2024-10-04 Fri
■ #5639. 朝カルシリーズ講座の第4回「現代の英語に残る古英語の痕跡」をマインドマップ化してみました [asacul][oe][mindmap][notice][kdee][etymology][hel_education][lexicology][vocabulary][heldio][link]
7月27日に開講した,標記のシリーズ講座第4回「現代の英語に残る古英語の痕跡」について,その要旨を markmap というウェブツールによりマインドマップ化しました(画像としてはこちらからどうぞ).受講された方は復習用に,そうでない方は講座内容を垣間見る機会としてご活用ください.
シリーズ第3回「英単語と「グリムの法則」」については hellog と heldio の過去回で取り上げているので,ご参照ください.
・ hellog 「#5511. 6月8日(土)の朝カル新シリーズ講座第3回「英単語と「グリムの法則」」のご案内」 ([2024-05-29-1])
・ heldio 「#1095. 6月8日(土),朝カルのシリーズ講座第3回「英単語と「グリムの法則」」が開講されます」
次回の朝カル講座は明後日9月28日(土)17:30--19:00に「第6回 英語,ヴァイキングの言語と交わる」と題して開講します.いつものとおり,対面・オンラインのハイブリッド形式(見逃し配信あり)です.予告編として「#5619. 9月28日(土)の朝カル新シリーズ講座第6回「英語,ヴァイキングの言語と交わる」のご案内」 ([2024-09-14-1]) をご覧いただければ.本講座に関心のある方は,ぜひ朝日カルチャーセンター新宿教室の「語源辞典でたどる英語史」のページよりお申し込みください.
・ 寺澤 芳雄(編集主幹) 『英語語源辞典』新装版 研究社,2024年.
{kind=link}
2024-09-24 Tue
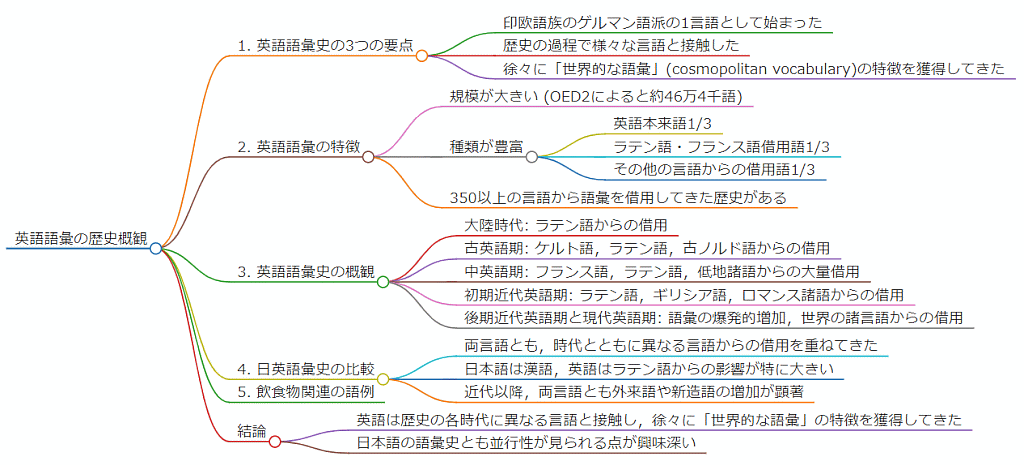
■ #5629. 朝カルシリーズ講座の第2回「英語語彙の歴史を概観する」をマインドマップ化してみました [asacul][mindmap][notice][kdee][etymology][hel_education][lexicology][vocabulary][heldio][link]
「#5625. 朝カルシリーズ講座の第1回「英語語源辞典を楽しむ」をマインドマップ化してみました」 ([2024-09-20-1]) に続き,5月18日に開講したシリーズ第2回「英語語彙の歴史を概観する」のマインドマップを markmap により作成しました(画像としてはこちらからどうぞ).
このシリーズ第2回については hellog と heldio の過去回で取り上げているので,ご参照ください.
