2012-04-15 Sun
■ #1084. 英語の重要性を示す項目の一覧 [elf][statistics][internet][airspeak]
現代世界における英語の重要性を示す事実や統計については,elf の各記事や,とりわけ statistics elf の各記事で取り上げてきた.英語の世界化は現在進行中であり,英語に関する事実と統計も常に変化の最中にあるために,最新の情報を正確に捉えることは難しい.いきおい数年遅れ,場合によっては数十年遅れの情報をもとに現状を推し量るということになりがちである.また,多くの研究者や機関が事実や統計を調査しているものの,個別の情報を個別に公表するにとどまることが多く,全体像を得ることが難しい.
以下の一覧は,2006年に出版された Schmitt and Marsden (2--3) に挙げられている英語の重要性を示す事実と統計の諸項目だが,著者もいうように "In many cases, the most current information available dates from the 1990s, or even the 1980s." (2) である.あくまで参考資料だが,このように一覧されていると便利ではある.なお,原文では,各項目に典拠が注記されており,必要に応じて参照することができる.
・ English is the principal language of intercontinental telephone communication.
・ Perhaps as much as 75 percent of mail around the world is written in English.
・ About half of the world's newspapers are published in English.
・ Twenty-eight percent of the books published annually are in English.
・ The majority of academic journals with international readership are in English.
・ The majority, and perhaps even more than two-thirds, of international scientists write in English. For example, nearly two-thirds of the publications produced by French scientists were in English in the early 1980s. Likewise, English was the major working language for German academics surveyed in the early 1990s. In 13 out of 20 disciplines, at least 40 percent claimed to work in English, and for psychology, biology, chemistry, and physics, the figures ranged from 81 to 98 percent. One can only suspect that these figures are even higher today.
・ Ninety percent of Internet hosts were based in English-speaking countries in the mid-1998s.
・ Close to 80 percent of the world's computer data available on the Internet was stored in English in the 1990s, which is not surprising considering that English-speaking countries took the lead in developing the Internet. However, as other countries rapidly increase their use of the Internet, the use of non-English languages is rising. Still, English sites on the Internet continue to attract a disproportionately high percentage of hits.
・ Forty percent of the people online on the Internet speak English (228 million people), though this may eventually drop to around 30 percent. The next highest language is Chinese at 9.8 percent (55.5 million people).
・ The most influential software company, Microsoft, is based in an English-speaking country: the United States.
・ Most of the largest advertising agencies are based in the United States.
・ Eighty-five percent of world institutions use English as their language, or as one of their languages; for example, it is the official language of the Olympics and the World Council of Churches.
・ The official international language for both aviation and maritime use is English.
・ English is the dominant language of international trade, with about 40 percent of the business deals made in English.
・ The most influential movies and modern music come from English-speaking countries.
・ In 1994, 80 percent of all feature films that were shown in cinemas worldwide were in English.
・ About 85 percent of the global movie market was controlled by the United States in 1995.
・ The fact that large numbers of people are learning English as a second language is reflected by the large number of people taking the TOEFL® Test (about 689,000 people in 215 countries) and University of Cambridge Local Examinations Syndicate (UCLES) tests (more than 1 million people in more than 130 countries) every year.
1997年に出版の Graddol や2003年に出版の Crystal も(いずれもやはり古いが)この種の統計情報に満ちている.関連して,「#48. 国際的に英語が使用される主要な分野」 ([2009-06-15-1]) や「#716. 英語史のイントロクイズ(2011年度版)とその解答」 ([2011-04-13-1]) も参照.
本当は個別に情報をアップデートできればよいのだが,日に日に状況が変わるので,情報更新だけでもフルタイム専任の仕事になってしまう.このような項目一覧は,古いことを認めつつ,便利に使ってゆくのがよい.
・ Schmitt, Norbert, and Richard Marsden. Why Is English Like That? Ann Arbor, Mich.: U of Michigan P, 2006.
・ Graddol, David. The Future of English? The British Council, 1997. Digital version available at http://www.britishcouncil.org/learning-research-futureofenglish.htm.
・ Crystal, David. English As a Global Language. 2nd ed. Cambridge: CUP, 2003.
2012-02-13 Mon
■ #1022. 英語の各音素の生起頻度 [phoneme][frequency][statistics]
昨日の記事「#1021. 英語と日本語の音素の種類と数」 ([2012-02-12-1]) で,音素一覧を掲げた.では,英語の音素のなかでもっとも多く使われる音素は何だろうか.そして,もっとも使われないのは何だろうか.
その統計をとった研究がある.Fry, D. B. "The Frequency of Occurrence of Speech Sounds in Southern English." Archives Néerlandaises de Phonétique Expérimentale 20 (1947) で出された統計が Crystal (239, 242) に掲載されているので,ここに再掲する.一定の長さの談話における延べ音素で数えたものである.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | total | ||||
| /iː/ | /ɪ/ | /e/ | /æ/ | /ʌ/ | /ɑː/ | /ɒ/ | /ɔː/ | /ʊ/ | /uː/ | /ɜː/ | /ə/ | /eɪ/ | /aɪ/ | /ɔɪ/ | /əʊ/ | /aʊ, ɑʊ/ | /ɪə/ | /eə/ | /ʊə/ | |||||
| 1.65 | 8.33 | 2.97 | 1.45 | 1.75 | 0.79 | 1.37 | 1.24 | 0.86 | 1.13 | 0.52 | 10.74 | 1.71 | 1.83 | 0.14 | 1.51 | 0.61 | 0.21 | 0.34 | 0.06 | 39.21 | ||||
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | |
| /p/ | /b/ | /t/ | /d/ | /k/ | /g/ | /ʧ/ | /ʤ/ | /f/ | /v/ | /θ/ | /ð/ | /s/ | /z/ | /ʃ/ | /ʒ/ | /h/ | /m/ | /n/ | /ŋ/ | /l/ | /r/ | /w/ | /j/ | |
| 1.78 | 1.97 | 6.42 | 5.14 | 3.09 | 1.05 | 0.41 | 0.60 | 1.79 | 2.00 | 0.37 | 3.56 | 4.81 | 2.46 | 0.96 | 0.10 | 1.46 | 3.22 | 7.58 | 1.15 | 3.66 | 3.51 | 2.81 | 0.88 | 60.78 |
母音が39.21%,子音が60.78%.頻度の高い順にソートすると,以下のようになる.
/ə/ (10.74), /ɪ/ (8.33), /n/ (7.58), /t/ (6.42), /d/ (5.14), /s/ (4.81), /l/ (3.66), /ð/ (3.56), /r/ (3.51), /m/ (3.22), /k/ (3.09), /e/ (2.97), /w/ (2.81), /z/ (2.46), /v/ (2.00), /b/ (1.97), /aɪ/ (1.83), /f/ (1.79), /p/ (1.78), /ʌ/ (1.75), /eɪ/ (1.71), /iː/ (1.65), /əʊ/ (1.51), /h/ (1.46), /æ/ (1.45), /ɒ/ (1.37), /ɔː/ (1.24), /ŋ/ (1.15), /uː/ (1.13), /g/ (1.05), /ʃ/ (0.96), /j/ (0.88), /ʊ/ (0.86), /ɑː/ (0.79), /aʊ, ɑʊ/ (0.61), /ʤ/ (0.60), /ɜː/ (0.52), /ʧ/ (0.41), /θ/ (0.37), /eə/ (0.34), /ɪə/ (0.21), /ɔɪ/ (0.14), /ʒ/ (0.10), /ʊə/ (0.06).
上位9音素までが,弛緩母音あるいは歯・歯茎を用いる音である.最下位の2重母音や摩擦音も覚えておきたい.音声変化を考える上で,このように音素別の頻度を頭に入れておくと役立つことがあるだろう.主要なものだけでも音節別の頻度でこのようなランキング表はないだろうか.
(後記 2012/04/22(Sun):石橋 幸太郎 編 『現代英語学辞典』の "Frequency of occurrence of phonemes" (323--24) に類似した他の統計値あり.)
・ Crystal, David. The English Language. 2nd ed. London: Penguin, 2002.
2012-01-07 Sat
■ #985. 中英語の語彙の起源と割合 [lexicology][loan_word][statistics][me][sggk]
[2011-08-20-1]の記事で「#845. 現代英語の語彙の起源と割合」を総括したが,中英語の語彙の内訳はどうだったのだろうか.これについても様々な研究があるが,従来の統計では,古英語由来の語彙が60--70%,古仏語由来の語彙が22--30%,古ノルド語由来の語彙が8--10%,それ以外が1%未満という数値が出されている (Duggan 238) .
