2010-04-24 Sat
■ #362. 英語例文検索 EReK [corpus][kwic][web_service]
今日は軽くウェブ上のコンコーダンサーを紹介.英語例文検索 EReK は「英語で書かれたウェブページのテキストを巨大な例文集(コーパス)とみなし,それを検索するサイト」.Yohoo! の Web API が利用されている.出力は KWIC ( Key Word in Context ) で,百数十の例文が表示される.各コンコーダンス・ラインから,ワンクリックでソースに飛ぶことができるのも便利.また,キーワード前後の語での並べ替え機能や,検索対象を .edu ドメインや ニュースサイトに限定するオプションも装備されている.「ウェブ上の文書なので正確な表現である保証はありません」と但し書きがあるが,Web上の手軽なコンコーダンサーとして利用価値はありそうだ.
時々刻々と変化するウェブ・リソースを検索対象とするので一種の monitor corpus とも考えられ,時事を反映した出力が期待できる.例えば,2010年4月24日現在,ニュースサイト限定検索 "volcano" とやれば Iceland や Icelandic と共起するコンコーダンス・ラインが大量に得られる.( see [2010-04-20-1]. )
姉妹版で日本語版の JReK もあり,こちらは日本語の文章書きに効果を発揮しそう.
2010-04-16 Fri
■ #354. COLT:ロンドンの十代の若者話し言葉コーパス [corpus][colt][lexicology][syllable]
少し変わり種のコーパスとして,COLT: The Bergen Corpus Of London Teenage Language を紹介する.1993年におけるロンドンの若者(13歳から17歳)の話し言葉を収集したコーパスで,約50万語からなる.31人のロンドン各地・各階層の男子女子の会話を,合計50時間だけ録音し,文字に起こしたものである.BNC ( The British National Corpus ) にも組み込まれているコーパスだ.語類情報や休止などの韻律情報がタグ付けされており,若者言葉によって先導される言語変化の調査や語用論的な研究において実績がある.
コーパス自体は有料だが,上記のHPから手に入る COLT による最頻1000語のリスト が目を引いた.COLT に現れる表記語 ( graphic word ) の最頻リストで,lemmatise されていない.要するに,do と did,laugh と laughing などは別々にカウントされている.
今回,このコーパスに目を付けたのは,先日[2010-04-10-1], [2010-04-11-1]でパイロット・スタディとしておこなった「BNC Word Frequency List による音節数の分布調査」の COLT 版を試してみようと思ったからである.BNC による音節数分布調査では,書き言葉と話し言葉の両方を対象とし,lemmatise された基底形 ( base form ) での頻度表を用いたが,COLT を用いれば,大きく異なった条件のもとで類似した調査をおこなうことができる( COLT が BNC の一部になっていることを考慮しても).具体的には,話し言葉に限定された,表記語に基づく頻度表をベースとして音節数の分布を調べられる.
注意を要するのは,COLT の頻度表には unclear, nv, singing など,地の文の語ではなくタグ名として使われている語もうっかり数えられてしまっていることだ.したがって,この種の語は手作業で除去し,最終的に有効最頻語976語のリストが得られた.これをもとにして,音節数の分布をいざ探ってみることにする.結果は,明日.
2010-03-23 Tue
■ #330. Cobuild Concordance and Collocations Sampler [corpus][bnc][cobuild][collocation]
本ブログでは,オンラインで利用できる現代英語のコーパスとして,簡便に使える BNC ( The British National Corpus ),より本格的に使える BNCWeb(要無料登録)を紹介してきた.BNC はその名の如くイギリス英語専門のコーパスで,ほぼ1975年以降の英語が約1億語おさめられている.そのうち9割は書き言葉,1割は話し言葉という構成である.現在オンラインで利用できる最大級の規模の英語コーパスである.
規模だけでいえば,もっと大きな英語コーパスが存在する.常に拡大を続けるモニターコーパス The Bank of English であり,その規模は5億5000万語にまで達する.BNC と異なり,イギリス英語だけでなくアメリカ英語を含めた他の変種もカバーしている.
このうちの一部,約5600万語が Cobuild Concordance and Collocations Sampler としてオンラインで無料で公開されている.コンコーダンス・ラインは40行まで,コロケーションのスコア・ランキングは100位までしか出力されない「デモ版」ではあるが,検索語に簡単なタグ指定ができるなど,手軽な目的であれば十分に使える仕様だろう(有料版 Collins WordbanksOnline もあり).
コロケーションのスコアとしては,T-score か MI ( Mutual Information ) かを選べる.[2010-03-04-1]でも触れたが,それぞれのスコアの特徴を簡単に述べる.
・ MI (mutual information): 共起する2語が持つ意味的特性に焦点が当てられる傾向がある.慣用句,ことわざ,複合語,専門用語など独特の言い回しを構成する語に高い値が与えられる.コーパスのサイズに依存しない.3以上の値をもって collocate しているとみなせるといわれる.イメージとしては,連想ゲーム的な語と語の関係が明らかになると考えるとよい ( = lexical collocation ).低頻度語が強調される傾向があり,独特でおもしろい結果になることがある.
・ T-score: collocation 強度そのものの指標というよりも,互いに関連があると言い切れる確信度の指標.コーパスのサイズが勘案されている.通常は,2以上の値でその collocation が統計的に有意とみなされる.特定の2語の共起頻度に焦点を当てるため,キーワードの前後に頻繁に生起する前置詞,不変化詞,人称代名詞,限定詞などの文法構造を満たすための語のほか,常套句や使い古されてしまった比喩,決まり文句などを構成する語が上位にランクインする.イメージとしては,主に文型や機能語の連語情報が明らかになると考えるとよい ( = grammatical collocation ) .