・ hellog 「#5486. 5月18日(土)の朝カル新シリーズ講座第2回「英語語彙の歴史を概観する」のご案内」 ([2024-05-04-1])
・ heldio 「#1079. 土曜日,朝カル新シリーズ講座第2回「英語語彙の歴史を概観する」が開講されます」
次回の朝カル講座は今週末の9月28日(土)17:30--19:00に,対面・オンラインのハイブリッド形式(見逃し配信あり)で開講されます.「英語,ヴァイキングの言語と交わる」と題し,英語史上もっともエキサイティングな言語接触に迫ります.予告編として「#5619. 9月28日(土)の朝カル新シリーズ講座第6回「英語,ヴァイキングの言語と交わる」のご案内」 ([2024-09-14-1]) をご覧ください.本講座に関心のある方は,ぜひ朝日カルチャーセンター新宿教室の「語源辞典でたどる英語史」のページよりお申し込みいただければ.
・ 寺澤 芳雄(編集主幹) 『英語語源辞典』新装版 研究社,2024年.
{kind=link}
2024-09-20 Fri
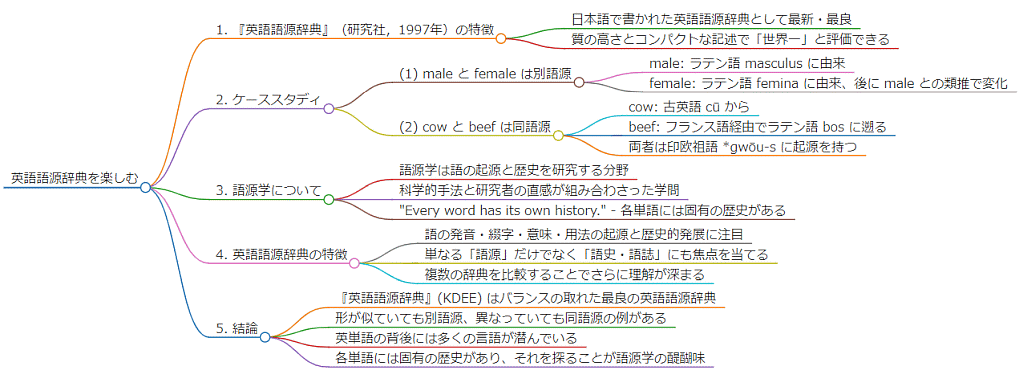
■ #5625. 朝カルシリーズ講座の第1回「英語語源辞典を楽しむ」をマインドマップ化してみました [asacul][mindmap][notice][kdee][etymology][hel_education][lexicology][vocabulary][lexicography][bibliography][dictionary][heldio][link]
今年度,朝日カルチャーセンター新宿教室にてシリーズ講座「語源辞典でたどる英語史」を月に一度のペースで開講しています.対面・オンラインのハイブリッド形式(見逃し配信あり)です.
次回第6回は9月28日(土)の17:30--19:00に「英語,ヴァイキングの言語と交わる」と題して開講します.古英語と古ノルド語の言語接触に注目します.
全12回のシリーズも半分ほど進んできました.このタイミングで,前半の各回をマインドマップで要約しておくのも有用かもしれないと思い立ち,markmap というウェブ上のツールを用いて,まずシリーズ初回「英語語源辞典を楽しむ」(2024年4月27日開講)のマインドマップを作ってみました(画像としてはこちらからどうぞ).
このシリーズ初回については hellog と heldio の過去回でも取り上げているので,そちらもご参照ください.
・ hellog 「#5453. 朝カル講座の新シリーズ「語源辞典でたどる英語史」が4月27日より始まります」 ([2024-04-01-1])
・ hellog 「#5481. 朝カル講座の新シリーズ「語源辞典でたどる英語史」の第1回が終了しました」 ([2024-04-29-1])
・ heldio 「#1058. 朝カル講座の新シリーズ「語源辞典でたどる英語史」が4月27日より月一で始まります」
・ 寺澤 芳雄(編集主幹) 『英語語源辞典』新装版 研究社,2024年.
