第6回授業内容
コンピュータの集中処理
コンピュータを協調して働かせる
家庭と企業や大学でのコンピュータの使い方を考えた場合、大きく異なる点は単独で動かすか、協調させて動かすかの違いである。
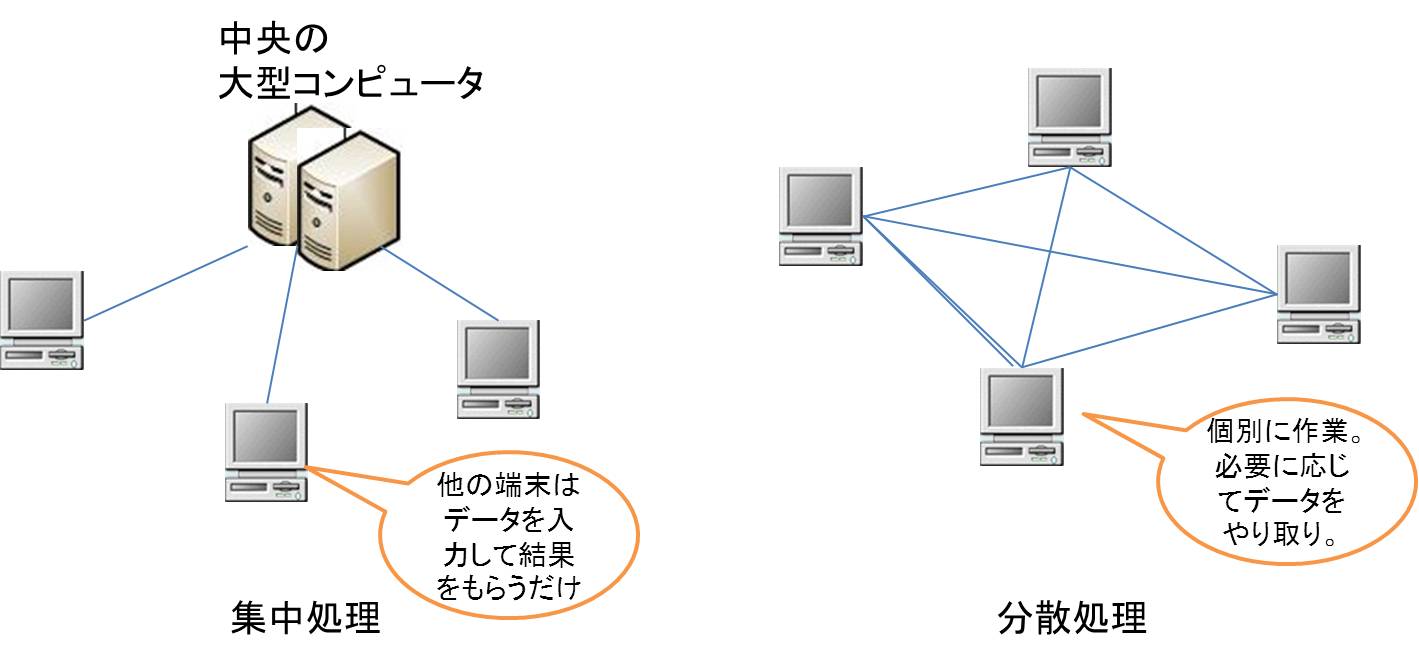
家庭のコンピュータはかなりの割合でスタンドアローン(単独)で動いている。企業や大学でもそのように扱っても構わないのだが、たくさんのコンピュータで効率的に活用するためには協調させた方が都合がよい。中央に構えた大型コンピュータ(スーパーコンピュータやメインフレーム)にすべての仕事をやらせ、他の端末は結果を受け取るだけなのが集中処理、個別に分担して仕事をするのが分散処理である。
たとえば、銀行のATMは集中処理で働いている。個別のATMそれぞれで勝手に計算をしていると残高合わせが大変だが、中央のコンピュータが一括管理していればその心配はない。
最近は個々のコンピュータの性能が上がってきたので分散処理が効率よさそうに見えるが、個別分業でやっていた仕事を1つにまとめたり、頻繁に情報の共有が必要な場合、管理負担が大きい。
クライアント・サーバ・システム
コンピュータ1台1台の性能が高くなり、個別に作業を行ってもよさそうだし、分散処理なら、自分好みのシステムに独自で変更しても周囲の迷惑にはならない。確かにそれも一理あるが、企業や大学のPCはまとめて一括管理できたほうが効率がよい。いちいち新規のソフトをインストールする際に50台や100台以上のPCを個別にカスタマイズしていては負担が大きいのである。
そこで集中処理と分散処理の利点を折衷したシステムがクライアント・サーバ・システムである。サーバとは、比較的処理能力が高く、難しい仕事をこなす役割を与えられたコンピュータで、データベースやメールなど、1か所でやらなければ収拾が付かなくなる仕事も担当する。クライアントはユーザが手元で使うコンピュータで、個人的な仕事はそれ自体でこなしてしまう。高い処理能力が要求される仕事や、他のユーザと連携して行う仕事はサーバと協調して仕事をする。
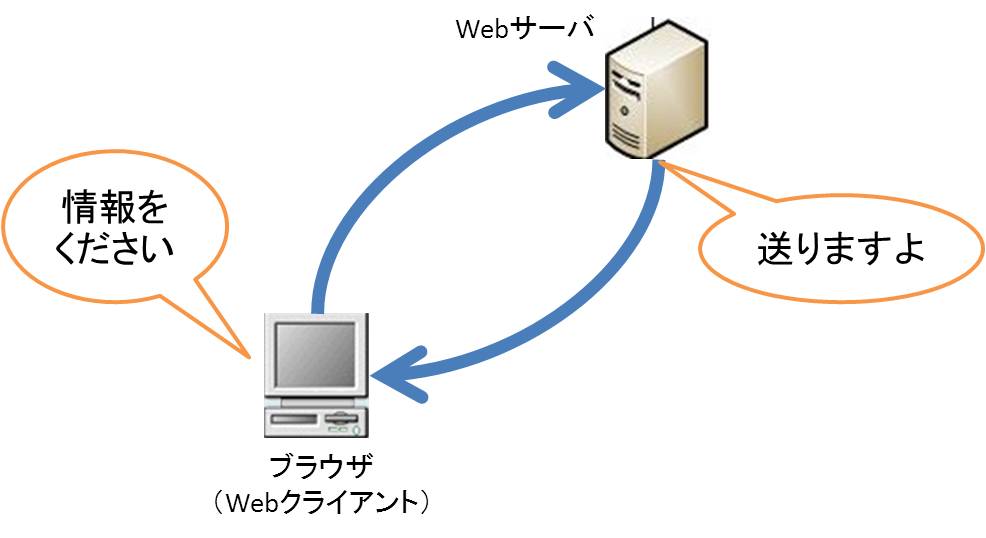
サーバにはメールサービスを提供してくれるメールサーバや、ホームページを見せてくれるWebサーバなどがある。この場合、私たちが手元で利用しているコンピュータは「メールを送ってほしい☆」「ホームページを見せて欲しい」など依頼をしているクライアントである。
サーバやクライアントという言葉は、単に役割を指す言葉であり、普通のPCをサーバにすることもできる。しかし、一般的には処理能力が高く、故障対策などを施したものを用いる。サーバが別のサーバに対してクライアントになったり、複数のサーバ機能を一台で兼ねたりすることもある。
シン・クライアント
サーバに依存する比重の高いクライアント・サーバ・システム。クライアントは表示や入力のみを担当する。クライアントの自由度や処理能力が減るが、処理や情報をサーバ側で一括管理できるため、セキュリティを高めることができる。
たとえば、ノートパソコンをどこかに置き忘れても、シン・クライアント型であれば情報はクライアントに保存されていないので、漏えいなどのリスクは小さくできる。企業でもモバイル機器を業務に利用することが多くなったので注目を集めているシステムである。
クラウドコンピューティング
2000年代後半からクラウドコンピューティングと呼ばれるコンピュータ資源を効率的に活用する新しいしくみが登場した。これは、従来個人または組織が自分たちで用意していたハードウェアやソフトウェアを廃して、代わりにインターネット経由でデータセンターにアクセスして必要なサービスを利用する仕組みである。ユーザーはサービスが提供されているサーバーの実体を意識することなく利用できるため、サーバーは雲 (could)の中にあるというイメージでこのように呼ばれている。
クラウドコンピューティングの形態で提供されるサービスをクラウドサービスと呼ぶ。クラウドサービスは、大きくSaaS、PaaS、IaaS/HaaS に分類されるが、エンドユーザーが利用できるサービスはSaaS に属する。SaaS (Software as a Service) は、メールやスケジュール管理などアプリケーションの機能をサービスとして提供し、ユーザーはWeb ブラウザを介してそれらを利用する。Gmail などのメールサービスやGoogleDrive、Dropbox、Evernote などのオンラインストレージが代表的である。メールや予定、ファイルがWeb上に置かれるため、スマートフォンとパソコンなど複数の情報通信機器で常に最新のファイルを閲覧・編集することができる。また、他のユーザーと共有したり、共同編集したりすることもできる。
