2011-04-05 Tue
■ #708. Frequency Sorter CGI [corpus][bnc][statistics][web_service][cgi][lexicology][plural]
何らかの基準で集めた英単語のリストを,一般的な頻度の順に並び替えたいことがある.例えば,[2011-03-22-1]で論じたように,頻度と不規則な振る舞いとの関係を調べたいときに,注目する語(群)の一般的な頻度を知る必要がある.この目的には,[2010-03-01-1]で紹介したような大規模な汎用コーパスに基づく頻度表が有用である.BNC lemma-pos list (122KB) や ANC word-tagset list (7.2MB) などで問題の語を一つひとつ検索し,頻度数や頻度順位を調べてゆけばよいが,語数が多い場合には面倒だ.そこで,上記2つの頻度表から,入力した語(群)の頻度と順位を取り出す CGI を作成した.
改行でもスペースでもカンマでもよいのだが,区切られた単語リストを以下のボックスに入力し,"Frequency Sort Go!" をクリックする.出力結果を頻度順位の高い順にソートする場合には,"sort by rank?" をオンにする(デフォルトでオン.オフにすると,入力順に出力される).例えば,現代標準英語に残る純粋に i-mutation を示す複数形は以下の7語のみである(複合語,二重複数,[2011-04-01-1]で話題にした sister(e)n は除く).これをコピーしてボックスに入力する.
foot, goose, louse, man, mouse, tooth, woman
まず,BNC lemma-pos list による出力だが,この頻度表は約1億語の BNC 全体から,頻度にして800回以上現われる,上位6318位までの見出し語 ( lemma ) を収録している.したがって,それよりも頻度の下回る goose, louse については空欄となっている.頻度と不規則性の相関関係を考える際に参考になるだろう.
次に,ANC word-tagset list による出力が続くが,この頻度表は BNC のものよりも規模が大きく,かつきめ細かい.合計22,164,985語を有する ANC (American National Corpus) から,Penn Treebank Tagset によってクラス付与された単位で語形が列挙されたリストである.タグセットが細かいので読みにくいし,自動タグ付与に起因するエラーも少なからず含まれているが,BNC のものよりも低頻度の語(形)を収録しているので,goose や louse の頻度情報も現われる.こちらの頻度表では WORD FORM ごとの頻度も確認できるため,直接 geese や lice の頻度も確かめられる.
当初 Frequency Sorter の用途として想定していたのは,上記の不規則複数形を示す語群などの頻度と順位の一括調査だったが,他にも用途はあるかもしれない.以下に,思いつきをメモ.
・ 1単語から使えるので,like のような多品詞語を入力して,品詞(あるいはタグ付与されたクラス)ごとの頻度を取り出せる.
・ ヒット数だけを確認したい場合には,いちいちコーパスを立ち上げる必要がない.
・ 論文やプレゼンで,ある目的で集めた数百語の単語リストの中から典型的な例,分かりやすい例を10個ほど示したいときなど,頻度の高い10個を選べばよい.例えば,[2011-03-29-1]で列挙した sur- を接頭辞にもつ単語リストのうち,例示に最もふさわしい10個を選ぶなどの目的に.頻度に基づいた順番のほうが,ランダム順やアルファベット順よりも親切なことが多いだろう(今後,本ブログ執筆に活用する予定).
・ 英米それぞれの代表的なコーパスに基づく頻度表を利用しているので,綴字や形態などの頻度の英米差を確認するのに使える.
・ (実際には lemmatisation が必要だが)適当な英文を放り込んでみて,妙に頻度の低い語が含まれていないかを調べる.頻度のツールなので,その他,教育・学習目的にいろいろと使えるかもしれない.
2011-03-25 Fri
■ #697. Log-Likelihood Tester CGI [corpus][bnc][statistics][web_service][cgi][lltest][sociolinguistics]
昨日の記事[2011-03-24-1]で Log-Likelihood Test を話題にした.計算には Rayson 氏の Log-likelihood calculator を利用すればよいと述べたが,実際の検定の際に作業をもう少し自動化したいと思ったので CGI を自作してみた.細かい不備はあると思うが,とりあえず公開.
上のテキストボックスに入力すべきデータは,タブ区切りの表の形式.1行目(省略可)はコーパス名,2行目以降はキーワードと観察頻度数(ヒット数),最終行は各コーパスのサイズ(語数)."#" で始まる行はコメント行として無視される.1列目のキーワード列は省略可.