{kind=link}
2024-09-14 Sat
■ #5619. 9月28日(土)の朝カル新シリーズ講座第6回「英語,ヴァイキングの言語と交わる」のご案内 [asacul][notice][kdee][etymology][hel_education][helkatsu][link][lexicology][vocabulary][oe][old_norse][germanic][contact][voicy][heldio]

・ 日時:9月28日(土) 17:30--19:00
・ 場所:朝日カルチャーセンター新宿教室
・ 形式:対面・オンラインのハイブリッド形式(見逃し配信あり)
・ お申し込み:朝日カルチャーセンターウェブサイトより
2週間後の9月28日(土)17:30--19:00に朝日カルチャーセンター新宿教室にてシリーズ講座「語源辞典でたどる英語史」の第6回となる「英語,ヴァイキングの言語と交わる」を開講します.
前回8月24日の第5回では「英語,ラテン語と出会う」と題して,古英語期(あるいはそれ以前の時代)におけるラテン語の語彙的影響に注目しました.今回は8世紀後半から11世紀前半にかけてのヴァイキング時代に焦点を当て,古ノルド語 (old_norse) と古英語の言語接触について解説します.
ヴァイキングとは上記の時期に活動したスカンジナビア出身の海賊を指します.彼らはブリテン島にも襲来し,やがてイングランド東部・北部に定住するようになりました.その結果,古ノルド語を母語とするヴァイキングと古英語を話すアングロサクソン人との間で言語接触が起こりました.
古ノルド語からの借用語は,現代英語に900語ほど残っています.この絶対数はさほど大きいわけではありませんが,基本語や機能語など高頻度で使用される語が多く含まれているのが注目すべき特徴です.講座では具体的な古ノルド語からの借用語を取り上げ,その語源を読み解いていきます.
古ノルド語と英語の接触は非常に濃密なものでした.これは両言語がゲルマン語族に属しており,近い関係にあったことや,両民族の社会的な交流の深さを反映していると考えられます.ヴァイキングの活動を通じた古ノルド語との接触は,英語の語彙に(そして実は文法にも)多大な影響を与えました.現代英語の姿を理解する上で,この歴史的な言語接触の重要性は看過できません.
本シリーズ講座は各回の独立性が高いので,第6回からの途中参加でもまったく問題なく受講できます.新宿教室での対面参加のほかオンライン参加も可能ですし,その後1週間の「見逃し配信」もご利用できます.奮ってご参加ください.お申し込みはこちらよりどうぞ.
なお,本シリーズ講座は「語源辞典でたどる英語史」と題しているとおり,とりわけ『英語語源辞典』(研究社)を頻繁に参照します.同辞典をお持ちの方は,講座に持参されると,より楽しく受講できるかと思います(もちろん手元になくとも問題ありません).

(以下,後記:2024/09/21(Sat))
・ 寺澤 芳雄(編集主幹) 『英語語源辞典』新装版 研究社,2024年.
2024-08-17 Sat
■ #5591. 8月24日(土)の朝カル新シリーズ講座第5回「英語,ラテン語と出会う」のご案内 [asacul][notice][kdee][etymology][hel_education][helkatsu][link][lexicology][vocabulary][oe][latin][voicy][heldio]
1週間後の8月24日(土)17:30--19:00に朝日カルチャーセンター新宿教室にてシリーズ講座「語源辞典でたどる英語史」の第5回となる「英語,ラテン語と出会う」を開講します.
前回,7月27日の第4回では「現代の英語に残る古英語の痕跡」と題して,古英語の語彙,語形成,ケルト語からの僅少な影響に注目しました.そこでは古英語が純度の高いゲルマン系の語彙を保っており,造語能力も豊かであったことを解説しました.
