2012-10-31 Wed
■ #1283. 共起性の計算法 [corpus][statistics][bnc][collocation][lltest]
[2010-03-04-1]の記事「#311. girl とよく collocate する形容詞は何か」で,語と語の共起 (collocation) を測る計算法 (association measure) にはいくつかの種類があることを見た.コーパス言語学では,Log-Likelihood Test という検定にかかわる計算法が比較的よく使われているが,それぞれの計算法には特徴があるので,なるべく複数の方法を試すのがよい.今回は[2010-03-04-1]の内容と重複する部分もあるが,BNCweb で実装されている7種類の計算法の各々について Hoffmann et al. (149--58) を参照しながら,特徴および利用のヒントを示したい.
各種の計算法は,(a) 共起頻度 (frequency of co-occurrence),(b) 共起有意性 (significance of co-occurrence),(c) エフェクト・サイズ (effect-size) の1つ,あるいは複数の組み合わせに基づいている.(b) は,共起が統計的に有意であるとの確信度を表わす指標であり,共起の強さを表わすものではないことに注意する必要がある.(c) は,観察頻度と期待頻度との比を計算の基本とする指標である.
(1) Rank by frequency
観察される共起頻度そのものを用いる,最も単純で直感的な尺度.他の計算法のような複雑な統計処理はほどこされておらず,指標としては最も粗い.機能語や句読記号などが上位に来ることが多い.通常の共起分析には用いられない.
(2) Log-likelihood
共起有意性を用いる.BNCweb のデフォルトの計算法で,コーパス研究で広く用いられている.機能語や句読記号などの極めて高頻度の語との共起や,逆に極めて低頻度の語(1, 2回など)との共起をはじく傾向がある.しかし,共起頻度の高い組み合わせに高得点を与えるという特徴があり,解釈には注意を要する.
(3) Mutual information (MI)
エフェクト・サイズを用いる.非常によく用いられている計算法だが,利用に当たっては多くの注意を要する.機能語や句読記号などとのありふれた共起を効果的に排除してくれる点はよいが,反面,低頻度の共起表現への偏りが激しい.この偏りの影響を減じるために,BNCweb では "Freq(node, collocate) at least" を10以上に設定することが推奨される.これにより,"conspicuous and intuitively appealing collocations involving words of intermediate frequency" (Hoffmann et al. 154) が浮き彫りとなる.
(4) T-score
共起頻度と共起有意性を考慮する計算法.期待頻度が1以下程度の稀な共起表現については Rank by frequency と似たような振る舞いをし,頻度の高い共起表現については共起有意性を反映した振る舞いをする.また,観察頻度が期待頻度よりも必ず高くなる.Log-likelihood と類似した結果となることが多いが,高頻度へのバイアスは一層強くなる.ノードそのものが1000回を大きく下回る場合に,効果を発揮することがある.
(5) Z-score
共起有意性とエフェクト・サイズを考慮する計算法.高頻度の共起表現にはエフェクト・サイズをより重視するが,低頻度の共起表現にはそこまでエフェクト・サイズに寄りかからない.Log-likelihood と MI の両特徴を兼ね備えたような,バランスの取れた指標である.ただし,MI と同様に,低頻度の共起表現へのバイアスがみられるので,"Freq(node, collocate) at least" を5程度に設定するのがよいとされる.
(6) MI3
共起頻度とエフェクト・サイズを考慮する計算法.MI のもつ低頻度表現への偏重を取り除くべく改善されている.低頻度共起表現にはエフェクト・サイズが,高頻度共起表現には共起頻度が,比較的よく反映される.POS による限定とともに用いると効果的.複数語からなる用語などの取り出しに威力を発揮する.しかし,全体としては高頻度共起表現へのバイアスが強く,一般的な共起分析には向かない.
(7) Dice coefficient
MI3 と同様に,共起頻度とエフェクト・サイズを考慮する計算法.しかし,MI3と異なり,低頻度共起表現には共起頻度が,高頻度共起表現にはエフェクト・サイズがよく反映され,両者の切り替えが急なのが特徴的である.切り替えは,ノードそのものの頻度が共起表現の頻度の10倍ほどの点で起こるとされる.経験的に,Z-score と似たような結果が得られるが,Z-score ほど頻度に基づくバイアスが見られない.
以上のように多種類あって目移りするが,Hoffmann et al. の見解によれば,単一基準の計算法としては Log-likelihood と MI がお勧めで,混合基準の計算法としては Z-score と Dice がお勧めとのことである.
共起性の様々な計算法については,Association measures を参照.
・ Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee, and Ylva Berglund Prytz. Corpus Linguistics with BNCweb : A Practical Guide. Frankfurt am Main: Peter Lang, 2008.
2012-10-25 Thu
■ #1277. 文字をもたない言語の数は? [world_languages][writing][statistics]
世界の言語の数を把握するのが困難なことは,「#270. 世界の言語の数はなぜ正確に把握できないか」 ([2010-01-22-1]) や「#1060. 世界の言語の数を数えるということ」 ([2012-03-22-1]) の記事で取り上げてきた.私は,言語学概説書の記述や Ethnologue の統計に従って,現在,世界で行なわれている言語は6000--7000個ほどと認識しているが,あくまで仮の数字である.この数のうちどれほどの言語が文字をもっているのかに関心があるが,これまで文献上で概数の言及すらみつけたことがなかった.
先日,Crystal (17) に,軽い言及を見つけた.そこでは,4割ほどの言語(計2000言語を越える)が文字に付されたことがない言語であると述べられている.だが,この推計の根拠が何であるかが知りたいところである.また,逆算すると世界の言語の数は約5000個となるが,これは Crystal の他書での推計よりも少ないのではないか.また,文字をもたない言語数でなく,文字を読み書きできない話者数で考えると,世界人口の何割くらいになるのだろうか.ある言語に文字が備わっているということと,その話者がその文字を読み書きできることとは別の問題であるはずだ.いろいろと疑問がわき出して止まらないが,言語の数にもまして,実際上,数え上げは困難を極めるだろう.
勘としては,Crystal の言及よりもずっと多くの言語が無文字ではないかと思っていたので,意外ではあった.大した根拠のないのが勘というものだが,「#274. 言語数と話者数」 ([2010-01-26-1]) の統計から見当をつけて,話者数が数千人以下の言語に無文字言語が多いのではないかと踏んでいた.
通時的な観点からは,文字をもつ言語がどのくらいの速度で増えていったのか,世界の人々の識字率がどのように推移してきたのかという設問も興味深い.前者は文字文化の伝播の問題,後者は識字能力の独占の歴史や読み書き教育の推進といった問題にかかわる.どの問題1つをとっても,すぐには解答を得られないだろう.
本格的に調べれば,適当な概数の提案に行き当たるのかもしれない.この問題に触れている文献をご存じの方がいましたら,ぜひ教えてください.
関連して,文字の発生については「#41. 言語と文字の歴史は浅い」 ([2009-06-08-1]) ,書き言葉の話し言葉に対する二次的な性質については「#748. 話し言葉と書き言葉」 ([2011-05-15-1]) を参照.
・ Crystal, David. How Language Works. London: Penguin, 2005.
2012-09-04 Tue
■ #1226. 近代英語期における語彙増加の年代別分布 [loan_word][lexicology][statistics][emode][renaissance][inkhorn_term][latin]
英語史における借用語の最たる話題として,中英語期におけるフランス語彙の著しい流入が挙げられる.この話題に関しては,語彙統計の観点からだけでも,「#117. フランス借用語の年代別分布」 ([2009-08-22-1]) を始めとして,french loan_word statistics のいくつかの記事で取り上げてきた.しかし,語彙統計ということでいえば,近代英語期のラテン借用語を核とする語彙増加のほうが記録的である.