ところが,Norman Hinton が1980年代後半から発表している中英語語彙の大規模な調査の報告によれば,従来の統計とは相当に異なる数値が示されている.Hinton の論文は未入手なので,以下は Hinton の報告そのものではなく,Duggan (238--39) で言及されているその概要に基づくものだが,参考までに要約する.
MED からランダムに取り出した数千語の見出し語とその語源情報に基づいて語種を分類した結果,Germanic 35.06%, Romance 64.54%, Other 0.35% という数値がはじき出された.従来の統計と比べると Germanic と Romance の数値が逆転しているかのようであり,統計の前提や手法によって,これほどまでに結果が左右されるものかと恐ろしくなる.いずれの統計も,眉に唾を付けて解釈しなければならないことは認めつつ,先を続けよう.
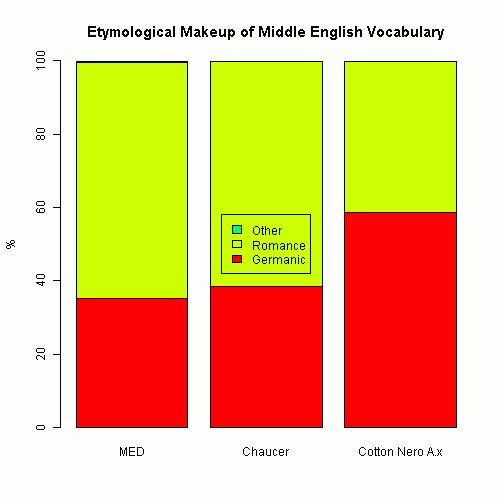
Hinton は,Chaucer や Cotton Nero A.x の言語についても語彙分類を行なっており,中英語の特定の時期における語彙の平均的な内訳と比較することによって,各言語の「年代測定」を試みている.Chaucer の語彙内訳は Germanic 38.5%, Romance 61.2%, Other 0.09% という比率であり,これは1460年の平均的な比率に相当するという.また,Cotton Nero A.x については Germanic 58.7, Romance 41%, Other 0.15% という比率で,1390年の平均的な比率を指すという.これはもちろん理論値であり,絶対年代を指すわけではない.むしろ,Chaucer と Cotton Nero A.x の70年という相対的な差が,それぞれの語彙の使い分けの差,そしておそらくは文体的な差に対応しているかもしれないという可能性がおもしろい.
・ Duggan, H. N. "Meter, Stanza, Vocabulary, Dialect". Chapter 8 of A Companion to the Gawain-Poet. Ed. Derek Brewer and Jonathan Gibson. Cambridge: Brewer, 1997. 221--42.
・ Hinton, Norman "The Language of the Gawain-Poems." Arthurian Interpretations 2 (1987): 83--94.
2011-11-16 Wed
■ #933. 近代英語期の英語話者人口の増加 [statistics][demography]
英語話者人口については共時的,通時的な側面から demography のいくつかの記事で取り上げてきた.特に以下を参照.
・ [2009-10-17-1]: #173. ENL, ESL, EFL の話者人口
・ [2010-03-12-1]: #319. 英語話者人口の銀杏の葉モデル
・ [2010-05-07-1]: #375. 主要 ENL,ESL 国の人口増加率
・ [2010-06-15-1]: #414. language shift を考慮に入れた英語話者モデル
・ [2010-06-28-1]: #427. 英語話者の泡ぶくモデル
通時的な英語話者人口の推移については,諸文献で様々な推測値が概数として挙げられている.[2010-03-12-1]の「銀杏の葉モデル」の図中に示されている数値もその一つである.値は大きく異ならないが,『英語史総合年表』に記されている概数をもとに,人口の推移グラフを作成してみた.1500年から1900年までの100年刻みでの人口統計である.
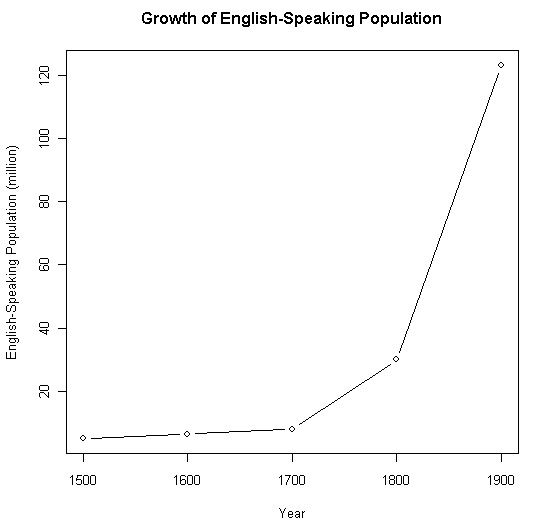
| Year | English-Speaking Population |
|---|---|
| 1500 | about 5 million |
| 1600 | about 6--7 million |
| 1700 | about 8 million (including about 2 million that had emigrated to the New World) |
| 1800 | 20--40 million |
| 1900 | about 123 million |
19世紀の爆発的増加が視覚的に表わされている.そして,20世紀のさらなる爆発により,2000年の段階で,上のグラフの高さを10倍にしても足りないほどの話者数を示すことになる.現在,第2言語話者,外国語話者を合わせて,英語を話す人口は15--20億と推定されている.
・ 寺澤 芳雄,川崎 潔 編 『英語史総合年表?英語史・英語学史・英米文学史・外面史?』 研究社,1993年.
2011-10-28 Fri
■ #914. BNC による語彙の世代差の調査 [bnc][corpus][statistics][lltest][interjection]
昨日の記事「#913. BNC による語彙の男女差の調査」 ([2011-10-27-1]) で取りあげた Rayson et al. では,話者の性別だけでなく年齢による語彙の変異も調査されている.年齢差といっても,35歳未満か以上かで上下の世代に分けた大雑把な分類だが,結果はいくつかの興味深い示唆を与えてくれる.以下は,χ2 の上位19位までの一覧である (142--43) .
| Rank | Under 35 | Over 35 | ||
| Word | χ2 | Word | χ2 | |
| 1 | mum | 1409.3 | yes | 2365.0 |
| 2 | fucking | 1184.6 | well | 1059.8 |
| 3 | my | 762.4 | mm | 895.2 |
| 4 | mummy | 755.2 | er | 773.8 |
| 5 | like | 745.2 | they | 682.2 |
| 6 | na as in wanna and gonna | 712.8 | said | 538.3 |
| 7 | goes | 606.6 | says | 443.1 |
| 8 | shit | 410.1 | were | 385.8 |
| 9 | dad | 403.7 | the | 352.2 |
| 10 | daddy | 380.1 | of | 314.6 |
| 11 | me | 371.9 | and | 224.7 |
| 12 | what | 357.3 | to | 211.2 |
| 13 | fuck | 330.1 | mean | 155.0 |
| 14 | wan as in wanna | 320.6 | he | 144.0 |
| 15 | really | 277.0 | but | 139.0 |
| 16 | okay | 257.0 | perhaps | 136.0 |
| 17 | cos | 254.4 | that | 131.3 |
| 18 | just | 251.8 | see | 122.1 |
| 19 | why | 240.0 | had | 118.3 |
予想される通り,若い世代に特徴的なキーワードはくだけた語を多く含んでいる.表外の語も含めてだが,yeah, okay, ah, ow, hi, hey, ha, no, ooh, wow, hello などの間投詞,fucking, shit, fuck, crap, arse, bollocks などのタブー語が目立つ.しかし,若い世代のキーワードとして,一見すると予想しがたい語も挙がる.例えば,please, sorry, pardon, excuse などの丁寧語が若い世代に特徴的だという.
ほかには,若い世代に特徴的な形容詞や副詞がいくつか見られる (ex. weird, massive, horrible, sick, funny, disgusting, brilliant, really, alright, basically) .評価を表わす形容詞・副詞が多く,一種の流行とみなすことができる語群だろう.年齢差を "apparent time" の差と考えれば,そこには "real time" の変化が示唆されることになるので,この語群の通時的な頻度の増加を探るのもおもしろそうだ.
・ Rayson, Paul, Geoffrey Leech, and Mary Hodges. "Social Differentiation in the Use of English Vocabulary: Some Analyses of the Conversational Component of the British National Corpus." International Journal of Corpus Linguistics 2 (1997): 133--52.
2011-10-27 Thu
■ #913. BNC による語彙の男女差の調査 [bnc][corpus][statistics][lltest][interjection][gender_difference]
標題の話題を扱った Rayson et al. の論文を読んだ.BNC の中で,人口統計的な基準で分類された,話し言葉を収録したサブコーパス(総語数4,552,555語)を対象として,語彙の男女差,年齢差,社会的地位による差を明らかにしようとした研究である.これらの要因のなかで,語彙的変異が統計的に最も強く現われたのは性による差だったということなので,本記事ではその結果を紹介したい.