PaaS (Platform as a Service) はアプリケーションを実行するためのプラットフォーム(OSの機能)をサービスとして提供する。IaaS / HaaS (Infrastructure as a Service / Hardware as a Service)の略称。
ネットワークの基礎 (4) トランスポート層
トランスポート層
ネットワーク層までに世界中へ通信を届けるルールが完成した。しかし、通信が確実に届いた保証はない。また、IPはPCとPCの通信を実現するが、通常は通信はソフトとソフトの間で行う。WindowsやMacOSでは複数のソフトを同時に立ち上げ作業を行う(マルチタスク)。同時に動くソフトのどれと通信すればいいのかを決める必要がある。これを解決するのがトランスポート層になる。その代表的プロトコルはTCPである。
TCP(Transmission Control Protcol)は通信が確実に届けられたことを確認する機能を持っている。また、ポート番号と呼ばれる情報を持っており、PCの中のどのソフトの通信であるのかを特定することができる。ポート番号は16ケタの2進数で表される。つまり216 = 65536 の識別が可能であり、IPアドレスに比べれば少ないが1台のPCで動かすソフトの数だけあればいいので十分といえる。

TCP/IP
TCPとIPは別のプロトコルだがセットで使われることが多いのでまとめて表記することがある。
ウェルノウンポート
ポート番号は基本的にソフトが起動するたびにOSが自動で割り当てるが、0から1023番までは、よく使うソフト用ということで定められている。これをウェルノウンポートと呼ぶ。代表的なものに、25:メール送信(SMTP)、110:メール受信(POP3)、80:Web通信(HTTP)などがある。ウェルノウンポート以外に1024番から65535番までポート番号が用意されており、登録された特定のプログラムのために使われるポート、ユーザーが自由に使用できるポートに分かれる。
セキュリティホールとファイアウォール
PCで動作しているプログラムは作成されたポートへ通信データが送られてくるのを待ち受けるが、プログラムに不備があるとある特別なデータを受信した時に誤動作してしまう。悪意を持って作られたこの類のデータにより、本来送信してはいけない情報(パスワードなど)を勝手に送信してしまう誤動作を引き起こすことができる。このような誤動作の元となるプログラムをセキュリティホールという。、
ソフトウェアは人間が作るものであるからセキュリティホールを完全になくすことは困難であり、また時にはセキュリティホール自体がユーザーにとって便利に利用がきる場合もある。
そのため、自分が所属するネットワークと外部のネットワーク(インターネット網)との間の通信に介入し、不正な通信の一部を遮断する機能があり、これをファイアーウォールと呼んでいる。また、クライアントのコンピュータに導入しインターネット外部からの不正な侵入を防いだり、ウイルスの侵入を防御したり、自分のコンピュータを外部から見えなくしたりする機能を、パーソナルファイアウォールと読んでいる。
ネットワークの基礎 (5)
アプリケーション層 (Web)
アプリケーション層は下位層がネットワーク接続されたことによって、つながった通信を使って何をするかを決めるプロトコルである。
Web
いわゆるホームページ。もともとはマニュアルや論文など、参考文献が多く、他の文献を読む必要がある場合に効率的に読めるように考えられた仕組みである。他の文書に一瞬で飛べるハイパーリンクと呼ばれる技術を使って、Webページでは、関連する情報が記載されたページにジャンプすることができる。
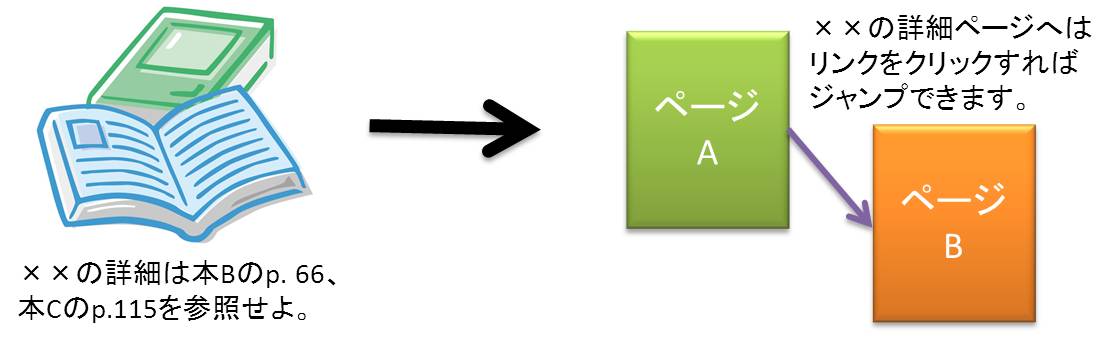
Webの仕組みはクライアントサーバによって構築されている。情報を提供するWebサーバに、Webクライアントソフト(ブラウザ)が情報をくれるように要求し、送ってもらう形式である。
Web小史
1989年、フランスとスイスにまたがる世界最大の素粒子物理学の研究所CERNに勤めていたTim Berners-Lee が世界中の物理学者たちの研究を互いにリンクして簡単に閲覧できる仕組みを考案した。これがWorld Wide Web(WWW) 、のちにWeb と呼ばれるようになった。1991年、CERNで最初のWeb サイトが立ち上がった。Webのアイデアは簡単で、 Web はCERNで発明された。 と書く代わりに、
