2021-05-14 Fri
■ #4400. 「犬猫」と cats and dogs の順序問題 [sound_symbolism][phonaesthesia][onomatopoeia][idiom][binomial][prosody][alliteration][phonetics][vowel][khelf_hel_intro_2021][clmet][coca][coha][bnc][sobokunagimon]
目下開催中の「英語史導入企画2021」より今日紹介するコンテンツは,学部生よりアップされた「犬猿ならぬ犬猫の仲!?」です.日本語ではひどく仲の悪いことを「犬猿の仲」と表現し,決して「犬猫の仲」とは言わないわけですが,英語では予想通り(?) cats and dogs だという興味深い話題です.They fight like cats and dogs. のように用いるほか,喧嘩ばかりして暮らしていることを to lead a cat-and-dog life などとも表現します.よく知られた「土砂降り」のイディオムも「#493. It's raining cats and dogs.」 ([2010-09-02-1]) の如くです.
これはこれとして動物に関する文化の日英差としておもしろい話題ですが,気になったのは英語 cats and dogs の語順の問題です.日本語では「犬猫」だけれど,上記の英語のイディオム表現としては「猫犬」の順序になっています.これはなぜなのでしょうか.
1つ考えられるのは,音韻上の要因です.2つの要素が結びつけられ対句として機能する場合に,音韻的に特定の順序が好まれる傾向があります.この音韻上の要因には様々なものがありますが,大雑把にいえば音節の軽いものが先に来て,重いものが後に来るというのが原則です.もう少し正確にいえば,音節の "openness and sonorousness" の低いものが先に来て,高いものが後にくるという順序です.イメージとしては,近・小・軽から遠・大・重への流れとしてとらえられます.音が喚起するイメージは,音象徴 (sound_symbolism) あるいは音感覚性 (phonaesthesia) と呼ばれますが,これが2要素の配置順序に関与していると考えられます.
母音について考えてみましょう.典型的には高母音から低母音へという順序になります.「#1139. 2項イディオムの順序を決める音声的な条件 (2)」 ([2012-06-09-1]) で示したように flimflam, tick-tock, rick-rack, shilly-shally, mishmash, fiddle-faddle, riffraff, seesaw, knickknack などの例が挙がってきます.「#1191. Pronunciation Search」 ([2012-07-31-1]) で ^([BCDFGHJKLMNPQRSTVWXYZ]\S*) [AEIOU]\S* ([BCDFGHJKLMNPQRSTVWXYZ]\S*) \1 [AEIOU]\S* \2$ として検索してみると,ほかにも chit-chat, kit-cat, pingpong, shipshape, zigzag などが拾えます.ding-dong, ticktack も思いつきますね.擬音語・擬態語 (onomatopoeia) が多いようです.
では,これを cats and dogs の問題に適用するとどうなるでしょうか.両者の母音は /æ/ と /ɔ/ で,いずれも低めの母音という点で大差ありません.その場合には,今度は舌の「前後」という対立が効いてくるのではないかと疑っています.前から後ろへという流れです.前母音 /æ/ を含む cats が先で,後母音 /ɔ/ を含む dogs が後というわけです.しかし,この説を支持する強い証拠は今のところ手にしていません.参考までに「#242. phonaesthesia と 遠近大小」 ([2009-12-25-1]) と「#243. phonaesthesia と 現在・過去」 ([2009-12-26-1]) をご一読ください.対句ではありませんが,動詞の現在形と過去形で catch/caught, hang/hung, stand/stood などに舌の前後の対立が窺えます.
さて,そもそも cats and dogs の順序がデフォルトであるかのような前提で議論を進めてきましたが,これは本当なのでしょうか.先に「英語のイディオム表現としては」と述べたのですが,実は純粋に「犬と猫」を表現する場合には dogs and cats もよく使われているのです.英米の代表的なコーパス BNCweb と COCA で単純検索してみたところ,いずれのコーパスにおいても dogs and cats のほうがむしろ優勢のようです.ということは,今回の順序問題は,真の問題ではなく見せかけの問題にすぎなかったのでしょうか.
そうでもないだろうと思っています.18--19世紀の後期近代英語のコーパス CLMET3.0 で調べてみると,cats and dogs が18例,dogs and cats が8例と出ました.もしかすると,もともと歴史的には cats and dogs が優勢だったところに,20世紀以降,最近になって dogs and cats が何らかの理由で追い上げてきたという可能性があります.実際,アメリカ英語の歴史コーパス COHA でざっと確認した限り,そのような気配が濃厚なのです.
「犬猫」か「猫犬」か.単なる順序の問題ですが,英語史的には奥が深そうです.
2021-01-08 Fri
■ #4274. 英語の学習・教育にも英語史・英語学の研究にもコーパスやオンラインツールを [corpus][coca][dictionary][methodology][elt]
先月出版された今井著『英語独習法』が広く読まれているようだ.認知科学に基づく効果的な英語学習の指南書である.私も読了したところだが,目を引いたのは「第5章 コーパスによる英語スキーマ探索法 基本篇」と「第6章 コーパスによる英語スキーマ探索法 上級篇」である.そこでは,学習者に求められるのは受け身の学習ではなくコーパスを利用した能動的な学習であると説かれ,具体的なオンラインコーパスの利用法が伝授される.ターゲットとなる単語についてコーパスが与えてくれる頻度,共起,例文,関連語などの情報をもとに,その単語に関するスキーマを自ら習得していくことが大事である,という趣旨だ.そこで挙げられているコーパスを含めたオンラインツールのうち,無料で利用できるものを挙げておきたい(今井,259--60).
・ Weblio 英和・和英辞典
・ Cambridge English Dictionary
・ SkELL (= Sketch Engine for Language Learning)
・ COCA (= Corpus of Contemporary American English)
・ WordNet: A Lexical Database for English
本書の5,6章のほか「探究実践篇」と題する50ページを超える部分では,英語学習のみならず英語学の研究テーマとなり得る種類の話題がいくつか取り上げられており,英語学・英語史を専攻する大学生にとっても有用である.コーパスを利用した研究のヒントとなるだろう.
本書を貫くキーワード「スキーマ」は「氷山の水面下の知識」とも言い換えられている.英語の単語や表現を真に習得するためには,それを取り巻く百科辞典的な知識たる「スキーマ」を習得することが必要である.英語の単語や表現の習得のためには,確かに必要である.
(ここからは我田引水にて失礼.)一方,英語という言語を理解するためには,英語のスキーマを理解しておく必要がある.英語を取り巻く社会言語学的な環境であるとか,英語を英語たらしめてきた歴史(=英語史)に関する知識である.これは氷山の水面下にある百科辞典的な知識であり,自然には身につけることができない.やはり能動的に学んでいく必要がある.
本書を読み,英語史は「英語のスキーマ」「英語という氷山の表面化の知識」の一部を構成するものだったのだな,と気づいた次第.
・ 今井 むつみ 『英語独習法』 岩波書店〈岩波新書〉,2020年.
2020-12-17 Thu
■ #4252. COCA と BNCweb でみる color vs colour [coca][bnc][corpus][ame_bre][spelling]
アメリカ式綴字 color とイギリス式綴字 colour をめぐる問題について,本ブログでは何度も取り上げてきた.綴字の米英差の代表例としてよく知られており,分かりやすい問題であるということもあるが,英語史的には意外と深掘りできる魅力的な問題だからでもある.