まず,以下に挙げる数値の解釈には前提知識が必要なので,それに触れておく.BNC に収録された話し言葉は志願者に2日間の自然な会話を Walkman に吹き込んでもらった上で,それを書き起こしたものであり,その志願者の内訳は男性73名,女性75名である.会話に登場する志願者以外の話者についても,女性のほうが多い.したがって,当該サブコーパスへの参加率でいえば,全体として女性が男性よりも高くなることは不思議ではない.
しかし,その前提を踏まえた上でも,全体として女性のほうがよく話すということを示唆する数値が出た.使用された word token 数でいえば,男性を1.00とすると女性が1.51,会話の占有率では,男性を1.00とすると女性は1.33だった.男女混合の会話では男性のほうが高い会話占有率を示すとする先行研究があるが,BNC のサブコーパスでは女性同士の会話が多かったということが,上記の結果の背景にあるのかもしれない.いずれにせよ,興味深い数値であることは間違いない.
次に,より細かく語彙における男女差を見てみよう.男女差の度合いの高いキーワードを抜き出す手法は,原理としては[2010-03-10-1], [2010-09-27-1], [2011-09-24-1]の記事で紹介したのと同じ手法である.男性コーパスと女性コーパスを区別し,それぞれから作られた語彙頻度表を突き合わせて統計的に処理し,カイ二乗値 (χ2) の高い順に並び替えればよい.以下は,上位25位までの一覧である (136--37) .
| Rank | Characteristically male | Characteristically female | ||
| Word | χ2 | Word | χ2 | |
| 1 | fucking | 1233.1 | she | 3109.7 |
| 2 | er | 945.4 | her | 965.4 |
| 3 | the | 698.0 | said | 872.0 |
| 4 | year | 310.3 | n't | 443.9 |
| 5 | aye | 291.8 | I | 357.9 |
| 6 | right | 276.0 | and | 245.3 |
| 7 | hundred | 251.1 | to | 198.6 |
| 8 | fuck | 239.0 | cos | 194.6 |
| 9 | is | 233.3 | oh | 170.2 |
| 10 | of | 203.6 | Christmas | 163.9 |
| 11 | two | 170.3 | thought | 159.7 |
| 12 | three | 168.2 | lovely | 140.3 |
| 13 | a | 151.6 | nice | 134.4 |
| 14 | four | 145.5 | mm | 133.8 |
| 15 | ah | 143.6 | had | 125.9 |
| 16 | no | 140.8 | did | 109.6 |
| 17 | number | 133.9 | going | 109.0 |
| 18 | quid | 124.2 | because | 105.0 |
| 19 | one | 123.6 | him | 99.2 |
| 20 | mate | 120.8 | really | 97.6 |
| 21 | which | 120.5 | school | 96.3 |
| 22 | okay | 119.9 | he | 90.4 |
| 23 | that | 114.2 | think | 88.8 |
| 24 | guy | 108.6 | home | 84.0 |
| 25 | da | 105.3 | me | 83.5 |
必ずしもこの25位までの表からだけでは読み取れないが,Rayson et al. (138--40) によれば以下の点が注目に値するという.
・ "four-letter words",数詞,特定の間投詞は男性に特徴的である (ex. shit, hell, crap; hundred, one, three, two, four; er, yeah, aye, okay, ah, eh, hmm)
・ 女性人称代名詞,1人称代名詞,特定の間投詞は女性に特徴的である (ex. she, her, hers; I, me, my, mine; yes, mm, really) (男性代名詞の使用には特に男女差はない)
・ the や of の使用は男性に多い(男性に一般名詞を用いた名詞句の使用が多いという別の事実と関連するか?)
・ 固有名詞,代名詞,動詞は女性に多い(男性の事実描写 "report" の傾向に対する女性の関係構築 "rapport" の傾向の現われか?)
・ 固有名詞のなかでも,人名は女性の使用が多く,地名は男性の使用が多い.
他のコーパスによる検証が必要だろうが,この結果と解釈に興味深い含蓄があることは確かである.
キーワードの統計処理と関連して,コーパス言語学でカイ二乗検定の代用として広く使用されるようになってきた Log-Likelihood 検定については,自作の Log-Likelihood Tester, Ver. 1 や Log-Likelihood Tester, Ver. 2 を参照.
・ Rayson, Paul, Geoffrey Leech, and Mary Hodges. "Social Differentiation in the Use of English Vocabulary: Some Analyses of the Conversational Component of the British National Corpus." International Journal of Corpus Linguistics 2 (1997): 133--52.
2011-09-23 Fri
■ #879. Algeo の新語ソース調査から示唆される通時的傾向 [pde][word_formation][loan_word][statistics][lexicology][neologism]
連日の話題となっているが,Algeo と Bauer を比べているうちに俄然おもしろくなってきた新語ソース調査について (##873,874,875,876,877,878,879) .Algeo の詳細な区分 は,1963--72年の新語サンプル5000語に基づいたあくまで共時的な調査結果だが,いくつかの点で通時的な傾向を示唆しているように思える.Algeo 自身が言及あるいは議論している点について,以下に要約する.
(1) 新語の約3分の2 (63.9%) が,既存要素の合成,つまり複合 (compounding) と接辞添加 (affixation) により生じている.複合と接辞添加は特に古英語において新語形成の主要な手段だったと言及されることが多いが,現在英語においてもお得意の語形成であるという事実は変わっていない.
(2) 合成のなかでは,接辞添加 (34.1%) のほうが複合 (29.8%) よりも多い.前者のなかでは,接頭辞のほうが接尾辞より種類が多いものの,接尾辞は統語機能をそなえているために出現頻度が高く,より重要である.この意味で,英語は "a suffixing language" (272) である.
(3) 短縮 (shortening) は,客観的な証拠はないものの,"I suspect that the number of shortenings in English has increased greatly during the last two or three centuries" (271) .その理由としては,識字率向上の結果として生じた書き言葉の優勢を指摘している."Of the various kinds of shortening, the largest subgroup is that in which the shortening is based on the written form (acronyms, alphabetisms, and the like); this preeminence of the written language is clearly one of the consequences of increasing literacy" (272) .
(4) 英語において借用 (borrowing) は14世紀をピークとして衰退してきており,現在ではむしろ他言語へ単語を貸し出すソース言語としての役割が大きくなってきている.
もう1つ,詳細な区分では数値として表われていないが興味深い事実として,以下の点を指摘している.
. . . of the whole sample of new words, 76.7 percent are nouns, 15.2 percent adjectives, 7.8 percent verbs, and .3 percent other parts of speech. It seems that there are far more new things than new events to talk about. Whatever the case may be syntactically, in its lexicon, English is a nominalizing language. (272)
新語に名詞が多いという事実は驚くに当たらないかもしれない(英語語彙の品詞別割合については[2011-02-22-1], [2011-02-23-1]の記事を参照).英語が本当に "a nominalizing language" かどうかを検証するには,語彙全体における名詞の割合について通言語的に調査する必要があるだろう.それでも,Algeo のこの指摘は,Potter のいう現代英語の "noun disease" (100--05) という問題と関係しているかもしれないと考えると,興味をそそられる( "noun disease" については,[2011-09-04-1]の記事「#860. 現代英語の変化と変異の一覧」の1項目として挙げた).
最後に,影が薄くなってきている新語ソースとしての借用について,借用元言語として日本語がフランス語に次いで第2位であるという事実が注意をひく.日本語からの借用については,以下の記事を参照.
・ #45. 英語語彙にまつわる数値: [2009-06-12-1]
・ #142. 英語に借用された日本語の分布: [2009-09-16-1]
・ #126. 7言語による英語への影響の比較: [2009-08-31-1]
・ Algeo, John. "Where Do the New Words Come From?" American Speech 55 (1980): 264--77.
・ Potter, Simon. Changing English. London: Deutsch, 1969.
2011-09-22 Thu
■ #878. Algeo と Bauer の新語ソース調査の比較 [pde][word_formation][loan_word][statistics][lexicology][neologism]
今日も,現代英語の新語ソースに関する最近の一連の話題 (##873,874,875,876,877,878) の続き.[2011-09-19-1]の記事「#875. Bauer による現代英語の新語のソースのまとめ」で Bauer の調査結果をグラフ化したが,それに Algeo の調査結果を追加したものを作成した(原データと表はHTMLソースを参照).各項目で4本目の棒が,Algeo による Barnhart の新語辞書に基づく1963--1974年の数値を反映している.棒グラフとしては隣り合っているが,Algeo の調査対象年代は Bauer の第3期に包含されることに注意されたい.