コンコーダンスやコロケーションの出力は,英語の研究や学習のためだけでなく,汎用の発想ツール,連想ツールとしても使える.例えば,octopus のコロケーションの MI 値を出してみると,上位に squid, dried, october などが現れる.味わい深い.
・ 鷹家 秀史,須賀 廣 『実践コーパス言語学』 桐原ユニ,1998年.113--15頁.
2010-03-10 Wed
■ #317. 拙著で自分マイニング(キーワード編) [text_tool][flob][corpus][keyword]
昨日の記事[2010-03-09-1]に引き続き,拙著 The Development of the Nominal Plural Forms in Early Middle English で自分マイニング.WordSmith には KeyWords 抽出機能がある.単に単語リストを頻度順に並べた昨日のリストでもおよそのテキストの主題を読み取ることは可能だが,上位に機能語などの雑音が大量に入り込み,解釈しにくい.それに対して,キーワードリストでは対象テキストの主題をよく表す実質的なキーワードが上位に来るので,解釈しやすい.
考え方としては以下の通りである.巨大なコーパスなどを参照テキストとして使用し,そこから単語ごとに一般的な頻度を導き出す.次に,対象テキスト内で各単語について頻度を出す.ある語の対象テキスト内での頻度が,参照テキスト内での頻度よりも相当に大きい場合には,それは対象テキストに特有のキーワードとみなせる.そのようなキーワードを自動的に探し出してくれるのが,WordSmith の KeyWords 抽出機能である.拙著はイギリス英語で書いていることもあり,参照テキストとしては FLOB ( Freiburg-LOB corpus ) を使用した.以下,上位50語のキーワードである.
plural, english, s, n, old, nouns, norse, dialect, midland, middle, plurals, dialects, texts, language, forms, text, ending, diffusion, v, south, west, nominative, early, stem, the, spread, linguistic, singular, endings, inflectional, contact, accusative, o, system, weak, in, development, sec, change, fem, dative, morphological, languages, saxon, item, formation, period, transfer, germanic, strong
ずばり来てくれました plural .複数形の研究なのでそうでなければ困るところだ.昨日のリストよりも機能語の雑音がよくはじかれている.
WordSmith には各キーワードのファイル内での出現箇所を視覚的にプロットする機能もあり,上記の50語について以下のようなプロットが得られた.
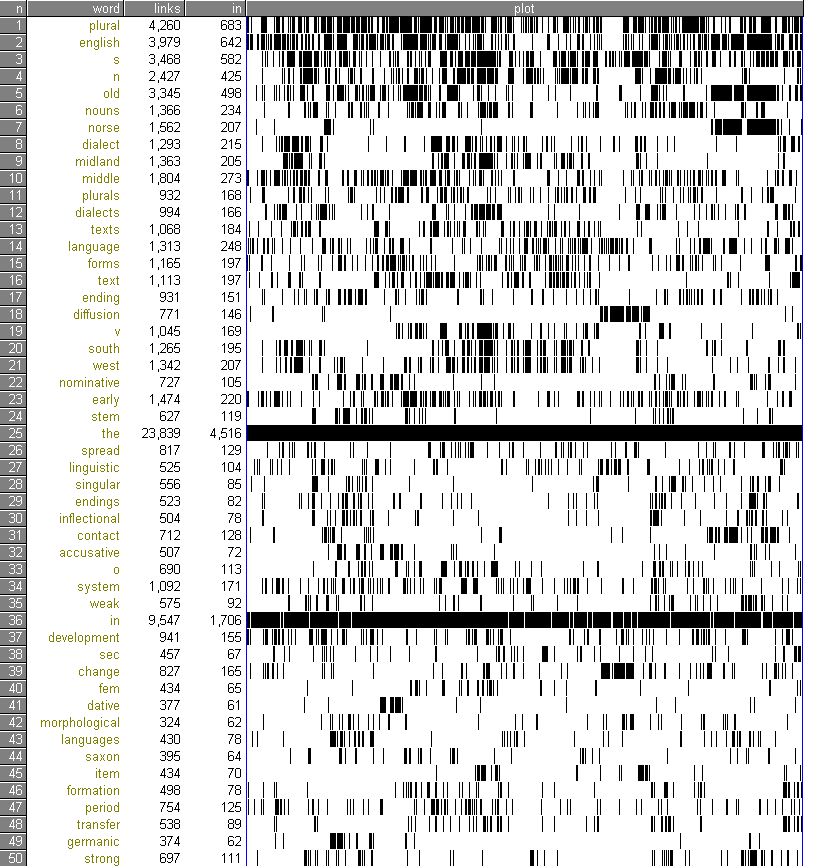
執筆者本人なので,なるほどと思えることが多い.最上位語はテキスト中にまんべんなく現れる傾向があるが,それでも分布が偏っているものもある.7位の norse は Old Norse について論じている7章に固まっているし,18位 diffusion は Lexical Diffusion を集中的に扱っている5章に集中している.
われながらの発見もあった.言語変化を論じているので development と change を多用しているが,執筆中にはそれほど意識して両語を使い分けていたわけではなかった.そうであればまんべんなく分布していそうなものだが,実際には change が5章辺りに偏在している.ということは,無意識のうちに使い分けていたということなのだろうか.無意識の癖とでもいうべきものが発見できておもしろい.
文章をこのように分析することで,実用的な効果がいろいろ考えられそうである.思いつきを記す.