しかし,古英語にも諸言語からの借用語は確かにありました.少数のケルト借用語の存在についてはすでに触れましたが,その他にもラテン語語や古ノルド語からの借用語が各々数百語(以上)の規模で古英語に入ってきていたのです.数百語ほどの数では語彙全体のなかではさほど目立たないのも確かですが,その後の豊富な語彙借用の歴史を念頭におけば,古英語期が英語史上重要な位置づけにあることが理解できるでしょう.
今回の講座では,古英語期(あるいはそれ以前の時代)におけるラテン語の語彙的影響に注目します.また,ラテン語の影響が語彙的・言語的なレベルにとどまらず文化的な次元にまで及んだことにも触れます.
本シリーズ講座は各回の独立性が高いので,第5回からの途中参加などでもまったく問題なく受講できます.新宿教室での対面参加のほかオンライン参加も可能ですし,その後1週間の「見逃し配信」もご利用できます.奮ってご参加ください.
なお,本シリーズ講座は「語源辞典でたどる英語史」と題しているとおり,とりわけ『英語語源辞典』(研究社)を頻繁に参照します.同辞典をお持ちの方は,講座に持参されると,より楽しく受講できるかと思います(もちろん手元になくとも問題ありません).
・ 寺澤 芳雄(編集主幹) 『英語語源辞典』新装版 研究社,2024年.
2024-07-28 Sun
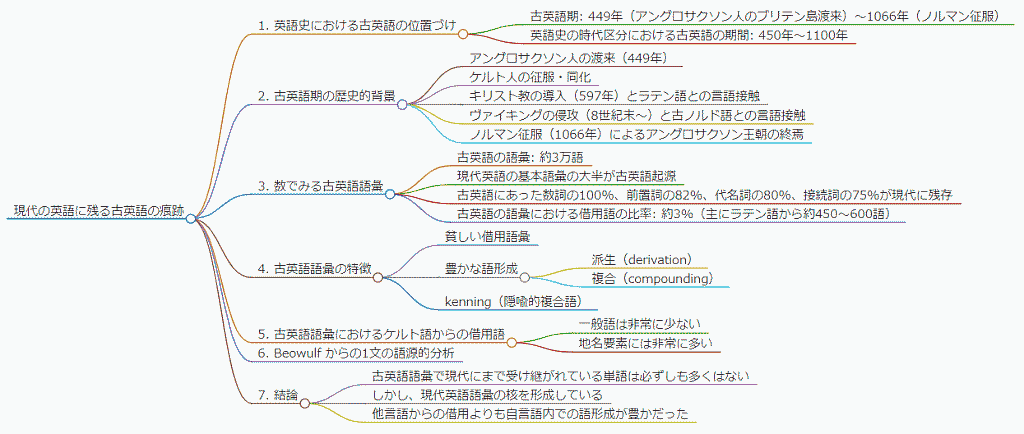
■ #5571. 朝カル講座「現代の英語に残る古英語の痕跡」のまとめ [asacul][notice][lexicology][vocabulary][oe][kenning][beowulf][compounding][derivation][word_formation][celtic][contact][borrowing][etymology][kdee]
先日の記事「#5560. 7月27日(土)の朝カル新シリーズ講座第4回「現代の英語に残る古英語の痕跡」のご案内」 ([2024-07-17-1]) でお知らせした通り,昨日朝日カルチャーセンター新宿教室にてシリーズ講座「語源辞典でたどる英語史」の第4回「現代の英語に残る古英語の痕跡」を開講しました.今回も教室およびオンラインにて多くの方々にご参加いただき,ありがとうございました.
古英語と現代英語の語彙を比べつつ,とりわけ古英語のゲルマン的特徴に注目した回となっています.古英語期の歴史的背景をさらった後,古英語には借用語は比較的少なく,むしろ自前の要素を組み合わせた派生語や複合語が豊かであることを強調しました.とりわけ複合 (compounding) からは kenning (隠喩的複合語)と呼ばれる詩情豊かな表現が多く生じました.ケルト語との言語接触に触れた後,「#1124. 「はじめての古英語」第9弾 with 小河舜さん&まさにゃん&村岡宗一郎さん」で注目された Beowulf からの1文を取り上げ,古英語単語の語源を1つひとつ『英語語源辞典』で確認していきました.