以下のテキストが入力サンプル.[2010-09-11-1]の記事で取り上げたテレビ広告で頻用される形容詞(比較級と最上級を含む)トップ20の頻度を,BNCweb の話し言葉サブコーパスから話者の性別に整理した表である.このままコピーして入力ボックスに貼り付けると,出力結果が確認できる.
BNC_Male_Speakers BNC_Female_Speakers new 149 91 good 408 310 free 173 75 fresh 84 118 delicious 12 34 full 210 107 sure 532 328 clean 197 223 wonderful 270 258 special 177 82 crisp 10 16 fine 347 215 big 470 415 great 203 96 real 163 80 easy 326 157 bright 113 110 extra 347 203 safe 182 92 rich 120 45 #-------- corpus_size 4949938 3290569
男女間で有意差の特に大きいのは,対応行が赤で塗りつぶされた fresh, delicious, clean, wonderful, big で,いずれも期待度数に基づいて計算された Diff_Co ( "Difference Coefficient" 「差異係数」 ) がマイナスであることから,女性に特徴的な形容詞ということになる.big は意外な気がしたが,おもしろい結果である.一方,男性に偏って有意差を示すのは黄色で示した easy や rich である.この結果はいろいろと読み込むことができそうだし,より詳細に調べることもできる.広告の形容詞という観点からは,話者ではなく聞き手の性別,年齢,社会階級などを軸に調査してもおもしろそうだ.いろいろと応用できる.
2011-01-16 Sun
■ #629. 英語の新語サイト Word Spy [lexicology][neologism][link][web_service]
英語の新語ウォッチには Paul McFedries によるサイト Word Spy が注目に値する.1996年以来,新語が日々追加されており,現時点で2750以上の新語が登録されている.最大の特徴は,ほとんどの新語(全体の約85%)について用例と出典が与えられており,多く(全体の約73%)は初出年も記されていることだ.
サイトを走査し,初出年の記載のある2019個について初出年ごとに数え上げてみたのが次の棒グラフである.連続して50例を超えているのは1987--2006年の20年間で,特に1990年代は層が厚い.
1962 ( 1) 1963 ( 1) 1964 ( 1) 1970 ( 1) 1972 ( 2) * 1973 ( 3) * 1975 ( 5) ** 1976 ( 8) **** 1977 ( 11) ****** 1978 ( 14) ******* 1979 ( 16) ******** 1980 ( 24) ************* 1981 ( 33) ****************** 1982 ( 32) ***************** 1983 ( 39) ********************* 1984 ( 38) ********************* 1985 ( 54) ****************************** 1986 ( 47) ************************** 1987 ( 59) ******************************** 1988 ( 66) ************************************ 1989 ( 67) ************************************* 1990 ( 77) ****************************************** 1991 ( 78) ******************************************* 1992 ( 83) ********************************************** 1993 ( 72) **************************************** 1994 (100) ******************************************************* 1995 (101) ******************************************************** 1996 (101) ******************************************************** 1997 ( 87) ************************************************ 1998 ( 78) ******************************************* 1999 (109) ************************************************************ 2000 ( 85) *********************************************** 2001 (111) ************************************************************* 2002 ( 87) ************************************************ 2003 ( 66) ************************************ 2004 ( 57) ******************************* 2005 ( 56) ******************************* 2006 ( 61) ********************************** 2007 ( 32) ***************** 2008 ( 33) ****************** 2009 ( 14) ******* 2010 ( 9) *****
[2011-01-10-1]の記事で American Dialect Society による2010年の流行語大賞の話題を取り上げたが,そのノミネート語の多くは Word Spy で発見できなかった.ただし,MOST LIKELY TO SUCCEED 部門でノミネートされた hacktivist と telework はしっかりと掲載されていた.
掲載基準など詳しいことは分からないが,American Dialect Society の定期刊行誌 American Speech の新語記事 "Among the New Words" と合わせて,直近数十年の新語の傾向を探る資料として活用することができるかもしれない.
2011-01-05 Wed
■ #618. OED の検索結果から語彙を初出世紀ごとに分類する CGI [lexicology][oed][cgi][web_service]
[2011-01-03-1], [2011-01-04-1]の記事で,OED 検索語彙を初出世紀ごとに分類して数え上げるという作業を行なった.よく考えてみると,このような作業はこれまでにも様々な調査・研究で繰り返し行なってきたことである.通時的語彙研究の基礎作業として今後も繰り返し行なう作業だと思われるので,OED の出力結果をもとに世紀ごとに数え上げるためのツールを作っておくことにした.名付けて "OED Century-by-Century Sorter".