[2009-08-19-1]の記事「#114. 初期近代英語の借用語の起源と割合」で言及したが,Görlach は初期近代英語の語彙の著しい増大を次のように評価し,説明している.
The EModE period (especially 1530--1660) exhibits the fastest growth of the vocabulary in the history of the English language, in absolute figures as well as in proportion to the total. (136)
. . . the general tendencies of development are quite obvious: an extremely rapid increase in new words especially between 1570 and 1630 was followed by a low during the Restoration and Augustan periods (in particular 1680--1780). The sixteenth-century increase was caused by two factors: the objective need to express new ideas in English (mainly in fields that had been reserved to, or dominated by, Latin) and, especially from 1570, the subjective desire to enrich the rhetorical potential of the vernacular. / Since there were no dictionaries or academics to curb the number of new words, an atmosphere favouring linguistic experiments led to redundant production, often on the basis of competing derivation patterns. This proliferation was not cut back until the late seventeenth/eighteenth centuries, as a consequence of natural selection or a s a result of grammarians' or lexicographers' prescriptivism. (137--38)
Görlach は,A Chronological English Dictionary に基づいて,次のような語彙統計も与えている (137) .これを図示してみよう.
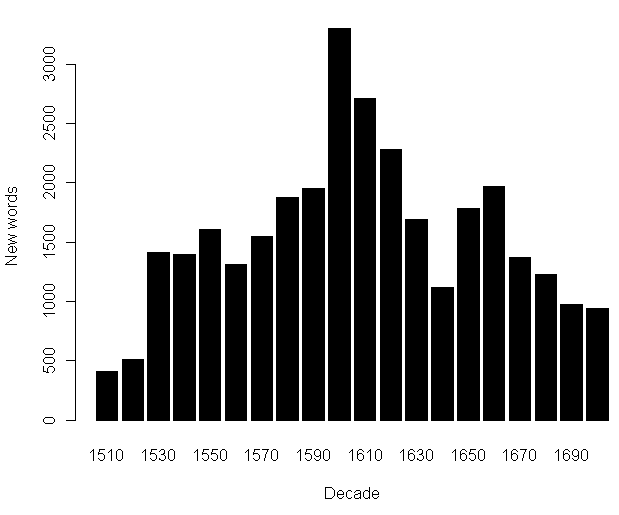
| Decade | 1510 | 1520 | 1530 | 1540 | 1550 | 1560 | 1570 | 1580 | 1590 | 1600 | 1610 | 1620 | 1630 | 1640 | 1650 | 1660 | 1670 | 1680 | 1690 | 1700 |
| New words | 409 | 508 | 1415 | 1400 | 1609 | 1310 | 1548 | 1876 | 1951 | 3300 | 2710 | 2281 | 1688 | 1122 | 1786 | 1973 | 1370 | 1228 | 974 | 943 |
近代英語期のラテン借用について関連する話題は,「#203. 1500--1900年における英語語彙の増加」 ([2009-11-16-1]) や emode loan_word lexicology の各記事を参照.
・ Görlach, Manfred. Introduction to Early Modern English. Cambridge: CUP, 1991.
・ Finkenstaedt, T., E. Leisi, and D. Wolff, eds. A Chronological English Dictionary. Heidelberg: Winter, 1970.
2012-09-03 Mon
■ #1225. フランス借用語の分布の特異性 [lexicology][statistics][loan_word][french][lexical_stratification]
「#845. 現代英語の語彙の起源と割合」 ([2011-08-20-1]) や「#1202. 現代英語の語彙の起源と割合 (2)」 ([2012-08-11-1]) でたびたび扱ってきた話題だが,もう1つ似たような統計を Brinton and Arnovick (298) に見つけた.Manfred Scheler に基づいた Angelika Lutz の統計から引用しているものである.General Service List (GSL; [2010-03-01-1]の記事「#308. 現代英語の最頻英単語リスト」ほか,##309,612,1103 を参照),Advanced Learners' Dictionary (ALD), Shorter Oxford English Dictionary (SOED) の3種の語彙リストを語源別に分類し,それぞれの割合を出している.表からグラフを作成してみた.
| SOED (80,096 words) | ALD (27,241 words) | GSL (3,984 words) | |
|---|---|---|---|
| West Germanic | 22.20% | 27.43% | 47.08% |
| French | 28.37% | 35.89% | 38.00% |
| Latin | 28.29% | 22.05% | 9.59% |
| Greek | 5.32% | 1.59% | 0.25% |
| Other Romance | 1.86% | 1.60% | 0.20% |
| Celtic | 0.34% | 0.25% | --- |
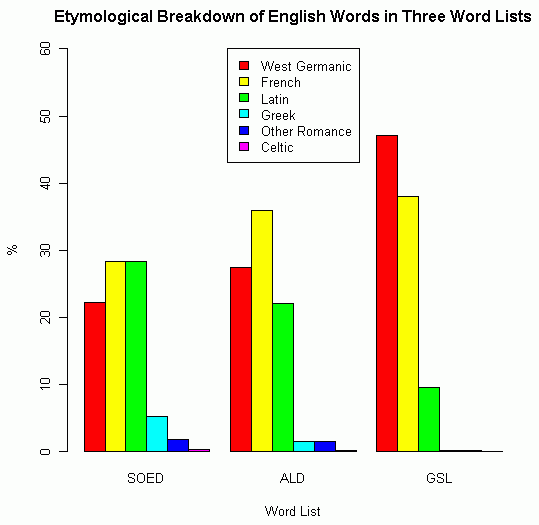
この統計のおもしろい点は,左列から右列に向かって対象語彙が小さくなるように並べられていることだ.別の言い方をすれば,語彙の難易度が右列に向かって下がっている.語彙が基本的であればあるほど,本来語の割合が高いことは上記の過去記事でも触れてきたが,意外なことにフランス借用語についても同様の傾向が見られるという.確かに,左列から右列に向かって割合が増えているのは,赤 (West Germanic) と黄色 (French) のみである.それ以外の語種は,むしろ割合が減っている.
このことから示唆されるのは,フランス借用は,ラテン借用のように文化的で専門的であるばかりではなく,征服者が被征服者に強要した言語接触の結果として,ある程度は基本的でもあるということだ.実際,英語語彙の三層構造 ([2010-03-27-1]) においてフランス語は中層を担っているが,覆う範囲は3層のなかで最も広く,下層へも(そして上層へも)大きくはみ出している.フランス借用語の分布の特異性は,フランス語との接触の歴史の特徴と関連していると考えられる.
ただし,この統計には不明な点もあり,解釈には注意を要する.本来語は West Germanic という広いくくりのなかに含まれると思われるが,ある程度の数のある北欧語系借用語はどこに納まっているのだろうか.また,上の議論では,特にラテン借用語の割合に対するフランス借用語の割合が鍵を握っているが,[2011-02-09-1]や[2011-08-23-1]でみたように,フランス借用語とラテン借用語の区別は難しい.語源判定の不確かさをここではどう処理しているのか,判定ミスによって数値はどのくらい変動するのだろうか.直接 Lutz に当たってみる必要がある.
(後記 2012/09/04(Tue): Lutz (147) を参照したところ,上記の北欧語系借用語に関する疑問について,"Other sources of lexical influence have been left out of account here." とあった.詳細は Scheler を参照せよとのことである.)
・ Brinton, Laurel J. and Leslie K. Arnovick. The English Language: A Linguistic History. Oxford: OUP, 2006.
・ Lutz, Angelika. "When did English Begin?" Sounds, Words, Texts and Change. Ed. Teresa Fanego, Belén Méndez-Naya, and Elena Seoane. Amsterdam and Philadelphia: John Benjamins, 2002. 145--71.