Web は<a href = http://cern.ch/> CERN </a> で発明された。と書けば、
WebはCERNで発明された。
と表示され CERN の部分をクリックすると指定されたページに飛ぶというものである。このような仕組みをハイパーリンクまたは単にリンクと呼ぶ。
リンクを使えば、科学の論文が他の論文を参照するのと同じように、世界中に分散したページが互いに他のページを参照することにより、世界中の知識を結び付けた巨大な知識の輪を作ることができる。
リンクのあるテキストをハイパーテキストと呼び、<a href =” “> </a> のようなタグを使ってハイパーテキストを作る仕組みをHTML (Hypertext Markup Language) と呼ぶ。
HTML は次第に仕様が膨らんでいき、整理が必要になっていった。そこで、HTMLから文書の見栄えにかかわる部分がCSS (Cascading Style Sheet) という別の仕組みにされた。そのバージョンCSS1が出たのが1996年である。現在はCSS 3 が広く使われている。
一方、HTMLは1999年にHTML4.01が出た後、XMLという別の規格と合わせてXHTMLという新しいものに移行するはずだったが、その後に出たHTML 5という優れた規格が流れを変え、現在ではXML化 は後回しにして、HTML 5 への移行が急速に進んでいる。
HTML や CSSを☆補完する技術としてJavaScript というプログラミング言語が1995年から使われるようになった。JavaScript を使えば、サーバと通信しながら、自分を書き換えるページも作れる。この技術は Ajax (エイジャックス)と呼ばれ、Google マップなどで使われている。
もともとWeb には、ブラウザからサーバに情報を送るための仕組みが備わっていたので、電子掲示板のような書き込めるWebページが次第に増えてきた。「2ちゃんねる」などの巨大掲示板はその例である。
またblog が広く使われるようになった。ブログは Web log つまり Web日誌のことだが、技術的にはCMS (Content Management System) という仕組みを使うことで、HTML や CSS を知らなくても簡単に情報発信ができるようになった。しかし、自由なページ作りをするためには、現在でもHTML の知識は欠かせない。
また、誰でも書き換えられるWiki という仕組みも出現した。Wiki の語源は「速い」「速く」を意味するハワイ語のwikiwiki である。いろいろなWiki が作られてきたが、有名なのは百科事典の Wikipedia である。誰でも好きな項目を追加でき、誰でも書き換えることができる。そんなことをすれば無茶苦茶になりそうである。確かにデタラメを書き込む人もいるが、それを直す人のほうがもっとたくさんいる―「悪人より善人のほうが多い」というのがWiki の哲学である。無数のボランティアのおかげで、今やWikipedia は大百科事典なみの内容で、しかも日本語版を含む多くの版が作られてきた。Wikiに自分の詳しいことを書き込むことは望ましいことではあるが、著作権、肖像権など他人の権利の侵害や、根拠の不確かなことの書き込みはしないように留意することが必要である。
従来からの情報発信型のWeb に対して、このような参加型の Web をWeb2.0 と呼ぶことがある。これはインターネット技術の進化というよりは、むしろ社会現象である。
知識を広く収集・公開することを目的としたものとは逆に、会員制で、読者を制限して文章や写真を公開する mixi や Facebook など、一般にSNS (Social Networking Service) と呼ばれるサービスが現れた。また、SNSと似ているが、140文字以内の短文 (「つぶやき」)を書き込むTwitter は、一つ一つの書き込みが独立したアドレス(URL)を持って、Twitter にユーザ登録しなくてもだれにでも閲覧できるので、マイクロブログ、ミニブログと呼ばれることがある。TwitterやFacebookはスマートフォンのアプリから使われることも増え、仕組みがWeb であるかどうかは次第に意識されなくなってきている。
URL (Uniform Resource Locator)
WEB上のページにアクセスするための識別子。一般にURLアドレスと言われる。
http://user.keio.ac.jp/~fjmk/index.html
このURLは以下のように分解することができる。
