2010-09-18 Sat
■ #509. Dracula に現れる whilst (2) [corpus][lob][brown][bnc][oanc][coca][lmode][conjunction]
昨日の記事[2010-09-17-1]の続編.Dracula に現れる同時性・対立を表す接続詞の3異形態 while, whilst, whiles の頻度を,20世紀後半以降の英米変種における頻度と比べることによって,この60?110年くらいの間に起こった言語変化の一端を垣間見たい.用いたコーパスは以下の通り.
(1) Dracula ( Gutenberg 版テキスト ): 1897年,イギリス英語.
(2) LOB Corpus ( see also [2010-06-29-1] ): 1961年,イギリス英語.
(3) BNC ( The British National Corpus ): late twentieth century,イギリス英語.
(4) Brown Corpus ( see also [2010-06-29-1] ): 1961年,アメリカ英語.
(5) OANC (Open American National Corpus): 1990年以降,アメリカ英語.
(6) Corpus of Contemporary American English (BYU-COCA): 1990--2010年,アメリカ英語.
各コーパスにおける接続詞としての while, whilst, whiles の度数と3者間の相対比率は以下の通り.
| while | whilst | whiles | |
| (1) Dracula | 14 (12.61%) | 95 (85.59%) | 2 (1.80%) |
| (2) LOB | 517 (88.68%) | 66 (11.32%) | 0 (0.00%) |
| (3) BNC | 48,761 (89.41%) | 5,773 (10.59%) | 0 (0.00%) |
| (4) Brown | 592 (100.00%) | 0 (0.00%) | 0 (0.00%) |
| (5) OANC | 7,893 (100.00%) | 0 (0.00%) | 0 (0.00%) |
| (6) COCA | 246,207 (99.82%) | 447 (0.18%) | 0 (0.00%) |
Dracula の whilst の比率が異常に高い.はたして同時代のイギリス英語の文語の特徴なのだろうか.この表だけ眺めると,20世紀前半にイギリス英語で whilst が激減し,同世紀後半以降は10%程度で安定したと読める.アメリカ英語では20世紀後半では whilst はほぼ無に等しく,問題にならない.whiles に至っては,関心の発端であった Dracula での2例のみ(他に副詞としては1例あった)で,あとはどこを探しても見つからなかった.しかも,その Dracula の2例というのはいずれも訛りの強い英語を話すオランダ人医師 Van Helsing の口から発せられているもので,同時代イギリス英語でどの程度 spontaneous form であったかは分からない.
今回の調査はもとより体系的な調査ではない.ジャンルの区別や作家の文体を意識していないし,比較する時代の間隔はたまたま入手可能なコーパスに依存したにすぎない.英米変種での比較というのも思いつきである.しかし,興味深い問いが新たに生まれたので,今後は追跡調査をしてみたい.
・ Dracula と同時代の他のイギリス文語では各異形の頻度はどうなのか
・ 20世紀前半に whilst が激減したように見えるのは本当なのか,本当だとしたらその背景に何があるのか
・ アメリカ英語のより古い段階では whilst はもっと頻度が高かったと考えてよいのか
・ whiles はいつ頃まで普通に見られたのか,あるいはそもそも普通に見られる形態ではなかったのか
・ the while や the whilst などの複合形については頻度はどうだったのか
2010-08-22 Sun
■ #482. oxes の出現 [plural][coca][bnc][ame]
現代英語に残る本来語の数少ない不規則複数形の1つに ox 「雄牛;牛」の複数形 oxen がある.現代の標準変種では,古英語の弱変化名詞に直接に由来する唯一の複数形である.ところが,最近アメリカ英語で oxes が現れ始めている.誤用としてではない.『ジーニアス英和大辞典』によると ox の語義2として次のようにあり,この語義での複数形には oxes もありうるという.
2 牛のような(力強い)人, ずんぐりした人, のろまの人 // a dumb ox ((略式))(ずうたいのでかい)うすのろ.
OED によるとこの比喩的な意味は16世紀からある.現在ではアメリカ英語では ox はこの語義以外にはあまり用いられないようだ.それではということで,British National Corpus (BYU-BNC) と Corpus of Contemporary American English (BYU-COCA) で調べてみた.
BNC では oxes が2例ヒットするが,いずれも ox は不規則複数を取る名詞だと教室で教えているという文脈で oxes を誤用として紹介している例なので,事実上ゼロと考えてよいだろう.
COCA では関与する例が6例あった.いずれも話し言葉かニュース英語で,政治的な文脈において使われており,gore 「(角で)突き刺す,傷つける」という動詞の対象として用いられている.例えば,以下のごとくである.
Now our oxes are being gored more directly, not with malice, but out of some perverse ego game.
The establishment, we are sometimes -- you knows, in some cases, convenient oxes to gore. But I think there's no question they represent an important political constituency in the country.
gore (one's) ox というイディオムは,俗語で "to goad or intentionally try to piss someone off" 「突っついていじめる,嫌がらせをする」という意味を表し,アメリカ英語特有のようである.ここの ox はイディオムの一部として用いられており,特に「うすのろ」という意味ではない(イディオムの意味については こちら を参照.このイディオム中で複数形が oxes でなく oxen が用いられている例が4例あることから,この表現が非歴史的な複数形態 oxes の出現に果たしている役割を疑うことができるかもしれない.