以下は使用方法の説明だが,The Oxford English Dictionary. 2nd ed. CD-ROM. Version 3.1. Oxford: OUP, 2004. での作業を前提としている.ヴァージョンが異なると動かないかもしれないのであしからず.
(1) OED の ADVANCED SEARCH 等により,特定の条件に該当する語彙リストを出力させる.
(2) 下のテキストボックスに,(1) の検索に適当につけた簡便なタイトルを,ピリオド1文字の後に続けて入力する.例えば ".alchemy" .これが見出し行となる.
(3) テキストボックスで改行後に,(1) の出力結果を丸ごとコピーして貼り付ける.OED での出力結果が1画面に収まらない場合には次ページに進んで累積コピーし,テキストボックスに累積して貼り付けてゆく.年代順にソートされていなくても可.
(4) 続けて別の検索を行なう場合には (1), (2), (3) の作業を繰り返す.テキストボックスには,貼り付けたテキストが累積されてゆくことになる.
(5) Go をクリックすると,各検索結果について世紀ごとにカウントされた表が現われる.
説明するよりも実例を見るのが早いので,こちらのテキストファイルを用意した.これは,OED の ADVANCED SEARCH で "language names" にそれぞれ Japanese, Chinese, Malay, Korean, Vietnamese を入れて検索した結果の語彙リストを上記の仕様で納めたもの.これらの言語からの借用語数を世紀ごとに把握するのが狙いである.もっとも,OED の検索機能の限界で,それなりの数の雑音が結果リストに混じっているのでその点には注意.この(ような仕様に則った)テキストをコピーして,以下のテキストボックスに貼り付け,Go をクリックすれば表が出力される.
CGI スクリプトは大雑把な仕様なので,およその傾向を知るためのツールとして参考までに.特に以下の点に注意.
・ 初出年が "a1866", "c1629", "15..", "?c1400" などとなっている語はそれぞれ19, 17, 16, 14世紀へ振り分けられる
・ 初出年の記載のない語は一括して「0世紀」として振り分けられる
(後記 2011/04/24(Sun):OED Online の Timeline 表示では,初出世紀の頻度をグラフ化までしてくれるので,今回の CGI よりも使い勝手がよい.ただし,CD-ROM版の OED で作業するときや,設定に細かいチューニングが必要な場合のために自作した.)
2010-12-30 Thu
■ #612. Academic Word List [lexicology][lexicography][academic_word_list][web_service][text_tool][elt]
英語教育や辞書学の分野で Academic Word List (AWL) という語彙集が知られている.1998年に Avril Coxhead が The Academic Corpus という350万語からなる独自コーパスをもとに英語教育用に開発した570語とその派生語(合わせて word family と呼ばれる)からなる語彙集で,高等教育で用いられる頻度の高い語からなっている.
もう少し詳しく AWL の語彙選定基準を記せば次のようになる.(1) 各 word family がコーパスの Arts, Commerce, Law, Science 部門のサブセットすべてにおいて生起し,かつ細分化された28分野のサブセットの過半数に生起する.(2) 各 word family の出現頻度がコーパス全体で100回を超える.(3) 各 word family がコーパスの各部門で最低10回は生起する.(4) GSL ( General Service List ) (1953) の最頻2000語は除く ( see [2010-03-02-1] ) . (5) 固有名詞は除く.(6) et al, etc, ibid などの最頻ラテン語表現は除く.
こうして厳選された語彙集が AWL で,AWL Headwords から閲覧およびダウンロードできる.word family の頻度の高い順に1から10の Sublists としてグループ分けされており,すべて合わせるとコーパス全体に生起する語の9.8%を覆うという.
最近の上級者用英英辞書は軒並み AWL の重要性を認識しているようだ.2006年出版の Longman Exams Dictionary を皮切りに,2007年の Longman Advanced American Dictionary, 2nd ed.,2009年 Longman Dictionary of Contemporary English, 5th ed. など売れ筋辞書でも AWL が考慮されている ( Dohi et al., p. 174 ) .Macmillan, Collins COBUILD 系でも同様である.目下の AWL の評価は Dohi et al. によると以下の通りである.
