2010-04-17 Sat
■ #355. COLT Word Frequency List による音節数の分布調査 [colt][syllable][lexicology][statistics]
昨日の記事[2010-04-16-1]で触れたように,COLT ベースの音節数分布調査をパイロット・スタディとして実施してみた.以下が結果.[2010-04-10-1], [2010-04-11-1]の BNC ベースの調査結果と比較するにはこちらのページへ.
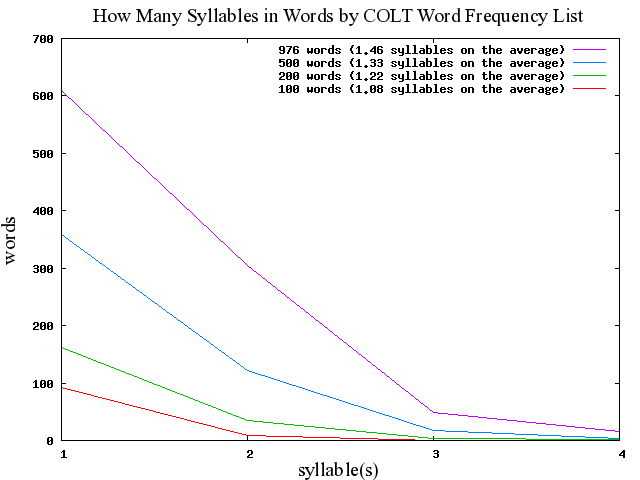
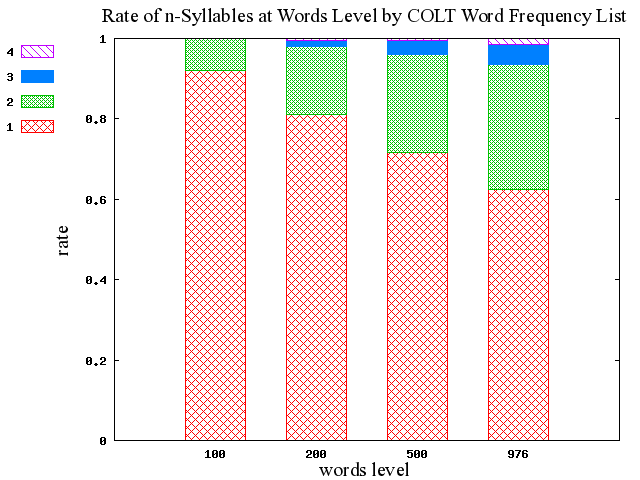
BNC ベースの結果と比べて,100語,200語,500語,1000語(976語)のいずれのレベルでも,COLT のほうが平均音節数は少ない.1000語(976語)レベルで比べると,COLT は単音節語と二音節語だけで93%をカバーしているが,BNC はそのカバー率は約10%ほど少ない.口語コーパスに限定した COLT とそうでない BNC の差が関与していると考えられる.
2010-04-16 Fri
■ #354. COLT:ロンドンの十代の若者話し言葉コーパス [corpus][colt][lexicology][syllable]
少し変わり種のコーパスとして,COLT: The Bergen Corpus Of London Teenage Language を紹介する.1993年におけるロンドンの若者(13歳から17歳)の話し言葉を収集したコーパスで,約50万語からなる.31人のロンドン各地・各階層の男子女子の会話を,合計50時間だけ録音し,文字に起こしたものである.BNC ( The British National Corpus ) にも組み込まれているコーパスだ.語類情報や休止などの韻律情報がタグ付けされており,若者言葉によって先導される言語変化の調査や語用論的な研究において実績がある.
コーパス自体は有料だが,上記のHPから手に入る COLT による最頻1000語のリスト が目を引いた.COLT に現れる表記語 ( graphic word ) の最頻リストで,lemmatise されていない.要するに,do と did,laugh と laughing などは別々にカウントされている.
今回,このコーパスに目を付けたのは,先日[2010-04-10-1], [2010-04-11-1]でパイロット・スタディとしておこなった「BNC Word Frequency List による音節数の分布調査」の COLT 版を試してみようと思ったからである.BNC による音節数分布調査では,書き言葉と話し言葉の両方を対象とし,lemmatise された基底形 ( base form ) での頻度表を用いたが,COLT を用いれば,大きく異なった条件のもとで類似した調査をおこなうことができる( COLT が BNC の一部になっていることを考慮しても).具体的には,話し言葉に限定された,表記語に基づく頻度表をベースとして音節数の分布を調べられる.
注意を要するのは,COLT の頻度表には unclear, nv, singing など,地の文の語ではなくタグ名として使われている語もうっかり数えられてしまっていることだ.したがって,この種の語は手作業で除去し,最終的に有効最頻語976語のリストが得られた.これをもとにして,音節数の分布をいざ探ってみることにする.結果は,明日.
Powered by WinChalow1.0rc4 based on chalow