2012-08-24 Fri
■ #1215. 属格名詞の衰退と of 迂言形の発達 [word_order][syntax][genitive][lexical_diffusion][statistics][synthesis_to_analysis]
昨日の記事「#1214. 属格名詞の位置の固定化の歴史」 ([2012-08-23-1]) で,中英語における被修飾名詞に対する属格名詞の位置の固定可について見たが,前置であれ後置であれ,属格名詞そのものが同時期に衰退していったという事実を忘れてはならない.属格名詞を用いた A's B の代わりに B of A というof による迂言形が発達し,前者を脅かした.この交替劇は,大局から見れば,総合から分析へ (synthesis_to_analysis) という英語史の潮流に乗った言語変化である.
Fries (206) に与えられている表は,古英語から中英語にかけて3種類の属格(前置属格,of 迂言形,後置属格)がそれぞれどの程度の割合で用いられれたかを示す統計値である.これをグラフ化してみた.
| Post-positive genitive | 'Periphrastic' genitive | Pre-positive genitive | |
|---|---|---|---|
| c. 900 | 47.5% | 0.5% | 52.0% |
| c. 1000 | 30.5% | 1.0% | 68.5% |
| c. 1100 | 22.2% | 1.2% | 76.6% |
| c. 1200 | 11.8% | 6.3% | 81.9% |
| c. 1250 | 0.6% | 31.4% | 68.9% |
| c. 1300 | 0.0% | 84.5% | 15.6% |
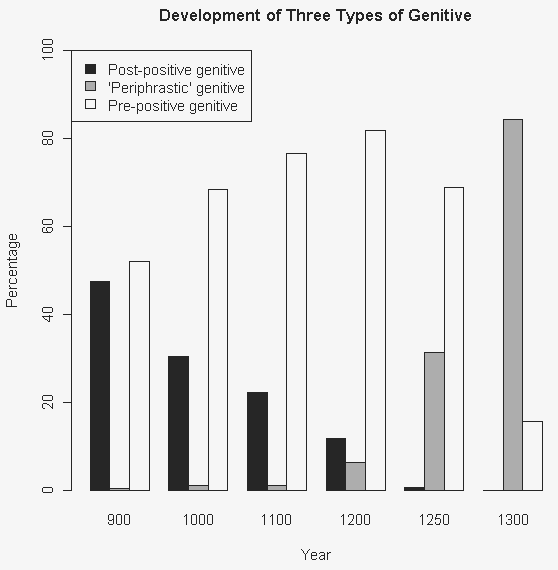
グラフからは,3種類の属格の交代劇が一目瞭然である.古英語の終わりにかけて後置属格が衰退するにともなって前置属格が伸長し,その後13世紀中に of 迂言形が一気に拡大して前置属格を置き換えてゆく.of 迂言形の拡大については,Mustanoja (74--76) が詳しい.
・ Fries, Charles C. "On the Development of the Structural Use of Word-Order in Modern English." Language 16 (1940): 199--208.
・ Mustanoja, T. F. A Middle English Syntax. Helsinki: Société Néophilologique, 1960.
2012-08-23 Thu
■ #1214. 属格名詞の位置の固定化の歴史 [word_order][syntax][genitive][lexical_diffusion][statistics]
「#132. 古英語から中英語への語順の発達過程」 ([2009-09-06-1]) と昨日の記事「#1213. 間接目的語の位置の固定化の歴史」 ([2012-08-22-1]) に引き続き,Fries の研究の紹介.今回は,属格名詞が被修飾名詞に対して前置されるか後置されるかという問題について.
c900--c1250年の発展について,次のような結果が得られた (Fries 205) .
| c. 900 | c. 1000 | c. 1100 | c. 1200 | c. 1250 | |
|---|---|---|---|---|---|
| Genitive before its noun | 52.4% | 69.1% | 77.4% | 87.4% | 99.1% |
| Genitive after its noun | 47.6% | 30.9% | 22.6% | 12.6% | 0.9% |
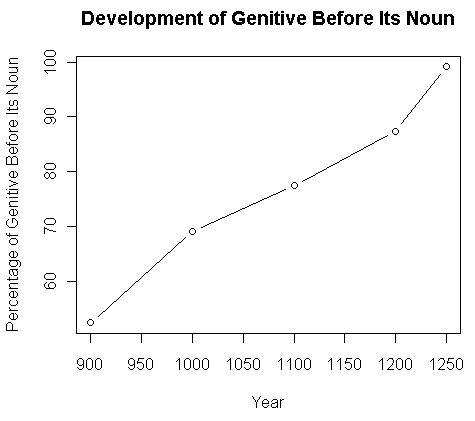
早くも13世紀には,属格名詞の前置が固定可されていたことがわかる.
関連して,17世紀後半に属格名詞ではなく通格名詞(単数でも複数でも)が他の名詞に前置されてそのまま修飾語として用いられる例 (ex. school teacher, examination paper) が現われるが,修飾語と被修飾語の位置関係が固定されていなければ不可能な統語手段である (206) .
これまでに動詞と直接目的語と間接目的語の位置関係,属格名詞と被修飾名詞の位置関係の歴史について見てきたことになるが,いずれも遅くとも中英語の終わりまでには現代英語的な語順に固定していたことがわかる.中英語は,語順の固定可が著しく進んだ時代と結論づけてよいだろう.
・ Fries, Charles C. "On the Development of the Structural Use of Word-Order in Modern English." Language 16 (1940): 199--208.
2012-08-22 Wed
■ #1213. 間接目的語の位置の固定化の歴史 [word_order][syntax][lexical_diffusion][statistics]
[2009-09-06-1]の記事「#132. 古英語から中英語への語順の発達過程」で取り上げた Fries の調査は,英語の語順の発達に関する重要な研究である.先の記事では,動詞に対する直接目的語の相対的な位置に関する通時的推移のみを取り上げたが,Fries はほかにも直接目的語や動詞に対する間接目的語の相対的な位置や,被修飾名詞に対する形容詞や属格名詞の相対的な位置をも対象としている.今回は前者について紹介する.
古英語からは,900--1000年の範囲のコーパスより2558例を集めた F. C. Cassidy の調査結果を参照している.間接目的語と直接目的語の位置関係について,前者が名詞か代名詞か両者を含むかにより,次の統計値を得た (202) .
| OE Corpus (900--1000) | Dative-object before acc-obj. | Dative-object after acc-obj. |
|---|---|---|
| Nouns | 249 (64.0%) | 140 (36.0%) |
| Pronouns | 674 (82.8%) | 141 (17.2%) |
| Both together | 923 (76.6%) | 281 (23.3%) |
全体として間接目的語の前置される傾向が目立ち,とりわけ代名詞の場合には,それが著しい.この傾向は,c1200年の初期中英語コーパスにおいても際立っており(約8割が前置),かなり早い時期から明確なパターンだったことがわかる.
間接目的語と動詞の位置関係については,古英語および初期中英語のコーパスから次の結果を得た (202) .
| OE Corpus (900--1000) | Dative-object before the verb | Dative-object after the verb |
|---|---|---|
| Nouns | 95 (27.6%) | 249 (72.4%) |
| Pronouns | 495 (48.7%) | 518 (51.3%) |
| Both together | 587 (43.4%) | 767 (56.6%) |
| EME Corpus (c1200) | Dative-object before the verb | Dative-object after the verb |
| Nouns | 26 (23.0%) | 88 (77.0%) |
| Pronouns | 218 (43.0%) | 288 (57.0%) |
| Both together | 244 (39.4%) | 376 (60.6%) |
古英語では必ずしも明確な傾向を示すわけではないが,動詞の後位置のほうが優勢である.この傾向は,初期中英語で拡大されてゆく.
