыЄШЄЄЄІЄГЄШЄЯЁЄСЧФОЄЫОоЛПЄШМѕЄБМшЄУЄЦЄшЄЄЄРЄэЄІЁЅЄПЄРЄЗЁЄKlein ЄЮМХЕЄЮЭјЭбЄЫЄЯУэАеЄЌЩЌЭзЄЧЄЂЄыЁЅБбИьЛЫЦтЄЧЄЮИьЛЫЕНвЄЌЩдННЪЌЄЧЄЂЄыЄГЄШЁЄЪдМдЄЮЗаЮђЄЋЄщЅЛЅрИьЁЪЦУЄЫЅиЅжЅщЅЄИьЁЫЄЮЕНвЄЯДќТдЄЕЄьЄНЄІЄРЄЌЩЌЄКЄЗЄтРЕГЮЄЧЄЯЄЪЄЄЄГЄШЄЪЄЩЄЯЁЄЕЄЄЫЄШЄсЄЦЄЊЄЏЩЌЭзЄЌЄЂЄыЁЅ
ЁЁДиЯЂЄЗЄЦЁЄЁж#600. БбИьИьИЛМНёЄЮНёЛяЁз ([2010-12-18-1]) ЄтЛВОШЁЅ
ЁЁЁІ Fisiak, Jacek. "Discovering English Historical Linguistics in Japan." Phrases of the History of English: Selection Papers Read at SHELL 2012. Ed. Michio Hosaka, Michiko Ogura, Hironori Suzuki, and Akinobu Tani. Frankfurt am Main: Peter Lang, 2013.
ЁЁЁІ ЛћпЗ ЫЇЭК (ЪдНИМчДД)ЁЁЁиБбИьИьИЛМХЕЁйЁЁИІЕцМвЁЄ1997ЧЏЁЅ
ЁЁЁІ ЪЁХч МЃ ЪдЁЁЁиБбИьЧЩРИИьИьИЛМХЕЁйЁЁЦќЫмПоНёЅщЅЄЅжЁЄ1992ЧЏЁЅ
ЁЁЁІ Klein, Ernest. A Comprehensive Etymological Dictionary of the English Language, Dealing with the Origin of Words and Their Sense Development, Thus Illustrating the History of Civilization and Culture. 2 vols. Amsterdam/London/New York: Elsevier, 1966--67. Unabridged, one-volume ed. 1971.
ЁЁЁІ ЛћпЗ ЫЇЭКЁЪЪдЁЫЁЁЁиМНёЁІРЄГІБбИьЁІЪ§ИРЁйЁЁИІЕцМвБбИьГиЪИИЅВђТъЁЁТш8ДЌЁЅИІЕцМвЁЅ2006ЧЏЁЅ
ЁЁЁІ Йг РЕПЭЁЁЁиЅєЅЁЅЄЅЅѓЅАЁЁРЄГІЛЫЄђЪбЄЈЄПГЄЄЮРяЛЮЁйЁЁУцБћИјЯРПЗМвЁвУцИјПЗНёЁгЁЄ1968ЧЏ.
2014-02-04 Tue
ЂЃ #1744. 2013ЧЏЄЮБбИьЮЎЙдИьТчОо [lexicology][ads][woy][register][rhetoric][punctuation]
ЁЁАьЗюСАЄЮЄГЄШЄЫЄЪЄыЄЌЁЄ1Зю3ЦќЁЄAmerican Dialect Society ЄЫЄшЄы 2013ЧЏЄЮ The Word of the Year ЄЌШЏЩНЄЕЄьЄПЁЅЅзЅьЅЙЁІЅъЅъЁМЅЙ (PDF) ЄЯЄГЄСЄщЁЅ
ЁЁ2013ЧЏЄЮТчОоЄЯ because ЄЧЄЂЄыЁЅИХЄЄИьЄРЄЌЁЄПЗЄЗЄЄИьЫЁЄЌШЏУЃЄЗЄЦЄЄПЄцЄЈЄЮМѕОоЄШЄЄЄІЁЅ
This past year, the very old word because exploded with new grammatical possibilities in informal online use. . . . No longer does because have to be followed by of or a full clause. Now one often sees tersely worded rationales like 'because science' or 'because reasons.' You might not go to a party 'because tired.' As one supporter put it, because should be Word of the Year 'because useful!'
ЁЁЄГЄЮПЗЭбЫЁЄЯЁЄИНКпЄЯ "in informal online use" ЄШЄЄЄІ register ЄЫИТФъЄЕЄьЄЦЄЄЄыЄЌЁЄОхЕЄЮФЬЄъЪиЭјЄЧЄЂЄыЄЫЄЯЄСЄЌЄЄЄЪЄЄЄЮЄЧЁЄКЃИх register ЄђГШЄВЄЦЄцЄЏВФЧНРЄЌЄЂЄыЁЅMOST USEFUL ЩєЬчЄЧЄтМѕОоЄЗЄЦЄЄЄыЁЅ
ЁЁПЗЭбЫЁЄЯ because ЄЌРсЄЧЄЯЄЪЄЏИьЄфЖчЄђНОЄЈЄыЄГЄШЄЌЄЧЄЄыЄшЄІЄЫЄЪЄУЄПЄШЄЄЄІЄтЄЮЄРЄЌЁЄЄГЄьЄЫЄЯ2МяЮрЄЌЖшЪЬЄЕЄьЄыЄшЄІЄЫЛзЄяЄьЄыЁЅ1ЄФЄЯЁЄ"because tired" Єф "because useful" ЄЮЄшЄІЄЫЁЄХ§ИьХЊЭзСЧЄЌОЪЮЌЄЕЄьЄЦЄЄЄыЄШЙЭЄЈЄщЄьЄыЄтЄЮЁЅЄГЄГЄЧЄЯЁЄЄНЄьЄОЄь "because (I am) tired" Єф "because (it is) useful" ЄЮЄшЄІЄЫМчИьЁм be ЦАЛьЄЌОЪЮЌЄЕЄьЄЦЄЄЄыЄШВђМсЄЧЄЄыЁЅШЏЯУЄЕЄьЄЦЄЄЄыОѕЖЗЄЪЄЩЄЮИьЭбЯРХЊЄЪО№ЪѓЄђЛВОШЄЛЄКЄШЄтЁЄХ§ИьХЊЄЫЁжЩќИЕЁзЄЧЄЄыЅПЅЄЅзЄРЁЅХ§ИьХЊЄЫЯРЄИЄщЄьЄыЄйЄЭбЫЁЄШЄЄЄЈЄыЄРЄэЄІЁЅ
ЁЁЄтЄІ1ЄФЄЯЁЄ"because science" Єф "because reasons" ЄЮЅПЅЄЅзЄРЁЅЄГЄьЄЯ "because of science" Єф "because of reasons" ЄШЄтАлЄЪЄыЄЗЁЄАьАеЄЫХ§ИьХЊЄЫРсЄиЁжЩќИЕЁзЄЧЄЄыЄяЄБЄЧЄтЄЪЄЄЁЅЄрЄЗЄэЁЄ1ИьЄЫЄшЄъРсЄЫСъХіЄЙЄыАеЬЃЄђСлСќЄЕЄЛЁЄДоУпЄфЭОБЄЄђЭПЄЈЄыНЄМХЊЄЪИњВЬЄђНаЄЗЄЦЄЄЄыЁЅЄГЄСЄщЄЯЁЄХ§ИьХЊЄШЄЄЄІЄшЄъЄЯНЄМХЊЄЫЯРЄИЄщЄьЄыЄйЄЭбЫЁЄШЄЄЄЈЄыЁЅ
ЁЁЄЕЄЦЁЄМѕОоЄЗЄП because ЄЮЄлЄЋЄЫЄтЁЄЅЮЅпЅЭЁМЅШИьЖчЄфТОЩєЬчЄЧЄЮМѕОоИьЖчЄЌЄЂЄъЁЄФЏЄсЄЦЄпЄыЄШЄЊЄтЄЗЄэЄЄЁЅЮуЄЈЄа slash ЄЯЁЄ"used as a coordinating conjunction to mean 'and/or' (e.g., 'come and visit slash stay') or 'so' ('I love that place, slash can we go there?')" ЄШРтЬРЄЕЄьЄЦЄЊЄъЁЄГЮЄЋЄЫЪиЭјЄЪИьЄЧЄЂЄыЁЅНёЄИРЭеЄЫТАЄЙЄыЖчЦЩЕЙц (punctuation) ЄЮ1ЄФЄђЩНЄЙИьЄЌЁЄЯУЄЗИРЭеЄЧРмТГЛьЄШЄЗЄЦЭбЄЄЄщЄьЄЦЄЄЄыЄШЄЄЄІЄЮЄЌЄЊЄтЄЗЄэЄЄЁЅЁжАЪОхНЊЄяЄъЁзЄђАеЬЃЄЙЄыДжХъЛьЄШЄЗЄЦЄЮ Period. ЄЫЮрЄЙЄыЦУАлЄЪЮуЄЧЄЂЄыЁЅ
2014-01-20 Mon
ЂЃ #1729. glottochronology КЦЫЌ [glottochronology][lexicology][family_tree][pidgin][punctuated_equilibrium][speed_of_change]
ЁЁЁж#1128. glottochronologyЁз ([2012-05-29-1]) ЄЧЁЄЅЂЅсЅъЅЋЄЮИРИьГиМдЁІПЭЮрГиМд Swadesh (1909--67) ЄЮФѓОЇЄЗЄПИРИьЧЏТхГиЄђЄпЄПЁЅЄНЄЮЭ§ЯРХЊЛйУьЄШЄЪЄыЄЮЄЯЁЄ"the fundamental everyday vocabulary of any language---as against the specialized or 'cultural' vocabulary---changes at a relatively constant rate" (452) ЄШЄЄЄІЄтЄЮЄРЁЅSwadesh ЄЯЪЃПєЄЮИРИьЄЮФДККЄЫД№ЄХЄЁЄЄНЄЮАьФъТЎХйЄЯЬѓ86%ЄЧЄЂЄыЄШЄпЄЦЄЄЄыЁЅЄГЄЮЙЭЄЈЪ§ЄЫЄЯЭЭЁЙЄЪШуШНЄЌФѓНаЄЕЄьЄЦЄЄЄыЄЌЁЄВОЄЫМѕЄБЦўЄьЄыЄШЄЗЄЦЄтЁЄЄЪЄМАьФъТЎХйЄШЄЄЄІЄтЄЮЄЂЄъЄІЄыЄЮЄЋЄШЄЄЄІТчЄЄЪЬфТъЄЌЛФЄыЁЅД№ЫмИьзУЄЌАьФъЄЮТЎХйЄЧУжДЙЄЕЄьЄЦЄцЄЏЄГЄШЄЫДиЄЙЄыИЖЭ§ХЊРтЬРЄЮЬфТъЄРЁЅЄГЄьЄЫЄФЄЄЄЦЁЄSwadesh МЋПШЄЯЁЄМЁЄЮЄшЄІЄЫНвЄйЄЦЄЄЄыЁЅ
Why does the fundamental vocabulary change at a constant rate? . . . . / A language is a highly complex system of symbols serving a vital communicative function in society. The symbols are subject to change by the influence of many circumstances, yet they cannot change too fast without destroying the intelligibility of language. If the factors leading to change are great enough, they will keep the rate of change up to the maximum permitted by the communicative function of language. We have, as it were, a powerful motor kept in check by a speed regulating mechanism. . . . / While it is subject to manifold impulses toward change, language still must maintain a considerable amount of uniformity. If it is to be mutually intelligible among the members of the community, there must be a large element of agreement in its details among the individuals who make up the community. As between the oldest and the youngest generations, there are often difference of vocabulary and usage but these are never so great as to make it impossible for the two groups to understand each other. This is the circumstance which sets a maximum limit on the speed of change in language. / Acquisition of additional vocabulary may proceed at a faster rate than the replacement of old words. Replacement in culture vocabulary usually goes with the introduction of new cultural traits replacing the old ones, a process which at times may be completed in a few generations. Replacement of fundamental vocabulary must be slower because the concepts (e.g., body parts) do not change fundamentally. Change can come about by the introduction of partial synonyms which only rarely, and even then for the most part gradually, expand their area and frequency of usage to the point of replacing the earlier word. (459--60)
ЁЁЄГЄьЄЯД№СУИьзУЄЮУжДЙТЎХйЄЮЄШЄыУЭЄЫИТГІЄЌЄЂЄыЄГЄШЄЫДиЄЗЄЦЄЮИЖЭ§ХЊРтЬРЄЫЄЯЄЪЄУЄЦЄЄЄыЄЌЁЄЄЪЄМ86%САИхЄШЄЄЄІЄлЄмАьФъЄЮУЭЄђЄШЄыЄЮЄЋЄШЄЄЄІЬфЄЄЄЫЄЯХњЄЈЄЦЄЄЄЪЄЄЄшЄІЄЫЛзЄяЄьЄыЁЅСсЄЄОьЙчЄтУйЄЄОьЙчЄтЄЂЄыЄЌЁЄЄЪЄщЄЛЄаЄНЄЮЄЏЄщЄЄЄЫЄЪЄыЄШЄЄЄІЗаИГХЊЄЪЕНвЄЫЄШЄЩЄоЄыЄШЄЄЄІЄГЄШЄРЄэЄІЄЋЁЅ
ЁЁЄоЄПЁЄglottochronology ЄЌСАФѓЄШЄЗЄЦЄЄЄыЄЮЄЯЁЄАѕВЄИьТВЄЮЗЯХ§МљЄЫМЈЄЕЄьЄыЄшЄІЄЪЁЄНєИРИьЄЮЛўДжХЊЄЪЯЂТГРЄЧЄЂЄыЁЅЄЗЄЋЄЗЁЄЖЏХйЄЮИРИьРмПЈЄЮВсФјЄШЄЗЄЦЄЮЅдЅИЅѓВН (pidginisation) ЄЮЛіЮуЄЪЄЩЄђЙЭЮИЄЙЄыЄШЁЄОхЕЄЮЗзЛЛЄЯЄоЄыЄЧФЬЭбЄЗЄЪЄЄЄРЄэЄІЁЅЗЯХ§МљЅтЅЧЅыЄЧЄІЄоЄЏАЗЄЈЄыЄшЄІЄЪИРИьЄЫЄФЄЄЄЦЄЯД№СУИьзУЄЮУжДЙЄЮАьФъТЎХйЄђЯРЄИЄыЄГЄШЄЌЄЧЄЄыЄЋЄтЄЗЄьЄЪЄЄЄЌЁЄРЄТхДжЄЮУЧРфЄђМЈЄЙИРИьОѕЖЗЄЫЦБЄИЕФЯРЄђХЌЭбЄЙЄыЄГЄШЄЯЄЧЄЄЪЄЄЄЮЄЧЄЯЄЪЄЄЄЋЁЅЄНЄЗЄЦЁЄИхМдЄЮИРИьОѕЖЗЄЯЁЄЅдЅИЅѓИьЄЮИІЕцЄфЁж#1397. УЧТГЪПЙеЅтЅЧЅыЁз ([2013-02-22-1]) ЄЌМЈКЖЄЙЄыЄшЄІЄЫЁЄПЭЮрИРИьЄЮЮђЛЫЄЫЄЊЄЄЄЦЄЯЁЄЄГЄьЄоЄЧСлФъЄЕЄьЄЦЄЄЄПЄшЄъЄтЄКЄУЄШЩсФЬЄЮЄГЄШЄЧЄЂЄУЄПВФЧНРЄЌЙтЄЄЁЅ
ЁЁЄПЄРЄЗЁЄglottochronology ЄЯЁЄЗЯХ§МљЅтЅЧЅыЄЧЄІЄоЄЏАЗЄЈЄыЄшЄІЄЪИРИьЄЫДиЄЙЄыИТЄъЄЫЄЊЄЄЄЦЄЯЁЄОЏЄЪЄЏЄШЄтЕНвХ§ЗзХЊЄЫЖНЬЃПМЄЄГиРтЄЧЄЂЄъЄІЄыЄШЛзЄІЁЅЄГЄЮЄшЄІЄЪИТФъЄФЄЄЧЩОВСЄЙЄыВСУЭЄЯЄЂЄыЄЮЄЧЄЯЄЪЄЄЄЋЁЅ
ЁЁЁІ Swadesh, Morris. "Lexico-Statistic Dating of Prehistoric Ethnic Contacts: With Special Reference to North American Indians and Eskimos." Proceedings of the American Philosophical Society 96 (1952): 452--63.
2014-01-15 Wed
ЂЃ #1724. Skeat ЄЫЄшЄы2НХИьАьЭї [doublet][etymology][lexicology]
ЁЁКђЦќЄЮЕЛіЁж#1723. ЅЗЅУЅзЅъЁМЄЫЄшЄы2НХИьАьЭїЁз ([2014-01-14-1]) ЄЫАњЄТГЄЁЄКЃХйЄЯ Skeat ЄЮИьИЛМХЕ (748--51) ЄЫЗЧКмЄЕЄьЄЦЄЄЄы2НХИь (doublet) ЄђАьЭїЄЗЄшЄІЁЅЄНЄЮСАЄЫЁЄSkeat (748) ЄЮ2НХИьЄЮФъЕСЄђЗЧЄВЄшЄІЁЅ
Doublets are words which, though apparently differing in form, are nevertheless, from an etymological point of view, one and the same, or only differ in some unimportant suffix. Thus aggrieve is from L. aggrauāre; whilst aggravate, though really from the pp. aggrauātus, is nevertheless used as a verb, precisely as aggrieve is used, though the senses of the words have been differentiated.