It remains to be seen whether Coxhead's AWL will continue to be used, will be revised or replaced in future advanced learners' dictionaries, because not all scholars concur with her AWL. . . . The AWL could be regarded for the time being as "a quick reference" for academic vocabulary until more research bears fruit . . . . (100)
関連して The AWL Highlighter なるツールがあり,ここに英文テキストを入れると,AWL 語彙をハイライトしてくれる.私が最近書いた英語論文のイントロ部の1235語で試してみたら,Sublist 10 までのレベルで128語がハイライトされた.これは全体の10.36%であり,academic 度は合格か!?
・ Dohi, Kazuo, Tetsuo Osada, Atsuko Shimizu, Yukiyoshi Asada, Rumi Takahashi, and Takashi Kanazashi. "An Analysis of Longman Dictionary of Contemporary English, Fifth Edition." Lexicon 40 (2010): 85--187.
2010-12-25 Sat
■ #607. Google Books Ngram Viewer [corpus][web_service][ame_bre][google_books][n-gram][statistics][frequency][lexicology]
Google がものすごいコーパスツールを提供してきた.Google Books Ngram Viewer は Google Labs 扱いだが,その規模と可能性の大きさに驚いた.2004年以来1500万冊の本をデジタル化してきた Google が,そのサブセットとなる520万冊の本,5000億語をコーパス化した.英語のほかフランス語,ドイツ語,ロシア語,スペイン語,中国語が含まれているが,英語では British English, American English, English, English Fiction, English One Million からサブコーパスを選択できる.最大の特徴は,指定した5語までの検索語の頻度を過去5世紀(1500--2008年)にわたって追跡し,グラフで表示してくれることだ.Google からの公式な説明はこちらの記事にある.
規模が大きすぎてコーパスとしてどう評価すべきかも分からないが,ひとまずはいじるだけで楽しい.上記の記事内にいくつかのサンプルがあるが,英語史的な関心を引くサンプルとして burnt と burned の分布比較があったので,English, American English, British English の3サブコーパスをグラフを出してみた.
次に,本年度の卒論ゼミ生の扱った話題を拝借し,一般に AmE on the street, BrE in the street とされる前置詞使用の差異を Google Books Ngram Viewer で確認してみた.American English と British English のそれぞれのサブコーパスから出力されたグラフは以下の通り.
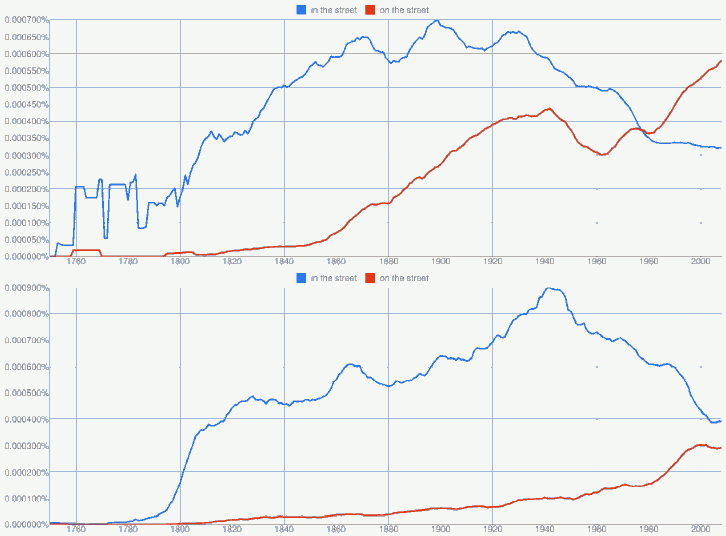
in と on の選択は句の意味(「街路で」か「失業して」か)などにも依存するため単純な形態の頻度比較では不十分だが,傾向はつかめる.
[2010-08-16-1], [2010-08-17-1]の記事で扱った gorgeous についても調べてみた.19世紀には流行っていたが20世紀には落ち目であったこの形容詞が,American English において1980年代以降,再び勢いを盛り返してきている状況がよくわかる.British English でも復調の兆しがあるだろうか?
コーパス言語学一般にいえるが,ツールの使用はアイデア次第である.文化史的な観点からは,[2009-12-28-1]の記事で紹介した American Dialect Society による "Words of the Century" や "Words of the Millennium" のノミネート語句を検索してみるとおもしろい.
他のオンラインコーパスについては[2010-11-16-1]を参照.
2010-08-25 Wed
■ #485. 語源を知るためのオンライン辞書 [web_service][link][dictionary][etymology]
今日は語源情報を与えてくれるオンライン辞書を紹介したい.専門的なオンラインの英語語源辞書は Online Etymology Dictionary だけだが,一般のオンライン辞書の語源欄にも便利なものがある.英語語源情報ぬきだしCGI(一括版)もどうぞ.