上に述べた間接目的語の相対的位置の傾向は後期中英語にかけて強化され,現代英語に見られるような「動詞の後,直接目的語の前」という規則が15世紀後半までに確立していった (203) .
・ Fries, Charles C. "On the Development of the Structural Use of Word-Order in Modern English." Language 16 (1940): 199--208.
2012-08-20 Mon
■ #1211. 中英語のラテン借用語の一覧 [latin][loan_word][lexicology][me][wycliffe][bible][statistics]
昨日の記事「#1210. 中英語のフランス借用語の一覧」 ([2012-08-19-1]) に続いて,今回は中英語に借用されたラテン語の一覧を掲げたい.「#120. 意外と多かった中英語期のラテン借用語」 ([2009-08-25-1]) でも57語からなる簡単な一覧を示したが,Baugh and Cable (185) を参照して,もう少し長い123語の一覧とした.むろん網羅的ではなくサンプルにすぎない.
中英語期には,ラテン語は14--15世紀を中心に千数百語ほどが借用されたといわれる.教会関係者や学者を通じて,話し言葉から入ったものもあるが,主として文献から入ったものである.ラテン語から英語への翻訳に際して原語を用いたという背景があり,Wycliffe とその周辺による聖書翻訳が典型例だが,Bartholomew Anglicus による De Proprietatibus Rerum を Trevisa が英訳した際にも数百語のラテン語が入ったという事例がある (Baugh and Cable 184) .
abject, actor, adjacent, adoption, allegory, ambitious, ceremony, client, comet, conflict, conspiracy, contempt, conviction, custody, depression, desk, dial, diaphragm, digit, distract, equal, equator, equivalent, exclude, executor, explanation, formal, frustrate, genius, gesture, gloria, hepatic, history, homicide, immune, impediment, implement, implication, incarnate, include, incredible, incubus, incumbent, index, individual, infancy, inferior, infinite, innate, innumerable, intellect, intercept, interrupt, item, juniper, lapidary, lector, legal, legitimate, library, limbo, lucrative, lunatic, magnify, malefactor, mechanical, mediator, minor, missal, moderate, necessary, nervous, notary, ornate, picture, polite, popular, prevent, private, project, promote, prosecute, prosody, pulpit, quiet, rational, recipe, reject, remit, reprehend, requiem, rosary, saliva, scribe, script, scripture, scrutiny, secular, solar, solitary, spacious, stupor, subdivide, subjugate, submit, subordinate, subscribe, substitute, summary, superabundance, supplicate, suppress, temperate, temporal, testify, testimony, tincture, tract, tradition, tributary, ulcer, zenith, zephyr
なお,赤字で示した語は,現代英語の頻度順位で1000位以内に入る高頻度語である(Frequency Sorter より).ラテン借用語に意外と身近な側面があることがわかるだろう.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
2012-08-18 Sat
■ #1209. 1250年を境とするフランス借用語の区分 [french][loan_word][me][norman_french][lexicology][statistics][bilingualism]
英語におけるフランス借用語の話題は,french loan_word などの多くの記事で扱ってきた.特に中英語期にフランス借用語が大量に借用された経緯とその借用の速度について,「#117. フランス借用語の年代別分布」 ([2009-08-22-1]) 及び「#1205. 英語の復権期にフランス借用語が爆発したのはなぜか」 ([2012-08-14-1]) で記述した.借用の速度でみると,13世紀の著しい伸びがフランス語借用史の1つの転換点となっているが,この前後ではフランス語借用について何がどう異なっているのだろうか.Baugh and Cable (168--69) により,それぞれの時代の特徴を概説しよう.
ノルマン・コンクェストから1250年までのフランス借用語は,(1) およそ900語と数が少なく,(2) Anglo-Norman の音韻特徴を示す傾向が強く,(3) 下流階級の人々が貴族階級との接触を通じて知るようになった語彙,とりわけ位階,文学,教会に関連する語彙が多い.例としては,baron, noble, dame, servant, messenger, feast, minstrel, juggler, largess; story, rime, lay, douzepers など.
一方,1250年以降のフランス借用語の特徴は次の通り.(1) 1250--1400年に爆発期を迎え,この1世紀半のあいだに英語史における全フランス借用語の4割が流入した.なお,中英語期に限れば1万語を超える語が英語に流れ込み,そのうちの75%が現在にまで残る (Baugh and Cable 178) .(2) フランス語に多少なりとも慣れ親しんだ上流階級が母語を英語へ切り替える (language shift) 際に持ち込んだとおぼしき種類の語彙が多い.彼らは,英語本来語の語彙では満足に表現できない概念に対してフランス語を用いたこともあったろうし,英語の習熟度が低いためにフランス語で代用するということもあったろうし,慣れ親しんだフランス語による用語を使い続けたということもあったろう.(3) 具体的には政治・行政,教会,法律,軍事,流行,食物,社会生活,芸術,学問,医学の分野の語彙が多いが,このような区分に馴染まないほどに一般的で卑近な語彙も多く借用されている.
要約すれば,1250年を境とする前後の時代は,誰がどのような動機でフランス語を借用したかという点において対照的であるということだ.Baugh and Cable (169) は,鮮やかに要約している.
In general we may say that in the earlier Middle English period the French words introduced into English were such as people speaking one language often learn from those speaking another; in the century and a half following 1250, when all classes were speaking or learning to speak English, they were also such words as people who had been accustomed to speak French would carry over with them into the language of their adoption. Only in this way can we understand the nature and extent of the French importations in this period.
・ Baugh, Albert C. and Thomas Cable. A History of the English Language. 5th ed. London: Routledge, 2002.
2012-08-11 Sat
■ #1202. 現代英語の語彙の起源と割合 (2) [lexicology][loan_word][statistics][old_norse]
[2011-08-20-1]の記事「#845. 現代英語の語彙の起源と割合」で,現代英語の最頻語を借用元言語別に分別した統計値を紹介した.このような語彙統計は,何を資料に使ったか,どのような方法で調査したかなどによって結果が変動しがちであるため,複数の調査結果を照らし合わせて評価するのがよい.Schmitt and Marsden (82) は,Bird による調査結果の統計値を与えている.これをグラフ化してみた.(数値データは,HTMLソースを参照.)
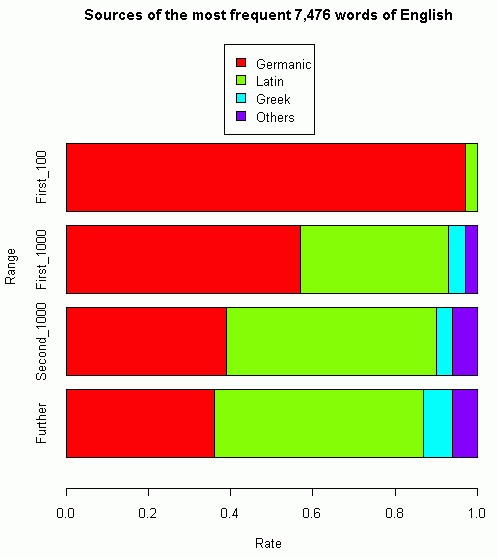
続けて Schmitt and Marsden (83) は,英語本来語のみで構成された印象深い1節を紹介している.
But with all its manifold new words from other tongues, English could never have become anything but English. And as such it has sent out to the world, among many other things, some of the best books the world has ever known. It is not unlikely, in the light of writings by Englishmen in earlier times, that this would have been so even if we had never taken any words from outside the word hoard that has come down to us from those times. It is true that what we have borrowed has brought greater wealth to our word stock, but the true Englishness of our mother tongue has in no way been lessened by such loans, as those who speak and write it lovingly will always keep in mind.