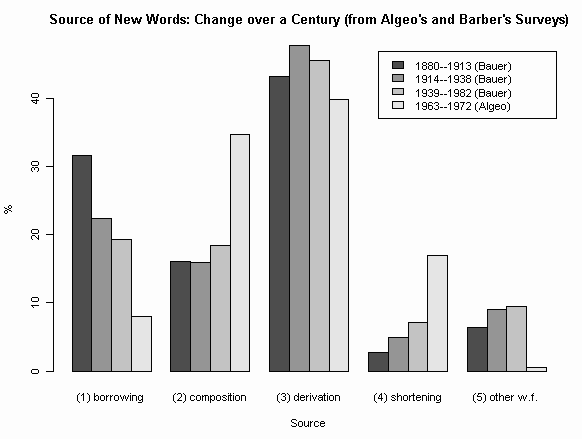
昨日の記事[2011-09-21-1]でも述べた通り,Bauer と Algeo の調査では前提がいくつか異なっている.特に Bauer では品詞転換が考慮に入れられていないので,比較条件を揃えるために,Algeo のデータから "Shifts" として区分されている数値を除いてあることにも注意されたい( "Shifts" は調査語彙全体の14.2%を占める小さくはない数値である.こちらの詳細区分を参照).また,Algeo の "Blends" は,今回のグラフ作成では "shortening" の一種として扱った.
Algeo の数値は Bauer の第3期の数値と開きこそあるが,新語ソースの傾向としてはおもしろいほどに一致している.Bauer の示唆する通時的な傾向が,Algeo によって著しく強調されて示されていると言ったらよいだろうか.比較基準の差異という問題は常について回るだろうが,互いに支持する結果となったのが興味深い.
・ Algeo, John. "Where Do the New Words Come From?" American Speech 55 (1980): 264--77.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
2011-09-21 Wed
■ #877. Algeo の現代英語の新語ソース調査 [pde][word_formation][loan_word][statistics][lexicology][neologism]
[2011-09-17-1], [2011-09-18-1], [2011-09-19-1]の記事で,Bauer (35, 38) による1880--1982年の約1世紀のあいだの新語ソースの変遷について触れてきた.現代英語の新語ソースの内訳が通時的にいかに変化してきたかに関する研究は他にあまり見たことがないが,共時的な内訳の調査であれば昨日の記事「#876. 現代英語におけるかばん語の生産性は本当に高いか?」 ([2011-09-20-1]) で触れた Algeo がある.
Algeo の調査は1963年以降の新語を収録した Barnhart の辞書から無作為抽出した1000語に基づくもので,時期区分で言えば Bauer の第3期(1939--82年)のおよそ後半に相当する時期の新語に関する調査ということになる.新語ソースの分類が Bauer に比べてずっと細かいのが特徴で,分類ラベルを眺めるだけでも形態論や語彙論の概要がつかめてしまいそうな細かさだ.また,Bauer は 品詞転換 (conversion) を調査対象に含めていないが,Algeo は "Shifts" の1部として含めている.ただし,この "Shifts" には意味変化の例も含まれており,新語の定義の問題(新語形のことなのか,あるいは新語義も含むのか)を考えさせられる.
Algeo の論文の Appendix (273--76) に掲載されている,詳細な新語ソース区分とその内訳の数値をこちらのページに転載したので,参照されたい.
上記のように Bauer と Algeo では調査対象とした辞書,時代,新語ソース区分,前提としている新語の定義が一致していないので直接比較はできないものの,両者の与える数値はいずれにせよ概数であるから,合わせて現代英語の新語ソースに関する傾向を示唆するものとして大いに参考になるだろう.
現代英語の新語については,[2011-01-16-1]の記事「#629. 英語の新語サイト Word Spy」を参照.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
・ Algeo, John. "Where Do the New Words Come From?" American Speech 55 (1980): 264--77.
・ Barnhart, Clarence L., Sol Steinmetz, and Robert K. Barnhart, eds. The Barnhart Dictionary of New English since 1963. Bronxville, N.Y.: Barnhart, 1973.
2011-09-20 Tue
■ #876. 現代英語におけるかばん語の生産性は本当に高いか? [blend][productivity][pde][pde_language_change][word_formation][statistics][lexicology]
[2011-01-18-1]の記事「#631. blending の拡大」で,現代英語においてかばん語が増加している件について取り上げた.かばん語は,現代英語の傾向の1つとして Leech et al. が指摘している "densification" (50) の現われと考えられそうである([2011-01-12-1]の記事「現代英語の文法変化に見られる傾向」を参照).多数のかばん語の例を示されれば,確かにさもありなんと直感されるところではある.しかし,[2011-09-17-1]の記事「#873. 現代英語の新語における複合と派生のバランス」で触れたとおり,Bauer の新語調査によれば,新語におけるかばん語の割合は1880--1982年の期間で p < 0.05 のレベルでも有意な増加を示していない(ただし絶対数は増加している).複数の観察者が指摘しており,私たちの直感にも適うかばん語の増加傾向と,客観的な統計値とのあいだに差があるのはどういうことだろうか.
1つには,Bauer の調査対象期間が1982年で終わっているということがあるだろう.当時の客観的状況と2011年の時点で私たちの抱いている直感とが食い違っていても不思議はない.この30年ほどの間に blending が激増したという可能性も考えられる.
もう1つ,直感と数値のギャップを説明し得る要因がある.この点に関して,Algeo の調査を紹介したい.多くの語彙研究が OED 系の辞書を利用しているが,Algeo はそれとは別系列の辞書を利用して独立した新語調査を行なった.彼の採った方法は,1963年以降の新語を収録した Barnhart の辞書から1000語を無作為抽出し,それをソースや語形成ごとに振り分けるというものである.その調査によると,かばん語は調査した新語語彙全体の4.8%を占めるにすぎず,他の主要な語形成のなかでは目立たないカテゴリーであるという結果となった.しかし,Algeo (271) はこの数値は過小評価だろうと述べている.
Last in numerical importance as a source of new words is blending. Less than a twentieth of our new words have been formed in that way (4.8 percent); however, blending is more popular than that statistic suggests. Its principal areas of use are popular journalism and advertising. Time magazine and Madison Avenue dearly love a blend. Most of the popular coinages are nonce forms that were unreported in the Barnhart dictionary and consequently are not included in these statistics. But every new word begins as a nonce form, so a source that is prolific of nonce forms today may be expected to increase its contribution to the general vocabulary tomorrow. Blending may look like a long shot, but the smart money will keep an eye on it.
"nonce-form" あるいは "nonce-word" (臨時語)に blending が多用されるというのは客観的に確かめにくいが,直感には適う.形態の生産性 (productivity) とは何を指すかという問題は,[2011-04-28-1], [2011-04-29-1], [2011-05-28-1]の記事でも触れてきたように,明確な解答を与えるのが難しい問題である.この問いは,何を(辞書に掲載するに値する)語とみなすかというもう1つの難問にも関係してくる([2011-03-28-1]の記事「#700. 語,形態素,接辞,語根,語幹,複合語,基体」を参照).blending の真の生産性は辞書や辞書に基づいた統計値には現われにくいが,言語使用の現場において活躍している語形成であることは恐らく間違いない.問題は,この主観的評価を,いかにして客観的に支持し得るかという方法の問題なのではないか.
・ Leech, Geoffrey, Marianne Hundt, Christian Mair, and Nicholas Smith. Change in Contemporary English: A Grammatical Study. Cambridge: CUP, 2009.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
・ Algeo, John. "Where Do the New Words Come From?" American Speech 55 (1980): 264--77.
・ Barnhart, Clarence L., Sol Steinmetz, and Robert K. Barnhart, eds. The Barnhart Dictionary of New English since 1963. Bronxville, N.Y.: Barnhart, 1973.
2011-09-19 Mon
■ #875. Bauer による現代英語の新語のソースのまとめ [loan_word][word_formation][lexicology][pde][pde_language_change][statistics][lexicology]
過去2日の記事[2011-09-17-1], [2011-09-18-1]で,Bauer の調査結果に基づいて新語のソースを概観した.類似した調査はそれほど多くないようなので,Bauer のデータ (35, 38) は貴重だと思い,もう少し分析してみた.(データは整理してHTMLソースに載せておいた.)