・ 文体の統計を把握することで今後の文章改善に活かす(誰々の文体に近づきたい,ボキャ貧をなおしたい,パラグラフ構成の指針をもちたい,など)
・ 自分の過去の文章と比較し,文体の経年変化を観察する
・ 論文などを書き終えた後でタイトル候補が複数ある場合に,キーワードを参考にして決定する
・ 自分の過去の論文などをひっくるめて分析対象とし,「私の研究テーマは(キーワード)です」と言い切れるようになる
・ 相手の過去の論文などをひっくるめて分析対象とし,「あなたの研究テーマは(キーワード)です」と言い切れるようになる(←おせっかい)
・ 緩やかに関連する二つの論文 A と B を互いに参照テキストとしてそれぞれのキーワードを抽出し,A の特徴と B の特徴を比べる.共通点が多いことを前提としているので,キーワードによって逆に相違点が浮き彫りになる可能性がある.
2010-03-07 Sun
■ #314. -ise か -ize か (2) [spelling][bre][bnc][lob][flob][corpus][suffix][z]
[2010-02-26-1]の記事で取りあげた話題の続編.先日の記事では,単語によって比率は異なるものの,イギリス英語では -ise と -ize の両方の綴字が行われることを,BNC に基づいて明らかにした.高頻度20語については,おおむね -ise 綴りのほうが優勢ということだった.
通時的な観点がいつも気になってしまう性質なので,そこで新たな疑問が生じた.-ise / -ize のこの比率は,過去から現在までに多少なりとも変化しているのだろうか.大昔までさかのぼらないまでも,現代英語の30年間の分布変化だけを見ても有意義な結果が出るかもしれないと思い,1960年代前半のイギリス英語を代表する LOB ( Lancaster-Oslo-Bergen corpus ) と1990年代前半のイギリス英語を代表する FLOB ( Freiburg-LOB corpus ) を比較してみることにした.
それぞれのコーパスで,前回の記事で取りあげた頻度トップ20の -ise / -ize をもつ動詞について,その変化形(過去形,過去分詞形,三単現の -s 形,-ing(s) )を含めた頻度と頻度比率を出してみた(下表参照).
| item | LOB: rate (freq) | FLOB: rate (freq) | ||
| -ise | -ize | -ise | -ize | |
| recognise | 59.6% (99) | 40.4% (67) | 71.8% (127) | 28.2% (50) |
| realise | 63.2% (134) | 36.8% (78) | 68.7% (125) | 31.3% (57) |
| organise | 65.6% (42) | 34.4% (22) | 67.2% (43) | 32.8% (21) |
| emphasise | 37.7% (20) | 62.3% (33) | 62.9% (39) | 37.1% (23) |
| criticise | 52.0% (13) | 48.0% (12) | 80.0% (24) | 20.0% (6) |
| characterise | 0.0% (0) | 100.0% (4) | 56.3% (18) | 43.8% (14) |
| summarise | 35.3% (6) | 64.7% (11) | 64.7% (11) | 35.3% (6) |
| specialise | 56.3% (18) | 43.8% (14) | 81.8% (27) | 18.2% (6) |
| apologise | 68.8% (11) | 31.3% (5) | 70.6% (12) | 29.4% (5) |
| advertise | 100.0% (41) | 0.0% (0) | 100.0% (55) | 0.0% (0) |
| authorise | 77.4% (24) | 22.6% (7) | 68.2% (15) | 31.8% (7) |
| minimise | 90.0% (9) | 10.0% (1) | 80.0% (16) | 20.0% (4) |
| surprise | 100.0% (182) | 0.0% (0) | 100.0% (173) | 0.0% (0) |
| supervise | 100.0% (10) | 0.0% (0) | 100.0% (9) | 0.0% (0) |
| utilise | 70.0% (7) | 30.0% (3) | 83.3% (5) | 16.7% (1) |
| maximise | 50.0% (2) | 50.0% (2) | 50.0% (9) | 50.0% (9) |
| symbolise | 50.0% (3) | 50.0% (3) | 40.0% (4) | 60.0% (6) |
| mobilise | 66.7% (2) | 33.3% (1) | 20.0% (1) | 80.0% (4) |
| stabilise | 58.3% (7) | 41.7% (5) | 33.3% (3) | 66.7% (6) |
| publicise | 81.8% (9) | 18.2% (2) | 84.6% (11) | 15.4% (2) |
いずれも100万語規模のコーパスなので,トップ20とはいっても下位のほうの語の頻度はそれほど高くない.だが,全体的な印象としては,-ise の綴字が30年のあいだにじわじわと増えてきているようである.頻度比率に大きな変化の見られないものも確かにあるが,著しく伸びたものとして emphasise, criticise, characterise, summarise, specialise などがある.ただ,これはあくまで印象なので,全体的に,あるいは個別の単語について統計的な有意差があるのかどうかは別に検証する必要がある.また,LOB には characterise は一例も例証されないが characterisation は確認されたことからも,動詞だけでなく名詞形の -isation / -ization も合わせて調査する必要がある.さらには,対応するアメリカ英語の状況も調査し,イギリス英語の通時的変化(もしあるとすればであるが)と関係があるのかどうかを探る必要がある.
2010-03-04 Thu
■ #311. girl とよく collocate する形容詞は何か [corpus][collocation][bnc]
コーパスを使った collocation 研究は多い.しかし自分では行ったことがなかったので,McEnery et al. (56--57, 210--20) を参考にしつつ,自らお題を一つ掲げて collocation 研究のさわりを試してみた.特に collocation にかかわる様々な統計指標の特徴に注意してみたい.