Hypertext Transfer Protcol (http:// )
Webサーバとクライアント(Webブラウザなど)がデータを送受信するのに使われるプロトコル。HTML文書や、文書に関連付けられている画像、音声、動画などのファイルを、表現形式などの情報を含めてやり取りできる。
ドメイン名 (user.keio.ac.jp/)
電子メール☆を送る時や、ウェブサイトを見たりする時に、相手(参照先)がインターネット上のどこにいるのかを特定するために、ドメイン名が利用される。いわば「インターネット上の住所」。インターネット上のコンピュータ同士が通信する際には、IPアドレスによって通信相手を特定しているが、数字の羅列を人間が識別するのは困難なので、人間が覚えやすいように「○○.jp」といった文字列からなるドメイン名が利用される。ドメイン名はDNS(domain name system)サーバーを経由することで、IPアドレスへと変換される。
ディレクトリ名 (~fjmk/)
ディレクトリはフォルダとほぼ同じ意味。
ファイル名 (index.html)
HTTPとHTML
Webページを記述するルールがHTML(HyperText Markup Language)、HTMLを送受信するためのルールがHTTP(HyperText Transfer Protcol)という。HTMLはマークアップ言語と呼ばれるが、これは「本文」と「本文に対する説明(タグ)」で構成され、文章の構造や、文章に対する修飾などがタグに書かれる言語である。HTMLは人間が読む部分と、ブラウザに対する指示の部分に分かれている。ブラウザに対する指示は< >で括られていて、タグと呼ばれる。
たとえば、
<赤くするタグ> ここ重要です </赤くするタグ>
こういうHTML文書がブラウザに送られてくると、ブラウザはそのまま表示するのではなく、タグの中身の指示にしたがって、「ここ重要です」と赤く表示する。< >の中は専門の文法があるので覚える必要がある。主なタグに<TITLE>(タイトルを表わす)、<BODY>(本文を表わす)、<IMG>(画像を表示させる)などがある。
CSS
HTMLは、そもそもは電子マニュアルのようなものを作るための技術だった。HTMLのタグはタイトル、見出しなど、文書の構造を示すものだった。しかし、いわゆるホームページとしての普及が進むと、急速にページの見栄えに関するタグが増えてきた。デザイン性の優れたWebページが作れるようになったが、単に文字を大きくするために「見出し」のタグを使うなど、文書構造が守られないページも増えた。
そこで、文書構造とデザインを分離し、文書構造タグはHTMLに、デザインタグはCSS (Cascadin Style Seets)に書くように分離した。それにより、PC用Webページとして作られた文書をCSSだけ変更してスマホ用Webページにしたり、見出しだけ抜き出したりする作業が容易になった。
XML
タグの要素を自分で決めることができるマークアップ言語。HTMLのタグが固定でWebページの制作に特化しているのと比べ柔軟な用途に使用できる。異なるシステム間でデータの共有をするために便利で、人間が読んでも意味がわかる。もともとHTMLもXMLもおおもとはSGMLというマークアップ言語である。これが使いにくいので簡素化したものがXMLで、とりわけWebに特化したものがHTMLである。したがって、XMLとHTMLは共通性が高い
Cookie
httpは新しいWebページを読み込むと、前のページの情報を破棄する。たとえば、通販サイトなどでページを行き来しても買い物情報を忘れないようにしたり、利用者を識別したりする目的で使われるのがCookieである。一度認証を行い、サーバにログインしたら一定期間その情報を維持し認証を不要とするシングルサインオンの技術にCookieが使用されることもある。具体的には、サーバが送信した情報をクライアント内にテキスト形式で保存したものである。
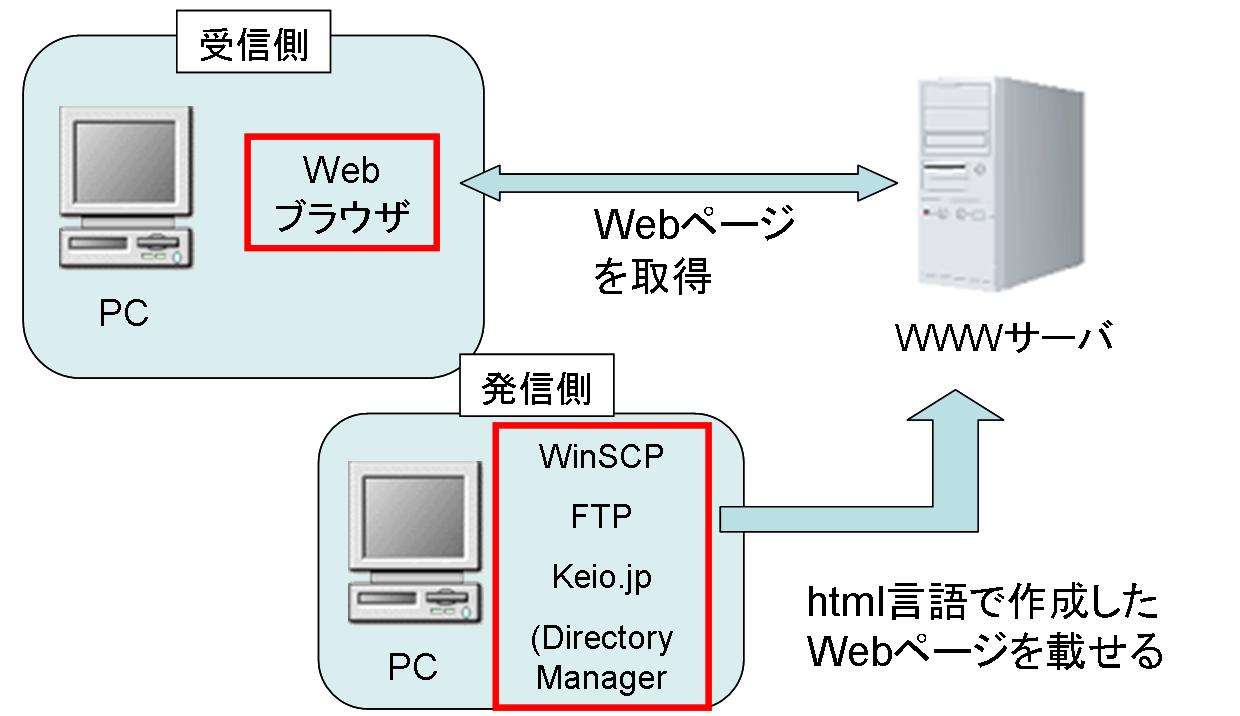
ソースコード(ホームページはどのようにして記述されているのか)
ホームページはHTML言語によって作成されている。ソースとは実際にそのページを作るために書かれた言語である。つまり、ブラウザ画面で私たちが目にしているページは、ソースコードやコード上で関連づけられた画像ファイルを、wwwサーバから取得し、映し出している。ブラウザはソースを翻訳しホームページを表示するためのアプリケーションとみなすことができる。ソースを表示するためにはブラウザ上で「右クリック → ソースの表示」。 ソースの表示は、HTML言語によって作成されたソースプログラムをメモ帳で表示する。