新語のソースを大きく2分すると,借用 (borrowing) と語形成 (word formation) のカテゴリーが得られる.借用は借用元言語によって数種類に下位区分され,語形成も主として形態論の観点から数種類に下位区分される.あまり細かく区分しても大きな傾向が見にくくなるので,借用は借用元言語を区別せず,語形成は4種類に大別し,(1) borrowing, (2) composition, (3) derivation, (4) shortening, (5) other word formations の5区分で集計しなおした.以下のグラフでは,ソースごとの3期にわたる割合の変化がつかみやすいように百分率で表示してある.例えば,第1期1880--1913年を示す黒棒の数値を足し合わせると100%となる,という読み方である.
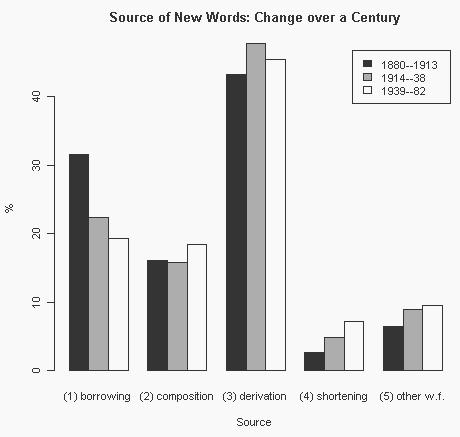
全体として,対象となった約100年間の通時的変化は p < 0.0001 のレベルで有意差が出た.そのなかでも借用の激減が最も顕著な変化である(同じく p < 0.0001 のレベルで有意).一方,各時期で合わせて6割ほどを示す composition と derivation の主要2カテゴリーは,時期によってそれほど変化していない( p < 0.05 レベルで有意差なし).また,全体での割合からすると目立たない shortening や他の語形成が順調に増加していることも見逃してはならない(shortening については,p < 0.001 のレベルで有意).カテゴリーの区別の仕方によって傾向の見え方も変化するので,同じデータを様々な角度から眺めることが必要だろう.
この3日間の記事のグラフをまとめてみられるように,3記事を「##873,874,875」で連結したので比較までに.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
2011-09-18 Sun
■ #874. 現代英語の新語におけるソース言語の分布 [loan_word][lexicology][pde][pde_language_change][statistics]
昨日の記事「現代英語の新語における複合と派生のバランス」 ([2011-09-17-1]) で取り上げた Bauer の調査は,現代英語の新語を構成する要素の起源,つまりソース言語をも考慮に入れている (32--33, 34--36) .(データはHTMLソースを参照.)
新語における借用比率は,1880--1913, 1914--38, 1939--82年の3期にわたり 31.4% -> 22.3% -> 19.2% と大きく目減りしている.現代英語においては,中英語や初期近代英語に比べ,全体的に借用に依存する程度が急減しているのがわかる.借用元言語ごとに状況を見てみよう.以下のグラフは,Bauer (35) に掲載されている表に基づいて作成したものである.
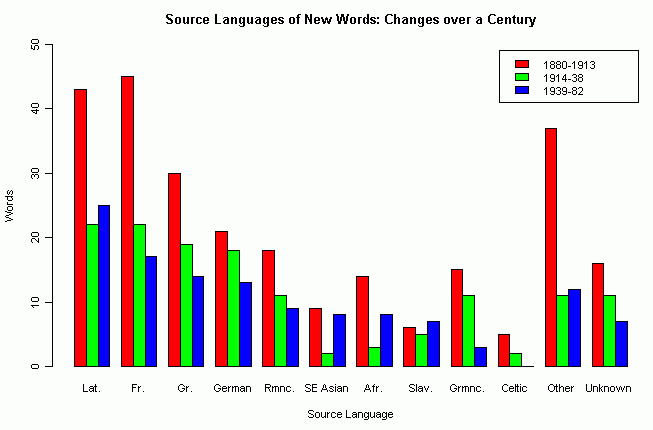
統計的には Fr. (French) と Grmnc (Other Germanic) において p < 0.05 のレベルで減少の有意差が認められるものの,特定のソース言語が全体的な減少に関与しているというよりは,ソース言語にかかわらず全般的に減少傾向が続いているものと読める.
注意すべきは,1880--1913年の Other カテゴリーが際立っていることだ.ここには,オーストラリア,ポリネシア,アメリカの土着言語からの借用が多く含まれているという.なぜこの時期にこれらの言語からの借用が多かったかという問題は,別途調査して考察する必要があるだろう.
Bauer の第3期の終了年である1982年より,約30年が経過している.以後,英語の借用離れは続いているのだろうか.これも興味深い問いである.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
2011-09-17 Sat
■ #873. 現代英語の新語における複合と派生のバランス [romancisation][compound][derivation][lexicology][pde][word_formation][productivity][statistics][pde_language_change]
英語語彙の歴史は,供給源という観点から,大雑把に次のように概括される.古英語では複合 (composition) と派生 (derivation) が盛んだったが,中英語から初期近代英語にかけては借用 (borrowing) が著しく,後期近代英語以降は再び複合と派生が伸張してきた.この語彙史の流れを受けて,現代は新語の供給源を,借用よりも既存要素(それ自体は本来語とは限らない)の再利用に多く負っている時代ということになる.では,現代英語を特徴づけるとされる複合と派生の2つの語形成では,どちらがより生産性が高いといえるだろうか.Potter (69--70) は,両者のバランスはよく取れていると評価している.
German and Dutch, like ancient Greek, make greater use of composition (or compounding) than derivation (of affixation). French and Spanish, on the other hand, like classical Latin, prefer derivation to composition. Present-day English is making fuller use of both composition and derivation than at any previous time in its history.
もちろん,両者のバランスが取れているからといって他言語よりも優れた言語ということにはまったくならない.ただし,ゲルマン語派とロマンス語派の語形成の特徴を兼ね備えていることにより,英語がいずれの立場からも「近い」言語と感じられるという効果はあるかもしれない(関連する議論は[2010-05-27-1]の記事「英語のロマンス語化についての評」を参照).ゲルマン系でもありロマンス系でもあるという現代英語の特徴は,語形成に限らず語彙全体にも言えることである.
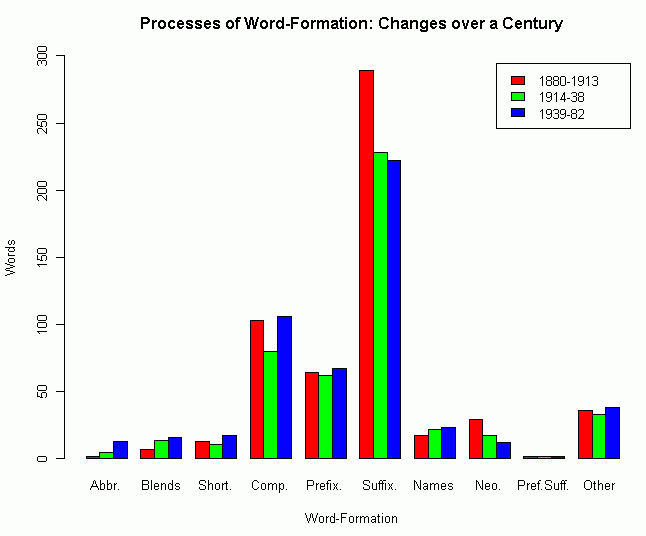
さて,Potter は上記のように複合と派生の好バランスを指摘したが,生産性を量的に測ったわけではなく,他の主要なヨーロッパ語あるいは古い英語との比較において評価したにすぎない.この点についてより客観的に調査したのが,Bauer (32--33, 36--39) だ.Bauer は The Supplement to the Oxford English Dictionary (1972--86) を用いた無作為標本調査で,対象に選ばれた本来語要素から成る新語1559語を初出年により (1) 1880--1913, (2) 1914--38, (3) 1939--82 の3期に区分して,造語法別に語を数えた.区別された造語法とは,Abbreviations, Blends, Shortenings, Compounds, Prefixation, Suffixation, Names, Neo-classical compounds, Simultaneous prefix and suffix, Other の10種類である.
Bauer (38) の掲げた表のデータを Log-Likelihood Tester, Ver. 2 に投げ込んで統計処理してみた(データはHTMLソースを参照;グラフは以下を参照.).全体として時期別の差は p < 0.05 のレベルで有意であり,分布の通時的変化が観察されると言ってよいだろう.次に造語法別に変化を見てみると,Abbreviations が p < 0.01 のレベルで有意な増加を示し,Suffixation と Neo-classical compounds がそれぞれ p < 0.05 のレベルで有意な減少を示した.その他の造語法については,3期にわたる揺れは誤差の範囲内ということになる.Bauer (37--38) は,Blends の増加を有意であると示唆しており,しばしば指摘される同趣旨の傾向を支持しているようだが,計算上は p < 0.05 のレベルでも有意差は認められなかったので注意が必要である([2011-01-18-1]の記事「blending の拡大」を参照).