お題は「girl とよく collocate する形容詞は何か」.使用するコーパスは BNCWeb .girl の左側3語までに現れる形容詞を検索対象とし,collocation の強度を示す様々な指標を出して,指標ごとに上位20個までの形容詞を一覧にしたのが下表である.
| Rank | raw frequency | observed/expected | t-score | z-score | log-likelihood | MI | MI3 |
|---|---|---|---|---|---|---|---|
| 1 | little | 15-year-old | little | little | little | 15-year-old | little |
| 2 | young | 16-year-old | young | young | young | 16-year-old | young |
| 3 | that | dark-haired | good | 15-year-old | good | dark-haired | good |
| 4 | this | 13-year-old | that | dark-haired | clever | 13-year-old | clever |
| 5 | good | nine-year-old | this | 16-year-old | poor | nine-year-old | pretty |
| 6 | one | 14-year-old | old | clever | pretty | 14-year-old | that |
| 7 | old | four-year-old | poor | pretty | old | four-year-old | 15-year-old |
| 8 | other | year-old | other | teenage | that | year-old | dark-haired |
| 9 | poor | clever | clever | 13-year-old | beautiful | clever | poor |
| 10 | clever | teenage | one | nine-year-old | lovely | teenage | 16-year-old |
| 11 | beautiful | blonde | pretty | four-year-old | golden | blonde | this |
| 12 | pretty | pretty | beautiful | head | nice | pretty | old |
| 13 | small | head | nice | 14-year-old | 15-year-old | head | beautiful |
| 14 | any | little | lovely | poor | teenage | little | teenage |
| 15 | nice | wee | big | blonde | dark-haired | wee | lovely |
| 16 | big | eldest | small | good | head | eldest | head |
| 17 | another | brave | golden | golden | 16-year-old | brave | golden |
| 18 | lovely | golden | tall | beautiful | tall | golden | nice |
| 19 | new | silly | dear | lovely | this | silly | tall |
| 20 | golden | young | teenage | year-old | dear | young | blonde |
各指標の読み方を以下にメモ.
・ raw frequency: コーパス内の総頻度.統計計算を加える前のベースとなる値で,それ自体は collocation の強度計測にはほとんど役に立たない.
・ observed/expected: 偶然に collocate している可能性からどれだけ隔たっているか.collocation の指標としては粗い.
・ t-score: 広く使われる指標.コーパスのサイズが勘案されている.通常は,2以上の値でその collocation が統計的に有意とみなされる.collocation 強度そのものの指標というよりも,互いに関連があると言い切れる確信度の指標.(後記 2010/03/21(Sun):特定の2語の共起頻度に焦点を当てるため,キーワードの前後に頻繁に生起する前置詞,不変化詞,人称代名詞,限定詞などの文法構造を満たすための語のほか,常套句や使い古されてしまった比喩,決まり文句などを構成する語が上位にランクインする.つまり,主に文型や機能語の連語情報 [ grammatical collocation ] に寄与する.)
・ z-score: 両語それぞれのコーパス中の全頻度を勘案したうえで,その collocation が期待値よりどれだけ高い頻度で現れているかを示す.広く使われている指標だが,データが正規分布をなすとの前提に立っており,多くの場合に必ずしも適切でない.コーパスが巨大か,あるいは(たいてい関心を引かない)超高頻度語を対象にするのでない限り,問題が生じうる.低頻度語が強調される傾向がある.
・ log-likelihood (LL test): データの正規分布を前提としない.コーパスのサイズが小さめでも有効.高頻度語にも低頻度語にも有効.手堅い統計値.
・ MI (mutual information): LL ほど統計的に厳格ではないが,z-score や LL の代替指標として広く使われている.3以上の値をもって collocate しているとみなせるといわれる.負の値が出ると,むしろ両語が背反し合うという意味になる.コーパスのサイズに依存しない.z-score と同様に低頻度語が強調される傾向がある.unique collocation を知るなど辞書学的な用途には役立つ指標だが,英語教育用には不向き.(後記 2010/03/21(Sun):共起する2語が持つ意味的特性に焦点が当てられる傾向がある.慣用句,ことわざ,複合語,専門用語など独特の言い回しを構成する語に高い値が与えられる.)
・ MI3: MI の低頻度語を強調しがちな傾向を補正した指標の一つ.英語教育用に向いている.同様の趣旨の指標として,log-log test というものもある.
正直なところ,どう読み解けばいいのかよくわからない(あくまで練習題なので・・・).little, young, good, clever などいずれの指標でもランクの高いものはあり,これらは明らかに強い collocation ありとみなしてよいだろう.ほかには, z-score や MI が 15-year-old などの影響を激しく反映しているのに対して,手堅い log-likelihood や補正済みの MI3 の値は -year-old を比較的よくはじいていることがわかる.このことから,-year-old は girl とよく collocate することは確かながらも,いくつかの指標が示唆するような最上位のランクであるというのは言い過ぎであるといえそうである.MI値の上位にはやや個性的と思われる形容詞も含まれており,若干くせのある値だということも肌で感じることができた.だが,統計値の解読はなかなかに難しい・・・.
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2010-03-03 Wed
■ #310. PPCMBE で広がる英語統語論の通時研究 [corpus][ppcmbe][syntax]
Penn Parsed Corpora of Historical English のプロジェクトの成果として,University of Pennsylvania から PPCMBE ( Penn Parsed Corpus of Modern British English ) が出版された.これにより,以下の通り,古英語から現代英語にわたる各時期のイギリス英語の統語タグ付きコーパスが出そろったことになる.