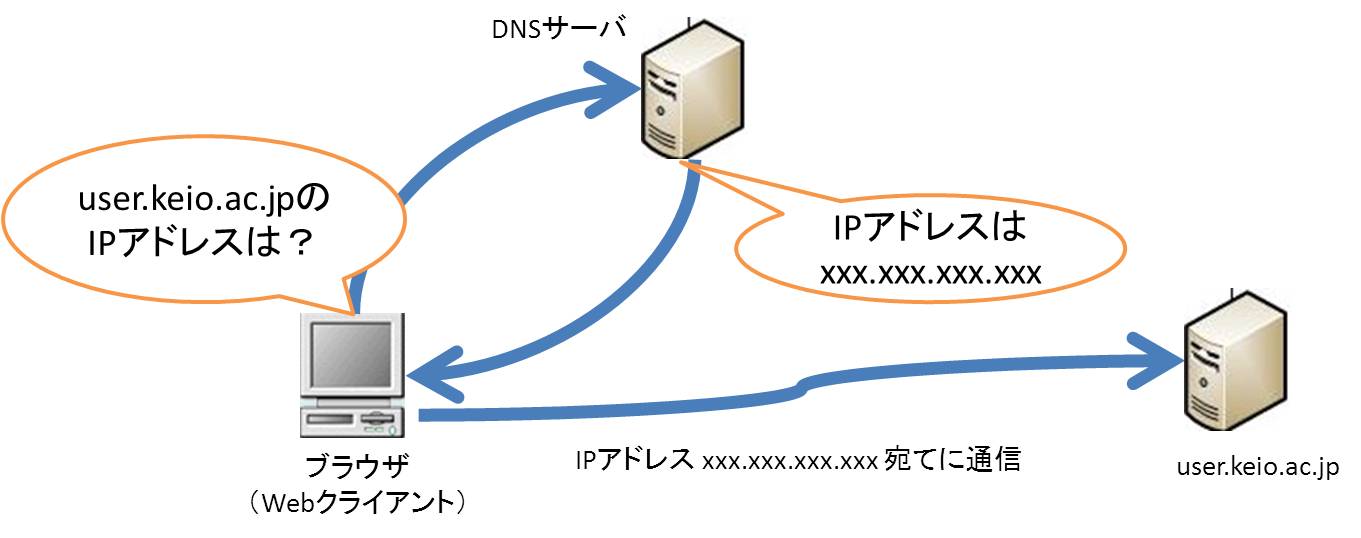
DNS
インターネット上でのアドレスを示すのにIPアドレスが使われる。IPアドレスは数字の羅列で、人間には覚えにくいものである。そこで、人間向けに数字よりも覚えやすいドメイン名というアドレス表記が作られた。たとえば、ドメイン名を使って、この慶應義塾大学のサーバのアドレスを表わすと、次のようになる。
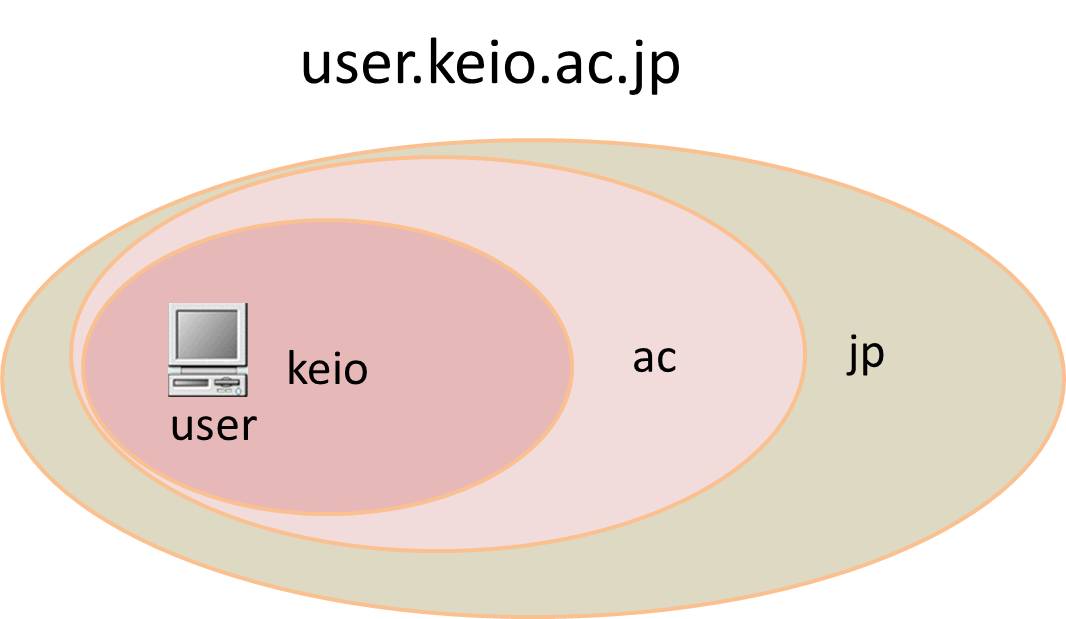
ドメイン名は右端から範囲が絞りこまれていく。jp=日本のac=大学のkeio=慶應義塾大学のuserという名のついたコンピュータがあると読んでいく。したがって、最も広い領域にあたるトップレベルドメインはjp(日本)、uk(英国)、cn(中国)など国を表わすものが多い。セカンドレベルドメインにはac(大学)、co(会社)、go(政府)など、組織形態を表わすものが多い。
メールアドレスの@以下や、HTML文書がある場所を表わすURLはドメイン名を使っている。
(httpは使うプロトコルの種類、user.keio.ac.jpは目的のhtml文書があるコンピュータのドメイン名、~8gはそのコンピュータのどこに保存されているかを示すパス名)
ただ、IPのルールによれば、インターネットで使えるアドレスはIPアドレスだけなので、ドメイン名というのは人間には使いやすくても、コンピュータには理解できない。そこで、通信に先立ってドメイン名をIPアドレスに直す(これを名前解決という)。そのためのサーバをDNS(Domain Name System)サーバという。DNSサーバはuser.keio.ac.jpをIPアドレスに直すようにクライアントから問い合わせを受けると、IPアドレスを返す。
FTP、DHCP
FTPはファイル転送プロトコル (File Transfer Protcol) のことで、ネットワーク上でファイルの送受信を行う目的で使われる。ファイルのダウンロード、アップロードではFTPを利用している。
IPアドレスやネットワークの接続情報を自動的に配布する仕組みをDHCP(Dynamic Host Configuration Protcol)と呼ぶ。IPアドレスの設定は初心者には難しく、管理者にとっても大量のコンピュータに設定を施すのは負担が大きい。これを解決するために考えられたのがDHCPで、DHCPサーバがIPアドレスを管理してDHCPクライアント(普通のパソコン端末など)からの要求に応じて、配布を行う。電源を落としたり、長く応答のないコンピュータからはIPアドレスを回収することもでき、効率的なアドレスの運用ができる。
インターネット技術の応用
イントラネットとエクストラネット
インターネットで標準的に使われている技術を使って、会社や組織などの内部ネットワークを構築することをイントラネットと呼ぶ。インターネットは本来、ネットワーク間接続の技術だが、非常に普及しているため、対応製品を安価に購入できる。これを使い内部ネットワークを作る発想である。内部ネットワーク向けの技術とインターネット接続の技術を使い分ける必要がなく、メールのクライアントソフトなども統一することができるため、運用にかかる諸費用や手間も軽減できる。また、関連会社や異なる会社間で、イントラネット同士を互いにつないだ形態をエクストラネットと呼ぶ。
VoIP
VoIP(Voice over Internet Protcol)とは、音声をカプセル化してIPパケットに格納し、インターネットなどのIPネットワークを使って伝送する技術である。インターネットと電話網を統一できるため、コスト減や運用の簡略化が期待でき、内線電話やインターネット電話などで使われる。しかし、IPネットワークは電話網に比べると信頼性や遅延、通話品質の点で劣る。そのため、まだ完全に電話網を置き換えるには至っていない。
ブラウザ
基本用語の解説
- ブラウザ
ホームページ閲覧用ソフトのこと。代表的なものにマイクロソフト社の「インターネットエクスプローラ(IE)」やMozillaプロジェクトによる「Firefox」、Apple社の「Safari」、Google社の「Chrome」などがある。その他にも、「Netscape」、「Sleipnir」、「Opera」などがある。また、特定のページ閲覧に特化したブラウザ(たとえば mixi用ブラウザ・2ch用ブラウザ)もある。またUSBに入れて持ち運べるPortable版ブラウザも作られている。