しかし,最も基本的な事実確認 --- 現代のアメリカ英語とイギリス英語で color と colour の各々の分布はどうなっているのかの調査 --- を行なわずいたことに気づいた.ということで,今回は現代アメリカ英語の代表的コーパス COCA と,イギリス英語の BNCweb で調べてみることにした.colo(u)r の屈折形,派生語,複合語を含めて網羅的に行なうのが理想だが,今回はレンマ検索を利用して,colo(u)r, colo(u)rs, colo(u)red (以上は屈折形として), colo(u)rful, colo(u)rless, discolo(u)r の6種類の語形の取り出しにとどめた.
| COCA による <color> と <colour> の頻度 | |||
| 語形 | <or> | <our> | <or> 比率 |
| COLOR | 124,778 | 4,792 | 0.9630 |
| COLORS | 33,225 | 1,886 | 0.9463 |
| COLORED | 5,553 | 179 | 0.9688 |
| COLORFUL | 10,871 | 412 | 0.9635 |
| COLORLESS | 1,000 | 57 | 0.9461 |
| DISCOLOR | 110 | 0 | 1.0000 |
| BNCweb による <color> と <colour> の頻度 | |||
| 語形 | <or> | <our> | <our> 比率 |
| COLOR | 115 | 11,332 | 0.9900 |
| COLORS | 24 | 4,396 | 0.9946 |
| COLORED | 14 | 2,432 | 0.9943 |
| COLORFUL | 6 | 1,093 | 0.9945 |
| COLORLESS | 4 | 166 | 0.9765 |
| DISCOLOR | 1 | 19 | 0.9500 |
COCA を用いたアメリカ英語の調査によれば,アメリカ式の <or> が,予想通りに圧倒的な95%前後の比率で用いられている.しかし,逆にいえば,5%ほどはイギリス式とされる <our> が用いられているというのも,とりわけ次のイギリス英語の状況と比較すると興味深い.
BNCweb を用いたイギリス英語の調査結果をみてみると,99%ほどというほぼ完全な比率でイギリス式の <our> が用いられている.アメリカ綴字を用いている少数の例を確認してみると,引用符に囲まれた短いタイトルらしきもの(アメリカ系由来の可能性があるもの)のなかで用いられているのが散見され,それを差し引いて考えることが許されるのであれば,さらに <our> は100%に近づく.この点では,イギリス英語のほうが綴字慣習についてより一貫しており,アメリカ英語は若干の寛容さを示すといえるかもしれない.
以上,標題の米英差の問題について事実確認した.
[ 固定リンク | 印刷用ページ ]
2020-10-27 Tue
■ #4201. 手紙の書き出しの Dear my friend [vocative][pragmatics][adjective][interjection][syntax][word_order][pragmatic_marker][coca]
最近,大学院生の指摘にハッとさせられることが多く,たいへん感謝している.標記の話題も一種の定型文句とみなしており,とりたてて分析的に考えたこともなかったが,指摘を受けて「確かに」と感心した.dear は「親愛なる」を意味する一般の形容詞であるから,my dear friend ならよく分かる.しかし,手紙の冒頭の挨拶 (salutation) などでは,統語的に破格ともいえる Dear my friend が散見される.Dear Mr. Smith なども語順としてどうなのだろうか.
共時的な感覚としては,冒頭の挨拶 Dear は純然たる形容詞というよりは,挨拶のための間投詞 (interjection) に近いものであり,語用標識 (pragmatic_marker) といってよいものかもしれない.つまり,正規の my dear friend と,破格の Dear my friend を比べても仕方ないのではないか,ということかもしれない.CGEL (775) でも,以下のように挨拶を導入するマーカーとみなして済ませている.
It is conventional to place a salutation above the body of the letter. The salutation, which is on a line of its own, is generally introduced by Dear;
Dear Ruth Dear Dr Brown Dear Madam Dear Sir
しかし,通時的にみれば疑問がいろいろと湧いてくる.Dear my friend のような語順が初めて現われたのはいつなのだろうか? その語用標識化の過程はいかなるものだったのだろうか? 近代英語では Dear my lord や Dear my lady の例が多いようだが,これは milord, milady の語彙化とも関わりがあるに違いない,等々.
ただし,現代英語の状況について一言述べておけば,COCA で検索してみた限り,実は「dear my 名詞」の例は決して多くない.歴史的にもいろいろな観点から迫れる,おもしろいテーマである(←Kさん,ありがとう!).
・ Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech, and Jan Svartvik. A Comprehensive Grammar of the English Language. London: Longman, 1985.
2020-05-15 Fri
■ #4036. stay at home か stay home か --- コーパス調査 [sobokunagimon][phraseology][preposition][bnc][coca][coha][clmet][ame_bre]
昨日の記事 ([2020-05-14-1]) で,目下世界のキーフレーズとなっている stay at home と stay home について英語史の観点から考察した.今回はいくつかのコーパスでざっと調査した結果を報告する.以下,細かい文脈調査や統計処理はしていないのであしからず.
まずは現代のイギリス英語とアメリカ英語について,それぞれ BNCweb と COCA (Corpus of Contemporary American English) から stay (at) home をレンマ検索で拾い出してみた.結果は,イギリス英語では stay at home が86.9%で優勢,逆にアメリカ英語では stay home が74.6%で優勢と出た.英米差が分かりやすく現われていることになる.
次に,通時的な分布の推移をみてみよう.イギリス英語については後期近代英語コーパス CLMET3.0 を利用し,アメリカ英語には1810年以降のテキストを収めた COHA (Corpus of Historical American English) を利用した.
CLMET では第1期 (1710--1780),第2期 (1780--1850),第3期 (1850--1920) のサブコーパスごとに stay (at) home をレンマ検索してみたところ,どの時期においても stay at home が事実上唯一の表現だった.第2期 (1780--1850) に staying home が1例現われるのみで,19世紀までは stay home はほとんど知られていなかったといってよさそうだ.上でみた BNCweb から分かった現代イギリス英語の状況を勘案すると,おそらく20世紀中に stay home が少し増えてきたということになろう.
一方,アメリカ英語での分布の推移がおもしろい.アメリカ英語でも,もともと stay at home が事実上唯一の表現だったが,19世紀中に stay home もちらほら現われてくる.20世紀に入ると stay home は急速に伸び始め,1940年代には従来の stay at home を頻度の上で逆転するに至った.そして,現在にかけて圧倒的な優位を確立してきたということになる.
簡単な調査なので証拠の穴はところどころに残っているものの,以上より両表現の分布の推移についておよその見当がつけられる.まとめると次のようになる.19世紀までは,英米両変種ともに歴史的により古い stay at home がデフォルトで,stay home はほとんど知られていなかった.ところが,20世紀にかけて stay home が少しずつ増えてきた.とりわけアメリカ英語では20世紀後半に古株の stay at home を抑えて躍進し,現在までに一気に普及してきた.
残る問題は stay home が英語史のどの段階で姿を現わしてきたかである.OED の home, adv. の 1e では,移動動詞を伴わない副詞 home の初出こそc1580年となっているが,stay home という句自体の初出がいつかは教えてくれない(keep home や be home などの表現は1600年前後に出ているようである.「#2237. I'm home.」 ([2015-06-12-1]) も参照).
さらに調べる必要があるが,場合によってはずっと遅れて後期近代英語期のことである可能性もある.stay home は実はかなり新しい表現なのではないか.