以下,インフォグラフィックで講座の内容を要約しておきます.
2024-07-17 Wed
■ #5560. 7月27日(土)の朝カル新シリーズ講座第4回「現代の英語に残る古英語の痕跡」のご案内 [asacul][notice][kdee][etymology][hel_education][helkatsu][link][lexicology][vocabulary][oe][voicy][heldio]
今年度,朝日カルチャーセンター新宿教室にてシリーズ講座「語源辞典でたどる英語史」を月に一度のペースで開講しています.4,5,6月と3回の春期クールを終え,この7月からは夏期クールが始まります.
第4回は来週末の7月27日(土)の夕方 17:30--19:00 に開講されます.お申し込み窓口が開いておりますので,ぜひこちらより詳細をご確認ください.講座形式はいわゆるハイブリッド形式で,新宿教室での対面受講,あるいはリアルタイム・オンラインでの受講が可能です.また申込みされた方は,「見逃し配信」として,その後1週間,講座を視聴できます.ご都合の良い方法でご参加ください.以下の通り,本シリーズは全12回を予定していますが,各回,各クールの独立性は高いので,夏期クールより初めての受講であっても,まったく問題ありません.
1. 英語語源辞典を楽しむ(2024年4月27日)
2. 英語語彙の歴史を概観する(2024年5月18日)
3. 英単語と「グリムの法則」(2024年6月8日)
4. 現代の英語に残る古英語の痕跡(2024年7月27日)
5. 英語,ラテン語と出会う(2024年8月24日)
6. 英語,ヴァイキングの言語と交わる(2024年9月28日)
7. 英語,フランス語に侵される(日付未定)
8. 英語,オランダ語と交流する(日付未定)
9. 英語,ラテン・ギリシア語に憧れる(日付未定)
10. 英語,世界の諸言語と接触する(日付未定)
11. 英語史からみる現代の新語(日付未定)
12. 勘違いから生まれた英単語(日付未定)
7月以降の夏期クールも毎月1回,指定の土曜日の夕方 17:30--19:00 に開講する予定です.春期クールから続いているシリーズではありますが,各クール,各回とも独立性の高い講座ですので,夏期クールより初めてのご参加であっても,まったく問題ありません.
春期クール3回の広い意味での「イントロ」を終え,夏期クールはいよいよ英語語彙史の具体的な記述が始まります.第4回は「現代の英語に残る古英語の痕跡」と題して,英語史の幕開きとなる古英語 (Old English) の時代に注目します.古英語とは紀元449--1100頃の英語を指しますが,語彙においても,そして発音,文字,文法においても,現代英語とは驚くほど異なる言語でした.現代の観点からみると,例えば古英語の語彙は,その多くの割合が現代まで生き延びずに,死語となっています.古英語と現代英語の語彙は,内容も規模も大きく異なるのです.
確かに語彙の断続性は著しいのですが,語彙の継続性にも注目したいところです.第4回講座の目標は,古英語と現代英語の語彙が間違いなくつながっているという事実を確認することです.
第4回のお知らせと概要は,先日 Voicy heldio でもお話ししました.「#1140. 7月27日(土),朝カルのシリーズ講座第4回「現代の英語に残る古英語の痕跡」が開講されます」をお聴きください.
シリーズでは『英語語源辞典』(研究社)を頻繁に参照します.同辞典をお持ちの方は,講座に持参されると,より楽しく受講できるかと思います(もちろん手元になくとも問題ありません).
本シリーズに関する hellog の過去記事へリンクを張っておきますので,ご参照ください.