(1) 唯一の本格派オンライン語源辞書
・ Online Etymology Dictionary: Douglas Harper 氏による本格的な語源辞書.初出年あり.英語語源情報ぬきだしCGI(一括版)でもお世話になっています.お薦め.
(2) 語源の勉強になるお薦めの辞書
・ Dictionary.com: 初出年あり.The Random House dictionary や Collins English Dictionary などの複数の辞書の記述を比べられるので便利.お薦め.
・ The Free Dictionary: American Heritage Dictionary of the English Dictionary と Collins English Dictionary に基づいた簡潔な語源説明.比べられて便利.また,thesaurus の情報も一緒に入ってきて有用.単なる類義語だけでなく関連語が一覧されるので,語彙増強にも役立つ.お薦め.
・ Merriam-Webster's Online Dictionary: 老舗辞書の語源欄として有用.初出年あり.
・ スペースアルクの語源辞典: 日本語で分かりやすい.関連語の一覧が出るので,語彙増強に利用できる.
(3) 意味や類義語などを知るついでに語源を軽く知りたいときに
・ Oxford Dictionaries Online - English Dictionary and Thesaurus: 老舗の辞書に簡潔な語源説明あり.Origin 欄で読みやすい説明.
・ Webster's Revised Unabridged Dictionary (1913 + 1828): 本格派辞書(旧版)の語源欄.
・ HyperDictionary.com: 同じく Webster (1913) の語源欄.ただ,thesaurus の情報も一緒に入ってくるので便利なときも.
・ Wiktionary: 簡潔な語源説明.先頭に語源欄が来る.
・ MSN Encarta Dictionary: 簡潔な語源説明.
(4) 語源に関する読み物
・ Etymologically Speaking: 語源豆辞典.228語しかないが各々に丁寧な説明があり,辞書としてよりも読み物として面白い.
・ hellog の語源の話題: 本ブログでも何かと語源は断片的に扱っているので.検索ボックスに "etymology ○○" (○○は英単語)などとすると引っかかるものがあるかもしれない.
2010-08-23 Mon
■ #483. Merriam-Webster Online が充実している [dictionary][web_service][link]
たまに表面的に利用することがあったが,ちゃんとサイト内を巡ったことはなかった.アメリカの老舗辞書出版社 Merriam-Webster の Merriam-Webster Online の充実振りに驚いた.Unabridged Dictionary こそ有料サービスだが,以下のものはフリーで利用できる.
・ Merriam-Webster Collegiate Dictionary
・ Thesaurus
・ Medical Dictionary
・ Learner's Dictionary: 2008年出版のアメリカ発・初のアメリカ英語 EFL 辞書 Merriam-Webster's Advanced Learner's English Dictionary ( MWALED ) に対応するオンライン版.以下の検索ボックスから検索可能.最近,老舗のイギリス系 EFL 辞書( LDOCE5 や OALD7 ) は語源に力を入れているが,MWALED は語源は重視していないようだ.
・ Encyclopedia - Britannica Online Encyclopedia
・ Visual Dictionary Online: 絵で見る百科辞典といった風.画像をブログに貼り付けたりできるので,今後本ブログでも利用機会が増えるかもしれない.例えば,昨日の記事[2010-08-22-1]で扱った ox と引っかけてウシの仲間たちを紹介.

2010-08-11 Wed
■ #471. toilet の豊富な婉曲表現を WordNet と Visuwords でみる [web_service][thesaurus][synonym][link]
昨日の記事[2010-08-10-1]で,toilet の婉曲表現が豊富であることを見た.複数の辞書を引き比べていて感じたが,最近の(特に学習者用)英英辞書は類義語間の使い分けや語法の解説が詳しく,類義語辞典 ( thesaurus ) ならずともそれに準ずる実用的な類義語リストが得られて有用である.それでも,類義語リストの提示に特化した thesaurus にはかなわない.
最近はWeb上にも thesaurus が豊富に転がっており,例えば the Free Online Dictionary, Thesaurus and Encyclopedia や Thesaurus.com などが手軽に利用できる.昨日はWeb辞書は調べていなかったが,追加すべき「トイレ」代替表現がいくつかあるようである.