ЁЁЄЧЄЯЁЄАЪВМЄЫ645СШЄЮ2НХИьАьЭїЄђЗЧЄВЄыЁЅЁЪЄЪЄЊЁЄЫмЅжЅэЅАБІЭѓЄЫЁжКЃЦќЄЮ doubletЁзЅГЁМЅЪЁМЄђРпЄБЄЦЄпЄоЄЗЄПЁЅЁЫ
| abbreviate | abridge |
| abet | bet |
| acajou | cashew |
| adamant | diamond |
| adventure | venture |
| advocate | avouch, avow |
| aggrieve | aggravate |
| ait | eyot |
| alarm | alarum |
| allocate | allow |
| ameer | emir, omrah |
| amiable | amicable |
| an | one |
| ancient | ensign |
| announce | annunciate |
| ant | emmet |
| anthem | antiphon |
| antic | antique |
| appal | pall |
| appeal (sb) | peal |
| appear | peer |
| appraise | appreciate |
| apprentice | prentice |
| aptitude | attitude |
| arc | arch |
| army | armada |
| arrack | rack, raki |
| asphodel | daffodil |
| assay | essay |
| assemble | assimilate |
| assess | assize (vb) |
| assoil | absolve |
| attach | attack |
| attire | tire, tire |
| bale | ball |
| balm | balsam |
| band | bond |
| banjo | mandoline |
| barb | bard |
| base | basis |
| bashaw | pasha |
| baton | batten |
| bawd | bold |
| beadle | bedell |
| beaker | pitcher |
| beef | cow |
| beldam | belladonna |
| bench | bank, bank |
| benison | benediction |
| blame | blaspheme |
| boil | bile |
| boss | botch |
| bough | bow |
| bound | bourn |
| bower | byre |
| bowl | bull |
| box | pyx, bush |
| brave | bravo |
| breve | brief |
| brother | friar |
| brown | bruin |
| buff | buffalo |
| cadence | chance |
| caitiff | captive |
| caldron, cauldron | chaldron |
| caliber | caliver |
| calumny | challenge |
| camera | chamber |
| cancer | canker |
| cannon | canon |
| caravan | van |
| card | chart, carte |
| case | chase, cash |
| cask | casque |
| castigate | chasten |
| catch | chase |
| cattle | chattels, capital |
| cavalier | chevalier |
| cavalry | chivalry |
| cess | assess |
| chaise | chair |
| chalk | calx |
| champaign | campaign |
| channel | canal, kennel |
| chant | cant |
| chapiter | capital |
| charge | cark, cargo |
| chateau | castle |
| cheat | escheat |
| check (sb) | shah |
| chicory | succory |
| chief | cape |
| chieftain | captain |
| chirurgeon | surgeon |
| choir | chorus, quire |
| choler | cholera |
| chord | cord |
| chuck | shock, shog |
| church | kirk |
| cipher | zero |
| cist | chest |
| cithern | guitar, gittern, kit |
| cive | chive |
| clause | close (sb) |
| climate | clime |
| coffer | coffin |
| coin | coign, quoin |
| cole | kail |
| collect | cull, coil (vb) |
| collocate | couch |
| comfit | confect |
| commend | command |
| commodore | commander |
| complacent | complaisant |
| complete (vb) | comply |
| compost | composite |
| comprehend | comprise |
| compute | count |
| conduct (sb) | conduit |
| confound | confuse |
| construe | construct |
| convey | convoy |
| cool | gelid |
| corn | grain |
| corn | horn |
| coronation | carnation |
| corral | kraal |
| corsair | hussar |
| costume | custom |
| cot | cote |
| couple (vb) | copulate |
| coy | quiet, quit, quite |
| coy | cage |
| crape | crisp |
| cream | chrism |
| crease | crest |
| crevice | crevasse |
| crib | cratch |
| crimson | carmine |
| crop | coup |
| crowd | rote |
| crypt | grot |
| cud | quid |
| cue | queue |
| curari | wourali |
| curricle | curriculum |
| curtle-axe | cutlass |
| cycle | wheel |
| dace | dart, dare |
| dainty | dignity |
| dame | dam, donna, duenna |
| dan | don, domino |
| dauphin | dolphin |
| deck | thatch |
| defence | fence |
| defend | fend |
| delay | dilate |
| dell | dale |
| demesne | domain |
| dent | dint |
| deploy | display, splay |
| depot | deposit (sb) |
| descry | describe |
| desiderate | desire (vb) |
| despite | spite |
| deuce | two |
| devilish | diabolic |
| die | dado |
| direct (vb) | dress |
| dish | disc, desk, daïs |
| disport | sport |
| distain | stain |
| ditch | dike |
| ditto | dictum |
| diurnal | journal |
| doge | duke |
| doit | thwaite |
| dole | deal (sb) |
| dominion | dungeon |
| doom | -dom (suffix) |
| dragon | dragoon |
| dropsy | hydropsy |
| due | debt |
| dune | down |
| eatable | edible |
| éclat | slate |
| elf | oaf, ouphe |
| élite | elect |
| emerald | smaragdus |
| emerods | hemorrhoids |
| employ | imply, implicate |
| endow | endue, indue |
| engine | gin |
| entire | integer |
| envious | invidious |
| escape | scape |
| eschew | shy (vb) |
| escutcheon | scutcheon |
| especial | special |
| espy | spy |
| esquire | squire |
| establish | stablish |
| estate | state, status |
| estimate | esteem |
| estop | stop |
| estreat | extract |
| etiquette | ticket |
| example | ensample, sample |
| exemplar | sampler |
| extraneous | strange |
| fabric | forge (sb) |
| fact | feat |
| faculty | facility |
| fan | van |
| fancy | fantasy, phantasy |
| fashion | faction |
| fat | vat |
| fauteuil | faldstool |
| fealty | fidelity |
| feeble | foible |
| fell | pell |
| fester (sb) | fistula |
| feud | fief, fee |
| feverfew | febrifuge |
| fiddle | viol |
| fife | pipe, peep |
| finch | spink |
| finite | fine |
| fitch | vetch |
| flag | flake, flaw |
| flower | flour |
| flush | flux |
| foam | spume |
| font | fount |
| force | farce |
| foremost | prime |
| foster | forester |
| fragile | frail |
| fray | affray |
| fro | from |
| frounce | flounce |
| fungus | sponge |
| furl | fardel |
| gabble | jabber |
| gad | ged |
| gaffer | grandfather |
| gage | wage |
| gambado | gambol |
| game | gammon |
| gaol | jail |
| garth | yard |
| gear | garb |
| genteel | gentle, gentile |
| genus | kin |
| germ | germen |
| gig | jig |
| gin | juniper |
| gird | gride |
| girdle | girth |
| glamour | gramarye |
| grain | corn |
| granary | garner |
| grece, grise | grade |
| guarantee (sb) | warranty |
| guard | ward |
| guardian | warden |
| guest | host |
| guile | wile |
| guise | wise |
| gullet | gully |
| gust | gusto |
| guy | guide (sb) |
| gypsy | Egyptian |
| hackbut | arquebus |
| hale | whole |
| hamper | hanaper |
| harangue | ring, rank, rink |
| hash (vb) | hatch |
| hatchment | achievement |
| hautboy | oboe |
| heap | hope |
| heckle | hackle, hatchel |
| hemi- | semi- |
| hent | hint |
| history | story |
| hock | hough |
| hoop | whoop |
| hospital | hostel, hotel, spital, spittle |
| hub | hob |
| human | humane |
| hyacinth | jacinth |
| hydra | otter |
| hyper- | super- |
| hypo- | sub- |
| illumine | limn |
| inapt | inept |
| inch | ounce |
| indite | indict |
| influence | influenza |
| innocuous | innoxious |
| invite | vie |
| invoke | invocate |
| iota | jot |
| isolate | insulate |
| jaggery | sugar |
| jealous | zealous |
| jinn | genie |
| joint | junta, junto |
| jointure | juncture |
| jut | jet |
| jutty | jetty |
| ketch | catch |
| label | lapel, lappet |
| lac | lake |
| lace | lasso |
| lair | leaguer |
| lake | loch, lough |
| lateen | Latin |
| launch, lanch | lance (vb) |
| leal | loyal, legal |
| lection | lesson |
| lib | glib |
| lieu | locus |
| limb | limbo |
| limbeck | alembic |
| lineal | linear |
| liquor | liqueur |
| list | lust |
| load | lode |
| lobby | lodge |
| locust | lobster |
| lone | alone |
| losel | lorel |
| lurch | lurk |
| madam | madonna |
| major | mayor |
| male | masculine |
| malediction | malison |
| mandate | maundy |
| mangle | mangonel |
| manœuvre | manure |
| march | mark, marque |
| margin | margent, marge |
| marish | morass |
| maul | mall |
| mauve | mallow |
| maxim | maximum |
| mazer | mazzard |
| mean | mesne, mizen |
| memory | memoir |
| mentor | monitor |
| metal | mettle |
| milt | milk |
| minim | minimum |
| minster | monastery |
| mint | money |
| mister | master |
| mob | mobile, movable |
| mode | mood |
| mohair | moire |
| moment | momentum, movement |
| monster | muster |
| morrow | morn |
| moslem | mussulman |
| mould | module |
| munnion | mullion |
| musket | mosquito |
| naive | native |
| naked | nude |
| name | noun |
| natron | nitre |
| naught, nought | not |
| nausea | noise |
| neat | net |
| nias | eyas |
| noyau | newel |
| obedience | obeisance |
| octave | utas |
| of | off |
| onion | union |
| oration | orison |
| ordinance | ordnance |
| orpiment | orpine |
| osprey | ossifrage |
| otto | attar |
| ouch | nouch |
| outer | utter |
| overplus | surplus |
| paddle | spatula |
| paddock | park |
| pain (vb) | pine |
| paladin | palatine |
| pale | pallid, fallow |
| palette | pallet |
| paper | papyrus |
| parade | parry |
| paradise | parvis |
| paralysis | palsy |
| parole | parable, parle, palaver |
| parson | person |
| pass | pace |
| pastel | pastille |
| pasty | patty |
| pate | plate |
| patron | pattern |
| pause | pose |
| pawn | pane, vane |
| paynim | paganism |
| peer | appear |
| peise | poise |
| pelisse | pilch |
| pellitory | paritory |
| penance | penitence |
| peregrine | pilgrim |
| peruke | periwig, wig |
| pewter | spelter |
| phantasm | phantom |
| piazza | place |
| pick | peck, pitch (vb) |
| picket | piquet |
| piety | pity |
| pigment | pimento |
| pike | peak, pick (sb), pique (sb), spike |
| pippin | pip |
| pistil | pestle |
| pistol | pistole |
| plaintiff | plaintive |
| plait | pleat, plight |
| plan | plain, plane, llano |
| plateau | platter |
| plum | prune |
| poignant | pungent |
| point | punt |
| poison | potion |
| poke | pouch |
| pole | pale, pawl |
| pomade, pommade | pomatum |
| pomp | pump |
| poor | pauper |
| pope | papa |
| porch | portico |
| posy | poesy |
| potent | puissant |
| poult | pullet |
| pounce | punch |
| pounce | pumice |
| pound | pond |
| pound | pun (vb) |
| power | posse |
| praise | price |
| preach | predicate |
| premier | primero |
| priest | presbyter |
| private | privy |
| probe (sb) | proof |
| proctor | procurator |
| prolong | purloin |
| prosecute | pursue |
| provide | purvey |
| provident | prudent |
| punch | punish |
| puny | puisne |
| purl | profile |
| purpose | propose |
| purview | proviso |
| quartern | quadroon |
| queen | quean |
| raceme | raisin |
| rack | wrack, wreck |
| radix | radish, race, root, wort |
| raid | road |
| rail | rally |
| raise | rear |
| ramp | romp |
| ransom | redemption |
| rapine | ravine, raven |
| rase | raze |
| ratio | ration, reason |
| ray | radius |
| rayah | ryot |
| rear-ward | rear-guard |
| reave | rob |
| reconnaissance | recognisance |
| regal | royal, real |
| relic | relique |
| renegade | runagate |
| renew | renovate |
| reprieve | reprove |
| residue | residuum |
| respect | respite |
| revenge | revindicate |
| reward | regard |
| rhomb, rhombus | rumb |
| ridge | rig |
| rod | rood |
| rondeau | roundel |
| rote | route, rout, rut |
| round | rotund |
| rouse | row |
| rover | robber |
| sack | sac |
| sacristan | sexton |
| saw | saga |
| saxifrage | sassafras |
| scabby | shabby |
| scale | shale |
| scandal | slander |
| scar, scaur | share |
| scarf | scrip, scrap |
| scatter | shatter |
| school | shoal, scull |
| scot(free) | shot |
| screen | shriek |
| screed | shred |
| screw | shrew |
| scur | scour |
| scuttle | skillet |
| sect, sept, set | suite, suit |
| sennet | signet |
| separate | sever |
| sequin | sicca |
| sergeant, serjeant | servant |
| settle | sell, saddle |
| shammy | chamois |
| shark | search |
| shawm, shalm | haulm |
| sheave | shive |
| shed | shade |
| shirt | skirt |
| shrub | sherbet, syrup |
| shuffle | scuffle |
| sicker, siker | secure, sure |
| sine | sinus |
| sir, sire | senior, seignior, señor, signor |
| size, size | assise |
| skewer | shiver |
| skiff | ship |
| skirmish | scrimmage, scaramouch |
| slabber | slaver |
| sleight | sloid |
| sleuth | slot |
| slobber | slubber |
| sloop | shallop |
| snivel | snuffle |
| snub | snuff |
| soil | sole, sole |
| soprano | sovereign |
| sough | surf |
| soup | sup |
| souse | sauce |
| spade | spade |
| species | spice |
| spell | spill |
| spend | dispend |
| spirit | sprite, spright |
| spoor | spur |
| spray | sprig, asparagus |
| sprit | sprout (sb) |
| sprout (vb) | spout |
| spry | spark |
| squall | squeal |
| squinancy | quinsy |
| squire | square |
| stank | tank |
| stave | staff |
| steer | Taurus |
| still | distil |
| stock | tuck |
| stove | stew (sb) |
| strait | strict |
| strap | strop |
| stress | distress |
| superficies | surface |
| supersede | surcease |
| suppliant | supplicant |
| sweep | swoop |
| tabor | tambour |
| tache | tack |
| taint | attaint |
| tamper | temper |
| tarpauling | tar |
| task | tax |
| taunt | tempt, tent |
| tawny | tenny |
| tease | tose |
| tee | taw |
| teind | tithe, tenth |
| tend | tender |
| tense | toise |
| tercel | tassel |
| thread | thrid |
| thrill, thirl | drill |
| tine | tooth |
| tippet | tape |
| tit | teat |
| title | tittle |
| to | too |
| ton | tun |
| tone | tune |
| tour | turn |
| tow | tug |
| town | down |
| track | trick |
| tract | trait |
| tradition | treason |
| travail | travel |
| treble | triple |
| trifle | truffle |
| tripod | trivet |
| triumph | trump |
| troth | truth |
| tuck | tug |
| tuck | touch |
| tulip | turban |
| tweak | twitch |
| umbel | umbrella |
| unity | unit |
| ure | opera |
| vade | fade |
| vair | various |
| valet | varlet |
| vantage | advantage |
| vast | waste |
| vaward | vanguard |
| veal | wether |
| veldt | field |
| veneer | furnish |
| venew, veney | venue |
| verb | word |
| vermeil | vermillion |
| vertex | vortex |
| vervain | verbena |
| viaticum | voyage |
| viper | wyvern, wivern |
| visor | vizard |
| vizier, visier | alguazil |
| vocal | vowel |
| wain | wagon, waggon |
| wale | weal |
| wattle | wallet |
| weet | wit |
| whirl | warble |
| wight | whit |
| wold | weald |
| yelp | yap |
ЁЁЁІ Skeat, Walter William, ed. An Etymological Dictionary of the English Language. 4th ed. Oxford: Clarendon, 1910. 1st ed. 1879--82. 2nd ed. 1883.
