昨日の記事[2012-10-10-1]に引き続き,The LAEME Corpus の代表性の話題.今回は,語数,より正確には同コーパスで文法情報が付与されている語 (tagged words) の数により,方言・時代ごとの代表性を考える.まず,表を掲げよう.
Table 2: Dialectal and Diachronic Distribution of Linguistic Evidence by Number of Tagged Words
| C12b | C13a | C13b | C14a | Total | |
|---|---|---|---|---|---|
| N | 0 (0.000%) | 362 (0.062) | 0 (0.000) | 52,883 (9.083) | 53,245 (9.146) |
| NEM | 11,342 (1.948) | 0 (0.000) | 3,980 (0.684) | 2,344 (0.403) | 17,666 (3.034) |
| NWM | 0 (0.000) | 58,332 (10.019) | 16,173 (2.778) | 0 (0.000) | 74,505 (12.797) |
| SEM | 40,082 (6.885) | 26,722 (4.590) | 21,921 (3.765) | 31,408 (5.395) | 120,133 (20.634) |
| SWM | 1,030 (0.177) | 90,400 (15.527) | 106,981 (18.375) | 108 (0.019) | 198,519 (34.098) |
| SW | 1,168 (0.201) | 2,610 (0.448) | 46,032 (7.907) | 30,517 (5.242) | 80,327 (13.797) |
| SE | 0 (0.000) | 4,043 (0.694) | 3,199 (0.549) | 30,561 (5.249) | 37,803 (6.493) |
| Total | 53,622 (9.210) | 182,469 (31.341) | 198,286 (34.058) | 147,821 (25.390) | 582,198 (100.000) |
直感的に理解できるように,この分布をモザイクプロットで表現したのが下図である(印刷用にはこちらのPDFをどうぞ).
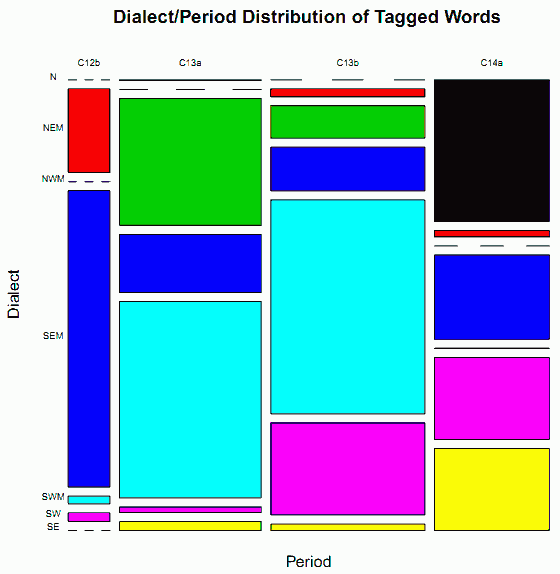
分布の偏りは一目瞭然である.しかし,方言・時代の各スロットを構成するテキストの種類などをより細かく調べると,さらに重要な問題が見えてくる.いくつかのスロットでは,総語数の大部分がほんの一握りのテキストによって占められているのである.例えば,N C14a というスロットは,全体のなかで4番目に収録語数の多いスロットだが,その語数の95.61%は Cursor Mundi という1作品(正確には,それを表わす3種類の異なる書写言語を反映した 3 scribal texts [##296, 297, 298])で占められている.同様に,NEM C13b では #182 のみで80.93%の語数がカバーされている.NWM C13b では #272 のみで93.11%だ.SEM C12b では異なる2人の写字生の手による Trinity Homilies (##1200, 1300) が総語数の84.06%を占め,SEM C13a でも異なる2人の写字生の手による Vices and Virtues (##64, 65) が総語数の93.83%を占める.SW C13b の #1600 は,それだけで69.71%を占める,等々.
これらの例が示唆することは,問題の方言・時代スロットは必ずしもその方言・時代の言語変種を代表しているわけではなく,むしろ特定のテキストに現われる言語変種を代表しているということかもしれなということだ.The LAEME Corpus の使用の際には,なお一層の注意が必要である.
Referrer (Inside):
[2020-05-30-1] [2016-06-07-1] [2012-10-27-1] [2012-10-12-1]