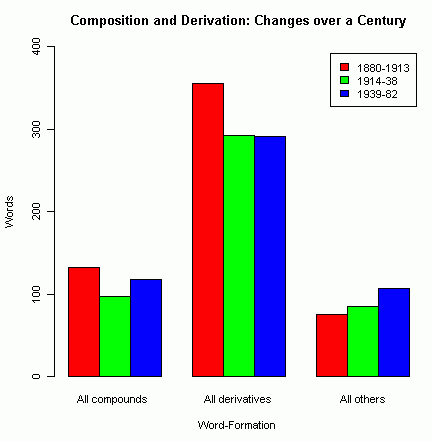
複合系 (Compounds, Neo-classical compounds) と 派生系 (Prefixation, Suffixation, Simultaneous prefix and suffix) で比べると,3時期を通じて後者の割合は前者の割合の2.7倍程度で圧倒している(以下のグラフを参照).数値的には,派生のほうにバランスが偏っているようだ.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
・ Potter, Simon. Changing English. London: Deutsch, 1969.
2011-08-29 Mon
■ #854. 船や国名を受ける代名詞 she (3) [personal_pronoun][she][gender][personification][political_correctness][corpus][statistics][lexical_diffusion]
標題について[2011-08-27-1], [2011-08-28-1]の記事で話題にしてきたが,現代英語でこの用法の she が《古風》となってきている,あるいは少なくともその register が狭まってきているのはなぜだろうか.
これには,1960年代以降,とりわけアメリカ英語で高まってきた言語の gender 論,男女平等という観点からの political correctness (PC) への関心がかかわっている.この観点から,人間の総称としての man(kind),女性接尾辞 -ess,職業人を表わす複合語要素 -man,一般人称代名詞としての he の使用などが疑問視され,数々の代替表現が提案されてきた.(関連する話題は,[2009-08-20-1]「男の人魚はいないのか?」, [2010-01-27-1]「現代英語の三人称単数共性代名詞」, [2011-04-17-1]「レトリック的トポスとしての語源」などの記事を参照.)
この観点から she の特殊用法を見ると,船や国名を取り立てて女性代名詞で受ける理由はないではないかという議論が生じる.船乗りや国の為政者が主として男性だったという英語国の歴史を反映していることは確かだろうが,現在も旧来の慣習を受け継ぐべき合理性はないという考え方である.
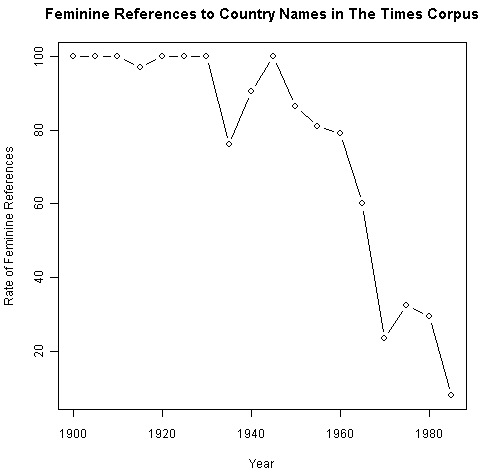
特に国名を受ける she の用法は,形式張った書き言葉という register に限ると,1960年代以降,激減してきていることが実証される.The Times corpus を用いてこれを検証した Bauer (148--49) によると,1930年までは国を指示する she の用法は標準的だった.実際,1900年から1930年の間で,国を指示する it の用例は3例のみだったという.ところが,1935年以降,it の例が断続的に現われだし,1970年にはshe を圧迫して一気に標準となった.she の用例が減少してきた過程は逆S字曲線を描いているかのようであり,語彙拡散 (lexical diffusion) を思わせる.以下のグラフは Bauer (149) のグラフに基づいて概数から再作成したものである.
・ Bauer, Laurie. Watching English Change: An Introduction to the Study of Linguistic Change in Standard Englishes in the Twentieth Century. Harlow: Longman, 1994.
2011-08-20 Sat
■ #845. 現代英語の語彙の起源と割合 [lexicology][loan_word][statistics][bnc][corpus]
現代英語の語彙における本来語と借用語の比率については,本ブログでも何度か取り上げてきた.いくつかリンクを張っておこう.
・ [2010-12-31-1]: #613. Academic Word List に含まれる本来語の割合
・ [2010-06-30-1]: #429. 現代英語の最頻語彙10000語の起源と割合
・ [2010-05-16-1]: #384. 語彙数とゲルマン語彙比率で古英語と現代英語の語彙を比較する
・ [2010-03-02-1]: #309. 現代英語の基本語彙100語の起源と割合
・ [2009-11-15-1]: #202. 現代英語の基本語彙600語の起源と割合
・ [2009-11-14-1]: #201. 現代英語の借用語の起源と割合 (2)
・ [2009-08-15-1]: #110. 現代英語の借用語の起源と割合
語種の数量的な調査には,数え挙げる際のソースを何にするか,type-count か token-count か,どのくらいの語彙規模を扱うか,語源にまつわる不正確さをどのように処理するか,などの考慮すべき事項が様々あり,研究者によって結果がまちまちとなることがある.しかし,複数の調査を比べれば,およその平均値や全体像が見えてくるのも確かである.
先日参加してきた ICOME7 (The Seventh International Conference on Middle English) で,8月4日,OED3 の主幹語源学者 Philip Durkin 氏が "Some neglected aspects of Middle English lexical borrowing from (Anglo-)French" と題する講演で関連する話題について触れていたので,要点をメモしておく.
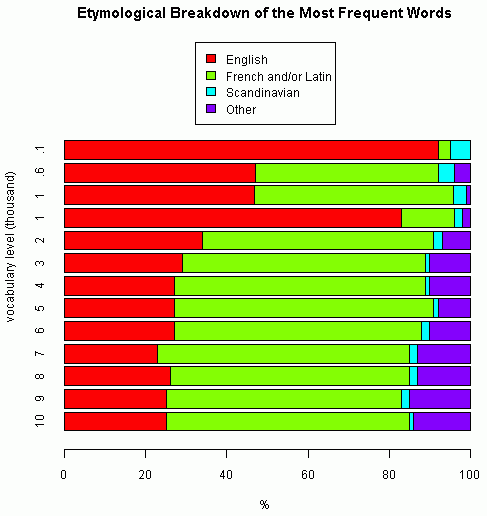
Durkin 氏は BNC から最頻1000語のリストを取り出し,語源分析した.その結果,英語本来語が489語,フランス・ラテン語が489語,ノルド語が32語,それ以外の言語が10語という数値が得られた.大規模コーパスの頻度リスト (see [2010-03-01-1]) を利用した語源調査はいつか自分でやろうと思っていたが,Durkin 氏のおかげでその労力を省くことができた(ありがとうございます!).
これにより,上記のリンクで示した諸調査と合わせて,type-count に基づく最頻100語,600語,1000語,2000語,3000語,4000語,5000語,6000語,7000語,8000語,9000語,10000語という12段階の語彙規模での語種別比率が得られたことになる.母体となる現代英語語彙の情報ソース,数え方,語種区分はそれぞれ異なっているのかもしれないが,一応の目安として以下で全体像を示したい.語種区分は English, French and/or Latin, Scandinavian, Other として4種類に統一した.
|
|
上から3つ目と4つ目の棒グラフは,同じ最頻1000語レベルでの比較だが,3つ目は上述の Durkin の BNC 調査によるもの,4つ目は[2010-06-30-1]の記事で示した Williams のものである.著しい差異が生じたが,これも調査方法が異なるがゆえだろうか.注意して解釈する必要があるが,この点を除けば全体としてなだらかに推移し,最終的には本来語25%,ラテン・フランス語60%,それ以外が15%という数値におよそ落ち着くようだ.
2011-07-20 Wed
■ #814. 名前動後ならぬ形前動後 [stress][diatone][statistics][derivation][prefix][suffix][phonaesthesia][-ate]
同綴りで品詞によって強勢位置の交替する語 (diatone) の典型例である「名前動後」については,[2009-11-01-1], [2009-11-02-1], [2011-07-07-1], [2011-07-08-1], [2011-07-10-1], [2011-07-11-1]の一連の記事で論及してきた.主に名詞と動詞の差異を強調してきたが,形容詞もこの議論に関わってくる([2011-07-07-1]の記事では関連する話題に言及した).強勢位置について,形容詞は原則として名詞と同じ振る舞いを示し,動詞と対置される.いわば「形前動後」である.