これは,動物としてでなくコンピュータマウスの複数形としての mouses や,触覚としてでなくアンテナの複数形の antennas など,比喩的に発展した意味に規則的な複数の -s が付加されるのと類似する現象だろう.gore (one's) ox の ox は原義の「雄牛」のイメージから一歩遠ざかっており,それが oxes という形態を取ることを可能にしているのではないか.ただし,今のところ「雄牛」の意味の複数形として oxes が侵入しているという証拠は(誤用以外には)ないようだ.
2010-08-16 Mon
■ #476. That's gorgeous! [bnc][corpus][bre][semantic_change][etymology][gender_difference]
フィギュアスケートの実況などで女性コメンテーターが Gorgeous! と感嘆するのを聞くことがある.また,イギリス留学中にまだ赤ん坊だった私の娘の髪型を指して,お世話になっていたイギリス人女性が Gorgeous! と口にしていたのを覚えている.「ゴージャス」は日本語にも借用されており「華麗な,豪華な」という意味で定着しているが,日本語では賞賛を表わす叫びとしては用いないと思うので,上記の英語表現を聞くと用法が違うのだなと気づく.OALD7 によると,形容詞 gorgeous の第1語義は以下の通りである.現在では「素敵な」の語義が主要な使い方になっているようだ.
1. (informal) very beautiful and attractive; giving pleasure and enjoyment
形容詞 gorgeous はフランス語の gorgias "fine, elegant" からの借用で,一説によると語幹の gorge が "bosom, throat" であることから "ruff for the neck" 「首を飾るのにふさわしいひだ襟」と関連づけられるのではないかとされている.別の説ではギリシャの修辞家で贅沢品を好んだという Gorgias (c483--376BC) に由来するともされ,真の語源は詳らかでない.OED によるとこの語は15世紀終わりから用いられており「華麗な,豪華な」という語義が基本だったが,賞賛を表わす口語表現としての用法が19世紀後半から現れ出す.ただし,口語表現としての用法が一般化したのは20世紀に入ってからであり,とりわけポピュラーになったのは20世紀も後半から21世紀にかけてのことではないかと疑われる.
そう考える根拠の1つは,20世紀前半の辞書をいろいろと調べたわけではないが,例えば Webster's Revised Unabridged Dictionary (1913 + 1828) で調べる限り,gorgeous のエントリーに口語的な表現に対応する語義が与えられていない.
もう1つの根拠は,BNCWeb で gorgeous の頻度の統計を取ってみた結果である.いくつか興味深い結果が出た.まず明らかなのは,"informal" というレーベルから当然予想されるとおり,この語は書き言葉よりも話し言葉で頻度が顕著に高いことである.100万語中の出現頻度は,書き言葉で4.8回に対して話し言葉で17.39回である.話し言葉に限定して分布を調べたところ,特に会話文で頻度の高いことが分かった.
そして,何よりもおもしろいのは使用者の性別と年齢の分布である.gorgeous は100万語中,男性には8.89回しか用いられていないが,女性には34.64回も使われている.複数の英和辞書,英英辞書を引き比べて「主に女性語・略式」としてレーベルが貼られているのは『ジーニアス英和大辞典』だけだったが,これほど男女差が明らかであれば他の辞書でも「女性語」のレーベルが欲しいところだ.また,使用者の年齢としては24歳以下が圧倒的である.BNC が代表する20世紀後半のイギリス英語の話し言葉に関する限り,gorgeous は若年層の女性にとりわけポピュラーな表現ということが分かる.一般にはあまりこの語を用いない男性も,若年層に限っては使用頻度が比較的高いという結果も出た.全体として,gorgeous の使用はここ1?2世代の間に使用が拡大していると考えられそうである.
より細かく調査する必要はあるが,以上の情報から判断する限り gorgeous の用法がまさに目の前で変化しているということになる.口語的な賞賛の表現は19世紀末から徐々に発達してきたが,ここ数十年で若年層女子の使用によってブレイクし,それが若年層男性にも拡がりつつある.今後は他の年齢層にも及んできてますますポピュラーになるかもしれないし,一時の流行表現としてしぼんでいくかもしれない.
今後,この用法の行方を見守っていきたい.私も機会があったら(性別・年齢不相応気味に) That's gorgeous! と叫んでみることにしよう.
2010-08-02 Mon
■ #462. BNC から取り出した発音されない語頭の <h> [corpus][bnc][oanc][ame][bre][h][spelling_pronunciation]
昨日の記事[2010-08-01-1]の OANC からの結果に飽き足りずに,語頭を <h> と綴るが /h/ で発音されない単語をより多く探すべく,BNC でも同じことをやってみた.そちらのほうがおもしろい結果が出たので,結果報告する( OANC の面目丸つぶれ?).