[2010-04-20-1]の記事「#358. アイスランド語と英語の関係」のなかで,"Though they are both weak fellows, she gives them gifts." という北欧単語のみで構成された英文(ただし語源について北欧系かどうか疑わしい語も含まれている)を提示したが,これはさすがに不自然で,強引な文だ.しかし,英語本来語で構成された上の文章は十分に自然だ.
フランス借用語のみで構成された文章は可能だろうか.可能だとしても,どのくらい自然だろうか.
・ Schmitt, Norbert, and Richard Marsden. Why Is English Like That? Ann Arbor, Mich.: U of Michigan P, 2006.
2012-07-17 Tue
■ #1177. EU 仏語の退潮 [french][global_language][elf][statistics]
7月15日(日)の読売新聞朝刊6面の「ワールドビュー」に標題の記事があった.EU は英仏独の3言語を作業言語に指定しているが,報告書はまず最初に英語で出版されるのが常態となっている.
第2次世界大戦後の統合欧州の歴史を振り返れば,当初は,英語圏抜きで歩み始めたために,仏語の支配的地位は盤石だった.しかし,英語の急速な世界化に伴い,仏語の相対的な地位は,世紀後半に向けて落ちていった.特に2004年のEU東方拡大では,仏語よりも英語の得意な中東欧諸国など10カ国が一気に加盟したことにより,仏語の退潮に拍車がかかった.欧州委員会翻訳総局によると,1997年に起草された文書のうち,原文が仏語だったものは40.5%であり,英語は45%だった.ところが,2010年には,その比は7%対77%となり,英語の圧倒的優勢が示された.
最近の欧州財政・金融危機を巡る報道でも,英語メディアの優勢が目立っている.市場への影響力の大きさを考慮したEU官僚が英語メディアに情報を流しているというのが理由のようだ.
ある言語が世界化すればするほど,周囲の環境がその世界化を後押しするために,スパイラル状に世界化が進行する.上で見た例でいえば,2004年のEU東方拡大や現在のEU財政情勢の報道が,部分的に英語の世界化を後押しする社会的要因となっている.
ほかに ELF (English as a Lingua Franca) の統計に関しては,statistics elf の各記事を参照.
2012-07-01 Sun
■ #1161. 英語と日本語における語彙の音節数別割合 [lexicology][statistics][syllable][corpus][japanese]
昨日の記事「#1160. MRC Psychological Database より各種統計を視覚化」 ([2012-06-30-1]) の (3) で,英語語彙を音節数により分別して,それぞれの頻度を出した.それによると,対象となった92767語の語彙全体における1音節語,2音節語,3音節語,4音節語の占める割合は,それぞれ13.46%,35.40%,29.91%,15.26%であり,合わせて94.03%に達する.とりわけ2音節語と3音節語を合わせて65.31%である.9万余という大規模な語彙で調査する限り,英語語彙の3分の2近くは2--3音節語であるということになる.
一方,##348,349,355 の記事では,BNC や COLT のコーパスを用いて,最も頻度の高い数百語から数千語を対象に音節数調査を行なった.調査対象となる語彙の規模は格段に小さく,それに従って音節数別の割合も変わる.1音節語と2音節語が優勢であり,最大の6000語規模の調査でもこの2種類だけで68.7%を占める(「#349. BNC Word Frequency List による音節数の分布調査 (2)」 ([2010-04-11-1]) のグラフを参照).対象とする語彙規模により,優勢な占有率を示す音節数が変動することがわかるが,全般的に,英語語彙においては1--3音節語が主要であることは間違いないだろう.
では,日本語の語彙について,音節数別の割合はどうだろうか.加藤ほか (80) では,林大氏による『日本語アクセント辞典』の見出し語形に基づく拍数の分布の調査結果が要約されている.辞典の見出し語形であるから対称語彙は数万語の規模と思われる.以下のような結果が出た.
| 1拍 | 2拍 | 3拍 | 4拍 | 5拍 | 6拍 | 7拍 | 8拍 | 9拍 | 10拍 | 計 |
| 0.3 | 4.8 | 22.7 | 38.8 | 17.7 | 11.0 | 3.3 | 1.2 | 0.2 | 0.1 | 100 |
割合のピークは4拍語にあり,その前後の3拍語と5拍語を合わせて79.2%,6拍語を加えれば90.2%になる.英語の語彙の主たる構成要素が1--3音節語とすれば,日本語の語彙の主たる構成要素は3--5拍語となる.音節数でみる限り,英単語は相対的に短く,日本語単語は相対的に長いことがよくわかる.
両言語間の際だった差異は,音韻数の差と音節構造の差に起因するといってよいだろう.音韻数については,[2012-02-12-1]の記事「#1021. 英語と日本語の音素の種類と数」で見たとおり,著しい差がある.また,音節構造については,日本語の音節がほぼ「子音+母音」の1形式だけであるのに対して,英語の音節は,[2012-02-14-1]の記事「#1023. 日本語の拍の種類と数」で示唆したとおり,数万形式がある.
日本語の語彙は,2拍語を基本としていると考えられる.和語でも漢語でも2±1拍語が多く,語彙の膨張に従って,その結合が増え,結果として4±1拍語が主流となってきた経緯がある.洋語についても,優勢な4拍語に合わせて「マスコミュニケーション」→「マスコミ」,「ハンガーストライキ」→「ハンスト」,「エンジンストップ」→「エンスト」と省略されることが多い.2拍語を基本とした日本語語彙の成立と,その後の発展については,小松 (48--62) が詳しい.
・ 加藤 彰彦,佐治 圭三,森田 良行 編 『日本語概説』 おうふう,1989年.
・ 小松 秀雄 『日本語の歴史 青信号はなぜアオなのか』 笠間書院,2001年.
[ 固定リンク | 印刷用ページ ]
2012-06-30 Sat
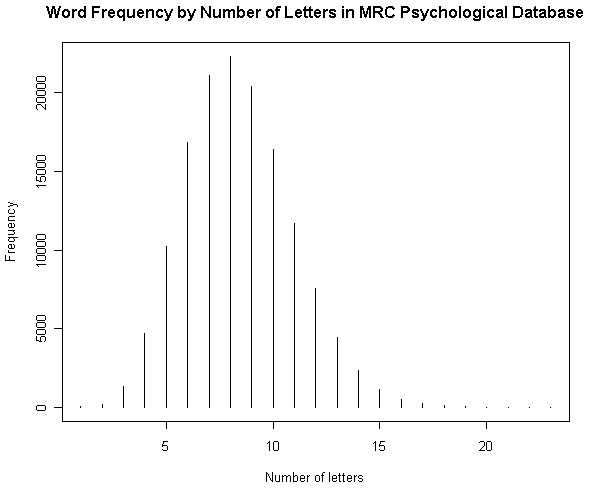
■ #1160. MRC Psychological Database より各種統計を視覚化 [lexicology][statistics][syllable][corpus]
[2012-06-28-1], [2012-06-29-1]と連日紹介してきた MRC Psycholinguistic Database に基づいて,4つの英語語彙統計を図示したい.原データファイルの仕様に示されている統計表をもとにグラフを作成しただけだが,別のコーパスに基づいて類似した調査を行なってきたものもあるので,比較に値するだろう.数値データは,HTMLソースを参照.