2019-07-09 Tue
■ #3725. 語彙力診断テストや語彙関連ツールなど [lexicology][bnc][coca][corpus][webservice][link]
以前「#833. 語彙力診断テスト」 ([2011-08-08-1]) を紹介したが,今回は中田(著)『英単語学習の科学』 (12) で取り上げられていた別の語彙診断力テスト Test Your Vocabulary Online With VocabularySize.com を紹介しよう.140問の4択問題をクリックしながら解き進めていくことで,word family ベースでの語彙力が判定できる.母語を日本語に設定して診断する.また,英語での出題のみとなるが,同じ語彙セットを用いた100問からなる語彙診断テストの改訂版もある.
関連して中田 (13) では,英単語の頻度レベルを調べるツールとして,Compleat Lexical Tutor の VocabProfilers が便利だとも紹介されている.BNC や COCA などを利用して,入力した単語(群)の頻度を1000語レベル,2000語レベルなどと千語単位で教えてくれる.ある程度の長さの英文を放り込むと,各単語を語彙レベルごとに色づけしてくれたり,分布の統計を返してくれる優れものだ.ただし,インターフェースがややゴチャゴチャしていて分かりにくい.
日本人の英語学習者にとっては,「標準語彙水準 SVL 12000」などに基づいて英文の語彙レベルを判定してくれる Word Level Checker も便利である.単語ごとにレベルを返してくれるわけではなく,入力した英文内の語彙レベルとその分布を返してくれるというツールである.
英文を入力すると,単語の語注をアルファベット順に自動作成してくれる Apps 4 EFL の Text to Flash というツールも便利だ.さらにこれの応用版で,単語をクリックすると意味がポップアップ表示される英文読解ページを簡単に作れる Pop Translation なるツールもある.世の中,便利になったものだなあ.
・ 中田 達也 『英単語学習の科学』 研究社,2019年.
2015-09-07 Mon
■ #2324. n-gram [corpus][information_theory][coca][bnc][google_books][statistics][n-gram][collocation][frequency][link]
情報理論や自然言語処理の分野で用いられる n-gram という分析手法がある.コーパス言語学でもすでにお馴染みの概念であり,共起表現 (collocation) の研究などでは当たり前のように用いられるようになった.種々のコーパスのインターフェースにおいても採用されており,「#607. Google Books Ngram Viewer」 ([2010-12-25-1]) では名前に含まれているほどだし,本ブログでも COCA (Corpus of Contemporary American English) の N-gram データベースを用いて「#956. COCA N-Gram Search」 ([2011-12-09-1]) を実装してきた(その応用は,「#953. 頭韻を踏む2項イディオム」 ([2011-12-06-1]),「#954. 脚韻を踏む2項イディオム」 ([2011-12-07-1]),「#955. 完璧な語呂合わせの2項イディオム」 ([2011-12-08-1]) を参照).BNC では,Explore Words and Phrases from the BNC が利用できる.
コンピュータを用いた分析手法というと難しそうに聞こえるが,n-gram の考え方は至って単純である.文字レベルの 2-gram (bigram) を考えてみよう.最長の英単語といわれる pneumonoultramicroscopicsilicovolcanoconiosis (「#63. 塵肺症は英語で最も重い病気?」 ([2009-06-30-1])) を例にとる.まず,先頭の2文字1組の pn を取り出す.次に,2文字目に進んで同じように ne を取り出す.3文字目に進んで eu を,4文字目に進んで um を得る.同じように,1文字ずつ右にずらしながら,最後の is まで2文字1組を次々と拾っていく.これで44組の2文字を得たことになる.この組のなかで,ic と co という組み合わせは各々3回起こり,os, si, no, on の組み合わせは各々2回現われ,それ以外の組み合わせはいずれも1度きりである.したがって,この単語において最高頻度の2文字1組は ic と co となる.
n-gram の単位は,このように文字である必要はなく,音素でもよいし,より大きな単位である形態素や語でもよく,さらに大きな句などのより大きな単位でもよい.英語コーパス言語学では,語という単位で考えるのが普通だろう.Martin Luther King, Jr. の I Have a Dream の演説のテキストで語単位の 4-gram を取ると,最も多い4語の組み合わせは,予想通り "I have a dream" の8回だが,"will be able to" も同じく8回現われる."Let freedom ring from" も7回とよく現われる,等々の分析が可能となる.ここでは4語という「窓」を設定したので 4-gram と呼ばれるが,隣接するいくつの文字を考慮するかにより 1-gram (unigram), 2-gram (bigram), 3-gram (trigram),そして 5-gram 以上ももちろん考えることができる(1-gram の場合,得られるリストは,事実上各語の生起頻度表である).
巨大コーパスから得られた 2-gram や 3-gram の一覧は,それ自体が共起表現の研究などでは基本データとなるため,ウェブ上でもいろいろと公開されている.日本語では「N-gram コーパス - 日本語ウェブコーパス 2010」があるし,現代英語では COCA の n-gram データベース がある.また,Bigram Plus では,歴史英語コーパスを含めた各種英語コーパスから N-Gram Search を行なえる機能を提供している.ほかにも任意のテキストやコーパスを対象に n-gram を取る各種のツールやソフトも,ウェブ上で入手可能だ.
n-gram 分析の言語分野への応用範囲は広い.次に来る語(音,文字)は何か,という予測可能性とも関係が深いため,機械による音声認識,統語分析,言語判定,自動翻訳,スペルチェック,剽窃探知,全文検索用インデックスの作成などに活用される.もちろん,共起表現の研究では,基本にして不可欠の手段となっている.一方,n-gram はもっぱら言語として表面化されたテキストを対象とし,深層にある構造にまったく触れることがないため,生成文法のような言語理論の方面からは批判があるようだ.詳しくは,n-gram in Wikipedia を参照.
n-gram は工夫次第で,まだまだ使い道がありそうだ.歴史英語テキストにも,応用していきたい.
(後記 2015/09/12(Sat): Sketch Engine より N-grams も参照.)
2015-05-22 Fri
■ #2216. 研究社Webマガジンの記事「コーパスで探る英語の英米差 ―― 実践編 ――」 [link][corpus][bnc][coca][ame_bre][sociolinguistics][language_change][gender_difference][link]
一ヶ月前の「#2186. 研究社Webマガジンの記事「コーパスで探る英語の英米差 ―― 基礎編 ――」」 ([2015-04-22-1]) に引き続き,5月20日付で「実践編」が公開されました.研究社WEBマガジン Lingua リンガより,こちらをご覧ください. *
今回は,複数のコーパスを用いることの利点やおもしろさを押し出しました.また,英語の英米差という一見すると静的な話題にも,動的あるいは通時的に迫ることにより,新たな見方が得られる点も強調しました.
記事のなかでも触れましたが,実際には今回の「実践編」で述べた結論に至るには,もっと詳しく調査しなければなりません.しかし,コーパスを用いて,例えばこのような言語変化の徴候をとらえることができるかもしれないという可能性を感じ取ってもらえれば,という気持ちで執筆しました.基礎編,実践編で私の執筆担当は完結ですが,来月以降も引き続き研究社WEBマガジン Lingua リンガの記事にご注目ください.バックナンバーも非常に有用です.以下,改めて研究社WEBマガジン Lingua リンガの各記事へのリンク(最新版)を張っておきます.