- ウェブページ・ウェブブラウザ
ホームページのことをウェブページ、ブラウザのことをウェブブラウザなどと呼ぶこともある。ウェブ(Web)とは、WWW(World Wide Web)の最後の部分を指している。WWWとはインターネットが提供するサービスのひとつで、ホームページを表示するための技術や仕組みをさす。「世界中に張り巡らされたクモの巣」という意味で、世界中にある多くのコンピュータがクモの巣のようにリンクでつながってホームページに記載された情報を共有するようすを表現している。
ホームページ内の文書のコピー
ホームページ内に記述されている文書はコピーして、メモ帳などのソフトに貼り付けることができる。ただし、ホームページ内に記述されている文書には著作権が存在するので、利用には注意が必要である。
方法は、コピーしたい文書の先頭でクリックして、末尾までドラッグしてドロップする。青く反転している選択部分にマウスのカーソルを合わせ、右クリックしてコピーを選択する。あとはそのままメモ帳などで右クリックして貼り付けを選択する。☆
ブラウザの機能
タブ
一般的にはテキストラベルを表示する形で画面上部に表示され、クリックすることでページを切り替えて表示できる。タブを利用すれば1つのウィンドウ内で複数のウェブページを表示することができる。
リンク
マウスのポインタの形が矢印からフィンガーカーソルに変わる場所は、他のホームページへのリンクが貼られている。リンクは文字列に貼ることもできるし、画像に貼ることもできる。多くの場合、文字色が青く、下線がある文字列にリンクが貼られていることが多い。しかし、そうでない場合もあるのでマウスのポインタで確認すること。
また、リンク先を新しいウィンドウで開きたい場合は、リンクされている箇所で右クリック→「新しいウィンドウで開く」。もしくは「Shift」キーを押しながらクリック。新しいタブで開くには「右クリック」→「新しいタブで開く」。もしくは「Ctrl」キーを押しながらクリック
スタートページの設定
起動したとき最初に表示されるページを「ホームページ」と呼ぶ。もともとは初期設定状態になっているが、よく見るWebサイトをホームページに設定することができる。Internet Explorerの場合は「ツール」→「インターネットオプション」→「全般」タブ→「ホームページ」欄を変更する。あらかじめホームペ^ジに設定したいページを表示させてからこの作業を進めた場合は「現在のページを使用」を選択すればよい。
ファイルのダウンロード
ホームページ上のリンクには、他のホームページのリンクだけではなく、ファイルのダウンロードを行う機能もある。安全であることがわかっているファイルであればダウンロードしてもよいが、よく知らないファイルはダウンロードしないこと。ウィルスソフトや国際電話に自動的に接続するソフトなど悪質なファイルもある。特に拡張子(ファイルの末尾についている文字)が「exe」のものは注意する。
閲覧情報を削除する
Webブラウザには、Cookie、閲覧履歴、フォームに入力したデータ(パスワードやアドレス)など、様々な情報が蓄積されている。パソコンを共有で使って☆いてこれらの情報を知られたくない場合は削除をする。
Internet Explorerの場合、「ツール」→「インターネットオプション」→「全般」タブ→「閲覧の履歴」欄の「削除」をクリックする。閲覧したWebサイト一覧だけは、同じく「閲覧の履歴」欄にある「終了時に閲覧履歴を削除する」にチェックを付ければ、ブラウザを終了するだけで自動的に削除することができる。
ブラウザの基本操作
- 複数のタブを開きたい場合
タブの最右端をクリック、または Altメニューバー「ファイル」→「新しいタブ」。キーボードショートカットは「Ctrl + T」。
- 複数のウィンドウを開きたい場合
Altメニューバー「ファイル」→「新規ウィンドウ」。キーボードショートカットは「Ctrl + N」。
- タブ間の移動
キーボードショートカットは「Ctrl + Tab」。
ちなみに起動中のプログラムやフォルダを切り替える際には「Alt + Tab」である。
- ホームページ内の任意の文字列の検索
Altメニューバー「編集」→「このページの検索」。キーボードショートカットは「Ctrl + F」。
- サイトの拡大・縮小
Ctrl + マウススクロール。キーボードショートカットは「Ctrl + +」で拡大、「Ctrl + -」で縮小、「Ctrl + 0(ゼロ)」で等倍に戻す。
- すでに訪れたホームページの表示
Altメニューバー「表示」→「移動」。
- お気に入りの整理