Web上の本格的な thesaurus として有名なのは,Princeton University の George A. Miller の指揮によって編纂されている WordNet である.自然言語処理の世界では WordNet と連係しながら様々な応用が図られているようだ.現時点では Version 3.0 のデータベースがこちらから検索可能となっており,例えば toilet の検索結果はこの通り である.上位語 ( hypernym ) や下位語 ( hyponym ) へも一瞬のうちにアクセスでき,英語の意味の世界が手軽に扱えるようになったことを実感できる.また,WordNet 3.0 database statistics には英語の名詞の平均語義数が1.24なのに対して動詞の平均語義数は2.17であるなど,有用な情報がある.
語の意味の世界を視覚化したネットワーク図が手軽に得られるようなWeb上のサービスも出てきた.Visual Thesaurus がその1つだが有料.フリーでも以下のような簡便なネットワーク図が得られる.
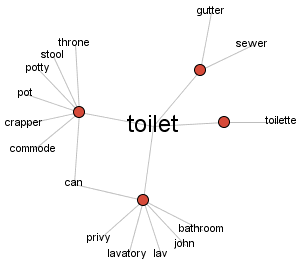
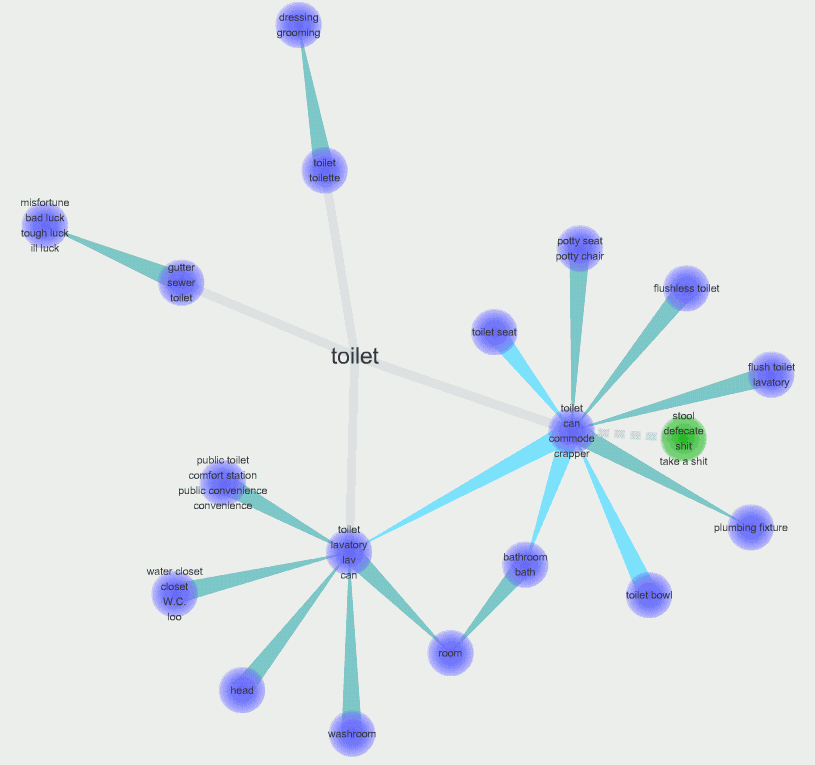
Visual Thesaurus は有料なので,代わりに私がたまに使っているフリーのものが Visuwords.上記の WordNet のデータベースと連係している.出力されるネットワーク図は以下の通り.以下のイメージをクリックして現われる拡大画像,あるいは Visuwords で直接 toilet を検索した出力で,詳細を確かめてみてほしい.
2010-04-24 Sat
■ #362. 英語例文検索 EReK [corpus][kwic][web_service]
今日は軽くウェブ上のコンコーダンサーを紹介.英語例文検索 EReK は「英語で書かれたウェブページのテキストを巨大な例文集(コーパス)とみなし,それを検索するサイト」.Yohoo! の Web API が利用されている.出力は KWIC ( Key Word in Context ) で,百数十の例文が表示される.各コンコーダンス・ラインから,ワンクリックでソースに飛ぶことができるのも便利.また,キーワード前後の語での並べ替え機能や,検索対象を .edu ドメインや ニュースサイトに限定するオプションも装備されている.「ウェブ上の文書なので正確な表現である保証はありません」と但し書きがあるが,Web上の手軽なコンコーダンサーとして利用価値はありそうだ.
時々刻々と変化するウェブ・リソースを検索対象とするので一種の monitor corpus とも考えられ,時事を反映した出力が期待できる.例えば,2010年4月24日現在,ニュースサイト限定検索 "volcano" とやれば Iceland や Icelandic と共起するコンコーダンス・ラインが大量に得られる.( see [2010-04-20-1]. )
姉妹版で日本語版の JReK もあり,こちらは日本語の文章書きに効果を発揮しそう.