・ YCOE: Taylor, Ann, Anthony Warner, Susan Pintzuk, and Frank Beths. York-Toronto-Helsinki Parsed Corpus of Old English Prose, first edition. Oxford Text Archive, 2003. (1.5 million words)
・ PPCME2: Kroch, Anthony and Ann Taylor. Penn-Helsinki Parsed Corpus of Middle English, second edition. University of Pennsylvania, 2000. (1.3 million words)
・ PPCEME: Kroch, Anthony, Beatrice Santorini, and Ariel Diertani. Penn-Helsinki Parsed Corpus of Early Modern English, first edition. University of Pennsylvania, 2004. (1.8 million words)
・ PPCMBE: Kroch, Anthony, Beatrice Santorini, and Ariel Diertani. Penn-Hensinki Parsed Corpus of Modern British English, first edition. University of Pennsylvania, 2010. (1.0 million words)
いずれも Helsinki Corpus をベースとしたソースに対して同一の annotation scheme による統語的タグが付加されており,互いに連携できるように作られている.視点は異なるが,およそ1410年から1695年までのあいだの書簡集となるコーパス PCEEC も同様の annotation scheme でタグ付けされており,やはり連携が可能である(ただし利用は限定的).
・ PCEEC: Taylor, Ann, Arja Nurmi, Anthony Warner, Susan Pintzuk, and Terttu Nevalainen. Parsed Corpus of Early English Correspondence, first edition. Oxford Text Archive, 2006. (2.2 million words)
現時点で,あわせて 7.8 million words が通時的かつ統語的な視点からタグ付けされ,一般に利用可能になったことになる.
一昨日と昨日と,東京外国語大学のグローバルCOEプログラム「コーパスに基づく言語学教育研究拠点」 ( Corpus-based Linguistics and Language Education ) 主催で,"Corpus Analysis and Diachronic Linguistics" と題する国際シンポジウムが同大学で開かれ,Anthony Kroch や Merja Kytö など英語史コーパス言語学の著名な学者も講演した(ポスターはこちら).PPCMBE の出版直後ということもあったので,特に Anthony Kroch が何を話すかに興味をもっていた.一連の歴史英語コーパスを使った統語研究の一端でも見せてくれるのかなと期待していたが,驚いたことに,歴史英語コーパスと歴史フランス語コーパスを組み合わせた「英仏対照通時統語コーパス言語学」とでもいうべき研究の可能性を示す発表だった.今や University of Pennsylvania は英語に限らず諸言語のコーパス作成の拠点となっており,あれやこれやと組み合わせるとこんなこともあんなこともできるんだぞというところを見せつけられたとでもいおうか.
ちなみに,取り上げられた話題は英仏の direct object topicalization の歴史で,英語の場合には 1151--1250 年期から 1251--1350 年期にかけて,直接目的語の前置される頻度が一気に減少したという.
2010-03-01 Mon
■ #308. 現代英語の最頻英単語リスト [lexicology][corpus][link][academic_word_list][alphabet][frequency][statistics][letter_frequency]
現代英語の最頻英単語は何か.この話題についてはコーパス言語学,辞書学,計算機の発展により,様々な頻度表が作られてきた.ウェブ上でも簡単に手に入るので,いくつか代表的なリストや情報源へのリンクを掲げておく.語彙研究に活用したい.
[主要な頻度表]
・ GSL ( General Service List ): 最頻2000語を掲げたリスト.出版が1953年と古いが,現在でも広く参照されているリスト.
・ AWL ( Academic Word List ): 学術テキストに限定した最頻語リスト.2000年に出版され,GSLに含まれる語と重複しないように選ばれた570語を掲載.10のサブリストに分かれている.AWL の前身となる,1984年に出版された808語のリスト UWL ( University Word List ) も参照.
・ BNC Word Frequency Lists: BNC ( The British National Corpus ) による最頻6318語のリスト.頻度表の直接ダウンロードはこちらから.
・ Top 1000 words in UK English: 18人の著者,29作品,460万語のコーパスから抽出したイギリス英語の最頻1000語リスト.
・ Brown Corpus List: Brown Corpus によるアルファベット順リスト.
・ The Longman Defining Vocabulary: LDOCE の1988年版の定義語彙リスト.2000語以上.
[他のリストへのリンク集]
・ Work/Frequency List: 様々な頻度表へのリンク集.(2010/09/10(Fri)現在リンク切れ)
・ Famous Frequency Lists: 様々な頻度表へのリンク集.
・ Basic English and Common Words: ML上の最頻語頻度表についての議論.
[アルファベットの文字の頻度表]
・ Letter Frequencies (rankings for various languages): いくつかのランキング表がある.BNCでは "etaoinsrhldcumfpgwybvkxjqz" の順とある.
(後記 2010/03/07(Sun):American National Corpus に基づいた頻度表を見つけた.Written と Spoken で分別した頻度表もあり.)
(後記 2010/04/12(Mon):COLT: The Bergen Corpus Of London Teenage Language に基づいた最頻1000語のリストを見つけた.)
(後記 2011/02/14(Mon):Corpus of Contemporary American English (COCA) に基づいた Corpus-based word frequency lists, collocates, and n-grams を見つけた.Top 5,000 lemma, Top 500,000 word forms など.)
2010-02-28 Sun
■ #307. コーパス利用の注意点 [corpus][link]
英語研究を始め言語研究にコーパスが利用されるようになって,すでに久しい.英語史の分野でも,革新的な The Diachronic Part of the Helsinki Corpus of English Texts の出版以来,様々な種類の歴史・通時コーパスが出ている.
研究には大いにコーパスを利用したいが,コーパス利用研究の注意点を(コメントつきで)挙げておきたい (McEnery et at. 121).
(1) コーパスは negative evidence を提供してくれない.○○がどれだけ生起するかは教えてくれるが,××が生起しないことは教えてくれない.(だが,一般的にいって存在しないかもしれないことを研究することは難しいので,これはコーパス言語学に限った問題点ではない.)
(2) コーパスは事実を提供してくれるが,その事実の説明はしてくれない.(確かに.説明それ自身は研究者の仕事である.)
(3) コーパスは,研究の範囲を限定する.(コーパスではできない研究もたくさんある.コーパス研究は,問題を適切に設定すればその目的のためには常に有効である.しかし,最初の問題設定の外にも問題が広がっていることは忘れてはいけない.)