メニューバー「お気に入り」→「お気に入りの整理」で、フォルダを作成してお気に入りのホームページを整理したり、もう見なくなったホームーページを削除したりできる。
非常によく閲覧するホームページは「リンク」フォルダに追加しておくと、リンクバーに表示されようになるため、一回のクリックでそのホームページを表示させることができる。
ツールバーの基本操作
- 「戻る」「進む」
フォルダの操作と同じ。
- 「中止」
読み込もうとしているページの表示に時間がかかる場合、「中止」ボタンを押すことでそのページの表示が中止される。
- 「更新」
ページの内容が変更している場合、「更新」ボタンを押す事でページ内容を刷新できる。
- 「ホーム」
ブラウザを起動させたときに一番最初に表示されるページ。「ツール」→「インターネットオプション」で変更可能。
検索サービス
検索エンジン
検索エンジンとは、インターネット上で目的とするサイトを探し出す検索システムのこと。サーチエンジンなどとも呼ばれる。「Yahoo!」、「Google」、「goo」、「bing」、「livedoor」、「Inforseek」、「excite」、「DuckDuckGo」など。検索方法は大きく分けて ロボット型検索エンジンとディレクトリ型検索エンジンの2種類がある。
なお検索デスクというサイトに、検索エンジンがまとめられている。
「ディレクトリ検索」型
ディレクトリ検索では、「Yahoo!」のYahooカテゴリが有名。人やロボットによって収集したページを、人の手によって内容審査し、カテゴリに分類していく。キーワードを入力すれば、そのカテゴリ内にあるホームページが表示される。また利用者はトップページから、カテゴリをたどりながら目的のサイトを見つけることができる。多くのディレクトリはカテゴリを辿るだけでなく、キーワード検索ができるようになっているがこれで探すのはサイト名、カテゴリ名、説明文までであり、ページ内の個々の内容までは追わない。
ディレクトリ検索の長所はキーワードと検索されたサイトとの相関が強いので、特定業界の企業や団体などの公式サイトを探す際には便利なことである。相関が強いのは人の手で審査・分類をしているからである。そのため、検索者が意図しない検討外れのノイズサイトが混入している可能性が低いということである。また、目的のサイトを含むカテゴリは、関連するサイトの一覧となっているので関連サイトも同時に探すことができ、審査を行っているので総じて掲載サイトの品質は高めである。短所は人手に依存するので、収録されるホームページは少ないこと、既存のカテゴリに当てはめにくいページは見つけにくいこと、専門用語などのディレクトリが想定していない特殊なキーワードではうまく検索できないことである。
「ロボット検索」型
ロボット検索では、「Google」「Bing」などがあり、現在ではこれが主流である。ロボット型検索エンジンでは「ロボット」と言われるプログラムが自動的に世界中のありとあらゆる各サイトを巡回し、WWWのページを読み取ってデータベースを作成していく。そのデータベースを元に入力されたキーワードが検索される。「全文検索」型検索とも呼ばれる。
ロボット型検索エンジンの代表であるGoogleの特徴はページランクというシステムを取り入れていることで、入力したキーワードに対して重要であると推定されるホームページが重要度別に表示される。そのため自分の必要な情報が記載されたホームページが的確に検索される。「Google」の検索で最初に表示されるホームページは自然にアクセス件数も増えるため、多くの商用サイトではどのようにしてページランクを上げるかの傾向と対策を考えている。これはSEO(Search Engine Optimization)対策と呼ばれている。
ロボット検索の長所は検索の対象となるページが多い、専門用語などの特殊なキーワードも検索できることである。短所はホームページの性格に無関係な検索であるため、企業や団体などの公式サイトを探すのには向いていないことである。
検索方法の比較
最近は、Googleロボット検索が検索手段として他を圧倒しているが、個々の情報サイトはデータ内容を目的に合わせたディレクトリ(カテゴリ)で絞って作られている。 たとえば、オンライン書店の「Amazon」は書籍などのカテゴリで絞った上で検索を行うことができる。外食店検索の「食べログ」や旅行サイト「じゃらん」も目的を絞った上で検索が可能である。 ロボット検索はそれらのサイトも自動的に回収し表示リストに加えていくのだが、私たちはそのリストから情報サイトを選び、最終的に求める個別の情報については各サイトのディレクトリ検索を使用していることが多い。