2010-04-23 Fri
■ #361. 英語語源情報ぬきだしCGI(一括版) [etymology][dictionary][link][cgi][web_service]
[2010-04-03-1]の語源情報抜きだしCGIの改良版.情報源は同じ Online Etymology Dictionary.今回の「一括版」は複数の語の語源を一覧したいときに便利.1行1語で入力された単語リストを用意し,それを以下のテキストエリアに入れて Go するだけ.1語だけでも使えるので,事実上,前回の版の上位互換.語数が多いと時間がかかるし,サーバに負担がかかるので注意.
こうしてますます面倒くさがりになってゆく.
2010-04-03 Sat
■ #341. 英語語源情報ぬきだしCGI [etymology][dictionary][link][cgi][web_service]
電子辞書はもちろんのこと,今ではWeb上で利用できる英語辞書も数え切れないほど出ており,紙の辞書を引く時代に育ったものとしては驚きの世の中になった.あまたあるWeb辞書のなかでも,個人的に使う機会の多い英英辞書が Dictionary.com である.複数の辞書を横断しての「串刺し検索」が可能である.また,簡便な語源情報が "Word Origin & History" という項で得られるので,これだけのために参照することもある.語源と例文が特に有用なので,私は毎日ランダムに単語情報を自動配信してくれるサービス "Word of the Day" にも登録している.
もっとも,語源情報だけを参照したいのであれば,"Word Origin & History" の提供元である Online Etymology Dictionary を直接検索するのがはやい.(c) 2001-2010 Douglas Harper による英語語源のサイトで,簡単便利.これだけでも十分に簡単便利なのだが「辞書の雑多な情報はいらない,とりあえず語源情報だけを今すぐ欲しい,早く早く!」という(私だけの?)喫緊のニーズに対応し,一発スクリプトを作って使っている.特に初出年やどの言語から来ているかを即座に知りたいときに重宝している.
そのスクリプトのCGI版を以下に作ってみた.単に Online Etymology Dictionary の検索結果から語源記述の部分をぬきだすだけのもの.電子検索が可能になると,どんどん面倒くさがりになってゆく・・・.
2009-07-15 Wed
■ #78. Verbix とコーパス [software][web_service][conjugation][inflection][oe][me][corpus][variation]
昨日の記事[2009-07-14-1]で,Verbix の古英語版の機能を紹介し,評価して終わったが,実は述べたかったことは別のことである.
動詞の不定詞形を入れると活用表が自動生成されるという発想は,標準語として形態論の規則が確立している現代語を念頭においた発想である.これは古英語や中英語などには,あまりなじまない発想である.確かに古英語にも Late West-Saxon という「標準語」が存在し,古英語の文法書では,通常この方言にもとづいた動詞の活用表が整理されている.だが,Late West-Saxon の「標準語」内ですら variation はありうるし,方言や時代が変われば活用の仕方も変わる.中英語にいたっては,古英語的な意味においてすら「標準語」が存在しないわけであり,Verbix の中英語版というのは果たしてどこの方言を標準とみなして活用表を生成しているのだろうか.
Verbix 的な発想からすると,方言や variation といった現象は,厄介な問題だろう.このような問題に対処するには,Verbix 的な発想ではなくコーパス検索的な発想が必要である.タグ付きコーパスというデータベースに対して,例えば「bēon の直説法一人称単数現在形を提示せよ」とクエリーを発行すると,コーパス中の無数の例文から該当する形態を探しだし,すべて提示してくれる.その検索結果は,おそらく Verbix 型のきれいに整理された表ではなく,変異形 ( variant ) の羅列になるだろう.古英語の初学者にはまったく役に立たないリストだろうが,研究者には貴重な材料だ.
英語史研究,ひいては言語研究における現在の潮流は,標準形を前提とする Verbix 的な発想ではなく,variation を許容するコーパス検索的な発想である.同じプログラミングをするなら,Verbix のようなプログラムよりも,コーパスを検索するプログラムを作るほうがタイムリーかもしれない.
とはいえ,Verbix それ自体は,学習・教育・研究の観点から,なかなかおもしろいツールだと思う.だが,個人的な研究上の都合でいうと,古英語や中英語の名詞の屈折表の自動生成ツールがあればいいのにな,と思う.誰か作ってくれないだろうか・・・.自分で作るしかないのだろうな・・・.