(4) コーパス研究で導かれた結論を一般化する際には細心の注意を要する.(いくら膨大なコーパスでも,あくまで対象とする言語事実の部分集合である.)
以上4点を書き留めてみてふと立ち止まった.考えてみれば,この4点はコーパス利用ならずとも常に気をつけなければならない点である.英語史を含め歴史言語学の研究は,話者の直感に頼ることができない以上,残された事実(=コーパス)を分析するところから始まらざるをえないのだから,それを電子的に扱うか否かにかかわらず,やっていることはコーパス言語学にほかならない.ただ,電子的な統計に注目する傾向のある近年の(コンピュータ)コーパス言語学では,上記4点について余計に注意すべきだということは言えるだろう.
(3) に関連して,望遠鏡(コーパス言語学に代表される量的研究)と顕微鏡(文献学や談話分析に代表される質的研究)の比喩が興味深い.コーパスを利用するか否かにかかわらず,研究の目的が最重要ということだろう.
If it is ridiculous to criticize a telescope for not being a microsope, it is equally pointless to criticize the corpus-based approach for not doing what it is not intended to do (McEnery et al. 121)
英語コーパス研究の入り口として,以下の非常に良質なリンクを参照.
・ コーパス言語学の入門: 家入葉子先生のサイトより.英語史研究に有用.
・ 英語史関係のコーパス・電子テキスト: 家入葉子先生のサイトより.
・ 英語史関係のコーパス: 三浦あゆみさんの A Gateway to Studying HEL より.
・ コーパス研究に有用なWebサイト一覧
・ JAECS 英語コーパス学会
(後記 2010/03/21(Sun))
・ おすすめコーパスサイト: 『実践コーパス言語学』の著者の一人,須賀廣氏のリンク集.
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2010-02-26 Fri
■ #305. -ise か -ize か [spelling][ame_bre][bnc][corpus][suffix][z]
私は,普段,英語を書くときにはイギリス綴りを用いている.英国留学中,指導教官に -ize / -ization の語を -ise / -isation に訂正されてから意識しだした習慣である.そのきっかけとなったこのペアは,一般には,アメリカ英語ではもっぱら -ize を用い,イギリス英語では -ise も用いられるとされる.
イギリス英語での揺れの理由としては,アメリカ英語の影響や,接尾辞の語源としてギリシャ語の -izein に遡るために -ize がふさわしいと感じられることなどが挙げられるだろう.単語によって揺れ幅は異なるようだが,実際のところ,イギリス英語での -ise と -ize のあいだの揺れはどの程度あるのだろうか.
この問題について,Tieken-Boon van Ostade (38) に BNC ( The British National Corpus ) を用いたミニ検査が示されていた.generalise, characterise, criticise, recognise, realise の5語で -ise と -ize の比率を調べたというものである.このミニ検査に触発されて,もう少し網羅的に揺れを調べてみようと思い立ち,BNC-XML で計399個の -ise / -ize に揺れのみられる動詞についてそれぞれの頻度を出してみた.以下は,-ise / -ize を合わせて頻度がトップ20の動詞である.ちなみに,399個の動詞についての全データはこちら.
| item | -ise rate (freq) | -ize rate (freq) | -ise + -ize |
|---|---|---|---|
| recognise | 61.1% (9143) | 38.9% (5812) | 14955 |
| realise | 63.2% (9442) | 36.8% (5492) | 14934 |
| organise | 62.3% (5540) | 37.7% (3359) | 8899 |
| emphasise | 60.0% (2998) | 40.0% (1998) | 4996 |
| criticise | 54.9% (2054) | 45.1% (1688) | 3742 |
| characterise | 52.2% (1398) | 47.8% (1278) | 2676 |
| summarise | 61.4% (1164) | 38.6% (731) | 1895 |
| specialise | 70.7% (1163) | 29.3% (481) | 1644 |
| apologise | 68.8% (1084) | 31.2% (492) | 1576 |
| advertise | 99.5% (1542) | 0.5% (7) | 1549 |
| authorise | 64.5% (987) | 35.5% (543) | 1530 |
| minimise | 65.4% (984) | 34.6% (521) | 1505 |
| surprise | 99.9% (1345) | 0.1% (1) | 1346 |
| supervise | 99.8% (1303) | 0.2% (3) | 1306 |
| utilise | 68.9% (798) | 31.1% (360) | 1158 |
| maximise | 63.2% (719) | 36.8% (418) | 1137 |
| symbolise | 49.2% (324) | 50.8% (334) | 658 |
| mobilise | 45.5% (286) | 54.5% (342) | 628 |
| stabilise | 53.5% (334) | 46.5% (290) | 624 |
| publicise | 69.4% (419) | 30.6% (185) | 604 |
この表で advertise, surprise, supervise の3語については -ise が規則だとみなしてよいだろうが,それ以外は全体的に -ise がやや優勢なくらいで,イギリス英語でも -ize は十分に一般的であることがわかる.399語の平均を取ると,-ise の比率は51.6%となり,-ize とほぼ拮抗していることがわかる.詳しく調べれば個々の動詞の慣用というのがあるのかもしれないが,イギリス英語の綴り手としては,ひとまず「-ise に統一」と考えておくのも手かもしれない.
・ Tieken-Boon van Ostade, Ingrid. An Introduction to Late Modern English. Edinburgh: Edinburgh UP, 2009.