・ 「#5453. 朝カル講座の新シリーズ「語源辞典でたどる英語史」が4月27日より始まります」 ([2024-04-01-1])
・ 「#5481. 朝カル講座の新シリーズ「語源辞典でたどる英語史」の第1回が終了しました」 ([2024-04-29-1])
・ 「#5486. 5月18日(土)の朝カル新シリーズ講座第2回「英語語彙の歴史を概観する」のご案内」 ([2024-05-04-1])
・ 「#5511. 6月8日(土)の朝カル新シリーズ講座第3回「英単語と「グリムの法則」」のご案内」 ([2024-05-29-1])
・ 「#5528. 朝カル講座の新シリーズ「語源辞典でたどる英語史」の春期3回が終了しました」 ([2024-06-15-1])
春期クールは,私の歴代朝カル講座のなかで最も多くの方々に受講していただきました.第4回から始まる夏期クールも,多くの方々のご参加をお待ちしております!
・ 寺澤 芳雄(編集主幹) 『英語語源辞典』 研究社,1997年.
2024-05-29 Wed
■ #5511. 6月8日(土)の朝カル新シリーズ講座第3回「英単語と「グリムの法則」」のご案内 [asacul][notice][kdee][etymology][hel_education][helkatsu][link][lexicology][vocabulary][grimms_law][verners_law][consonant][stress][phonetics][loan_word][french][latin][voicy][heldio]
新年度より,朝日カルチャーセンター新宿教室にてシリーズ講座「語源辞典でたどる英語史」を月に一度のペースで開講しています.
これまでに第1回「語源辞典でたどる英語史」を4月27日(土)に,第2回「英語語彙の歴史を概観する」を5月8日(土)に開講しましたが,それぞれ驚くほど多くの方にご参加いただき盛会となりました.ご関心をお寄せいただき,たいへん嬉しく思います.
第3回「英単語と「グリムの法則」」は来週末,6月8日(土)の 17:30--1900 に開講されます.シリーズを通じて,対面・オンラインによるハイブリッド形式での開講となり,講義後の1週間の「見逃し配信」サービスもご利用可能です.シリーズ講座ではありますが,各回はおおむね独立していますし,「復習」が必要な部分は補いますので,シリーズ途中からの参加でも問題ありません.ご関心のある方は,こちらよりお申し込みください.
2回かけてのイントロを終え,次回第3回は,いよいよ英語語彙史の各論に入っていきます.今回のキーワードはグリムの法則 (grimms_law) です.この著名な音規則 (sound law) を理解することで,英語語彙史のある魅力的な側面に気づく機会が増すでしょう.グリムの法則の英語語彙史上の意義は,思いのほか長大で深遠です.英語語彙学習に役立つことはもちろん,印欧語族の他言語の語彙への関心も湧いてくるだろうと思います.『英語語源辞典』(研究社,1997年)をはじめとする語源辞典や,一般の英語辞典も含め,その使い方や読み方が確実に変わってくるはずです.
講座ではグリムの法則の関わる多くの語源辞典で引き,記述を読み解きながら,実践的に同法則の理解を深めていく予定です.どんな単語が取り上げられるかを予想しつつ講座に臨んでいただけますと,ますます楽しくなるはずです.『英語語源辞典』をお持ちの方は,巻末の「語源学解説」の 3.4.1. Grimm の法則,および 3.4.2. Verner の法則 を読んで予習しておくことをお薦めします.

参考までに,本シリーズに関する hellog の過去記事へのリンクを以下に張っておきます.第3回講座も,多くの皆さんのご参加をお待ちしております.
・ 「#5453. 朝カル講座の新シリーズ「語源辞典でたどる英語史」が4月27日より始まります」 ([2024-04-01-1])
・ 「#5481. 朝カル講座の新シリーズ「語源辞典でたどる英語史」の第1回が終了しました」 ([2024-04-29-1])
・ 「#5486. 5月18日(土)の朝カル新シリーズ講座第2回「英語語彙の歴史を概観する」のご案内」 ([2024-05-04-1])
(以下,後記:2024/05/30(Thu))
・ 寺澤 芳雄(編集主幹) 『英語語源辞典』 研究社,1997年.