216種類の語が得られたが,固有名詞や頭字語が多く,一覧してもあまりおもしろくない(見たい方はHTMLソースを参照).また,品詞のタグ付けに誤りがある例もあったので,今回はあくまで概要を知るための初期調査として理解されたい.一般名詞や形容詞に絞った117例をアルファベット順に示す.
habitual, habituated, habitué, haemoglobin, half, half-hour, hallucination, hallucinatory, hallucinogenic, handful, haphazardly, happy, haute-couture, hazard, heap, heartening, hedonistic, heir, heir-apparent, heiress, heirloom, hell, heparin, hepatic, heraldic, herbaceous, herbalist, hereditary, heretical, hermaphrodite, heroic, heterogenous, heterologous, heuristic, hexadecimal, hexagonal, hi, hiatus, hibiscus, hide, hierarchical, hierarchically, hierarchy, high, higher, hilarious, historian, historic, historically, historically-created, historically-evolved, historicist, historiographical, history, histrionic, hitherto, hockey, hole, holiday, holistic, holoenzyme, holy, home-grown, homogeneous, homologous, hon., honest, honest-to-god, honest-to-goodness, honestly, honesty, honorable, honorarium, honorary, honour, honour-able, honourable, honourably, honoured, honouring, hopeful, horchata, horizon, horizontal, horrendous, horrific, horror, hors-d'oeuvre, horse, hospital, host/target, hotel, hotel-keeper, hour's-worth, hour-an-a-half, hour-and-a-half, hour-glass, hour-long, hourglass, hourglass-shaped, hourly, hours, howitzer, human, humanities, humble, hundred, hydraulic, hydraulically, hydroxyapatite, hydroxyl, hypnotic, hypostasised, hypothesis, hypothetical, hysterical, hysterically
history, honest, honour, hour の関連語はやはり多い.おもしろいところを取りあげると,habitual, hallucination, hepatic, hereditary, heretical, heroic, hierarchical, hilarious, homogeneous, horizon, horrendous, horrific, hypothetical, hysterical あたりだろうか.いずれも第1音節に主強勢がおかれないので語頭の /h/ が特に弱まりやすい.ただ,第1音節に主強勢が落ちる例も少なくないことは確かである.
昨日の OANC での結果として出た herb や homage が BNC では出なかった.いずれの語も /h/ のない発音はアメリカ英語発音のみであるという辞書の記述と一致しているようだ.
それにしても,BNC と OANC の収録語数に差があるとはいえ,イギリス英語からの例の種類の豊富さは際立っている.確かにイギリス英語には h-dropping で名高い Cockney などの方言もあるし,/h/ の不安定さは著しいのではないかと予想はしていた.また,アメリカ英語では綴り字発音 ( spelling-pronunciation ) の傾向が強いことも一般論としては分かっていた.今回の BNC と OANC での初期調査の結果は予想と一致するものだったが,より詳しく調べていくと結構おもしろいテーマに発展してゆくかもしれない.
2010-04-11 Sun
■ #349. BNC Word Frequency List による音節数の分布調査 (2) [syllable][lexicology][bnc][statistics]
今回は,昨日の記事[2010-04-10-1]で扱った音節数に関するデータを,角度を変えて見てみたい.100語レベルから6000語レベルまでの各頻度レベルの数値を標準化して,単音節語から7音節音語までの相対頻度を比べられるようにしたものである.(数値データはこのページのHTMLソースを参照.)
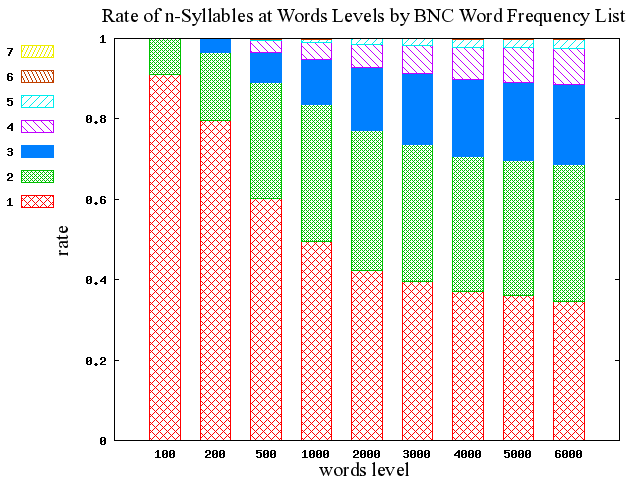
昨日のグラフだけでは読み取りにくかったいくつかのポイントが見えてきた.
・ 対象語彙が大きくなればなるほど単音節語の比率は減少するが,1000語レベル以上からの減り幅は比較的小さい
・ 2音節語の比率は,1000語レベル以上ではほとんど変化していない
・ 500語レベル以上からは3音節語と4音節語が存在感を増してくる
・ とはいえ,2000語レベル以上からは相対的な分布の変化は小さく,全体として安定しつつあるように見える
2010-04-10 Sat
■ #348. BNC Word Frequency List による音節数の分布調査 [syllable][lexicology][bnc][statistics]
昨日の記事[2010-04-09-1]に続く話題.BNC Word Frequency List の6318語の見出し語化された ( lemmatised ) 最頻語リストを材料として,音節数の分布がどのようになっているかを調査してみた.