また、大学図書館で論文を検索するためのデータベースサービスがあり、インターネット上からオンラインで利用できる。これはディレクトリ検索であるため、自分の専門の領域に絞り、その中から必要なキーワードを入力して検索することができる。
論文検索にはGoogleの提供する「Google scholar」を利用することもできる。こちらは学術論文で絞れる点でディレクトリ要素が入るが、全体的に縛りは弱くロボット検索の色が濃いので、専門以外の論文も関係が浅い論文も不必要にヒットしてしまう。 このように、ロボット検索全盛ではあるが、ディレクトリ検索の要素がより効率的に必要情報を絞れる場合もあることを見逃すべきではない。
ポータルサイト
「Google」は検索サービスに特化した検索エンジンとして出発したが、それ以外の「Yahoo!」や「goo」といった検索エンジンは検索の機能だけでなく、ニュースや株価、地図、辞書、路線案内などの情報提供サービスや、メールサービス、電子掲示板、チャットなど様々なサービスを兼ねて出発した。このようにあるページへ行けば、様々な目的を満たしてくれるならば自然とそのサイトの利用頻度が上がり、閲覧者が増えるならばサイト運営会社にとっては広告収入の増加を見込める。閲覧者が「ブラウザを立ち上げたらとりあえずあのサイトへ」と思えるページは、インターネットの入り口となる巨大なWebサイトという意味で、「ポータルサイト」とも呼ばれる。
検索エンジンの使い方・コツ
検索エンジンの使い方は非常に簡単である。知りたい情報に関するキーワードを入力して「検索」ボタンを押すと、その言葉が含まれたページが表示がされる。 しかし、抽象的なキーワードをひとつだけ使用すると何万というホームページがヒットする。この中から目的のホームページを探し出すのは難しい。そのため、複数のキーワードを使用して絞り込んで検索を行うほうがよい。その際、キーワードとキーワードの間には半角または全角のスペースを入れる。
検索のコツは、キーワードを上手に選ぶことである。自分の行きたいホームページにどのような用語が記述されているかをよく考えて、入力すること。
Googleの便利な使い方
- 「ウェブ全体から検索」と「日本語のページを検索」の使い分け
特に英語のキーワードを入力する場合に使い分ける必要がある。
- not検索
指定したキーワードを含まないページを検索する。-(マイナス)を語句の先頭につける。例えば、 「オリンピック -冬季」とすると、冬季が含まれたページは表示されない。つまり冬季オリンピックに関連するページは表示されない可能性が高くなる。
- AND検索とOR検索
複数のキーワードを含むページを検索するAND検索は半角または全角のスペースを挟んで複数のキーワードを入力すればよい。複数のキーワードのいずれかを含むページを検索するOR検索はキーワード間に半角で「OR」または半角「|」を入力する。「慶應義塾大学 | keio university」「文学部 OR Faculty of letter」
- フレーズ検索
例えば、「at the mercy of」という英熟語を検索したい場合、そのまま検索しても、「at」や「the」や「of」は一般すぎる語句のため検索に使用されない。このようにフレーズをそのまま検索したい場合は、”at the mercy of”のように””で語句を囲むとそのフレーズがそのまま記載されているホームページが表示される。
- ワイルドカード
キーワード語彙の正確な名称を思い出せない場合、*(アスタリスク)で代用することができる。「基礎*処理」「慶*大学」
- とは検索
日本語サイトから用語を検索したい場合、キーワードの後に「とは」をつけると、その言葉の意味を解説するページが数多く検索できる。「DNSとは」
- 乗換案内や電卓の代用
「日吉から三田」のように地名を"から"で結ぶと乗換案内がトップに表示される。数値演算を入力すると電卓の代用になる。「1024^3 + 1024」「log(10)」「sine(2)」
- キャッシュの利用
検索したにもかかわらず、表示されないホームページに出会うことがある。これは「Google」のデータベースに収録された後にそのページが削除されてしまった場合や現在何らかの事情でそのページが表示できない場合などに生じる。この場合、「キャッシュ」をクリックすれば、「Google」のデータベース上に以前保存されていたページが表示できる。
- 「I'm Feeling Lucky」ボタン
検索結果の最高位にあるホームページがダイレクトにそのまま表示される。検索結果のリストは表示されない。