2014-01-14 Tue
ЂЃ #1723. ЅЗЅУЅзЅъЁМЄЫЄшЄы2НХИьАьЭї [doublet][etymology][lexicology]
ЁЁЫмЅжЅэЅАЄЧЄЯ2НХИь (doublet) ЄЫДиЄЙЄыЕЛіЄђТПЄЏНёЄЄЄЦЄЄПЄЌЁЄАьЭїЄђКюЄУЄЦЄЊЄЏЄШЪиЭјЄЧЄЂЄыЁЅЅЗЅУЅзЅъЁМЄЮИьИЛМХЕЄЮДЌЫіЄЫЁЄ2НХИьЁЪЄШ3НХИьАЪОхЄЮТПНХИьЁЫЄЮЅъЅЙЅШЄЌКмЄУЄЦЄЄЄПЄЮЄЧЁЄАЪВМЄЫХОКмЄЙЄыЁЅЄНЄЮСАЄЫЁЄЅЗЅУЅзЅъЁМ (708) ЄЫЄшЄы2НХИьЄЮФъЕСЄШРтЬРЄђМЈЄЗЄЦЄЊЄГЄІЁЅ
ЦѓНХИьЄШЄЯЁЄЦБЄИИьИЛЄЮИРЭеЄЌАлЄЪЄУЄПЗаЯЉЄђЗаЄЦБбИьЄЫЄЪЄУЄПАьСШЄЮИРЭеЁЪЄЂЄыЄЄЄЯЄНЄЮСШЄЮАьИьЁЫЄђАеЬЃЄЙЄыЁЅВМЕЄЯЄНЄЮЮуЄЫПєЄЈЄщЄьЄыЄтЄЮЄЧЁЄЄНЄьЄщЄЮИьИЛЄфЗаЯЉЄђЄПЄЩЄэЄІЄШЛзЄЈЄаЁЄЄЙЄйЄЦ OED ЁЪЁиЅЊЅУЅЏЅЙЅеЅЉЁМЅЩБбИьТчМХЕЁйЁЫЄЧИЋЄыЄГЄШЄЌЄЧЄЁЄЄГЄьЄщЄЮЦѓНХИьЄЋЄщЁЄБбИьЄЮЫЄЋЄЕЄШЁЄИРЭеЄЫЄФЄЄЄЦЄЮЄЕЄоЄЖЄоЄЪЖНЬЃЄЂЄыЯУЄЗЄђЦЩЄпМшЄыЄГЄШЄЌЄЧЄЄыЁЅЦѓНХИьЄЫЄЯЁЄИьИЛЄЯЦБЄИЄЧЄЂЄъЄЪЄЌЄщЁЄЄНЄЮАеЬЃЄЯИпЄЄЄЫТчЄЄЄЫАлЄЪЄыЄтЄЮЄЌЄЂЄыЁЅ
ЁЁЄЧЄЯЁЄАЪВМЄЫ126СШЄЮ2НХИьАьЭїЄђЗЧЄВЄыЁЅ
| abbreviate ЁЪЮЌЕЄЙЄыЁЫ | abridge ЁЪУЛНЬЄЙЄыЁЫ | |||
| acute ЁЪРшЄЮРэЄУЄПЁЫ | cute ЁЪЄЋЄяЄЄЄЄЁЫ | ague ЁЪЗуЄЗЄЄЧЎЁЄЁкЩТЭ§ЁлАДЈЁЫ | ||
| adamant ЁЪЙфФОЄЪЁЫ | diamond ЁЪЅРЅЄЅЂЅтЅѓЅЩЁЫ | |||
| adjutant ЁЪНѕМъЄЮЁЫ | aid ЁЪМъХСЄІЁЫ | |||
| aggravate ЁЪЄЕЄщЄЫАВНЄЕЄЛЄыЁЫ | aggrieve ЁЪШсЄЗЄоЄЛЄыЁЫ | |||
| aim ЁЪСРЄЄЄђФъЄсЄыЁЫ | esteem ЁЪТКНХЄЙЄыЁЫ | estimate ЁЪЩОВСЄЙЄыЁЫ | ||
| allocate ЁЪГфЄъХіЄЦЄыЁЫ | allow ЁЪУжЄЏЁЫ | |||
| alloy ЁЪЙчЖтЁЫ | ally ЁЪЦБЬСЄЙЄыЁЫ | |||
| an ЁЪАьЄФЄЮЁЇЩдФъДЇЛьЁЫ | one ЁЪАьЄФЄЮЁЫ | |||
| antic ЁЪЄГЄУЄБЄЄЄЪЄЗЄАЄЕЁЫ | antique ЁЪИХНЄЄЁЫ | |||
| appreciate ЁЪЙтЄЏЩОВСЄЙЄыЁЫ | appraise ЁЪУЭУЪЄђЄФЄБЄыЁЫ | apprize ЁЪТКНХЄЙЄыЁЫ | ||
| aptitude ЁЪХЌРЕЁЫ | attitude ЁЪТжХйЁЫ | |||
| army ЁЪЗГТтЁЫ | armada ЁЪДЯТтЁЫ | |||
| asphodel ЁЪЁдЛэИьЁеЅЙЅЄЅЛЅѓЁЫ | daffodil ЁЪЅщЅУЅбЅЙЅЄЅЛЅѓЁЫ | |||
| assemble ЁЪНИЙчЄЕЄЛЄыЁЫ | assimilate ЁЪОУВНЕлМ§ЄЙЄыЁЫ | |||
| astound ЁЪЖФХЗЄЕЄЛЄыЁЫ | astonish ЁЪЖУЄЋЄЙЁЫ | stun ЁЪЪђСГЄШЄЕЄЛЄыЁЫ | ||
| attach ЁЪХНЄъЩеЄБЄыЁЫ | attack ЁЪЙЖЗтЄЙЄыЁЫ | |||
| band ЁЪЅаЅѓЅЩЁЫ | bond ЁЪЄЄКЄЪЁЫ | |||
| banjo ЁЪЅаЅѓЅИЅчЁМЁЫ | mandolin ЁЪЅоЅѓЅЩЅъЅѓЁЫ | |||
| bark ЁЪЅаЁМЅЏСЅЁЫ | barge ЁЪЪПФьВйСЅЁЫ | |||
| beaker ЁЪЅгЁМЅЋЁМЁЫ | pitcher ЁЪЅдЅУЅСЅуЁМЁЫ | |||
| beam ЁЪЮТЁЫ | boom ЁЪЁкГЄЛіЁлШСЗхЁЫ | |||
| belly ЁЪЪЂЩєЁЫ | bellows ЁЪЄеЄЄЄДЁЫ | |||
| benison ЁЪНЫЪЁЄЮЕЇЄъЁЫ | benediction ЁЪНЫЪЁЁЫ | |||
| blame ЁЪШѓЦёЄЙЄыЁЫ | blaspheme ЁЪЫС瀆ЄЙЄыЁЫ | |||
| block ЁЪТчЄЄЪВєЁЫ | plug ЁЪРђЁЫ | |||
| book ЁЪЫмЁЫ | buck(wheat) ЁЪЅНЅаЁЫ | beech ЁЪЅжЅЪЁЫ | ||
| boulevard ЁЪЙЄЄЪТЬкЦЛЁЫ | bulwark ЁЪдШЮнЁЫ | |||
| brother ЁЪЗЛФяЁЫ | friar ЁЪТёШНЄЦЛЛЮЁЫ | |||
| cadet ЁЪЛХДБИѕЪфРИЁЫ | cad ЁЪАщЄСЄЮАЄЄУЫЁЫ | |||
| cadence ЁЪЧяЛвЁЫ | chance ЁЪЖіСГЁЫ | |||
| cage ЁЪФЛЄЋЄДЁЫ | cave ЁЪЦЖЗЂЁЫ | |||
| calumny ЁЪШ№ыюЁЫ | challenge ЁЪФЉРяЁЫ | |||
| cancel ЁЪМшЄъОУЄЙЁЫ | chancel ЁЪЁдЖЕВёЦВЄЮЁеЦтПиЁЫ | |||
| cant ЁЪЕЖСБХЊЄЪРтЖЕЁЫ | chant ЁЪБгОЇЁЫ | |||
| captain ЁЪМѓЮЮЁЫ | chieftain ЁЪЁдЛГТБЄЪЄЩЄЮЁеЄЋЄЗЄщЁЫ | |||
| cavalry ЁЪЕГЪМТтЁЫ | chivalry ЁЪЕГЛЮЦЛЁЫ | |||
| cell ЁЪЁдТчСШПЅЄЮЁеД№ЫмСШПЅЁЫ | hall ЁЪЅлЁМЅыЁЫ | |||
| charge ЁЪЩщУДЄЕЄЛЄыЁЄРСЕсЄЙЄыЁЫ | cargo ЁЪСЅВйЁЫ | |||
| chariot ЁЪЁдЧЯЄЧАњЄЏЁеЦѓЮиРяМжЁЫ | cart ЁЪВйЧЯМжЁЫ | |||
| chattel ЁЪЁкЫЁЮЇЁлЦАЛКЁЫ | cattle ЁЪУмЕэЁЫ | capital ЁЪЛёЫмЁЫ | ||
| check ЁЪСЫЛпЄЙЄыЁЄЁкЅСЅЇЅЙЁлВІМъЁЫ | shah ЁЪЅЄЅщЅѓЙёВІЁЫ | |||
| costume ЁЪЩўСѕЁЫ | custom ЁЪДЗНЌЁЫ | |||
| crate ЁЪЄяЄЏШЂЁЫ | hurdle ЁЪЅЯЁМЅЩЅыЁЫ | |||
| daft ЁЪЄаЄЋЄЪЁЫ | deft ЁЪДяЭбЄЪЁЫ | |||
| dainty ЁЪОхЩЪЄЪЁЫ | dignity ЁЪАвИЗЁЫ | |||
| danger ЁЪДэИБЁЫ | dominion ЁЪЛйЧлИЂЁЫ | |||
| dauphin ЁЪЁкЮђЛЫЁлЁдЅеЅщЅѓЅЙЄЮЁеВІТРЛвЁЫ | dolphin ЁЪЅЄЅыЅЋЁЫ | |||
| deck ЁЪЅЧЅУЅЁЫ | thatch ЁЪЄяЄщЩјЄВАКЌЁЫ | |||
| defeat ЁЪЩщЄЋЄЙЁЫ | defect ЁЪЗчДйЁЫ | |||
| depot ЁЪФфМжОьЁЫ | deposit ЁЪЭТЖтЁЫ | |||
| devilish ЁЪАЫтЄЮЄшЄІЄЪЁЫ | diabolical ЁЪМйАЄЪЁЫ | |||
| diaper ЁЪТПКЬЄЫОЎЪСЬЯЭЭЄЫЄЙЄыЁЫ | jasper ЁЪЪЫЖЬЁЫ | |||
| disc ЁЪЅьЅГЁМЅЩЁЫ | discus ЁЪБпШзЁЫ | dish ЁЪЛЎЁЫ | dais ЁЪБщУХЁЫ | desk ЁЪДљЁЫ |
| ditto ЁЪЦБОхЁЫ | dictum ЁЪИјМАИЋВђЁЄЖтИРЁЫ | |||
| employ ЁЪИлЄІЁЫ | imply ЁЪАХЄЫАеЬЃЄЙЄыЁЫ | implicate ЁЪАХЄЫМЈЄЙЁЫ | ||
| ensign ЁЪЗГДњЁЫ | insignia ЁЪЕОЯЁЫ | |||
| etiquette ЁЪЅЈЅСЅБЅУЅШЁЫ | ticket ЁЪРкЩфЁЫ | |||
| extraneous ЁЪГАЩєЄЋЄщЄЮЁЫ | strange ЁЪДёЬЏЄЪЁЫ | |||
| fabric ЁЪПЅЪЊЁЫ | forge ЁЪУУЬъОьЁЫ | |||
| fact ЁЪЛіМТЁЫ | feat ЁЪАЮЖШЁЫ | |||
| faculty ЁЪКЭЧНЁЫ | facility ЁЪЭЦАзЄЕЁЫ | |||
| fashion ЁЪЅеЅЁЅУЅЗЅчЅѓЁЫ | faction ЁЪЧЩШЖЁЫ | |||
| feeble ЁЪМхЄЄЁЫ | foible ЁЪЁдАІеШЄЮЄЂЄыЁеМхХРЁЫ | |||
| flame ЁЪБъЁЫ | phlegm ЁЪстЁЫ | |||
| flask ЁЪЅеЅщЅЙЅГЁЫ | fiasco ЁЪДАСДЄЪМКЧдЁЫ | |||
| flour ЁЪОЎЧўЪДЁЫ | flower ЁЪВжЁЫ | |||
| fungus ЁЪЖнЮрЁЫ | sponge ЁЪГЄЬЪЁЫ | |||
| genteel ЁЪОхЩЪЄжЄУЄПЁЫ | gentle ЁЪЭЅЄЗЄЄЁЫ | gentile ЁЪАлЖЕХЬЄЮЁЫ | jaunty ЁЪЭлЕЄЄЪЁЫ | |
| glamour ЁЪЬЅЯЧХЊЄЪЁЫ | grammar ЁЪЪИЫЁЁЫ | |||
| guarantee ЁЪЪнОкЁЫ | warranty ЁЪЪнОкЁЄИЂИТЁЫ | |||
| hale ЁЪЗђСДЄЪЁЫ | whole ЁЪСДТЮЄЮЁЫ | |||
| inch ЁЪЅЄЅѓЅСЁЫ | ounce ЁЪЅЊЅѓЅЙЁЫ | |||
| isolation ЁЪИЩЮЉЁЫ | insulation ЁЪГжЮЅЁЫ | |||
| jay ЁЪЅЋЅБЅЙЁЫ | gay ЁЪЦБРАІЄЮЁЄВїГшЄЪЁЫ | |||
| kennel ЁЪЙТЁЫ | channel ЁЪГЄЖЎЁЫ | canal ЁЪБПВЯЁЫ | ||
| kin ЁЪЗьБяЁЫ | genus ЁЪЁдЪЌЮрОхЄЮЁеТАЁЫ | |||
| lace ЁЪФљЄсЄвЄтЁЫ | lasso ЁЪХъЄВЮиЁЫ | |||
| listen ЁЪФАЄЏЁЫ | lurk ЁЪТдЄСЩњЄЛЄЙЄыЁЫ | |||
| lobby ЁЪЅэЅгЁМЁЫ | lodge ЁЪЛГОЎВАЁЫ | |||
| locust ЁЪЅаЅУЅПЁЫ | lobster ЁЪЅЋЅЁЫ | |||
| maneuver ЁЪКюРяЙдЦАЁЫ | manure ЁЪШюЮСЄђЄфЄыЁЈШюЮСЁЫ | |||
| monetary ЁЪФЬВпЄЮЁЫ | monitory ЁЪЗйЙ№ЄЮЁЫ | |||
| monster ЁЪВјЪЊЁЫ | muster ЁЪОЄНИЄЙЄыЁЫ | |||
| musket ЁЪЅоЅЙЅБЅУЅШНЦЁЫ | mosquito ЁЪВуЁЫ | |||
| naive ЁЪУБНуЄЪЁЫ | native ЁЪРИЄоЄьЄПЛўЄЋЄщЄЮЁЫ | |||
| onion ЁЪЅПЅоЅЭЅЎЁЫ | union ЁЪЗыЙчЁЫ | |||
| paddock ЁЪОЎЪќЫвУЯЁЫ | park ЁЪИјБрЁЫ | |||
| parable ЁЪЖїЯУЁЫ | parabola ЁЪЪќЪЊРўЁЫ | parole ЁЪМЙЙдЭБЭНЁЫ | parley ЁЪЦЄЕФЁЫ | palaver ЁЪОІУЬЁЫ |
| parson ЁЪЖЕЖшЫвЛеЁЫ | person ЁЪПЭЁЫ | |||
| particle ЁЪЪЌЛвЁЫ | parcel ЁЪОЎЪёЁЫ | |||
| patron ЁЪИхБчМдЁЫ | pattern ЁЪЬЯЭЭЁЫ | |||
| piazza ЁЪЁдЅЄЅПЅъЅЂХдЛдЄЮЁеЙОЎЯЉЁЫ | place ЁЪОьЁЫ | plaza ЁЪЁЪЅЙЅкЅЄЅѓХдЛдЄЪЄЩЄЮЁЫЙОьЁЫ | ||
| poignant ЁЪФЫРкЄЪЁЫ | pungent ЁЪПЩЄщЄФЄЪЁЫ | |||
| poison ЁЪЦЧЬєЁЫ | potion ЁЪЁдЦЧБеЄЮЁеАьЩўЁЫ | |||
| poor ЁЪЩЯЄЗЄЄЁЫ | pauper ЁЪИ№ПЉЁЫ | |||
| pope ЁЪЅэЁМЅоЖЕЙФЁЫ | papa ЁЪЅбЅбЁЫ | |||
| praise ЁЪЄлЄсЄыЁЫ | price ЁЪВСГЪЁЫ | |||
| quiet ЁЪРХЄЋЄЪЁЫ | quit ЁЪЄфЄсЄыЁЫ | quite ЁЪЄЙЄУЄЋЄъЁЫ | coy ЁЪЦтЕЄЄЪЁЫ | |
| raid ЁЪНБЗтЁЫ | road ЁЪЦЛЯЉЁЫ | |||
| ransom ЁЪПШТхЖтЁЫ | redemption ЁЪЧуЄЄЬсЄЗЁЫ | |||
| ratio ЁЪШцЮЈЁЫ | ration ЁЪГфЄъХіЄЦЁЫ | reason ЁЪЭ§ЭГЁЫ | ||
| respect ЁЪТКЗЩЄЙЄыЁЫ | respite ЁЪЁдЛХЛіЄЪЄЩЄЮЁеОЎЕйЛпЁЫ | |||
| restrain ЁЪЭоРЉЄЙЄыЁЫ | restrict ЁЪРЉИТЄЙЄыЁЫ | |||
| rover ЁЪЪќЯВМдЁЫ | robber ЁЪХЅЫРЁЫ | |||
| saliva ЁЪТУБеЁЫ | slime ЁЪЄЭЄаХкЁЄЄЬЄсЄъЁЫ | |||
| scandal ЁЪУбПЋЁЫ | slander ЁЪУцН§ЁЫ | |||
| scourge ЁЪЄрЄСЁЄХЗШГЁЫ | excoriate ЁЪШщЄђЄЯЄАЁЫ | |||
| scout ЁЪРЭИѕЁЫ | auscultate ЁЪФАПЧЄЙЄыЁЫ | |||
| secure ЁЪАТСДЄЪЁЫ | sure ЁЪМЋПЎЄђЛ§ЄУЄЦЁЫ | |||
| sergeant ЁЪЗГСтЁЫ | servant ЁЪЛШЭбПЭЁЫ | |||