(1) 文字数による頻度
(2) 音素数による頻度
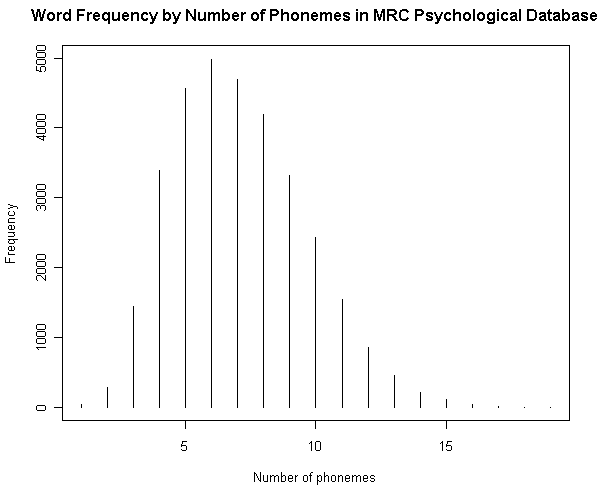
(参考)
・ [2012-02-13-1]: 「#1022. 英語の各音素の生起頻度」
(3) 音節数による頻度
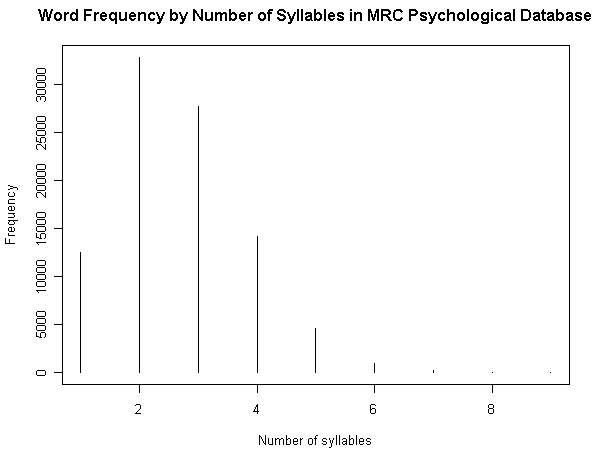
(参考)
・ [2010-04-09-1]: 「#347. 英単語の平均音節数はどのくらいか?」
・ [2010-04-10-1]: 「#348. BNC Word Frequency List による音節数の分布調査」
・ [2010-04-11-1]: 「#349. BNC Word Frequency List による音節数の分布調査 (2)」
・ [2010-04-17-1]: 「#355. COLT Word Frequency List による音節数の分布調査」
(4) 品詞による頻度
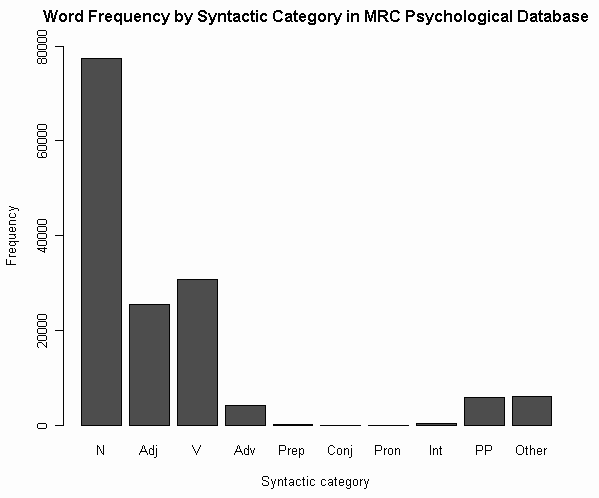
(参考)
・ [2012-06-02-1]: 「#1132. 英単語の品詞別の割合」
・ [2011-02-23-1]: 「#667. COCA 最頻50万語で品詞別の割合は?」
・ [2011-02-22-1]: 「#666. COCA 最頻5000語で品詞別の割合は?」
・ [2011-02-16-1]: 「#660. 中英語のフランス借用語の形容詞比率」
その他,語彙の頻度や,語種別の割合については以下の記事も参照.
・ [2010-03-01-1]: 「#308. 現代英語の最頻英単語リスト」
・ [2011-08-20-1]: 「#845. 現代英語の語彙の起源と割合」
・ [2012-01-07-1]: 「#985. 中英語の語彙の起源と割合」
2012-06-29 Fri
■ #1159. MRC Psycholinguistic Database Search [cgi][web_service][lexicology][frequency][statistics]
昨日の記事[2012-06-28-1]で紹介した英語語彙データベース MRC Psycholinguistic Database を,本ブログ上から簡易検索するツールを作成した.実際には検索ツールというよりは,MRC Psycholinguistic Database を用いると,こんなことができるということを示すデモ版にすぎず,出力結果は10行のみに限定してある.本格的な使用には,昨日示したページからデータベースと検索プログラムをダウンロードするか,ウェブ上のインターフェース (Online search (answers limited to 5000 entries) or Online search (limited search capabilities)) よりどうぞ.
以下,使用法の説明.SQL対応で,テーブル名は "mrc2" として固定.フィールドは以下の27項目:ID, NLET, NPHON, NSYL, K_F_FREQ, K_F_NCATS, K_F_NSAMP, T_L_FREQ, BROWN_FREQ, FAM, CONC, IMAG, MEANC, MEANP, AOA, TQ2, WTYPE, PDWTYPE, ALPHSYL, STATUS, VAR, CAP, IRREG, WORD, PHON, DPHON, STRESS.各パラメータが取る値の詳細については,原データファイルの仕様を参照のこと(仕様中に示されている各種統計値はそれ自身が非常に有用).select 文のみ有効.以下に,典型的な検索式を例として載せておく.
# 文字数で語彙を分別
select NLET, count(NLET) from mrc2 group by NLET;
# 音素数で語彙を分別
select NPHON, count(NPHON) from mrc2 group by NPHON;
# 音節数で語彙を分別
select NSYL, count(NSYL) from mrc2 group by NSYL;
# -ed で終わる形容詞を頻度順に
select WORD, K_F_FREQ from mrc2 where WTYPE = 'J' and WORD like '%ed' order by K_F_FREQ desc;
# 2音節の名詞,形容詞,動詞を強勢パターンごとに分別 (「#814. 名前動後ならぬ形前動後」 ([2011-07-20-1]) 及び「#801. 名前動後の起源 (3)」 ([2011-07-07-1]) を参照)
select WTYPE, STRESS, count(*) from mrc2 where NSYL = 2 and WTYPE in ('N', 'J', 'V') group by WTYPE, STRESS;
# <gh> の綴字で終わり,/f/ の発音で終わる語
select distinct WORD, DPHON from mrc2 where WORD like '%gh' and DPHON like '%f';
# 不規則複数形を頻度順に
select WORD, K_F_FREQ from mrc2 where IRREG = 'Z' and TQ2 != 'Q' order by K_F_FREQ desc;
# 馴染み深く,具体的な意味をもつ語
select distinct WORD, FAM from mrc2 where FAM > 600 and CONC > 600;
# イメージしやすい語
select distinct WORD, IMAG from mrc2 order by IMAG desc limit 30;
# 「有意味」な語
select distinct WORD, MEANC, MEANP from mrc2 order by MEANC + MEANP desc limit 30;
# 名前動後など品詞によって強勢パターンの異なる語
select WORD, WTYPE, DPHON from mrc2 where VAR = 'O';
2012-06-28 Thu
■ #1158. MRC Psycholinguistic Database [web_service][lexicology][frequency][statistics]
心理言語学の分野ではよく知られた英語の語彙データベースのようだが,「#1131. 2音節の名詞と動詞に典型的な強勢パターン」 ([2012-06-01-1]) と「#1132. 英単語の品詞別の割合」 ([2012-06-02-1]) で参照した Amano の論文中にて,その存在を知った.MRC Psycholinguistic Database は,150837語からなる巨大な語彙データベースである.各語に言語学的および心理言語学的な26の属性が設定されており,複雑な条件に適合する語のリストを簡単に作り出すことができるのが最大の特徴だ.特定の目的をもった心理言語学の実験に用いる語彙リストを作成するなどの用途に特に便利に使えるが,検索パラメータの組み合わせ方次第では,容易に語彙統計学の研究に利用できそうだ.