形前動後の事実は,まず統計的に支持される.Bolinger (156--57) によれば,3万語の教育用語彙集からのサンプル調査によると,多音節語について,形容詞の91%が non-oxytonic (最終音節以外に強勢がある)だが,動詞の63%が oxytonic (最終音節に強勢がある)であるという.単音節語については,強勢の位置が前か後ろかを論じることはできないしその意味もないが,単純に動詞と形容詞の個数の比率を取ると動詞が60.7%を占める.単音節語の強勢は通常 oxytonic と解釈されるので,この比率は形容詞に比して動詞の oxytonic な傾向を支持する数値といえよう.
形前動後という強勢位置の分布に関連して,Bolinger は両品詞の語形成上の差異に言及している.形容詞は接尾辞によって派生されるものが多いが (ex. -ant, -ent, -ean, -ial, -al, -ate, -ary, -ory, -ous, -ive, -able, -ible, -ic, -ical, -ish, -ful) ,動詞は接頭辞による派生が多い (ex. re-, un-, de-, dis-, mis-, pre-) .例外的にそれ自身に強勢の落ちる -ose のような形容詞接尾辞もあるが,例外的であることによってかえって際立ち,音感覚性 (phonaesthesia) に訴えかける 増大辞 ( augmentative ) としての機能を合わせもつことになっている(増大辞については[2009-08-30-1]の記事「投票と風船」も参照).bellicose, grandiose, jocose, otiose, verbose などの如くである.
当然のことながら,強勢のない接尾辞により派生された多くの形容詞は必ず non-oxytonic となるし,強勢のない接頭辞により派生された多くの動詞は強勢が2音節目以降に置かれることになり oxytonic となる可能性も高い.この議論を発展させるには,各接辞の生産性や派生語の実例数を考慮する必要があるが,接辞による派生パターンの相違が形前動後の出現に貢献したということであれば大いに興味深い.また,名詞の派生も,形容詞の派生と同様に,接頭辞ではなく接尾辞を多用することを考えれば,名前動後の説明にも同じ議論が成り立つのではないだろうか.
・ Bolinger, Dwight L. "Pitch Accent and Sentence Rhythm." Forms of English: Accent, Morpheme, Order. Ed. Isamu Abe and Tetsuya Kanekiyo. Tokyo: Hakuou, 1965. 139--80.
2011-06-07 Tue
■ #771. 名詞の単数形と複数形の頻度 [corpus][statistics][plural][countability]
Biber et al. (Section 4.5.6 [pp. 291--22]) に,一般名詞の単数形と複数形の頻度に関する記述がある.現代英語における大雑把な分布ではあるが,LSWE Corpus の500万語サブコーパスを用いた信頼できる数値なので参考までにメモしておく.まず,各サブコーパスで100万語当たりの生起数に換算してのグラフの再現から(数値データは与えられていなかったのでグラフから概数を読み取っての再現).
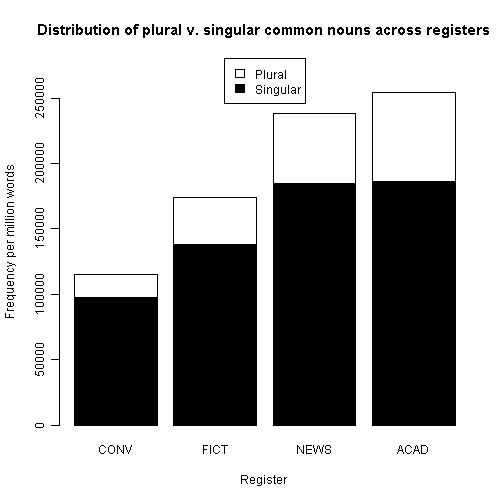
(1) conversation transcription (CONV), fiction text (FICT), newspaper text (NEWS), academic text (ACAD) の4サブコーパス間の差が激しい.
- 原則として複数形をとらない不可算名詞も含めているとはいえ,すべてのサブコーパスで単数形が複数形よりも頻度が高い.
- 会話では単数形の頻度が比較的高い.
- 書き言葉では話し言葉よりも複数形の頻度が3--4倍も高い.
(2) 個々の名詞でみると,多くの名詞が単数形あるいは複数形のいずれかへの強い偏りを示す.
(3) 例えば,次の名詞は75%以上の割合で単数形をとる.ex. car, god, government, grandmother, head, house, theory.
(4) 例えば,次の名詞は75%以上の割合で複数形をとる.ex. grandchildren, parents, socks, circumstances, eyebrows, onlookers, employees, perks.
(1) に関して,単数形が圧倒的に多いこと自体はまったく不思議ではない.上述のように不可算名詞は原則として単数形しかあり得ない.また,ほとんどの可算名詞では単数形が lemma そのものであるし無標の形態でもある.ほかには,数の概念が中立化される場合,例えば hand in hand, from time to time などの慣用表現においては,単数形が用いられるのが普通である.
(2)--(4) に関して,名詞によって単数形か複数形への偏りを示すというのも驚くに当たらない.それぞれの語群を眺めれば,そこに "the communicative needs of the language user" (291) が反映されていることがはっきりと分かるだろう.名詞全体をならせば,「コミュニケーション上の必要性」が単数形に偏りそうだということも直感される.
では,会話で単数形の使用が多いというのは,どういうわけだろうか.Biber et al. (291--92) は次のように述べている.
In general, the high frequency of singular nouns in conversation probably follows from the concern of speakers with individuals: a person, a thing, an event. Writers of academic prose, on the other hand, are more preoccupied with generalizations that are valid more widely (for people, things, events, etc.). This same tendency applies not only to nouns, but also to determiners and pronouns (4.4.3.1, 4.12.1, 4.14.1, 4.15.2.1).
コーパス全体としては,複数形は一般名詞の2割程度しか占めないことになる.複数形の研究を専門とする(つまり複数形の例をなるべく多く集めなければならない)私にとっては,なかなか厳しい数値だなあ・・・.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
2011-05-26 Thu
■ #759. 21世紀の世界人口の国連予測 [demography][statistics][elf]
2011年5月3日付けで国連の World Population Prospects: The 2010 Revision が公表された.プレスリリースのPDFはこちら.
これによると,世界人口は今年10月末までに70億人に達し,2050年には93億人,2100年には101億人に達するとされる.人口を押し上げる主因は高い出生率を示す国々で,これにはアフリカの39カ国,アジアの9カ国,オセアニアの6カ国,ラテンアメリカの4カ国が含まれるという.
主な国の数値を示すと,日本の人口は2010年の1億2600万人から2100年には約9130万人へ減少.中国の人口は1925年の約13億9500万人をピークに,2100年には約9億4100万人へ減少.インドの人口は,1925年に中国を追い抜き,1960年には17億1796万人に達し,2100年には約15億5000万人へ減少.
大規模な人口統計予測には多くの前提が含まれている.例えば,プレスリリースの標題にもあるように "if Fertility in all Countries Converges to Replacement Level" という前提がある.したがって解釈には注意を要するが,英語話者人口を推計する上でも,このような統計値は最重要である.[2010-05-07-1]の記事「主要 ENL,ESL 国の人口増加率」で取り上げた主要ENL国(7カ国;参考として日本を追加)とESL国(13カ国)について,2100年までの人口推移( medium variant に基づく)をグラフ化してみた.
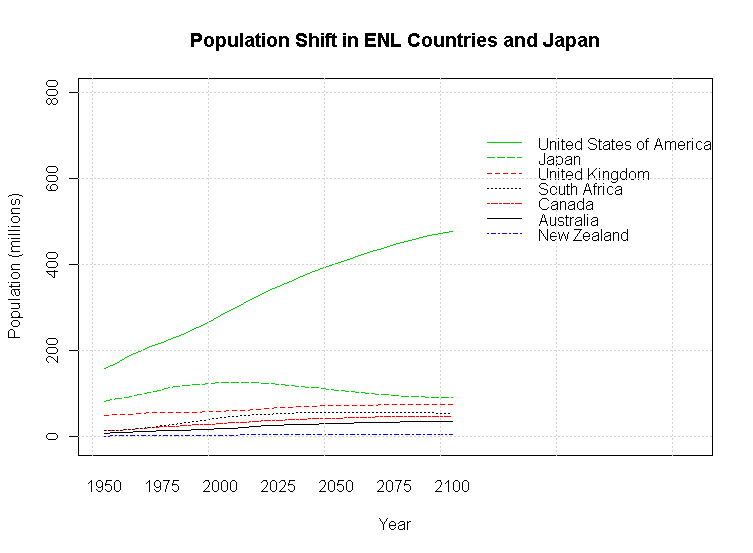
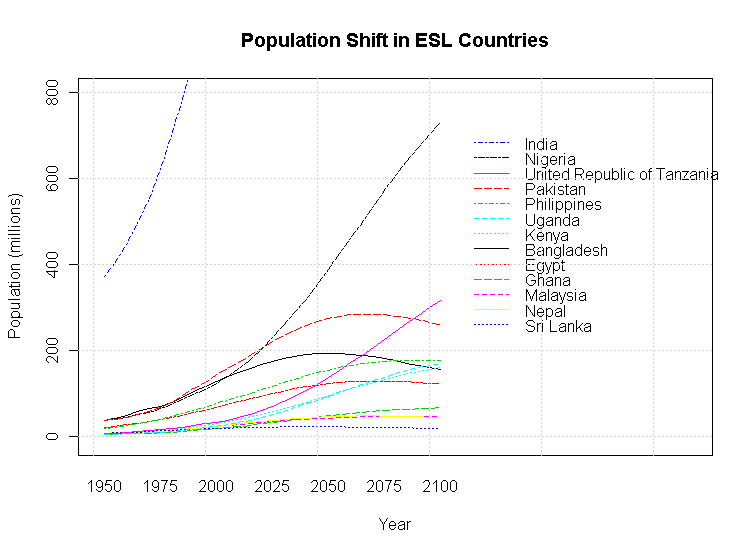
ENL国はアメリカを除いて今世紀は低迷の予測だ.一方,ESL国は今世紀半ばにかけて伸長著しく,後半も衰えにくい.インドは突き抜けており,ナイジェリア,パキスタン,タンザニアの勢いも目を見張るものがある.