| sovereign ЁЪМчИЂМдЁЫ | soprano ЁЪЅНЅзЅщЅЮЁЫ | |||
| stack ЁЪДГЄЗС№ЄЮЛГЁЫ | stake ЁЪЙКЁЫ | steak ЁЪЅЙЅЦЁМЅЁЫ | stock ЁЪУпЄЈЁЫ | |
| supervisor ЁЪДЩЭ§МдЁЫ | surveyor ЁЪТЌЮЬМдЁЫ | |||
| tamper ЁЪДГОФЄЙЄыЁЫ | temper ЁЪЕЄРЁЫ | |||
| triumph ЁЪОЁЭјЁЫ | trump ЁЪЅШЅщЅѓЅзЁЫ | |||
| tulip ЁЪЅСЅхЁМЅъЅУЅзЁЫ | turban ЁЪЅПЁМЅаЅѓЁЫ | |||
| two ЁЪ2ЄЮЁЫ | deuce ЁЪЅИЅхЁМЅЙЁЫ | |||
| utter ЁЪИ§ЄЫНаЄЙЁЫ | outer ЁЪГАТІЄЮЁЫ | |||
| valet ЁЪЖсЛјЁЫ | varlet ЁЪНОМдЁЫ | |||
| vast ЁЪЙТчЄЪЁЫ | waste ЁЪЙгЧбЄЕЄЛЄыЁЫ | |||
| veneer ЁЪЅйЅЫЅЂЁЫ | furnish ЁЪВШЖёЄђРпШїЄЙЄыЁЫ | |||
| verb ЁЪЦАЛьЁЫ | word ЁЪИРЭеЁЫ | |||
| whirl ЁЪРћВѓЄЙЄыЁЫ | warble ЁЪЄЕЄЈЄКЄыЁЫ | |||
| yelp ЁЪЄЋЄѓЙтЄЄРМЄђОхЄВЄыЁЫ | yap ЁЪЅЅуЅѓЅЅуЅѓЫЪЄЈЮЉЄЦЄыЁЫ | |||
| zero ЁЪЅМЅэЁЫ | cipher ЁЪАХЙцЁЫ |
ЁЁЁІ ЅИЅчЁМЅМЅе T. ЅЗЅУЅзЅъЁМ УјЁЄЧпХФ НЄЁІтУЪ§ УщЦЛЁІЗъПс ОЯЛв ЬѕЁЁЁиЅЗЅУЅзЅъЁМБбИьИьИЛМХЕЁйЁЁТчНЄДлЁЄ2009ЧЏЁЅ
2013-12-16 Mon
ЂЃ #1694. ВЪГиИьзУЄЫЄЊЄЄЄЦЅЎЅъЅЗЅЂИьЭзСЧЄЌШЫБЩЄЗЄПЭ§ЭГ [greek][compounding][scientific_name][lexicology][combining_form][scientific_name][scientific_english]
ЁЁВЪГиИьзУ (ISV = International Scientific Vocabulary) ЄЫЄЯЁЄЅЎЅъЅЗЅЂИьЄЮЭзСЧЄђЪЃЙчЄЕЄЛЄПЄтЄЮЄЌТПЄЄЁЅЄЗЄаЄЗЄа neo-Hellenic compounds ЄШИЦЄаЄьЄыЄЌЁЄЄГЄьЄщЄЮИьзУЄЯМчЄШЄЗЄЦЖсТхЄЮЛКЪЊЄЧЄЂЄыЁЪЅщЅЦЅѓИьЄЮОьЙчЄЫЄЯ neo-Latin compounds ЄШЄтИЦЄаЄьЁЄЙчЄяЄЛЄЦ neo-classical compounds ЄШИЦЄаЄьЄыЄГЄШЄтЄЂЄыЁЫЁЅГиЬОЄЫЄЊЄЄЄЦЄтЁЄЁж#511. Myrmecophaga tridactylaЁз ([2010-09-20-1]) ЄфЁж#512. ГиЬОЁз ([2010-09-21-1]) ЄЧЄпЄПЄшЄІЄЫЁЄЅЎЅъЅЗЅЂИьЭзСЧЄЌЦУИЂХЊЄЫЭјЭбЄЕЄьЄЦЄЄЄыЄЗЁЄЁж#552. combining formЁз ([2010-10-31-1]) ЄЮЖЁЕыИЛЄШЄЗЄЦЄтЦБИРИьЄЮЬђГфЄЯТчЄЄЄЁЅЄоЄПЁЄeco-, micro-, tele-, -ology ЄЪЄЩЄЮЅЎЅъЅЗЅЂИьЄЫЭГЭшЄЙЄыРмМЄЯРИЛКЮЯЄЌУјЄЗЄЏЙтЄЏЁЄISV ЄЮЯШЄђЄЯЄпНаЄЗЄЦЁЄАьШЬИьзУЄЮЗСРЎЄЫЄтЕкЄѓЄЧЄЄЄыЁЅ
ЁЁISV ЄЫЄЊЄЄЄЦЅЎЅъЅЗЅЂИьЄЌШЫБЩЄЗЄПЧиЗЪЄЫЄЯЁЄЖсТхВЪГиЄЌШЏХИЄЗЄПРОЭЮЄЫЄЊЄЄЄЦЁЄЅщЅЦЅѓИьЄШЪТЄѓЄЧЅЎЅъЅЗЅЂИьЄЌФЙЄЄДжИЂАвЄЂЄыИРИьЄШЄпЄЪЄЕЄьЄЦЄЄПХСХ§ЄЌЄЂЄыЁЅЅшЁМЅэЅУЅбЄЫЄЊЄЄЄЦЁЄЅЎЅъЅЗЅЂИьЄЮАвПЎЄЌИьЧЩЄђФЖБлЄЗЄЦЙЄЌЄУЄЦЄЄЄПЄШЄЄЄІЄЮЄЯЁЄЖсТхВЪГиЄЮШЏХИЄЫЄШЄУЄЦЄЯЙЌБПЄЪЄГЄШЄРЄУЄПЁЅБбИьЄтЅеЅщЅѓЅЙИьЄтЅЩЅЄЅФИьЄтЁЄISV ЄЮЄПЄсЄЫЄЯХљЄЗЄЏЅЎЅъЅЗЅЂИьЄђЭјЭбЄЙЄыЄШЄЄЄІДЗНЌЄЌГЮЮЉЄЗЄфЄЙЄЋЄУЄПЁЅЅыЅЭЅЕЅѓЅЙАЪЙпЁЄТКЄжЄйЄУЮМБЄЮИЛРєЄЯЅЎЅъЅЗЅЂИьЁЪЕкЄгЅщЅЦЅѓИьЁЫЄЫЄЂЄъЁЄЄШЖІФЬЄЗЄЦЙЭЄЈЄщЄьЄыЄшЄІЄЫЄЪЄУЄПЄГЄШЄЧЁЄЄНЄЮИхЄЮВЪГиЁЪИьзУЁЫЄЮШЏХИЄШГШТчЄЫЄШЄУЄЦЁЄЙЅОђЗяЄЌРАЄУЄПЄЮЄЧЄЂЄыЁЅ
ЁЁPotter (86) ЄЯЁЄУЮМБЄЮИЛРєЄШЄЗЄЦЄЮЅЎЅъЅЗЅЂИьЄШЄЄЄІЙЭЄЈЪ§ЄЌЁЄЅВЅыЅоЅѓНєИьЄфЅэЅоЅѓЅЙНєИьЄЮЄпЄЪЄщЄКЁЄЅЙЅщЅєЗЯЄЮЅэЅЗЅЂИьЄЫЄтХіЄЦЄЯЄоЄУЄПЄГЄШЄЯЁЄЄШЄъЄяЄБЙЌБПЄЪЄГЄШЄЧЄЂЄУЄПЄШНвЄйЄЦЄЄЄыЁЅ
In the ever expanding world of science and invention most of these new words are either taken direct from Greek or compounded of Greek elements. This applies not only to English but also to the other three widely disseminated languages --- French, Spanish and Portuguese. Moreover, and in some ways more important still, this also applies to Russian. The modified Cyrillic 33-letter alphabet of modern Russian is based upon the 22-letter alphabet of Greek which is the same today as it was in the time of Plato and Aristotle. Ties between Kiev, Byzantium and Athens have been close throughout the ages. / It is indeed most fortunate that the scientists of the two leading powers --- the United States and the Soviet Union --- both go to Greek for their technical terms. Scientists now have at their disposal a copious store of neo-Hellenic components. They have come to regard the Greek language as a kind of quarry from which they can mine blocks to be shaped at need to make new words or to adapt forms already in use. (86)
ЁЁЅэЅЗЅЂИьЄЯЁЄЪИЛњТЮЗЯЄђДоЄрИРИьЪИВНЄЮЮђЛЫЄђФЬЄИЄЦЁЄЅЎЅъЅЗЅЂИьЄШЄЮЬЉЄЪРмПЈЄђЪнЄУЄЦЄЄПЁЅРОЅшЁМЅэЅУЅбНєИьЪИВНЄШЅэЅЗЅЂИьЪИВНЄШЄЮДжЄЫЄЯЮђЛЫХЊЄЫФОРмЄЮРмХРЄЯТПЄЏЄЪЄЏЁЄЄЗЄПЄЌЄУЄЦЁЄЄШЄтЄЙЄьЄаРЄГІЄЮ ISV Єт2ЄФЁЪАЪОхЁЫЄЮЗЯЮѓЄЫЪЌЄЋЄьЄЦЄЗЄоЄУЄЦЄЄЄПЄЋЄтЄЗЄьЄЪЄЄЁЅЄтЄЗЄНЄІЄЪЄУЄЦЄЄЄПЄщЁЄЖсТхВЪГиЄЮШЏХИЄЮТЎХйЄЯЄтЄУЄШУйЄЏЄЪЄУЄЦЄЄЄПЄРЄэЄІЁЅЄЗЄЋЄЗЁЄЅшЁМЅэЅУЅбЄЮХьРОЄЧЖІФЬЄЗЄЦАвПЎЄЂЄъЄШЧЇЄсЄщЄьЄЦЄЄЄПЅЎЅъЅЗЅЂИьЄЌВЪГиИьзУЗСРЎЄЮД№СУЄШЄЕЄьЄПЄГЄШЄЧЁЄЙЌБПЄЫЄт ISV ЄЯ1ЗЯЮѓЄЫМ§ЄоЄУЄЦЄЄЄыЄЮЄЧЄЂЄыЁЅ
ЁЁЦќЫмИьЪьИьЯУМдЄЫЄШЄУЄЦЁЄISV ЄЮД№ШзЄЫЅЎЅъЅЗЅЂИьЄЌЄЂЄыЄЋЄщЄШЄЄЄУЄЦЁЄЄНЄьЄђГиЄжОхЄЧЦУЄЫЅсЅъЅУЅШЄЌЄЂЄыЄяЄБЄЧЄЯЄЪЄЄЁЅЄЗЄЋЄЗЁЄISV ЄЌ1ЗЯЮѓЄЧЄоЄШЄоЄУЄЦЄЄЄыЄГЄШЄЫЄшЄУЄЦВЪГиЄЮШЏХИЄЌКЧТчИТЄЫТЅЄЕЄьЁЄЄНЄЮВИЗУЄђРЄГІЛдЬБЄШЄЗЄЦКЧТчИТЄЫЕ§МѕЄЗЄЦЄЄЄыЄШЙЭЄЈЄьЄаЁЄЄфЄЯЄъЅЎЅъЅЗЅЂИьЄЮЦЏЄЄЯТчЄЄЄЄШЩОВСЄЧЄЄыЄРЄэЄІЁЅ
ЁЁЁІ Potter, Simon. Changing English. London: Deutsch, 1969.
2013-12-11 Wed
ЂЃ #1689. ЦюРОТРЪПЭЮУЯАшЄЮЅдЅИЅѓИьЄШЅЏЅьЅЊЁМЅыИьЄЮИьзУ [pidgin][creole][map][reduplication][lexicology][etymology][tok_pisin]
ЁЁКђЦќЄЮЕЛіЁж#1688. Tok PisinЁз ([2013-12-10-1]) ЄђМѕЄБЄЦЁЄЦюРОТРЪПЭЮУЯАшЄЮЅдЅИЅѓИьЄШЅЏЅьЅЊЁМЅыИьЄЮЯУТъЁЅДиЯЂНєИРИьЄЮЪЌЩлПоЄђЁЄGramley (220) ЄЮУЯПоЄђЛВЙЭЄЫМЈЄЗЄЦЄпЄПЁЅ
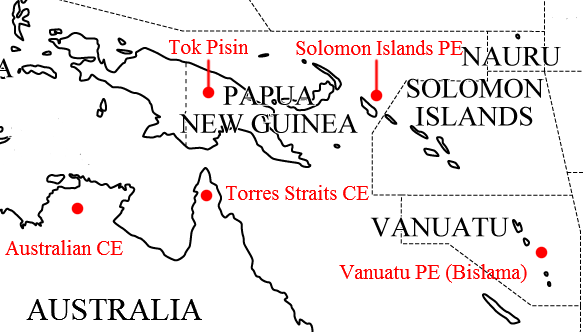
ЁЁЄГЄГЄЫЕѓЄВЄщЄьЄЦЄЄЄыЅдЅИЅѓИьЄфЅЏЅьЅЊЁМЅыИьЄЯЮђЛЫХЊЄЫДиЯЂЄЌПМЄЏЁЄИРИьХЊЄЫЄтЖсЄЄЁЅЄЄЄКЄьЄтБбИьЄђОхСиИРИь (superstrate language) ЕкЄгИьзУЖЁЕыИРИь (lexifier) ЄШЄЙЄыКЎРЎИьЄЧЁЄМТКнЄЫЄЄЄКЄьЄтИьзУЄЮ8ГфСАИхЄЯБбИьЅйЁМЅЙЄЧЄЂЄыЁЅMühlhäusler ЄђЛВОШЄЗЄП Gramley (220) ЄЮЩНЄЫЄшЄыЄШЁЄЅєЅЁЅЬЅЂЅФЄЮ Bislama ЁЪЁж#1536. ЙёИьЄЧЄЂЄъЄЪЄЌЄщГиЙЛЄЧЄЮЛШЭбЄЌЖиЛпЄЕЄьЄЦЄЄЄы BislamaЁз ([2013-07-11-1]) ЄђЛВОШЁЫ, ЅбЅзЅЂЅЫЅхЁМЅЎЅЫЅЂЄЮ Tok Pisin, ЅНЅэЅтЅѓНєХчЄЮ Solomon Pijin ЄЮ3ЅдЅИЅѓИьЄЧЄпЄыЄШЁЄИьМяЪЌЩлЄЯАЪВМЄЮФЬЄъЄЧЄЂЄыЁЅ
| English | Indigenous | Others | |
|---|---|---|---|
| Bislama | 90% | 5 | 3 (French) |
| Tok Pisin | 77 | 16 | 7 (German etc.) |
| Solomon Pijin | 89 | 6 | 5 |
ЁЁАьШЬЄЫЅдЅИЅѓИьЄфЅЏЅьЅЊЁМЅыИьЄЮИьзУЄЯЁЄОхСиИРИьЄђД№НрЄШЄЙЄыЄШЁЄБЊИРЁЄЫнЬѕМкЭб (loan_translation)ЁЄАеЬЃЪбВНЁЄВУНХ (reduplication)ЁЄАлЪЌРЯЄЪЄЩЄЮЮуЄЫЫўЄСЄЦЄЄЄыЁЅАЪВМЄЫЁЄGramley (220--22) ЄЫЕђЄУЄЦ Tok Pisin ЄЋЄщЄЮЮуЄђМЈЄНЄІЁЅhair ЄШЄЄЄІТхЄяЄъЄЫ gras bilong hed (grass that belongs to the head)ЁЄbeard ЄШЄЄЄІТхЄяЄъЄЫ gras bilong fes (grass that belongs to the face) ЄШЄЄЄУЄПЩїЄЧЄЂЄыЁЅИНКпЗСЄШВсЕюЗСЄЮЖшЪЬЄЯЄЪЄЏЁЄЮуЄЈЄа stei (stay) ЄЯЪИЬЎМЁТшЄЧИНКпЁІВсЕюЄЄЄКЄьЄЮАеЬЃЄЫЄтЄЪЄъЄІЄыЁЅtudir (too dear) ЄЯЁЄЁжЙтВСЄЪЁзЄђЩНЄяЄЙ1ИьЄШЄЗЄЦЪЌРЯЄЕЄьЁЄЦБЭЭЄЫ lego (let go) ЄЯЁжЙдЄЋЄЛЄыЁз, sekan (shake hands) ЄЯЁжЯТВђЄЙЄыЁзЄШЄЗЄЦИьзУВНЄЗЄЦЄЄЄыЁЅБбИь arse ЁЪПЌЁЫЄЫЕЏИЛЄђЄтЄФ, as ЄЯЪИТЮХЊЄЫУцЮЉЄЪЁжИхЩєЁЈПЌЁзЄЧЄЂЄъЁЄЄЕЄщЄЫАеЬЃЪбВНЄђЕЏЄГЄЗЄЦЁжЕЏИЛЁЈИЖАјЁзЄЮАеЄЧЄтЭбЄЄЄщЄьЄыЁЅthat's all ЄЫЕЏИЛЄђЄтЄФ tasol ЄЯЁЄАьШЬХЊЄЫ but ЄЮАеЬЃЄЮРмТГЛьЄШЄЗЄЦШЏУЃЄЗЄПЁЅВУНХЄЮЮуЄЫЄФЄЄЄЦЄЯЁЄЁж#65. БбИьЄЫЄЊЄБЄы reduplicationЁз ([2009-07-02-1]) ЄђЛВОШЄЕЄьЄПЄЄЁЅ
ЁЁИНУЯЄЮЪИВНЄЌИьзУЄЫШПБЧЄЕЄьЄыЄГЄШЄтЄЂЄыЁЅЄШЄъЄяЄБПЦТВЬООЮ (kinship terms) ЄЧЄЯЁЄmama (mother), papa (father) ЄоЄЧЄЯЩИНрБбИьЄШЦБЄИЄРЄЌЁЄЩуЗЯЄЮЄЊЄИЄШЄЊЄаЄЯЄНЄьЄОЄь smalpapa, smalmama ЄРЄЌЁЄЪьЗЯЄЮЄЊЄИЄШЄЊЄаЄЯЄШЄтЄЫ kandare ЄШЄЄЄІ1ИьЄЧЩНЄяЄЙЁЅСФЩуЪьЄШТЙЄЯРЪЬЄЮЖшЪЬЄтЄЪЄЏЁЄАьНяЄЏЄПЄЫ tumbuna ЄШЩНИНЄЙЄыЁЅЗЛФяЛаЫхЄтЁЄЦБРЄЧЄЂЄьЄа brataЁЄАлРЄЧЄЂЄьЄа susa ЄђЭбЄЄЄыЄШЄЄЄІХРЄЧЁЄЩИНрБбИьЄШАлЄЪЄыЁЅ
ЁЁЁІ Gramley, Stephan. The History of English: An Introduction. Abingdon: Routledge, 2012.