2024-05-04 Sat
■ #5486. 5月18日(土)の朝カル新シリーズ講座第2回「英語語彙の歴史を概観する」のご案内 [asacul][notice][kdee][etymology][hel_education][helkatsu][link][lexicology][vocabulary][loan_word][borrowing][word_formation][voicy][heldio]
新年度より,朝日カルチャーセンター新宿教室にてシリーズ講座「語源辞典でたどる英語史」を月に一度のペースで開講しています.
第1回「語源辞典でたどる英語史」は,4月27日(土)の 17:30--19:00 に開講され,おかげさまで盛況のうちに終了しました.こちらの回については,本ブログでも「#5453. 朝カル講座の新シリーズ「語源辞典でたどる英語史」が4月27日より始まります」 ([2024-04-01-1]) および「#5481. 朝カル講座の新シリーズ「語源辞典でたどる英語史」の第1回が終了しました」 ([2024-04-29-1]) で事前・事後に取り上げました.
第2回「英語語彙の歴史を概観する」は2週間後の5月18日(土)の 17:30--1900 に開講される予定です.対面・オンラインによるハイブリッド開講で,「見逃し配信」サービスもご利用可能です.第1回を逃した方も問題なくご参加いただけます.ご関心のある方は,ぜひこちらよりお申し込みください.
第2回は,シリーズ全体のイントロとして,1500年以上にわたる英語語彙史を俯瞰してみます.今後のシリーズ展開に向けて,英語の語彙の変遷について大きな見通しを得ることが目標です.英語語彙史を概観していく過程で,英語史の各時代からいくつかのキーワードをピックアップして『英語語源辞典』(研究社,1997年)をはじめとする各種の英語語源辞典を参照します.同辞典をお持ちの方は,ぜひお手元にご用意しつつ,講座にご参加ください.どんな単語が取り上げられるかを予想しながら講座に臨んでいただければ.
(以下,後記:2024/05/14(Tue))
・ 寺澤 芳雄(編集主幹) 『英語語源辞典』 研究社,1997年.
2023-03-17 Fri
■ #5072. 機械も人間も無限に増えていく語彙を学習し続けている [social_media][vocabulary][nlp][complex_system][dynamic_equilibrium]
この2日間の記事「#5070. ソーシャルメディアと中英語の綴字のヴァリエーションは酷似している」 ([2023-03-15-1]) と「#5071. ソーシャルメディアは自然言語データの最大の発生源である」 ([2023-03-16-1]) に引き続き,ソーシャルメディアの言語について.今回は同メディアにおける語彙の増加率が著しい件を取り上げる.
Vajjala 他 (296) に「増え続ける語彙」という1節がある(引用中の図の再掲は省略する).
ほとんどの言語では,毎年新しい単語が増えることはほとんどありません.しかし,「ソーシャルの言語」では,非常に早いスピードで語彙が増えています.毎日のように新しい単語が現れるのです.つまり,ソーシャルメディアのテキストを処理する NLP システムは,学習データの語彙に含まれていない大量の新語を扱うことになります.
この問題の深刻さを知るために,図8-5を見てみましょう.これは数年前に行った実験で,大規模なツイートのコーパスを集め,月ごとに新語の数を可視化したものです.この図は,1か月間に見られた新語の割合を前月のデータと比較しています.画像からもわかるように,前月の数字と比較すると,毎月10~15%の新しい単語が増えています.
冒頭の「ほとんどの言語では,毎年新しい単語が増えることはほとんどありません」は正確ではないが,ソーシャルメディアでの語彙増加率として提示されている「10~15%」を信じるならば,それと比較して微々たるものだという主張としては受け入れられそうだ.
自然言語処理のシステムは,このような日々の語彙爆発に対応するために,新単語をひたすら学習し,語彙体系を最新状態に保たなければならない.疲れ知らずの機械とはいえ,処理効率を維持するにあたり,大きな負荷になっているという.自然言語処理のシステムは,そもそも動的に更新されなければならない宿命なのである.
システムの動的性格について,Vajjala 他は別の箇所で次のようにも述べている (398) .