パラメータは実に多岐にわたる.文字数,音素数,音節数の指定に始まり,種々のコーパスに基づく頻度の範囲による絞り込みも可能.心理言語学的な指標として,語の familiarity, concreteness, imageability, meaningfulness なども設定されている.品詞などの統語カテゴリーはもちろん,接頭辞,接尾辞,略語,ハイフン形などの形態カテゴリーの指定もできる.発音や強勢パターンの指定にも対応している.組み合わせによって,およそのことができるのではないかと思わせる精緻さである.
全データベースと検索プログラムはこちらからダウンロードできるが,プログラムをコンパイルするなど面倒が多いので,ウェブ上のインターフェースを用いるのが便利である.2つのインターフェースが用意されており,それぞれ機能は限定されているが,通常の用途には十分だろう.
・ Online search (answers limited to 5000 entries): パラメータの細かい指定が可能だが,出力結果は5000語までに限られる.
・ Online search (limited search capabilities): 出力結果の数に制限はないが,言語学的なパラメータの細かい指定(綴字や発音のパターンの直接指定など)はできない.
・ Amano, Shuichi. "Rhythmic Alternation and the Noun-Verb Stress Difference in English Disyllabic Words." 『名古屋造形大学名古屋造形芸術大学短期大学部紀要』 15 (2009): 83--90.
2012-06-02 Sat
■ #1132. 英単語の品詞別の割合 [lexicology][corpus][statistics]
昨日の記事で,MRC Psycholinguistic Database (全150837語を含む)を利用した Amano の研究を参照した.Amano では,名詞と動詞の stress typicality の調査の副産物として,同データベースに基づいた語の品詞別割合の表が示されていたので,今回はそれをメモしておきたい.
Amano (86) は,データベースより計10894個の2音節語を抜き出した.複数の品詞の機能をあわせもつ語については,それぞれの品詞のもとで1個として加えた(その他,詳しい作業手順は p. 86 に明記されている).結果として得られた品詞別の個数と割合は以下の通りである.
| POS | FREQ | % |
| noun | 7326 | 57.04% |
| verb | 2501 | 19.47% |
| adjective | 2420 | 18.84% |
| adverb | 291 | 2.27% |
| preposition | 68 | 0.53% |
| conjunction | 21 | 0.16% |
| pronoun | 15 | 0.12% |
| interjection | 37 | 0.29% |
| past participle | 57 | 0.44% |
| others | 108 | 0.84% |
品詞別の割合の算出は,用いるデータベースやコーパスの性質や規模,word form で数えるか lemma で数えるかなどの「語」の定義の問題に左右されるが,複数の調査結果を比較すれば,ある程度は信頼できる値が得られるだろう.本ブログ内でこれまでに紹介した品詞別の割合については,以下を参照.
・ [2011-02-23-1]: 「#667. COCA 最頻50万語で品詞別の割合は?」
・ [2011-02-22-1]: 「#666. COCA 最頻5000語で品詞別の割合は?」
・ [2011-02-16-1]: 「#660. 中英語のフランス借用語の形容詞比率」
・ Amano, Shuichi. "Rhythmic Alternation and the Noun-Verb Stress Difference in English Disyllabic Words." 『名古屋造形大学名古屋造形芸術大学短期大学部紀要』 15 (2009): 83--90.
2012-06-01 Fri
■ #1131. 2音節の名詞と動詞に典型的な強勢パターン [stress][diatone][statistics]
「名前動後」の現象について,diatone の各記事で触れてきた.Kelly and Bock の研究によれば,2音節語における名前動後の強勢パターンは,一般的な強勢位置の傾向を反映しているという.すなわち,2音節の名詞では第1音節に強勢のおちる強弱型 (trochaic) ,2音節の動詞では第2音節に強勢の落ちる弱強型 (iambic) が普通とされる.この傾向は stress typicality と呼ばれるが,率でいえばどの程度の傾向を示すのだろうか.
Amano は,Kelly and Bock や Sereno の調査結果を参照しながら,MRC Psycholinguistic Database を用いた独自の調査をおこなった.調査間の比較が可能となるように,純粋な名詞(他の品詞機能をもたないもの)と純粋な動詞に限定しての数え上げだが,次のような結果となった.他の調査と合わせて,Amano (86) の調査の統計を挙げよう.
| researcher | category | result |
| Sereno (1986) | noun | out of 1425 nouns, 93% are trochaic |
| verb | out of 523 verbs, 76% are iambic | |
| Kelly & Bock (1988) | noun | out of 3202 nouns, 94% are trochaic |
| verb | out of 1021 verbs, 69% are iambic | |
| Amano (2009) | noun | out of 5766 nouns, 92.92% are trochaic |
| verb | out of 1184 verbs, 72.65% are iambic |
(注記.Sereno の値は Brown Corpus によるものであり,Amano (86) より孫引きしたものである.しかし,直接 Sereno の原典に当たったところ,名詞が92%,動詞が85%と異なる値が示されていた.)
調査間に大きな差異はなく,名詞の約93%が trochaic,動詞の約73%が iambic という事実が確認された.対比的に評価すれば,品詞ごとに stress typicality があることは,疑いえない.なぜこのような傾向があるのかという問題については,Kelly and Bock および Amano で論じられている.要約すれば,2音節名詞を強弱型に,2音節動詞を弱強型にそれぞれはめ込むことにより,周囲の語とともに,強勢と無強勢の交替のリズムを作りやすくなるからである.名詞は無強勢の冠詞が前置されることが多いので,あわせて「弱強弱」となりやすく,動詞は1音節の屈折語尾(-ing および語幹の一定の音声環境のもとでの ed や -es)を伴う頻度が名詞よりも高いので,あわせて「弱強弱」となりやすい,等々.
名前動後の問題を考える際にも,2音節語の名詞・動詞に関するこの一般的な傾向を念頭に置いておく必要があるだろう.
・ Kelly, Michael H. and J. Kathryn Bock. "Stress in Time." Journal of Experimental Psychology: Human Perception and Performance 14 (1988): 389--403.
・ Sereno, J. A. "Stress Pattern Differentiation of Form Class in English." The Journal of the Acoustical Society of America 79 (1986): S36.
・ Amano, Shuichi. "Rhythmic Alternation and the Noun-Verb Stress Difference in English Disyllabic Words." 『名古屋造形大学名古屋造形芸術大学短期大学部紀要』 15 (2009): 83--90.
2012-05-04 Fri
■ #1103. GSL による Zipf's law の検証 [lexicology][statistics][frequency][zipfs_law][corpus]
[2012-05-02-1], [2012-05-03-1]の記事で取り上げてきた Zipf's law を検証(というよりは体験)するために,General Service List (GSL) の最頻2000語余りのデータを利用して計算してみた(データファイルはこちら).
![]()
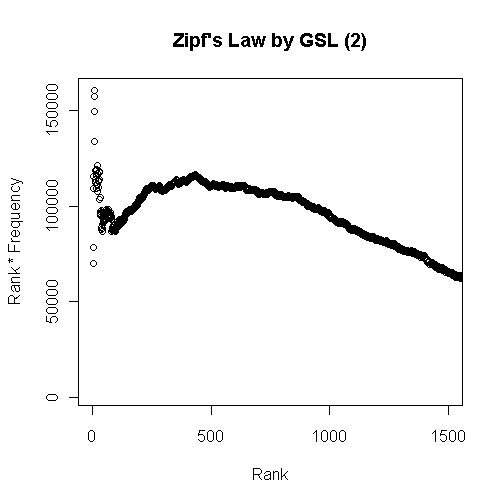
最初のグラフは頻度順位と頻度を掛け合わせたグラフで,頻度順で100位ほどまでの語を対象とした.以下はひたすら漸減してゆくのみなので省略.累積頻度のグラフを作成するまでもなく,最頻の数十語ほどで延べ語数のほとんどを覆ってしまう様子がよくわかる.