まずはリストを頻度順に眺めてみるだけで,ある程度の検討はついた.[2010-03-02-1]の記事「現代英語の基本語彙100語の起源と割合」からも明らかなとおり,最頻基本語にはゲルマン系の本来語が多い.このことは,単音節語が多いということにもつながる.しかし,リストを下って頻度のより低い語に目をやると,徐々に2音節語,3音節語が目につくようになってくる.したがって,頻度で上位どのくらいまでを対象にするかによって,音節数の相対的な分布は変わってくることが予想される.そこで,まず6318語すべての音節数を出した上で,最頻100語,200語,500語,1000語,2000語,3000語,4000語,5000語,6000語というレベルで音節数の分布を調査した.レベル間の比較が可能となるようにグラフ化したのが下図である.(数値データはこのページのHTMLソースを参照.)
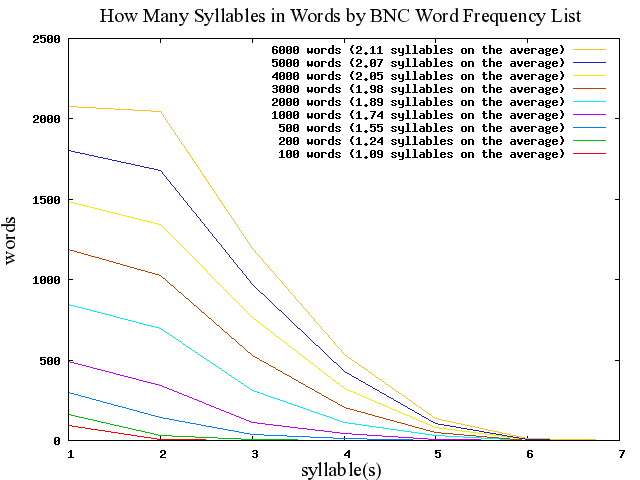
このグラフからいくつかの興味深い事実を読み取ることができる.
・ どのレベルでも単音節語が最も多い
・ 対象語彙が大きくなればなるほど,2音節語数が単音節語数に肉薄する
・ 英語語彙の圧倒的多数が単音節語か2音節語である
・ 対象語彙が大きくなればなるほど,平均音節数が漸増する
・ いずれにせよ英単語の平均音節数はせいぜい2音節ほどである
今回は最頻約6000語レベルの語彙で調査したが,対象語彙をどんどん大きくしてゆくとどのような結果が出るのか,おおいに気になった.やがては2音節語が単音節語を追い抜き,平均音節数も漸増を続けるのだろうか? あるいは平均音節数がこれ以上は変わらないという限界点が存在するのだろうか? non-lemmatised な語彙リストを材料にすると平均音節数はどのくらい変化するのだろうか? 次々に疑問が生じた.
ちなみに,最頻5000語レベルで初めて現れる7音節語が一つある.英語の平均音節数からすると異常に長い超多音節語だが,比較的よくお目にかかる単語ということになる.何であるか,想像できるだろうか? 答えは,4657番目に現れる
telecommunication
(←クリック)である.なるほど?.
2010-03-23 Tue
■ #330. Cobuild Concordance and Collocations Sampler [corpus][bnc][cobuild][collocation]
本ブログでは,オンラインで利用できる現代英語のコーパスとして,簡便に使える BNC ( The British National Corpus ),より本格的に使える BNCWeb(要無料登録)を紹介してきた.BNC はその名の如くイギリス英語専門のコーパスで,ほぼ1975年以降の英語が約1億語おさめられている.そのうち9割は書き言葉,1割は話し言葉という構成である.現在オンラインで利用できる最大級の規模の英語コーパスである.
規模だけでいえば,もっと大きな英語コーパスが存在する.常に拡大を続けるモニターコーパス The Bank of English であり,その規模は5億5000万語にまで達する.BNC と異なり,イギリス英語だけでなくアメリカ英語を含めた他の変種もカバーしている.
このうちの一部,約5600万語が Cobuild Concordance and Collocations Sampler としてオンラインで無料で公開されている.コンコーダンス・ラインは40行まで,コロケーションのスコア・ランキングは100位までしか出力されない「デモ版」ではあるが,検索語に簡単なタグ指定ができるなど,手軽な目的であれば十分に使える仕様だろう(有料版 Collins WordbanksOnline もあり).
コロケーションのスコアとしては,T-score か MI ( Mutual Information ) かを選べる.[2010-03-04-1]でも触れたが,それぞれのスコアの特徴を簡単に述べる.
・ MI (mutual information): 共起する2語が持つ意味的特性に焦点が当てられる傾向がある.慣用句,ことわざ,複合語,専門用語など独特の言い回しを構成する語に高い値が与えられる.コーパスのサイズに依存しない.3以上の値をもって collocate しているとみなせるといわれる.イメージとしては,連想ゲーム的な語と語の関係が明らかになると考えるとよい ( = lexical collocation ).低頻度語が強調される傾向があり,独特でおもしろい結果になることがある.