NLP のモデルは,静的なものではありません.本番環境でも頻繁にモデルの更新を求められます.これについてはいくつかの理由があります.本番環境では,以前の学習データとは異なる,より多くの(そしてより新しい)データを得られます.この変化に合わせてモデルを更新しなければ,モデルはすぐに陳腐化してしまい,予測性能は低下するでしょう.また,モデルの予測が間違っている場合について,ユーザーからフィードバックを得られることがあります.その際には,モデルとその特徴を反映し,適宜修正を加える必要があります.いずれの場合も,現行モデルを定期的に再学習して更新し,新しいモデルを本番にデプロイするプロセスを構築する必要があります.
ここまで考察して,これは機械による自然言語処理のシステムに限った話しではなく,まさに人間の言語処理にもそのまま当てはまることだと気づいた.人間も,周囲で生じている言語環境の変化に合わせて常に言語体系を最新状態に更新しているのであり,その点では特に機械と異なるところはない.言語は複雑系 (complex_system) の動的システムであり,動的平衡 (dynamic_equilibrium) を保ちながら機能し続けているのである.
人間の言語知識を再現しようとしている自然言語処理の分野の知見が,むしろ人間の言語知識とは何かという問いに示唆を与えてくれる1例ではないか.
・ Vajjala, Sowmya, Bodhisattwa Majumder, Anuj Gupta, Harshit Surana (著),中山 光樹(訳) 『実践 自然言語処理 --- 実世界 NLP アプリケーション開発のベストプラクティス』 オライリー・ジャパン,2022年.
2023-01-29 Sun
■ #5025. 最長の英単語をめぐって --- 『英文学者がつぶやく英語と英国文化をめぐる無駄話』より [review][spelling][vocabulary][shakespeare][word_game]
昨年出版された安藤聡(著)『英文学者がつぶやく英語と英国文化をめぐる無駄話』(平凡社)を読了した.英語(文化)史を中心とした教養のエッセイ集である.

本書の2つめのエッセイの題が「最も長い英単語」である (24--31) .本ブログでも関連する記事を3本書いてきた.
・ 「#63. 塵肺症は英語で最も重い病気?」 ([2009-06-30-1]) より pneumonoultramicroscopicsilicovolcanoconiosis
・ 「#2797. floccinaucinihilipilification」 ([2016-12-23-1])
・ 「#391. antidisestablishmentarianism 「反国教会廃止主義」」 ([2010-05-23-1])
この3つの語は当該のエッセイでも触れられているが,もう1つ私の知らなかった長大な語が挙げられていたので,オォっとなった.supercalifragilisticexpialidocious という34文字からなる無意味な語である.OED によると "A nonsense word, originally used esp. by children, and typically expressing excited approbation: fantastic, fabulous." と説明がある.1931年が初出だが,1964年のディズニー映画『メリー・ポピンズ』のなかで呪文として用いられ有名になった語ということだ.
同エッセイでは,特別部門での最長英単語も紹介されている.例えば固有名詞部門としてウェイルズの地名 Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch は58文字からなる.2つの村が合併して両方の名前が接続されたために,このようなことになったらしい.読み方は不明で,そもそも英単語なのかというと怪しいところがあり,アレではある.
同じ文字を繰り返さない pangram 的な最長英単語の部門としては,dermatoglyphics 「掌紋学」と uncopyrightable 「版権を取ることが出来ない」がそれぞれ15文字で最長語候補となる.pangram については「#1007. Veldt jynx grimps waqf zho buck.」 ([2012-01-29-1]) を参照.
Shakespeare が用いた最長単語の部門としては,『恋の骨折り損』より honorificabilitudinitatibus 「名誉を受けるに値する」が挙げられている.
最後に,語頭と語末の間に1マイルもの距離がある smiles が最長英単語であるというのは古典的なジョークである.
英語好きにぜひお勧めしたいエッセイ集.
・ 安藤 聡 『英文学者がつぶやく英語と英国文化をめぐる無駄話』 平凡社,2022年.
Powered by WinChalow1.0rc4 based on chalow