2010-01-23 Sat
■ #271. 語彙研究ツールとしての辞書とコーパス [dictionary][corpus][methodology][lexicology]
現代英語の語彙研究あるいは英語語彙の歴史的研究をおこなうときに,情報源は二つある.一つは辞書であり,もう一つは(電子)コーパスである.(膨大な量のテキストに体当たりという力業もあるが,ここではその可能性は考えないことにする.)歴史的な観点から英語の語彙論や形態論に関心のある私は,とりわけ OED 等の辞書(電子版)にお世話になることが多いが,The Helsinki Corpus of English Texts (Diachronic Part) を始めとする電子コーパスをもっと活用すべきだと自認している.
辞書は語と語にまつわる諸情報を集めることに特化した出版物なので,電子版を用いれば「かくかくしかじかの条件に当てはまる語彙を一覧にせよ」という類の命令にはめっぽう強い.一方で,電子コーパスは通常,語彙研究に特化しているわけではなく広く言語研究全般に供する情報源として出版されている.だが,語彙研究において電子コーパスのほうが辞書よりも有用であるケースは少なくない.Baayen and Lieber (803) によると,語彙研究におけるコーパスの利点は以下の通り.
(1) コーパスで語を検索すると,その頻度を知ることができる.辞書では頻度はわからない.
(2) コーパスは生の言語使用を反映しており,辞書に掲載されない語を含んでいる可能性が高い.(辞書は一般に保守的な傾向が強く,俗語や新語を含んでいないことが多い.)
(3) 逆に辞書に掲載されていてもコーパスではヒットしない語が多く存在する.
まとめると,語彙研究にコーパスを用いる利点は,「生きた語彙を頻度つきで集めることができる」という点だろう.要は,辞書とコーパスそれぞれの長所と短所をわきまえたうえで,目的に応じて両者を使い分ければよいということになろう.
辞書とコーパスのちょっとした比較例としては,octopus の複数形 ([2009-08-26-1]) と rhinoceros の複数形 ([2009-10-05-1]) の記事を参照.
・Baayen, Harald and Rochelle Lieber. "Productivity and English Derivation: A Corpus-Based Study." Linguistics 29 (1991): 801--43.
2009-12-29 Tue
■ #246. 男性着は「メンズ」だが,女性着は? [japanese_english][link][corpus]
「レディース」と答える人が圧倒的ではないだろうか.英語でも,men's wear に対して ladies' wear というのが一般的である.ところが,先日,ユニクロの日替わりセールの広告で「ウィメンズ 3Dスキニージーンズ 1,490円」なる文言を見つけた.
確かに,英語でも women's wear という表現はないではないし,むしろ mens' wear との対比が綴字上の eye rhyme として効果的に示されるという利点はあるかもしれない.ただ,[2009-12-06-1], [2009-12-07-1]で見たように,発音上は /mɛnz/ と /wɪmɪnz/ とでは韻を踏まない.
一方,日本語では,綴字上も発音上も見事に韻を踏む.「メンズ」に対して,「ウィメンズ」と発音が日本語化するからである.無標の ( unmarked ) 「レディース」ではなく,あえて有標の ( marked ) 「ウィメンズ」を使うというのは,ユニクロの差別化戦略だろうか?
英語の話しに戻るが,ladies' wear と women's wear のように二つ(以上)の variants があり,どちらの使用頻度がより高いかの見当をつけたい場合に便利なウェブツールがある.英文校正サイト [NativeChecker]は「Web上に蓄積されている膨大な英文テキストを基盤とした,英語のネイティブチェックシステム」で,自然な英語表現のチェックに威力を発揮する.入力された英語表現のヒット数によって,その頻度や自然度も計れるので,今回のような問題に活用できる.
これによると,ladies' wear のヒットは2,780,000件,women's wear のヒットは1,520,000件だった.前者のほうが,およそ倍近くの頻度を誇るようだ.およその見当付けとして活用したい.
2009-10-05 Mon
■ #161. rhinoceros の複数形 [plural][etymology][bnc][corpus][clipping][drift]
[2009-08-26-1]で octopus の複数形は何かという話題を扱ったが,今回は rhinoceros /raɪnˈɑsərəs/ 「犀」の複数形は何かという問題に分け入りたい.
この語はギリシャ語にさかのぼり,rhīno- "nose" + -kerōs "horned" の複合語である.英語には1300年頃に借用された.
この語は,私が知っている英単語のなかで,取り得る複数形態の種類が最も多い語である.まずは OED で調べてみると,8種類の複数形があり得ると分かる.
rhinoceros, rhinocerons, rhinocerontes, rhinoceroes, rhinocero's, rhinoceri, rhinoceroses, rhinocerotes
とてつもない語なので,Jespersen の文法などでも取りあげられているし,『英語青年』にも記事がある.これには,さすがに犀もびっくりしていることだろう.
須貝氏の記事によれば,1905年に Sir Charles Eliot なる人物がこの問題に頭を悩ませていたという記録がある.rhinocerotes は衒学的であり,かといって rhinoceroses は口調が良くない.口語での省略形の rhinos では威厳がなく,単複同形の rhinoceros では問題を回避しているに過ぎないとも言う.
また,1938年には Julian Huxley なる生物学者が,rhinoceri は誤用であり,rhinoceroses がもっとも抵抗が少ないだろうが,それですら衒学的な響きを禁じ得ないとも述べている.結論としては rhinos を正規の複数形とするよう提案している.
この二人の記録と洞察を忠実に受け入れて考えてみよう.1905年の時点で rhinocerotes にはすでに衒学的な響きがあったということだが,「規則複数」の rhinoceroses には特に衒学的な響きがあったとは触れられていない.だが,1938年には rhinoceroses ですら衒学的になっていたということが述べられている.だからこそ,rhinos を提案したわけである.