国別の人口予測をもとに未来の英語話者の人口予測をすることは単純な作業ではないが,少なくともESL国の人口爆発力が具体的な予測に基づいて視覚的に確認されたとはいえるだろう.
英語話者人口については,[2010-06-28-1], [2010-06-15-1], [2010-05-29-1]の記事も参照.
2011-04-08 Fri
■ #711. Log-Likelihood Tester CGI, Ver. 2 [corpus][bnc][statistics][web_service][cgi][lltest]
以下に,汎用の Log-Likelihood Tester, Ver. 2 を公開.(後に説明するように,入力データのフォーマットに不備がある場合や,モードが適切に選択されていない場合にはサーバーでエラーが生じる可能性があるので注意.)
[2011-03-25-1]の記事で,コーパス研究でよく用いられる対数尤度検定 ( Log-Likelihood Test ) の計算機 Log-Likelihood Tester, Ver. 1 を公開した.Ver. 1 は,コーパスサイズを加味しながら2つのコーパスでのキーワード(群)の出現頻度を比べ,コーパス間の差が有意であるかどうかを検定するものだった.
Log-Likelihood Test は上述の目的で用いることが多いと思い,Ver. 1 ではあえて機能を特化させたのだが,より一般的に複数行,複数列の分割表で与えられるデータに対応する対数尤度検定を行ないたい場合もある.例えば,昨日の記事[2011-04-07-1]で,現代英語における though と although の出現傾向について BNC に基づいた調査を紹介したが,Text Domain ごとの頻度比率は,両語の間で統計的にどの程度一致している,あるいは一致していないとみなすことができるのだろうか.昨日のグラフから,although は学術散文に多く,though は創作散文に多いという傾向が一目瞭然だが,この直感的な「一目瞭然」は統計的にはどのように表現されるのだろうか.
このような場合には,次のような頻度表(値は100万語当たりの出現頻度に標準化済み)を準備し,これをコピーして入力ボックスに貼り付ける."lump mode" にチェックを入れ替え,"Go!" する.(デフォルトは "each-line mode" で,これは Ver. 1 と同等のモード.)
| though | although | |
|---|---|---|
| Natural and pure sciences | 56.3 | 80.13 |
| Applied science | 37.36 | 68.31 |
| World affairs | 45.81 | 68.2 |
| Social science | 48.98 | 63.38 |
| Commerce and finance | 46.18 | 57.21 |
| Arts | 74.07 | 52.93 |
| Leisure | 45.85 | 49.46 |
| Belief and thought | 70.78 | 46.75 |
| Imaginative prose | 80.2 | 26.37 |
結果は,1行だけの表として出力される.though と although を表わす2列の数値の並びが,統計的にどのくらい近似しているかを計算している.結論としては,両語の Text Domain ごとの頻度の並びの差は p < 0.0001 という非常に高いレベルで有意であり,両語の出現傾向は Text Domain によってほぼ確実に異なるといえる.
入力ボックスに入れるデータの書式は,タブ区切りの分割表.表頭と表側はいずれも省略可.サンプルのように表頭と表側の両方を含める場合には,左上のセルは空白にしておく必要あり.
"each-line mode" の機能は Ver. 1 と互換なので,入力形式もそちらの説明を参照.今回の Ver. 2 の "each-line mode" では,出力結果をシンプルにおさえてある(逆に,詳しい内部計算値を得たい場合には Ver. 1 のほうが有用).
Log-Likelihood Test の概要については,[2011-03-24-1]の記事を参照.
2011-04-07 Thu
■ #710. though と although の語法の差 (2) [bnc][corpus][lltest][conjunction][statistics]
昨日の記事[2011-04-06-1]で,though と although の語法の差に触れた.今日も同じ話題で.
4000万語超からなる The Longman Spoken and Written English Corpus (the LSWE Corpus) を駆使した現代英語の文法書,Biber et al. (845--46) では次のようにある.
Both of these subordinators [though and although] occur in all four registers [conversation, fiction, news, and academic prose], although the registers show different preferences of use. Conversation and fiction show a slightly greater use of though (concessive clauses are, however, uncommon in conversation generally). News shows no particular preference. In academic prose, although is about three times as frequent as though. Although seems to have a slightly more formal tone to it, fitting the style of academic prose . . . . The greater use of although by writers of academic prose may also result from an attempt to distinguish this subordinator from the common use of though as a linking adverbial in conversation . . . .
また,同書の p. 842 の表からは,相対的に though が fiction で多く,although は academic prose で多いことが確認される.ジャンルによる差が現われているとの結果だ.
このような先行研究を受けて,今回は BNC ( The British National Corpus ) によりこれを確かめてみる.BNCweb で,{although/CONJ}, {though/CONJ} をそれぞれ検索し,Written/Spoken, Text Domain, Sex of Author/Speaker, Perceived Level of Difficulty など様々なパラメータで出現分布を分析した.主立った結果を以下に示そう(数値データはこのページのHTMLソースを参照).
まず,Written/Spoken の差については,予想されるとおり,両語とも Written への偏りが激しい(差異係数は though で 0.66344 ,although で 0.49770 で,明らかに書き言葉に偏る).Log-Likelihood Test では,p < 0.0001 のレベルで書き言葉と話し言葉の有意差が明確に示された.
書き手,話し手の性による差も興味深い.書き言葉と話し言葉の両方で,although は有意差をもって男性の使用に偏っている.though については,性差は although ほど顕著ではない(ただし書き言葉では p < 0.05 で有意差あり).
次に,Text Domain 別に頻度をみる.9種類の Text Domain を区別した ( Natural and pure sciences, Applied science, World affairs, Social science, Commerce and finance, Arts, Leisure, Belief and thought, Imaginative prose ) .100万語当たりの出現回数に標準化した値で,両語の Text Domain 別頻度をグラフ化したのが以下の図だ.
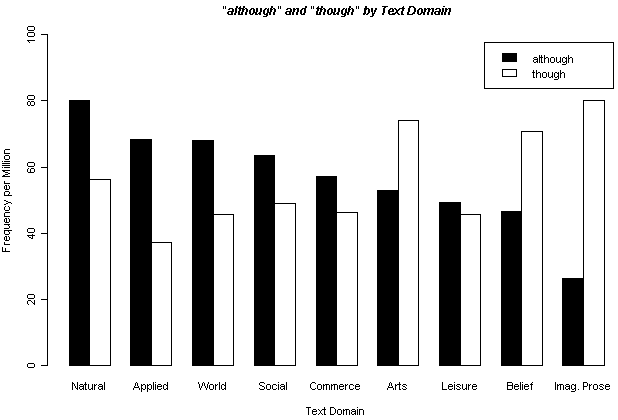
Text Domain によって両語の出現頻度に対照的な傾向が見られることがわかる.相対的に sciences ( = academic prose ) に although が目立ち,Imag(inative) Prose ( = fiction ) に though が多い.Log-Likelihood Test では,Text Domain による出現傾向の差は p < 0.0001 で有意である.
直感的にも先行研究の結果からも予想され得たことではあるが,although は男性の書き手により学術散文で顕著に用いられるという図式が現われた.
・ Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad, and Edward Finegan. Longman Grammar of Spoken and Written English. Harlow: Pearson Education, 1999.
Powered by WinChalow1.0rc4 based on chalow