1. なぜコーパスか? (赤須 薫)
2. 英語コーパス体験ツアー ― BNCweb を検索してみる ―(前編) (石井 康毅)
3. 英語コーパス体験ツアー ― BNCweb を検索してみる ―(後編) (石井 康毅)
4. Google をコーパスに見立てる (仁科 恭徳)
5. 言語統計の基礎(前編) ― 頻度差の検定 ― (小林 雄一郎 )
6. 言語統計の基礎(後編) ― 共起尺度 ― (小林 雄一郎)
7. コーパスを活用した古くて新しい学問領域:フレイジオロジー ― 理論編 ― (井上 亜依)
8. コーパスを活用した古くて新しい学問領域:フレイジオロジー ― 実践編 ― (井上 亜依)
9. 学習者コーパスとは何か? (鎌倉 義士)
10. 学習者コーパスで何ができるのか? (鎌倉 義士)
11. パラレルコーパスの可能性 (仁科 恭徳)
12. 日本語コーパスに見られる慣用句の用法 (石田 プリシラ)
13. 日本語コーパスに見られる慣用句の変化可能性 (石田 プリシラ)
14. COCA を使ったコロケーションの検索 (内田 諭)
15. COCA を使った類義語の検証 (内田 諭)
16. コーパスで話し言葉を探る ― 基礎編 ― (青木 理香)
17. コーパスで話し言葉を探る ― 実践編 ― (青木 理香)
18. 学習者の話し言葉コーパスを使った語用論分析 (1)談話標識 well, I mean, kind of, like の使い方 (三浦 愛香)
19. 学習者の話し言葉コーパスを使った語用論分析 (2)買い物での要求の表現 (三浦 愛香)
20. 認知言語学を用いてコーパスから意味を探る― 入門編 ― (大谷 直輝)
21. 認知言語学を用いてコーパスから意味を探る― 前置詞・句動詞編 ― (大谷 直輝)
22. コーパスで探る英語の英米差 ―― 基礎編 ―― (堀田 隆一)
23. コーパスで探る英語の英米差 ―― 実践編 ―― (堀田 隆一)
なお,今回の実践編で注目した gorgeous に関しては,本ブログでも以下の記事で扱ってきましたのでご参照ください.
・ 「#476. That's gorgeous!」 ([2010-08-16-1])
・ 「#477. That's gorgeous! (2)」 ([2010-08-17-1])
・ 「#607. Google Books Ngram Viewer」 ([2010-12-25-1])
また,英語(言語)の男女差についても gender_difference の各記事で扱ってきました.特に言語の男女差とコーパス利用を絡めた記事として,「#913. BNC による語彙の男女差の調査」 ([2011-10-27-1]) をご覧ください.
2012-03-03 Sat
■ #1041. COCA の "ANALYZE TEXT" [coca][corpus][web_service][academic_word_list][text_tool]
COCA ( Corpus of Contemporary American English ) を運営する Mark Davies 氏が,[2012-01-08-1]の記事「#986. COCA の "WORD AND PHRASE . INFO"」で紹介した機能 (Frequency List) に加え,英文を投げ込むとCOCAベースで各語に関する諸情報を色づけして返してくれるサービス WORD AND PHRASE . INFO, ANALYZE TEXT を公開した.
適当な英文を投げ込むと,各単語が頻度レベルによって色分けされた状態で返される.上位500語までの超高頻度語は青,3,000語までの高頻度語は緑,それ以下の頻度の語は黄色で示されるほか,academic word が赤字として返される.文章内でのそれぞれの割合も示され,その語彙リストを出すことも容易だ.各語はクリッカブルで,クリックすると用例のサンプルが KWIC で右下ペインに表示される.また,左下ペインには類義語が現われる.以下は,昨日の記事「#1040. 通時的変化と共時的変異」 ([2012-03-02-1]) に引用した英文を投げ込んでのスクリーンショット.
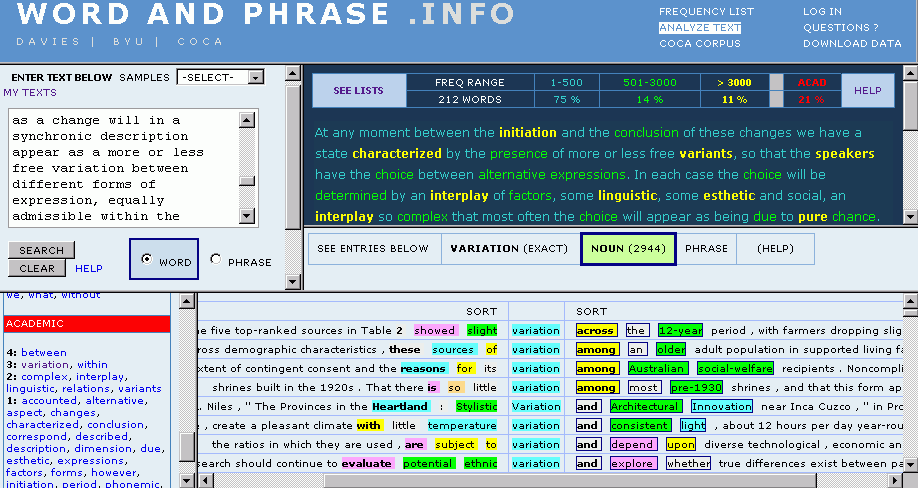
英文を書くときには collocation や synonym を調べながら書くことが多いので,使い方次第では英作文学習に威力を発揮しそうだ.ある文章の academic 度を判定するのにも使える.Academic Word List に含まれる語彙の含有度ということでいえば,[2010-12-30-1]の記事「#612. Academic Word List」で挙げた The AWL Highlighter も類似ツールだ.
2012-01-08 Sun
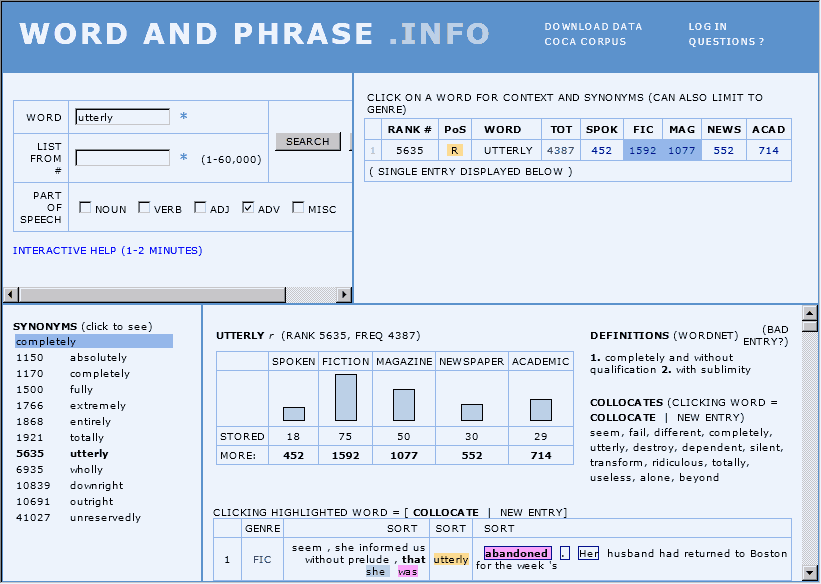
■ #986. COCA の "WORD AND PHRASE . INFO" [coca][corpus][dictionary][synonym][collocation][semantic_prosody][intensifier][web_service]
COCA ( Corpus of Contemporary American English ) を運営する Mark Davies 氏が,年末に,COCAベースで語に関する諸情報を一覧できるサービス WORD AND PHRASE . INFO を公開した.語(lemma 頻度で上位60,000語以内に限る)を入力すると,ジャンルごとの生起頻度やそのコンコーダンス・ラインはもとより,WordNet に基づいた定義や類義語群までが画面上に現われる.ほとんどの項目がクリック可能で,さらなる機能へとアクセスできる.インターフェースが直感的で使いやすい.