・ T-score: collocation 強度そのものの指標というよりも,互いに関連があると言い切れる確信度の指標.コーパスのサイズが勘案されている.通常は,2以上の値でその collocation が統計的に有意とみなされる.特定の2語の共起頻度に焦点を当てるため,キーワードの前後に頻繁に生起する前置詞,不変化詞,人称代名詞,限定詞などの文法構造を満たすための語のほか,常套句や使い古されてしまった比喩,決まり文句などを構成する語が上位にランクインする.イメージとしては,主に文型や機能語の連語情報が明らかになると考えるとよい ( = grammatical collocation ) .
コンコーダンスやコロケーションの出力は,英語の研究や学習のためだけでなく,汎用の発想ツール,連想ツールとしても使える.例えば,octopus のコロケーションの MI 値を出してみると,上位に squid, dried, october などが現れる.味わい深い.
・ 鷹家 秀史,須賀 廣 『実践コーパス言語学』 桐原ユニ,1998年.113--15頁.
2010-03-07 Sun
■ #314. -ise か -ize か (2) [spelling][bre][bnc][lob][flob][corpus][suffix][z]
[2010-02-26-1]の記事で取りあげた話題の続編.先日の記事では,単語によって比率は異なるものの,イギリス英語では -ise と -ize の両方の綴字が行われることを,BNC に基づいて明らかにした.高頻度20語については,おおむね -ise 綴りのほうが優勢ということだった.
通時的な観点がいつも気になってしまう性質なので,そこで新たな疑問が生じた.-ise / -ize のこの比率は,過去から現在までに多少なりとも変化しているのだろうか.大昔までさかのぼらないまでも,現代英語の30年間の分布変化だけを見ても有意義な結果が出るかもしれないと思い,1960年代前半のイギリス英語を代表する LOB ( Lancaster-Oslo-Bergen corpus ) と1990年代前半のイギリス英語を代表する FLOB ( Freiburg-LOB corpus ) を比較してみることにした.
それぞれのコーパスで,前回の記事で取りあげた頻度トップ20の -ise / -ize をもつ動詞について,その変化形(過去形,過去分詞形,三単現の -s 形,-ing(s) )を含めた頻度と頻度比率を出してみた(下表参照).
| item | LOB: rate (freq) | FLOB: rate (freq) | ||
| -ise | -ize | -ise | -ize | |
| recognise | 59.6% (99) | 40.4% (67) | 71.8% (127) | 28.2% (50) |
| realise | 63.2% (134) | 36.8% (78) | 68.7% (125) | 31.3% (57) |
| organise | 65.6% (42) | 34.4% (22) | 67.2% (43) | 32.8% (21) |
| emphasise | 37.7% (20) | 62.3% (33) | 62.9% (39) | 37.1% (23) |
| criticise | 52.0% (13) | 48.0% (12) | 80.0% (24) | 20.0% (6) |
| characterise | 0.0% (0) | 100.0% (4) | 56.3% (18) | 43.8% (14) |
| summarise | 35.3% (6) | 64.7% (11) | 64.7% (11) | 35.3% (6) |
| specialise | 56.3% (18) | 43.8% (14) | 81.8% (27) | 18.2% (6) |
| apologise | 68.8% (11) | 31.3% (5) | 70.6% (12) | 29.4% (5) |
| advertise | 100.0% (41) | 0.0% (0) | 100.0% (55) | 0.0% (0) |
| authorise | 77.4% (24) | 22.6% (7) | 68.2% (15) | 31.8% (7) |
| minimise | 90.0% (9) | 10.0% (1) | 80.0% (16) | 20.0% (4) |
| surprise | 100.0% (182) | 0.0% (0) | 100.0% (173) | 0.0% (0) |
| supervise | 100.0% (10) | 0.0% (0) | 100.0% (9) | 0.0% (0) |
| utilise | 70.0% (7) | 30.0% (3) | 83.3% (5) | 16.7% (1) |
| maximise | 50.0% (2) | 50.0% (2) | 50.0% (9) | 50.0% (9) |
| symbolise | 50.0% (3) | 50.0% (3) | 40.0% (4) | 60.0% (6) |
| mobilise | 66.7% (2) | 33.3% (1) | 20.0% (1) | 80.0% (4) |
| stabilise | 58.3% (7) | 41.7% (5) | 33.3% (3) | 66.7% (6) |
| publicise | 81.8% (9) | 18.2% (2) | 84.6% (11) | 15.4% (2) |
いずれも100万語規模のコーパスなので,トップ20とはいっても下位のほうの語の頻度はそれほど高くない.だが,全体的な印象としては,-ise の綴字が30年のあいだにじわじわと増えてきているようである.頻度比率に大きな変化の見られないものも確かにあるが,著しく伸びたものとして emphasise, criticise, characterise, summarise, specialise などがある.ただ,これはあくまで印象なので,全体的に,あるいは個別の単語について統計的な有意差があるのかどうかは別に検証する必要がある.また,LOB には characterise は一例も例証されないが characterisation は確認されたことからも,動詞だけでなく名詞形の -isation / -ization も合わせて調査する必要がある.さらには,対応するアメリカ英語の状況も調査し,イギリス英語の通時的変化(もしあるとすればであるが)と関係があるのかどうかを探る必要がある.