2013-10-28 Mon
ЂЃ #1645. ИНТхЦќЫмИьЄЮИьМяЪЌЩл [japanese][lexicology][statistics][etymology][loan_word][lexical_stratification]
ЁЁБбИьИьзУЄЮИьМяЪЬЄЮГфЙчЄЫЄФЄЄЄЦЁЄЄГЄьЄоЄЧТПЄЏЄЮЕЛіЄЧГЦМяХ§ЗзЄђМЈЄЗЄЦЄЄПЁЅ
ЁЁЁІ [2012-09-03-1]: Ёж#1225. ЅеЅщЅѓЅЙМкЭбИьЄЮЪЌЩлЄЮЦУАлРЁз
ЁЁЁІ [2012-08-11-1]: Ёж#1202. ИНТхБбИьЄЮИьзУЄЮЕЏИЛЄШГфЙч (2)Ёз
ЁЁЁІ [2012-01-07-1]: Ёж#985. УцБбИьЄЮИьзУЄЮЕЏИЛЄШГфЙчЁз
ЁЁЁІ [2011-09-18-1]: Ёж#874. ИНТхБбИьЄЮПЗИьЄЫЄЊЄБЄыЅНЁМЅЙИРИьЄЮЪЌЩлЁз
ЁЁЁІ [2011-08-20-1]: Ёж#845. ИНТхБбИьЄЮИьзУЄЮЕЏИЛЄШГфЙчЁз
ЁЁЁІ [2010-12-31-1]: Ёж#613. Academic Word List ЄЫДоЄоЄьЄыЫмЭшИьЄЮГфЙчЁз
ЁЁЁІ [2010-06-30-1]: Ёж#429. ИНТхБбИьЄЮКЧЩбИьзУ10000ИьЄЮЕЏИЛЄШГфЙчЁз
ЁЁЁІ [2010-05-16-1]: Ёж#384. ИьзУПєЄШЅВЅыЅоЅѓИьзУШцЮЈЄЧИХБбИьЄШИНТхБбИьЄЮИьзУЄђШцГгЄЙЄыЁз
ЁЁЁІ [2010-03-02-1]: Ёж#309. ИНТхБбИьЄЮД№ЫмИьзУ100ИьЄЮЕЏИЛЄШГфЙчЁз
ЁЁЁІ [2009-11-15-1]: Ёж#202. ИНТхБбИьЄЮД№ЫмИьзУ600ИьЄЮЕЏИЛЄШГфЙчЁз
ЁЁЁІ [2009-11-14-1]: Ёж#201. ИНТхБбИьЄЮМкЭбИьЄЮЕЏИЛЄШГфЙч (2)Ёз
ЁЁЁІ [2009-08-19-1]: Ёж#114. НщДќЖсТхБбИьЄЮМкЭбИьЄЮЕЏИЛЄШГфЙчЁз
ЁЁЁІ [2009-08-15-1]: Ёж#110. ИНТхБбИьЄЮМкЭбИьЄЮЕЏИЛЄШГфЙчЁз
ЁЁЁж#334. БбИьИьзУЄЮЛАСиЙНТЄЁз ([2010-03-27-1])ЁЄЁж#335. ЦќЫмИьИьзУЄЮЛАСиЙНТЄЁз ([2010-03-28-1])ЁЄЁж#1526. БбИьЄШЦќЫмИьЄЮИьзУЛЫТаОШЩНЁз ([2013-07-01-1]) ЄЧИЋЄПЄшЄІЄЫЁЄБбИьЄШЦќЫмИьЄЮИьзУЄЯШцГгЄЕЄьЄыЮђЛЫЄђЄПЄЩЄУЄЦЄЄЦЄЊЄъЁЄЗыВЬЄШЄЗЄЦИНТхЄЮЖІЛўХЊЄЪИьзУЙНРЎЄЫЄтЖІФЬХРЄЌИЋЄщЄьЄыЁЅКЃВѓЄЯЁЄИНТхБбИьЄШЄЮШцГгЄЮЄПЄсЄЫЁЄИНТхЦќЫмИьЄЮИьМяЪЬЄЮГфЙчЄђЄпЄшЄІЁЅАьШЬХЊЄЫЄГЄЮМяЄЮИьзУХ§ЗзЄђЦРЄыЄЮЄЯЦёЄЗЄЄЄЌЁЄЁиЦќЫмИьЩДВЪТчЛіХЕЁй (420--21) ЄЫЕђЄъЄЪЄЌЄщ3МяЄЮФДККЗыВЬЄЮГЕДбЄђМЈЄЙЁЅ
ЁЁ(1) ЬРМЃЄЋЄщОМЯТЄЫЄЋЄБЄЦЄЮ3МяЄЮЙёИьМХЕЁиИРГЄЁйЁЪЬРМЃ22ЧЏЁЈ1889ЧЏЁЫЁЄЁиЮуВђЙёИьМХЕЁйЁЪОМЯТ31ЧЏЁЈ1956ЧЏЁЫЁЄЁиЮуВђЙёИьМХЕЁйЁЪОМЯТ44ЧЏЁЈ1969ЧЏЁЫЄЮМ§ЯПИьЄђИьМяЪЬЄЫПєЄЈЄПИІЕцЄЌЄЂЄыЁЅСэИьПєЄЯЁЄЁиИРГЄЁй39,103ЁЄЁиЮуВђЙёИьМХЕЁй40,393ЁЄЁиГбРюЙёИьМХЕЁй60,218 ЄЧЄЂЄыЁЅАЪВМЄЫГфЙчЄђМЈЄЙЩНЄШПоЄђМЈЄНЄІЁЅ
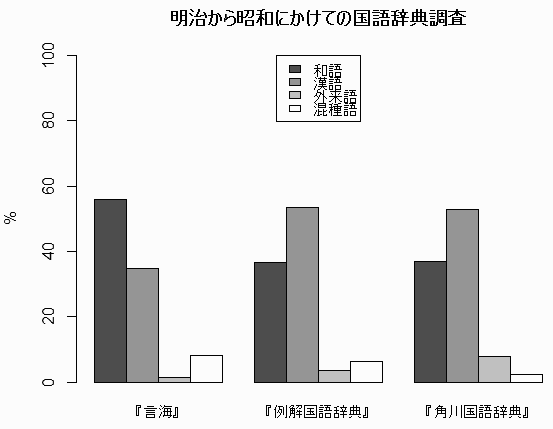
| ЯТИь | ДСИь | ГАЭшИь | КЎМяИь | |
|---|---|---|---|---|
| ЁиИРГЄЁй | 55.8% | 34.7 | 1.4 | 8.1 |
| ЁиЮуВђЙёИьМХЕЁй | 36.6 | 53.6 | 3.5 | 6.2 |
| ЁиГбРюЙёИьМХЕЁй | 37.1 | 52.9 | 7.8 | 2.2 |
ЁЁЛўТхЄЌПЪЄрЄЫЄФЄьЄЦЁЄЯТИьЄЫТаЄЙЄыДСИьЄШГАЭшИьЄЮГфЙчЄЌЙтЄоЄУЄЦЄЄЦЄЄЄыЄЮЄЌЄяЄЋЄыЁЅОМЯТЄЧЄЯЁЄ1/2ЖЏЄЌДСИьЁЄ1/3ЖЏЄЌЯТИьЄШЄЄЄІГфЙчЄРЁЅ
ЁЁ(2) ИНТхЄЮНёЄЄГЄШЄаЄЫЄФЄЄЄЦЄЯЁЄЙёЮЉЙёИьИІЕцНъЄЮЁиИНТхЛЈЛяЖхННМяЄЮЭбИьЭбЛњЁйФДККЄЮЅЧЁМЅПЄЌЄшЄЏЛВОШЄЕЄьЄыЁЅОМЯТ31ЧЏЁЪ1956ЧЏЁЫЄЮЛЈЛяЄЋЄщЁЄНѕЛьЁЄНѕЦАЛьЁЄИЧЭЬОЛьЄђНќЄЄЄЦИьзУЄђМ§НИЄЗЄПЄтЄЮЄЧЄЂЄыЁЅЦРЄщЄьЄПИьзУЄЯЁЄАлЄЪЄъИьПєЄЧ30,331ЁЄБфЄйИьПєЄЧ411,972ЁЅ21РЄЕЊЄЮИНКпЄЋЄщИЋЄыЄШИХЄЄЅЧЁМЅПЄЧЄЯЄЂЄыЄЌЁЄМСЄЫЄЊЄЄЄЦШцИЊЄЙЄыПЗЄЗЄЄФДККЄЯЙдЄяЄьЄЦЄЄЄЪЄЄЁЅ
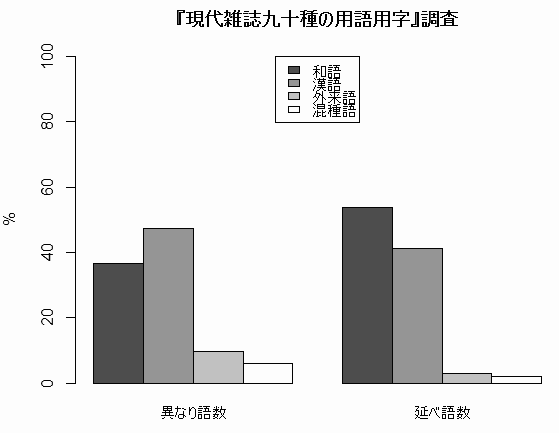
| ЯТИь | ДСИь | ГАЭшИь | КЎМяИь | |
|---|---|---|---|---|
| АлЄЪЄъИьПє | 36.7% | 47.5 | 9.8 | 6.0 |
| БфЄйИьПє | 53.9 | 41.3 | 2.9 | 1.9 |
ЁЁАлЄЪЄъИьПєЄШБфЄйИьПєЄЧЄЯПєУЭЄЌЄЋЄЪЄъАлЄЪЄУЄЦЄЊЄъЁЄЦУЄЫЯТИьЄШДСИьЄЮНчАЬЄЌЦўЄьТиЄяЄУЄЦЄЄЄыЄЮЄЌУэЬмЄЫУЭЄЙЄыЁЅ
ЁЁ(3) ИНТхЄЮЯУЄЗЄГЄШЄаЄЮФДККЄШЄЗЄЦЄЯЁЄУЮМБСиЄђТаОнЄШЄЗЄПЄтЄЮЄЌЄЂЄыЁЅЦќЫмИьЖЕАщЄЊЄшЄгИьГиДиЗИЄЮИІЕцМд7ПЭЄШЄНЄЮЯУЄЗСъМъЄЮВёЯУЄђБфЄй42ЛўДжЪЌЯПВЛЄЗЁЄЪЌРЯЄЗЄПЄтЄЮЄЧЄЂЄыЁЅАлЄЪЄъИьПєЄЯ4,617ЄЧЁЄБфЄйИьПєЄЯ64,023ЁЅ
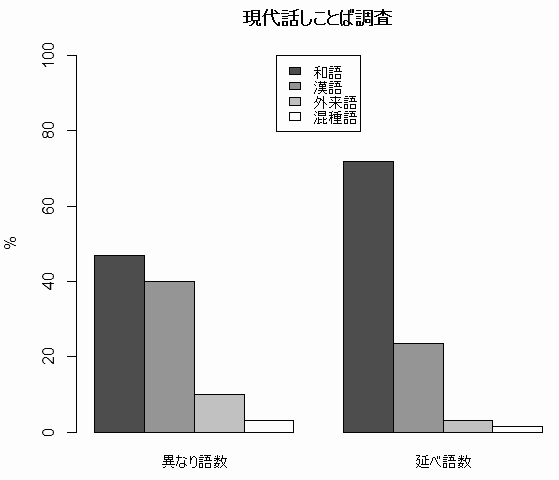
| ЯТИь | ДСИь | ГАЭшИь | КЎМяИь | |
|---|---|---|---|---|
| АлЄЪЄъИьПє | 46.9% | 40.0 | 10.1 | 3.0 |
| БфЄйИьПє | 71.8 | 23.6 | 3.2 | 1.4 |
ЁЁЯУЄЗЄГЄШЄаЄЧЄЯЁЄНёЄЄГЄШЄаЄШАлЄЪЄъЁЄАлЄЪЄъИьПєЄШБфЄйИьПєЄЮДжЄЧЯТДСИьЄЮНчАЬЦўЄьТиЄЈЄЯЄЪЄЄЁЅЄЄЄКЄьЄЮПєЄЈЪ§ЄЧЄтЯТИьЄЮГфЙчЄЌКЧЄтТПЄЄЄЌЁЄЄШЄъЄяЄББфЄйИьПєЄЧЄЯЯТИьЄЌАЕХнЄЗЄЦЄЄЄыЁЅ
ЁЁЄГЄЮЯУЄЗЄГЄШЄаЄЮФДККЄЧЄЯЁЄИјХЊЄЪОьЬЬЄфЛфХЊЄЪОьЬЬЄЪЄЩОьЬЬЪЬЄЫЪЌРЯЄЌЄЪЄЕЄьЄПЄЌЁЄСДТЮХЊЄЪЗЙИўЄШЄЗЄЦЁЄЯТИьЄЯ (1) ЛфХЊЄЪОьЬЬЄЧЄЮЄлЄІЄЌТПЄЄЁЄ(2) БфЄйИьПєЄЧЄЮЄлЄІЄЌТПЄЄЁЄ(3) ЛШЭбЩбХйЄЮЙтЄЄИьЄлЄЩТПЄЄЁЄ(4) ЯУЄЗИРЭеЄЧЄЮЄлЄІЄЌТПЄЄЁЄЄШЄЄЄІЗыВЬЄЌНаЄПЁЅЛфХЊЄЪЯУЄЗЄГЄШЄаЄЧЙтЩбХйЄЫЭбЄЄЄщЄьЄыИьЄЯЁЄЯТИьЄЧЄЂЄыГЮЮЈЄЌКЧЄтЙтЄЄЄШЄЄЄІЄГЄШЄЫЄЪЄыЁЅЄГЄЮЗыВЬЄЯФОДЖЄШАьУзЄЙЄыЄРЄэЄІЁЅ
ЁЁБбИьЄЫЄЊЄЄЄЦЄтЫмЭшИьЄЯЁжЛфХЊЄЪОьЬЬЄЮЯУЄЗЄГЄШЄаЄЧЙтЩбХйЄЫЭбЄЄЄщЄьЄыЁзГЮЮЈЄЌЙтЄЄЄШСлСќЄЕЄьЄыЄЌЁЄЄГЄьЄЫЄФЄЄЄЦЄЯХ§ЗзЄЯИЋЄПЄГЄШЄЯЄЪЄЏЁЄКЃИхЁЄМТОкЄЗЄЦЄцЄЏЩЌЭзЄЌЄЂЄыЄЋЄтЄЗЄьЄЪЄЄЁЅ
ЁЁЁІ ЁиЦќЫмИьЩДВЪТчЛіХЕЁйЁЁЖтХФАь НеЩЇЄлЄЋ ЪдЁЄТчНЄДлЁЄ1988ЧЏЁЅ
2013-10-21 Mon
ЂЃ #1638. ЅеЅщЅѓЅЙИьЄШЅщЅЦЅѓИьЄЋЄщЄЮТчЮЬИьзУМкЭбЄЮЅПЅЄЅпЅѓЅАЄЮЖІФЬХР [french][latin][renaissance][lexicology][loan_word][borrowing][reestablishment_of_english][language_shift]
ЁЁЅеЅщЅѓЅЙИьМкЭбЄЮЧњШЏДќЄЯЁж#117. ЅеЅщЅѓЅЙМкЭбИьЄЮЧЏТхЪЬЪЌЩлЁз ([2009-08-22-1]) ЄЧИЋЄПЄшЄІЄЫ14РЄЕЊЄЧЄЂЄыЁЅЄГЄЮЅПЅЄЅпЅѓЅАЄЫЄФЄЄЄЦЄЯЁЄЁж#1205. БбИьЄЮЩќИЂДќЄЫЅеЅщЅѓЅЙМкЭбИьЄЌЧњШЏЄЗЄПЄЮЄЯЄЪЄМЄЋЁз ([2012-08-14-1]) ЄфЁж#1209. 1250ЧЏЄђЖЄШЄЙЄыЅеЅщЅѓЅЙМкЭбИьЄЮЖшЪЌЁз ([2012-08-18-1]) ЄЮЕЛіЄЧЯУТъЄЫЄЗЄПЄшЄІЄЫЁЄЅЄЅѓЅАЅщЅѓЅЩЄЫЄЊЄЄЄЦБбИьЄЌЩќИЂЄЗЄЦЄЄПЛўДќЄШНХЄЪЄыЁЅЄНЄьЄоЄЧЅеЅщЅѓЅЙИьЄЌУДЄУЄЦЄЄПМвВёХЊЄЪЕЁЧНЄђБбИьЄЌИЊТхЄяЄъЄЙЄыЄГЄШЄЫЄЪЄъЁЄЦЭЧЁЄШЄЗЄЦТчЮЬЄЮИьзУЄЌЩЌЭзЄШЄЪЄУЄПЄЋЄщЄШЄЕЄьЄыЁЅЅеЅщЅѓЅЙИьЄђЯУЄЗЄЦЄЄЄПЅЄЅѓЅАЅщЅѓЅЩЄЮВІИєЕЎТВЄЫЄШЄУЄЦЄЯЁЄБбИьЄиЄЮИРИьИђТи (language shift) ЄЌЕЏЄГЄУЄЦЄЄЄПЛўДќЄШЄтЄЄЄЈЄыЁЪЁж#1540. УцБбИьДќЄЫЄЊЄБЄыИРИьИђТиЁз ([2013-07-15-1]) ЄђЛВОШЁЫЁЅ
ЁЁАьЪ§ЁЄЅщЅЦЅѓИьМкЭбЄЮЧњШЏДќЄЯЁЄЁж#478. НщДќЖсТхБбИьДќЄЫХђПхЄЮЄшЄІЄЫМкЄъЄщЄьЄЦЄЯМЮЄЦЄщЄьЄПЅщЅЦЅѓИьЁз ([2010-08-18-1]) ЄфЁж#1226. ЖсТхБбИьДќЄЫЄЊЄБЄыИьзУС§ВУЄЮЧЏТхЪЬЪЌЩлЁз ([2012-09-04-1]) ЄЧИЋЄПЄшЄІЄЫЁЄ16РЄЕЊИхШОЄђУцПДЄШЄЙЄыЛўДќЄЧЄЂЄыЁЅЄГЄЮЅПЅЄЅпЅѓЅАЄЯЁЄЄНЄьЄоЄЧЅщЅЦЅѓИьЄЌУДЄУЄЦЄЄПМвВёХЊЄЪЕЁЧНЁЄЄШЄъЄяЄБЙтОАЄЪНёЄЪЊЄЮИРИьЄЫЄеЄЕЄяЄЗЄЄЄШЄЕЄьЄЦЄЄПУЯАЬЄђЁЄБбИьЄЌНљЁЙЄЫИЊТхЄяЄъЄЗЛЯЄсЄПЛўДќЄШНХЄЪЄыЁЅЅыЅЭЅЕЅѓЅЙЄЫЄшЄыПЗУЮМБЄЮЧњШЏЄЮЄПЄсЄЫЦЭЧЁЄШЄЗЄЦТчЮЬЄЮИьзУЄЌЩЌЭзЄЫЄЪЄъЁЄБбИьЄЯФЩЄЄЄФЄБЁЄФЩЄЄБлЄЛЄЮЬмЩИЄЧЄЂЄыЅщЅЦЅѓИьЄЋЄщЄНЄЮЄоЄоИьзУЄђМкЭбЄЗЄПЄЮЄРЄУЄПЁЅЄГЄЮЄшЄІЄЫЅщЅЦЅѓИьЧЎЄЌЄЄЄфЄоЄЗЄЫЙтЄоЄУЄПЄЌЁЄЮЂЄђЪжЄЛЄаЁЄЄНЄЮЄШЄЄоЄЧЄЫПЭЁЙЄЮАьШЬХЊЄЪЅщЅЦЅѓИьЛШЭбЄЌСъХіЭюЄСЙўЄѓЄЧЄЄЄПЄГЄШЄђМЈКЖЄЙЄыЁЅЅЄЅѓЅАЅщЅѓЅЩУЮМБПЭЄЮДжЄЫЁЄЄЂЄыАеЬЃЄЧЅщЅЦЅѓИьЄЋЄщБбИьЄиЄЮИРИьИђТиЄЌЕЏЄГЄУЄЦЄЄЄПЄШЄтЙЭЄЈЄщЄьЄыЁЅ
ЁЁЄФЄоЄъЁЄЅеЅщЅѓЅЙИьЄШЅщЅЦЅѓИьЄЋЄщЄЮТчЮЬИьзУМкЭбЄЮКЧРЙДќЄЯАлЄЪЄУЄЦЄЯЄЄЄыЄтЄЮЄЮЁЄЖІФЬЙрЄШЄЗЄЦЁжБбИьЄиЄЮИРИьИђТиЁзЄЌЄЏЄЏЄъЄРЄЛЄыЄшЄІЄЫЛзЄЈЄыЁЅЄГЄГЄЧЄЮЁжИРИьИђТиЁзЄЯЪИЛњФЬЄъЄЮЪьИьЄЮОшЄъДЙЄЈЄЧЄЯЄЪЄЏЁЄЄНЄьЄоЄЧСъМъИРИьЄЌЄтЄУЄЦЄЄЄПМвВёИРИьГиХЊЄЪЕЁЧНЄђЁЄБбИьЄЌИЊТхЄяЄъЄЙЄыЄшЄІЄЫЄЪЄУЄПЄШЄЄЄІЄлЄЩЄЮАеЬЃЄЧЭбЄЄЄЦЄЄЄыЁЅЄГЄЮХРЄђЛиХІЄЗЄП Fennell (148) ЄЮЦЖЛЁЄЮБдЄЕЄђЩОВСЄЗЄПЄЄЁЅ
As is often the case when use of a language ceases (as French did at the end of the Middle English period), the demise of Latin coincides with the borrowing of huge numbers of Latin words into English in order to fill perceived gaps in the language.