とすると,1938年までの推移の順序は以下のように推論できるのではないか.まず,rhinocerotes を含めた多くの「不規則複数」が20世紀初頭にはすでに衒学的だった.そこで,「規則複数」たる rhinoceroses がより一般的になりかけた.だが,口調上の理由でこれも最終的には好まれず,やや口語ぽい響きが気にはなるものの,省略形に規則的な -s を付け足した rhinos が一般化し出した.
須貝氏のいうように,この30年余の期間における「犀」の複数形の推移は,Jespersen のいう simplification と monosyllabism という英語の通時的傾向を表す好例のように思われる( rhinos の場合,厳密には monosyllabism への変化とはいえないが,音節数の減少であることは確かである).まず不規則を規則化し,それでも飽き足りずに切り株 ( clipping ) にした.
さて,現在に話しを移そう.須貝氏の記事は1938年のものであり,それから現在までに「犀」の複数形はどのように変化したか.BNC ( The British National Corpus ) の単純検索によると,「不規則複数」のヒットは皆無だった(タグ付き検索ではないため,単複同形の rhinoceros の複数形としてのヒット数については未確認).規則形については,ヒット数は以下の通り.
| rhinoceroses | 13 |
| rhinos | 100 |
複数の学習者英英辞書で,rhino には今でも「口語」というレーベルがついているものの,全体の頻度としては rhinoceroses を突き放している.須貝氏の記事から約70年,どうやら結論はすでに出たといってもよさそうである.
・Jespersen, Otto. Growth and Structure of the English Language. 2nd Rev. ed. Leipzig: Teubner, 1912. 143 fn.
・Jespersen, Otto. A Modern English Grammar on Historical Principles. Part 2. Vol. 1. 2nd ed. Heidelberg: C. Winter's Universitätsbuchhandlung, 1922. 39.
・須貝 清一 「Rhinoceros の複数」 『英語青年』80巻3号,1938年,81頁.
2009-08-26 Wed
■ #121. octopus の複数形 [plural][greek][bnc][corpus]
octopus の複数形は何か.手持ちの辞書を引き比べてもらうとわかるが,すべての辞書で規則的な octopuses が挙がっていることだろう.特に記述のない辞書では octopuses を当然とみなしての省略に違いない.
だが,大きめの辞書や古めの辞書を引くと,octopodes なる複数形が併記されている.例えば OED では,octopodes /ɒkˈtəʊpədi:z/ が先に挙がっており,その後に octopuses が追記されている.
Web3 ( Webster's Third New International Unabridged Dictionary ) にいたっては,第三の複数形として octopi /ˈɑktəˌpaɪ/ が挙げられている.
複数形態に関するこの複雑な状況は,この単語がギリシャ語からネオ・ラテン語を経て,18世紀に英語へ借用されてきたという経緯による.ギリシャ語の屈折に従えば octopodes となり,ラテン語の屈折を適用すると octopi になる( see sg. alumnus -- pl. alumni ).ただし,ラテン語に準じた octopi は,COD11 ( The Concise Oxford English Dictionary 11th ed. ) によると誤用とされている.
ただ,この二種類の古典語に基づく不規則複数形は,現在では衒学的・専門的な響きが強すぎて普通には用いられないと考えてよい.このことは,多くの学習者英英辞典で octopuses のみが挙げられていることからもわかる.
BNC ( The British National Corpus )で調べてみるとヒット数は以下の通りだった.
| octopuses | 29 |
| octopi | 11 |
| octopodes | 4 |
ついでだが,日本語ではタコを数えるときにつける助数詞は「匹」でもよいし,イカと同じく「杯」でもよいという.知らなかった.
2009-07-15 Wed
■ #78. Verbix とコーパス [software][web_service][conjugation][inflection][oe][me][corpus][variation]
昨日の記事[2009-07-14-1]で,Verbix の古英語版の機能を紹介し,評価して終わったが,実は述べたかったことは別のことである.
動詞の不定詞形を入れると活用表が自動生成されるという発想は,標準語として形態論の規則が確立している現代語を念頭においた発想である.これは古英語や中英語などには,あまりなじまない発想である.確かに古英語にも Late West-Saxon という「標準語」が存在し,古英語の文法書では,通常この方言にもとづいた動詞の活用表が整理されている.だが,Late West-Saxon の「標準語」内ですら variation はありうるし,方言や時代が変われば活用の仕方も変わる.中英語にいたっては,古英語的な意味においてすら「標準語」が存在しないわけであり,Verbix の中英語版というのは果たしてどこの方言を標準とみなして活用表を生成しているのだろうか.
Verbix 的な発想からすると,方言や variation といった現象は,厄介な問題だろう.このような問題に対処するには,Verbix 的な発想ではなくコーパス検索的な発想が必要である.タグ付きコーパスというデータベースに対して,例えば「bēon の直説法一人称単数現在形を提示せよ」とクエリーを発行すると,コーパス中の無数の例文から該当する形態を探しだし,すべて提示してくれる.その検索結果は,おそらく Verbix 型のきれいに整理された表ではなく,変異形 ( variant ) の羅列になるだろう.古英語の初学者にはまったく役に立たないリストだろうが,研究者には貴重な材料だ.
英語史研究,ひいては言語研究における現在の潮流は,標準形を前提とする Verbix 的な発想ではなく,variation を許容するコーパス検索的な発想である.同じプログラミングをするなら,Verbix のようなプログラムよりも,コーパスを検索するプログラムを作るほうがタイムリーかもしれない.
とはいえ,Verbix それ自体は,学習・教育・研究の観点から,なかなかおもしろいツールだと思う.だが,個人的な研究上の都合でいうと,古英語や中英語の名詞の屈折表の自動生成ツールがあればいいのにな,と思う.誰か作ってくれないだろうか・・・.自分で作るしかないのだろうな・・・.
Powered by WinChalow1.0rc4 based on chalow