2010-03-04 Thu
■ #311. girl とよく collocate する形容詞は何か [corpus][collocation][bnc]
コーパスを使った collocation 研究は多い.しかし自分では行ったことがなかったので,McEnery et al. (56--57, 210--20) を参考にしつつ,自らお題を一つ掲げて collocation 研究のさわりを試してみた.特に collocation にかかわる様々な統計指標の特徴に注意してみたい.
お題は「girl とよく collocate する形容詞は何か」.使用するコーパスは BNCWeb .girl の左側3語までに現れる形容詞を検索対象とし,collocation の強度を示す様々な指標を出して,指標ごとに上位20個までの形容詞を一覧にしたのが下表である.
| Rank | raw frequency | observed/expected | t-score | z-score | log-likelihood | MI | MI3 |
|---|---|---|---|---|---|---|---|
| 1 | little | 15-year-old | little | little | little | 15-year-old | little |
| 2 | young | 16-year-old | young | young | young | 16-year-old | young |
| 3 | that | dark-haired | good | 15-year-old | good | dark-haired | good |
| 4 | this | 13-year-old | that | dark-haired | clever | 13-year-old | clever |
| 5 | good | nine-year-old | this | 16-year-old | poor | nine-year-old | pretty |
| 6 | one | 14-year-old | old | clever | pretty | 14-year-old | that |
| 7 | old | four-year-old | poor | pretty | old | four-year-old | 15-year-old |
| 8 | other | year-old | other | teenage | that | year-old | dark-haired |
| 9 | poor | clever | clever | 13-year-old | beautiful | clever | poor |
| 10 | clever | teenage | one | nine-year-old | lovely | teenage | 16-year-old |
| 11 | beautiful | blonde | pretty | four-year-old | golden | blonde | this |
| 12 | pretty | pretty | beautiful | head | nice | pretty | old |
| 13 | small | head | nice | 14-year-old | 15-year-old | head | beautiful |
| 14 | any | little | lovely | poor | teenage | little | teenage |
| 15 | nice | wee | big | blonde | dark-haired | wee | lovely |
| 16 | big | eldest | small | good | head | eldest | head |
| 17 | another | brave | golden | golden | 16-year-old | brave | golden |
| 18 | lovely | golden | tall | beautiful | tall | golden | nice |
| 19 | new | silly | dear | lovely | this | silly | tall |
| 20 | golden | young | teenage | year-old | dear | young | blonde |
各指標の読み方を以下にメモ.
・ raw frequency: コーパス内の総頻度.統計計算を加える前のベースとなる値で,それ自体は collocation の強度計測にはほとんど役に立たない.
・ observed/expected: 偶然に collocate している可能性からどれだけ隔たっているか.collocation の指標としては粗い.
・ t-score: 広く使われる指標.コーパスのサイズが勘案されている.通常は,2以上の値でその collocation が統計的に有意とみなされる.collocation 強度そのものの指標というよりも,互いに関連があると言い切れる確信度の指標.(後記 2010/03/21(Sun):特定の2語の共起頻度に焦点を当てるため,キーワードの前後に頻繁に生起する前置詞,不変化詞,人称代名詞,限定詞などの文法構造を満たすための語のほか,常套句や使い古されてしまった比喩,決まり文句などを構成する語が上位にランクインする.つまり,主に文型や機能語の連語情報 [ grammatical collocation ] に寄与する.)
・ z-score: 両語それぞれのコーパス中の全頻度を勘案したうえで,その collocation が期待値よりどれだけ高い頻度で現れているかを示す.広く使われている指標だが,データが正規分布をなすとの前提に立っており,多くの場合に必ずしも適切でない.コーパスが巨大か,あるいは(たいてい関心を引かない)超高頻度語を対象にするのでない限り,問題が生じうる.低頻度語が強調される傾向がある.
・ log-likelihood (LL test): データの正規分布を前提としない.コーパスのサイズが小さめでも有効.高頻度語にも低頻度語にも有効.手堅い統計値.
・ MI (mutual information): LL ほど統計的に厳格ではないが,z-score や LL の代替指標として広く使われている.3以上の値をもって collocate しているとみなせるといわれる.負の値が出ると,むしろ両語が背反し合うという意味になる.コーパスのサイズに依存しない.z-score と同様に低頻度語が強調される傾向がある.unique collocation を知るなど辞書学的な用途には役立つ指標だが,英語教育用には不向き.(後記 2010/03/21(Sun):共起する2語が持つ意味的特性に焦点が当てられる傾向がある.慣用句,ことわざ,複合語,専門用語など独特の言い回しを構成する語に高い値が与えられる.)
・ MI3: MI の低頻度語を強調しがちな傾向を補正した指標の一つ.英語教育用に向いている.同様の趣旨の指標として,log-log test というものもある.