2009-07-14 Tue
■ #77. 動詞の活用表を生成してくれる「Verbix」 [software][web_service][conjugation][inflection][oe]
Verbix: conjugate Old-English verbsでは,古英語の動詞(不定詞)をキーワードとして入れると,活用表が自動的に生成されるというウェブサービスを無償で提供している.
古英語のみならず,現代英語を含め,世界の諸言語に対応しており,各言語の学習者,教育者,研究者にとって有益である.このサイトでは,ダウンロード可能な単体で動く同機能のアプリケーションもシェアウェアとして提供しており,一ヶ月までなら試用もできる.アプリケーション版では,機能拡張を施せば,中英語にも対応するようになるというから興味深い.
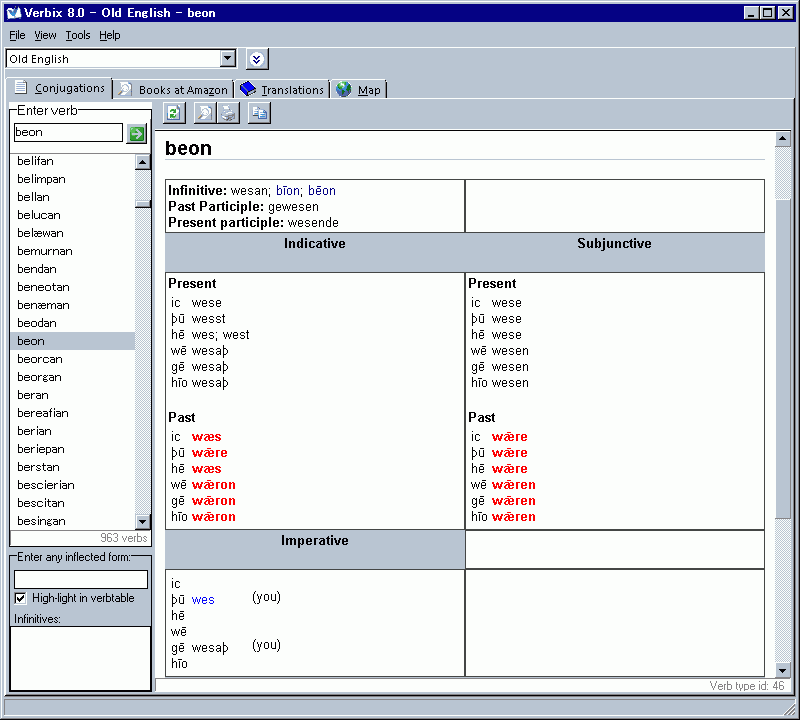
上のスクリーンショットは,アプリケーション版で古英語の bēon "to be" の活用表を生成させた場面だが,みごとに wesan ( bēon に代わる別の動詞)の活用表に置き換えられてしまっている.現代英語でもそうだが bēon は著しく不規則な活用を示すわけで,こんな動詞をキーワードに入れてくれるなという Verbix からのメッセージとも受け取れる.
そもそもアプリケーションのプログラム内では,どのように活用表が生成されているのだろうか.最初は,おそらく各動詞の活用形がそのままデータベースに納められており,プログラム側がそれを呼び出すだけなのではないかと思っていた.だが,bēon の例を見ると,そのようなきめ細かなデータ格納法はとられていないように思える.
考えられるもう一つの方法は,最少限の基底形(古英語であれば「不定形 -- 第一過去形 -- 第二過去形 -- 過去分詞形」の4形態[2009-06-09-1])と所属クラスだけがデータベースに登録されており,あとは形態音韻規則によってプログラムに各活用形を生成させるという方法だ.こうすると,データ部の容量は節約できる.
人間の脳では,上の二つの仕組みが連携して作用していると考えられる.大半の動詞についてはルールに基づいて活用形が生成されるが,bēon のような不規則活用をする動詞の場合には,ルールでは導かれないので,活用形がそのままデータとして格納されているというわけである.Verbix でも二つの方法が組み合わさって活用表の生成機能が実現されているのかもしれないが,bēon まではサポートが及ばなかったというだけのことかもしれない.
上記のような問題はあるが,古英語動詞の活用の練習には使えそうだ.かつて学んだ動詞活用を Verbix で復習してみよう.
・Verbix の古英語版
・Verbix の現代英語版
・Verbix の対応言語一覧
Powered by WinChalow1.0rc4 based on chalow