ЁЁЁІ Fennell, Barbara A. A History of English: A Sociolinguistic Approach. Malden, MA: Blackwell, 2001.
2013-10-13 Sun
ЂЃ #1630. ЅЄЅѓЅЏдфИьЁЄЅЋЅПЅЋЅЪИьЁЄЅСЅѓЅзЅѓДСИь [japanese][kanji][katakana][waseieigo][lexicology][emode]
ЁЁНщДќЖсТхБбИьДќЁЄМчЄШЄЗЄЦЅщЅЦЅѓИьЄЫЭГЭшЄЙЄыЅЄЅѓЅЏдфИь (inkhorn_term) ЄШИЦЄаЄьЄыГиМдИьЄЌТчЮЬЄЫМкЭбЄЕЄьЄПЄШЄЁЄГАЭшИьЄЮШХЭєЄЫТаЄЙЄыТчЕФЯРЄЌДЌЄЕЏЄГЄУЄПЄГЄШЄЯЁЄЁж#1408. ЅЄЅѓЅЏдфИьЯРСшЁз ([2013-03-05-1]) ЄфЁж#1410. ЅЄЅѓЅЏдфИьШуШНЄШЫмЭшИьВѓЕЂЁз ([2013-03-07-1]) ЄЪЄЩЄЮЕЛіЄЧПЈЄьЄПЁЅBragg (116) ЄЮЩОВСЄЫЄшЄьЄаЁЄ"This controversy was the first and probably the greatest formal dispute about the English language." ЄШЄЄЄІЄГЄШЄРЄУЄПЁЅ
ЁЁИНТхЦќЫмИьЄЫЄЊЄЄЄЦЛїЄПЄшЄІЄЪЬфТъЄЌЁЄЅЋЅПЅЋЅЪИьЄЮШХЭєЄШЄЄЄІЗСЄЧРИЄИЄЦЄЄЄыЁЅЅЄЅѓЅЏдфИьЄШЅЋЅПЅЋЅЪИьЄЮЬфТъЄЮЮрЛїХРЄЫЄФЄЄЄЦЄЯЁЄЁж#1615. ЅЄЅѓЅЏдфИьЄђХ§ЙчЄЙЄыЛюЄпЁЄ2МяЁз ([2013-09-28-1]) ЄШЁж#1616. ЅЋЅПЅЋЅЪИьЄђХ§ЙчЄЙЄыЛюЄпЁЄ2МяЁз ([2013-09-29-1]) ЄЧМшЄъОхЄВЄПЄЌЁЄМкЭбИьзУЄЮМѕЭЦЄђНфЄыЕФЯРЄЯЁЄЄЊЄшЄНЛїЄПЄшЄІЄЪРМСЄђТгЄгЄыЄтЄЮЄщЄЗЄЄЁЅЄНЄГЄиЄтЄІ1ЄФПЗИьзУЄЮМѕЭЦЄђНфЄыЬфТъЄђВУЄЈЄыЄШЄЙЄьЄаЁЄЖсТхДќЄЮЦќЫмЄЮПЗДСИьЬфТъЄЌЛзЄЄЩтЄЋЄжЁЅКђЦќЄЮЕЛіЁж#1629. ЯТРНДСИьЁз ([2013-10-12-1]) ЄЧЄтЯУТъЄЫЄЗЄПЁЄЯТРНДСИьЄђМяЄШЄЙЄыПЗДСИьЄЮТчЮЬРИЛКЄЧЄЂЄыЁЅ
ЁЁЫыЫіАЪЙпЁЄЦУЄЫЬРМЃНщДќАЪЭшЁЄБбИьЄђЄЯЄИЄсЄШЄЙЄыТчЮЬЄЮРОЭЮИьЄђМѕЄБЦўЄьЄыЄЮЄЫЁЄЄНЄьЄђДСЬѕЄЗЄЦМѕЭЦЄЗЄПЁЅХіЛўЄЮУЮМБПЭЄЫДСГиЄЮСЧЭмЄЌЄЂЄУЄПЄЋЄщЄЧЄЂЄыЁЅДСЬѕЄЫХіЄПЄУЄЦЄЯЁЄИХЭшЄЮДСИьЄђЭјЭбЄЗЄПЄъЁЄW. Lobscheid ЄЮЁиБбВкЛњХЕЁйЄђЛВОШЄЗЄПЄъЁЪЮуЄЈЄаЁЄЪИГиЁЄЖЕАщЁЄЦтГеЁЄЙёВёЁЄГЌЕщЁЄХСЕЄЪЄЩЁЫЄЗЄЦТаНшЄЗЄПЄтЄЮЄтЄЂЄУЄПЄЌЁЄЯТРНДСИьЄђКюЄъНаЄЙОьЙчЄЌТПЄЋЄУЄПЁЅЄГЄЮТчЮЬЄЮПЗДСИьЄЯЁжДСИьЄЮШХЭєЁзЬфТъЄђМцЕЏЄЗЁЄАьШЬНюЬБЄЫЄоЄЧБЦЖСЄђЕкЄмЄЙЄГЄШЄЫЄЪЄУЄПЁЅ
ЁЁЮуЄЈЄаЁЄЁиЦќЫмИьЩДВЪТчЛіХЕЁй (453--54) ЄЫЄшЄьЄаЁЄЁиХдюСПЗЪЙЁйТш1ЙцЁЪЗФиц4ЁІЬРМЃ1ЁЫЄЫЁжКЁЄЯКЂГћХьЅЮЄЮЗнЕИЁЄОЏНїЅЫЛъЅыЅоЅЧЁЄРьЅщДСИьЅђЅФЅЋЅеЅГЅШЅђЙЅЅпЁЄ№УБЋЅЫЫпУЯЅЮЖтЕћЅЌУІСіЅЗЁЄВаШЅЌАјНлЅЗЅЦЅ№ЅыЅЪЅЩЁЄВПЅЮЅяЅЅоЅиЅтЅЪЅЏЅЄЅвЙчЅеЅГЅШЅГЅьЅЪЅъЁзЄШЄЄЄІШщЦљЄЌЪЙЄЋЄьЄПЄЗЁЄЁиДСИьЛњЮрЁйЁЪЬРМЃ2ЁЫЄЫЄЯЁжЪ§КЃдїБПРЙЅЫГЋЅБЁЄЪИВНЦќЅЫПЗЅПЅЪЅъЁЅОхЅпЅЯФЋФюЅЮРЏЮсЁЄЪ§ЧьЅЮЗМСеЅшЅъЁЄВМЅтЛдАцяуяхЅЮИРУЬЯРЕФЅЫЛъЅыЅоЅЧЁЄГЇТПЅЏЛЈЅцЅыЅЫДСИьЅђАЪЅЦЅЙЁзЄШЄЂЄыЁЅЁиВцГкТПФСЪѓЁйЁЪЬРМЃ14. 9. 30ЁЫЄЧЄЯЁжРИАеЕЄЄЪЧЅЯДСИьЄЧЬЕПДЄЄЄвЁзЄШЄоЄЧЄЂЄыЁЅЄГЄЮЄшЄІЄЫПЗДСИьЄЌЮЎЙдЄЗЄЦЄЄЄПЄшЄІЄРЄЌЁЄНюЬБЄЌЄЩЄЮФјХйЭ§ВђЄЗЄЦЄЄЄПЄЋЄЯЕПЬфЄЧЁЄЁжЅСЅѓЅзЅѓДСИьЁзЄШЄоЄЧИЦЄаЄьЄЦЄЄЄПЄлЄЩЄЧЄЂЄыЁЅ"inkhorn terms" ЄфЁжЅЋЅПЅЋЅЪИьЁзЄШЄЄЄІИЦОЮЄШШцГгЄЕЄьЄшЄІЁЅЄНЄЗЄЦЁЄДСИьЄђХ§ЙчЄЙЄыЛюЄпЄЮ1ЄФЄШЄЗЄЦЁЄДСИьЛњАњЄЌМЁЁЙЄШНаШЧЄЕЄьЄПЄГЄШЄтЁЄТОЄЮ2ЮуЄШЖУЄЏЄлЄЩЄшЄЏЛїЄЦЄЄЄыЁЅ
ЁЁИНТхЦќЫмИьЄЮЅЋЅПЅЋЅЪИьЬфТъЄђЕФЯРЄЙЄыЄЮЄЫЁЄ16РЄЕЊИхШОЄЮЅЄЅѓЅАЅщЅѓЅЩЄф19РЄЕЊИхШОЄЮЦќЫмЄЮИРИьЛіО№ЄђЛВОШЄЙЄыЄГЄШЄЯЁЄАеЬЃЄЮЄЂЄыЄГЄШЄРЄэЄІЁЅ
ЁЁЁІ Bragg, Melvyn. The Adventure of English. New York: Arcade, 2003.
ЁЁЁІ ЁиЦќЫмИьЩДВЪТчЛіХЕЁйЁЁЖтХФАь НеЩЇЄлЄЋ ЪдЁЄТчНЄДлЁЄ1988ЧЏЁЅ
2013-10-12 Sat
ЂЃ #1629. ЯТРНДСИь [japanese][kanji][waseieigo][lexicology]
ЁЁЁж#1624. ЯТРНБбИьЄЮАьЭїЁз ([2013-10-07-1]) ЄЧЯТРНБбИьЄЮАьЭїЄђЗЧЄВЄПЄЌЁЄКЃВѓЄЯЯТРНДСИьЄЮЮуЄђЮѓЕѓЄЗЄПЄЄЁЅБбУБИьЄЮМкЭбЄЫДЗЄьЄПЦќЫмИьЄЌТчРЕДќЄЫЯТРНБбИьЄђКюЄъНаЄЗЛЯЄсЄПЄшЄІЄЫЁЄЄНЄьЄЫЄтЄоЄЗЄЦФЙЄщЄЏЦќЫмИьЄЫЄЪЄИЄѓЄЧЄЄПДСИьЄЌЅтЅЧЅыЄШЄЪЄУЄЦЁЄПєЁЙЄЮЯТРНДСИьЄЌРИЄпНаЄЕЄьЄЦЄЄПЄГЄШЄЯЁЄЄоЄУЄПЄЏМЋСГЄЪЄГЄШЄЧЄЂЄыЁЅЯТРНБбИьЄЮОьЙчЄШЦБЭЭЄЫЁЄЄЂЄыДСИьЄЌЯТРНЄЧЄЂЄыЄЋШнЄЋЄђФъЄсЄыЄЫЄЯЦќЫмИьЄЊЄшЄгУцЙёИьЄЮСаЪ§ЄЫЄЊЄБЄыЪИИЅГиХЊЄЪЙЭОкЄЌЩЌЭзЄШЄЪЄъЁЄЄПЄфЄЙЄЄЬфТъЄЧЄЯЄЪЄЄЄЌЁЄИНТхУцЙёЄЮРьЬчВШЄЫЄшЄьЄаЁЄМЁЄЮДСИьЄЯЯТРНДСИьЄЧЄЂЄыВФЧНРЄЌЙтЄЄЄШЄЄЄІЁЪАЪВМЄЮЮуЄЯЄЙЄйЄЦЁиЦќЫмИьЩДВЪТчЛіХЕЁй pp. 1029--30 ЄшЄъЁЫЁЅ
ШїЩЪЁЄЛВДЧЁЄЛВОШЁЄРЎАјЁЄУўЛљЁЄУБНуЁЄХљГАЁЄХЈЛыЁЄЦЩЫмЁЄШжЙцЁЄЪ§ПЫЁЄЩїАЬЁЄЩўЬГЁЄЩќМАЁЄЩћПЉЁЄИјЮЉЁЄИјШНЁЄИјЧЇЁЄИјБФЁЄЙёЮЉЁЄНИУцЁЄНИЗыЁЄЕЙцЁЄРэЪМЁЄЗјЛ§ЁЄДЪУБЁЄЖтГлЁЄЕ№ОЂЁЄЕ№РБЁЄЙюЩўЁЄЯЋКюЁЄЭюСЊЁЄЬРГЮЁЄЦтЖаЁЄЧРКюЪЊЁЄИЂИТЁЄИЂБзЁЄПЭСЊЁЄЦљУЦЁЄМТРгЁЄМТИЂЁЄЛфЮЉЁЄСЪИЂЁЄТцМжЁЄЦУФЙЁЄГАЖаЁЄЙЛЗБЁЄЖНПЎНъЁЄГиВёЁЄГиЮђЁЄЗБЯУЁЄЗБЮсЁЄЖфЭуЁЄАѕДеЁЄИЖЦАЮЯЁЄИЖАеЁЄИЖКюЁЄПиЭЦЁЄЛйЩєЁЄНХХРЁЄМъЦАЁЄСШРЎЁЄКТУЬ
ЁЁЦќЫмЄЮЪИЪЊЄђЩНЄЙДСИьЄтЁЄЯТРНЄШЙЭЄЈЄЦЄшЄЄЄРЄэЄІЁЅЮуЄШЄЗЄЦЄЯЁЄЯТЩўЁЄЯТЪИЁЄПЭЮЯМжЁЄОєЮмЭўЁЄЧНГкЁЄЛАЬЃРўЁЄУуЦЛЁЄЕнЦЛЁЄНРЦЛЄЪЄЩЄЌЄЂЄыЁЅ
ЁЁЄоЄПЁЄАЪВМЄЮДСИьЄтЯТРНДСИьЄЮВФЧНРЄђЄтЄФЄЌЁЄЖсТхЦќЫмЄШУцЙёЄЮДжЄЧЄЮАмЦўЁІАмНаЄЮДиЗИЄЯЪЃЛЈЄЧЄЂЄъЁЄАьБўЄЮЅъЅЙЅШЄШЄЗЄЦЭ§ВђЄЗЄЦЄЊЄЄПЄЄЁЅЄГЄьЄщЄЮТПЄЏЄЯЁЄЖсТхДќЄЫЁЄБбИьЄЪЄЩЄђМшЄъЦўЄьЄыКнЄЫДСЬѕЄЗЄЦМшЄъЦўЄьЄПЄГЄШЄЫЭГЭшЄЙЄыЁЅ
АХМЈЁЄЧђЖтЁЄШОЗТЁЄЫАЯТЁЄЪнИБЁЄШсЗрЁЄЧиЗЪЁЄЫмМСЁЄШцНХЁЄЩЌЭзЁЄЩИИьЁЄЩНЗшЁЄЧШФЙЁЄЩдЦАЛКЁЄКтШЖЁЄСоЯУЁЄРЎЪЌЁЄОшЕвЁЄУъОнЁЄНаШЧЁЄПЈЧоЁЄТчЕЄЁЄТхЕФЛЮЁЄУБИЕЁЄУСЧђМСЁЄЦЛЖёЁЄХаЕЁЄФуФДЁЄФёЙГЁЄУЯМСЁЄХХЧШЁЄХХМжЁЄХХЯУЁЄХХЮЎЁЄХХЛвЁЄЦАЛКЁЄЦШРъЁЄТтОІЁЄТаОнЁЄТаОШЁЄЫЁПЭЁЄШПЦАЁЄШПДЖЁЄШПМЭЁЄШПБўЁЄШЯсЦЁЄЪ§ФјМАЁЄЪ§МАЁЄЪЗАЯЕЄЁЄШнФъЁЄЩэУхЁЄЪЃРНЁЄВўЪдЁЄВўФћЁЄГЕГчЁЄГЕЮЌЁЄГЕЧАЁЄДЖРЁЄДДЩєЁЄДДРўЁЄЙтФЌЁЄЙтЯЇЁЄВЮЗрЁЄЙЉЖШЁЄИјЪѓЁЄИјОЮЁЄИјЬБЁЄИјЫЭЁЄИјСЪЁЄЖІЛКМчЕСЁЄЖІЬФЁЄДиЗИЁЄДбТЌЁЄДбЧАЁЄИїЧЏЁЄИїРўЁЄЙЙ№ЁЄЙЕСЁЄЕЂЧМЁЄЙёКнЁЄЙёИЫЁЄЙёРЧЁЄДЈТгЁЄДЈЮЎЁЄЙвЖѕЪьДЯЁЄЙцГАЁЄВНЧПЁЄВНРаЁЄВНГиЁЄВНОбЩЪЁЄВшЯЁЄИИХєЁЄИИСлЖЪЁЄВѓМ§ЁЄВёЯУЁЄВёМвЁЄВёУЬЁЄГшЬіЁЄВаРЎДфЁЄРбЖЫЁЄД№ФДЁЄД№НрЁЄНИУФЁЄЗзВшЁЄЕЛЛеЁЄВОФъЁЄРэУМЁЄДжРмЁЄЗњУлЁЄДеФъЁЄЙжУХЁЄИђКнЁЄИђЖСГкЁЄчБУхИьЁЄЕгЫмЁЄЖЕВЪНёЁЄЖЕЭмЁЄЙкСЧЁЄРмЪЁЄЗыГЫЁЄВђЪќЁЄВђЫЖЁЄВ№ЦўЁЄЖтЙфРаЁЄЖтКЇМАЁЄЖтЧзЁЄЖтЭЛЁЄЖлФЅЁЄПЪХйЁЄПЪВНЁЄПЪВНЯРЁЄПЪХИЁЄЗаИГЁЄЗЪЕЄЁЄЗйЛЁЁЄЗйДБЁЄОєВНЁЄРХЬЎЁЄЖЅЕЛЁЄНЂЧЄЁЄЕ№ЦЌЁЄЗшЛЛЁЄРфТаЁЄДЧИюЩиЁЄДЧМщЁЄЙГЕФЁЄВЪГиЁЄВФЗшЁЄЕвДбЁЄЕвТЮЁЄЙЮФъЁЄЖѕДжЁЄВёЗзЁЄГШЛЖЁЄЮрЗПЁЄЮфТЂЁЄЮфТЂИЫЁЄЭ§ЯРЁЄЭ§ЧАЁЄЭ§СлЁЄЭ§УвЁЄЮЯГиЁЄЮЉЗћЁЄЮуВёЁЄЮЛВђЁЄЮЮГЄЁЄЮЮЖѕЁЄЮЮМчЁЄЮЮХкЁЄЯРЭ§ГиЁЄЬЁВшЁЄЬеНОЁЄЧоМСЁЄШўДЖЁЄЬЉХйЁЄЬШЕіЁЄЬБЫЁЁЄЩвДЖЁЄЬПТъЁЄЬлМЈЁЄЪьТЮЁЄЪьЙЛЁЄЬмЩИЁЄЬмХЊЁЄЦтЭЦЁЄЦтКпЁЄЧНЦАЁЄЧНЮЈЁЄЕМПЭЫЁЁЄЧЏХйЁЄУШЮЎЁЄЧЩИЏЁЄШНЗшЁЄЧцПГЁЄЧлЕыЁЄШуЩОЁЄЪПЬЬЁЄЩОВСЁЄДыЖШЁЄЕЄЪЌЁЄЕЄТЮЁЄЕЄМСЁЄЕЅСЅЁЄЕЅХЋЁЄЗРЕЁЁЄСАРўЁЄЖЏРЉЁЄЗкЙЉЖШЁЄРЖЖЕХЬЁЄРЖЛЛЁЄО№ЪѓЁЄИЂАвЁЄЧЎТгЁЄПЭГЪЁЄПЭИЂЁЄЧЄЬПЁЄЭЯТЮЁЄЦўОьЗєЁЄЦўФЖЁЄОІЫЁЁЄОІЖШЁЄМвИђЁЄПГШНЁЄОКВкЁЄРИЭ§ГиЁЄРИТжГиЁЄМКЮјЁЄЛмЙЉЁЄЛмЙдЁЄЛўДжЁЄМТДЖЁЄМТЖШЁЄЛШХЬЁЄЛЮДБЁЄРЄГІДбЁЄЛдОьЁЄЛдФЙЁЄЛіТжЁЄМъЙЉЖШЁЄМѕЦёЁЄПхСЧЁЄЛзФЌЁЄЛрГбЁЄСЧКрЁЄСЧЩСЁЄТЎХйЁЄТЎЕЁЄПяАїЁЄКїАњЁЄУЬШНЁЄУЕИБЁЄЦУИЂЁЄТЮАщЁЄХДЗьЁЄХ§ЗзЁЄХъБЦЁЄХъЛёЁЄПоАЦЁЄГАКпЁЄВЙОВЁЄВЙХйЁЄЪИИЫЁЄЪИГиЁЄЬЕЛКМдЁЄЪЊМСЁЄДюЗрЁЄЗЯЮѓЁЄЗИПєЁЄКйЫІЁЄЖЙЕСЁЄСЁАнЁЄИНМТЁЄИНОнЁЄИНЬђЁЄЗћЪМЁЄСъТаЁЄСлСќЁЄОнФЇЁЄОУЫЩЁЄОУШёЁЄОУЖЫЁЄОЎЬыЖЪЁЄИњВЬЁЄЖЈФъЁЄЖЈВёЁЄПДЭ§ГиЁЄПЎЙцЁЄПЎТїЁЄРЧНЁЄНјЫыЁЄНјЖЪЁЄРыРяЁЄРћШзЁЄГиАЬЁЄЗьРђЁЄЗьЕлУюЁЄНфЭЮДЯЁЄАЕБфЁЄАЁБєЁЄБщНаЁЄБщСеЁЄБэШјЩўЁЄЭлЖЫЁЄЭзСЧЁЄЖШЬГЁЄБеТЮЁЄЕФВёЁЄЕФАїЁЄЕФБЁЁЄАеЬѕЁЄАјЛвЁЄБЂЖЫЁЄЖфЙдЁЄЖфКЇМАЁЄБЩЭмЁЄБЦСќЁЄЭЅРИГиЁЄЬ§СхМжЁЄЭЗЮЅЁЄЭНИхЁЄИЕСЧЁЄБрЗнЁЄИЖЭ§ЁЄИЖТЇЁЄИЖЛвЁЄИЖКсЁЄБѓТЁЄБПЦАЁЄБПЦАОьЁЄЛЈЛяЁЄКФИЂЁЄКФЬГЁЄХИЭїВёЁЄРяРўЁЄХЏГиЁЄОкЗєЁЄРЏКіЁЄРЏХоЁЄЛйРўЁЄФОДбЁЄФОРмЁЄФОЗТЁЄФОЮЎЁЄЛпЭШЁЄЛиЩИЁЄЛиЦГЁЄЛиПєЁЄРЉКлЁЄРЉИТЁЄРЉЬѓЁЄМСЮЬЁЄНЊХРЁЄУчКлЁЄНХЙЉЖШЁЄМчЩЎЁЄМчДбЁЄЛёЮСЁЄЛчГАРўЁЄНЁЖЕЁЄСэЙчЁЄСэЦААїЁЄСэЭ§ЁЄКюЩЪ