正直なところ,どう読み解けばいいのかよくわからない(あくまで練習題なので・・・).little, young, good, clever などいずれの指標でもランクの高いものはあり,これらは明らかに強い collocation ありとみなしてよいだろう.ほかには, z-score や MI が 15-year-old などの影響を激しく反映しているのに対して,手堅い log-likelihood や補正済みの MI3 の値は -year-old を比較的よくはじいていることがわかる.このことから,-year-old は girl とよく collocate することは確かながらも,いくつかの指標が示唆するような最上位のランクであるというのは言い過ぎであるといえそうである.MI値の上位にはやや個性的と思われる形容詞も含まれており,若干くせのある値だということも肌で感じることができた.だが,統計値の解読はなかなかに難しい・・・.
・ McEnery, Tony, Richard Xiao, and Yukio Tono. Corpus-Based Language Studies: An Advanced Resource Book. London: Routledge, 2006.
2010-02-26 Fri
■ #305. -ise か -ize か [spelling][ame_bre][bnc][corpus][suffix][z]
私は,普段,英語を書くときにはイギリス綴りを用いている.英国留学中,指導教官に -ize / -ization の語を -ise / -isation に訂正されてから意識しだした習慣である.そのきっかけとなったこのペアは,一般には,アメリカ英語ではもっぱら -ize を用い,イギリス英語では -ise も用いられるとされる.
イギリス英語での揺れの理由としては,アメリカ英語の影響や,接尾辞の語源としてギリシャ語の -izein に遡るために -ize がふさわしいと感じられることなどが挙げられるだろう.単語によって揺れ幅は異なるようだが,実際のところ,イギリス英語での -ise と -ize のあいだの揺れはどの程度あるのだろうか.
この問題について,Tieken-Boon van Ostade (38) に BNC ( The British National Corpus ) を用いたミニ検査が示されていた.generalise, characterise, criticise, recognise, realise の5語で -ise と -ize の比率を調べたというものである.このミニ検査に触発されて,もう少し網羅的に揺れを調べてみようと思い立ち,BNC-XML で計399個の -ise / -ize に揺れのみられる動詞についてそれぞれの頻度を出してみた.以下は,-ise / -ize を合わせて頻度がトップ20の動詞である.ちなみに,399個の動詞についての全データはこちら.
| item | -ise rate (freq) | -ize rate (freq) | -ise + -ize |
|---|---|---|---|
| recognise | 61.1% (9143) | 38.9% (5812) | 14955 |
| realise | 63.2% (9442) | 36.8% (5492) | 14934 |
| organise | 62.3% (5540) | 37.7% (3359) | 8899 |
| emphasise | 60.0% (2998) | 40.0% (1998) | 4996 |
| criticise | 54.9% (2054) | 45.1% (1688) | 3742 |
| characterise | 52.2% (1398) | 47.8% (1278) | 2676 |
| summarise | 61.4% (1164) | 38.6% (731) | 1895 |
| specialise | 70.7% (1163) | 29.3% (481) | 1644 |
| apologise | 68.8% (1084) | 31.2% (492) | 1576 |
| advertise | 99.5% (1542) | 0.5% (7) | 1549 |
| authorise | 64.5% (987) | 35.5% (543) | 1530 |
| minimise | 65.4% (984) | 34.6% (521) | 1505 |
| surprise | 99.9% (1345) | 0.1% (1) | 1346 |
| supervise | 99.8% (1303) | 0.2% (3) | 1306 |
| utilise | 68.9% (798) | 31.1% (360) | 1158 |
| maximise | 63.2% (719) | 36.8% (418) | 1137 |
| symbolise | 49.2% (324) | 50.8% (334) | 658 |
| mobilise | 45.5% (286) | 54.5% (342) | 628 |
| stabilise | 53.5% (334) | 46.5% (290) | 624 |
| publicise | 69.4% (419) | 30.6% (185) | 604 |
この表で advertise, surprise, supervise の3語については -ise が規則だとみなしてよいだろうが,それ以外は全体的に -ise がやや優勢なくらいで,イギリス英語でも -ize は十分に一般的であることがわかる.399語の平均を取ると,-ise の比率は51.6%となり,-ize とほぼ拮抗していることがわかる.詳しく調べれば個々の動詞の慣用というのがあるのかもしれないが,イギリス英語の綴り手としては,ひとまず「-ise に統一」と考えておくのも手かもしれない.
・ Tieken-Boon van Ostade, Ingrid. An Introduction to Late Modern English. Edinburgh: Edinburgh UP, 2009.
2009-10-05 Mon
■ #161. rhinoceros の複数形 [plural][etymology][bnc][corpus][clipping][drift]
[2009-08-26-1]で octopus の複数形は何かという話題を扱ったが,今回は rhinoceros /raɪnˈɑsərəs/ 「犀」の複数形は何かという問題に分け入りたい.
この語はギリシャ語にさかのぼり,rhīno- "nose" + -kerōs "horned" の複合語である.英語には1300年頃に借用された.