類義語研究や collocation 研究には相当に役立つ仕様になったのではないか.例えば,semantic_prosody を扱った[2011-03-12-1]の記事「#684. semantic prosody と文法カテゴリー」で,強意語 utterly, absolutely, perfectly, totally, completely, entirely, thoroughly についての研究を紹介したが,WORD AND PHRASE . INFO で utterly を入力すれば,これらの類義語群が左下ウィンドウに一覧される.あとは,各語をクリックしてゆくだけで,頻度や collocation の詳細が得られる.このような当たりをつけるのに効果を発揮しそうだ.
2011-12-09 Fri
■ #956. COCA N-Gram Search [cgi][web_service][coca][corpus][collocation][n-gram]
##953,954,955 の記事で,最近公開された COCA ( Corpus of Contemporary American English ) の n-gram データベースを利用してみた.COCA に現われる 2-grams, 3-grams, 4-grams, 5-grams について,それぞれ最頻約100万の表現を羅列したデータベースで,手元においておけば,工夫次第で COCA のインターフェースだけでは検索しにくい共起表現の検索が可能となる.
ただし,各 n-gram のデータベースは,数十メガバイトの容量のテキストファイルで,直接検索するには重たい.そこで,SQLite データベースへと格納し,SQL 文による検索が可能となるように検索プログラムを組んだ.以下は,検索結果の最初の10行だけを出力する CGI である.
以下,使用法の説明.テーブル名は n-gram の "n" の値に応じて,"two", "three", "four", "five" とした.ちなみに,1-grams のデータベース(事実上,COCA に3回以上現われる語の頻度つきリスト)も付随しており,こちらもテーブル名 "one" としてアクセス可能にした.フィールドは,全テーブルに共通して "freq" (頻度)があてがわれているほか,"n" の値に応じて,"word1" から "word5" までの語形 (case-sensitive) と,"pos1" から "pos5" までの COCA の語類標示タグが設定されている.select 文のみ有効.以下に,典型的な検索式を例として載せておく.
# 1-grams で,前置詞を頻度順に取り出す(ただし,case-sensitive なので再集計が必要)
select * from one where pos1 like "i%" order by freq desc;
# 2-grams で,ハンサムなものを頻度順に取り出す
select * from two where word1 = "handsome" and pos1 = "jj" and pos2 like "nn_" order by freq desc;
# 2-grams で,"absolutely (adj.)" で強調される形容詞を頻度順に取り出す([2011-03-12-1]の記事「#684. semantic prosody と文法カテゴリー」を参照)
select * from two where word1 = "absolutely" and pos2 = "jj" order by freq desc;
# 3-grams で,高頻度の as ... as 表現を取り出す
select * from three where word1 = "as" and word3 = "as" order by freq desc;
# 4-grams で,高頻度の from ... to ... 表現を取り出す
select * from four where word1 = "from" and pos1 = "ii" and word3 = "to" and pos3 = "ii" order by freq desc;
# 5-grams で,死因を探る; "die of" と "die from" の揺れを観察する
select * from five where word1 in ("die", "dies", "died", "dying") and pos1 like "vv%" and word2 in ("of", "from") and pos2 like "i%" order by word3;
n-gram データベースを最大限に使いこなすには,このようにして得られた検索結果をもとにさらに条件を絞り込んだり,複数の検索結果を付き合わせるなどの工夫が必要だろう.
2011-12-08 Thu
■ #955. 完璧な語呂合わせの2項イディオム [binomial][rhyme][corpus][coca][collocation][euphony][n-gram][suffix][proverb]
[2011-12-06-1], [2011-12-07-1]の記事で,COCA ( Corpus of Contemporary American English ) の 3-gram データベースから取り出した,現代英語における頭韻を踏む2項イディオム (binomial) と脚韻を踏む2項イディオムの例を見てきた.分析するなかで,両リストのなかで重複する2項イディオムが散見されたので,取り出してみた.これぞ,頭韻と脚韻の両方を兼ねそなえた,完璧な語呂合わせとしての共起表現である.(検索結果を収めたテキストファイルはこちら.)整理した50表現を挙げよう.
Saturday and Sunday, personal and professional, himself or herself, quantity and quality, morbidity and mortality, quantitative and qualitative, security and stability, best and brightest, latitude and longitude, sixteenth and seventeenth, whenever and wherever, sensitivity and specificity, watching and waiting, majority and minority, basketball and baseball, fight or flight, ranting and raving, forties and fifties, cooperation and coordination, nature and nurture, pushing and pulling, tossing and turning, twisting and turning, grandchildren and great-grandchildren, skiers and snowboarders, communication and collaboration, cooking and cleaning, psychiatrists and psychologists, biggest and best, development and deployment, slipping and sliding, communication and cooperation, Dungeons and Dragons, heterosexual and homosexual, healthier and happier, grandmother and grandfather, stopping and starting, sixteen or seventeen, hooting and hollering, competence and confidence, stalactites and stalagmites, waxing and waning, positive and productive, reading and rereading, patience and perseverance, bedroom and bathroom, consultation and collaboration, going and getting, grandfather and grandmother, protection and promotion
多くは,頭韻と脚韻が語呂として偶然に一致したと考えるよりは,語幹どうしに語源的な関連があるがゆえに頭韻を踏んでいるのであり,同じ接尾辞を用いているがゆえに脚韻を踏んでいるのだ,と解釈すべきだろう.
単なる語呂遊びというなかれ.上記の例は,音と意味の調和をいやおうなく感じさせ,2項の間に一種の必然性すら呼び起こすかのような,高度に修辞的な表現といえるだろう.fight or flight, nature and nurture, competence and confidence, positive and productive などは,単なる高頻度の共起表現であるという以上に,教訓的,ことわざ的ですらある.
2011-12-07 Wed
■ #954. 脚韻を踏む2項イディオム [binomial][rhyme][corpus][coca][collocation][euphony][n-gram][suffix][compound]
昨日の記事「#953. 頭韻を踏む2項イディオム」 ([2011-12-06-1]) に引き続き,今回は,脚韻を踏む高頻度の binomial を COCA ( Corpus of Contemporary American English ) の n-gram データベースにより拾い出したい.昨日と同様に,3-gram を用い,"A and/but/or B" の形の共起表現で,かつ A と B が脚韻を踏んでいるような例を取りだした.検索結果を納めたテキストファイルはこちら.
検索結果を眺めていて今更ながら気付いたことなのだが,脚韻は頭韻に比べてパターンが見つけやすい.特に顕著なのは,脚韻の多くが,語幹の語尾に依存しているというよりは,接尾辞に依存していることだ.-ing, -ed, -ly, -al, -y, -ion, -er などの屈折接尾辞や派生接尾辞が活躍している.
positive and negative, national and international, internal and external, Friday and Saturday, teaching and learning, gifted and talented, elementary and secondary, hunting and fishing, personal and professional, presence or absence, reliability and validity, coming and going, winners and losers, physical and psychological, formal and informal, directly and indirectly, advantages and disadvantages, rising and falling, physically and mentally, buyers and sellers
また,これも考えてみれば,さもありなんという事例なのだが,複合語の第2要素に同じ形態素を用いることにより韻を踏んでいる例も多い.一種の self-rhyme ではある.
Friday and Saturday, children and grandchildren, Saturday and Sunday, hardware and software, himself or herself, formal and informal, parents and grandparents, direct and indirect, buyers and sellers, mother and grandmother, father and grandfather, Afghanistan and Pakistan, anything and everything, football and basketball, indoor and outdoor, direct or indirect, servicemen and women, likes and dislikes, urban and suburban, indoor and outdoor
接尾辞を多用する屈折や派生,そして right-headed な複合を好む英語においては,脚韻を利用した2項イディオムの形成が容易であり,頻繁であることは,自然に理解できそうだ.逆から見れば,語幹の語頭音を利用する頭韻の2項イディオムの形成は,相対的に難しいということになるのかもしれない.
2011-12-06 Tue
■ #953. 頭韻を踏む2項イディオム [binomial][alliteration][corpus][coca][collocation][euphony][n-gram]
[2011-07-26-1]の記事「#820. 英仏同義語の並列」で,2項イディオム (binomial idiom) を紹介した.and, but, or などの等位接続詞で結ばれる2項からなる表現は現代英語でも顕在であり,よく見られるものには,語呂のよいもの (euphony) が多い.英語において語呂の良さといえば,[2011-11-26-1]の記事「#943. 頭韻の歴史と役割」で取り上げた頭韻 (alliteration) が,典型の1つとして挙げられる.
ところで,11月22日に,大規模オンライン・コーパス COCA ( Corpus of Contemporary American English ) などで知られるコーパス言語学者 Mark Davies が,COCA に基づく n-gram を無償で公開した.2, 3, 4, 5語からなる,それぞれ最頻100万の共起表現 (collocation) を,頻度数とともに列挙したデータベースで,ダウンロードしてオフラインで自由に処理できる.
・ Visit N-GRAMS: from the COCA and COHA corpora of American English. For downloading, directly visit Free lists.
・ Also visit Word frequency lists and dictionary: from the Corpus of Contemporary American English for other COCA-derived n-grams and frequency lists.
ここで,COCA n-gram から現代英語の2項イディオムに見られる頭韻を探して出してみようと思い立った.3-gram データベースを利用し,"A and/but/or B" の形の共起表現を探った.話者の意識していないところでも,頭韻は日常表現のなかに相当活用されているはずだとの予想のもとでの検索だったが,実際に多数の例を拾い出すことができた.検索結果のテキストファイルはこちら.2項の語頭の子音字が一致しているものを取り出しただけなので,それが表わす子音が一致しているとは限らず,注意が必要である.それでも,相当数の生きた日常的な頭韻の例を拾い出すことができた.
検索結果上位には,his or her, four or five, six or seven, this or that, Saturday and Sunday など,なるほどとは思わせるが,それほど興味深く感じられない例が少なくない.しかし,イディオム的な性格のもう少し強い,次のような共起表現も次々と挙がり,検索の甲斐があったと満足した.
public and private, rules and regulations, pots and pans, command and control, flora and fauna, free and fair, death and destruction, go and get, safety and security, signs and symptoms, fame and fortune, families and friends, fresh or frozen, peace and prosperity, past and present, quantity and quality, morbidity and mortality, slowly but surely, professional and personal, name and number, facts and figures, pencil and paper, state and society, small but significant, clear and convincing
n-gram については,[2010-12-25-1]の記事「#607. Google Books Ngram Viewer」も参照.
2011-04-01 Fri
■ #704. brethren and sister(e)n [plural][analogy][ame][i-mutation][relationship_noun][corpus][coca][coha]
昨日の記事[2011-03-31-1]で,古英語の親族名詞の屈折表を見た.brethren の起源についても言及したが,これと関連して親族名詞お得意の類推 ( analogy ) の例をもう一つ挙げよう.brethren との類推で sister(e)n という複数形がある.MED の記述にあるように,中英語では -(e)n 形はごく普通であり,-s 形が一般化するのは brother の場合と同じく近代期以降である.この辺りの話題は私の専門領域なので,詳細なデータをもっている.初期中英語でもイングランドの北部や東部では -s が優勢だが,南部や西部ではこの時期の sister の複数形は原則として -n あるいは母音の語尾が圧倒していることは間違いない ( Hotta, p. 256 ) .
さて,sister(e)n は現代英語に生き残っているが,brethren と異なり,通常辞書には記載されていない.BNC ( The British National Corpus ) でもヒットしなかった.しかし,COCA ( Corpus of Contemporary American English ), COHA ( Corpus of Historical American English ) ではそれぞれ4例,15例(19世紀後半以降の例)がヒットし,もっぱらアメリカ英語で聞かれることが分かる.COCA からの例を1つ挙げる.政治討論会番組 "CNN Crossfire" からの用例である(赤字は引用者).
Well, you know, I hate to correct you, but you made the same mistake many of your liberal brethren and sisteren, have said in analyzing this dissent by Judge Stevens.
COCA, COHA 両コーパスからの計19例のうち16例までが brethren and sister(e)n として現われ,主にフィクションで用いられ,dear や my が先行する呼びかけの使い方が多い.brethren と同様に宗教的,組合的な文脈で現われているようだが,限定された語義としてのほか,文体的な効果もあるのかもしれない.関連して,OED の sister の語義5を引用しておこう."In the vocative, as a mode of address, chiefly in transferred senses. Also colloq. as a mode of address to an unrelated woman, esp. one whose name is not known."
もっぱらアメリカ英語で用いられることについては,Mencken (502) が触れている.
Sisteren or sistern, now confined to the Christians, white and black, of the Get-Right-with-God country, was common in Middle English and is just as respectable, etymologically speaking, as brethren.
sister(e)n という複数形に関する歴史的な問題は,近現代アメリカ英語での使用を,中英語期以来の継続としてとらえるべきか,あるいはアメリカ英語で改めてもたらされた刷新としてとらえるべきか,である.OED によると,sister(e)n は一般的な文章語としては16世紀半ばに廃れたとある.初期近代英語期の例やイギリス英語を含めた諸方言の例を調査しないと分からないが,(1) brethren との類推は時代を問わずありそうであること,(2) brethren と脚韻を踏むので呼びかけなど口語で特に好まれそうであること,この2点からアメリカ英語での再形成と考えるのが妥当ではないだろうか.中英語で非語源的な sister(e)n が作り出されたくらいだから,近代英語で改めて作られたとしても不思議はない.
sister(e)n は通常の辞書には載っていないくらいのレアな複数形だが,brethren, children, oxen (but see [2010-08-22-1]) と同じ,現代に残る少数派 -en 複数の仲間に入れてあげたい気がする.
・ Hotta, Ryuichi. The Development of the Nominal Plural Forms in Early Middle English. Hituzi Linguistics in English 10. Tokyo: Hituzi Syobo, 2009.
・ Mencken, H. L. The American Language. Abridged ed. New York: Knopf, 1963.
2011-02-23 Wed
■ #667. COCA 最頻50万語で品詞別の割合は? [lexicology][corpus][french][loan_word][adjective][statistics][coca]
昨日の記事[2011-02-22-1]に引き続き,COCA ( Corpus of Contemporary American English ) に基づく単語の頻度リストを利用したパイロット・スタディ.今回は,こちらで最近になって追加された最頻50万語のリストを用いて,昨日と同様の品詞別割合を調べた.昨日のリストは見出し語 ( lemma ) に基づいた最頻5000語,今日のリストは語形 ( word form ) に基づいた最頻50万語(正確には497187語)で,性格が異なることに注意したい.
昨日とほぼ同じ作業だが,今回は2万語ずつで階級を区切り,L1からL25までの階級のそれぞれにおいて noun, verb, adj., adv., others の5区分で品詞別割合を出した.(数値データはこのページのHTMLソースを参照.)