ЁЁЯТРНБбИьЄЫЄЛЄшЯТРНДСИьЄЫЄЛЄшЁЄСъМъЄЮИРИьЄЋЄщЄЮФОРмЄЮИьзУМкЭбЄЫННЪЌЄЪЄИЄѓЄЧЄЏЄыЄШЁЄКЃХйЄЯЄНЄьЄђЅтЅЧЅыЄШЄЗЄЦМЋВШРНЄЮИьзУЄђРИЄпНаЄНЄІЄШЄЗЄЦЄЄПХРЄЌЛїЄЦЄЄЄыЁЅСъМъЄЮИРИьЄЫЦнЄоЄьЄЦЄЄЄыЄШЙЭЄЈЄьЄаИьзУМкЭбШПТаЯРЄШЄЪЄыЄЗЁЄСъМъЄЮИРИьЄђМъЄЪЄКЄБЄЦЄЄЄыЄШЙЭЄЈЄьЄаЛПРЎЯРЄШЄЪЄыЁЅЛфЄЯЁЄЯТРНЁћИьЄЮТИКпЄЯЦќЫмИьЄЌМкЭбИЕИРИьЄЮМъЄЪЄКЄБЄЫРЎИљЄЗЁЄЙтМЁЄЫПЪЄѓЄРМкЭбУЪГЌЄЫЄЂЄыЄГЄШЄђМЈЄЙЄтЄЮЄШЄЗЄЦВђМсЄЗЄЦЄЄЄыЁЅ
ЁЁЁІ ЁиЦќЫмИьЩДВЪТчЛіХЕЁйЁЁЖтХФАь НеЩЇЄлЄЋ ЪдЁЄТчНЄДлЁЄ1988ЧЏЁЅ
2013-10-07 Mon
ЂЃ #1624. ЯТРНБбИьЄЮАьЭї [waseieigo][japanese][katakana][borrowing][semantic_change][word_formation][lexicology][false_friend]
ЁЁ9Зю21--22ЦќЄЫЁЄТчЯЂТчГиЦќЫмИРИьЪИВНГиБЁЄЧГЋЄЋЄьЄПТшИоВѓЁиУцЁІЦќЁІДкЦќЫмИРИьЪИВНИІЕцЙёКнЅеЅЉЁМЅщЅрЁйЄЫЛВВУЄЗЁЄУцБћТчГиЄЮЦБЮНЄШЅСЁМЅрЄђСШЄѓЄЧЁжИРИьЛШЭбЄЮСАЗЪЄШЧиЗЪ---ИРИьИІЕцЄШЪИГиИІЕцЄЫЄФЄЄЄЦЁзЄШТъЄЙЄыЅбЅЭЅыЅЧЅЃЅЙЅЋЅУЅЗЅчЅѓЄђЙдЄУЄПЁЅЛфЄЯЁжЯТРНБбИьЄЮМЋСГЄЕЁІЩдМЋСГЄЕЁзЄШЄЄЄІТъЬмЄЧОЏЄЗЯУЄЗЄђЄЗЄПЁЅРьЬчГАЄЧЄЯЄЂЄыЄЌЁЄЦќЫмИьГиЄЫЄЊЄЄЄЦЯТРНБбИьЄфГАЭшИьЄЮИІЕцЄЯЁЄБбИьЄЮИІЕцМдЄЫЄшЄыЄтЄЮЄЌОЏЄЪЄЏЄЪЄЄЄШЄЄЄІЄГЄШЄЪЄЮЄЧЁЄЛфЄтЄНЄЮЮЉОьЄЋЄщЄяЄКЄЋЄаЄЋЄъЛВЭПЄЕЄЛЄЦЄЄЄПЄРЄЄЄПЁЄЄШЄЄЄІМЁТшЄЧЄЂЄыЁЅ
ЁЁЄГЄЮШЏЩНЄЮЄПЄсЄЫЁЄЕЛіЫіЄЫЕѓЄВЄПЄшЄІЄЪЛВЙЭПоНёХљЄЋЄщЯТРНБбИьЄШЄЄЄяЄьЄЦЄЄЄыЩНИНЄђМ§НИЄЗЄПЁЅЗыВЬЄШЄЗЄЦ231ИФЄЌНИЄоЄУЄПЁЅГЦЁЙЄЌЫмХіЄЫЯТРНБбИьЄЋШнЄЋЄШЄЄЄІЬфТъЄЫЄФЄЄЄЦЄЯЁЄЁж#1492. ЁжЅДЁМЅыЅЧЅѓЅІЅЃЁМЅЏЁзЄЯЯТРНБбИьЄЋЁЉЁз ([2013-05-28-1]) ЄЧПЈЄьЄПЄшЄІЄЫЁЄЫмЭшЁЄОмКйЄЪЪИИЅГиХЊФДККЄЌЩЌЭзЄРЄЌЁЄКЃВѓЄЯЄНЄГЄоЄЧЄЯЗЁЄъВМЄВЄЦЄЄЄЪЄЄЁЅЄоЄПЁЄЯТРНБбИьЄЮИЗЬЉЄЪФъЕСЄЌЦёЄЗЄЄЄШЄЄЄІЛіО№ЄтЄЂЄыЁЅЄЗЄПЄЌЄУЄЦЁЄАЪВМЄЮИФЁЙЄЮЮуЄЫЄФЄЄЄЦЄЯЕПЬфЄЌФшЄЕЄьЄыЄЋЄтЄЗЄьЄЪЄЄЄЌЁЄОхЕЄЮЄшЄІЄЪУЂЄЗНёЄЄђЄФЄБЄПЄІЄЈЄЧЁЄНИЄсЄПЄтЄЮЄђАьЭїЄШЄЗЄЦИјГЋЄЗЄЦЄЊЄЏЄГЄШЄЯЬђЄЫЮЉЄФЄРЄэЄІЁЅ
ЁЁЯТРНБбИьЄЮЪЌЮрЄЫЄФЄЄЄЦЄЯЁЄЄоЄРВОЄЮЄтЄЮЄЫЄЙЄЎЄЪЄЄЄЌЁЄАЪВМЄЮЄшЄІЄЫ (1) ЕЙцХЊЯТРНБбИьЁЄ(2) АеЬЃХЊЯТРНБбИьЁЄ(3) ЗСТжХЊЯТРНБбИьЄЫ3ЪЌЮрЄЗЄЦЄпЄПЁЅЪЌЮрЄЮРКхЬВНЄЯКЃИхЄЮВнТъЄШЄЗЄПЄЄЁЅ

(1) ЕЙцХЊЯТРНБбИь
ЁЁЅЂЅЄЅЙЅЅуЅѓЅЧЅЃЁМ (popsicle)ЁЄЅЂЅЄЅЩЅъЅѓЅАЅЙЅШЅУЅз (shutting off the engines)ЁЄЅЂЅІЅШЅГЁМЅЙ (outside)ЁЄЅЂЅбЁМЅШ (apartment, apartmenthouse)ЁЄЅЂЅеЅПЁМЅБЅЂЁПЅЂЅеЅПЁМЅЕЁМЅгЅЙ (after-sales service, after-the-sale service)ЁЄЅЂЅеЅьЅГ (post recording)ЁЄЅЂЅсЅъЅЋЅѓЁЪЅГЁМЅвЁМЁЫ ((regular) coffee)ЁЄЅЄЅсЁМЅИЅЂЅУЅз (improve one's image)ЁЄЅЄЅсЁМЅИЅСЅЇЅѓЅИ (change one's image)ЁЄЅІЅЇЅЙЅШЅаЅУЅА (fanny bag, bum bag)ЁЄЅЈЅЙЅЦ (beauty salon, beauty spa, beauty-treatment clinic)ЁЄЅЈЅУЅС (dirty-minded, sex-mad, have a one-track mind, indecent, salacious, pervert, abnormal)ЁЄЅЊЁМЅЈЅыЁЪЅЊЅеЅЃЅЙЅьЅЧЅЃЁЫ (office worker)ЁЄЅЊЁМЅРЁМЅсЁМЅЩ (custom-made, made-to-order)ЁЄЅЊЁМЅШЅаЅЄ (motorbike, motorcycle)ЁЄЅЊЁМЅгЁМ (alumnus, alumna, graduate)ЁЄЅЊЁМЅжЅѓЅШЁМЅЙЅПЁМ (toaster oven)ЁЄЅЊЁМЅзЅѓЅЋЁМ (convertible)ЁЄЅЊЁМЅыЅаЅУЅЏ (combed (straight) back, combed towards the back)ЁЄЅЋЅеЅЙЅмЅПЅѓ (cuff links)ЁЄЅЌЁМЅЩ (overpass)ЁЄЅЌЁМЅЩЅоЅѓ ((security) guard, watchman)ЁЄЅЌЅНЅъЅѓЅЙЅПЅѓЅЩ (gas station)ЁЄЅЌЅУЅФЅнЁМЅК (victory pose)ЁЄЅЅУЅСЅѓЅкЁМЅбЁМ (paper towel)ЁЄЅЅуЅУЅСЅГЅдЁМ (slogan)ЁЄЅЅуЅУЅСЅлЅѓ (call-waiting)ЁЄЅЅуЅУЅСЅмЁМЅы (play catch)ЁЄЅЏЁМЅщЁМ (air conditioner)ЁЄЅАЅщЅгЅЂ (glamour photos, cheesecake, Page Threes)ЁЄЅАЅьЁМЅЩЅЂЅУЅз (upgrade)ЁЄЅВЁМЅрЅЛЅѓЅПЁМ (amusement arcade)ЁЄЅГЅЄЅѓЅщЅѓЅЩЅъЁМ (launderette)ЁЄЅГЅЙЅШЅРЅІЅѓ (lower costs, reduce costs)ЁЄЅГЅѓЅЛЅѓЅШ (outlet, outlet box, receptacle, wall outlet, wall socket)ЁЄЅГЅѓЅгЅЫ (drugstore, grocery)ЁЄЅДЁМЅыЅЧЅѓЅЂЅяЁМ (prime time)ЁЄЅДЁМЅыЅЧЅѓЅІЅЃЁМЅЏ (holidays in May)ЁЄЅЕЅЄЅЩЅгЅИЅЭЅЙ (side job)ЁЄЅЕЅщЅъЁМЅоЅѓ (company employee)ЁЄЅЗЁМЅКЅѓЅЊЅе (off-season)ЁЄЅЗЁМЅСЅЅѓ (canned tuna)ЁЄЅЗЅЇЅЄЅзЅЂЅУЅз (become thin, lose weight)ЁЄЅЗЅЙЅЦЅрЅЅУЅСЅѓ (organized kitchen)ЁЄЅЗЅЦЅЃЅлЅЦЅы (big hotel)ЁЄЅЗЅуЁМЅкЅѓ (mechanical pencil, automatic pencil)ЁЄЅЗЅуЅУЅПЁМЅСЅуЅѓЅЙ (the right moment on film)ЁЄЅЗЅыЅаЁМЅІЅЃЁМЅЏ (holidays in November)ЁЄЅЗЅыЅаЁМЅЗЁМЅШ (priority seat)ЁЄЅИЁМЅИЅуЅѓ (denim jacket, jeans jacket)ЁЄЅИЁМЅбЅѓ (jeans)ЁЄЅИЅЇЅУЅШЅГЁМЅЙЅПЁМ (roller coaster)ЁЄЅИЅхЁМЅЕЁМ (blender)ЁЄЅЙЁМЅбЁМ (supermarket)ЁЄЅЙЅЅѓЅЗЅУЅз (touching, bonding, physical contact)ЁЄЅЙЅЏЁМЅыЅЋЅщЁМ (the traditional feature of a school)ЁЄЅЙЅБЁМЅыЅсЅъЅУЅШ (economies of scale)ЁЄЅЙЅПЅсЅѓ (starting lineup)ЁЄЅЙЅПЅѓЅЩЅзЅьЁМ (grandstand play)ЁЄЅЙЅдЁМЅЩЅРЅІЅѓ (slow down)ЁЄЅЙЅъЁМЅЕЅЄЅК ((bust-waist-hip) measurement)ЁЄЅМЅЭЅГЅѓ (big construction company, large construction company)ЁЄЅНЁМЅщЁМЅЗЅЙЅЦЅр (solar power)ЁЄЅНЅеЅШ (software)ЁЄЅНЅеЅШЅЏЅъЁМЅр (soft-serve ice cream, ice cream cone, swirl ice-cream cone)ЁЄЅПЁМЅпЅЪЅыЅлЅЦЅы (station hotel)ЁЄЅПЅЄЅрЅЕЁМЅгЅЙ (blue-light special, limited time offer (special))ЁЄЅПЅЄЅрЅъЁМЅвЅУЅШ (RBI hit)ЁЄЅПЅУЅСЅЂЅІЅШ (tagged and out)ЁЄЅРЅЄЅЫЅѓЅАЅЅУЅСЅѓ (kitchenette)ЁЄЅРЅѓЅзЅЋЁМ (dump truck)ЁЄЅСЅЂЅЌЁМЅы (cheerleader a)ЁЄЅСЅуЅѓЅЙЅсЁМЅЋЁМ (table setters)ЁЄЅЦЁМЅжЅыЅЙЅдЁМЅС (speech at a party)ЁЄЅЦЅьЅгЅВЁМЅр (video game)ЁЄЅЦЅѓЅЁМ (numeric keypad)ЁЄЅЧЅГЅьЁМЅЗЅчЅѓЅБЁМЅ (birthday cake, decorated cake)ЁЄЅЧЅУЅЩЅмЁМЅы (hit by (a) pitch)ЁЄЅЧЅъЅаЅъЁМЅиЅыЅЙ (massage parlor)ЁЄЅШЅьЁМЅЫЅѓЅАЅбЅѓЅФЁЪЅШЅьЅбЅѓЁЫ (sweat pants)ЁЄЅЩЅЏЅПЁМЅЙЅШЅУЅз (doctor's orders)ЁЄЅЩЅщЅЄЅжЅЄЅѓ (rest area, rest stop)ЁЄЅЪЅЄЅПЁМ (night game)ЁЄЅЫЅхЁМЅЯЁМЅе (drag queen, transvestite)ЁЄЅЭЅЄЅЦЅЃЅєЅСЅЇЅУЅЋЁМ (proof reader, native-speaking proof reader)ЁЄЅЭЅУЅШЅЗЅчЅУЅдЅѓЅА (on-line shopping)ЁЄЅЮЁМЅЋЅУЅШ (uncut (movie))ЁЄЅЮЁМЅЙЅъЁМЅж (sleeveless dress)ЁЄЅЮЁМЅПЅЄЁЪЅЮЁМЅЭЅЏЅПЅЄЁЫ (without a tie)ЁЄЅЮЁМЅШЅбЅНЅГЅѓ (laptop)ЁЄЅЮЅѓЅЙЅЦЅУЅзЅаЅЙ (bus without steps)ЁЄЅЮЅѓЅЛЅЏЅЗЅчЅѓ (trivia)ЁЄЅЯЁМЅШЅеЅы (heartwarming)ЁЄЅЯЁМЅе (someone of mixed race)ЁЄЅЯЅЄЅНЅУЅЏЅЙ (knee socks)ЁЄЅЯЅЄЅЦЅЃЁМЅѓ (late teens)ЁЄЅЯЅЄЅЦЅѓЅЗЅчЅѓ (excitable, overexcited, carried away)ЁЄЅЯЅэЁМЅяЁМЅЏ (Job Centre)ЁЄЅаЅУЅЏЅпЅщЁМ (rearview mirror)ЁЄЅаЅШЅѓЅЌЁМЅы (baton twirler)ЁЄЅаЅШЅѓЅПЅУЅС (baton pass, hand over)ЁЄЅбЅПЅѓЅЪЁМ (pattern maker)ЁЄЅбЅШЅЋЁМ (police car)ЁЄЅбЅЭЅщЁМ (panelist)ЁЄЅбЅѓЅСЅбЁМЅо (tight-perm, short-perm)ЁЄЅгЁМЅСЅбЅщЅНЅы (beach umbrella)ЁЄЅгЅИЅЭЅЙЅлЅЦЅы (economy hotel, budget hotel)ЁЄЅеЅЃЁМЅыЅЩЅЂЅЙЅьЅСЅУЅЏ (obstacle course)ЁЄЅеЅЉЅЂЅмЁМЅы (base on balls, walk)ЁЄЅеЅщЅЄЅЩЅнЅЦЅШ (French fries, chips)ЁЄЅеЅщЅЄЅѓЅА (false start)ЁЄЅеЅъЁМЅЕЅЄЅК (one-size-fits-all)ЁЄЅеЅъЁМЅРЅЄЅфЅы (toll-free number)ЁЄЅеЅэЅѓЅШЅЌЅщЅЙ (windshield)ЁЄЅжЅУЅЏЅЋЅаЁМ (book jacket, dust jacket)ЁЄЅзЅьЁМЅЌЅЄЅЩ (booking office)ЁЄЅиЅЂЅЬЁМЅЩ (full-frontal nudity (photo))ЁЄЅиЅЧЅЃЅѓЅАЅЗЅхЁМЅШ (header)ЁЄЅиЅыЅЙЅсЁМЅПЁМ (bathroom scale)ЁЄЅйЁМЅЙЅЂЅУЅз (raise of the wage base)ЁЄЅйЅУЅЩЅПЅІЅѓ (bedroom suburb)ЁЄЅйЅгЁМЅЕЁМЅЏЅы (playpen)ЁЄЅкЁМЅбЁМЅЋЅѓЅбЅЫЁМ (shell company)ЁЄЅкЁМЅбЁМЅЩЅщЅЄЅаЁМ (person with a driving licence but no practice, driver in name only)ЁЄЅкЅЂЅыЅУЅЏ (dressed in matching outfits)ЁЄЅкЅУЅШЅмЅШЅы (plastic bottle)ЁЄЅлЁМЅр (platform)ЁЄЅлЅУЅШЅЋЁМЅкЅУЅШ (electric carpet)ЁЄЅлЅУЅШЅБЁМЅ (pancake)ЁЄЅмЅЧЅЃЅСЅЇЅУЅЏ (frisk, security check, body search)ЁЄЅоЅЄЅЋЁМ (one's own car)ЁЄЅоЅЄЅЪЅЙЅЄЅсЁМЅИ (negative image)ЁЄЅоЅЄЅкЁМЅЙ (go one's own way)ЁЄЅоЅЋЅэЅЫЅІЅЇЅЙЅПЅѓ (spaghetti Western)ЁЄЅоЅАЅЋЅУЅз (mug)ЁЄЅоЅЖЅГЅѓ (mummy's boy)ЁЄЅоЅѓЅФЁМЅоЅѓ (one-on-one (one-to-one) lesson, private lesson)ЁЄЅпЅЗЅѓ (sewing machine)ЁЄЅпЅЫЅГЅп (free paper)ЁЄЅпЅыЅЏЅЦЅЃЁМ (tea with milk)ЁЄЅсЅПЅм (big, overweight, fat)ЁЄЅтЁМЅЫЅѓЅАЅГЁМЅы (wake-up call)ЁЄЅтЁМЅЫЅѓЅАЅЕЁМЅгЅЙ (breakfast special)ЁЄЅщЅЄЅжЅЯЅІЅЙ (club with live music, live music club)ЁЄЅщЅжЅлЅЦЅы (hot-pillow hotel, no-tell motel)ЁЄЅщЅѓЅЫЅѓЅАЅЗЅуЅФ (undershirt)ЁЄЅщЅѓЅЫЅѓЅАЅлЁМЅрЅщЅѓ (inside-the-park home run)ЁЄЅъЅЏЅыЁМЅШЅЙЁМЅФ (suit for an interview)ЁЄЅъЅЕЅЄЅыЅЏЅыЅЗЅчЅУЅз (secondhand shop, recycled-goods shop)ЁЄЅъЅУЅзЅЏЅъЁМЅр (lip balm, chapstick)ЁЄЅъЅеЅЦЅЃЅѓЅА (keepy-uppy)ЁЄЅыЁМЅКЅНЅУЅЏЅЙ (loose-fitting socks)ЁЄЅэЁМЅЦЅЃЁМЅѓ (early teens)ЁЄЅэЅЙЅПЅЄЅр (additional time, injury time, stoppage time)ЁЄЅяЅЄЅЗЅуЅФ (business shirt)ЁЄЅяЅЄЅЩЅЗЅчЁМ (talk and variety (TV) show, tabloid show, TV magazine show)ЁЄЅяЅѓЅбЅПЁМЅѓ (predictable, routine)
(2) АеЬЃХЊЯТРНБбИь
ЁЁЅЂЅЄЅЩЅы (pop idol)ЁЄЅЂЅУЅШЅлЁМЅр (cozy, homey)ЁЄЅЂЅаЅІЅШ (irresponsible)ЁЄЁЪЅЄЅйЅѓЅШЁЫЅГЅѓЅбЅЫЅЊЅѓ (booth girl, promotional model, trade show model)ЁЄЅЋЅѓЅЫЅѓЅА (cheating)ЁЄЅЏЅщЅЏЅЗЅчЅѓ (car horn)ЁЄЅЏЅьЁМЅр (complaint)ЁЄЅЕЅЄЅѓ (autograph, signature)ЁЄЅЗЁМЅы (sticker)ЁЄЅЙЅПЅѓЅЩ (grandstand)ЁЄЅЙЅЪЅУЅЏ (bar, pub)ЁЄЅЙЅоЁМЅШ (slender, slim)ЁЄЅЛЅѓЅЙЁЪЩўСѕЁЫ (good dress sense, well-dressed, stylish)ЁЄЅНЁМЅзЁЪЩїТЏЁЫ (bordello, house of ill repute, whorehouse, knocking shop)ЁЄЅПЅьЅѓЅШ (celebrity, entertainer, TV personality)ЁЄЅРЅУЅСЅяЅЄЅе (blow-up doll)ЁЄЅСЅуЅУЅЏ (zipper, zip-fastener)ЁЄЅШЅщЅѓЅз ((playing) cards)ЁЄЅЩЅщЅЄ (businesslike)ЁЄЅЩЅщЅЄЅаЁМЁЪЙЉЖёЁЫ (screwdriver)ЁЄЅЪЅЄЁМЅж (uncorrupted, unspoiled)ЁЄЅЭЅУЅЏ (weak link, dead wood, disadvantage, burden)ЁЄЅЯЅѓЅЩЅы ((steering) wheel)ЁЄЅаЁМЅГЁМЅЩЁЪШБЗПЁЫ (Bobby Charlton)ЁЄЅаЅЄЅЅѓЅА (buffet)ЁЄЅбЅяЁМЅЂЅУЅз (build)ЁЄЅеЅЁЅЄЅШ (Go for it, Do your best)ЁЄЅеЅэЅѓЅШ (front desk, reception)ЁЄЅжЁМЅр (fad)ЁЄЅзЅъЅѓЅШ (handout, printout)ЁЄЅзЅэЅЧЅхЁМЅЕЁМ (coordinator)ЁЄЅоЅИЅУЅЏ (felt tip pen, marker pen)ЁЄЅоЅѓЅЗЅчЅѓ (condominium, apartment)ЁЄЅсЅъЅУЅШЁПЅЧЅсЅъЅУЅШ (pros and cons, advantages and disadvantages)ЁЄЅтЅЫЅПЁМ (test user, product tester)ЁЄЅфЅѓЅЁМ (good-for-nothings, layabouts, hooligans, thugs)ЁЄЅъЅеЅЉЁМЅр (alteration, refurbish, renovate)ЁЄЅъЅйЅѓЅИ (rematch)ЁЄЅыЁМЅК (lax, careless, negligent, irresponsible)
(3) ЗСТжХЊЯТРНБбИь
ЁЁЅЂЅЄЅэЅѓ (flat iron)ЁЄЅЂЅЏЅЛЅы (accelerator)ЁЄЅЂЅзЅъ (application)ЁЄЅЂЅнЁПЅЂЅнЅЄЅѓЅШ (appointment)ЁЄЅІЅЄЅыЅЙ (virus)ЁЄЅЈЅѓЅЙЅШ (engine stall)ЁЄЅЊЅѓЅЖЅэЅУЅЏ (on the rocks)ЁЄЅЋЅьЁМЅщЅЄЅЙ (curry and rice, curry with rice)ЁЄЅГЁМЅѓЅгЁМЅе (corned beef)ЁЄЅГЅЭ (connection)ЁЄЅЕЅѓЅЊЅЄЅы (suntan oil)ЁЄЅЙЅтЁМЅЏЅЯЅр (smoked ham)ЁЄЅЛЅЏЅЯЅщ (sexual harassment)ЁЄЅЛЅУЅШЅэЁМЅЗЅчЅѓ (setting lotion)ЁЄЅЧЅбЁМЅШ (department store)ЁЄЅШЅЄЅь (bathroom, restroom)ЁЄЅЩЅѓЅоЅЄ (Don't worry about it, Never mind)ЁЄЅЫЅЙ (varnish)ЁЄЅЭЁМЅжЅы (navel orange)ЁЄЅЮЁМЅШ (notebook)ЁЄЅЮЅѓЅзЅэ (nonprofessional)ЁЄЅбЁМЅо (permanent)ЁЄЅбЅНЅГЅѓ (personal computer)ЁЄЅбЅѓЅЏ (flat tyre, puncture)ЁЄЅгЅПЅпЅѓ (vitamin)ЁЄЅгЅы (building)ЁЄЅеЅЁЅѓЅПЅИЅУЅЏ (fantastic)ЁЄЅзЅъЅѓ (pudding, custard pudding)ЁЄЅзЅэЅьЅЙЅщЁМ (professional wrestler)ЁЄЅоЅЄЅЏ (microphone)ЁЄЅоЅЙЅГЅп (mass communication, mass media, the media)ЁЄЅоЅЫЅЂ (maniac, fan)ЁЄЅъЅЙЅШЅЂЅУЅз (list)ЁЄЅъЅЙЅШЅщ (restructuring, corporate downsizing)ЁЄЅьЅИ (cash register)
ЁЁЁІ ЅЙЅЦЅЃЁМЅжЅѓЁІЅІЅЉЅыЅЗЅхЁЁЁиУбЄКЄЋЄЗЄЄЯТРНБбИьЁйЁЁС№ЛзМвЁЄ2005ЧЏЁЅ
ЁЁЁІ ЖЭРИ ЄъЄЋЁЁЁиЅЋЅПЅЋЅЪИьЁІГАЭшИьЛіХЕЁйЁЁМЎЪИМвЁЄ2006ЧЏЁЅ
ЁЁЁІ ЁиПЗШЧЦќЫмИьЖЕАщЛіХЕЁйЁЁЦќЫмИьЖЕАщГиВё ЪдЁЄТчНЄДлНёХЙЁЄ2005ЧЏЁЅ
ЁЁЁІ ЅЧЅЄЅгЅУЅЩЁІЅЛЅЄЅѓЁЁЁиЦќЫмПЭЄЌЄФЄЄДжАуЄЈЄыNGЅЋЅПЅЋЅЪБбИьЁйЁЁМчЩиЄШРИГшМвЁЄ2012ЧЏЁЅ
ЁЁЁІ ЁиЦќЫмИьГиИІЕцЛіХЕЁйЁЁШєХФ ЮЩЪИЄлЄЋ ЪдЁЄЬРМЃНёБЁЁЄ2007ЧЏЁЅ
ЁЁЁІ ЁиЦќЫмИьЩДВЪТчЛіХЕЁйЁЁЖтХФАь НеЩЇЄлЄЋ ЪдЁЄТчНЄДлЁЄ1988ЧЏЁЅ
ЁЁЁІ ТМРа ЭјЩзЁЁЁиЅЋЅПЅЋЅЪИьЄЊЄтЄЗЄэМХЕЁйЁЁЄЕЁІЄЈЁІЄщНёЫМЁЄ1990ЧЏЁЅ
ЁЁЁІ ЛГИ§ Э§ЁЁЁиЙёИьЄЊЄтЄЗЄэШЏИЋЅЏЅщЅжЁЁГАЭшИьЁІЯТРНБбИьЁйЁЁ2012ЧЏЁЅ
Powered by WinChalow1.0rc4 based on chalow