次のグラフは,Zipf's law によると定数になるとされる頻度順位と頻度の積を縦軸にとったものである.上位数十語までは「定数」は上下に大きく揺れて安定しないが,以後1000語ぐらいまでは,緩やかな増減はあるものの,落ち着く.その後のグラフ外ではひたすら漸減を続ける.したがって,「定数」を云々できるのは大目に見ても上位1000語ぐらいまでだろう.
これを法則と呼ぶのはあまりに外れていると考えるか,統計的傾向がよく出ているととらえるかは,観察者の見方ひとつである.Zipf's law における「定数」は「およそ定数」と解釈するのが暗黙の了解だが,「およそ」の幅がどの程度であるのかは明示されていない.また,Zipf's law が主張しているのと異なり,グラフの線は頻度をとるコーパスのサイズにも依存するようだ.
2012-05-03 Thu
■ #1102. Zipf's law と語の新陳代謝 [information_theory][frequency][statistics][zipfs_law][shortening][language_change]
昨日の記事[2012-05-02-1]で Zipf's law について概説した.Zipf's law には派生した「法則」が多くあり,その1つに,[2012-04-22-1]の記事「#1091. 言語の余剰性,頻度,費用」でも指摘した「言語要素は,頻度が高ければ音形が短い」というものがある.これを,より動的に,通時的に表現すると「言語要素は,頻度が高くなれば音形が短くなる」となる.ある語の頻度が高くなってゆくと,ある程度の遅延はあるものの,その音形が短くされてゆく傾向のあることは,私たちも経験的によく知っていることである.「#878. Algeo と Bauer の新語ソース調査の比較」([2011-09-22-1]) や「#879. Algeo の新語ソース調査から示唆される通時的傾向」([2011-09-23-1]) で見たとおり,現代英語の新語ソースとして短縮 (shortening) による語形成が増加しており,例には事欠かない.
この Zipf's law の派生法則のもつ共時的意義と通時的意義を合わせて考えると,語の頻度と長さによって,それが老いゆく語 (senescent word) なのか,生まれつつある語 (nascent word) なのかを区別できるという可能性が生じる.Zipf 著 Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology の書評を著わした Chao (399) より,関連箇所を引用しよう.
A very interesting application of the tool analogy is that of senescent and nascent tools in connection with the Principle of Economical Specialization. Reasoning from tool efficiency yields the result that 'whenever we find a tool (or word) whose magnitude is smaller than that of its neighbors in the frequency range, we may conclude that the tool (or word) of below-average size is an older tool (or word) whose usage is on the decrease (hereinafter we shall call this a senescent tool)', and 'whenever we find a tool (or word) whose magnitude is above average for its frequency, we may conclude not only that it is a newer tool (or word), but that its usage may well be directed toward an increase (hereinafter we shall call this a nascent tool)' (72). The application to words is verified to a fair degree for English of various periods (111). By regarding all behavior as work and words as tools, the analogy becomes a case and the qualifier 'or word' can be omitted.
音形の比較的短いある単語 A を考える.Zipf's law によれば,A は比較的頻度の高い語だと予想されるが,実際には同程度の頻度を示す他の多くの語に比べると音形が短すぎたとする.この場合,おそらく A はさかりを過ぎて頻度が徐々に低まってきた senescent word と考えてよいだろう.反対に,音形の比較的長いある単語 B を考える.Zipf's law によれば,B は比較的頻度の低い語だと予想されるが,実際には同程度の頻度を示す他の多くの語に比べると音形が長すぎたとする.この場合,おそらく B はこれから頻度がますます増してゆき,短縮を起こしてゆくと予想される nascent word と考えてよいだろう.これは,Zipf's law に,冒頭に述べた時間的遅延とを掛け合わせた応用法則といってよい.
通常 Zipf's law は静的で共時的な統計的法則ととらえられているが,動的で通時的な観点から,語の新陳代謝の法則として再解釈してみるとおもしろい.
・ Chao, Y. R. "Review of Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology by George Kingsley Zipf." Language 26 (1950): 394--401.
2012-05-02 Wed
■ #1101. Zipf's law [information_theory][frequency][statistics][language_change][zipfs_law][shortening][pragmatics][zipfs_law]
##1089,1090,1091,1098 の記事で,情報理論 (information theory) が言語学に与えてくれる知見について,いくつか見てきた.情報理論からの貢献として,最もよく知られているものの1つに,アメリカの言語学者 George Kingsley Zipf (1902--50) が1949年に Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology において提唱した Zipf's law (ジップの法則)がある.語の頻度についての経験的な法則であり,語の頻度を f とし,その頻度の順位を r とすると,その積 C はほぼ定数となるという.
r × f = C
この法則は,言語,テキストの主題,著者,その他の言語的な変数にかかわらず成り立つとされるが,実際には頻度が最高および最低の語群については誤差の大きいことがわかっており,信頼性は高くないとして批判も多い.また,r (頻度順位)は当然ながら f (頻度)に依存しており,f が増えれば r が減るのは自明であるから,その積が近似値をとるということは驚くべき帰結ではない,一種のトートロジーであるという批判がある.しかし,経験的事実に照らして法則とまではいわずとも傾向をよく表わしているということはでき,これを明示的に指摘した意義は大きい.
Zipf's law の波及効果は多岐にわたる.例えば,この法則によれば,使用頻度の高い語からその使用頻度の累計を求めて行くと比較的少数の語で延べ語数の大部分を占めることから,学習基本語彙の設定に根拠を与えるものとなる.また,この法則に適合しない頻度分布を示す語彙があるとすれば,他の特殊な要因が関与している可能性が疑われるとされる(少数の語の頻度があまりに高すぎれば語彙の貧弱化が生じていると診断されるし,頻度の低いはずの語が高頻度で用いられている場合には爆発的な新造語彙や精神分裂症が原因と想定される等々).
Zipf's law は,人間の行動を司るとされるより大きな原則,the Principle of Least Effort (最小努力の原則)の一部であり,その言語への応用は,上記の最もよく知られた頻度と頻度順の関係の公式化のみならず,他の公式の提案にも及んでいる.例えば,語の頻度と語の長さは反比例の関係にある,というものもある.最頻語は単音節であることが多いという事実(音節数の分布調査については ##348,349,355 を参照)や,頻度が高くなると頭字語などのように短縮・省略されることが多いという事実も,この公式で説明される.ほかには,ある頻度範囲とそれに属する語の数の関係を表わす公式,調音の難しい音素は頻度が低いとする原則など,派生した法則は数多い.語用論の cooperative principle (協調の原則)における量の格律「(その状況において)必要とされている(だけの)情報を与えよ」とも関与するだろう."effort" の定義などの難しい問題が残っており,また最小努力が人間の行動を司る唯一の原則であるとは考えることもできないが,真理の一面をついたものとして重要な学説であることは間違いない.
なお,諸文献では,上記のいずれの原則も Zipf's law として言及されることがあり,また Zipf's laws と複数形でまとめられたり,the Principle of Least Effort と総括されたりすることもあるので注意が必要である.Zipf の著書の書評としては Chao を参照.類似の統計的法則については,Crystal (86--87) を参照.
・ Chao, Y. R. "Review of Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology by George Kingsley Zipf." Language 26 (1950): 394--401.
・ Crystal, David. The Cambridge Encyclopedia of Language. 2nd ed. Cambridge: CUP, 1997.
Powered by WinChalow1.0rc4 based on chalow