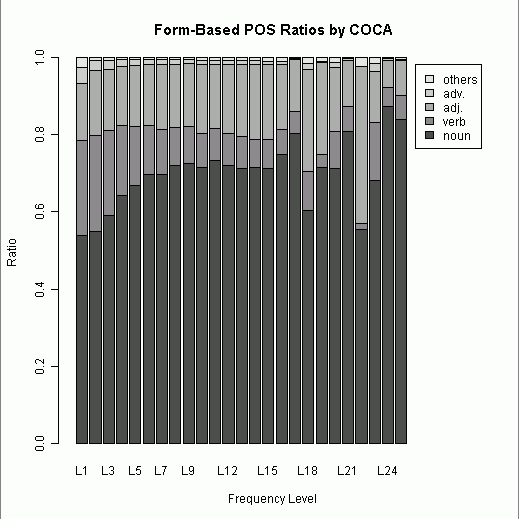
L6(12万語レベル)辺りから品詞別比率は安定期に入るといってよいだろう.L17(34万語レベル)辺りから変動期が始まるのが気になるが,階級幅を大きくしてみると(ならしてみると)直前のレベルから大きく逸脱していない.
[2011-02-16-1]の記事以来,形容詞の比率が気になっているが,今回のデータ全体から計算すると,0.1738という値がはじきだされた.昨日の lemma 調査では0.1678だったから,値は非常に近似している.ただし,名詞と動詞の lemma 対 word form の比率は,名詞が 0.5086 : 0.6985,動詞が 0.2000 : 0.1065 と大きく異なるので,形容詞の 0.1678 : 0.1738 という近似は偶然かもしれない.lemma 対 word form の品詞別割合には異なる傾向があるのかもしれないが,それでも大規模に調べると安定期と呼びうる区間が出現することは確かなようだ.
[2011-02-16-1]の記事で触れたように,中英語期のフランス借用語における形容詞比率は0.1768だった.今回の値0.1738と酷似しているが,主題の性質がまるで違うので,直接の関係を論じることは無理である.もとより昨日と今日の調査は,[2011-02-16-1]の調査とは無関係に始めたものである.しかし,偶然と思えるこの結果は,示唆的ではある.借用語彙といえば名詞が圧倒的なはずだと予想していたものの,フランス語や古ノルド語からはおよそ一定の割合の形容詞(それぞれ lemma 調査で0.1768と0.1817)が借用されていた.そして,その比率は時代が異なるとはいえ現代英語の比率と近似している.英語語彙全体における比率と借用語彙における比率が近似しているということは,もし偶然でないとしたら,何を意味するのだろうか.フランス借用語彙や古ノルド借用語彙が,英語に適応するような自然な比率で英語語彙へ溶け込んだということだろうか.これは,今回のパイロット・スタディの結果を受けての印象に基づく speculation にすぎない.今後も品詞別割合という観点に注目していきたい.
2011-02-22 Tue
■ #666. COCA 最頻5000語で品詞別の割合は? [lexicology][corpus][statistics][n-gram][coca]
COCA ( Corpus of Contemporary American English ) に基づいた各種語彙リストが Corpus-based word frequency lists, collocates, and n-grams から入手できる.そのなかで最も基本的なリストが,こちらの最頻5000語リストである.列挙されているのは見出し語 ( lemma ) 単位で,順位はコーパスに現われる頻度と分散の関数で計算されている.UCREL CLAWS7 Tagset の品詞コード表に基づいた粗い品詞情報も付与されており,品詞別の頻度などを手軽に分析することができる.
今回は,500語ごとに区切って頻度の高い順にL1からL10までの階級を設け,それぞれの階級における品詞別割合を出した.品詞は開いた語類 ( open class ) を中心とし,noun, verb, adj., adv., others の5区分とした.(数値データはこのページのHTMLソースを参照.)
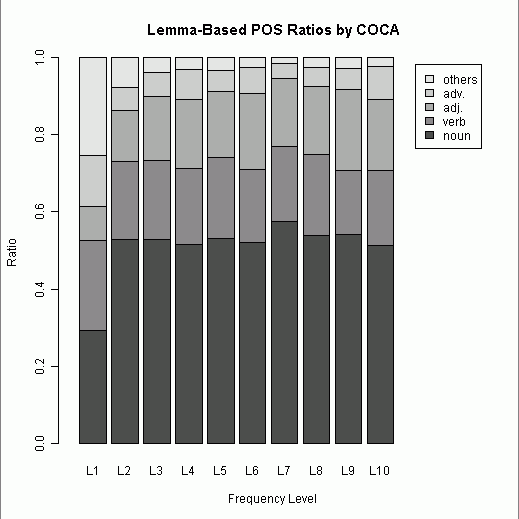
第1階級を除き,どの階級でも名詞が過半数を占めているのは予想できたことだが,第2階級以降に名詞の割合が思ったほど伸びていないことが分かった.動詞と形容詞が後半の階級でもおよそ一定の割合を占め続けているのも予想外だった.全体として,最頻5000語リストに限れば,名詞が飛び抜けつつも,開いた語類の内部比率はおよそ一定に保たれているといえよう.階級幅を様々に動かして試してみたが,およそ安定期に入るのは500語以降と見てよさそうだ.
[2011-02-16-1]の記事で中英語期のフランス借用語の品詞別割合をみたが,全体としての形容詞比率は0.1768だった.今回の現代英語の最頻5000語では,全体としての形容詞比率は0.1678.比べて意味のある数値かどうかは分からないが,英語(言語?)における品詞別比率の「安定感」のようなものはあるのだろうか.
COCA に基づくもの以外にオンラインで入手できる最頻英単語リストについては[2010-03-01-1]の記事を参照.頻度表を利用した別のパイロット・スタディとしては,単語の音節数を扱った[2010-04-17-1]の記事を参照.
2010-09-30 Thu
■ #521. 意外と使われている octopi [plural][coca][oanc][dictionary]
[2009-08-26-1]の記事で,octopus の複数形としては規則的な octopuses が普通であり,octopi や octopodes などの「古典語に基づく不規則複数形は,現在では衒学的・専門的な響きが強すぎて普通には用いられないと考えてよい.このことは,多くの学習者英英辞典で octopuses のみが挙げられていることからもわかる.」と述べた.この説明は octopodes については正しいが,octopi については修正を要するようだ.
ウェブ上で「タコの飼い方」に関する記事を見つけた.その記事の題名は Owning Octopi である.複数形 octopi に惹かれて読んでみたら,内容もおもしろかったのだが,それ以上に341語ほどの記事のなかにもう1度 octopi が現われているので嬉しくなった.一方,規則形の octopuses はさすがに多く,5回ほど使われていた.octopi は確かにマイナー形態ではあるが,題名に採用されているというところが意義深い.COD11 ( The Concise Oxford English Dictionary 11th ed. ) によると octopi は誤用とされているのだが,誤用という感覚,マイナー形態であること,読者を惹きつける題名に求められる新規さとは互いに何らかの関係があるのかもしれない.記事内に1度だけ octopi が現われている箇所について,なぜそこだけが octopi なのかはよくわからないが,同段落内で前後に octopuses が使用されていることから,単調さを嫌っての文体的な動機づけがあるのかもしれない.
Sealing the tank is crucial because octopuses are deft at escaping from even the smallest opening. Because octopi have no skeletal structure, they can fit through practically any gap and can even lift many lids. Sealing a tank is crucial to keeping your octopus safe. Octopuses escape in order to feed their desire to hunt. These aggressive hunters are best served by being fed live crustaceans to quell their hunger and desire to hunt.