この語は,私が知っている英単語のなかで,取り得る複数形態の種類が最も多い語である.まずは OED で調べてみると,8種類の複数形があり得ると分かる.
rhinoceros, rhinocerons, rhinocerontes, rhinoceroes, rhinocero's, rhinoceri, rhinoceroses, rhinocerotes
とてつもない語なので,Jespersen の文法などでも取りあげられているし,『英語青年』にも記事がある.これには,さすがに犀もびっくりしていることだろう.
須貝氏の記事によれば,1905年に Sir Charles Eliot なる人物がこの問題に頭を悩ませていたという記録がある.rhinocerotes は衒学的であり,かといって rhinoceroses は口調が良くない.口語での省略形の rhinos では威厳がなく,単複同形の rhinoceros では問題を回避しているに過ぎないとも言う.
また,1938年には Julian Huxley なる生物学者が,rhinoceri は誤用であり,rhinoceroses がもっとも抵抗が少ないだろうが,それですら衒学的な響きを禁じ得ないとも述べている.結論としては rhinos を正規の複数形とするよう提案している.
この二人の記録と洞察を忠実に受け入れて考えてみよう.1905年の時点で rhinocerotes にはすでに衒学的な響きがあったということだが,「規則複数」の rhinoceroses には特に衒学的な響きがあったとは触れられていない.だが,1938年には rhinoceroses ですら衒学的になっていたということが述べられている.だからこそ,rhinos を提案したわけである.
とすると,1938年までの推移の順序は以下のように推論できるのではないか.まず,rhinocerotes を含めた多くの「不規則複数」が20世紀初頭にはすでに衒学的だった.そこで,「規則複数」たる rhinoceroses がより一般的になりかけた.だが,口調上の理由でこれも最終的には好まれず,やや口語ぽい響きが気にはなるものの,省略形に規則的な -s を付け足した rhinos が一般化し出した.
須貝氏のいうように,この30年余の期間における「犀」の複数形の推移は,Jespersen のいう simplification と monosyllabism という英語の通時的傾向を表す好例のように思われる( rhinos の場合,厳密には monosyllabism への変化とはいえないが,音節数の減少であることは確かである).まず不規則を規則化し,それでも飽き足りずに切り株 ( clipping ) にした.
さて,現在に話しを移そう.須貝氏の記事は1938年のものであり,それから現在までに「犀」の複数形はどのように変化したか.BNC ( The British National Corpus ) の単純検索によると,「不規則複数」のヒットは皆無だった(タグ付き検索ではないため,単複同形の rhinoceros の複数形としてのヒット数については未確認).規則形については,ヒット数は以下の通り.
| rhinoceroses | 13 |
| rhinos | 100 |
複数の学習者英英辞書で,rhino には今でも「口語」というレーベルがついているものの,全体の頻度としては rhinoceroses を突き放している.須貝氏の記事から約70年,どうやら結論はすでに出たといってもよさそうである.
・Jespersen, Otto. Growth and Structure of the English Language. 2nd Rev. ed. Leipzig: Teubner, 1912. 143 fn.
・Jespersen, Otto. A Modern English Grammar on Historical Principles. Part 2. Vol. 1. 2nd ed. Heidelberg: C. Winter's Universitätsbuchhandlung, 1922. 39.
・須貝 清一 「Rhinoceros の複数」 『英語青年』80巻3号,1938年,81頁.
2009-08-26 Wed
■ #121. octopus の複数形 [plural][greek][bnc][corpus]
octopus の複数形は何か.手持ちの辞書を引き比べてもらうとわかるが,すべての辞書で規則的な octopuses が挙がっていることだろう.特に記述のない辞書では octopuses を当然とみなしての省略に違いない.
だが,大きめの辞書や古めの辞書を引くと,octopodes なる複数形が併記されている.例えば OED では,octopodes /ɒkˈtəʊpədi:z/ が先に挙がっており,その後に octopuses が追記されている.
Web3 ( Webster's Third New International Unabridged Dictionary ) にいたっては,第三の複数形として octopi /ˈɑktəˌpaɪ/ が挙げられている.
複数形態に関するこの複雑な状況は,この単語がギリシャ語からネオ・ラテン語を経て,18世紀に英語へ借用されてきたという経緯による.ギリシャ語の屈折に従えば octopodes となり,ラテン語の屈折を適用すると octopi になる( see sg. alumnus -- pl. alumni ).ただし,ラテン語に準じた octopi は,COD11 ( The Concise Oxford English Dictionary 11th ed. ) によると誤用とされている.
ただ,この二種類の古典語に基づく不規則複数形は,現在では衒学的・専門的な響きが強すぎて普通には用いられないと考えてよい.このことは,多くの学習者英英辞典で octopuses のみが挙げられていることからもわかる.
BNC ( The British National Corpus )で調べてみるとヒット数は以下の通りだった.
| octopuses | 29 |
| octopi | 11 |
| octopodes | 4 |
ついでだが,日本語ではタコを数えるときにつける助数詞は「匹」でもよいし,イカと同じく「杯」でもよいという.知らなかった.
Powered by WinChalow1.0rc4 based on chalow