また,多くの学習者英々辞書に octopuses しか挙げられていないという件についても修正が必要だ.Oxford, Collins COBUILD, Macmillan の辞書には確かに octopi は記載されていないが,Longman, Cambridge, Merriam-Webster の辞書には octopi は代替複数形として記載されている.大英和辞書系でも octopi は記載されている.
次にコーパスで調べてみた.BNC でのヒット数については[2009-08-26-1]で紹介した通りだが,Corpus of Contemporary American English (BYU-COCA) では octopuses が128回,octopi が36回現われた.OANC (Open American National Corpus) では octopuses が4回,octopi が2回である.ただし OANC の各形態の1例ずつは octopi の誤用の指摘という文脈で現われている.特に COCA でみる限り,最近はそれなりに使われているようだ.
関連する拙著論文で,20世紀前半からの文法書や辞書を比較してラテン語由来の不規則複数が通時的に規則化してゆく傾向を調べたことがあるが,20世紀前半には octopi は皆無ではないがあまり目立たない存在だった.文法書でいえば Jespersen に言及があったくらいである.もしかすると20世紀後半なりの最近の時期に octopi の使用が少しずつ増えてきたということも考えられる.-s への規則化が進む一方で,不規則複数が minor trend として復活する流れが生じているのかもしれない.
・ Hotta, Ryuichi. "Thesauri or Thesauruses? A Diachronic Distribution of Plural Forms for Latin-Derived Nouns Ending in -us." Journal of the Faculty of Letters: Language, Literature and Culture 106 (2010): 117--36.
・ Jespersen, Otto. A Modern English Grammar on Historical Principles. Part 2. Vol. 1. 2nd ed. Heidelberg: C. Winter's Universitätsbuchhandlung, 1922.
2010-09-18 Sat
■ #509. Dracula に現れる whilst (2) [corpus][lob][brown][bnc][oanc][coca][lmode][conjunction]
昨日の記事[2010-09-17-1]の続編.Dracula に現れる同時性・対立を表す接続詞の3異形態 while, whilst, whiles の頻度を,20世紀後半以降の英米変種における頻度と比べることによって,この60?110年くらいの間に起こった言語変化の一端を垣間見たい.用いたコーパスは以下の通り.
(1) Dracula ( Gutenberg 版テキスト ): 1897年,イギリス英語.
(2) LOB Corpus ( see also [2010-06-29-1] ): 1961年,イギリス英語.
(3) BNC ( The British National Corpus ): late twentieth century,イギリス英語.
(4) Brown Corpus ( see also [2010-06-29-1] ): 1961年,アメリカ英語.
(5) OANC (Open American National Corpus): 1990年以降,アメリカ英語.
(6) Corpus of Contemporary American English (BYU-COCA): 1990--2010年,アメリカ英語.
各コーパスにおける接続詞としての while, whilst, whiles の度数と3者間の相対比率は以下の通り.
| while | whilst | whiles | |
| (1) Dracula | 14 (12.61%) | 95 (85.59%) | 2 (1.80%) |
| (2) LOB | 517 (88.68%) | 66 (11.32%) | 0 (0.00%) |
| (3) BNC | 48,761 (89.41%) | 5,773 (10.59%) | 0 (0.00%) |
| (4) Brown | 592 (100.00%) | 0 (0.00%) | 0 (0.00%) |
| (5) OANC | 7,893 (100.00%) | 0 (0.00%) | 0 (0.00%) |
| (6) COCA | 246,207 (99.82%) | 447 (0.18%) | 0 (0.00%) |
Dracula の whilst の比率が異常に高い.はたして同時代のイギリス英語の文語の特徴なのだろうか.この表だけ眺めると,20世紀前半にイギリス英語で whilst が激減し,同世紀後半以降は10%程度で安定したと読める.アメリカ英語では20世紀後半では whilst はほぼ無に等しく,問題にならない.whiles に至っては,関心の発端であった Dracula での2例のみ(他に副詞としては1例あった)で,あとはどこを探しても見つからなかった.しかも,その Dracula の2例というのはいずれも訛りの強い英語を話すオランダ人医師 Van Helsing の口から発せられているもので,同時代イギリス英語でどの程度 spontaneous form であったかは分からない.
今回の調査はもとより体系的な調査ではない.ジャンルの区別や作家の文体を意識していないし,比較する時代の間隔はたまたま入手可能なコーパスに依存したにすぎない.英米変種での比較というのも思いつきである.しかし,興味深い問いが新たに生まれたので,今後は追跡調査をしてみたい.
・ Dracula と同時代の他のイギリス文語では各異形の頻度はどうなのか
・ 20世紀前半に whilst が激減したように見えるのは本当なのか,本当だとしたらその背景に何があるのか
・ アメリカ英語のより古い段階では whilst はもっと頻度が高かったと考えてよいのか
・ whiles はいつ頃まで普通に見られたのか,あるいはそもそも普通に見られる形態ではなかったのか
・ the while や the whilst などの複合形については頻度はどうだったのか
2010-08-22 Sun
■ #482. oxes の出現 [plural][coca][bnc][ame]
現代英語に残る本来語の数少ない不規則複数形の1つに ox 「雄牛;牛」の複数形 oxen がある.現代の標準変種では,古英語の弱変化名詞に直接に由来する唯一の複数形である.ところが,最近アメリカ英語で oxes が現れ始めている.誤用としてではない.『ジーニアス英和大辞典』によると ox の語義2として次のようにあり,この語義での複数形には oxes もありうるという.
2 牛のような(力強い)人, ずんぐりした人, のろまの人 // a dumb ox ((略式))(ずうたいのでかい)うすのろ.
OED によるとこの比喩的な意味は16世紀からある.現在ではアメリカ英語では ox はこの語義以外にはあまり用いられないようだ.それではということで,British National Corpus (BYU-BNC) と Corpus of Contemporary American English (BYU-COCA) で調べてみた.
BNC では oxes が2例ヒットするが,いずれも ox は不規則複数を取る名詞だと教室で教えているという文脈で oxes を誤用として紹介している例なので,事実上ゼロと考えてよいだろう.
COCA では関与する例が6例あった.いずれも話し言葉かニュース英語で,政治的な文脈において使われており,gore 「(角で)突き刺す,傷つける」という動詞の対象として用いられている.例えば,以下のごとくである.
Now our oxes are being gored more directly, not with malice, but out of some perverse ego game.
The establishment, we are sometimes -- you knows, in some cases, convenient oxes to gore. But I think there's no question they represent an important political constituency in the country.
gore (one's) ox というイディオムは,俗語で "to goad or intentionally try to piss someone off" 「突っついていじめる,嫌がらせをする」という意味を表し,アメリカ英語特有のようである.ここの ox はイディオムの一部として用いられており,特に「うすのろ」という意味ではない(イディオムの意味については こちら を参照.このイディオム中で複数形が oxes でなく oxen が用いられている例が4例あることから,この表現が非歴史的な複数形態 oxes の出現に果たしている役割を疑うことができるかもしれない.
これは,動物としてでなくコンピュータマウスの複数形としての mouses や,触覚としてでなくアンテナの複数形の antennas など,比喩的に発展した意味に規則的な複数の -s が付加されるのと類似する現象だろう.gore (one's) ox の ox は原義の「雄牛」のイメージから一歩遠ざかっており,それが oxes という形態を取ることを可能にしているのではないか.ただし,今のところ「雄牛」の意味の複数形として oxes が侵入しているという証拠は(誤用以外には)ないようだ.
Powered by WinChalow1.0rc4 based on chalow